
Abstract
Serology is critical for understanding pathogen-specific immune responses, but is fraught with difficulty, not least because the strength of antibody (Ab) response varies greatly between individuals and mild infections generally generate lower Ab titers1–3. We used robust IgM, IgG and IgA Ab tests to evaluate anti-SARS-CoV-2 responses in individuals PCR+ for virus RNA (n=105) representing different categories of disease severity, including mild cases. All PCR+ individuals in the study became IgG-positive against pre-fusion trimers of the virus spike (S) glycoprotein, but titers varied greatly. Elevated IgA, IL-6 and neutralizing responses were present in intensive care patients. Additionally, blood donors and pregnant women (n=2,900) sampled throughout the first wave of the pandemic in Stockholm, Sweden, further demonstrated that anti-S IgG titers differed several orders of magnitude between individuals, with an increase of low titer values present in the population at later time points4,5. To improve upon current methods to identify low titers and extend the utility of individual measures6,7, we used our PCR+ individual data to train machine learning algorithms to assign likelihood of past infection. Using these tools that assigned probability to individual responses against S and the receptor binding domain (RBD), we report SARS-CoV-2-specific IgG in 13.7% of healthy donors five months after the peak of spring COVID-19 deaths, when mortality and ICU occupancy in the country due to the virus were at low levels. These data further our understanding of antibody responses to the virus and provide solutions to problems in serology data analysis.
Significance statement Antibody testing provides critical clinical and epidemiological information during an emerging disease pandemic. We developed robust SARS-CoV-2 IgM, IgG and IgA antibody tests and profiled COVID-19 patients and exposed individuals throughout the outbreak in Stockholm, Sweden, where full societal lockdown was not employed. As well as elucidating several disease immunophenotypes, our data highlight the challenge of identifying low IgG titer individuals, who comprise a significant proportion of the population following mild/asymptomatic infection, especially as antibody titers wane following peak responses. To provide a solution to this, we used SARS-CoV-2 PCR+ individual data to develop machine learning approaches that assigned likelihood of past infection to blood donors and pregnant women, improving the accuracy and utility of individual and population-level Ab measures.
Introduction
Characterization of the humoral response to nascent SARS-CoV-2 outbreaks is central to optimizing approaches to the pandemic and further our understanding of human immunology8,9. Here, we followed the first wave of the pandemic in Stockholm, Sweden, characterizing Ab responses in severely ill COVID-19 patients and exposed healthy individuals.
Despite the plethora of Ab testing and phenotyping for SARS-CoV-210–17, consensus on several key issues remains outstanding. For instance, the majority of data are derived from commercial, mass-produced kits utilizing spike derivatives (e.g. S1 or S2 domains) or the nucleocapsid to detect pathogen-specific antibodies10,18,19. Many of these assays suffer from epitope loss/modification20, cross-reactivity10,21 and suboptimal sensitivity22–25. Here, we developed highly sensitive and specific ELISA protocols based on in-house native-like pre-fusion-stabilized spike (S) trimers26 and the smaller ACE-2 receptor-binding domain (RBD), and used them in tandem to evaluate anti-viral Ab responses. As S and the RBD are required for ACE-2-mediated cell entry, we also examined virus neutralisation capacity and isotype levels alongside a descriptive set of clinical features.
Aside from the target antigen, a major consideration for Ab testing concerns setting the assay cut-off for positivity. Commonly, 3 or 6 standard deviations (SD) from the mean of negative controls is used27–29, which is highly dependent on a representative set of negative control sera - significantly affecting seroprevalence estimates and individual clinical management30. It is important to note that humoral responses within the population are not so much positive or negative, but rather represent a wide spectrum2, highlighting the need for more quantitative tools to examine low titer individuals. To obtain accurate seroprevalence estimates in key community groups, we strictly controlled our assay with a large number of historical controls (n=595, repeatedly analyzed alongside test samples) and used tandem anti-S and RBD responses from SARS-CoV-2 PCR+ individuals to train machine learning (ML) algorithms on ELISA measurements.
Developing these approaches, that assigned likelihood of past infection to each data point (values and code openly available), we sampled 100 blood donors and 100 pregnant women per week throughout the outbreak in Stockholm. Both groups are a good proxy for population health. Furthermore, blood donors serve as an important clinical resource (including for COVID-19 plasma therapy), while pregnant women require close clinical monitoring with respect to fetal-maternal health and are known to employ poorly characterized immunological mechanisms impacting infectious pathology31–33. The study was terminated when new cases, mortality and ICU occupancy were at low levels. As Sweden did not impose a strict lockdown in response to the pandemic, these data provide a contrast to comparable settings where social lockdown was not imposed.
Results
Study samples are detailed in Table 1.
Study samples
Antibody test development
We developed ELISA protocols to profile IgM, IgG and IgA specific for a stabilized spike (S) glycoprotein trimer26, the RBD, and the internal viral nucleocapsid (N). The two S antigens were produced in mammalian cells (Fig. S1A) and the trimer conformation was confirmed in each batch by cryo-EM34. A representative subset of study samples (n = 230, Fig S1) was used for assay development (Fig. S1B). No IgG reactivity was recorded amongst the negative control samples during test development, although two individuals who were PCR-positive for endemic coronavirus-positive (ECV+) displayed reproducible IgM reactivity to SARS-CoV-2 N and S, and two 2019 blood donors had low anti-S IgM reactivity (Fig. S1C). Thus, further investigation is required to establish the contribution of cross-reactive memory and germline immunoglobulin alleles to SARS-CoV-2 responses35. We did not observe reproducible IgG reactivity to S or RBD across all 595 historical controls in the study.

(A) Trimeric S and RBD were expressed in 293F cells and purified as described. (B) A random subset of PCR+ individuals, negative controls and BD were used to validate the assays for the three isotypes, these were individuals with confirmed SARS CoV-2 infection (n=36, from a range of disease severity categories); blood donors from the spring of 2020 (n=100); two sets of negative controls, blood donors from the spring of 2019 (n=75) and individuals PCR+ for endemic coronaviruses (ECV+) (n=20). (C) Two ECV+ donors, K2 and K4, showed reproducible IgM binding to S. Testing of another subset of historical controls (n=75) for a similar observation, two additional individuals were found to show IgM binding to S. (D) Serial dilutions of PCR+ participant serum are shown (in a representative sample, n=40) of titrated individuals for anti-S and anti-RBD IgG.
Our assay revealed a greater than 10,000-fold difference in anti-viral IgG titers between Ab-positive individuals when examining serially diluted sera. In SARS-CoV-2 PCR+ individuals, anti-viral IgG titers were comparable for S (EC50=3,064; 95% CI [1,197 - 3,626]) and N (EC50=2,945; 95% CI [543 - 3,936]) and lower for RBD [EC50=1,751; 95% CI 966 - 1,595]. A subset (ca. 10%) of the SARS CoV-2-confirmed individuals in test development did not have detectable IgG responses against N (Fig. S1D), as previously reported10. Therefore, we did not explore responses to N further.
Elevated anti-viral Ab titers are associated with increased disease severity
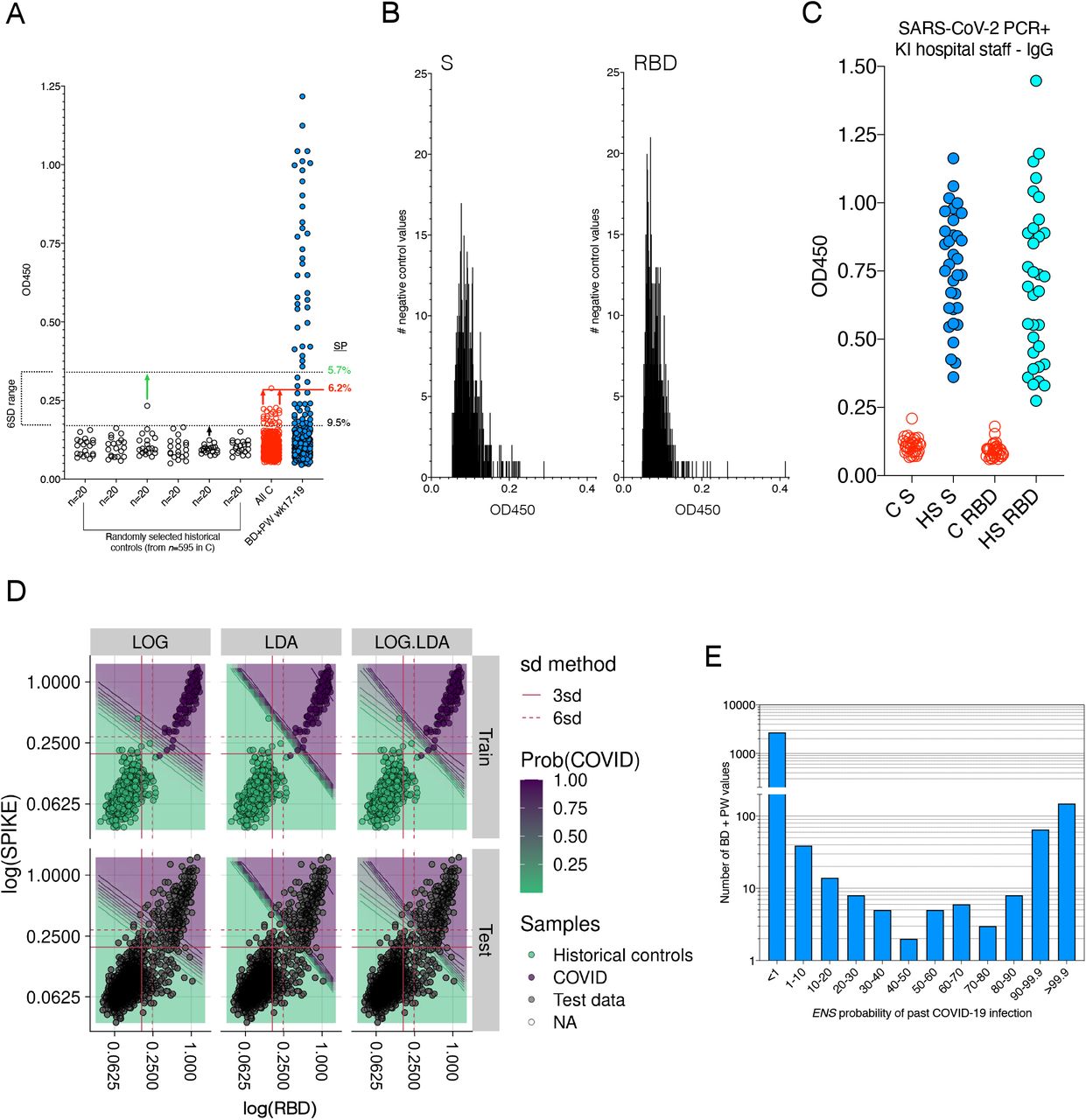
We next screened all SARS-CoV-2 PCR+ individuals collected for the study (n=105) and detected potent IgG responses against S in all participants, and against RBD in 97% of persons (Fig. 1A and S2A). In healthy blood donors and pregnant women, titers varied greatly but were generally lower (Fig. 1A and S2A). In PCR+ patients, IgM and IgA responses against S and RBD were generally weaker and more variable between individuals than the IgG response (Fig. 1B and S2B). Therefore, we sought to investigate whether isotype titers segregated with clinical features.

(A) Log10 OD450 anti-S and -RBD IgG responses in SARS-CoV-2 PCR+ individuals and healthy donors, with a 6 SD cut-off shown calculated from all 595 negative control values. (B) Raw OD450 isotypic responses in PCR+ individuals. A limited number of negative controls are depicted by clear circles. (C) Anti-S vs -RBD responses in PCR+ individuals are highly correlated. (D) Elevated anti-viral Ab and serum IL-6 are associated with disease severity in PCR+ individuals, IgM and IgG.

(A) Raw optical density (OD) anti-S and -RBD IgG responses are shown in SARS-CoV-2 PCR+ individuals (n=105), blood donors (BD, n=1,500) and pregnant women (PW, n=1,400). Controls, C, represent n=595 blood donors from spring 2019. Conventional 6 SD cut-offs shown by dotted lines. (B) IgM, IgG and IgA responses against S and RBD in PCR+ individuals (n=105), with a limited number of controls for each assay represented by open circles. (C) Anti-viral Ab levels are associated with disease severity, most pronounced for IgA. COVID-19 patients in the ICU category were mechanically ventilated. Anti-S and RBD responses are graphed together. (D) Two discordant longitudinal profiles of seroconversion and neutralisation capacity are shown. (E) In vitro pseudotyped virus neutralization ID50 titers are associated with disease severity, with the highest titers observed in Cat 3 (ICU) patients. Forty-eight SARS-CoV-2 PCR+ individuals analyzed in duplicate. (F) Comparison of neutralization ID50 titers between PCR+ individuals (n=48), BD (n=28) and PW (n=28), all analyzed in duplicate. Bars represent the geometric mean and P values are from a two-tailed Mann-Whitney test.
To achieve this, SARS-CoV-2 PCR+ individuals (n=105) were grouped with regards to their disease severity: Category 1 – non-hospitalized (mild and asymptomatic infections); Category 2 – hospitalized; Category 3 – intensive care (on mechanical ventilation) (Table 1). In all PCR+ individuals, anti-S and anti-RBD responses were highly correlated (Fig. S2C) and multivariate analyses revealed that increased anti-viral IgM, IgG and IgA were positively correlated with disease severity (Supp. Table 1), in line with the lower titers observed in blood donors and pregnant women, who did not have signs or symptoms of COVID-19 when they were sampled. Severe disease was most associated with virus-specific IgA, suggestive of mucosal disease36, as well as elevated serum IL-6 (Fig. 1C and S2D), a cytokine that feeds Ab production37–40. IL-6 is dysregulated in several common non-communicable diseases41–43 and during acute respiratory distress syndrome44, risk factors for COVID-19-associated mortality45,46. Interestingly, we observed a lack of association between IL-6 and IgM levels, supporting that levels of the cytokine and IgA mark a protracted, severe clinical course of COVID-19. IgA anti-RBD responses were lower in non-hospitalized and hospitalized females as compared to males, trending similarly for S (Fig. S3A) and in line with females developing less severe disease47.

(A) Antibody responses according to sex for anti-S and –RBD IgA. (B) IgM and IgA titers declined with time from first symptom/SARS-CoV-2+ PCR. IgG levels were maintained during this time. P values from a Spearman rank correlation test. (C) Spearman’s rank correlation of PCR+ dataset features and antibody levels. DOB - date of birth; d-p SymO - days post-symptom onset; d-p PCR – days post SARS-CoV-2+ PCR; PSV ID50 – neutralizing titer (D) Adjusted fold-change for dataset features in PCR+ individuals compared to category 1. The effects of age (DOB), sex, days from PCR test were considered.
In our study, PCR+ individual anti-viral IgG levels were maintained two months post-disease onset/positive PCR test, while IgM and IgA decreased, in agreement with their circulating t1/2 and viral clearance (Fig. S3B). In longitudinal patient samples (sequential serum sampling of 10 PCR+ individuals in the study) where we observed seroconversion, IgM, IgG and IgA peaked with similar kinetics when all three isotypes developed, although IgA was not always generated in Category 1 and 2 individuals (Fig 1D). Overall, disease severity showed the most consistent relationship with any measure and was the primary predictor of Ab levels (Fig. S3C and D).
We next characterized the virus neutralizing Ab response, a key parameter for understanding the potential for protective humoral immune responses and the selection of plasma therapy donors. Benefitting from a robust in vitro pseudotype virus neutralization assay48, we measured serum inhibition of viral cell entry and detected neutralizing antibodies in the serum of all SARS-CoV-2 PCR+ individuals (n=48), and in all except two healthy Ab-positive donors screened (n=56). Neutralizing responses were not seen in samples before seroconversion (Fig. 1D) or negative controls. A large range of neutralizing ID50 titers was apparent, with binding and neutralizing Ab levels being highly correlated (Fig. S3D). The strongest neutralizing responses were observed in samples from patients on mechanical ventilation in intensive care (Category 3, g.mean ID50=5,058; 95% CI [2,422 - 10,564]), in-keeping with their elevated Ab response (Fig 1E). Sera from healthy blood donors and pregnant women also displayed neutralizing responses, but consistent with the binding data were less potent than those observed in individuals with severe disease (ID50=600; 95% CI [357 – 1,010] and ID50=350; 95% CI [228 - 538], respectively, Fig. 1F). Across the two antigens and three isotypes, anti-RBD IgG levels were most strongly correlated with neutralization.
Probabilistic seroprevalence estimates in blood donors and pregnant women
As Stockholm is a busy urban area and Sweden did not impose strict lockdown in response to SARS-CoV-2 emergence, we sought to better understand the frequency and nature of anti-viral responses in healthy blood donors and pregnant women sampled throughout the first outbreak (March 30 - August 23rd 2020) (Fig. 2A). However, critical to accurate individual measures and seroprevalence estimates is the decision about whether a sample is defined as positive or not. For example, current clinically approved tests use a ratio between a “representative” positive and negative serum calibrator to determine positivity, although we show here that these are highly variable.

Study sample collection intervals are shown alongside the 14-day COVID-19 death rate per million inhabitants in Sweden and relevant countries for comparison. (B) Log-transformed un-normalized OD measurements from all BD and PW in the study. Conventional 3 (dotted red line) and 6 SD (solid red line) cut-offs are shown; calculated from n=595 historical controls; 100 random negative controls (C, with 95% CI of the median) are shown for each assay. (C) The percentage anti-S and -RBD IgG positive per sampling week in BD and PW show according to 3 or 6 SD cut-offs. (D) S and RBD responses from PCR+ individuals were used to train different machine learning algorithms to assign likelihood of past infection. We created an ensemble learner (ENS) from the output of logistic regression and linear discriminant analysis, providing a highly sensitive, specific and consistent multi-dimensional solution to the problem of weak reactors, and assigning each data point a probability of being positive. Conventional 3 and 6 SD cut-offs are shown for each antigen, with probabilities assigned to selected points. (E) Heatmap of assigned ENS probabilities for the top 35 BD and PW values per week, with each square representing an individual. (F) Seroprevalence (SP) estimates in Stockholm modelled over time in BD and PW using a cut-off-independent Bayesian framework.
To improve our understanding of the assay boundary, we repeatedly analyzed a large number of historical (SARS-CoV-2-negative) controls (blood donors from the spring of 2019, n=595) alongside test samples throughout the study. We considered the spread of negative values critical, since the use of a small and unrepresentative set of controls can lead to an incorrectly set threshold and errors in the seroprevalence measurement. This is illustrated by the random sub-sampling of non-overlapping groups of negative controls, resulting in a 40% difference in the seroprevalence estimate (Fig. S4A). Seroprevalence in the healthy cohorts according to conventional 3 and 6 SD cut-offs are shown in Fig. 2C.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(A) Random sub-sampling of non-overlapping negative controls illustrates how the range of negative control values can influence the conventional test cut-off. Depending on the control values used to set the test threshold for positivity, seroprevalence (SP) estimates vary by 40%. 600 BD and PW values are used as an example. Anti-S IgG values are shown. (B) The distribution of negative control serum values for anti-S and –RBD IgG. (C) As ML methods improve with additional data, we analyzed a small cohort (n=33) of PCR+ Karolinska University hospital staff (HS) for S and RBD IgG responses. n=32 historical controls, C, were analyzed alongside. (D) Comparison of logistic regression, linear discriminant analysis and the ENS learner, showing the training data set and BD and PW test samples. ENS was trained using 595 negative control values and 138 PCR+ individuals. (E) ENS identified several study BD and PW to have uncertain measurements when S and RBD responses were considered, facilitating individual re-testing.
The fact that many healthy donor test samples had optical densities between the 3 and 6 SD cut-offs for both or a single antigen (Fig. 2B and C), highlights the problem of assigning case to low responder values. Therefore, to exploit individual titers and improve our statistical estimates, we used the data from PCR+ individuals (Fig. 1) and our negative controls (Fig. S4B) to train machine learning (ML) algorithms to assign likelihood of past infection. A small cohort of seropositive individuals among Karolinska University Hospital staff (n=33) provided additional low titer training values four months post SARS-CoV-2+ PCR (Fig. S4C).
After comparing different methods for this purpose (Materials & Methods), we found that logistic regression (LOG) achieved the highest sensitivity, while linear discriminant analysis (LDA) showed the best specificity. LOG and LDA both model log odds of a sample being case as a linear equation with a resulting linear decision boundary, but differ in how the coefficients for the linear models are estimated from the data. When applied to the Ab response data, the output of LOG and LDA is the probability of each new sample being case. Therefore, we generated an equal-weighted ensemble learner (ENS) from the output of LOG and LDA that maximized sensitivity, specificity and consistency across different cross-validation strategies (Fig. 2D and S4D). While weekly rates varied (S Table 2), the ENS learner identified 13.7% seroprevalence in healthy blood donors and pregnant women at the last sampling week (Supp. Table 2). Importantly, ENS identified 155 (5.3%) blood donor and pregnant women measures to be associated with some degree of uncertainty, encouraging follow-up investigation in given cases (Fig. 2E and S4E).
Finally, to model population changes in seroprevalence over time, we developed and validated a cut-off-independent Bayesian ML framework able to share information between sampling weeks49 (Fig. 2F and Materials & Methods). Using this model on the combined BD and PW data, we found an almost linear increase in seroprevalence since the start of the pandemic (Fig. 2E), consistent with continued virus spread in the Stockholm population during the study period. The results mirrored the results obtained using ENS, yielding a seroprevalence of 13.2% (95% Bayesian CI [10.1-16.8]) at the end of the study period (Supp. Table 3). We propose that these tools and related approaches be used to facilitate future antibody measures and better characterize Ab test uncertainty at individual and population levels.
Discussion
Serology remains the gold standard for estimating previous exposure to pathogens and benefits from a large historical literature. Although the concept of herd immunity is based upon the study of antibodies, worryingly, there is no standardization for the many SARS-CoV-2 Ab tests currently available. Globally, hospital staff and health authorities are struggling with test choices, negatively impacting individual outcomes and efforts to contain the pandemic.
Benefitting from a robust antibody test developed alongside a diagnostic clinical laboratory responsible for monitoring sero-reactivity during the pandemic, we profiled SARS-CoV-2 Ab responses in three cohorts of clinical interest. COVID-19 patients receiving intensive care showed the highest anti-viral Ab titers, developing augmented serum IgA and IL-6 with worsening disease. Isotype-level measures may assist COVID-19 clinical management and determine, for example, whether all critically ill patients develop class-switched mucosal responses to SARS-CoV-2, potentially informing lung therapeutic delivery50,51. Our neutralization data showed that nearly all SARS-CoV-2 PCR+ individuals and healthy donors who seroconvert, develop neutralizing Ab capable of preventing S-mediated cell entry in vitro.
Outside of the severe disease setting, it is critical to accurately determine who and how many people have seroconverted. This is complicated by low titer values, which in some cases - and increasingly with time since exposure - overlap outlier values among negative control samples. Test samples with true low anti-viral titers will, therefore, fall into this range of weak responders as the B lymphocyte response contracts following viral clearance, highlighting the need to better understand the assay boundary in multiple dimensions. As future tests begin to survey individual Ab responses to a multitude of antigens in parallel, the ML approaches presented here will enable the identification of disease sub-types and facilitate longitudinal measures.
We applied these tools to blood donors and pregnant women, two good sentinels for population health, although they are not enriched for groups with high risk for SARS-CoV-2 infection, such as healthcare workers and public transportation employees, where seroprevalence may be higher. Blood donors are generally working age, active and mobile members of society with a good understanding of health, and pregnant women in Sweden will have been advised to take precautions against infectious diseases through their practitioners. Interestingly, in our study, both groups showed a similar seroprevalence during the time period analyzed. Tracking these cohorts over time, we modelled seroprevalence changes at the population level. We found the steep climb in Ab positivity at the start of the pandemic (as the virus emerged) to increase at a slower rate during subsequent weeks, reaching nearly 14% by five months from the peak of spring 2020 COVID-19 deaths in the country. These data indicate that serological herd immunity to the initial outbreak was not achieved in these cohorts. We terminated the study in line with the decreasing caseload and number of fatalities in Sweden52, despite on-going virus spread in the Stockholm population.
Given the uniqueness of the public health response to the pandemic in the country53, these data may inform the management of this and future pandemics elsewhere. Our data also highlight high inter-individual variability in anti-viral Ab responses and offer solutions for how to handle this at individual and population levels.
Materials and methods
Human samples and ethical declaration
Samples from PCR+ individuals and admitted COVID-19 patients (n=105) were collected by the attending clinicians and processed through the Departments of Medicine and Clinical Microbiology at the Karolinska University Hospital. Samples were used in accordance with approval by the Swedish Ethical Review Authority (registration no. 2020-02811). All personal identifiers were pseudo-anonymized, and all clinical feature data were blinded to the researchers carrying out experiments until data generation was complete. PCR testing for SARS-CoV-2 RNA was by nasopharyngeal swab or upper respiratory tract sampling at Karolinska University Hospital. As viral RNA levels were determined using different qPCR platforms (with the same reported sensitivity and specificity) between participants, we did not analyze these alongside other features. PCR+ individuals (n=105) were questioned about the date of symptom onset at their initial consultation and followed-up for serology during their care, up to 2 months post-diagnosis. Serum from SARS-CoV-2 PCR+ individuals was collected 6-61 days post-test, with the median time from symptom onset to PCR being 5 days. In addition, longitudinal samples from 10 of these patients were collected to monitor seroconversion and isotype persistence.
Hospital workers at Karolinska University Hospital were invited to test for the presence of SARS-CoV-2 RNA in throat swabs in April 2020 and virus-specific IgG in serum in July 2020. We screened 33 PCR+ individuals to provide additional training data for ML approaches. All participants provided written informed consent. The study was approved by the National Ethical Review Agency of Sweden (2020-01620) and the work was performed accordingly.
Anonymized samples from blood donors (n=100/week) and pregnant women (n=100/week) were randomly selected from their respective pools by the department of Clinical Microbiology, Karolinska University Hospital. No metadata, such as age or sex information were available for these samples in this study. Pregnant women were sampled as part of routine for infectious diseases screening during the first trimester of pregnancy. Blood donors (n=595) collected through the same channels a year previously were randomly selected for use as negative controls. Serum samples from individuals testing PCR+ for endemic coronaviruses, 229E, HKU1, NL63, OC43 (n=20, ECV+) in the prior 2-6 months, were used as additional negative controls. The use of study samples was approved by the Swedish Ethical Review Authority (registration no. 2020-01807). Stockholm County death and Swedish mortality data was sourced from the ECDC and the Swedish Public Health Agency, respectively. Study samples are defined in Table 1.
Serum sample processing
Blood samples were collected by the attending clinical team and serum isolated by the department of Clinical Microbiology. Samples were anonymized, barcoded and stored at - 20°C until use. Serum samples were not heat-inactivated for ELISA protocols but were heat-inactivated at 56°C for 60 min for neutralization experiments.
SARS-CoV-2 antigen generation
The plasmid for expression of the SARS-CoV-2 prefusion-stabilized spike ectodomain with a C-terminal T4 fibritin trimerization motif was obtained from26. The plasmid was used to transiently transfect FreeStyle 293F cells using FreeStyle MAX reagent (Thermo Fisher Scientific). The ectodomain was purified from filtered supernatant on Streptactin XT resin (IBA Lifesciences), followed by size-exclusion chromatography on a Superdex 200 in 5 mM Tris pH 8, 200 mM NaCl.
The RBD domain (RVQ – QFG) of SARS-CoV-2 was cloned upstream of a Sortase A recognition site (LPETG) and a 6xHIS tag, and expressed in 293F cells as described above. RBD-HIS was purified from filtered supernatant on His-Pur Ni-NTA resin (Thermo Fisher Scientific), followed by size-exclusion chromatography on a Superdex 200. The nucleocapsid was purchased from Sino Biological.
Anti-SARS-CoV-2 ELISA
96-well ELISA plates (Nunc MaxiSorp) were coated with SARS-CoV-2 S trimers, RBD or nucleocapsid (100 μl of 1 ng/μl) in PBS overnight at 4°C. Plates were washed six times with PBS-Tween-20 (0.05%) and blocked using PBS-5% no-fat milk. Human serum samples were thawed at room temperature, diluted (1:100 unless otherwise indicated), and incubated in blocking buffer for 1h (with vortexing) before plating. Serum samples were incubated overnight at 4°Cbefore washing, as before. Secondary HRP-conjugated anti-human antibodies were diluted in blocking buffer and incubated with samples for 1 hour at room temperature. Plates were washed a final time before development with TMB Stabilized Chromogen (Invitrogen). The reaction was stopped using 1M sulphuric acid and optical density (OD) values were measured at 450 nm using an Asys Expert 96 ELISA reader (Biochrom Ltd.). Secondary antibodies (all from Southern Biotech) and dilutions used: goat anti-human IgG (2014-05) at 1:10,000; goat anti-human IgM (2020-05) at 1:1000; goat anti-human IgA (2050-05) at 1:6,000. All assays of the same antigen and isotype were developed for their fixed time and samples were randomized and run together on the same day when comparing binding between PCR+ individuals. Negative control samples were run alongside test samples in all assays and raw data were log transformed for statistical analyses.
In vitro virus neutralisation assay
Pseudotyped viruses were generated by the co-transfection of HEK293T cells with plasmids encoding the SARS-CoV-2 spike protein harboring an 18 amino acid truncation of the cytoplasmic tail26; a plasmid encoding firefly luciferase; a lentiviral packaging plasmid (Addgene 8455) using Lipofectamine 3000 (Invitrogen). Media was changed 12-16 hours post-transfection and pseudotyped viruses harvested at 48- and 72-hours, filtered through a 0.45 µm filter and stored at −80°Cuntil use. Pseudotyped neutralisation assays were adapted from protocols validated to characterize the neutralization of HIV, but with the use of HEK293T-ACE2 cells. Briefly, pseudotyped viruses sufficient to generate ∼100,000 RLUs were incubated with serial dilutions of heat-inactivated serum for 60 min at 37°C. Approximately 15,000 HEK293T-ACE2 cells were then added to each well and the plates incubated at 37°Cfor 48 hours. Luminescence was measured using Bright-Glo (Promega) according to the manufacturer’s instructions on a GM-2000 luminometer (Promega) with an integration time of 0.3s. The limit of detection was at a 1:45 serum dilution.
IL-6 cytometric bead array
Serum IL-6 levels were measured in a subset of PCR+ serum samples (n=64) using an enhanced sensitivity cytometric bead array against human IL-6 from BD Biosciences (Cat # 561512). Protocols were carried out according to the manufacturer’s recommendations and data acquired using a BD Celesta flow cytometer.
Statistical analysis of SARS-CoV-2 PCR+ data
All univariate comparisons were performed using non-parametric analyses (Kruskal-Wallis, stratified Mann-Whitney, hypergeometric exact tests and Spearman rank correlation), as indicated, while multivariate comparisons were performed using linear regression of log transformed measures and Wald tests. For multivariate tests, all biochemical measures (IL-6, PSV ID50 neut., IgG, IgA, IgM) were log transformed to improve the symmetry of the distribution. As “days since first symptom” and “days since PCR+ test” are highly correlated, we cannot include both in any single analysis. Instead, we show results for one, then the other (Supp. Table 1).
Probabilistic seroprevalence estimations
Prior to analysis, each sample OD was standardized by dividing by the mean OD of “no sample controls” on that plate or other plates run on the same day. This resulted in more similar distributions for 2019 blood donor samples with 2020 blood donors and pregnant volunteers, as well as smaller coefficients of variation amongst PCR+ COVID patients for both SPIKE and RBD.
We employed two distinct probabilistic strategies for estimating seroprevalence without thresholds, each developed independently. Our machine learning approach consisted of evaluating different algorithms suited to ELISA data, which we compared through ten-fold cross validation (CV): logistic regression (LOG), linear discriminant analysis (LDA), and support vector machines (SVM) with a linear kernel. Logistic regression and linear discriminant analysis both model log odds of a sample being case as a linear equation with a resulting linear decision boundary. The difference between the two methods is in how the coefficients for the linear models are estimated from the data. When applied to new data, the output of logistic regression and LDA is the probability of each new sample being a case. Support vector machines is an altogether different approach. We opted for a linear kernel, once again resulting in a linear boundary. SVM constructs a boundary that maximally separates the classes (i.e. the margin between the closest member of any class and the boundary is as wide as possible), hence points lying far away from their respective class boundaries do not play an important role in shaping it. SVM thus puts more weight on points closest to the class boundary, which in our case is far from being clear. Linear SVM has one tuning parameter C, a cost, with larger values resulting in narrower margins. We tuned C on a vector of values (0.001, 0.01, 0.5, 1, 2, 5, 10) via an internal 5-fold CV with 5 repeats (with the winning parameter used for the final model for the main CV iteration). We also note that the natural output of SVM are class labels rather than class probabilities, so the latter are obtained via the method of Platt54.
We considered three strategies for cross-validation: i) random: individuals were sampled into folds at random, ii) stratified: individuals were sampled into folds at random, subject to ensuring the balance of cases:controls remained fixed and iii) unbalanced: individuals were sampled into folds such that each fold was deliberately skewed to under or over-represent cases compared to the total sample. We sought a method that worked equally well across all cross-validation schemes, as the true proportion of cases in the test data is unknown and so a good method should not be overly sensitive to the proportion of cases in the training data. We found most methods worked well and chose to create an ensemble (ENS) method combining the method with the highest sensitivity (LOG) with the highest specificity (LDA), defined as an unweighted average of the probabilities generated under both.
We trained the ensemble learner on all 733 training samples and predicted the probability of anti-SARS-CoV-2 antibodies in blood donors and pregnant volunteers sampled in 2020. The ENS learner had average sensitivity > 99.1% and average specificity >99.8%. We inferred the proportion of the sampled population with positive antibody status each week using multiple imputation. We repeatedly (1,000 times) imputed antibody status for each individual randomly according to the ensemble prediction, and then analyzed each of the 1,000 datasets in parallel, combining inference using Rubin’s rules, derived for the Wilson binomial proportion confidence interval55.
Our Bayesian approach is explained in detail in Christian et al49. Briefly, we used a logistic regression over anti-RBD and -S training data to model the relationship between the ELISA measurements and the probability that a sample is antibody-positive. We adjusted for the training data class proportions and used these adjusted probabilities to inform the seroprevalence estimates for each time point. Given that the population seroprevalence cannot increase dramatically from one week to the next, we constructed a prior over seroprevalence trajectories using a transformed Gaussian Process, and combined this with the individual class-balance adjusted infection probabilities for each donor to infer the posterior distribution over seroprevalence trajectories.
Data Availability
Data generated as part of the study, along with custom code for statistical analyses, is openly available via our GitHub repositories: https://github.com/MurrellGroup/DiscriminativeSeroprevalence/ and https://github.com/chr1swallace/seroprevalence-paper.
Data and code availability statement
Data generated as part of the study, along with custom code for statistical analyses, is openly available via our GitHub repositories: https://github.com/MurrellGroup/DiscriminativeSeroprevalence/ and https://github.com/chr1swallace/seroprevalence-paper.
Author contributions
GKH and XCD designed the study, analyzed the results and wrote the manuscript with input from co-authors. JA, TA, JD, SM, GB, MA and SA provided the study serum samples and clinical information. LH, LPV, AMM, DJS, KCI, BM and GM generated SARS-CoV-2 antigens and pseudotyped viruses. XCD and MF developed the ELISA protocols and XCD generated the data. DJS and BM developed and performed the neutralization assay. MCh and BM developed the Bayesian framework. CW and NFG assisted with patient data statistical analyses and executed machine learning approaches. MA, SK, PP, MM, JC, MCo and JR carried out wet lab experiments and assisted with data analysis.
Conflict of interest
The study authors declare no competing interests related to the work.
Acknowledgments
We would like to thank the study participants and attending clinical teams. Secondly, we extend our thanks to Björn Reinius, Marc Panas, Julian Stark, Remy M. Muts and Darío Solis Sayago for their input and discussion. Funding for this work was provided by a Distinguished Professor grant from the Swedish Research Council (agreement 2017-00968) and NIH (agreement 400 SUM1A44462-02). CW and NFG are funded by the Wellcome Trust (WT107881) and MRC (MC_UP_1302/5).
References



