
Abstract
Joint modelling for mixed longitudinal responses has played a prominent part in disease decision-making. It is based on a joint strategy of estimating joint likelihood with shared random effects. Non-ignorable missingness in outcomes increases complexity in joint model; a shared parameter model is proposed to incorporate non-ignorable missing data for joint modelling of longitudinal responses and missing data mechanism. Parameters are estimated under the Bayesian paradigm and implemented via Markov chain Monte Carlo (MCMC) methods with Gibbs sampler. To demonstrate the effectiveness of the proposed method, the joint model is applied to analyze a prostate cancer dataset. The objective is to assess whether there is an association between two mixed longitudinal biomarkers, which could have important implications for understanding disease progression and guiding treatment decisions. The dataset contains non-monotone missingness pattern. To evaluate the performance and robustness of the proposed joint model, simulation studies are conducted.
1. Introduction
Longitudinal studies have a wide range of applications in medicine, where measurements are repeatedly observed for individuals over time. These measurements are correlated even for different types of responses and collected for the same individuals. For example, in oncology research, more than one biomarker of mixed types is measured repeatedly over time for the same patient. These biomarkers are inherently associated – and this association is accounted for valid conclusions. Simultaneous modelling of mixed biomarkers is an optimal approach to account for correlation among multiple biomarkers [1].
Missing data is an unavoidable issue in longitudinal studies because patients may not come for a pre-specified follow-up visit at a particular time point for many reasons. In this regard, missingness exists in collected data and creates hindrances to extracting inference without making assumptions about the missingness mechanism. According to Rubin [2], missing completely at random (MCAR) and missing at random (MAR) mechanisms being not dependent upon unobserved measurements are ignorable. Not missing at random (NMAR) mechanism may depend upon both observed and unobserved responses and is considered non-ignorable. Non-ignorable missingness mechanism is considered in data analysis with longitudinal measurements to get unbiased estimates.
In literature, selection models, pattern-mixture models (PMMs), and shared parameter models (SPMs) are mostly applied to tackle non-ignorable missing data. These models use different factorizations for missingness and measured processes to jointly model longitudinal responses incorporating missingness. The SPM approach is widely applied to model MAR data in longitudinal responses. Still, there exists a gap to employ SPM for NMAR. Non-ignorable missing data is addressed by employing logistic or probit models, which are specifically designed to handle situations where the missing data mechanism is influenced by unobserved variables or responses, resulting in NMAR mechanisms. By integrating the logistic or probit model into the analysis, researchers can effectively mitigate potential biases caused by non-ignorable missing data that consequently makes precise inferences based on the available data. Logistic and probit models provide valuable insights into the underlying patterns of missingness, contributing to obtaining reliable results in longitudinal studies and other scenarios where missing data is common.
Joint modelling terms are applied to simultaneously analyzed more than one outcome. Many methods have been proposed to jointly analyze single or multivariate longitudinal measurements alongside event time data in recent years [3,4]. Another joint modelling term is used to simultaneously analyze more than one longitudinal outcome possibly of different types using random effects, marginal or conditional models [5,6]. Catalano and Ryan [7] analyzed toxicity data proposing bivariate latent variable models to account for the relationship between fetal weight and malformation in live fetuses. Leon and Carriere [8] studied one longitudinal and one binary response to assess maternal smoking’s effect on the respiratory illness of children. Liu et al. [9] formulated a joint model to handle longitudinal binary and continuous responses by incorporating an ignorable missing data mechanism. Li et al. [10] applied joint modelling for continuous, binary, and ordinal responses under the Bayesian framework, while Kürüm et al. [11] proposed a joint model to analyze binary and continuous responses under frequentist statistics.
Under the umbrella of non-ignorable missing data (NMAR) fall both non-monotone and monotone missingness patterns, which in turn provide incomplete observations. Intermittent missingness comes under non-monotone missingness pattern, where an individual misses any visit during the follow-up time, and returns to show up for subsequent visits. The monotone missingness pattern usually refers to informative drop-out, where an individual leaves the study before completion and never comes back to complete follow-up time. Stubbendick and Ibrahim [12] used a likelihood-based approach to incorporate non-monotone NMAR by proposing a joint likelihood of outcome and missing data indicators. Hogan et al. [13] worked on monotone missingness in longitudinal data. Gaskins et al. [14] worked on non-ignorable drop-out mixed longitudinal responses using PMM under joint modelling methodology.
In this article, a joint model is proposed for longitudinal continuous-binary biomarkers using a conditional modelling approach, and two shared parameter models are proposed for non-ignorable missingness under the conditional model. For estimating the model’s parameters different approaches are employed: likelihood-based approach, linear programming technique, and Bayesian approach. We work under the Bayesian framework to obtain parameter estimates.
The article presents a robust statistical approach to analyze longitudinal mixed-effects biomarker measurements, accounting for non-monotone, non-ignorable missingness in the context of prostate cancer research. By utilizing joint modelling techniques and considering the missingness mechanisms, the researchers aim to obtain more reliable and meaningful results from their data analysis.
2. Motivation: Prostate cancer dataset
This research is motivated by a comprehensive dataset obtained from prostate cancer patients who underwent external beam radiotherapy (EBRT), Androgen deprivation therapy (ADT), and a combination of ADT along with other therapies. This dataset spans from 2012 to 2019 and includes information collected during up to 5 follow-up visits after treatment. The data was sourced from Mayo hospital, a renowned referral hospital in Pakistan. Data was received in 2021 by the authors of this study. The authors had no access to information that could identify individual participants.
The evaluation of patients took place from the pre-treatment phase to the post-treatment follow-up. During the pre-treatment phase, demographic characteristics and medical history of the patients were recorded. We specifically focused on patients’ age, body mass index (BMI), and Gleason score as baseline predictors for our study. Blood tests were also conducted to measure prostate-specific antigen (PSA), alkaline phosphatase (ALT), platelets, and bilirubin. These biomarkers were tracked after treatment at each follow-up visit, with PSA and ALP values considered as indicators of prostate cancer progression after treatment, and endogenous platelets and bilirubin as time-dependent covariates. Our study included a total of 1,504 patients diagnosed with prostate cancer, out of which 1,026 received ADT and combination therapies as part of their treatment.
3. Model specification
3.1 Model for longitudinal measurements
Data analysis is described by the joint model specification; sub-models illustrate such mixed types of complex data modelling. The first sub-model assumes to follow linear mixed-effects model specified for continuous longitudinal biomarker. Binary longitudinal response is assumed to follow mixed-effects logistic regression model.
Let Yij be the continuous longitudinal outcome for ith individual i = 1,2,3,….,n at time tij j = 1,2,3,….,my, assume linear mixed effects model as
 where, α1 is a py dimensional vector of fixed effects regression coefficients,
where, α1 is a py dimensional vector of fixed effects regression coefficients, 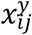 vector of covariates.
vector of covariates.  is qy dimensional vector of random effects, u1i is a vector of random effects, that is independently and identically distributed as multivariate normal with mean vector 0 and covariance matrix D.
is qy dimensional vector of random effects, u1i is a vector of random effects, that is independently and identically distributed as multivariate normal with mean vector 0 and covariance matrix D.  is the random error term.
is the random error term.
Let, Zij be the binary repeated measurements observe for ith individual, i = 1,2,3,….,n at time sij. Where sij = tij, j = 1,2,3,….,mz, binary response Zij assumes to follow logistic mixed effects model that is given by
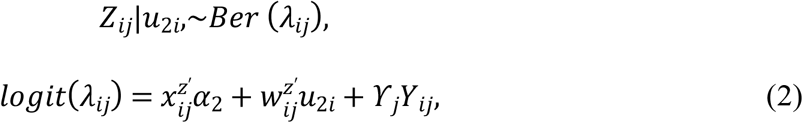 where, α2 is a pz dimensional vector of fixed effects regression coefficients,
where, α2 is a pz dimensional vector of fixed effects regression coefficients, 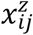 vector of covariates.
vector of covariates. 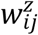 is qy dimensional vector of random effects, u2i∼MVN(0, D) is a vector of random effects, with the addition of associated parameter ϒj to measure the effect of response Yij at time tij on response Zij at the same time sij.
is qy dimensional vector of random effects, u2i∼MVN(0, D) is a vector of random effects, with the addition of associated parameter ϒj to measure the effect of response Yij at time tij on response Zij at the same time sij.
3.2 Missing data mechanism and shared parameter model
Longitudinal data are not fully observed which leads to incomplete measurements. The most important consideration is to specify an appropriate missing data mechanism based on assumptions related to unobserved and observed data. Little and Schluchter [15] as well as Fitzmaurice and Laird [16] applied general location model described by Olkin and Tate [17] assuming the ignorability assumption. This assumption leads to the usage of observed responses only without considering a model for missingness mechanism. Usually, the expectation-maximization (EM) algorithm is employed for parameter estimation.
In this study, we examine two distinct missingness mechanisms to account for the presence of two different missingness patterns in longitudinal outcomes, two SPM are specified for missingness mechanisms.
Let Ri = (Ri1, Ri2,Ri3,….,Rin)′ be the vector of response indicators, if Yij observed Rij = 1, and Rij = 0 for missing Yij. In this paper, a SPM based on non-ignorable missigness mechanisms for Yi and Zi consider, assuming logistic mixed effects regression models for 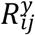 and
and  responses.
responses.
Let 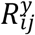 be the missingness indicator for continuous response at time tij, such that
be the missingness indicator for continuous response at time tij, such that  if Yij is not fully observed, the model for
if Yij is not fully observed, the model for 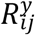 is given by
is given by
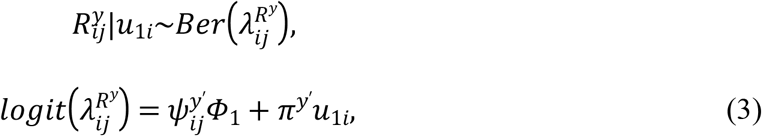
Let 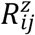 be the missingness indicator for continuous response at time sij, such that
be the missingness indicator for continuous response at time sij, such that  if Zij is not fully observed, the model for
if Zij is not fully observed, the model for 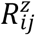 is given by
is given by
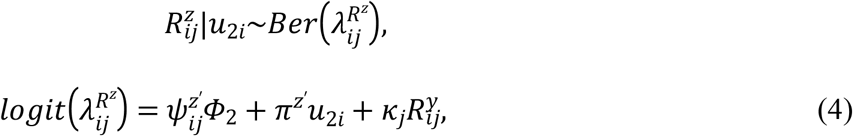
To formulate joint distribution of responses given the random effects, let Yij and Zij are partitioned into 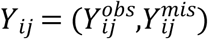 and
and 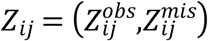 , respectively.
, respectively.
Joint model given the random effects is given as

Joint probability distribution function is formulated further as
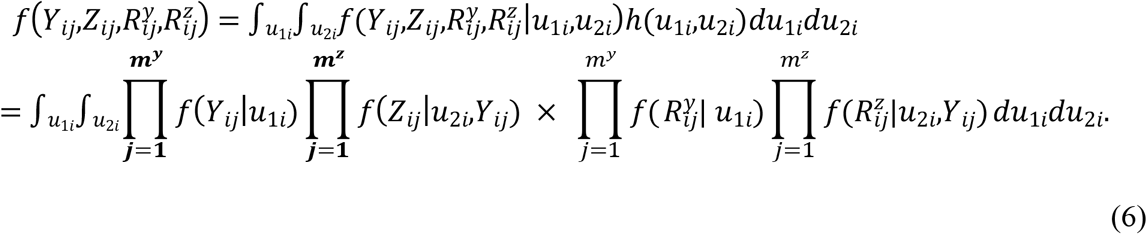
3.3 Prior distributions and hierarchical model
The unknown parameters of the proposed model are estimated by employing the Bayesian framework using Markov chain Monte Carlo (MCMC) techniques [18]. MCMC has an advantage over conventional methods, with MCMC conditional distribution of each parameter given others is easily specifying. Priors are chosen to carry out Bayesian inference for unknown parameters, let Ø = {α1,α2,σ2,D1,D2,Φ1,Φ2,πy,πz,ϒl,κk} be the unknown parameters’ vector where k = 1,2,3,…., my and l = 1,2,3,….,mz. We specify proper prior for each set of unknown parameters: Gaussian distribution for the fixed effects, and Inverse Gamma distribution for random effects. Different levels of variances for each distribution are tried out to make robust choice of fixed effects estimates. Independent prior distributions for unknown parameters are chosen by assigning hyperparameters that lead to low-informative prior distributions.
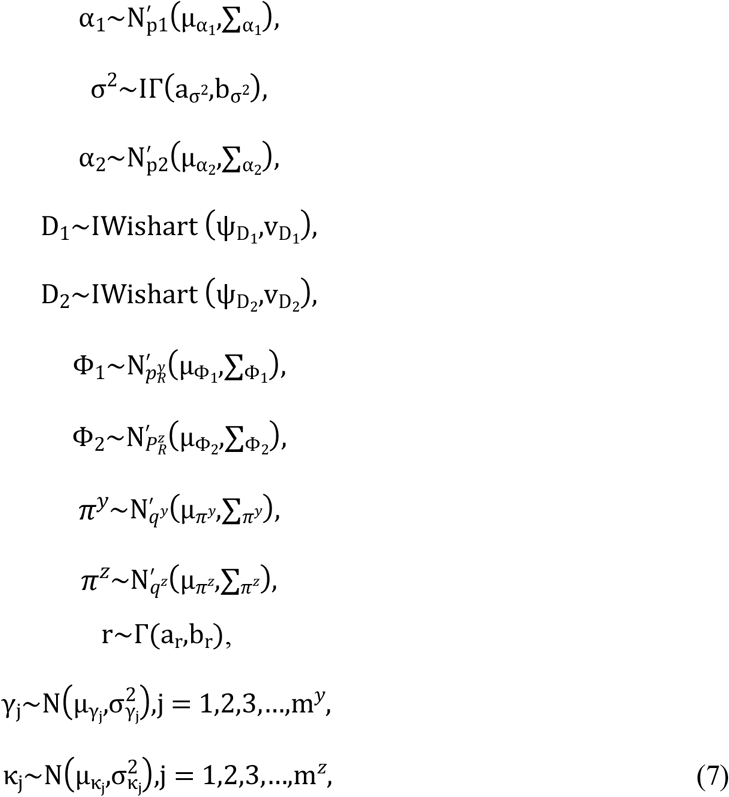 where IΓ(a,b) and Γ(a,b) denote inverse gamma distribution and gamma distribution with shape parameter a and scale parameter b. IWishart (ψ, v) represents the inverse Wishart distribution with scale and matrix parameters v and ψ, respectively. N(μ, ∑) denotes a normal distribution with mean vector μ and covariance matrix ∑.
where IΓ(a,b) and Γ(a,b) denote inverse gamma distribution and gamma distribution with shape parameter a and scale parameter b. IWishart (ψ, v) represents the inverse Wishart distribution with scale and matrix parameters v and ψ, respectively. N(μ, ∑) denotes a normal distribution with mean vector μ and covariance matrix ∑.
The joint posterior density is formulated as
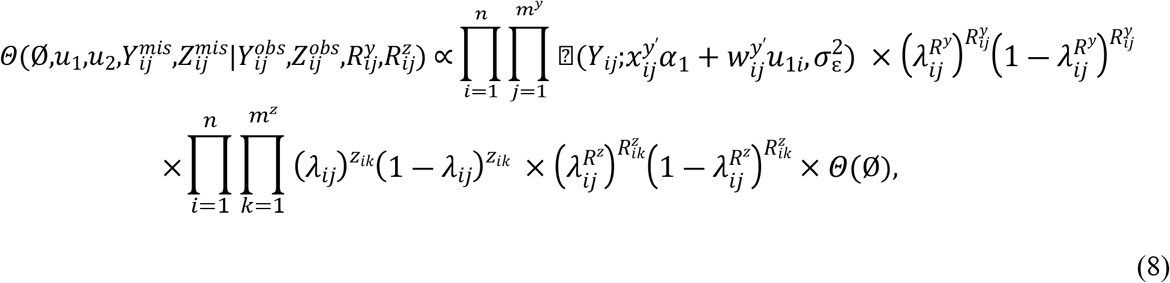 where, Θ(Ø) is the joint prior distribution of unknown parameters.
where, Θ(Ø) is the joint prior distribution of unknown parameters.
Samples are drawn iteratively from conditional posterior distributions derived from (8) using Gibbs sampler, the full conditional distributions for parameters are given by
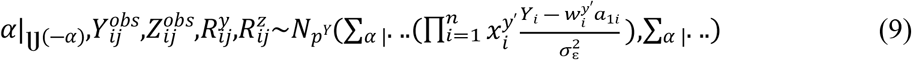
Where 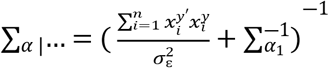
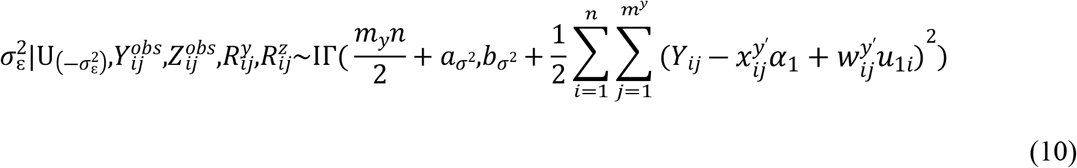
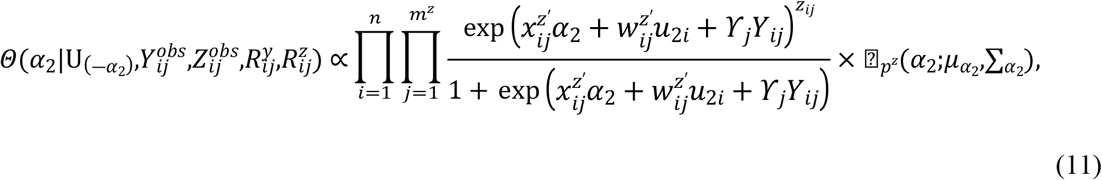
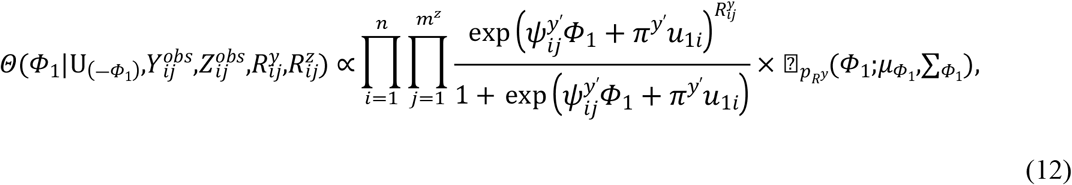


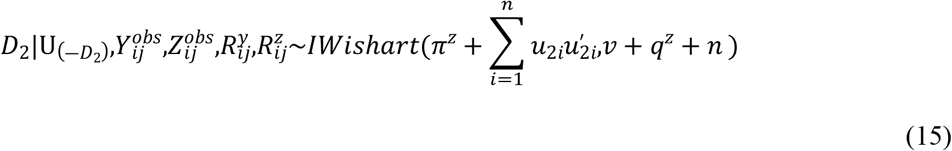
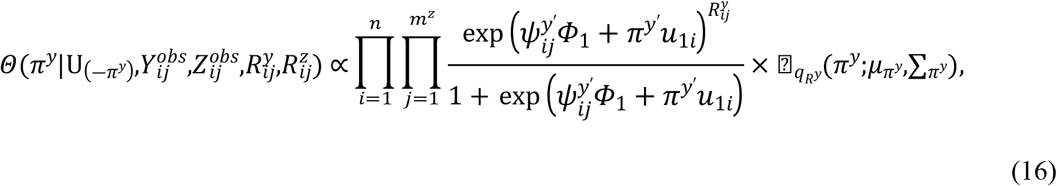
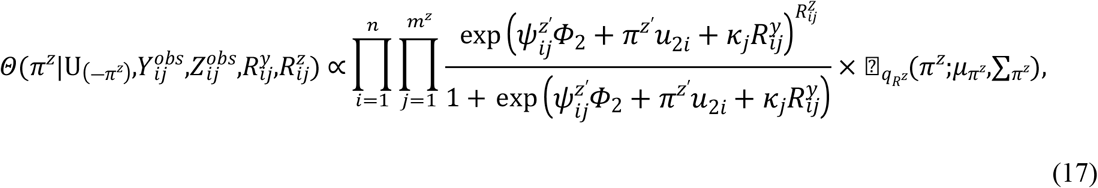
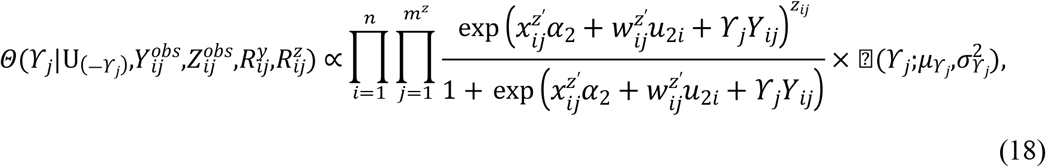
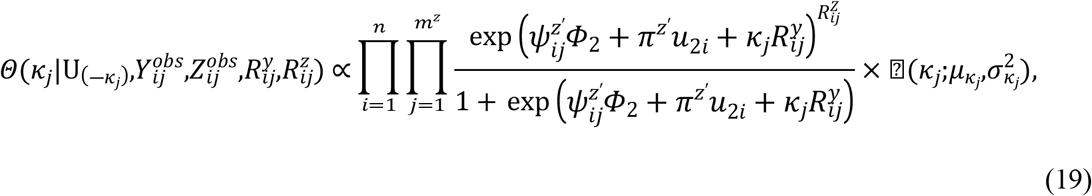
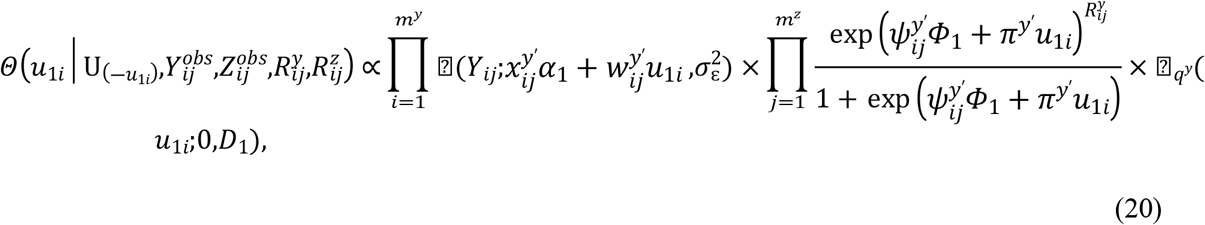
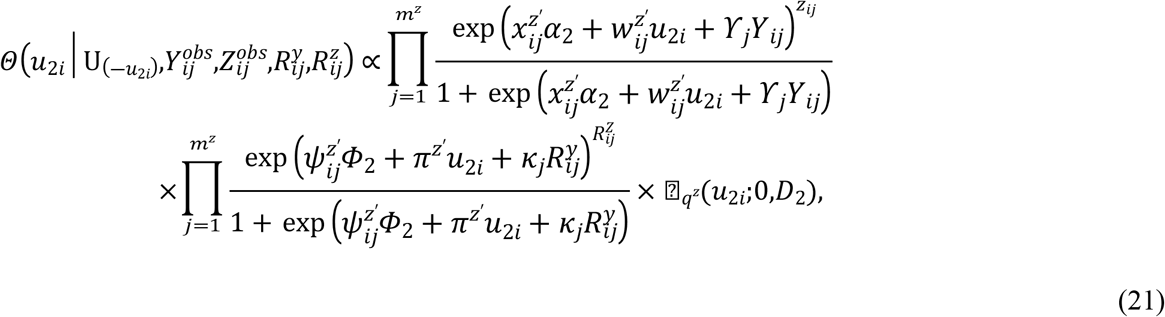
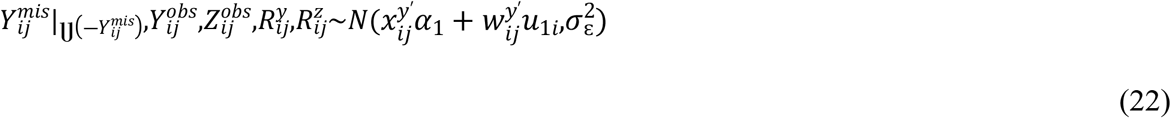

4. Simulation studies
Some simulation studies are conducted to assess the performance of the proposed model. The first simulation is designed with assuming no association between two responses, and between measurements and missingness processes. The second simulation assumes different associations between biomarkers, also between biomarkers and missingness processes. Each simulation has 100 random samples and each sample includes 500, 1,000, and 3,000 subjects.
For each individual, the two longitudinal measurements are generated from the following joint model,
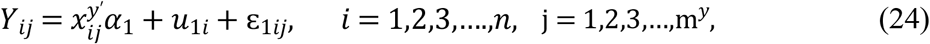
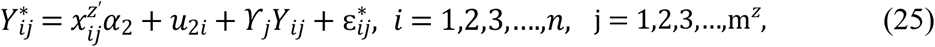 where
where 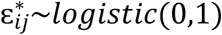 , Zij = 1 for
, Zij = 1 for  and Zij = 0 for
and Zij = 0 for 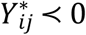
For missingness processes, following models are assumed to generate data,
 where,
where, 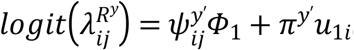
 where,
where, 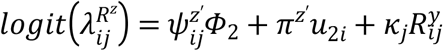
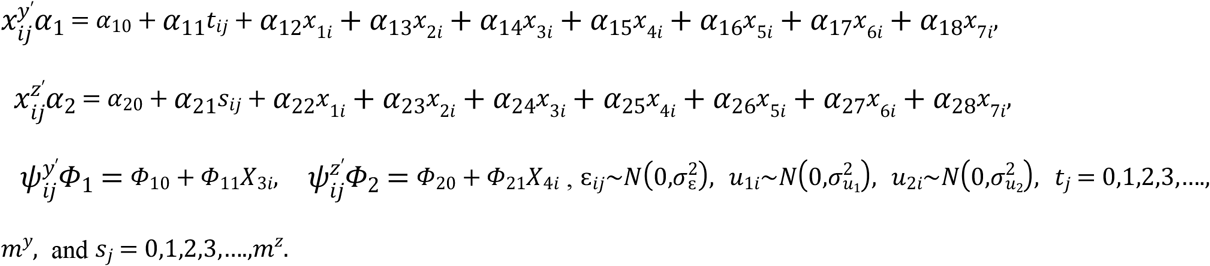
To make simulation feasible, each dataset included small to large individuals with longitudinal measurements. Follow-up visits are scheduled at time = {0, 1, 2, 3, 4, 5}. The true values considered for α1 = α2 = (1, ― 1,0,2,1,1,1, ― 1, ― 1)′ and Φ1 = Φ2 = (2,1)′. x11,x12,x13,x14 are generated from N(0,1), and x15,x16,x17 are generated from binom(n,1,0.1). ui = (u1i,u2i) is generated from MVN = (0,D), where
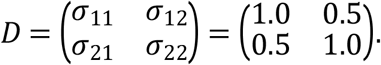
For the SPM incorporating non-monotone, non-ignorable missing data mechanism, model (26) and model (27) are formulated following Fitzmaurice et al. [19]. We first considered independence (ϒj,κj) = (0,0)′. Sample sizes are assessed by considering n = 500, n = 1,000, and n = 3,000 individuals with different association parameters as (ϒj,κj) = (1.000, ― 1.000)′, (ϒj,κj) = (0.500, ― 0.500)′, (ϒj,κj) = (― 0.500, ― 0.500)′.
Sensitivity analysis of posterior distribution is assessed by selecting different prior distributions. In the case of informative priors, the structure of prior distributions take main focus during the sensitivity analysis. Non-informative priors are assessed based on changes in posterior inference. All our parameters are checked for different parameters’ values to assess robustness of posterior means. In addition, sensitivity analysis can also be done for missingness mechanisms, where the assessment for ignorable and non-ignorable missingness can be evaluated. We do not apply sensitivity analysis for different missingness mechanisms, as it is beyond the scope of our study objective.
A computational procedure to estimate parameters in proposed joint model is conducted using Gibbs sampling by WinBUGS software. Two parallel MCMC sampling chains run with different starting values, convergence of chains is examined by trace plots and with diagnostic statistics suggested by Gelman et al. [18]. Posterior estimates are based on 10,000 iterations after discarding 5,000 of the burn-in period.
Data are generated under two scenarios: biomarker variability is not associated with each other (ϒ = 0), and both biomarkers are associated with each other (ϒ = ± 0.5, or ± 1.0). With that, it is also evaluated whether either missingness process is associated with the measurements process (κ = ± 0.5, 0r ± 1.0) or not. Each dataset is then analyzed using our proposed joint model.
Based on the results presented in Table 1, it is to be noted that the performance of the proposed joint model is good. Consistency of parameter estimates is evaluated by increasing sample size which causes reduced bias and standard error for respective parameters. The same interpretation of parameter estimates holds for zero to non-zero association parameters.
Results of the simulation study for binary and continuous longitudinal biomarkers data incorporating NMAR based on joint modelling for the simulation study. Estimate (Est.), standard error (SE), Bias for N = 100 simulated data with sample size 500, 1,000, and 3,000 considering association (ϒj,κj) = (0.5, ― 0.5)′.
5. Prostate cancer data analysis
The primary objective of prostate cancer (PC) data analysis is to detect any potential association between PSA and ALP biomarkers, and to simultaneously analyze both. PC data were collected from n =1504 patients who had at least 2 measurements of PSA, and ALP. Patients’ Age, Platelets, BMI, Bilirubin, Gleason Score, Grade are recorded along with the prescribed Drug. Following joint model is considered,


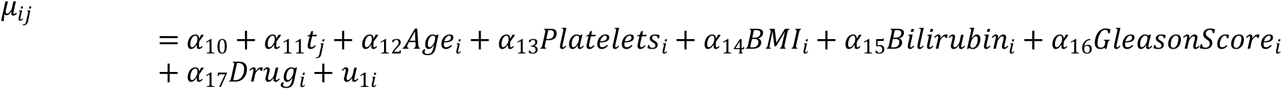 and
and
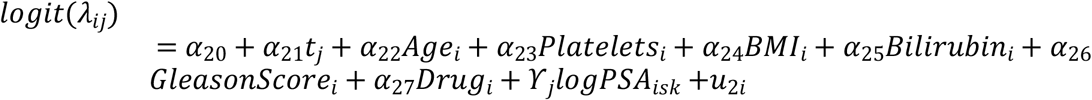
In addition, for non-ignorable missingness mechanisms following models are proposed,
 where
where 
 where,
where,  , and
, and 
Two parallel MCMC chains runs with different initial values for 10,000 iterations and discarded first 5,000 iterations as pre-convergence burn-in. Convergence of MCMC chains is checked using Gelman-Rubin diagnostic test. In addition, trace plots can plot for unknown parameters to assess convergence. To get posterior inference, prior distributions for unknown parameters are selected as, ui = (u1i,u2i)∼MVN((0,0),Du), i = 1,…,n, where Du∼IWishart  , such that the hyper-parameters of
, such that the hyper-parameters of 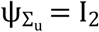 and
and 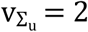 which lead to low-informative priors. It is also to be assumed that
which lead to low-informative priors. It is also to be assumed that 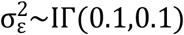 , the regression coefficients (αi1,αi2,ψi1,ψi2)′ are fixed effects unknown parameters and the prior distributions for them are N(0,1000), γj, j = 1,…,my is the associated parameter of the continuous longitudinal log(PSA) on the binary longitudinal ALP at time j and the prior distributions for it is N(0,1000). Prior distribution for associated parameter κj, j = 1,…,mz is N(0,1000), πlogPSA,πALP∼N(0,1000).
, the regression coefficients (αi1,αi2,ψi1,ψi2)′ are fixed effects unknown parameters and the prior distributions for them are N(0,1000), γj, j = 1,…,my is the associated parameter of the continuous longitudinal log(PSA) on the binary longitudinal ALP at time j and the prior distributions for it is N(0,1000). Prior distribution for associated parameter κj, j = 1,…,mz is N(0,1000), πlogPSA,πALP∼N(0,1000).
For model selection, we apply the deviance information criterion (DIC), which identifies the most suitable model by balancing between likelihood and parameters’ numbers. Posterior means and the number of parameters are used in this criteria to find the best-fitted model [20].

Where,  and
and  .
.
D(Ø) and 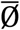 are posterior estimates of D(Ø) and Ø. w = wi = (w1,w2,w3,….,wn) is full data with marginal density,
are posterior estimates of D(Ø) and Ø. w = wi = (w1,w2,w3,….,wn) is full data with marginal density, 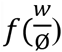 and Ø are vectors of model parameters. The lowest DIC leads us to the best model fit, that is our proposed joint model.
and Ø are vectors of model parameters. The lowest DIC leads us to the best model fit, that is our proposed joint model.
The parameter estimates and their 95% posterior intervals are presented in Table 2 and summarized for joint model: PSA level decreases with respect to time after treatment, and it is a good sign to evaluate efficiency of prescribed treatment when this decrease is significant. PSA alone is not an adequate biomarker, ALP measurements are also taken into account. ALP increases with respect to time for individuals, but this increase has not had any significant effect. The results indicate that with increasing age, both PSA and ALP increase. This positive increase is significant for PSA but non-significant for ALP. Platelets are another predictor of increasing PSA significantly, but due to one unit increase in platelets, ALP level decreases non-significantly with 0.026 on average. With increasing BMI, patients’ PSA and ALP both tend to significantly decrease. One unit increase in bilirubin measurement makes a significant increase of 0.201, and 0.617 in PSA and ALP measurements, respectively. The results show that PSA and ALP measurements are lower among those patients with a Gleason score greater than or equal to (4+3) as compared to those whose score is lower than and equal to (3+4), it is due to treatment effect. This study’s results revealed that patients who received ALT, prostatectomy, and their combinations have lower PSA and ALP measurements as compared to those who received EBRT; and this is a good sign to prove drug efficacy. There exists a positive correlation between PSA and ALP measurements that can be revealed with associated parameters ϒ; while a negative association exists between missingness and measurement processes. Results revealed that due to the existence of a positive association both PSA and ALP measurements should be simultaneously taken on PC patients to get insights about PC progression. In addition, missingness must be incorporated into data to avoid loss of information.
6. Conclusion
The primary goal of this manuscript was to jointly model different types of longitudinal outcomes incorporating non-ignorable missingness. One can directly apply mixed modelling techniques with considering missingness as an ignorable phenomenon. However, follow-up studies could get over the hurdles of loss of information in case of missingness by proposing SPM for mixed-longitudinal outcomes with missingness. For each missing data process, a logit model is proposed via a latent variable to depict the tendency of change for individuals. SPM proposed to join longitudinal and missingness models using random effects. This paper presents a joint modelling approach to analyze longitudinal biomarkers measurements in the presence of non-ignorable missing data due to both intermittent and monotone missingness. In our PC dataset, the non-monotone missingness pattern exists due to patients who missed visits, and monotone missingness data are from those patients who left the follow-up and never came back to complete the treatment process. We use logistic models to describe the missingness patterns. Our proposed model is adequate to account for the association between measurements and missingness processes, and it can be extended to models with more than two mixed longitudinal outcomes incorporating more than two missing outcomes processes.
Correlated random effects provide inference for non-ignorable missing data. However, the non-ignorable missingness assumption is untestable for the data at hand. In our collected PC dataset, non-ignorable assumption is verified as missingness occurred due to lack of treatment efficacy. Therefore, we incorporated missingness process in data analysis. However, researchers must put extra care to check assumptions about missingness mechanism, if the cause of missing data is not internally related to responses; local sensitivity analysis should be performed.
This study emphasis that PC patients must be monitored for PSA and ALP simultaneously. It is important to take into consideration both PSA and ALP levels as both can influence the health of PC patients. In addition, missing observations must be incorporated in data analysis to get full information about patients’ health and wellbeing. An elevated level of PSA shows the non-effectiveness of particular treatment, and an elevated level of ALP depicts the spread of PC tumor cells.
Data Availability
Data cannot be shared publicly because it is secondary data taken from a hospital. Data is available from the corresponding author upon reasonable request for researchers who meet the criteria for access to confidential data.
Acknowledgements
None.
Footnotes
madiha.phd.stat{at}pu.edu.pk
kamal0shahid{at}gmail.com
References



