
Abstract
A logistic formula in biology is applied to analyze deaths by COVID-19 for both of the first and the second waves in Japan. We then discuss ends of both waves and their mortality ratios. The meaning of population N in an epidemic is discussed.
1 Introduction
The SIR model [1] in the theory of infection is powerful to analyze an epidemic about how it spreads and how it ends [2-8]. The SIR model is composed of three equations for S, I and R, where they are numbers for susceptibles, infectives and removed, respectively. Three equations can be solved numerically, if two parameters α and c are given, where α is the basic reproduction number and c the removed ratio.
In Sec. 2 we summarize approximate solutions of the SIR equations, based on the logistic formula in biology [9], which have been derived in a previous work [10]. These approximate solutions have simple forms, so that they are very useful to discuss an epidemic. In Sec. 3 these solutions are applied to fix the basic reproduction number α and the removed ratio c, especially from data of accumulated number of deaths by COVID-19 for the first wave in Japan. Here, our policy is to use only data of deaths, but not of cases. The mortality ratio for the first wave is also calculated. In addition we discuss the meaning of population N in an epidemic. In Sec. 4 same things are given for the second wave. The final section is devoted to concluding remarks. In Appendix data of deaths for the first and the second waves are summarized.
2 A logistic curve from the SIR model
Equations of the SIR model [1] are given by


 where S, I and R are numbers for susceptibles, infectives and removed, respectively,b the infection ratio and c the removed ratio. From Eqs. (2.1) and (2.3) we get dS/dR = −αS, (α = b/c), which is integrated to be
where S, I and R are numbers for susceptibles, infectives and removed, respectively,b the infection ratio and c the removed ratio. From Eqs. (2.1) and (2.3) we get dS/dR = −αS, (α = b/c), which is integrated to be
 where α stands for the basic reproduction number. In the same way, from Eqs. (2.2) and (2.3), we have dI/dR = αS − 1 = α exp(−αR) − 1, which is integrated to be
where α stands for the basic reproduction number. In the same way, from Eqs. (2.2) and (2.3), we have dI/dR = αS − 1 = α exp(−αR) − 1, which is integrated to be
 The solutions (2.4) and (2.5) satisfy boundary conditions S = 1 and I = 0 at R = 0. We normalize the total number to be unity, i.e., S + I + R = 1. Since I(t) is 0 when t → ∞, we have 1 − R(∞) − exp[−αR(∞)] = 0 from Eq.(2.5). Hence, it follows a useful formula
The solutions (2.4) and (2.5) satisfy boundary conditions S = 1 and I = 0 at R = 0. We normalize the total number to be unity, i.e., S + I + R = 1. Since I(t) is 0 when t → ∞, we have 1 − R(∞) − exp[−αR(∞)] = 0 from Eq.(2.5). Hence, it follows a useful formula
 Some exact formulas at the infection peak t = T are summarized as follows:
Some exact formulas at the infection peak t = T are summarized as follows:

 The first one is derived as follows: Since the peak point is given by dI/dt = c(αS − 1)I = 0 at t = T, we get S(T) = exp[−αR(T)] = 1/α. This proves Eq.(2.7). The second equation (2.8) directly follows by I(T) = 1 − R(T) − S(T) = 1 − ln α/α − 1/α.
The first one is derived as follows: Since the peak point is given by dI/dt = c(αS − 1)I = 0 at t = T, we get S(T) = exp[−αR(T)] = 1/α. This proves Eq.(2.7). The second equation (2.8) directly follows by I(T) = 1 − R(T) − S(T) = 1 − ln α/α − 1/α.
Let us summarize logistic formulas for SIRs functions [10]. The third equation (2. 3) can be written as
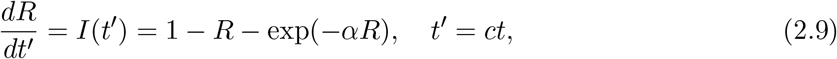 with t the true time. Let us expand the exponential factor in the second order of x = αR,
with t the true time. Let us expand the exponential factor in the second order of x = αR,
 Then we have
Then we have
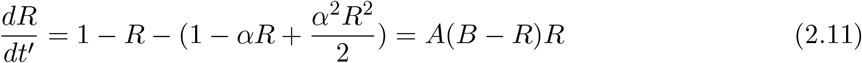 with A = α 2/2, B = 2(α − 1)/α2. This equation is a type of the logistic growth curve in the biology [9], easily solved as
with A = α 2/2, B = 2(α − 1)/α2. This equation is a type of the logistic growth curve in the biology [9], easily solved as
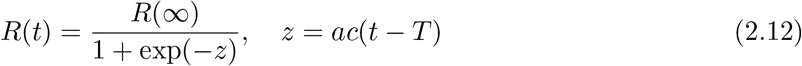 where AB = α − 1 = a and B = R(∞) = 2(α − 1)/α2. Inserting R(t) into I(t) = (1/c)dR/dt, we have
where AB = α − 1 = a and B = R(∞) = 2(α − 1)/α2. Inserting R(t) into I(t) = (1/c)dR/dt, we have
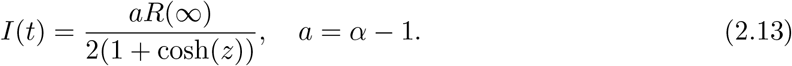 Note that peak values of I(t) and R(t) at t = T are given by
Note that peak values of I(t) and R(t) at t = T are given by
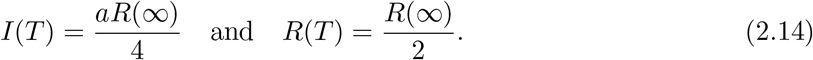 Hence we have a useful formula
Hence we have a useful formula

3 Application to COVID-19 for the first wave
We make use of data [11] of deaths rather than cases. It is our policy not to use data of cases. Define the mortality ratio λ by
 where D(t) is the accumulated number of deaths. For the population N, the total number of deaths at t is given by
where D(t) is the accumulated number of deaths. For the population N, the total number of deaths at t is given by
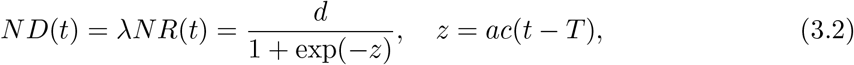 where d = ND(∞) = λNR(∞) stands for the final total number of deaths. Note that from Eq.(3.2) we have a theorem, ND(T) = d/2, which means the total number of deaths at the peak is just a half of the final ones.
where d = ND(∞) = λNR(∞) stands for the final total number of deaths. Note that from Eq.(3.2) we have a theorem, ND(T) = d/2, which means the total number of deaths at the peak is just a half of the final ones.
Let us rewrite Eq.(3.2) into the form as
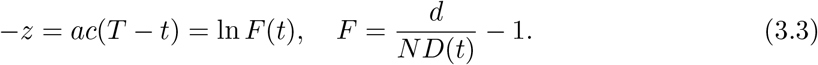 Accordingly, for different times t1, t2 and t3 we have
Accordingly, for different times t1, t2 and t3 we have

 (ND(t) is the total number of deaths in the first wave at t in Japan, which is an average of 5-day deaths of t − 2, t − 1, t, t + 1, t + 2. The t is the number of date starting from Feb. 16) A use is made of data of deaths [11]. Substituting data on the Table 1 into Eqs.(3.4) and (3.5), and eliminating ac, we get
(ND(t) is the total number of deaths in the first wave at t in Japan, which is an average of 5-day deaths of t − 2, t − 1, t, t + 1, t + 2. The t is the number of date starting from Feb. 16) A use is made of data of deaths [11]. Substituting data on the Table 1 into Eqs.(3.4) and (3.5), and eliminating ac, we get
Date and the total number of deaths in the first wave
 This is nothing but the equation for d, that is,
This is nothing but the equation for d, that is,
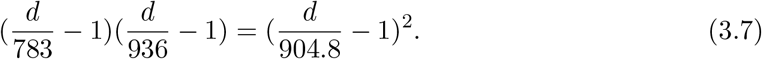 We find a solution of this equation to be d=984. According to the theorem ND(T) = d/2, the number of deaths at t = T is d/2 = 492. This means the peak day is May 2nd, as seen on data. The result of d = 984 is substituted into Eq.(3.4), then it follows
We find a solution of this equation to be d=984. According to the theorem ND(T) = d/2, the number of deaths at t = T is d/2 = 492. This means the peak day is May 2nd, as seen on data. The result of d = 984 is substituted into Eq.(3.4), then it follows
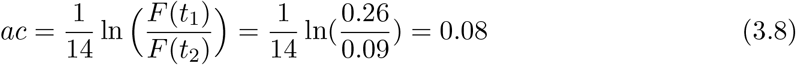 In the following we take c = 0.04, which is frequently quoted value. Then we have a = 0.08/0.04 = 2.00, that is, α = 1 + a = 3. Also, from the formula (2.6) it follows R(∞) = 0.94.
In the following we take c = 0.04, which is frequently quoted value. Then we have a = 0.08/0.04 = 2.00, that is, α = 1 + a = 3. Also, from the formula (2.6) it follows R(∞) = 0.94.
The original SIR equations are also solved by means of Excel. Their curves are drawn in Figure 1.

Graph of S, I and R for α = 3 and c = 0.04
From the curve of I(t′) we find that t′= 3.00 gives a peak, which is compared with the formula t′= ct = 0.04 × 77 = 3.08. This slightly differs from t′= 3.00. However, such a small difference may be allowed for a margin of error arising from our approximate method. After approximately 77 days later, the first epidemic will end around a middle of July(7/18) with the total number 984 of deaths.
Finally let us calculate the mortality ratio λ = D(t)/R(t). The removed number R(t) is given by R(t) = r(t) + D(t), where r(t) is the accumulated number of people discharged from hospital and D(t) is the accumulated number of deaths. We find its mean value is < λ >= 0.1 with σ = 0.002.
Here we have a comment about the population N. From Eq.(2.7) it follows R(T) = ln α/α = 0.37 for α = 3, whereas NR(T) = 4877 from the data. Hence we get N = 4877/R(T) = 4877/0.37 ≈ 13000. What is such a small population as N = 13000? In order to discuss this question, we divide the Japan population into two groups A and B, A is immune to the present epidemic and B is not immune the epidemic. We can add also people who completely quarantine themselves to A. We then conclude that such a small population as N = 13000 corresponds to B, because A is irrelevant to infection.
4 The second wave
The second wave of COVID-19 in Japan seems to start from around June 22. The virus is now called the Tokyo type.
(ND(t) is the total number of deaths with 3-day average in the second wave at t. The t is the number of date starting from July 20. We make use of data in the appendix, where the number of deaths in the second wave is completely separated from that of the first wave. It is shown that the first death of the second wave appears on July 20.)
The corresponding equation to Eq.(3.7) is, from Table 2,
Date and the number of deaths in the second wave
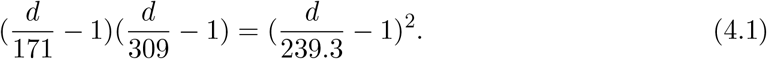 We have a solution d = 482, so that d/2 = 241 is the death number at the peak. Hence the peak day is Aug. 26 and T = 38, as seen from Appendix.
We have a solution d = 482, so that d/2 = 241 is the death number at the peak. Hence the peak day is Aug. 26 and T = 38, as seen from Appendix.
The result of d = 482 is substituted into Eq.(3.4), then it follows
 In the following we take c = 0.028.. Then we get a = 3.6, that is, α = 4.6. Once having the basic reproduction number α = 4.6 with the removed ratio c = 0.028, we can draw curves of S, I and R by means of Excel in Figure 2.
In the following we take c = 0.028.. Then we get a = 3.6, that is, α = 4.6. Once having the basic reproduction number α = 4.6 with the removed ratio c = 0.028, we can draw curves of S, I and R by means of Excel in Figure 2.

Graph of S, I and R for α = 4.6 and c = 0.028
From the curve of I(t′) we find that the peak day is t′= 1.51, which is compared with the formula t = ct = 0.028 × 38 = 1.06. This slightly differs from t′= 1.51. However, such a small difference may be allowed for a margin of error arising from our approximate method. Since the second infection begins from July 20, the t′= 1.51 corresponds with the true time t = 38 days, so that the peak day is Aug. 26, with the total number 241 of deaths. After approximately 38 days later, the epidemic will end around Oct. 3 with the total number 241 × 2 = 482 of deaths. One can see that a ratio of both infectives on peak days is I2/I1 = 3/2, where I1 and I2 stand for infectives of 1st and 2nd waves.
Finally let us calculate the mortality ratio λ = D(t)/R(t). We find that its mean value between July 20 and Aug. 22 is < λ >= 0.005 with σ = 0.0006.
5 Concluding remarks
Our logistic formulas have been applied to analyze deaths by COVID-19 in Japan. Our policy is to use only data of deaths, but not of cases.
For the first wave, the basic reproduction number α is determined to be α = 3 and the removed ratio c = 0.04. The corresponding curves of S, I and R are given in Figure 1. From the curve of I(t′) we find that the infection peak day is May 2nd, then after approximately 77 days later, the first epidemic will end around a middle of July(7/18) with the total number 984 of deaths. The mortality ratio λ = D(t)/R(t) is also calculated to be its mean value < λ >= 0.1 with σ = 0.002.
Here we have a comment about the population N. We find N being calculable from the formula R(T) = ln α/α = 0.37 for α = 3. Namely, from data we see NR(T) = 4877 to give N ≈ 13000. What is such a small population as N = 13000? In order to discuss this question, we divide the Japan population into two groups A and B, A is immune to the present epidemic and B is not immune the epidemic. We can add also people who completely quarantine themselves to A. We then conclude that such a small population as N = 13000 corresponds to B, because A is irrelevant to infection.
For the second wave, the basic reproduction number α is determined to be α = 4.6 and removed ratio c = 0.028. The corresponding curves of S, I and R are given in Figure 2. From the curve of I(t′) we find that the infection peak day is Aug. 26, then after approximately 38 days later, the second epidemic will end around Oct. 3, with the total number 482 of deaths. The mortality ratio λ is also calculated to be its mean value < λ >= 0.005 with σ = 0.0006. A ratio of both infectives of 1st and 2nd waves on peak days can be seen to be 2/3.
Data Availability
I agree with the availability of all data referred.
Acknowledgment
The author would like to express his deep gratitude to K. Shigemoto for many valuable discussions and big supports.
Appendix
Data of accumulated number of deaths in the second wave




{kind=link}
{kind=link}