
Abstract
The availability of electronic medical records (EMR) data has grown dramatically in recent years, and clustering methods are often applied to them for a variety of purposes, including finding unknown subtypes of diseases. The abundance and redundancy of information in EMR data raises the need to identify and rank the features that are most relevant for clustering.
Here we propose FRIGATE, an ensemble feature ranking algorithm for clustering, which uses the concepts of Shapley value and Multiplicative Weights. FRIGATE derives the importance of features from multiple clustering solutions on sub-groups of features. For each clustering solution a small group of features is ranked in a Shapley-like framework, and multiplicative weights are applied to limit the randomness of their choice. FRIGATE outperforms previously suggested ensemble ranking algorithms, both in solution quality and in speed.
1. Introduction
In the past two decades, medical systems around the world underwent a major digitization revolution [1]. As a result, most of the personal medical information is now stored electronically, transforming the way medical research is conducted. Although medical data sharing has been slow [2], the number of clinical data sets available to researchers is growing [3]. Such resources include data sets that span a large range of clinical data types, such as MIMIC [4], [5], and some even offer a combination of genomic and medical information, e.g., the UK BioBank [6].
Medical data have some unique challenging characteristics. Firstly, some of them are of great magnitude. For example, in MIMIC-III alone there is information of 46,520 patients, with 753 different lab tests and 14567 different ICD-9 codes [4] (each test or code is called a feature). Another challenge is the data incompleteness. Medical data typically have high percentage of missing values even for frequently taken measurements [7].
A growing number of machine-learning studies attempted to respond to these challenges on medical data [8] and developed computational tools dedicated to analyzing them [9], [10]. One type of such machine-learning models is clustering, an unsupervised approach, that is used for the discovery of new subgroups of known diseases [11]–[13]. Here patients are partitioned into subgroups based on their feature similarity. Our research is focused on this type of problems.
A key challenge in medical research is the interpretability of the results. When finding new clusters in the data, we want to understand the most important features that distinguish them, in order to assign a clinical meaning to each cluster and obtain clinical insights. When dealing with large data sets with possibly thousands of features, this is challenging. Also, running the algorithms on huge data sets is computationally expensive and even prohibitive. For these reasons, feature selection algorithms, which seek the most important features for the clustering task, were proposed [14]. Our goal here is the development of such an algorithm that ranks all the features according to their importance to the clustering task, in a way that specifically fits medical data.
Many medical databases contain a large number of features. One way to deal with the large number is dimension reduction [15], but such procedures obscure the effect of individual features, which is crucial for medical insights. Another option is to use feature selection algorithms, which choose a subset of features that will create a sub matrix with “good” clusters. There are several feature selection methods for clustering algorithms [14], [16]. In recent years several ensemble feature ranking algorithms were suggested, which create an ensemble of clustering solutions on subsets of features and then use some metric to evaluate the contribution of each feature [17].These include FRMV [18], FRCM [19], and FRSD [17]. These methods were shown to perform better than the traditional filter and wrapper methods, including on medical data sets [17]– [19]. Ensemble methods can also be used for choosing a subset of important features, in addition to ranking the full set of features [20]. Here we develop a new algorithm within the ensemble ranking framework. As we aim to work with medical information, we prefer to lose as little information as possible and thus rank the full set of features.
We introduce a new algorithm called FRIGATE (Feature Ranking In clustering using GAme ThEory), which uses two concepts from game theory. The first is motivated by Shapley value, a measure of the contribution of every player to the group in a cooperative game [21], [22]. In our case the players are the features and the “game” is clustering. Shapley values are widely used for feature evaluation in classification models [22] and so far were not used in clustering for feature selection or ranking. The second is Multiplicative Weights (MW) [23], a framework to improve the selection of players by iteratively selecting the players from a distribution based on their performance so far. In FRIGATE we use MW to guide the choice of features for each clustering solution and thus reduce the chance to choose features that proved to be insignificant. All previously presented ensemble algorithms choose subsets of features at random. To the best of our knowledge this is the first time that MW is adapted to feature selection for clustering.
The paper is organized as follows: we first present relevant background on clustering methods, ensemble feature ranking for clustering and relevant game theory concepts. Next, in the Methods section, we present the FRIGATE algorithm, describe the construction of simulated data and demonstrate a run of FRIGATE. In the Results section we measure the performance of FRIGATE and the extant ensemble algorithms both on simulated and on 11 different real genomics and EMR datasets. We conclude with a discussion of the results.
2. Background
In this chapter we describe the computational methods that will be used in the paper.
A fundamental, broadly used clustering algorithm for data with real-valued features is k-means [24]. Given the number of clusters k, it selects k points in Rd called centroids, assigns samples to the closest centroid and recomputes the new centroid of each resulting set. The process is iterated till convergence.
k-modes [25] is a variant of k-means for categorical data, namely, where feature values are discrete (two or more) categories. The Hamming distance is used as the distance metric instead of Euclidean distance. Here we used the k-modes implementation in [26]. k-prototypes [27] is an algorithm that clusters mixed data, i.e. data with both continuous and categorical features. The distance metric is:
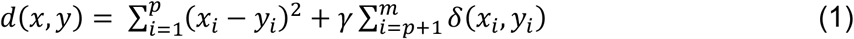 Where x1, … xp are numerical variables, xp+1, … xm are categorical variables, and δ is the Hamming distance function. The γ factor determines the relative contribution of the categorical features in comparison to the continuous features. k-prototypes was reported as one of the best performers in a recent benchmark of mixed-data clustering algorithms [28]. Here we used a k-prototype implementation in [26].
Where x1, … xp are numerical variables, xp+1, … xm are categorical variables, and δ is the Hamming distance function. The γ factor determines the relative contribution of the categorical features in comparison to the continuous features. k-prototypes was reported as one of the best performers in a recent benchmark of mixed-data clustering algorithms [28]. Here we used a k-prototype implementation in [26].
We now briefly describe extant ensemble feature ranking algorithms for clustering. In the FRMV algorithm [18], in each iteration of the algorithm a clustering solution is obtained for a subset of features, which are ranked based on some relevance measure (e.g. linear correlation). The final feature ranking is done according to the average rank. FRCM [19] was originally designed for genomic data. It does not require k as an input. For each run of k-means on a subset of features, k is selected uniformly at random from a prescribed range. Features are ranked based on a measure similar to Adjusted Rand Index [29] which measures the similarity between a consensus matrix for the clustering solutions, and a matrix for each feature, representing distances between pairs of samples for that feature. Finally, in the FRSD algorithm [17], in each iteration the algorithm randomly chooses a subset of the features, produces a clustering solution using k-means and ranks the selected features based on the change in the silhouette score [30] after shuffling the values of the feature. A prescribed range of k values is tested and the final score is based on the average rank of the iterations per k and over all values of k. Since no implementations were provided for the three algorithms, we implemented them as described in [17]–[19]. For FRMV we used the linear correlation as the relevance measure. For FRSD we used silhouette as implemented in Scikit learn [31]. In all cases we used k-means for clustering.
Shapley Values
In cooperative game theory, a set N of players can form coalitions. Each coalition S ⊂ N has a value g(S). According to the Shapley theory [21] the contribution of player i to group S ∪ {i} is defined as:
 and the Shapley value of player i is a weighted average of its contributions over all possible Ss, i.e.:
and the Shapley value of player i is a weighted average of its contributions over all possible Ss, i.e.:
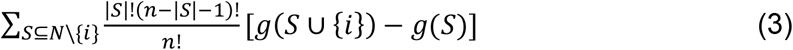 This value is widely used in supervised learning to measure the contribution of a feature to a prediction model, where for efficiency reasons it is usually evaluated using random permutations instead of enumerating all possible groups S [22]. To the best of our knowledge, Shapley values were not used to date in feature selection for clustering.
This value is widely used in supervised learning to measure the contribution of a feature to a prediction model, where for efficiency reasons it is usually evaluated using random permutations instead of enumerating all possible groups S [22]. To the best of our knowledge, Shapley values were not used to date in feature selection for clustering.
Multiplicative Weights
Multiplicative Weights (MW) is an algorithmic update method used in game theory and algorithm design. The motivation of MW [23] is to iteratively improve the decisions one makes by gradually favoring decisions that were proven to be right so far. In our case the decisions are the features selected and we use the Hedge update rule that was suggested by Arora et al. [23]:
 Where
Where 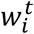 is the weight of feature i at the t-th iteration, η ≤ 1 is a constant parameter and mt is the cost of feature i at iteration t.
is the weight of feature i at the t-th iteration, η ≤ 1 is a constant parameter and mt is the cost of feature i at iteration t.  is a value in the range [−1,1] that reflects how good decision i was in iteration t, where higher positive values correspond to worse decisions and negative values correspond to good decisions that warrant an award instead of a cost. A common practice, also used in our implementation, is to use non-negative values only.
is a value in the range [−1,1] that reflects how good decision i was in iteration t, where higher positive values correspond to worse decisions and negative values correspond to good decisions that warrant an award instead of a cost. A common practice, also used in our implementation, is to use non-negative values only.
3. Methods
3.1 The FRIGATE algorithm
FRIGATE is a new ensemble feature ranking algorithm, which uses the Shapley value concept to find the most valuable features for clustering based on multiple runs of k-means (or k-prototypes/k-modes) algorithm.
To use the Shapley values in our context, the players are the features. We assume the number of clusters k is given, and use the total distance of samples to their cluster centroids as the objective function g:
 Here S is a set of features, k is the number of clusters, Cj is the set of samples included in cluster j and yj is the centroid of cluster j. dS is the distance function on the sample vectors restricted to the coordinates in S. We call g(S) the solution score.
Here S is a set of features, k is the number of clusters, Cj is the set of samples included in cluster j and yj is the centroid of cluster j. dS is the distance function on the sample vectors restricted to the coordinates in S. We call g(S) the solution score.
dS and the clustering algorithm that we use will depend on the data types in S. If all the features are continuous then we use k-means for clustering and the Euclidean distance. When we have a mixture of categorical and continuous features, we will use k-prototype for clustering, and the corresponding distance function (Equation 1). If we have only categorical features, k-modes is used for clustering with d as the Hamming distance. We used k-means as implemented in Scikit learn [31] with 100 k-means++ initializations in each run.
Algorithm 1 presents the procedure for continuous features. In iteration t, the algorithm selects at random a subset of features and performs k-means on the corresponding submatrix A(t). Once a solution has been obtained, we calculate the contribution of feature i as the difference between that solution’s score and the score obtained by the same clustering on the submatrix A(t) in which the values of feature i were randomly shuffled among the samples, keeping the rest unchanged. For the final ranking we use the average scores of the features.

Note that FRSD can also be seen as a type of a Shapley-like algorithm with a function g that uses the silhouette. However, a main difference is that FRIGATE does not rank the features on every iteration and accumulates the ranks for the final score, as in FRSD and FRMV, but instead summarizes the raw scores. That way poor clustering solutions that are based on non-informative features will have large g(h) values (line 8 in Algorithm 1) as well as large gv values (line 12). This will limit the ability of these features to receive high scores, as they are calculated by subtracting the distance after shuffling the values of a feature from the original distance (line 13 in Algorithm 1). Thanks to these properties of g(h) and gv, we do not need to use an additional factor, as FRSD does with silhouette, to assess the quality of the clusters. It also reduces the number of calculations and improves the efficiency of the algorithm.
We now discuss runtime complexity, referring only to k-means for simplicity. The runtime of k-means is O(m · q · k · c) for m samples, q features, k clusters and up to c iterations. We sample in each FRIGATE iteration q = f · n features. For each k-means run we perform i initializations. Therefore, the runtime of the k-means executions in each iteration of FRIGATE is O(mqkci). Other than k-means runs, in each iteration we shuffle the values of q features over the full cohort in O(m) for each feature and recalculate the solution score dv in O(m). The overall runtime of an iteration is O(mqkci + mq) = O(mqkci). Hence, the additional actions to test the contribution of each feature do not increase the asymptotic runtime. We perform T iterations, so the overall runtime is O(mTqkci). As q = f · n with constant f we can write the runtime as: O(mTnkci).
3.2 The FRIGATE-MW algorithm
MW offers a smarter way to choose the features in FRIGATE for each clustering solution instead of choosing them randomly. Algorithm 2 shows the version of FRIGATE that uses MW for continuous features, which we call FRIGATE-MW.
We define an n-long array L so that  . At each iteration we rank the features by their scores so far and use the ranks and L to determine
. At each iteration we rank the features by their scores so far and use the ranks and L to determine  (see chapter 2). If the rank of feature i at iteration t is r then
(see chapter 2). If the rank of feature i at iteration t is r then 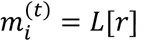 . The weights of features that were not selected in the iteration remain unchanged. For the next iteration we select features from distribution
. The weights of features that were not selected in the iteration remain unchanged. For the next iteration we select features from distribution  where
where 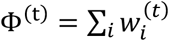 is the sum of weights at the t-th iteration. To the best of our knowledge, this is the first use of MW in feature selection for clustering.
is the sum of weights at the t-th iteration. To the best of our knowledge, this is the first use of MW in feature selection for clustering.

In each iteration we update the weights of the q participating features in constant time for each feature and sort the array of weights in O(n · log(n)). The overhead of MW for each iteration is thus O(n · log(n) + q) = O(n · log(n)), since q < n . The total runtime of each iteration in FRIGATE-MW is: O(mqkci + n · log(n)) . Therefore, the total runtime is: O(mTqkci + Tn · log(n)) = O(Tn(mkci + log(n))). Altogether, the increase in the runtime over FRIGATE is not major. However, note that in FRIGATE-MW the iterations cannot be programmed to run in parallel, in contrast to FRIGATE.
For both variations of the algorithm we used T = 2n and f = 0.1, and for FRIGATE-MW we used η = 0.5. For a detailed description of the parameter choice see Supplementary 2.
3.3 Simulation
We performed simulations in order to test the algorithms in situations where the true clustering and the informative features are known. The simulations were along the same lines of those described in [17]. The parameters of the simulation are:
k – number of clusters
c – number of samples in each cluster
α – number of informative features
β – number of non-informative features
μ – distribution parameter
σ – correlation coefficient between features
Simulating continuous data: For each cluster j, we construct c vectors of length n = α + β from multivariate normal distribution, where α features are sampled from a normal distribution with mean of j · μ for jϵ[0, …, k − 1]. The other β features are sampled from a normal distribution with mean 0 for all clusters and therefore represent the non-informative features. Thus, the mean vector of a sample in the jth cluster is: μj = [(j · μ)αx1, 0βx1].
Next, we define a covariance matrix, parameterized by σ, used to create correlations between the different features. The covariance matrix Σ is identical for all clusters:
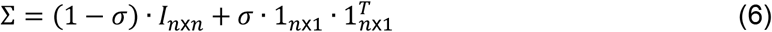 The nx(k · c) data matrix A then undergoes z-score normalization for each feature. This step is needed when working with many data types, especially in the medical domain as the values of different features can be of different magnitude.
The nx(k · c) data matrix A then undergoes z-score normalization for each feature. This step is needed when working with many data types, especially in the medical domain as the values of different features can be of different magnitude.
Simulating mixed data: To build a simulation of mixed data we add three more parameters:
αcategorical – number of informative categorical features
βcategorical – number of non-informative categorical features
p – probability of choosing the right category
We assume that the categorical features have k categories, labeled {0,1, …, k − 1}. For the informative features of a sample in the jth cluster, we choose the value j with probability p and a value from {0, …, k − 1}\{j} with probability 1 − p where the value is chosen uniformly at random. For the non-informative features we choose a random value uniformly from {0, …, k − 1}. The simulation of the continuous features is done as described before, and we concatenate the two matrixes into a single input matrix. In our simulation we used p = 0.95.
3.4 Demonstration of FRIGATE
For better understanding of the FRIGATE process, we demonstrate it graphically. We simulated data as described in section 3.3, with two continuous features, two clusters (k = 2), and 100 samples in each cluster, and simulation parameters μ = 4, σ = 0. Figure 1 shows the data, where each axis is a feature and the samples are colored by cluster membership. We simulated three scenarios:

Illustrations of simulations with two clusters. In the simulation, there are 100 samples in each cluster, μ = 4, σ = 0, and two features. A-C: features are represented by the axes. Each color represents a different cluster. A: both features are informative for clustering, B: only the feature represented by the y axis is informative, C: both features are not informative. D: Demonstration of FRIGATE iteration on the data of A-C. Solution score refers to line 8 in Algorithm 1, feature’s score refers to line 13 in Algorithm 1. F1 is represented by the x-axis in Figure1 A-C and F2 is represented by the y-axis. We can see that the informative features received higher scores than the non-informative ones.
Both features are informative for the clustering solution (Figure 1A).
Only one feature is informative (Figure 1B)
Both features are not informative (Figure 1C).
Next, we performed an iteration of the FRIGATE algorithm, using the centroids obtained from the clustering solution on the two features, to show the differences in scores in each scenario (Figure 1D):
When the two features were informative, the solution score (line 8 in Algorithm 1) was 81.76, and the scores of the features (line 13 in Algorithm 1) were 313.48 and 286.33. Both feature scores are high, and the difference can result from the randomness in shuffling the values (line 10 in Algorithm 1) or from the simulation that might have produced one feature that is more informative than the other.
When only one feature was informative, the solution score was 237.28, and the feature scores were 0.51 for the non-informative features and 304.05 for the informative feature.
When the two features were non-informative, the solution score was 256.48, and the feature scores were 117.59 and 150.57.
In Figure 2 we demonstrate graphically the iteration for scenario 2 (line 2 in Table 2). Figure 2A shows the results of k-means clustering of the data (line 6 in Algorithm 1), with a solution score of 237.28. Figure 2B shows the data after shuffling the values of the non-informative feature (line 10 in Algorithm 1). The shuffled data has an almost identical solution score of 237.79 (line 12 in Algorithm 1) and a feature score of 0.51. Figure 2C shows the sample locations after shuffling the values of the informative feature, which gives a new solution score of 541.33 and a feature score of 304.05.

Illustrations of the different steps of FRIGATE for scenario 2 that is shown in Figure 1B, where one feature is informative (y axis) and one is non-informative (x axis). A – a clustering solution of the data (line 6 in Algorithm 1) colored by clusters labels. The solution score is 237.28 (line 8 in Algorithm 1). B-Results of shuffling the x coordinates, representing the non-informative feature (lines 10-13 in Algorithm 1). The solution score is similar to A and the feature’s score is 0.51. C-Results of shuffling the y coordinates, representing the informative feature. An increase in the solution score led to a feature’s score of 304.5.
The illustrations of scenarios A and C are given in Supplementary 3. In all scenarios the informative features scored much higher than the non-informative ones. Notice that the differences in scores are due to the initial solution score of each scenario – the poor results of scenario 3 already produced a relatively high solution score, so the ability of any feature to score high is limited.
3.5 Evaluation measures
When applied to a real dataset, each algorithm produces a ranking of the features. In our tests the truly informative features were unknown but the “true” clustering is known. We therefore applied the following procedure from [17]–[19] to evaluate the results. We ran k-means on the subset of the data containing only the j top ranked features. The clustering produced was compared to the true labels available for the dataset using the Adjusted Rand Index (ARI) [29]. The process was repeated with increasing values of j, for jϵ[1, N] for N number of features. The rationale was that a better feature ranking will manifest a high ARI for smaller values of j, as it puts the most informative features at the top. The process was repeated ten times per algorithm.
The above measure gives a value for the top j features, and a separate value for each j. We developed two new scores that summarize the measure across all values of j, while giving higher weight to the features that rank higher.
Suppose M feature ranking algorithms are compared on the same dataset. For each j, we compute the ARI of each algorithm on the top j features that it selected, and rank the algorithms based on their scores, from 1 for the top performer to M. For simplicity of the description, we assume there are no ties. The weighted rank of algorithm a is defined as:
 Here rank(a, j) is the rank of algorithm a on the top j features. Hence, the second factor in the sum ranges from 1 for the top ranked algorithm to 1/M for the worst ranked, and the first factor gives a different weight to each j, from N for the first feature to 1 for the last ranked. The factor
Here rank(a, j) is the rank of algorithm a on the top j features. Hence, the second factor in the sum ranges from 1 for the top ranked algorithm to 1/M for the worst ranked, and the first factor gives a different weight to each j, from N for the first feature to 1 for the last ranked. The factor  rescales the total sum to [0,1].
rescales the total sum to [0,1].
The WR measure is relative and depends on the set of algorithms tested. We introduce a second measure for a single algorithm. The algorithm’s ARI score is computed for each top j features and weighted as above. The weighted ARI of algorithm a is defined as:
 where ARI(a, j) is the ARI of algorithm a on the top j features. Hence, the range of the score is [-1,1] and higher scores are better.
where ARI(a, j) is the ARI of algorithm a on the top j features. Hence, the range of the score is [-1,1] and higher scores are better.
Both scores can be generalized to handle ties and also situations where not all values of j are tested, e.g., when there are too many features.
4. Results
4.1 Algorithms Performance
We measured the performance of FRMV, FRSD, FRCM, FRIGATE and FRIGATE-MW on simulated and real data, including four genomic and seven EMR datasets. The number of clusters k in FRIGATE and for FRMV was chosen with the elbow method that we implemented as suggested in [32].
4.1.1 Simulated Data
We simulated data with 200 samples and 100 features of which 20 are informative, divided into two or four equal-sized clusters (k = {2,4}), mean distances μ = {0.5,1,2,4} and feature correlation levels σ = {0,0.05,0.2, 0.5}. We ran the algorithms on data with and without z-score normalization. The accurate recognition rate is defined as the fraction of informative features in the top 20 ranked features. Results for k = 4 with μ = {0.5,1} are shown in Tables 1, and the other cases are found in Supplementary 5. In all cases, the elbow method chose k = 2. On normalized data FRCM performed best, and FRIGATE-MW second. On non-normalized data FRIGATE-MW was best. FRMV scored poorly in all cases. FRSD scored poorly in most normalized scenarios, while in most non-normalized scenarios it scored high. We can also see that in general smaller values of μ and k account for harder cases, and normalized data is more challenging than non-normalized data. The FRIGATE variations and FRCM are affected by the correlation levels, where high levels of correlation cause a drop in performance. We can see the major drop in performance of these algorithms for σ ≥ 0.2. FRSD and to some extant FRMV show opposite behavior, where extreme levels of correlation lead to improved results. This is counter-intuitive, as high correlation levels are expected to cause higher similarities between all features, including pairs of informative and non-informative ones. FRSD and FRMV are also more affected by the structure of the data (k, μ, normalized. See Supplementary 5) in comparison to FRIGATE and FRCM (see Discussion). It is worth mentioning that as 20% of the features were informative, a score below 0.2 accounts for performance worse than random ordering of features. FRMV repeatedly scored below 0.2, FRSD scored low for most of the normalized cases with low correlation levels, and FRIGATE scored below random levels in the extreme correlation setting. FRCM is the only algorithm that rarely dropped significantly below random levels (Supplementary 5).
In bold are the top performers.
4.1.2 Real Data
We tested the five algorithms on 11 real genomic and EMR datasets from different sources for which a known clustering was available or created by us. The datasets are described in Table 2. Figure 3 shows the performance of the algorithms on four genomic databases [33]–[36] (datasets 1-4 in Table 2). These datasets were used in a benchmark of clustering [37]. They have a large number of features and a modest number of samples (about two orders of magnitude lower). Note that here we do know the true clustering but we do not know which and how many features are informative, but it is expected that many features do not carry information relevant to the clustering. In all cases the value chosen by the elbow method for FRIGATE and FRMV was k = 2.
The numbers in parentheses in column “# of samples” are the sizes of the clusters, and in the column “# of features” are the number of continuous and categorical features, respectively.

Performance of the tested algorithms on genomic datasets. The ranking produced by each algorithm was used to cluster the data with a growing number of features. The Y axis is the ARI score compared to the known clustering. The results are average of ten runs. The light-colored sleeve around each plot is ±1 std. A-D for datasets 1-4 in Table 2, respectively.
The performance of both variations of FRIGATE and FRSD was comparable and generally good, reaching maximum ARI of 0.35-0.7 already with less than 100 features in most cases. FRSD performed markedly better than the other methods on dataset 3 (Figure 3C). FRCM performed poorly in most cases, with slow gradual increase in ARI. FRMV performed better than the others on dataset 2 (Figure 3B), and its results had a wide variance across repetitions in most cases. It is worth mentioning that the description of the FRMV algorithm in [18] was not clear, especially calculating linear correlation between continuous features and categorical cluster membership. This, as well as sampling features with replacement, can potentially create major variability between different runs of the algorithm.
We created three EMR datasets from the MIMIC-III repository [4], [5] and three from the eICU repository [40], [41], both downloaded from PhysioNet [3] (datasets 5-7, 9-11 in Table 2). The input features used were continuous, containing lab tests (“labs”), age and length of stay in the hospital (days in MIMIC and minutes in eICU) and Apache score in eICU. For each lab, we included only the first measurement that was available for the patient during the ICU stay. For each patient we included data from a single ICU stay. For the MIMIC datasets ICD-9 diagnosis codes were extracted per ICU stay and used for labeling the patients. For the eICU datasets, diagnoses and Apache score parameters were used as categorical variables and for labeling. Labs that were missing in >70% of the cohort were removed. To remove potential outliers, we z-scored each continuous measurement across the cohort, and removed patients that had any lab with |z − score| ≥ 3. We then applied the Iterative Imputer as implemented in [31] to the raw data to complete missing data and performed z-score normalization. The MIMIC cohorts that we constructed were:
Dataset 5 – patients that had a cancer ICD-9 diagnosis, aged 18-40. The data were divided into two clusters by length of stay: 122 patients who were discharged alive and spent less than 18 days in ICU, and 39 patients who either died during the ICU stay or stayed 18 days or more at the ICU. 70 features were recorded.
Dataset 6 – “healthy” patients: individuals aged 20-30 who did not have ICD-9 diagnosis of cancer, benign tumors, hypertension, cardiac disease, endocrine related disease, or hepatitis and stayed up to one day at ICU. They were divided into two clusters by sex: 84 males and 26 females. Here 47 features were recorded.
Datasets 7 – Newborns divided into two clusters: 1534 with jaundice and 3752 without jaundice, with 29 features.
The results on these datasets are shown in Figure 4A-C and summarized in Table 3. For Dataset 5 (Figure 4A), when using up to 50% of the ranked features FRIGATE performance was best. With over 50% of features FRCM results were comparable. For Dataset 6 (Figure 4B) FRCM was best followed by FRIGATE. FRMV performed comparably to FRIGATE and FRSD performed worst. For Dataset 7 (Figure 4C) with up to 50% of features FRCM performed best. With 50% or more of the ranked features the results of FRIGATE and FRMV were comparable to FRCM or better. FRSD was the worst performer.
In bold are the top performers.

A-D: Performance on datasets 5-8 respectively. See Figure 3 for caption details.
Dataset 8 consists of heart failure patients from Zigong Fourth People’s Hospital [38], [39], also extracted from PhysioNet. This cohort was divided into two age groups: 68 patients of ages 29-49 and 101 patients of ages 89-100. We had 77 features in this cohort after removing features with >30% missing data, and used the Iterative Imputer for missing data. The results are shown in Figure 4D and Table 3. Here FRSD performed comparably to FRIGATE and even slightly better in some thresholds, with FRMV and FRCM performed much worse, with especially poor results in the first 40% of features. A full comparison among the results is found in Supplementary 6.
The eICU cohorts that we constructed included Caucasian patients admitted directly to ICU with sex labels:
Dataset 9 – intubated patients aged 70 and above were divided according to status at discharge of “Alive”, 305 patients, and “Expired”, 136 patients. 87 continuous and 70 categorical features that had a value in at least 1% of the cohort were used.
Dataset 10 – patients who stayed up to one day in ICU, separated by age groups: 487 patients aged 18 to 80, and 83 patients aged 80 or older. 59 continuous and 20 categorical features that had a value in at least 5% of the cohort were used.
Dataset 11 – patients aged 18-30 separated by length of stay: 138 who stayed over 4.5 days (>6500 minutes) or expired, and 94 who stayed 4.5 days or less and were discharged alive. 72 continuous and 14 categorical features that had a value in at least 5% of the cohort were used.
The results for the eICU datasets are shown in Figure 5. Figures 5A, 5C, 5E compare all algorithms using the continuous features only. The same trends are observed – both versions of FRIAGTE and FRCM perform best, FRMV has a large variance in results and FRSD performs poorly.

Performance on datasets 9-12 from the eICU repository. See Figure 3 captions for details. A-B: dataset 9, C-D: dataset 10, E-F: dataset 11. A, C, E show results when using only the continuous features of the datasets, and B, D, F show results for the mixed data.
We next used these datasets to test the ability to improve the results by adding categorical features. We tested different values of γ and looked for a change in the ARI of the full set of features in comparison to only using the continuous features (results not shown). A change in ARI means a different composition of the clusters caused by the categorical features. For γ < 5 in most cases there was no change in the composition of the clusters, and γ > 6 lead to a major decrease in ARI. We therefore chose γ = 6 in all cases. In most datasets we do not see an improvement, and in some cases more features were needed to reach high values of ARI. Overall, the categorical features did not improve the solution. Interestingly, in dataset 10 (Figure 5D) adding the categorical variables harmed the performance of FRIGATE-MW more than that of FRIAGATE.
In Table 4 we show the weighted rank (WR) and weighted ARI (WARI) scores of all algorithms for datasets 1-11. Apart from dataset 7 with the WARI, a variant of FRIGTAE is among the top two algorithms in all cases. In terms of WR, FRIGATE was best in the 4 cases and second in 4, and FRIGATE-MW was best in one and second in 6. In terms of WARI, FRIGATE was best in 4, second in 2, FRIGATE-MW best in 2 and second in 5 cases. FRCM was best in 3 and second in one case for both measures.
In bold is the top performer for the dataset, underlined is the second best. * -Datasets where the top two performing algorithms were different for the two evaluation metrics.
4.2 Clinical Significance – Test Case
We wished to evaluate the clinical relevance of the leading chosen features to the target labels. We chose to focus on Dataset 6 as there is evidence for sex-based differences in lab tests [42]. We chose the twelve features that were available in both cohorts and according to [42] fulfil:
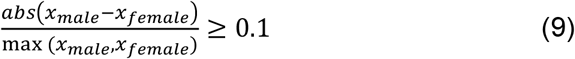 where xi is the mean value of feature x for sex i [42]. We call these the top features. A ranked list of all features according to FRIGATE and FRIGATE-MW and the top features are in Supplementary 7.
where xi is the mean value of feature x for sex i [42]. We call these the top features. A ranked list of all features according to FRIGATE and FRIGATE-MW and the top features are in Supplementary 7.
We performed a hypergeometric test between the 12 top ranked features according to FRIGATE and the top features from [42], and similarly for FRIGATE-MW. For FRIGATE-MW, six of the top ranked features were also top features in [42] giving a significant p-value of 0.034. For FRIGATE, five of the top twelve features were common with the top features of [42], which accounts to a non-significant p-value of 0.136.
We also calculated the p-value of the minimum hypergeometric score (mHG), as used in the DRIM algorithm [43], for calculating the significance without determining in advance the threshold for the hypergeometric test and accounting for multiple testing. For FRIGATE the mHG was obtained for 13 features, with p-value of 0.07. For FRIGATE-MW the threshold was 10 features with p-value of 0.01.
It is important to remember that [42] refers to seemingly healthy individuals, while Dataset 6 comprised of patients who spent in the ICU for up to one day, and some stayed overnight. That means that although the patients were young and did not require a major intervention, they still suffered from some medical condition. Indeed, the top feature in both versions of FRIGATE was “days in hospital” (more females stayed overnight, details not shown), which might suggest some correlation between the clusters and the medical condition, together with the correlation with sex.
4.3 Runtime comparison
Table 5 shows the runtimes on Databases 1-8 for the tested algorithms. The FRIGATE variants are slower on the genomic Datasets 1-4, which have many features and a few samples, but fast on the EMR datasets, which have less features. FRCM runs faster on Datasets 1-4, but when the number of samples grows its runtime increases sharply (Database 7).
Results are mean±STD of five runs for Datasets 1-4 and of three runs for Datasets 5-8 (the number of repetitions was reduced as the total runtime was large).
The behavior of FRIGATE can be explained by the choice to set the number iterations depending on the number of features. However, this is a tunable parameter with a trade off with f, the number of features included per iteration (see Supplementary 2). FRCM, on the other hand, has a set number of iterations, and produces an mxm matrix for each feature, which is expensive both in runtime and in space. Note also the slowdown of FRSD on Dataset 7, which has thousands of patients.
5. Discussion
We presented here FRIGATE, a new ensemble feature ranking algorithm for clustering, aimed for clustering of medical data. To the best of our knowledge, this is the first use of MW within the feature ranking for clustering framework and the first explicit use of Shapley values for unsupervised feature selection. Unlike extant ensemble feature ranking algorithms, FRIGATE incorporates categorical and mixed data features. In tests on simulated and on real EMR datasets FRIGATE was the only algorithm that performed constantly well, and had an acceptable runtime in all cases.
The simulation results revealed interesting behaviors of the tested algorithms. FRSD and FRMV seem to improve, while FRIGATE and FRCM performed worse with higher correlation levels. Intuitively, it should be harder to set apart the informative features from the full set of features when high correlation levels are present. Our hypothesis is that enforcing extreme levels of correlation between all features shaped the data so that the differences between features are better captured by the changes in the silhouette score, which is incorporated in FRSD. This should be further addressed in future research.
When algorithms had accurate recognition rates below the random 0.2, the informative features tended to be recognized as non-informative. Indeed, at the bottom 20 features of FRIGATE on 10 simulation runs with: k = 4, μ = 2, σ = 0.05 and normalized data, 68 ± 24% of the informative features were in the bottom 20%. This suggests that not only that FRIGATE did not recognize the informative features, but high levels of correlation make the algorithm recognize the informative features as the most non-informative. Although these levels of correlation are unrealistic, the behavior of the algorithm is not fully understood. Further research is needed to understand why the distance to centroids, which is objective function used by FRIGATE, was affected more dramatically for non-informative features when the correlation levels between all features were high.
FRIGATE and FRIGATE-MW had different behavior on simulated and real data. On simulated data, the two algorithms performed comparably, but when a difference was observed it was usually in favor of FRIGATE-MW. This suggests that MW has the potential to improve random selection of features in unsupervised tasks. On real data FRIGATE performed slightly better than FRIGATE-MW. However, although the algorithm was designed to work with mixed data, including categorical features did not improve the results. Future work should evaluate the possible contribution of MW to the ensemble framework, and more specifically, broaden the options for cost functions, which are a key factor in MW.
A limitation of FRIGATE compared to FRSD and FRCM is that the number of clusters k is needed as input. However, when testing different values of k on simulated data, the FRIGATE results were stable even when the input k was much larger than the real k (see Supplementary 8). Future research should test waiving the required input k. FRSD and FRCM are averaging their results over different values of k, but this method is currently not relevant for FRIGATE, as the solution score is affected by the number of clusters, and averaging over different values of k will probably be biased.
Our study has several limitations. We compared FRIGATE to three other algorithms for which code was not available. Their reported performance here is based on our implementation. This is mostly relevant to the runtime comparison. Other implementations may improve runtime for some of the tested algorithms.
A key limitation in the evaluation of EMR data was the validity of the clusters that we produced. Heterogenous cohorts like these of MIMIC and eICU may contain multiple overlapping subgroups, which may confound clustering attempts and their evaluation. Including mixed data where both the categorical and continuous features are relevant, was another challenging task. In our tests, adding the categorical features did improve the results, and in some cases harmed them. Also, all the datasets that we generated were partitioned into two clusters. More analysis is needed on medical datasets with mixed data and a larger number of clusters.
We used the elbow method for choosing k, the number of clusters. In all runs of both simulated and real data, the value k = 2 was chosen, even when the real number of clusters was higher. This is in line with a previous report [13]. Although we showed on simulated data that FRIGATE is unaffected by choosing the wrong k, there is a need for a better method to choose k.
Data Availability
All real data used in this paper are from publicly available sources. See Table 2 for details.
6. Data availability
All real data used in this paper are from publicly available sources. See Table 2 for details.
7. Code availability
The code for FRMV, FRCM, and FRSD was not provided by their authors, and we reimplemented them. Their code, as well as the code for FRIGATE and FRIGATE-MW, are available in: https://github.com/Shamir-Lab/FRIGATE
8. Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
9. Acknowledgements
This study was supported in part by a grant from the Tel Aviv University Center for AI and Data Science (TAD). ES was supported in part by a fellowship from the Edmond J. Safra Center for Bioinformatics at Tel-Aviv University.
Footnotes
Addresses: 1 Tel Aviv University, P.O. Box 39040, Tel Aviv 6997801, Israel




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}