
ABSTRACT
Objective COVID-19 Living OVerview of Evidence (COVID-19 L·OVE) is a public repository and classification platform for COVID-19 articles. The repository contains over 430,000 articles as of 20 September 2021 and intends to provide a one-stop shop for COVID-19 evidence. Considering that systematic reviews conduct high-quality searches, this study assesses the comprehensiveness and currency of the repository against the total number of studies in a representative sample of COVID-19 systematic reviews.
Methods Our sample was generated from all the studies included in the systematic reviews of COVID-19 published during April 2021. We estimated the comprehensiveness of COVID-19 L·OVE repository by determining how many of the individual studies in the sample were included in the COVID-19 L·OVE repository. We estimated the currency as the percentage of studies that were available in the COVID-19 L·OVE repository at the time the systematic reviews conducted their own search.
Results We identified 83 eligible systematic reviews that included 2132 studies. COVID-19 L·OVE had an overall comprehensiveness of 99.67% (2125/2132). The overall currency of the repository, that is, the proportion of articles that would have been obtained if the search of the reviews was conducted in COVID-19 L·OVE instead of searching the original sources, was 96.48% (2057/2132). Both the comprehensiveness and the currency were 100% for randomised trials (82/82).
Conclusion The COVID-19 L·OVE repository is highly comprehensive and current. Using this repository instead of traditional manual searches in multiple databases can save a great amount of work to people conducting systematic reviews and would improve the comprehensiveness and timeliness of evidence syntheses. This tool is particularly important for supporting living evidence synthesis processes
BACKGROUND
Researchers from all over the world have been rapidly working to respond to the pandemic. As a result, an overabundance of scientific articles is making it difficult for healthcare professionals, policy makers, journalists and the general public to keep pace with the body of knowledge about SARS-CoV-2 and COVID-19 [1].
Identifying all the articles relevant to a specific purpose requires sifting through multiple electronic databases. Due to the urgent need to share new findings fast, articles are frequently shared on preprint servers, so these must also be consulted [2].
Several organisations have released resources to facilitate access to articles about SARS-CoV-2 and COVID-19 [3-7]. However, these resources seem to have a very low level of use. Indeed, it is not clear if they have actually facilitated access to the information or just added to the number of sources that researchers and others must sift through [8].
One of the reasons why these COVID-19 resources might be underutilised is because users distrust that they contain all the relevant information. One way of testing this is by comparing exhaustive searches, like those conducted in systematic reviews, against searches using these resources [9].
In June 2020 Epistemonikos Foundation launched COVID-19 L·OVE (Living OVerview of Evidence), a free access repository and classification platform for COVID-19 evidence available at https://app.iloveevidence.com/covid19 (the repository is available through the advanced search interface. See Figure 1).
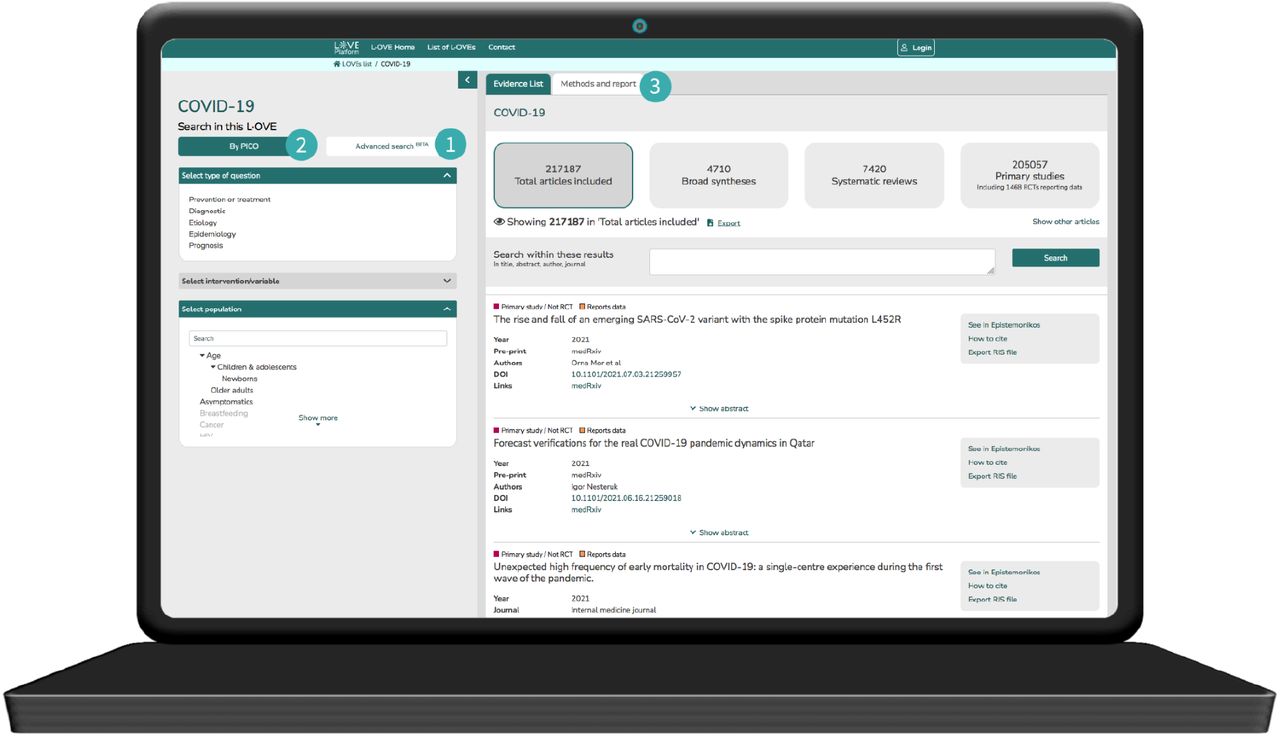
(1) The COVID-19 L·OVE repository (https://app.iloveevidence.com/covid19/repository) is accessible through the ‘advanced search’ interface. An empty search retrieves all the available records. (2) The classification platform allocates the records to the different terms or a combination of terms relevant to COVID-19. The performance of this component is not addressed in this article. (3) The latest version of the methods and the updated report of the results is provided on the website.
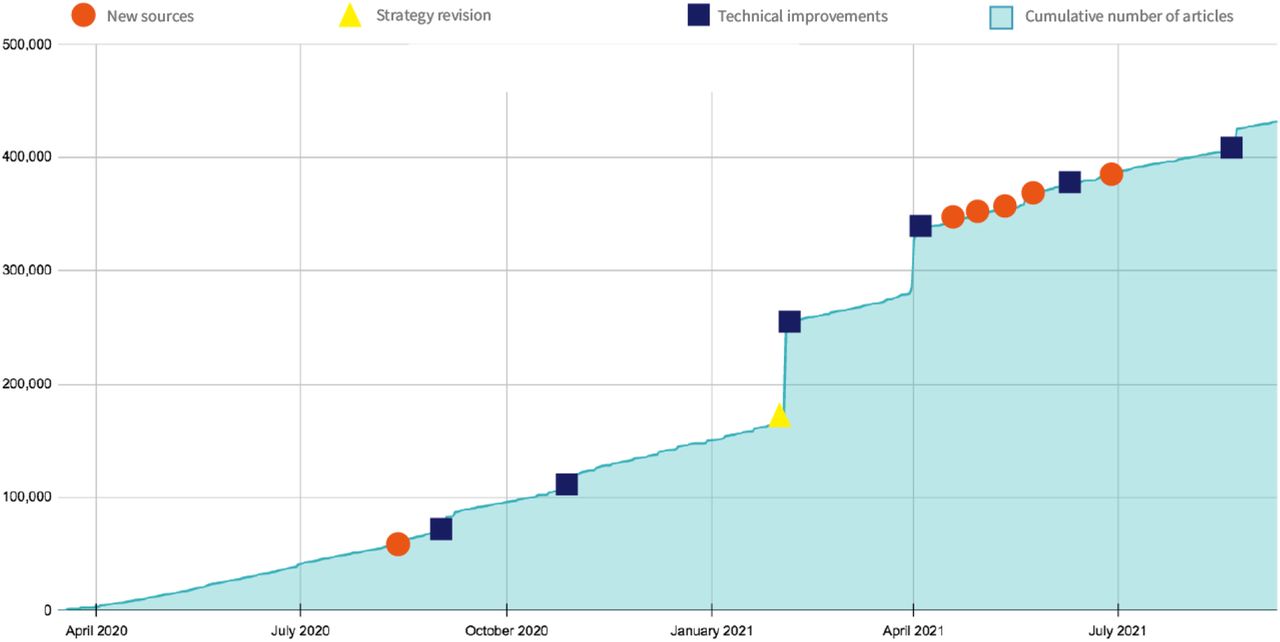
The systematic methods used to build and maintain this resource, the high level of automation used to retrieve the articles and the large number of sources that are harvested makes it one of the largest COVID-19 repositories available. As of 20 September 2021, it contains 434,659 articles (see Figure 2).

The COVID-19 L·OVE repository was built through multiple iterations that included the addition of relevant sources, the refinement of the search strategies used for each source, and the application of technological developments to improve the harvesting process from each source. Modifications that translated into substantial upload of articles are shown in the figure.
One of the main purposes of the COVID-19 L·OVE repository is to replace the need to search multiple sources of COVID-19 evidence. Considering the high quality of searches conducted in systematic reviews, we designed this study to assess how comprehensive and current the repository is against a reference standard composed of the totality of studies included in a representative sample of COVID-19 systematic reviews.
METHODS
Methods used to build and maintain the repository
The COVID-19 L·OVE is based on two interrelated components: a repository and a classification platform. The latest version of the methods used in each of these components is available in the methods section of the COVID-19 L·OVE website (https://app.iloveevidence.com/covid19/methods).
Given that this article only covers the methods and performance of the repository component of the COVID-19 L·OVE, we briefly summarise said methods, as of September 2021, here:
The COVID-19 L·OVE repository was built, and is maintained, by systematic searches of 42 databases, trial registries and preprint servers. Searches are not restricted by study design, language or publication status. The sources include PubMed, EMBASE, CINAHL (the Cumulative Index to Nursing and Allied Health Literature), PsycINFO, LILACS (Latin American & Caribbean Health Sciences Literature), Wanfang Database, CBM (Chinese Biomedical Literature Database), CNKI (Chinese National Knowledge Infrastructure), VIP (Chinese Scientific Journal Database), IRIS (WHO Institutional Repository for Information Sharing), IRIS PAHO (PAHO Institutional Repository for Information Sharing), IBECS (Spanish Bibliographic Index on Health Sciences), Microsoft Academic, ICTRP Search Portal, Clinicaltrials.gov, ISRCTN registry, Chinese Clinical Trial Registry, IRCT (Iranian Registry of Clinical Trials), EU Clinical Trials Register, Japan NIPH Clinical Trials Search, JPRN (Japan Primary Registries Network - includes JapicCTI, JMACCT CTR, jRCT, UMIN CTR), CRiS (Clinical Research Information Service), ANZCTR (Australian New Zealand Clinical Trials Registry), ReBec (Brazilian Clinical Trials Registry), CTRI (Clinical Trials Registry - India), RPCEC (Cuban Public Registry of Clinical Trials), DRKS (German Clinical Trials Register), LBCTR (Lebanese Clinical Trials Registry), TCTR (Thai Clinical Trials Registry), NTR (The Netherlands National Trial Register), PACTR (Pan African Clinical Trial Registry), REPEC (Peruvian Clinical Trial Registry), SLCTR (Sri Lanka Clinical Trials Registry), MedRxiv, BioRxiv, SSRN Preprints, Research Square, ChinaXiv and SciELO Preprints.
We adapted our main COVID-19 boolean strategy (Appendix 1) to the syntax of each source. The information is obtained from the sources using different technology solutions, such as querying publicly available APIs, subscribing to RSS feeds, parsing .csv files posted on websites and running traditional manual searches.
In order to identify articles that an electronic search could potentially miss, we manually check all the systematic reviews and other types of evidence syntheses (e.g. overviews of systematic reviews, scoping reviews, guidelines) and add all articles included in those. Additionally, we evaluate potentially eligible articles that users send by email and other means (e.g. twitter).
As randomised trials are particularly relevant for decision-making, we also run a regular search for randomised trials on Twitter using the terms #COVID19 OR #COVID-19 OR #COVID_19 OR #COVID randomized OR randomised, and scan relevant scientific conferences, press release websites and the websites of the main trials or companies relevant to COVID-19.
All the articles retrieved by the electronic searches are assessed by two automated classifiers specifically developed for this project. The first classifier is a binary exact-match classifier based on a continuously updated list of terms obtained by applying Word2vec technology with proprietary software developed by Epistemonikos to the corpus of documents available in the repository [10]. The terms with more similar vectors are analysed by a team of content and methods experts and are selected based on their incremental recall (i.e. their capacity to identify new ‘positives’ in the unclassified records). The second classifier combines a highly specific COVID-19 boolean strategy with the publication date of the articles (year 2020 or more recent).
The articles excluded by the classifier are not checked. However, any time an article is identified by another means (e.g. a study included in a systematic review) the methods team checks for the presence of any term that can be added to the search strategy or the list of terms used by the exact-match classifier.
The articles included by the classifiers are screened by the COVID-19 L·OVE users, collaborators or methods team (e.g. during collective screening of the classification platform). Articles are only included if they directly address an issue concerning COVID-19 or the indirect consequences of COVID-19 (e.g. the consequences of lockdown). We do not include COVID-19 articles that might be relevant but were conducted in different contexts (e.g. telemedicine before the COVID-19 pandemic, facemasks for influenza).
Methods to assess the performance of the repository
Sample
The sampling method is based on the relative recall method, where a sample of primary studies from published systematic reviews is used as a reference standard to evaluate the performance [11]. Our sample was composed of all the primary studies, published as journal articles or preprints, included in the systematic reviews identified on the COVID-19 L·OVE platform during April 2021.
We considered eligible any review that:
fulfilled the definition of systematic review used in the Epistemonikos Database [12].
addressed a question directly relevant to COVID-19. We excluded reviews addressing an issue broader than COVID-19. That is, reviews including studies of COVID-19 and other conditions (e.g. other coronaviruses) or using indirect evidence (e.g. evidence from previous pandemics).
clearly reported the search date.
provided the list of included studies.
only included studies published before the search date reported in the review.
We extracted the following data from the systematic reviews: authors, title, type of article, date of publication, date of the search and list of included studies (according to the definition of primary study used in Epistemonikos Database [12]). From the primary studies we extracted: authors, title, date of publication, type of article (e.g. preprint, journal) and study design.
Comprehensiveness
To evaluate the comprehensiveness (sensitivity or recall) of COVID-19 L·OVE we determined if the primary studies in the sample were contained within the repository at the time that COVID-19 L·OVE detected the systematic review. All the studies included in a specific review that were available in the repository before the detection date were defined as being contained in the COVID-19 L·OVE repository. The studies that entered the repository after this date were defined as not being contained because the missing studies might have been added after the list of studies included in the systematic review was checked manually, which is part of the search strategy of COVID-19 L·OVE.
We calculated comprehensiveness as:
Currency
We defined currency as the percentage of references that were available in the COVID-19 L·OVE repository at the time of the review search in comparison to the total number of references in the sample.
In other words, our definition of currency is the proportion of references that would have been obtained if the search of the review was conducted in COVID-19 L·OVE instead of searching the original sources.
We calculated currency as:
Audit
To understand the reasons for the failure or delay in the identification of articles, we conducted an audit of all references that were not contained in the repository or were not contained at the search date of the reviews. That is, the studies that were not added to the numerator of the comprehensiveness and currency calculation, respectively.
RESULTS
Description of the sample
We identified 405 potentially eligible systematic reviews published during April 2021. We excluded 322 reviews because they were protocols (n=14), addressed a population broader than COVID-19 (n=269) or did not clearly report the last search date (n=39). Our final sample was generated from 83 eligible systematic reviews. The details about the reviews used to build the sample are available in the Appendix 2. The 83 reviews included 2683 studies overall. After removing 533 duplicates and 18 studies based on unpublished data only, the final sample resulted in 2132 studies.
The selection process is summarised in figure 3.

{kind=link}
{kind=link}
{kind=link}
From the 83 systematic reviews in our sample, 66 (79.52%%) were journal articles, 7 (8.43%) were preprints and 1 (1.20%) was an HTA report. The search date of the reviews ranged from 8 April 2020 to 21 April 2021 (median= 21 November 2020) and the number of studies included in each review ranged from 2 to 350 (median=21). The 2132 primary studies in the sample corresponded to 82 (3.85%) randomised trials and 2050 (96.15%) studies of other designs. There were 2016 (94.56%) journal articles and 116 (5.44%) preprints.
Comprehensiveness
Based on our sample, the overall comprehensiveness of the COVID-19 L·OVE repository was 99.67% (2125/2132).
Only seven of 2132 studies in the sample were not contained in the repository. The missing seven studies were from two systematic reviews. Six of them were observational studies in Chinese from a review of COVID-19 related pressure injuries [13] and one was an observational study in Chinese from a review addressing shedding of fecal SARS-CoV-2 RNA in COVID-19 [14].
An audit of these seven studies showed that all of them were available in Chinese databases that were in the list of sources searched by COVID-19 L·OVE. However, retrieval from Chinese databases is one of the few processes not fully automated in the repository, so the most likely explanation for their omission was human error.
The COVID-19 L·OVE repository had perfect comprehensiveness for randomised trials (100%,82/82) and very high comprehensiveness for other types of studies (99.66%, 2043/2050). The coverage was very high for journal articles (99.65%,2009/2016) and perfect for preprints (100%,116/116). The details are presented in table 1.
Currency
Based on our sample, the overall currency of the COVID-19 L·OVE repository was 96.48% (2057/2132).
All the randomised trials in the sample (82/82) and 96.34% (1975/2050) of the other types of study were available in the repository when the reviews were searched. The currency was 97.17% (1959/2016) and 84.48% (98/116) for journal articles and preprints, respectively. The details are presented in table 1.
An audit of the 75 articles that entered COVID-19 L·OVE with a delay showed that 27 out of 75 (36%) were not available in the sources of COVID-19 L·OVE at the time of the review search. These were all articles that were available on the journal’s website but were not yet indexed in the electronic databases harvested by COVID-19 L·OVE. Most reviews capturing these studies reported a search in Google or Google Scholar, or used strategies to complement the electronic searches, which is the most likely manner in which they captured these studies.
Thirteen of 75 (17.33%) references were not available in COVID-19 L·OVE at the time of the search but were entered in the following two days. This delay is due to the frequency of the searches of the sources that feed the COVID-19 L·OVE repository, which varies from daily to weekly.
Five references out of a total of 75 (6.67%) were added even though they were not available in any of the electronic sources used to maintain the repository. They were entered because they were referred to in reviews that were captured by COVID-19 L·OVE. The manual addition of studies referenced by reviews is one of the strategies used to feed the repository. This process is prone to delays since it depends on manual work.
Sixteen of 75 (21.33%) references corresponded to preprints from searches conducted before July 2020, when automated searches in preprint servers were not fully deployed in the COVID-19 L·OVE repository.
Finally, 14 of 75 (18.67%) references were entered into the repository with a substantial delay because of different technical issues in the retrieval system. All these issues have been identified and solved at the time of writing this article.
DISCUSSION
This formal evaluation of the COVID-19 L·OVE repository was based on a large and representative sample of more than 2,000 studies from all the eligible systematic reviews published during a whole month.
Our main conclusion is that the comprehensiveness and currency of the repository range from very high to perfect for all types of primary studies released as journal articles or preprints. It is particularly remarkable that the coverage and currency for randomised trials was 100%. In practical terms, our results show that the COVID-19 L·OVE repository can be safely used as the sole source for studies in any COVID-19 topic.
Our results are in agreement with previous evaluations of the performance of COVID-19 L·OVE. The comprehensiveness of the COVID-19 L·OVE repository was assessed by researchers from the COVID-NMA initiative. This evaluation demonstrated that COVID-19 L·OVE identified 100% of the randomised trials and observational studies that were identified through the initial extensive search strategy, which included electronic databases, preprint servers and several other COVID-19 resources [15,16]. A comparative analysis of the studies included in multiple systematic reviews found that among 25 systematic reviews addressing one specific question, they included 17 primary studies overall. All of them were contained in the COVID-19 L·OVE platform and there were 11 extra primary studies that were not identified by any of the reviews [17].
The available information on the performance of other COVID-19 resources is very limited. For most resources we only know the number of articles they include. We know, for instance, that as of 20 September 2021 there were 355,746 records in the WHO COVID-19 database [3] and 172,850 in LitCovid [5]. But using the number of articles as a proxy for the comprehensiveness is unreliable since the differences might be explained by the use of different inclusion criteria, which could lead, for example, to the inclusion of non-scientific records (e.g. news articles) and the retrieval of non-COVID literature.
As far as we know, the only published evaluation of a study assessing another COVID-19 resource, the Cochrane COVID-19 Study Register, showed that the overall comprehensiveness was only 77.2% and the evaluation found there were substantial issues with currency, especially in relation to preprints [6]. A study assessing the performance of multiple specialised COVID-19 collections is underway [18].
One limitation of our study is that a sample obtained by the relative recall method might not be representative of the total number of existing studies [11]. Considering the high level of standardisation of systematic reviews it is possible they all cover much the same territory. An evaluation against a sample derived from a manual review of journals and other sources might provide a more reliable estimate [19]. However, this approach may not be suitable in the context of the deluge of scientific information about COVID-19.
Another limitation of our evaluation is the scope of the assessment. We addressed only primary studies and not the other types of scientific articles that are contained in the COVID-19 L·OVE repository, which includes any type of scientific article. Considering the inclusive nature of the methods used to maintain the COVID-19 L·OVE repository, we can expect similar results for the other types of articles, but a formal evaluation would provide a definitive answer.
Our study is not designed to assess the specificity of the repository nor any of the components of the COVID-19 classification platform. We believe the latter has enormous potential to increase the reliability of search processes and to reduce the amount of work involved. However, it is yet to be tested.
Implications
Accessing all the available studies for a particular topic is key to avoiding being misled by research [20]. Unfortunately, substantial time and resources are needed to comprehensively identify all the evidence, as required by rigorous systematic review methods [21,22].
A resource like COVID-19 L·OVE can save everyone a ‘monumental amount of work’ [8]. More importantly, it can speed up access to evidence without sacrificing quality and therefore encourage timely evidence-informed decisions.
The community of researchers producing systematic reviews and other types of evidence synthesis has been overwhelmed by the outpouring of new research [8]. A resource like COVID-19 L·OVE can facilitate the production and update of systematic reviews, and make it possible to sustain living systematic reviews of COVID-19 [23].
Finally, the implications of this project extend beyond COVID-19. The replication of this approach in other areas would significantly improve access to scientific evidence while reducing research waste [24,25].
Data Availability
The datasets used and analysed during the current study or datasets needed to reproduce the results of this study (e.g. a list of included/excluded records) are available from the corresponding author on reasonable request.
REFERENCES




