
Abstract
Invasive coronary angiography is a primary imaging modality that visualizes the lumen area of coronary arteries for the diagnosis of coronary artery diseases and guidance for interventional devices. In the current practice of quantitative coronary analysis (QCA), semi-automatic segmentation tools require labor-intensive and time-consuming manual correction; this limits their application in the catheterization room. For a more automated QCA, it is necessary to minimize operator intervention through robust segmentation methods with improved predictability. In this study, we introduced two selective ensemble methods that integrated the weighted ensemble approach with per-image quality estimation. In our selective ensemble methods, the segmentation outcomes from five base models with different loss functions were ranked by mask morphology or estimated dice similarity coefficient (DSC). The final output was determined by imposing different weights according to the ranking. The ranking criteria based on mask morphology were determined empirically to avoid frequent types of segmentation errors, whereas the estimation of DSCs was performed by comparing the pseudo-ground truth generated from a meta-learner. In the assessment with 7,426 frames from 2,924 patients, the selective ensemble methods improved segmentation performance with DSCs of up to 93.11% and provided a better delineation of lumen boundaries near the coronary lesion with local DSCs of up to 94.04%, outperforming all individual models and hard voting ensembles. The probability of mask disconnection at the most narrowed region could be minimized to <1%. The robustness of the proposed methods was evident in the external validation. Inference time for major vessel segmentation was approximately one-third, indicating that our selective ensemble methods may allow the real-time application of QCA-based diagnostic methods in routine clinical settings.
1 Introduction
Cardiovascular diseases (CVDs) are the most prevalent cause of death worldwide, representing 32.2% of the total mortality; 49.7% of CVD-associated mortalities are coronary artery diseases (CADs) (World Health Organization, 2019). Obstruction of the coronary artery causes the restriction of blood flow to the heart muscle, a condition known as myocardial ischemia. For the revascularization of obstructed vessels, percutaneous coronary intervention with balloon angioplasty and stent implantation is the standard treatment.
Invasive coronary angiography (ICA) is a primary imaging modality that visualizes the lumen area of coronary arteries for the diagnosis of CAD and guidance for interventional devices. Through the delineation of vessel boundaries, quantitative coronary analysis (QCA) provides objective parameters for clinical decisions. Using QCA, Synergy between Percutaneous Coronary Intervention with Taxus and Cardiac Surgery (SYNTAX) scores allow a comprehensive assessment of coronary arteries with multi-vessel disease (Sianos et al., 2005; Thuijs et al., 2019). The functional evaluation of stenosed lesions (Morris et al., 2020; Tu et al., 2014) and the detection of unstable atherosclerotic plaque (Stone et al., 2012; Tomaniak et al., 2020) could be performed with a three-dimensional (3D) reconstruction of coronary geometry through the integration of QCA from multiple views.
In the current practice, QCA is performed by manually correcting the initial mask acquired using semi-automatic edge-detection tools. Due to the anatomical diversity of coronary arteries and imaging artifacts (Blondel et al., 2006), considerable experience is required to accurately perform QCA. Manual corrections could prolong the duration of the interventional procedure. Although various automated methods using image processing techniques have been proposed to mitigate the workload for QCA (Cruz-Aceves et al., 2016; Fazlali et al., 2018; Qin et al., 2019), they have not been adopted in the routine clinical setting due to their prediction accuracy and processing time.
Recent advances in segmentation methods using deep networks have demonstrated the improved predictability of the vessel areas in ICA (Iyer et al., 2021; Jun et al., 2020; Yang et al., 2019). Vessel overlaps, which hinder the accurate identification of coronary arteries, were alleviated with multi-view learning (Zhang et al., 2020). In addition, the coronary lesions could be localized without the direct segmentation of the luminal area (Moon et al., 2021). Nonetheless, images that yield a low segmentation performance from deep learning models require more manual correction compared to the conventional tool using the image processing method (Yang et al., 2019). Considering the real-time application in the catheterization room, it is necessary to minimize serious segmentation errors that require the operator’s intervention.
1.1 Related works
The application of deep learning has considerably improved the ICA segmentation performance (Silva et al., 2021; Zhao et al., 2021; Zhu et al., 2021). Yang et al. (2019) evaluated the segmentation performance for three major vessels using a large database of ICA images and U-Net architecture, exhibiting a dice similarity coefficient (DSC) of 91.7%. Jun et al. (2020) proposed a nested encoder-decoder architecture for ICA images. Iyer et al. (2021) proposed an integration of segmentation architecture with a preprocessing network as the trained filters for boundary sharpening and contrast enhancement of ICA. Real-time segmentation to capture the dynamic motion of coronary arteries could be performed using one-shot video object segmentation (Zhao et al., 2018). Recently, multi-view approaches using ICA sequences have been actively conducted (Liang et al., 2020; Wan et al., 2021; Wang et al., 2020). In a study by Zhang et al. (2020), discriminative information on the ICA images acquired from different projection angles was trained by adopting intra-view hierarchical attentive blocks.
The fundamentals for improving the prediction performance using the ensemble method is the diversity in base classifiers (Brown et al., 2005; Dietterich, 2000). Over the past decades, numerous approaches have been proposed to enhance and quantify the ensemble diversity (Ganaie et al., 2021). Recent ensemble studies for medical imaging achieved a remarkable improvement with multi-view (Sundaresan et al., 2021), various preprocessing (Lyu et al., 2020), and network architecture (Sohail et al., 2021). Neural architecture search (NAS) was also used to optimize the composition of the base classifiers for the ensemble approach (Baldeon Calisto and Lai-Yuen, 2020). For the prediction diversity, the featured loss functions could be applied. For the segmentation of medical imaging, many attempts have been made to improve the performance with a novel loss function suitable for the problem to be solved (Byrne et al., 2021; Caliva et al., 2019; Gerl et al., 2020; EL Jurdi et al., 2021). In particular, in highly imbalanced problems, the incorporation of a regional loss with the auxiliary loss to evaluate the morphological features of predicted masks was shown to augment the predictive capability (Kervadec et al., 2021; Shit et al., 2021).
Determining the optimal method to combine base classifiers is critical to the performance of the final outcomes from ensemble models (Zhou et al., 2002). The most widely used combination rule is naive averaging, which has demonstrated significant improvement in predictive accuracy for the semantic segmentation of medical imaging (Couteaux et al., 2019; Kang and Gwak, 2019; Murugesan et al., 2021; Weisman et al., 2020; Winzeck et al., 2019). Chassagnon et al. (2020) proposed AtlasNet using an ensemble of six convolutional neural networks to evaluate the extent of interstitial lung disease in systemic sclerosis; this showed a comparable performance to that of radiologists. The weight of each classifier can be determined proportionally with regard to the average performance in a validation set, such as accuracy, area under the curve, and DSC (Mondal et al., 2021). Zhai et al. (2020) proposed an ensemble method that imposed different weights to myocardium edema and scars in the aggregation of two-dimensional (2D) and 2.5D magnetic resonance imaging (MRI). The stacking scheme is a generalized form of the weighted averaging. Zheng et al. (2019) proposed a fully convolutional network-based meta-learner that is trained using the outputs of 3D and 2D base-learners.
Estimating the prediction quality of individual segmentation is another way to improve the performance using multiple outcomes. Recently, Hann et al. (2021) proposed a quality control-based framework for the segmentation of cardiac MRI T1 mapping that pick an output estimated to have the highest DSC among single and label-voting models. The DSC estimation was achieved using the DSC association matrix that correlated the final outcome with the DSC value of each model, which was constructed by applying linear regression to the training data.
1.2 Contributions
In this research, we proposed selective ensemble methods that integrated the weighted ensemble approach with per-image quality estimation for the ICA segmentation. The key contributions of our study are as follows:
We proposed two ranking rules to assess the major vessel segmentations from prediction models, which were determined using mask morphology and estimated DSC using meta-learners.
We adopted novel loss functions to employ the diversity of prediction outcomes. The loss functions were carefully tailored to tackle the error patterns frequently seen in previous studies.
We evaluated the performance of deep learning models for ICA segmentation using a database containing 7,426 labeled ICA images acquired from what we know to be the largest number of patients to date and conducted external validation. All of the patients for whom QCA was applied in routine clinical practice were included.
For the practical application of automated QCA, we analyzed the evaluation metrics in the local window near the coronary lesion and performed the major blob analysis. Severe prediction errors that hindered automated QCA were classified by ICA image.
2 Materials and Methods
In this study, we proposed two selective ensemble methods that produced a better prediction of major vessel areas for automated QCA. Both selective ensemble methods comprised 1) obtaining prediction results from segmentation models focusing on different morphological features, 2) ranking the prediction results based on morphological characteristics or estimated DSC, and 3) combining the prediction results with weights that varied according to the ranking (Fig. 1). For the major vessel segmentation in ICA, an integration of U-Net with DenseNet-121 Huang et al. (2017) was applied, and five different loss functions provided diversity in the prediction outcomes (Fig. 1a).

Overview of selective ensemble method using per-image quality estimation (a) Schematic diagram of deep learning approaches. The major vessel areas (marked white) in the predicted mask were evaluated with five different loss functions. (b) Application process of ensemble models using the outputs from five individual models. The hard voting models imposed fixed weights to the individual models (colored boxes). In our selective ensemble models, the predictions were weighted differently for individual images (colored rectangles) according to the ranking. The ranking was determined by morphology and estimated DSC for MSEN and ESEN models, respectively.
2.1 Loss functions
Let x : Ω ⊂ ℝ2; → ℝ be a gray-scale ICA image with 2D spatial domain Ω, and g : Ω → {0, 1} be a binary label mask corresponding to the ground truth: g(p) = 1 if p belongs to the target region G and 0 otherwise. Let s : Ω → [0, 1] be a pixel-wise softmax output of the base segmentation model. The binary mask s∗ corresponding to the prediction s is given as:
 where γ is a threshold and the predicted region is defined as S = {p ∈ Ω | s(p) ≥ γ}.
where γ is a threshold and the predicted region is defined as S = {p ∈ Ω | s(p) ≥ γ}.
2.1.1 Dice loss
DSC is a harmonic mean between the ground truth and predicted mask, defined as:
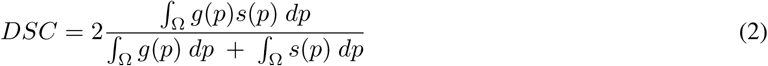 Dice loss LD is defined as 1-DSC, which is commonly used in semantic segmentation.
Dice loss LD is defined as 1-DSC, which is commonly used in semantic segmentation.
2.2.2 Centerline distance loss
Centerline distance loss LCD evaluates the prediction result using the Euclidean distance between the centerlines of the ground truth and predicted masks, as inspired by Acosta et al. (2017). To obtain the centerline, the soft-skeletonization algorithm of Shit et al. (2021) using iterative min-max pooling on binary masks was applied. Given a binary mask of y : Ω → {0, 1}, a recurrent form of soft-skeletonization function can be expressed for n ∈ ℕ as:

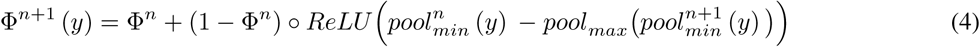 where poolmax and poolmin are shape conservative 3 × 3 max- and min-pooling, respectively, and ○ denotes a Hadamard product. In this study, the maximum iteration of soft-skeletonization was limited to 50 iterations. Accordingly, the binary mask corresponding to the centerline is given as c (y) = F50 (y) and the centerline is defined as C = {p ∈ Ω | c (p) = 1}. A distance map from the centerline C can be defined as:
where poolmax and poolmin are shape conservative 3 × 3 max- and min-pooling, respectively, and ○ denotes a Hadamard product. In this study, the maximum iteration of soft-skeletonization was limited to 50 iterations. Accordingly, the binary mask corresponding to the centerline is given as c (y) = F50 (y) and the centerline is defined as C = {p ∈ Ω | c (p) = 1}. A distance map from the centerline C can be defined as:
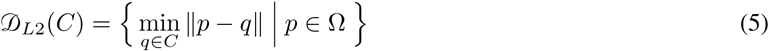 using Euclidean distance transform and modified as:
using Euclidean distance transform and modified as:
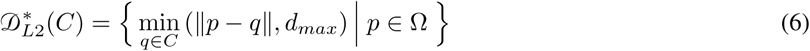 where dmax is a limit of distance to avoid overestimating false positives far from the ground truth. dmax was set as 3. Finally, centerline distance loss is given as:
where dmax is a limit of distance to avoid overestimating false positives far from the ground truth. dmax was set as 3. Finally, centerline distance loss is given as:
 The distance map was precalculated for fast model training.
The distance map was precalculated for fast model training.
2.1.3 Edge distance loss
Edge distance loss LED evaluates the prediction result by the Euclidean distance between the contours of the ground truth ∂G and prediction ∂S, defined as:
 The distance is calculated only outside ∂G to penalize false positives in the prediction S.
The distance is calculated only outside ∂G to penalize false positives in the prediction S.
2.1.4 Centerline length loss
Centerline length loss LCL compares the centerline lengths of the ground truth and predicted mask to estimate prediction errors, defined as:
 LCL is an indirect measure to evaluate the concordance of the predicted skeletons for semantic segmentation.
LCL is an indirect measure to evaluate the concordance of the predicted skeletons for semantic segmentation.
2.1.5 Square dice loss
Square dice loss LSD has a form of replacing the denominator of LD to square terms, defined as:
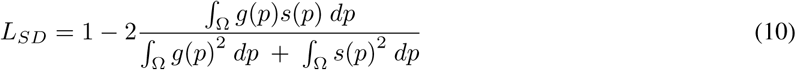
2.1.6 Application of loss functions
LD and LSD were assessed independently, whereas LCD, LED, and LCL as auxiliary terms were applied while being incorporated with LD. To determine the relative weight of auxiliary losses, a parametric test was performed prior to the cross-validation (Table 1). The relative weights of LCD, LED, and LCL with respect to LD were determined as 0.1, 0.2, and 0.1 that maximized the DSC values, respectively. Consequently, a set of loss functions 𝕃 = {LD, LD + 0.1LCD, LD + 0.2LED, LD + 0.1LCL, LSD} was determined. Hereafter, the binary mask of the segmentation model with loss function ℓ ∈ 𝕃 is indicated as 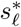 .
.
Impact of auxiliary loss weight (α) on average DSC. Maximum values are presented in bold. LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss.
2.2 Selective ensemble methods
2.2.1 Ranking based on morphology
From the source of errors observed in major vessel segmentation (Yang et al., 2019), two hypotheses were established. The first is that the predictive performance is poor if the vascular mask is disconnected. The second is that if a branching pattern is found in the vascular mask, one of the two branches is an obvious error. From the hypotheses, ranking rules for our morphological selective ensemble (MSEN) method were established: 1) rank in order of the centerline length of the major blob; and 2) move the predicted mask with branching patterns to a lower rank. The centerline C∗ was extracted using the algorithm of Lee et al. (1994) from the python package of scikit-image to avoid errors at the proximal and distal ends of the predicted mask. Branch patterns were detected using the convolution of 3 × 3 kernels with the binary mask c∗ corresponding to C∗ (Ardizzone et al., 2008):
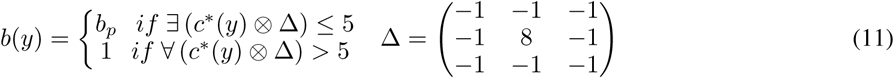 where bp is a branch penalty, which was set as 2. The rank of base model outcomes is determined in the descending order, using a 5 × 5 exchange matrix J:
where bp is a branch penalty, which was set as 2. The rank of base model outcomes is determined in the descending order, using a 5 × 5 exchange matrix J:
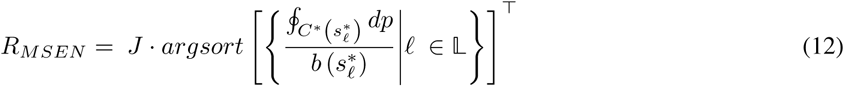
2.2.2 Ranking based on estmiated DSC
The hypothesis for estimated DSC-based selective ensemble (ESEN) was that the pseudo-ground truth from a meta-learner could be used to discriminate a better prediction. By feeding the angiogram and prediction outputs of the validation set, the meta-learner Fmeta combining DeepLabV3+ decoder with EfficientNet-B4 encoder was trained (Fig. 1) with Dice loss. The pseudo ground truth g′ with the same dimension as g is defined as:
 and accordingly, the ranking for ESEN can be expressed as:
and accordingly, the ranking for ESEN can be expressed as:

2.2.3 Ensemble output with ranking
During the inference of selective ensemble methods to an image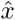 , the corresponding final output
, the corresponding final output 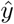 is expressed as:
is expressed as:
 where
where 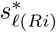 indicates the segmentation output corresponding to the i-th ranking, w is a column vector for ensemble weights, and e is the column vector of ones with the same dimension as w. First, w = (1, 0, 0, 0, 0) was given to select a single mask with the highest rank, which was indicated as ‘Top-1’. Second, the weight set based on the ranking was optimized by grid search in the integer domain of [0, 10], which maximized the average DSC of the image set and was indicated as ‘WO’ (Fig. 1b).
indicates the segmentation output corresponding to the i-th ranking, w is a column vector for ensemble weights, and e is the column vector of ones with the same dimension as w. First, w = (1, 0, 0, 0, 0) was given to select a single mask with the highest rank, which was indicated as ‘Top-1’. Second, the weight set based on the ranking was optimized by grid search in the integer domain of [0, 10], which maximized the average DSC of the image set and was indicated as ‘WO’ (Fig. 1b).
2.2.4 Hard voting
In an ensemble method, in general, the weight of each model is a fixed constant and does not depend on the prediction outcome of individual images. As a control, hard voting was applied for a pixel-wise ensemble (Fig. 1b). The individual models in hard voting were weighted equally (Hard voting WE) or had weights optimized (Hard voting WO). The weight optimization for hard voting was performed using the grid search as applied for the selective ensemble method.
2.3 Quantitative analysis
The segmentation performance was evaluated in two different regions of interest (ROI): the entire image and the local window. The local window was defined as a rectangle of 64 × 64 pixels centered at the minimum lumen diameter of the most narrowed location. If the major vessel had multiple lesions (diameter stenosis >30%), the local window was placed per lesion. To evaluate the performance within the local window, a local DSC was calculated. Considering the imbalance between the vessel area and background, DSC was calculated only for the vessel area.
QCA analysis requires a single mask enclosed by the delineated boundary of the coronary arteries. When the predictive vascular mask consists of multiple blobs, it is not possible to perform QCA analysis without additional image processing to determine whether blobs are placed on the major vessel area and to repair the predicted mask by connecting blobs with an appropriate path. Considering the practical application of deep learning segmentation to automated QCA analysis, further analysis was conducted on the major blob in the same way as the original prediction.
2.4 Training setup
Segmentaton models were trained for 400 epochs at maximum with a min-batch size of 12. Input images of 256 × 256 pixels were normalized by using 2D min/max normalization, and the pre-trained weight from ImageNet was adopted for transfer learning. Data augmentation was performed with rotation (−20° to 20°), translation shift (0 to 10% of the image size) and zoom (0 to 10%). The Adam optimizer with β1 = 0.9 and β2 = 0.999 was applied for training. The learning rate, which was initially set to 10−3, halved up to 10−6 with the patience of 20 epochs, and the early stop criteria was 80 epochs. The training was conducted using TensorFlow on a workstation with Intel i9-7900X, 128GB RAM, and 4 GeForce GTX 1080Ti.
The prediction network for the pseudo-ground truth of the ESEN method was trained with a mini-batch size of 16. The model input was set as five channels of binary labels from segmentation models concatenated with one channel of the corresponding angiogram. The patience for learning rate decay and the early stop criteria was 40 epochs. The rest of the hyperparameters were identical to those of the segmentation models.
For cross-validation, the internal data was divided into five folds according to the exam date. Each fold contained data from almost the same number of patients, preventing the angiograms of a patient from being included in multiple folds. The fold proportion for training, validation, and evaluation datasets were 3:1:1, and the composition was changed through cyclic permutation in sequence.
2.5 Angiography database
2.5.1 Internal dataset
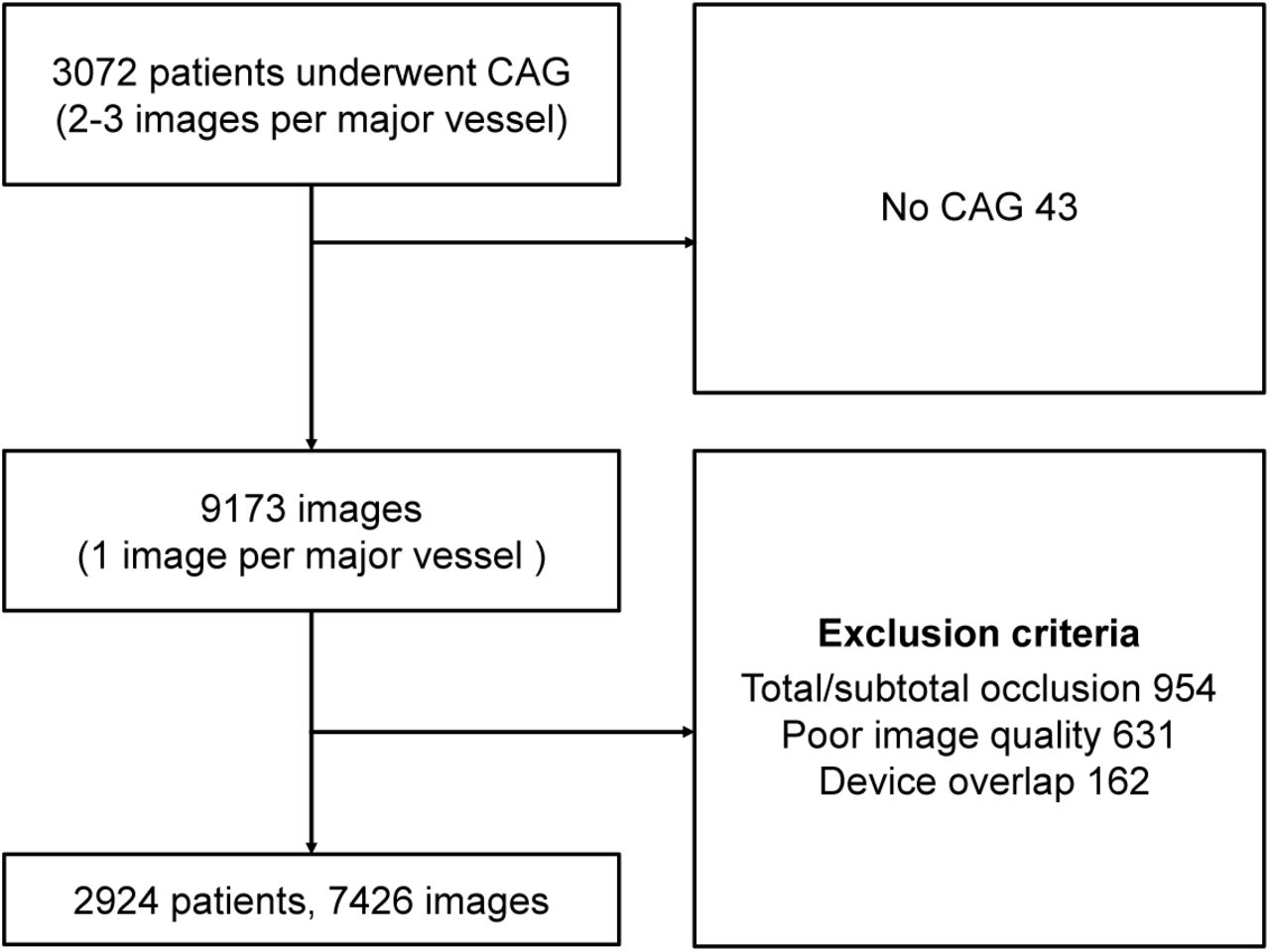
In the present study, 3,309 patients who underwent X-ray coronary angiography in Asan Medical Center from February 2016 to November 2016 were retrospectively enrolled (Fig. 2); the same patients had been enrolled in the previous study for major vessel segmentation (Yang et al., 2019). One angiographic image per major vessel (right coronary artery, RCA; left anterior descending coronary artery, LAD; left circumflex coronary artery, LCX) was selected in the projection angle indicating the lesion morphology (disease vessel with diameter stenosis 30%) or coronary tree structures (normal vessel). Coronary angiograms in which the coronary tree structure was not appropriately recognized, such as chronic total/subtotal occlusion (954 images), poor image quality (incomplete contrast filling, 210; diminutive vessels, 60; blurred images, 88; and severe vessel overlap, 273) and severe overlap with medical device (162 images), were excluded. Finally, a total of 7,426 angiograms from 2,924 patients were included in the internal dataset. With the inclusion of the cases excluded from the previous study (Yang et al., 2019), such as normal and stented vessels, the number of images increased to more than double. The baseline characteristics of the coronary arteries are summarized in Table 2.
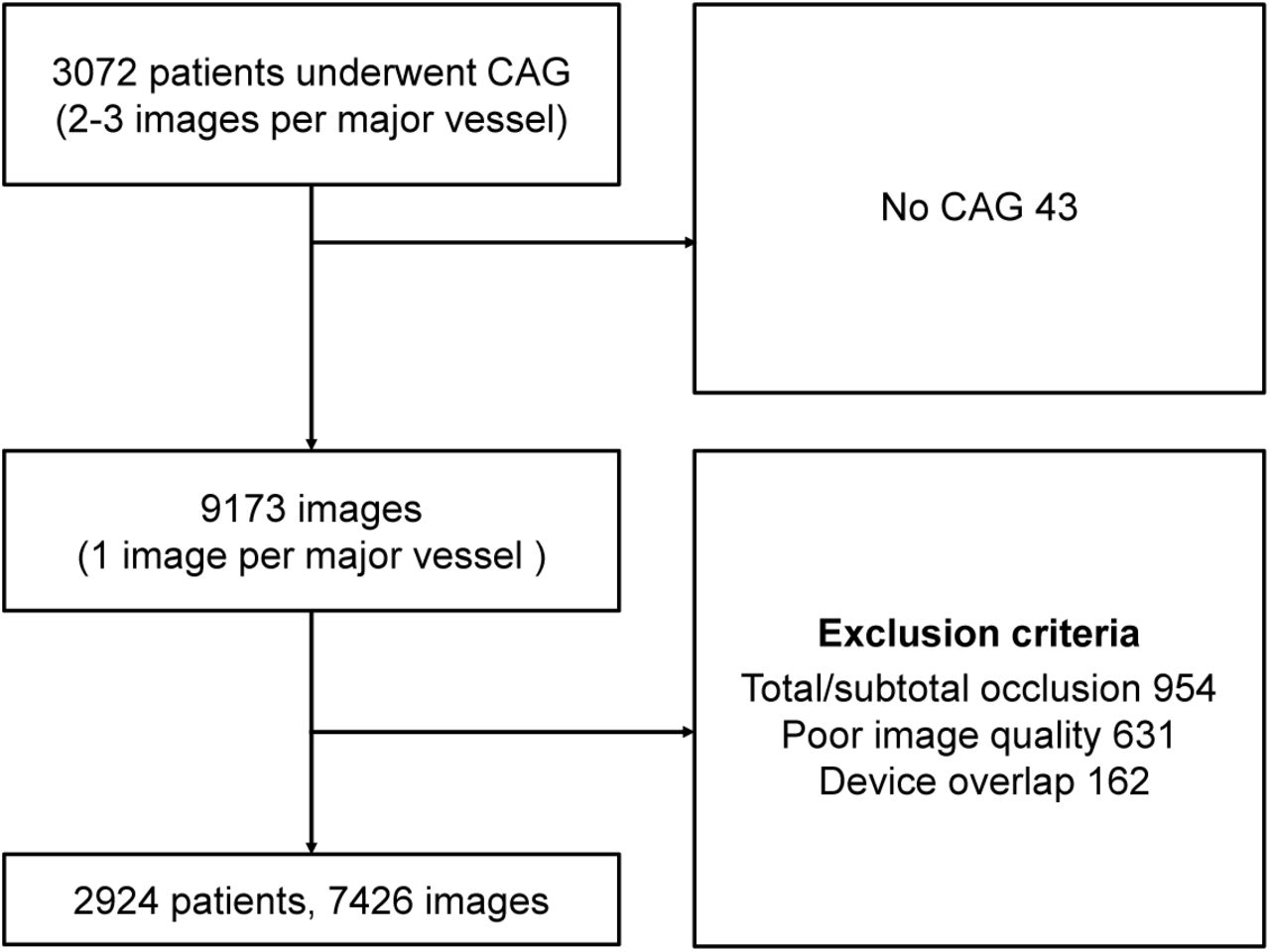
Patient enrollment criteria. After excluding invasive coronary angiography (ICA) in which the coronary tree structure was not appropriately recognized, 7,426 images of 2,924 patients were ultimately included in the present study.
Angiography statistics. N, number of patients; n, number of images; QCA, quantitative coronary angiography.
2.5.2 External dataset
The deep learning models trained with the internal dataset were further assessed using the external dataset. The external dataset consisted of 556 images of 226 patients who visited Chungnam National University Hospital from February 2016 to November 2016. The protocol for the enrollment and exclusion of angiographic images was the same as that for the internal dataset.
2.5.3 Labeling process
For the labeling process, angiograms in DICOM file format were anonymized by removing patient-identifiable information with the dedicated tool provided by the Big Data Research Center of Asan Medical Center. Using CAAS Workstation 7.5 (Pie Medical Imaging BV, Maastricht, Netherlands), three expert radiographers with more than 10 years of experience each annotated the major vessel areas. Each label was generated on the image frame at enddiastole by a semi-automatic edge-detection tool. The vessel area was then manually corrected. The target area of major vessel segmentation was set as the region from the ostium to the far distal location. Pixel information of the major vessel area was extracted using a customized Python script.
This study complies with the Declaration of Helsinki. Research approval was granted by the Institutional Review Board of Asan Medical Center and Chungnam National University Hospital. The requirement for informed consent from the patients was waived.
2.6 Statistical analysis
Continuous variables are presented as mean ś standard deviation (SD), and categorical variables are presented as numbers and percentages. Linear regression analysis was performed to estimate the relationship of the maximum difference in DSCs with the average DSC from the individual models. The Wilcoxon rank sum test (Mann-Whitney U test) was conducted to compare the segmentation performance between pairwise ranking in MSEN and ESEN. p values <0.05 were considered statistically significant, and the normality of data was tested with the Shapiro-Wilk W-test (p>0.05). All of the statistical analyses were performed using SPSS, Version 17.0 for Windows (IBM Corp., Armonk, NY, USA).
3 Results
3.1 Segmentation performance of individual models
The segmentation models exhibited a minor difference <0.11% except for the combination of Dice and Centerline length losses (LD + 0.1LCL) with a relatively low DSC (Table 3). However, the segmentation outputs demonstrated different morphological responses to the loss functions (Fig. 3). The segmentation model, which provided an accurate prediction of major vessel areas, differed from image to image, and the DSC that could be achieved varied depending on the model applied. The maximum differences in DSCs between individual models were greater for images with a lower mean DSC (y = −0.593 x + 0.591, R2 = 0.340 in Fig. 4a). The probabilities of individual models that performed best for images with a mean DSC <90% showed little deviation (15.74% –21.83% in Fig. 4b).
Average DSCs (%) of individual and ensemble models from internal dataset. Highest scores along the column are highlighted in bold. LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss; WE, weighted equally; WO weight optimized.

Representative examples of major vessel segmentation from 5 individual models. In the third to seventh columns, the predicted major vessel areas compared to the ground truth (second column) are indicated in red (true positive), yellow (false negative), and green (false positive). The DSC for each model is shown in the upper right corner. Orange arrows in the second column indicate coronary lesions. LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss

Performance analysis in relation to DSC variances. (a) Scatter plot for the difference between the maximum and minimum DSCs versus Mean DSC. Symbol indicates the segmentation model with the highest DSC. (b) The difference between the maximum and minimum DSCs is plotted as a histogram for images with mean DSC of less than 90% for five individual models. The color indicates the segmentation model with the highest DSC. DSC, dice similarity coefficient; LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss.
3.2 Ranking for selective ensemble methods and weight optimization
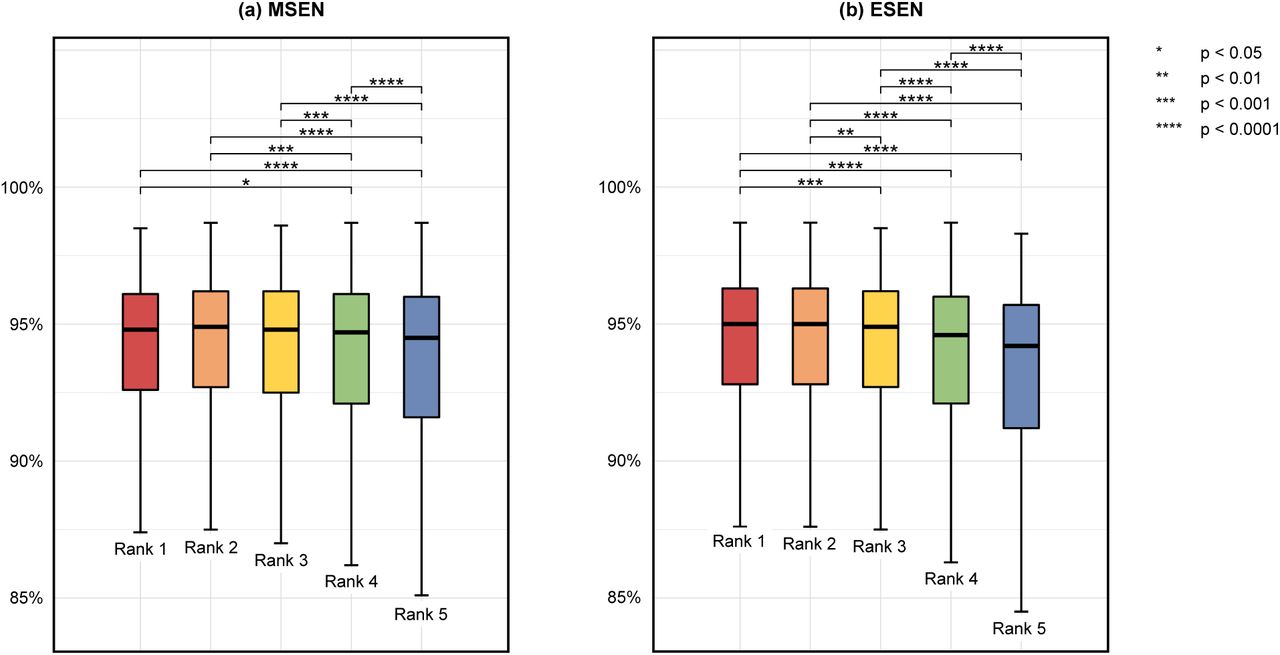
The ranking of the MSEN and ESEN methods successfully distinguished better outcomes among the outputs from individual models (Fig. 5). In the MSEN method, images in the top three ranks had statistically higher DSCs than did lower-rank images. In the ESEN method, the pseudo-ground truth from the meta-learner showed a slight improvement in average DSC (92.58% ± 7.39%) but successfully discriminated better predictions. That is, the higher the ranking, the better the segmentation performance, except for the 1st versus 2nd ranks. Therefore, in MSEN WO and ESENWO models, images with higher ranking had greater weights of (4, 3, 3, 2, 2) and (2, 2, 2, 1, 1), respectively. Meanwhile, the optimized weight in the Hard voting WO model was (3, 2, 2, 3, 4) for the loss function ℓ ∈ 𝕃.

Comparison of DSCs according to the ranking determined by (a) MSEN and (b) ESEN methods. DSC, dice similarity coefficient; MSEN, morphological selective ensemble; ESEN, estimated dice similarity coefficient-based selective ensemble.
3.3 Segmentation performance of selective ensemble models
All of the analyzed selective ensemble models improved the average DSCs compared to the individual models (Table 3). The ESEN WO model produced the best DSC of 93.11% ± 7.61%, followed by the MSEN WO and Hard voting WO models. Near the most narrowed region of the major vessel, the ESEN WO model also had the best performance (local DSC = 94.04% ± 11.59%). The improvement of DSC achieved by selective ensemble models was greater in the local window (0.31% –1.18%) than in the entire image (0.02% –0.99%).
Even when disconnection occurred in the majority of individual models, selective ensemble models provided an accurate prediction for major vessel areas (Fig. 6a). Although MSEN Top-1 successfully selected an outcome with better connectivity near the lesion (Fig. 6b), the ranking of the MSEN method was susceptible to false positives in the longitudinal direction of major vessels (Fig. 6c). Compared to the MSEN WO models, the ESEN WO model, which gave greater weights to images with relatively higher ranking, produced better results by combining poor prediction regions (Fig. 6d).

Representative examples for comparison of individual and ensemble models. The predicted major vessel areas compared to the ground truth are indicated in red (true positive), yellow (false negative), and green (false positive). The DSC for each model is shown in the upper right corner. The ranking in MSEN and ESEN methods are presented in the lower right corner. The orange box in the input image indicates the local window near the most narrowed region. DSC, dice similarity coefficient; ESEN, estimated dice similarity coefficient-based selective ensemble; MSEN, morphological selective ensemble; LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss; WE, weighted equally; WO weight optimized.
3.4 Major blob analysis
Since the disconnected blobs were likely to be distributed on the major vessel area, their removal resulted in the DSC decrease (Table 3). For individual models, the DSC reduction was more conspicuous in the local window (0.79% –0.87%) compared to the entire image (0.42% –0.56%). Selective ensemble models were less affected by disconnected blob exclusion than were the individual and hard voting models. The MSEN Top-1 model minimized the difference in DSCs between the original prediction and major blob (−0.11% for the entire image; -0.21% for the local window), indicating fewer occurrences of mask disconnection. For the major blob in the local window, MSEN models outperformed other segmentation models.
3.5 Cumulative histogram
With a selective ensemble model, the proportion of images exhibiting DSC >90% was more than 86.43% in the original prediction, whereas the highest among the individual models was 85.01% with LD + 0.1LCD (Table 4 and Fig. 7). In the local window, all of the selective ensemble models were more likely to have DSC >90% than the hard voting models, and their difference was maximum for the major blob in the local window (90.39% for MSEN Top-1 vs. 88.84% for Hard voting WE).
Average DSCs (%) of individual and ensemble models from internal dataset. Highest scores along the column are highlighted in bold. LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss; WE, weighted equally; WO weight optimized.

Cumulative histograms of DSCs. The maximum proportions of images with DSCs > 80% and % are indicated with circles and arrows. DSC, dice similarity coefficient; ESEN, estimated dice similarity coefficient-based selective ensemble; MSEN, morphological selective ensemble; LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss; WE, weighted equally; WO weight optimized.
3.6 Error analysis
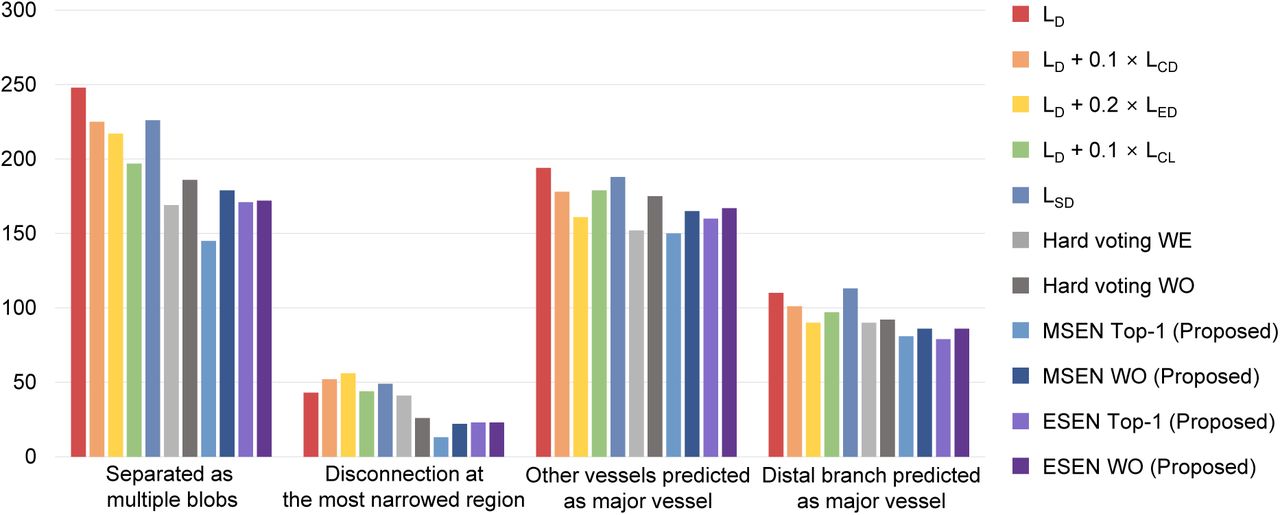
Selective ensemble models reduced the segmentation errors of mask disconnection compared to the individual models (Fig. 8). With the MSEN Top-1 model, the mask disconnection was reduced to less than three-fifths of the predictive model with LD, and the discontinuity at the most narrowed region occurred in <1% of the tested images (13/1457). Among the individual models, the loss function of LD + 0.1LCL used to evaluate the centerline length showed better connectivity. Misidentification error slightly improved in the ensemble models.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Error analysis of segmentation models for each error type. Two types of segmentation errors, disconnection and misidentification, were classified in a fold of the internal dataset (1,457 images). MSEN, morphological selective ensemble; LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss; WE, weighted equally; WO weight optimized.
3.7 External validation
In the external dataset, the combination of Dice and Centerline length losses (LD + 0.1LCL) performed better than other individual models did, except for the original prediction of the entire image in which LSD had the highest DSC (Table 5). The MSEN and ESEN models, as in the internal dataset, enhanced predictive capabilities in all of the ROIs. The benefits of selective ensemble models were apparent in the local window. In the major blob analysis of the local window, MSEN Top-1 models improved the DSC by more than 1.23% (vs. hard voting models) and by more than 2.08% (vs. individual models).
Average DSCs (%) of individual and ensemble models from external dataset. Highest scores along the column are highlighted in bold. LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss; WE, weighted equally; WO weight optimized.
4 Discussion and conclusion
In the present study, we proposed two selective ensemble methods in which the weights on prediction outcomes were imposed differently to individual images rather than fixed according to the average performance of individual models. The selective ensemble methods improved the segmentation performance, with DSCs of up to 93.11% in the entire image, and enabled a more accurate delineation of the coronary lesion. Here, a DSC >90% was achieved by 87.72% of the image dataset, and the probability of mask disconnection at the most narrowed region could be minimized to <1%. For the external dataset with different image characteristics, although the superiority between the average performance of individual models was changed, the MSEN and ESEN methods exhibited less performance degradation.
Our selective ensemble models demonstrated an accurate prediction of the major vessel in coronary angiography. Compared to previous studies for major vessel segmentation (Jun et al., 2020; Yang et al., 2019), the average DSC was increased by more than 1.41%. The proportion of images with DSC <90% was also reduced to about two-thirds (Yang et al., 2019). The previous studies used a single segmentation model trained using a smaller dataset (44.5% –63.3% of our database). Yang et al. (2019) achieved a DSC of 91.7% for only diseased coronary vessels. Unlike previous studies (Jun et al., 2020; Yang et al., 2019), the inclusion of the left main coronary artery into the label, where vessel overlap occurs frequently, allowed the detection of the ostium lesions of LAD and LCX. DSCs >90% for the external dataset indicated greater applicability for general use. Recently updated deep learning studies for the segmentation of the entire coronary tree exhibited DSCs of 86.4% –88% using a dataset of <1,000 patients (Iyer et al., 2021; Zhao et al., 2018). Despite the detailed capture of vascular structures, entire vessel segmentation could suffer from small branches (Wang et al., 2020). Because the segmentation criteria and the database may vary between studies (Iyer et al., 2021; Wang et al., 2020; Zhao et al., 2018), the interpretation of evaluation metrics should be made with careful consideration.
The MSEN method was inspired by clinical intuition with observation. Human anatomy in medical imaging has a set form, and medical experts could recognize deficiencies in the prediction by observing the segmentation outputs. In major vessel segmentation, the simple rule of the predicted mask should be not disconnected and branched worked well as an evaluation criterion for ranking. Instead of this empirical approach, anomaly detection (Liu et al., 2019; Sandfort et al., 2021; Schlegl et al., 2017; Xia et al., 2020) would be helpful in discriminating plausible candidates for the ensemble. In the post-processing stage, the morphology-based ranking could be corrected through quantitative analysis or allometric laws governing coronary anatomy (Huo and Kassab, 2009). For other organs in medical imaging, registration with the reference atlas that has been used for the segmentation of medical imaging (Išgum et al., 2009; Lorenzo-Valdés et al., 2002) could be employed for evaluation.
The ESEN method involved the meta-learner that was trained using prediction results from individual modes as an input. Unlike the previous studies in which the meta-learner’s outcome was determined as the final output (Zheng et al., 2019), the ESEN method used it as a pseudo-ground truth for quality control. In our application of the ESEN method, the performance of the individual prediction selected based on the pseudo-ground truth was better than the pseudo-ground truth. Although the pseudo-ground truth predicted a mask close to the ground truth, it also partly included minor predictions that were likely false positives. Therefore, it was not practical to select the pseudo-ground truth as the final output. Although both methods premised that the average prediction performance was sufficiently high, the ESEN method differed in that the ranking criterion using the pseudo-ground truth was affected by individual predictions. This method could be more susceptible to different image characteristics at the deployment stage, as shown in the local window analysis of external validation.
Recent developments in automated segmentation methods for ICA images could lead to changes in the clinical activity of coronary intervention. First, real-time analysis in the catheterization room could help guide and optimize the stent selection and implantation process beyond error-prone visual assessment (Shah et al., 2017). Automatic lesion detection integrated with segment identification (Zhai et al., 2019) would facilitate the diagnosis of multivessel disease with the calculation of the SYNTAX score (Cavalcante et al., 2017). Machine learning applications using lesion morphology for the prediction of fractional flow reserve could be accelerated (Cho et al., 2019). In applying computational fluid dynamics to 3D QCA, the bottleneck of geometric reconstruction could be tackled to estimate functional diagnostic values (Asano et al., 2019; Ono et al., 2021) and plaque vulnerability (Kweon et al., 2018; Wu et al., 2020). The time required to apply selective ensemble methods (0.36 s in Table 6) would not delay the clinical practice considering the overall duration of the coronary intervention (approximately 30 mins), facilitating the novel techniques using coronary angiography.
Computational cost to apply ensemble models. MSEN, Morphological selective ensemble; ESEN, Estimated dice similarity coefficient-based selective ensemble; LD, Dice loss; LCD, Centerline distance loss; LED, Edge distance loss; LCL, Centerline length loss; LSD, Square dice loss.
For the development of fully automated QCA, our approach had some aspects that need to be improved on. Although the proportion of major vessels in coronary lesions was dominant (Halon et al., 1983), side branch analysis is necessary to understand the coronary physiology and evaluate the bifurcation lesion. Analysis across angiographic sequences is necessary for adequate frame selection and more comprehensive interpretation. Since the performance of selective ensemble methods was bound to the best scores of individual models (Tables 3 and 5), an optimal combination of improved individual models is a prerequisite for a better performance of the selective ensemble models. In addition, to assess the performance robustness of our segmentation models, further validation studies should be conducted for the diversity of angiography characteristics. In summary, we proposed selective ensemble methods that ranked the prediction results obtained from multiple segmentation models and imposed greater weights to images with higher rankings. The evaluation criteria for ranking, morphology, and estimated DSC of predicted masks were applied. In the MSEN method, the ranking criteria were empirically determined to avoid the frequent types of segmentation errors. In the ESEN method, a deep neural network was introduced as a meta-learner for the generation of pseudo-ground truth. The selective ensemble methods improved the segmentation performance in the entire image area and provided better delineation around the lesion. Therefore, by enabling more automated QCAs to minimize the clinicians intervention, our selective ensemble methods may allow the real-time application of QCA-based diagnostic methods in routine clinical settings.
Data Availability
The datasets generated and/or analyzed during the current study are not publicly available because the permission of sharing patient data was not granted by the Institutional Review Board but are available from the corresponding author on reasonable request.
Competing interests statement
The authors declare no conflict of interest.
Author Contributions
Jeeone Park: Methodology, Software, Validation, Writing - Original Draft Jihoon Kweon: Conceptualization, Writing - Original Draft, Supervision, Funding acquisition Hyehyeon Bark: Methodology, Software Young In Kim, Inwook Back, Jihye Chae: Formal analysis Jae-Hyung Roh, Do-Yoon Kang, Pil Hyung Lee, Jung-Min Ahn, Soo-Jin Kang, Duk-Woo Park, Seung-Whan Lee, Cheol Whan Lee, Seong-Wook Park, Seung-Jung Park: Resources, Writing - Review & Editing Young-Hak Kim: Writing - Review & Editing, Supervision
Acknowledgements
This material was supported by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. 2020-0-00159), and by the Korea Medical Device Development Fund grant funded by the Korea government (the Ministry of Science & ICT, the Ministry of Trade, Industry & Energy, the Ministry of Health & Welfare, the Ministry of Food and Drug Safety) (Project Number: KMDF_PR_20200901_0013).
References



