
ABSTRACT
Importance Diagnostic codes are commonly used as inputs for clinical prediction models, to create labels for prediction tasks, and to identify cohorts for multicenter network studies. However, the coverage rates of diagnostic codes and their variability across institutions are underexplored.
Objective Primary objective was to describe lab- and diagnosis-based labels for 7 selected outcomes at three institutions. Secondary objectives were to describe agreement, sensitivity, and specificity of diagnosis-based labels against lab-based labels.
Methods This study included three cohorts: SickKidsPeds from The Hospital for Sick Children, and StanfordPeds and StanfordAdults from Stanford Medicine. We included seven clinical outcomes with lab-based definitions: acute kidney injury, hyperkalemia, hypoglycemia, hyponatremia, anemia, neutropenia and thrombocytopenia. For each outcome, we created four lab-based labels (abnormal, mild, moderate and severe) based on test result and one diagnosis-based label. Proportion of admissions with a positive label were presented for each outcome stratified by cohort. Using lab-based labels as the gold standard, agreement using Cohen’s Kappa, sensitivity and specificity were calculated for each lab-based severity level.
Results The number of admissions included were: SickKidsPeds (n=59,298), StanfordPeds (n=24,639) and StanfordAdults (n=159,985). The proportion of admissions with a positive diagnosis-based label was significantly higher for StanfordPeds compared to SickKidsPeds across all outcomes, with odds ratio (99.9% confidence interval) for abnormal diagnosis-based label ranging from 2.2 (1.7-2.7) for neutropenia to 18.4 (10.1-33.4) for hyperkalemia. Lab-based labels were more similar by institution. When using lab-based labels as the gold standard, Cohen’s Kappa and sensitivity were lower at SickKidsPeds for all severity levels compared to StanfordPeds.
Conclusions Across multiple outcomes, diagnosis codes were consistently different between the two pediatric institutions. This difference was not explained by differences in test results. These results may have implications for machine learning model development and deployment.
INTRODUCTION
Machine learning models based on electronic health records (EHRs) are increasingly being developed and implemented into routine care. They have improved outcomes related to reducing acute care visits among ambulatory cancer patients1, decreasing in-hospital clinical deterioration2, increasing serious illness conversations3, improving platelet utilization4 and refining antibiotic choice5 as examples.
To develop models, inputs or features are extracted from EHRs; these reflect different aspects of care such as diagnostic codes, laboratory tests, microbiology results, medication administrations, blood product administration, and procedures. Diagnostic codes are also frequently used to define the outcome of interest or label. How well each institution generates accurate diagnostic codes may vary depending on the coding process specific to the instution6 and clinical diagnostic practice specific to the hospital unit or physician6-8. This variability might influence the performance and generalizability of machine learning models developed at institutions with different diagnostic coverage rates. In pediatric populations, the coverage rates of diagnostic codes and their variability across institutions are underexplored9,10.
A challenge to studying the question of diagnostic code coverage is the creation of gold standard labels as the diagnostic codes themselves are often used to develop these labels. One type of clinical data in which the label is inherent within the result itself is laboratory-based outcomes. Abnormal lab tests can be defined using institution-specific reference ranges. In addition, levels of severity (mild, moderate, and severe) for each abnormal lab test can be defined based upon widely accepted thresholds. Thus, evaluating diagnostic code coverage against lab-based definitions provides a pragmatic setting in which to evaluate this question.
Consequently, the primary objective was to describe lab- and diagnosis-based labels for selected outcomes at three institutions. Secondary objectives were to describe agreement, sensitivity, and specificity of diagnosis-based labels against lab-based labels.
METHODS
Design
This study used data derived from EHRs at three institutions, namely The Hospital for Sick Children (SickKids) in Toronto, Ontario; Lucile Packard Children’s Hospital (primarily pediatric-directed care) in Palo Alto, California and Stanford Health Care (primarily adult-directed care) in Palo Alto, California. The overall goal was to compare lab- and diagnosis-based labels for pediatric patients at SickKids vs. Stanford. We included a Stanford adult cohort for descriptive purposes.
Data Sources
SEDAR
The data source at SickKids was the SickKids Enterprise-wide Data in Azure Repository (SEDAR)11. SEDAR contains a curated version of Epic Clarity data that is being used for operational, quality improvement and research purposes. This study was approved as a quality improvement project at SickKids and consequently, the requirement for Research Ethics Board approval and informed consent were not required.
STARR
The Stanford medicine research data repository (STARR)12 is the clinical data warehouse that contains records routinely collected in the EHR of Stanford Medicine, which is comprised of Lucile Packard Children’s Hospital and Stanford Health Care. The data have been mapped to the standard concept identifiers and structure of the Observational Medical Outcomes Partnership Common Data Model (OMOP-CDM)13, resulting in a dataset named STARR-OMOP. This study used a de-identified version of STARR-OMOP12 in which protected health information has been redacted. Because of de-identification, requirement for Institutional Review Board approval and informed consent were not required for data use.
Cohorts
We defined three cohorts. SickKidsPeds was obtained using SEDAR while StanfordPeds and StanfordAdults were obtained using STARR-OMOP and applying age-specific restrictions. Table 1 summarizes the inclusion criteria for each cohort. Across all three cohorts, inpatient admissions were included if they occurred between 2018-06-02 to 2022-08-01. The pediatric cohorts (SickKidsPeds and StanfordPeds) included patients who were 28 days or older and younger than 18 years on the day of admission. We excluded neonates 1 to 27 days of age because Lucile Packard Children’s Hospital has an obstetrical unit and consequently includes healthy newborns while SickKids does not have an obstetrical unit and does not routinely see healthy newborns. StanfordAdults included adult patients aged 18 or above on the day of admission. Multiple admissions per patient were permitted as long as eligibility criteria were met.
Outcome Definitions
We included seven clinical outcomes that have lab-based definitions, namely acute kidney injury (AKI), hyperkalemia, hypoglycemia, hyponatremia, anemia, neutropenia, and thrombocytopenia. We appreciate there are a large number of potential lab-based outcomes; these seven were chosen based on our current research interests and because they are clinically meaningful. The outcomes were chosen a priori, before conducting any of the analyses. We purposely did not include abnormal high and low for the same lab test (for example, hyperglycemia and hypoglycemia) as they may be correlated. For each outcome, we created four lab-based labels based on the test result and one diagnosis-based label; these five labels were evaluated in each patient admission. Appendix 1 shows the thresholds for each severity level (mild, moderate, and severe levels) of the lab-based labels; these thresholds were based upon research studies or guidelines14-20. We also labeled the result as abnormal if the result was above or below (not both) of the institution-specific reference range. For lab-based labels, units for lab results were normalized, and severity level was nested. For example, a patient admission with severe hypoglycemia would also be included in the analyses for mild and moderate hypoglycemia. For the diagnosis-based label, we considered an outcome to be present if at least one outcome-related diagnosis code was assigned to the admission.
Concept Selection for Lab-based and Diagnosis-based Labels
We adopted different search strategies for concepts in STARR-OMOP and SEDAR due to differences in structure and vocabularies for clinical codes. Diagnosis codes were derived from the “condition_occurrence” table for STARR-OMOP and from the “diagnosis” table for SEDAR. Lab test results were obtained from the “measurement” table for STARR-OMOP and from the “lab” table for SEDAR. For face validation, diagnosis codes and lab result distributions obtained from STARR-OMOP were reviewed by three clinicians (KEM, CA and LS) to identify errors related to normalization or concept selection. At SickKids, this same review was only conducted by one clinician (LS) due to access restrictions.
Baseline Characteristics by Cohort
To explore whether there were differences in the cohorts with respect to patients, we described the demographic characteristics and raw lab results of patients between centers. Demographic characteristics included age, sex, length of stay, and the prevalence of in-hospital mortality. For the evaluation of raw lab results, we determined the minimum or maximum result for each lab test per admission and stratified by cohort.
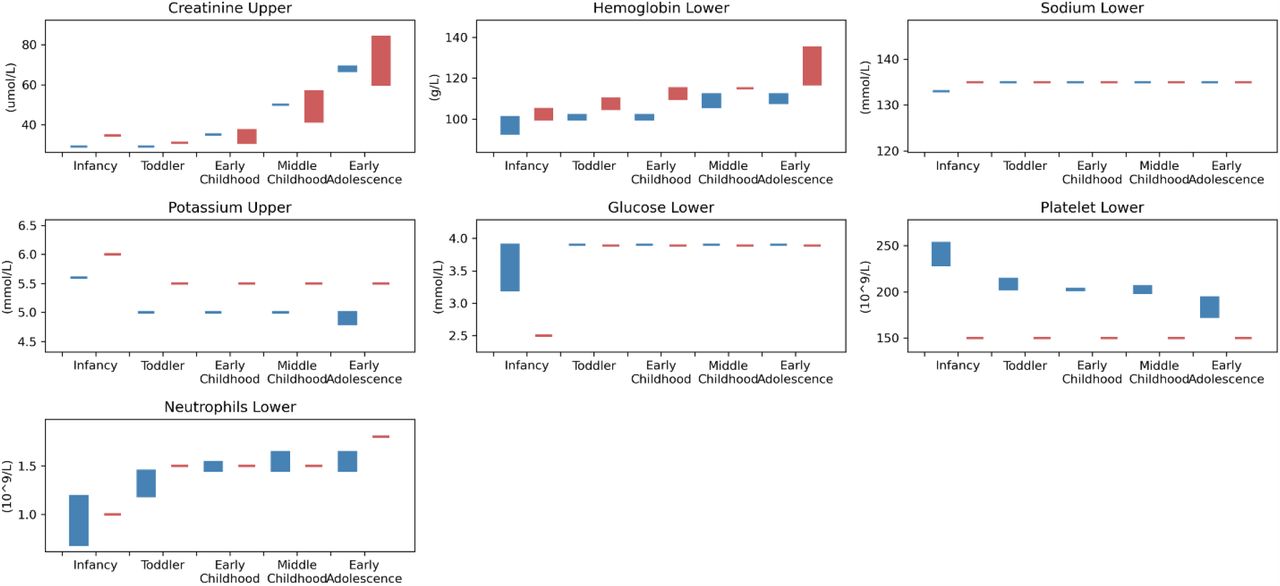
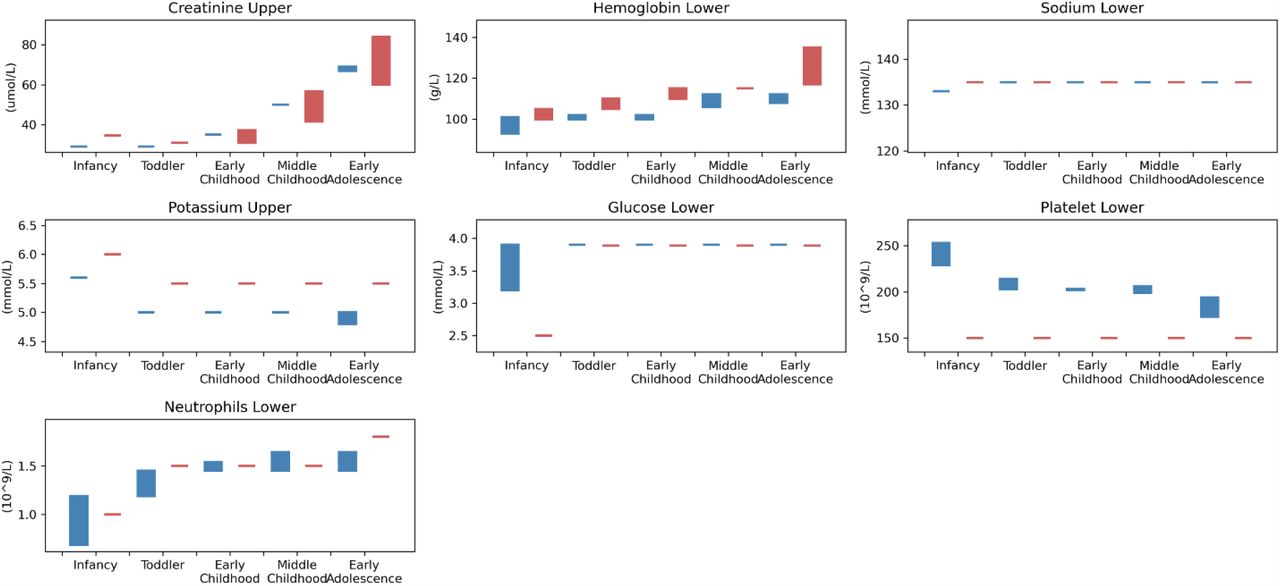
To gain insight into whether there were differences between pediatric institutions with respect to laboratory procedures or clinical practice, we described the institution- and age group-specific reference ranges for abnormal lab results by SickKidsPeds and StanfordPeds. The pediatric age groups were defined by the National Institute of Child Health and Human Development21 as infancy (28 days – 12 months), toddler (13 months – 2 years), early childhood (2 – 5 years), middle childhood (6 – 11 years) and early adolescence (12 – 17 years). In addition, we evaluated lab testing frequency calculated as the number of tests per inpatient day for each admission.
Statistical Analysis
The primary objective was to describe lab- and diagnosis-based labels at the three institutions. These were presented as the proportion of admissions with at least one positive label. To describe the odds of a lab- or diagnosis-based label by whether the pediatric admission occurred at StanfordPeds vs. SickKidsPeds, analysis was complicated by the large number of admissions and multiple testing (35 separate evaluations for this analysis alone). In addition, there were multiple admissions per patient, resulting in correlation within individuals. To address these concerns, we took several steps. First, we focused on describing the odds ratio (OR) and 99.9% confidence interval (CI) for a lab- or diagnosis-based label by pediatric institution. Second, we described the 99.9% confidence interval rather than the 95% confidence interval to help address multiple testing. Third, we did not calculate P values but rather, focused on describing CIs with the exception of comparing lab testing frequency by institution. Finally, to address multiple admissions per patient, OR and 99.9% CI were calculated using mixed-effects logistic regression. Models included each binary label as the outcome, institution and pediatric age group as fixed effects and subject as random intercept. Analysis was performed using the glmer function from lme4 package in R.
The secondary objectives were to describe agreement, sensitivity, and specificity of diagnosis-based labels against lab-based labels. Agreement in each cohort was described using Cohen’s Kappa coefficient. Sensitivity and specificity of the diagnosis-based labels were determined using each of the lab-based labels as the gold standard. For each metric, we presented the median and ranges stratified by cohort and lab-based severity (abnormal, mild, moderate and severe).
As an exploratory analysis, we separately evaluated each visited unit during admissions at each pediatric institution. We examined the weighted proportion of positive lab-based labels and positive diagnosis-based labels for each hospital unit and calculated Spearman’s rho (r) based on the average across lab-based severity.
To describe lab-based reference ranges for pediatric patients, we described the threshold for an abnormal lab test by pediatric age group stratified by institution. Where the threshold varied within an age group, the range was visually depicted using a bar rather than a line. To compare testing frequency between pediatric institutions, mixed-effects linear regression was performed with number of lab tests per admission as the outcome, institution and pediatric age group as fixed effects and subject as random intercept. Analysis was performed using the lmer function from the lme4 package in R.
All analyses were conducted using Python (version 3.7) and R (version 4.1.2).
RESULTS
Baseline Characteristics
The number of admissions included were: SickKidsPeds (n=59,298), StanfordPeds (n=24,639) and StanfordAdults (n=159,985). Characteristics of the three cohorts are listed in Table 1. The distributions of age, sex, in-hospital mortality, and median length of stay were similar between SickKidsPeds and StanfordPeds while the distribution of sex and in-hospital mortality differed at StanfordAdult. Table 2 shows the distribution of minimum or maximum results for each lab test per admission by cohort. Distributions appeared similar between StanfordPeds and SickKidsPeds with the exception of minimum absolute neutrophil count, which was lower at SickKidsPeds vs. StanfordPeds. Appendix 2 shows that the reference ranges varied between SickKidsPeds and StanfordPeds. Reference ranges for glucose and sodium were the same for all age groups except infants. Reference ranges for potassium and platelets were notably different by institution across age groups. Appendix 3 shows the average number of lab tests performed per inpatient day across all admissions stratified by institution. SickKidsPeds performed significantly fewer tests compared to StanfordPeds for all tests.
Prevalence of Lab-based and Diagnosis-based Labels
Table 3 provides the percentage of admissions with a positive lab- and diagnosis-based label. Table 3 and Figure 1 show OR and 99.9% CI. The proportion of admissions with a positive diagnosis-based label was significantly higher for StanfordPeds compared to SickKidsPeds across all outcomes, with OR (99.9% CI) for abnormal diagnosis-based label ranging from 2.2 (1.7-2.7) for neutropenia to 18.4 (10.1-33.4) for hyperkalemia. Lab-based labels were more similar by institution although several were significantly different as demonstrated by CIs that did not cross 1.

Figure shows odds ratio and 99.9% confidence interval showing odds of an abnormal label by institution. Dashed line indicates an odds ratio of 1. An odds ratio of >1 corresponds to higher odds of assigning a positive label for StanfordPeds compared to SickKidsPeds. Odds ratios were obtained using mixed-effects logistic regression with each binary label as outcome, institution and pediatric age group as fixed effects and subject as random intercept
Agreement between Outcome Definitions
Figure 2 shows the evaluations of diagnosis-based labels against each of the lab-based labels using Cohen’s Kappa coefficient, sensitivity, and specificity. Overall, diagnosis codes had high specificity (mean=0.984, standard deviation (SD)=0.026) but low sensitivity (mean = 0.203, SD=0.158) and low Kappa (mean=0.213, SD=0.132) with lab-based labels. Compared to StanfordPeds, SickKidsPeds diagnosis-based labels had lower Kappa statistic and sensitivity, but higher specificity.

The figure shows median, interquartile range (shaded box) and range (whiskers)
Figure 3 plots the weighted proportions of positive diagnosis-based labels against the weighted proportions of positive lab-based labels for each hospital unit at SickKidsPeds and StanfordPeds. At StanfordPeds, units associated with more patients with lab-based labels also had more patients with a positive diagnosis-based label for a clinical outcome, with Spearman r ranging from 0.513 (hyponatremia) to 0.871 (neutropenia). In contrast, the Spearman r’s were generally lower at SickKidsPeds across all outcomes, and ranged from 0.010 (hypoglycemia) to 0.356 (anemia).

The numbers on the x- and y- axis represent the weighted proportion of positive lab-based labels and positive diagnosis-based labels for each hospital unit visited during the admission. Spearman rho (r) was calculated based on the average across lab-based severity
DISCUSSION
Our results showed that despite similar demographic characteristics, there were large differences between the two pediatric institutions in the proportion of admissions with diagnosis codes for the evaluated clinical outcomes. In addition, diagnosis-based labels generally had low agreement with lab-based labels and displayed low sensitivity but high specificity when considering lab-based labels as the gold standard, with differences observed between the two institutions. In addition, we found differences between the two institutions in terms of test ordering frequency and even laboratory test references ranges.
These results suggest that if machine learning models are intended for deployment at multiple institutions, reliance on diagnostic codes, either as feature or labels, could be problematic if institutions have different coding practices. Second, they suggest that using institutional reference ranges to categorize laboratory test results may contribute to geographic dataset shift. This study contributes to the body of evidence that demonstrates the limitations of using diagnosis codes for outcome identification. Studies have reported low sensitivity rate when using diagnosis codes to identify, for example, acute kidney injury22, obesity23, and symptoms of coronavirus disease 201924. In addition, this study showed differences between and within institutions in diagnostic practice that may have contributed to the differences in the performance of diagnosis codes for outcome identification.
Diagnosis codes from the EHR are commonly queried during feature extraction25-29, label creation30, and cohort identification31. Heterogeneity in diagnostic practice across hospital units within the same institution (e.g., SickKids) can impact a model’s performance within sub-populations or spuriously associate certain units with the outcome of interest during model development. In addition, the cross-institution difference in diagnostic coding practice has implications for network studies as it violates the assumption that coding practice is comparable across institutions and creates heterogeneity in outcome prevalence as an artifact of code availability.
While we found that the proportions of positive lab-based labels were more similar between pediatric institutions, there were significant differences although smaller than that observed for diagnosis-based labels. Possible contributions were the observed differences in lab testing frequency between the two pediatric institutions. In addition, the reference ranges themselves were different for tests with the same absolute interpretation regardless of where the test was conducted. For example, two hypothetical children with the same platelet count could be considered to have a normal test at one institution and an abnormal test at the second institution. Some SickKids reference ranges were based upon those established by the Canadian Laboratory Initiative on Pediatric Reference Intervals (CALIPER) initiative,32 which contributed to the disparity. Nonetheless, this has implications for machine learning models. First, it is common during feature processing to categorize lab test results as normal, high, and low based upon the reference range25,33. Having different reference ranges would thus produce different features despite having the same numerical value. Second, different reference ranges may impact downstream clinical decision making and variability of resultant clinical actions, for example procedures and medication administrations. Since these actions will be recorded in the EHR, impact on clinical decision making can further worsen geographic dataset shift.
The strengths of this study include the ability to evaluate multiple institutions in different countries and the involvement of clinician co-investigators who contributed to the identification of concepts to include in the various label definitions. However, this study is limited for several reasons. First, we only evaluated seven outcomes. In addition, the outcomes were restricted to those that have lab-based definitions in order to use lab tests to develop gold standard labels. Outcomes that are more complex might require chart review to establish gold standards and more sophisticated electronic phenotyping approaches to reach reasonable performance34,35. Finally, our analyses were restricted to admissions within a relatively narrow time period (2018-2022). It might be useful to characterize practice differences over time as temporal distribution shift can negatively impact model performance over time27,36.
In conclusion, across multiple outcomes, diagnosis codes were consistently different between the two pediatric institutions. This difference was not explained by differences in test results. These results may have implications for machine learning model development and deployment.
Data Availability
The data are available from the corresponding author upon reasonable request.
Figure Legend
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abbreviation: SickKids: The Hospital for Sick Children; Peds: pediatrics.
REFERENCES



