
Abstract
The human sex ratio at birth (SRB), defined as the ratio between the number of newborn boys to the total number of newborns, is typically slightly greater than 1/2 (more boys than girls) and tends to vary across different geographical regions and time periods. In this large-scale study, we sought to validate previously-reported associations and test new hypotheses using statistical analysis of two very large datasets incorporating electronic medical records (EMRs). One of the datasets represents over half (∼150 million) of the US population for over 8 years (IBM Watson Health MarketScan insurance claims) while another covers the entire Swedish population (∼9 million) for over 30 years (the Swedish National Patient Register). After testing more than 100 hypotheses, we showed that neither dataset supported models in which the SRB changed seasonally or in response to variations in ambient temperature. However, increased levels of a diverse array of air and water pollutants, were associated with lower SRBs, including increased levels of industrial and agricultural activity, which served as proxies for water pollution. Moreover, some exogenous factors generally considered to be environmental toxins turned out to induce higher SRBs. Finally, we identified new factors with signals for either higher or lower SRBs. In all cases, the effect sizes were modest but highly statistically significant owing to the large sizes of the two datasets. We suggest that while it was unlikely that the associations have arisen from sex-specific selection mechanisms, they are still useful for the purpose of public health surveillance if they can be corroborated by empirical evidences.
Author Summary The human sex ratio at birth (SRB), usually slightly greater than 1/2, have been reported to vary in response to a wide array of exogenous factors. In the literature, many such factors have been posited to be associated with higher or lower SRBs, but the studies conducted so far have focused on no more than a few factors at a time and used far smaller datasets, thus prone to generating spurious correlations. We performed a series of statistical tests on 2 large, country-wide health datasets representing the United States and Sweden to investigate associations between putative exogenous factors and the SRB, and were able to validate a set of previously-reported associations while also discovering new signals. We propose to interpret these results simply as public health indicators awaiting further empirical confirmation rather than as implicated in (adaptive) sexual selection mechanisms.
Introduction
Because human male gametes bearing X or Y chromosomes are equally frequent (being produced by meiosis symmetrically partitioning two sex chromosomes), and because ova bear only X chromosomes, one would expect a sex ratio at conception of exactly  [1]. Indeed, a recent study using fluorescent in situ hybridization and array comparative genomic hybridization showed that the sex ratio at conception (SRC) was statistically indistinguishable from
[1]. Indeed, a recent study using fluorescent in situ hybridization and array comparative genomic hybridization showed that the sex ratio at conception (SRC) was statistically indistinguishable from  [2]. Nevertheless, the apparent sex ratio at birth (SRB), also known as the secondary sex ratio, has been documented to significantly deviate from
[2]. Nevertheless, the apparent sex ratio at birth (SRB), also known as the secondary sex ratio, has been documented to significantly deviate from  under various circumstances, suggesting that a proportion of embryos are lost between conception and birth.
under various circumstances, suggesting that a proportion of embryos are lost between conception and birth.
At least three processes may affect the observed SRB. First, female-embryo pregnancies may terminate early in development, driving the SRB up. It has been documented that these excess female-embryo losses tend to occur primarily during the first and early-second trimesters of pregnancy. Second, male-embryo deaths would drive the apparent SRB down. Male-embryo losses have indeed been observed to occur during the late-second and third trimesters [3]. Third, the SRB may be affected by maternal peri-conceptual hormonal levels [4, 5]. Past studies proposed that the SRB can fluctuate with time and may be driven by a number of environmental factors, such as chemical pollution, events exerting psychological stress on pregnant women (such as terrorist attacks and earthquakes), radiation, changes in weather, and even seasons of conception (Table 1).
While there are multiple studies which have observed the positive associations between air pollution and spontaneous abortion [15, 16], most of those conclusions based on analyses of relatively small samples (Table 1), severely curtailing their statistical power. In this study, we harnessed the power of 2 very large datasets: the MarketScan insurance claim data [17] in the United States (which records the health events of more than 150 million unique Americans, with more than 3 million unique newborns recorded between 2003 to 2011), and Sweden’s birth registry data (covering the birth and health trajectories of over ∼3 million newborns from 1983 to 2013) [18]. Our present study is the first systematic investigation of numerous chemical pollutants and other environmental factors using large datasets from two continents.
Methods
Data
The IBM Health MarketScan data [17] represents 104, 565, 671 unique individuals and 3, 134, 062 unique live births. The Swedish Health Registries [18] record health statistics for over ten million individuals, and 3, 260, 304 unique live births. We juxtaposed time-stamped birth events in the two countries with exogenous factor measurements retrieved from the US National Oceanic and Atmospheric Administration, the US Environmental Protection Agency, the Swedish Meteorological and Hydrological Institute, and an organization called Statistics Sweden. We used a subset of the MarketScan data that contained information on livebirths between 2003 to 2011 with county information encoded in Federal Information Processing Standards (FIPS) codes and a family link profile indicating the composition of the households in the dataset. The date, geographic distribution, and the mothers of the newborns can be directly extracted from these datasets. For environmental factors, we used the Environmental Quality Index (EQI) data compiled by the United States Environmental Protection Agency (EPA) [19, 20].
Cluster Analysis
In order to simplify subsequent analyses, we first performed hierarchical clustering analysis on the Spearman’s rank correlation coefficients matrix (ρ), using the Ward’s method, which reduced the the EQI dataset’s dimensionality. We then used the R-language [21] package pvclust [22] to minimize the total within-cluster variance [23]. The resulting dendrogram and list of factors can be found in the SI. Each cluster contains at least two factors and is represented by the mean of all the elements in the cluster.
Regression Analysis
We used multilevel Bayesian logistic regression with random effects implemented in the R-language package rstan [24]. To facilitate model building, we used the R-language package brms [25] with default priors. Sampling was performed with the No-U-Turn sampler (NUTS) [26] with 500 warm-up steps and 1500 iteration steps with 28 Markov chains, of which the convergence was asseessed using the  statistic [27]. The model for the jth factor (predictor) is given as follows:
statistic [27]. The model for the jth factor (predictor) is given as follows:
 where pj is the probability that a newborn is male, xj is the vector representing the jth factor, βj their coefficients, and α[k]j the intercept for the kth group-level, representing states or counties in the US, and kommuner (municipalities) or län (counties) in Sweden, whenever applicable. The group-level effect was modeled for a single random effect by
where pj is the probability that a newborn is male, xj is the vector representing the jth factor, βj their coefficients, and α[k]j the intercept for the kth group-level, representing states or counties in the US, and kommuner (municipalities) or län (counties) in Sweden, whenever applicable. The group-level effect was modeled for a single random effect by

 and for two random effects, representing e.g. state- and county-specific effects, by
and for two random effects, representing e.g. state- and county-specific effects, by


 where ηj and νj are independent of each other and for all j [28]. Moreover, we partitioned the independent variables into septiles, so that βj ∈ ℝ6, with one regression coefficient for each of the six septiles other than the first, which was treated as baseline [29].
where ηj and νj are independent of each other and for all j [28]. Moreover, we partitioned the independent variables into septiles, so that βj ∈ ℝ6, with one regression coefficient for each of the six septiles other than the first, which was treated as baseline [29].
We applied logistic regression in two ways. First, to assess the effect of environmental factors, we regressed each of the individual factors’ septiles against the SRB, with each sample point representing a county. Therefore, each septile, aside from the baseline, has a coefficient. Second, to test whether maternal diagnostic history (DX) affected the SRB, we regressed a DX’s indicator variables against the SRB, with each sample point representing a newborn/mother pair. For model selection in both cases, we performed repeated (10 times) 10-fold cross-validation and calculated the information criterion relative to the null model (where xj = 0, meaning, the model was comprised solely of the intercept). We computed the average difference in information criterion (ΔIC) and standard error (SE) for each factor obtained from leave-one-out (LOO) cross-validation [30], and used the Benjamini–Yekutieli method to adjust for multiple comparisons [31].
Univariate Time-Series Analysis
To assess the effect of one-off, stressful events on the SRB, we used two different time series techniques. First, we fitted seasonal univariate, autoregressive, integrated, moving average (sARIMA) models using the Box-Jenkins method [32], in conjunction with monthly (28-day periods) and weekly live birth data up to the event and then performed an out-of-sample prediction. An sARIMA model is given by
 where AR indicates the auto-regression term, I the integration term, and MA the moving average term (an “s” before any of the above stands for “seasonal”). Moreover, yt indicates the observed univariate time series of interest, L is the lag operator such that L(yt) = yt−1, ε’s white noises, S ⩾2 the degree of seasonality (i.e., the number of seasonal terms per year, chosen to be 4 in our study), and ϕ’s, θ’s, Φ’s, and Θ’s are model parameters to be estimated. We used the auto.arima function from the R-language package forecast [33, 34] to fit the data, which performed a step-wise search on the (p, d, q, P, D, Q) hyperparameter space and compared different models by using the Bayesian Information Criterion (BIC) [35]. We confirmed the optimalx models’ goodness-of-fit using the Breusch-Godfrey test on the residuals, which tested for the presence of autocorrelation, up to degree S [36–38].
where AR indicates the auto-regression term, I the integration term, and MA the moving average term (an “s” before any of the above stands for “seasonal”). Moreover, yt indicates the observed univariate time series of interest, L is the lag operator such that L(yt) = yt−1, ε’s white noises, S ⩾2 the degree of seasonality (i.e., the number of seasonal terms per year, chosen to be 4 in our study), and ϕ’s, θ’s, Φ’s, and Θ’s are model parameters to be estimated. We used the auto.arima function from the R-language package forecast [33, 34] to fit the data, which performed a step-wise search on the (p, d, q, P, D, Q) hyperparameter space and compared different models by using the Bayesian Information Criterion (BIC) [35]. We confirmed the optimalx models’ goodness-of-fit using the Breusch-Godfrey test on the residuals, which tested for the presence of autocorrelation, up to degree S [36–38].
On the other hand, we fitted the same data as above to Bayesian structural time series (BSTS) models, which are state-space models given in the general form by [39]:

 where yt is the observed time series and αt the unobserved latent state. In particular, we used the local linear trend model with additional seasonal terms [39, 40]:
where yt is the observed time series and αt the unobserved latent state. In particular, we used the local linear trend model with additional seasonal terms [39, 40]:



 Here, we define ηt = [ut vt wt]; Qt is a t-invariant block diagonal matrix with diagonal elements
Here, we define ηt = [ut vt wt]; Qt is a t-invariant block diagonal matrix with diagonal elements  and
and  . Finally, we denote αt = [µt δt τt−S+2 … τt], which implies that both Zt and Tt are t-invariant matrices of 0’s and 1’s such that Equations 10–13 hold. We used the R package CausalImpact [41], which in turn relied on the R package bsts [42] as backend, to fit the data.
. Finally, we denote αt = [µt δt τt−S+2 … τt], which implies that both Zt and Tt are t-invariant matrices of 0’s and 1’s such that Equations 10–13 hold. We used the R package CausalImpact [41], which in turn relied on the R package bsts [42] as backend, to fit the data.
Correlation and Causality
To test whether the SRB was effected by ambient temperature, we grouped daily SRB data and temperatures into 91-day (13-week) periods and calculated the Pearson correlation coefficient (r) between each SRB and ambient temperature. We then performed the Student’s t-test for the null hypothesis that the true correlation is 0. Furthermore, we fitted the SRB/temperature pair to a vector autoregression (VAR) model for a maximum lag order of 4 (52 weeks), using the BIC as the metric for model selection, and then tested for the null hypothesis of the non-existence of Granger causality using the F-test [43].
Results
We start by describing the negative results (i.e., a lack of a significant association), concordant across the two datasets. Our model selection rejected the whole spectrum of models that allow for periodic, annual SRB changes [7, 8]. For both US and Swedish datasets, the best-fitting model described the SRB as lacking seasonality throughout the year. Similarly, when we tested the claim that ambient temperatures during conception affect the SRB [9–12], we found that neither dataset supported this association. Both the Student’s t-test and the F-test concluded that the SRB was independent of ambient temperature measurements (Table S7).
A comparison of each dataset’s environmental measurements revealed that Sweden enjoyed both lower variations and lower mean values of measured concentrations of substances in the air. Unfortunately, the Swedish dataset also provided fewer measured pollutants, which made our cross-country analysis more difficult. Fig 1A shows a comparison of pollutant concentration distributions in both countries. The US environmental measurements dataset presented its own difficulty, as many pollutants appeared highly collinear in their spatial variation. To address this, we performed a cluster analysis on the environmental factors, subdividing them into 26 clusters (Table 2 and Fig S2). All pollutants within the same cluster were highly correlated, while the correlation between distinct clusters was much smaller, allowing for useful association inferences between SRB changes and environmental states.
Pollutant clusters discovered by applying the Ward’s method to the EQI raw measurements dataset.

Airborne health-related substances and their association with the SRB. A: Comparison of airborne pollutant concentrations across the US (cyan violin plots) and Sweden (pink violin plots). Only 4 air components, fine particulate matter (PM2.5), coarse particulate matter (PM10), sulfur dioxide (SO2), and nitrogen dioxide (NO2) are measured in both countries. US counties appear to have higher mean pollution levels and are more variable in terms of pollution. B-M: A sample of 12 one-environmental factor logistic regression models that are most explanatory with respect to SRB. For each environmental factor, we partition counties into 7 equal-sized groups (septiles), ordered by levels of measurements, so that the first septile corresponds to the lowest and the highestnth septile to the highest concentration. Each plot shows bar plots of regression coefficients and 95% confidence intervals (error bar) of the second to the seventh septiles, with the first septile chosen as the reference level. We rank the 12 models by the statistically significant factor’s association strength with at least one statistically significant coefficient by decreasing ΔIC; septiles whose coefficients are not significantly different from 0 at the 95% confidence level have been plotted with a reduced alpha level. Blue bars represent positive coefficients, whereas red bars represent negative coefficients. “Negative food-related businesses” is a term used by the Environmental Protection Agency’s Environmental Quality Index team and is explained as “businesses like fast-food restaurants, convenience stores, and pretzel trucks.” “Percent vacant units” stands for “percent of vacant housing units.” Substances contributing to clusters 10 and 25 are listed in Table 2. See Table S11 for more details regarding the factors’ and clusters’ identities.
Using the US dataset, we were able to validate the findings of a number of previous studies regarding the association between the SRB and exogenous factors (Table 3). Specifically, our data suggests that PCBs (polychlorinated biphenyls), aluminium (Al) in air, chromium (Cr) in water and total mercury (Mg) quantity drive the SRB up, while lead (Pb) in soil appears to be associated with a decreased SRB. Meanwhile, we have found no evidence for a number of previous reports, indicated with a dash in the second column in Table 3. We also established several new environmental associations that have not been reported before (Table 4, Fig 1 B–M, and Fig 2). Fig 1 B–M show that increased pollutant levels appear to be associated with both increased and decreased SRB values (Plates E,F,H,I, and J, and the remaining Plates, respectively).
Test results for factors selected from the literature reports (Table 1). We included a factor only if both its ΔIC and the coefficient of at least one of its septiles was statistically significant.
Test results for additional factors with statistically significant effects. We included a factor only if both its ΔIC and the coefficient of at least one of its septiles was statistically significant.

County-level geographical septile distribution for the first 12 statistically significant factors with at least one statistically significant coefficient ranked by decreasing ΔIC. The factors labelled A–M are the same as shown in Fig 1, Plates B–M and are ordered identically in both figures.
The geographic distribution of these pollutants varies remarkably, as seen in Fig 2. For example, lead in land (Fig 2B) appears to be enriched in the northeast, southwest, and mid-east US, but not in the south. Hydrazine (Fig 2F) appears to follow capricious, blotch-like shapes in the eastern US, each blotch likely centered at a factory emitting this pollutant. Total mercury deposition in water (Fig 2E) mostly affects eastern US states with the heaviest load in the northeastern states. It is this variability in the environmental distribution of various substances that allowed us to tease out these individual associations.
Finally, when we tested links between two stressful events in the US (Hurricane Katrina and the Virginia Tech shooting) and the SRB using seasonal autoregressive integrated moving-average (sARIMA) models and state-space models (SSMs) (see the Univariate time-series analysis section in Methods), we were able to identify significant associations only in the case of the Virginia Tech shooting – the SRB was lower than expected 34 weeks after the event (see Figs 3C and 4C, cf. Tables S5c and S6c).
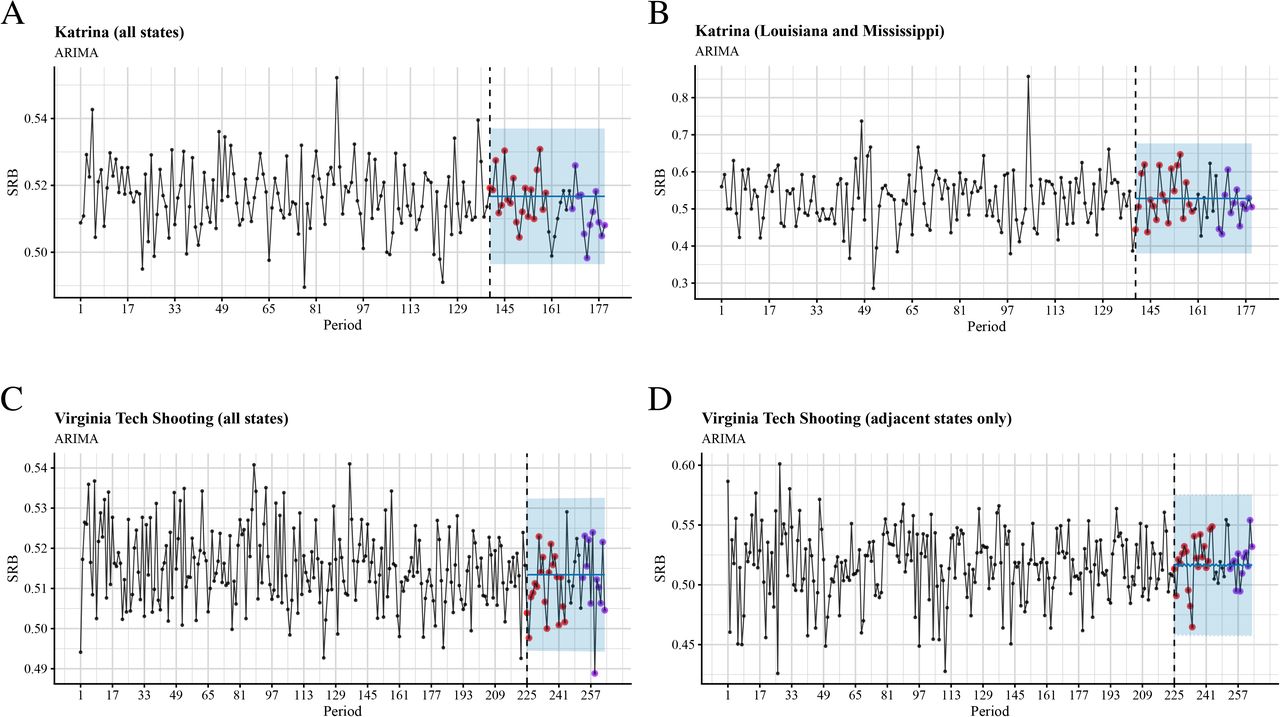
Time series plots and out-of-sample forecasts for SRB data grouped into 7-day periods and fitted with seasonal ARIMA models. The blue shade is the 95% confidence level. The observed SRBs for the first five months after the intervention are presented by red dots, whereas the observed SRBs for 7 to 9 months after the intervention are presented by purple dots. A: Hurricane Katrina, all states; B: Hurricane Katrina, Louisiana and Mississippi only; C: Virginia Tech shooting, all states; D: Virginia Tech shooting, adjacent states only.

Time series plots and out-of-sample forecasts for SRB data grouped into 7-day periods and fitted with state space models. The blue shade is the 95% confidence level. The observed SRBs for the first five months after the intervention are presented by red dots, whereas the observed SRBs for 7 to 9 months after the intervention are presented by purple dots. A: Hurricane Katrina, all states; B: Hurricane Katrina, Louisiana and Mississippi only; C: Virginia Tech shooting, all states; D: Virginia Tech shooting, adjacent states only.
Discussion
While SRB fluctuations in space and time are well-documented and non-controversial, there is a diverse range of competing theories striving to explain SRB changes in terms of mechanistic selective pressure [44]. The most frequently mentioned theory, is called the Trivers–Willard hypothesis (TWH), named after the researchers who proposed it [45]). The TWH postulates that, because the cost of rearing children is much higher for females than for males, in favourable, resource-rich environments, maleswould have more offspring than females, and vice versa in unfavourable conditions. Natural selection would then favour individuals with higher fitness, where fitness is equated to individuals’ reproductive success (in this case, the number of offspring reaching reproductive age). According to the TWH, natural selection pushes the SRB up (more males) in favourable conditions, and down (more females) in unfavourable environment.
More explicitly stated, the TWH depends on the following three assumptions [5,45,46]:
Assumption A1. The condition of a mother during parental investment is correlated with the condition of her offspring; in other words, mothers in better conditions have offspring that will be in better conditions.
Assumption A2. The condition of the offspring persists after parental investment ends, and is positively correlated with the offspring’s reproductive success.
Assumption A3. Males have larger variability in reproductive success than females and, as a result, they are more susceptible to sexual selection.
From these assumptions the TWH makes the following deductive inference on SRB variability:
Conclusion C1. The SRB varies such that females in favourable conditions have more male offspring, and in unfavourable conditions, more female offspring.
Assumption A3 is called Bateman’s principle [47] (BP), and was suggested in a classic fruit fly genetics study on sexual selection. The original experimental results with Drosophila melanogaster indicated that males benefited more from multiple mating than females in terms of fitness. This asymmetry was thought to have originated in anisogamy, which means that a sperm is much smaller than an ovum and therefore requires less resources. Unfortunately, this result was never replicated (see [48, 49] for critiques of Bateman’s methodology). Nevertheless, a modified version of BP, which generalizes anisogamy to parental investment, has enjoyed prominence among evolutionary biologists [50]. One of the critiques of BP claims that male cost of reproduction is in reality much higher than suggested by Bateman. This is because Bateman failed to account for the fact that males do not produce sperms stoichiometrically to match the number of female-produced ova. Instead, they produce semen, a mixture of a very large number of male gametes and accompanying secretions, rich in nutrients and other substances beneficial to reproduction [51]. Therefore, once the full range of investment patterns across life history (e.g. intrasex competition, secondary sexual characteristics, territorial defence) has been taken into account, it is unclear if reproductive investments of females exceed those of males [52, 53].
Faced with such criticisms, as well as an increasing amount of evidence from across the animal kingdom in which species did not conform to BP [54], supporters for BP have responded that sex differences ultimately originated from historical anisogamy [55, 56], and that there have also been subsequent ecological factors independent of anisogamy that drove sexual dimorphism, having to do with resource competition between the sexes, which may not result in stronger selection on males [57, 58]. Moreover, as a counter-challenge to the former point, Bateman’s critics also refer to aggregate results in favour of BP, including a phylogenic meta-analysis by Janicke et al., in which significant differences in reproductive success variances in species across the animal kingdom were found [59]. This reworking allowed for a potential remedy for BP, namely by generalizing it as follows [54, 60, 61]:
Assumption A3*. The sex with the larger reproductive success variance is more susceptible to sexual selection.
From this, the generalized version of the TWH follows:
Conclusion C1*. The SRB should vary such that females in favourable conditions have more offspring of that sex more susceptible to sexual selection, and in unfavourable conditions, more offspring of that sex less susceptible to sexual selection.
This version of BP is consistent with “sex-role reversals” observed in many species, in which females exhibit larger susceptibility to sexual selection. In addition, it allows for sufficient flexibility such that the identity of “the sex more susceptible to sexual selection” may be influenced by exogenous conditions [57]. Candidates for the identity of that sex include higher variance in number of (adult) offspring and higher variance in parental investments [5, 62]. Nevertheless, under this revised framework, for sexually dimorphic selection patterns to develop and persist, as opposed to randomly fluctuating across time [63], one inevitably has to invoke the sexual cascade hypothesis; namely that a small initial difference (e.g. anisogamy) in sex-related phenotype will “snowball” into larger, persistent patterns through hereditary feedback loops [64–66]. Such cascading has also featured in the above-mentioned meta-analysis discussion regarding high-level explanatory patterns among animal species [59], bracketing all differences in sex-related traits into one-dimensional sexual selection [54]. There is a plethora of other competing theories, e.g. [63] and [61], which predict largely stochastic variations of sex-related phenotypes, emphasizing the role social and ecological factors have played in shaping plastic sex-roles [54, 67, 68]. Even if the last point may still be somewhat contentious [65], BP and (by extension) the TWH are, at the very least, not the only game in town when it comes to explaining and predicting patterns related to sexual selection: male and female phenotypes of a given species in a given environment are most likely the results of a large number of exogenous factors without any single one of them being particularly dominant [69, p. 177].
One key ramification of the above analysis is that the TWH cannot provide a comprehensive account of the range of exogenous factors associated with SRB variation under the kind of circumstances present in our study. Further, the empirical success of the TWH is mixed, with only 50% of studies confirming it, and around 20% of studies producing statistically significant results in the opposite direction [46], which is consistent with our finding that many different pollutants might be assumed to be “bad” for mothers (e.g. pollutants, traffic fatality rates, junk food) had associations with SRB in opposite directions. The scepticism against the applicability of the TWH in contemporary human societies is further strengthened by two recent population studies in Sweden with large sample sizes (4.7 and 5.7 million live births, respectively), which found no SRB heritability [70, 71]. In particular, Zietsch et al. have demonstrated that there exists neither within-individual SRB auto-correlation (contra Assumption A1) nor similarity in the SRB for children of siblings (contra Assumption A2). They also concluded that within-family SRB was associated with the final family size, suggesting that SRB variations may have been the result of SRB-aware family planning [70]. Taken together, such evidence also places other adaptive (i.e. via heritable sexual selection) theories explaining SRB variations, such as adaptive versions of hormonal hypothesis [62], maternal dominance hypothesis [72,73] and the Bruce effect [74] in the same predicament. Thus, our results are better interpreted as supporting the intrinsic randomness of the SRB and/or the dependence of the SRB on non-adapative (e.g. socio-cultural [70, 75, Ch. 12]), causal factors, possibly including those common to both changes in the SRB and associated exogenous factors.
By way of conclusion, we note that the literature includes substantial reports on the relationship between the SRB and public health [3], and we would like to consider the question of whether the SRB can be used as an indicator for public health events and, if so, whether the relationship between the SRB and certain diseases reveals causal relationships. As the preceding discussion demonstrates, even if the existence of adaptive causal relationships between environmental factors and the SRB may be unlikely (contra [76]), associations – including the ones presented in this work – may be used as signals for (adverse) public health conditions, as long as they are established experimentally. To this end, we reiterate that there are agreements between the associations established in our work and those in the literature [6, 14], and that our results do support the non-monotonous, dose-response profiles frequently reported in the literature [77] (Table 3). Therefore, future research programmes might instead focus on exploring and validating the associations between SRB and environmental factors that reliably predict adverse public health effects for certain subpopulations [71] using large datasets with covariates sampled frequently across considerable spatio-temporal ranges [70]. Another interesting direction would be to determine the potentially non-adaptive physiological mechanisms.
Limitations
Unlike some of the recent studies [78], we did not have access to the sex of stillbirths, which would have enabled us to probe negative selection in utero against frail males [3]. When quantifying pollutants in the US, we used the EPA air quality raw data, which was an average of measurements taken over a short period of time, rather than over years or decades, which would have enabled long-term and causal analyses. Neither did it include information for individual exposures to those factors, which might render a straightforward interpretation of our results subject to ecological fallacies. Finally, the subjects in our US study were commercially-insured and had medical claims, which likely came from a different probability distribution to the general population in the US.
Supporting Information
S1 Appendix Additional results, figures and tables
Acknowledgments
We are grateful to E. Gannon and M. Rzhetsky for comments on earlier versions of this manuscript.
Footnotes
↵* andrey.rzhetsky{at}uchicago.edu
Submission to PLOS Computational Biology. Abstract and Discussion were substantially rewritten to connect our results to sexual selection theories, such as the Trivers--Willard hypothesis (TWH) and other adaptive theories.
References
- 1.↵
- 2.↵
- 3.↵
- 4.↵
- 5.↵
- 6.↵
- 7.↵
- 8.↵
- 9.↵
- 10.
- 11.
- 12.↵
- 13.
- 14.↵
- 15.↵
- 16.↵
- 17.↵
- 18.↵
- 19.↵
- 20.↵
- 21.↵
- 22.↵
- 23.↵
- 24.↵
- 25.↵
- 26.↵
- 27.↵Vehtari A, Gelman A, Simpson D, Carpenter B, Bürkner PC. Rank-normalization, folding, and localization: An improved
 for assessing convergence of MCMC. Bayesian analysis. 2021;1(1):1–28.
for assessing convergence of MCMC. Bayesian analysis. 2021;1(1):1–28. - 28.↵
- 29.↵
- 30.↵
- 31.↵
- 32.↵
- 33.↵
- 34.↵
- 35.↵
- 36.↵
- 37.
- 38.↵
- 39.↵
- 40.↵
- 41.↵
- 42.↵
- 43.↵
- 44.↵
- 45.↵
- 46.↵
- 47.↵
- 48.↵
- 49.↵
- 50.↵
- 51.↵
- 52.↵
- 53.↵
- 54.↵
- 55.↵
- 56.↵
- 57.↵
- 58.↵
- 59.↵
- 60.↵
- 61.↵
- 62.↵
- 63.↵
- 64.↵
- 65.↵
- 66.↵
- 67.↵
- 68.↵
- 69.↵
- 70.↵
- 71.↵
- 72.↵
- 73.↵
- 74.↵
- 75.↵
- 76.↵
- 77.↵
- 78.↵





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
2
Blogs/Media
Author Videos