
ABSTRACT
Objective While there exist numerous methods to predict binary phenotypes using electronic health record (EHR) data, few exist for prediction of phenotype event times, or equivalently phenotype state progression. Estimating such quantities could enable more powerful use of EHR data for temporal analyses such as survival and disease progression. We propose Semi-supervised Adaptive Markov Gaussian Embedding Process (SAMGEP), a semi-supervised machine learning algorithm to predict phenotype event times using EHR data.
Methods SAMGEP broadly consists of four steps: (i) assemble time-evolving EHR features predictive of the target phenotype event, (ii) optimize weights for combining raw features and feature embeddings into dense patient-timepoint embeddings, (iii) fit supervised and semi-supervised Markov Gaussian Process models to this embedding progression to predict marginal phenotype probabilities at each timepoint, and (iv) take a weighted average of these supervised and semi-supervised predictions. SAMGEP models latent phenotype states as a binary Markov process, conditional on which patient-timepoint embeddings are assumed to follow a Gaussian Process.
Results SAMGEP achieves significantly improved AUCs and F1 scores relative to common machine learning approaches in both simulations and a real-world task using EHR data to predict multiple sclerosis relapse. It is particularly adept at predicting a patient’s longitudinal phenotype course, which can be used to estimate population-level cumulative probability and count process estimators. Reassuringly, it is robust to a variety of generative model parameters.
Discussion SAMGEP’s event time predictions can be used to estimate accurate phenotype progression curves for use in downstream temporal analyses, such as a survival study for comparative effectiveness research.
INTRODUCTION
Electronic Health Record (EHR) data collected during the routine delivery of care have in recent years enabled countless opportunities for translational and clinical research.[1–3] Comprising freeform clinical notes, lab results, prescriptions, and various codified features including International Classification of Diseases (ICD) and Current Procedural Terminology (CPT) billing codes, EHR data encode rich information for research. However, a major limitation of EHR data is the lack of precise information on disease phenotypes. Phenotype surrogate features such as ICD diagnosis codes often exhibit dismal specificity that can bias or de-power the downstream study.[4,5] Meanwhile, manual annotation of phenotypes via chart review is laborious and unscalable. These limitations become even more pronounced when the object of interest is the timing of clinical events – or equivalently, how clinical status changes over time – which is important for evaluating disease progression. Surrogates of event time derived from EHR codes often exhibit systematic biases, and multiple features may be needed to accurately predict how a phenotype progresses over time.[6-8]
For binary phenotypes, researchers have proposed a variety of unsupervised and semi-supervised methods requiring few-to-no manually-annotated “gold-standard” labels.[9-20] However, very few such methods exist to predict phenotype event times. Chubak et al. developed a rule-based algorithm for breast cancer recurrence that 1) classifies a patient’s overall recurrence status, and 2) for recurrence-positive patients, takes the earliest encounter time of one or more expert-specified codes as the predicted recurrence time.[8] Hassett et al. proposed a similar algorithm averaging the peak times of the pre-specified codes rather than taking the first observed instance.[7] Uno et al. expanded on this by using points of maximal increase in lieu of peak values, and adjusting for systematic temporal biases between the timings of codes and the target phenotype.[6] While these approaches achieve notable performance, they are limited by their 1) reliance on domain expertise to identify predictive codes, 2) inability to utilize more than a handful of codes, and 3) sensitivity to sparsity, a common characteristic of EHR data.
Using more sophisticated machine learning methods to predict phenotype event times can potentially address these limitations. Traditional supervised learning methods such as logistic regression, random forest, and naive Bayes are suboptimal for modeling longitudinal processes as they cannot account for intertemporal associations in both outcomes and features. Recurrent neural networks (RNNs), which are designed for sequence data and well-conditioned to high feature dimensions, have enjoyed particularly widespread application to prediction using EHR data.[21-25] However, these models require large numbers of training labels to achieve stable performance, which is not feasible for phenotypes necessitating manual labeling. Consequently, existing applications of RNNs to EHR-based prediction all use readily available outcome measures such as discharge billing codes, limiting application to phenotypes with reliable codified proxies. In addition, these models are not intuitively interpretable.
On the other end of the spectrum, researchers have developed unsupervised computational models of chronic disease progression that do not require any gold-standard labels. Many of these approaches employ Hidden Markov Models (HMMs) in which latent states represent progressive stages of disease. For instance, Jackson et al. apply a multistage discrete HMM to aneurysm screening, Sukkar et al. apply one to Alzheimer’s disease, and Wang et al. apply a continuous HMM to progression of chronic obstructive pulmonary disease (COPD).[26-29] While these unsupervised models produce promising computational models of disease progression, they may learn latent disease stages that are not clinically relevant.
Using machine learning to predict pre-defined (i.e. not computational) phenotype state progression from EHR data remains a relatively untrodden problem. We draw inspiration from a handful of studies outside the EHR community that use longitudinal physiological measurements to predict sleep state – a binary time series outcome akin to clinical events such as relapse or flare.[30-33] Of particular note, Gao et al. fit a mixed effects logistic regression model to predict sleep state, achieving significantly higher accuracy than naive logistic regression, random forest, or other time-agnostic methods at the expense of requiring a large number of sleep state labels.[30] To efficiently leverage a small number (∼50-100) of labeled and large number of unlabeled longitudinal EHR data to predict the progression of a binary phenotype state, we propose in this paper the Semi-supervised Adaptive Markov Gaussian Embedding Process (SAMGEP) method. Unlike existing event time prediction algorithms, SAMGEP can leverage hundreds of features rather than a handful of surrogates by combining sparse EHR features and their embeddings into dense patient-timepoint embeddings via a novel weighting procedure. It then models the target phenotype state using a Hidden Markov Model with the patient-timepoint embedding progression as a Gaussian Process emission, combining aspects of existing methods to jointly model the evolution of a patient’s phenotype state and EHR feature set over time. SAMGEP enables more powerful application of EHR data to temporal analyses such as survival or disease progression.
METHODS
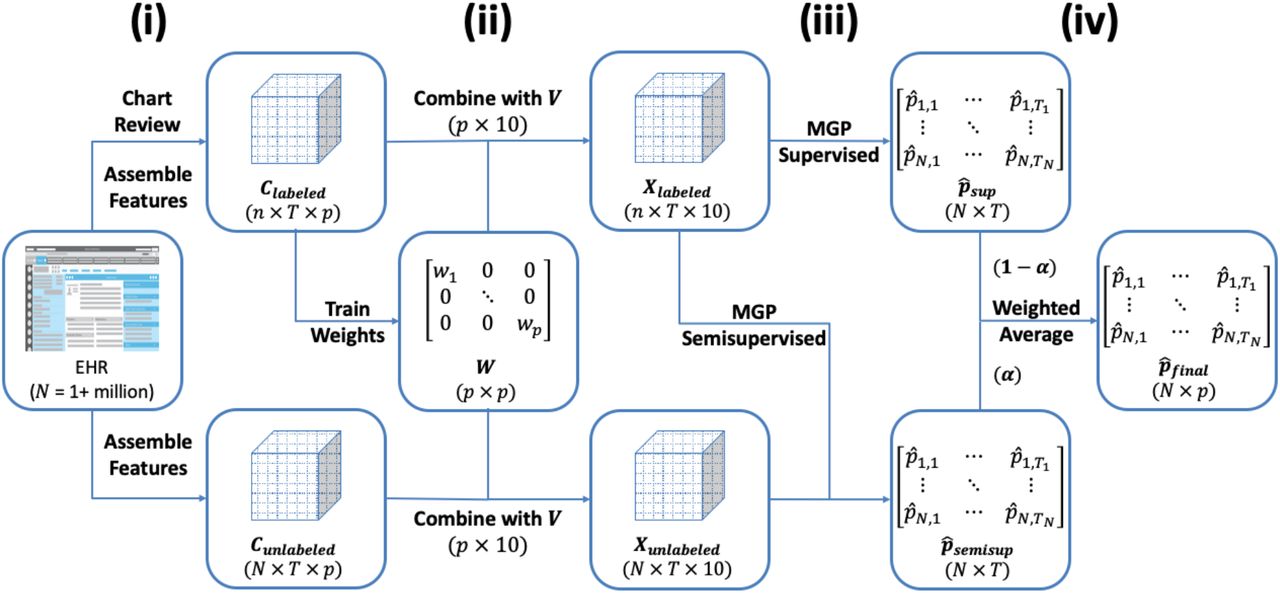
The SAMGEP algorithm broadly consists of four steps: (i) assemble time-evolving EHR features predictive of the target phenotype event, (ii) optimize weights for combining raw features and feature embeddings into dense patient-timepoint embeddings, (iii) fit supervised and semi-supervised Markov Gaussian Process (MGP) models to this embedding progression to predict marginal phenotype probabilities at each timepoint, and (iv) take a weighted average of these semi-supervised and supervised predictions with weights determined adaptively to optimize prediction performance. Figure 1 illustrates the overarching SAMGEP procedure.
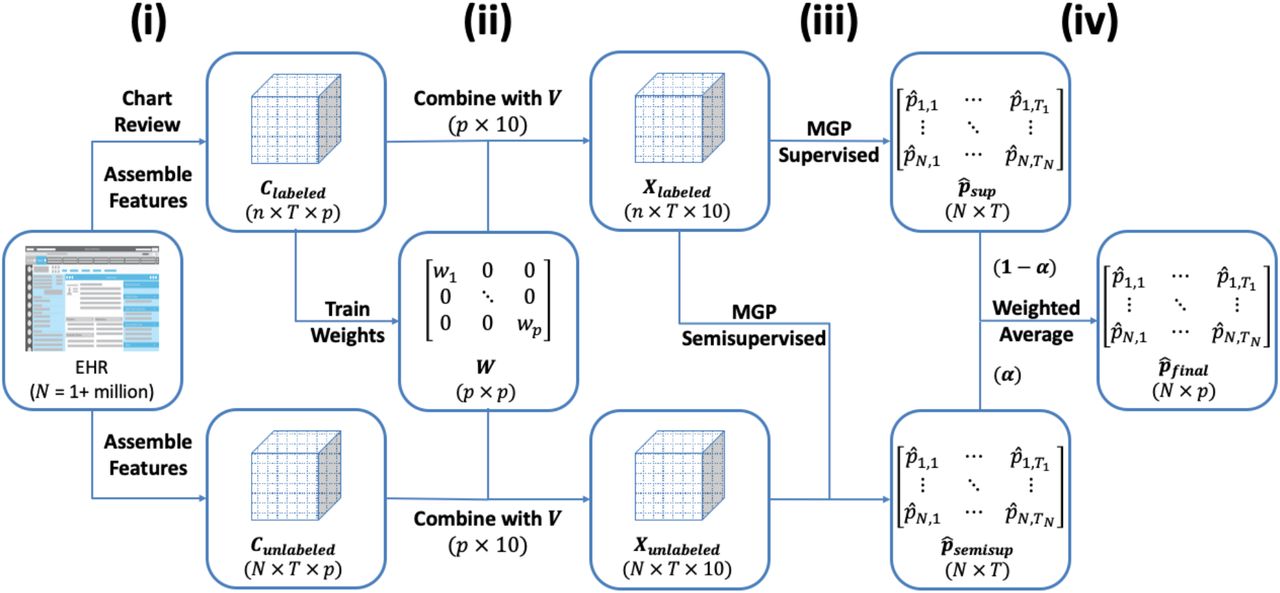
Schematic of the overall SAMGEP algorithm.
Assembling Predictive Features
Candidate features include log-transformed counts of ICD diagnosis codes or coarser “phenotype” codes (PheCodes), RxNorm drug codes, CPT procedure codes, lab tests, and NLP-curated mentions of relevant concept unique identifiers (CUIs) in a patient’s chart during a given time period. Features can be selected manually or identified automatically via label-free methods such as the surrogate-assisted feature extraction (SAFE) method.[34] In this study, time periods are defined as consecutive non-overlapping 1-month periods starting at the patient’s first PheCode for the target phenotype. Figure 2 depicts the form of raw EHR feature data. Since SAMGEP employs sparse feature weighting to select informative features, it is preferable to aim for inclusivity when assembling features.
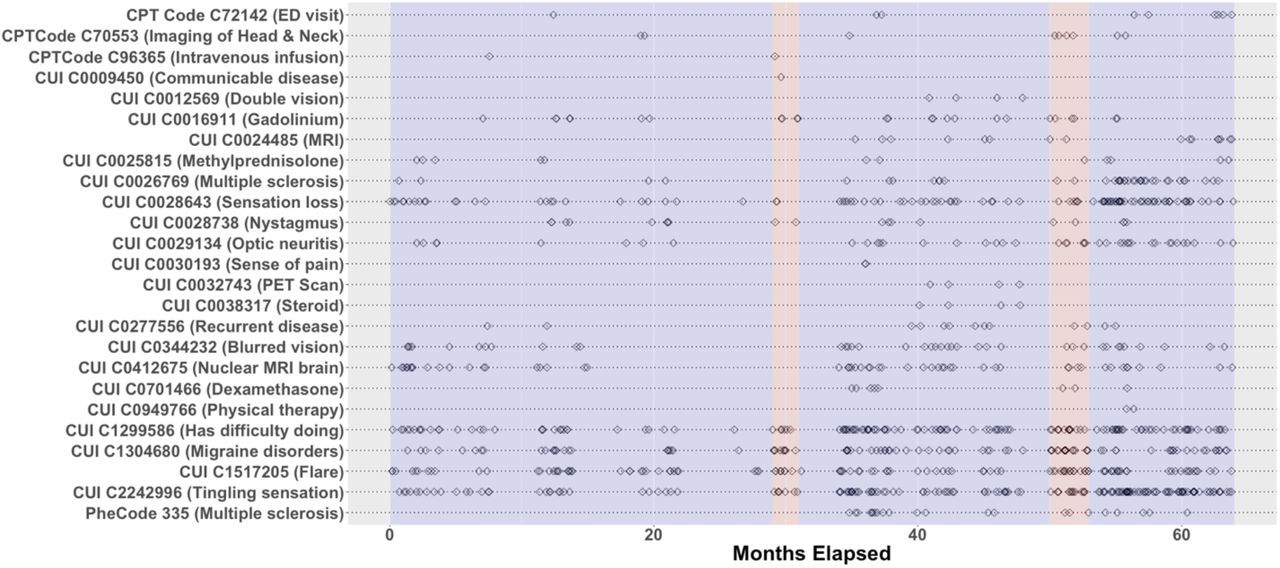
Depiction of the sparsity and temporal irregularity of EHR data. In this study we aim to predict MS relapse event times (red bands) using timestamped EHR feature observations (black diamonds).
Henceforth we let Vm×p denote the matrix of m-dimensional embedding vectors of p features. We use i, j, and t to index patients, raw features, and timepoints respectively, and we assume there are a total of N patients, and T(i) timepoints in our dataset. Let Ci,t denote the p-dimensional feature vector for patient i at timepoint t, and Yi,t ∈ {0,1} denote the phenotype state for patient i at timepoint t. Moreover, let 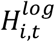 denote patient i’s log mean visit count during time period t – a measure of healthcare utilization. Finally, we once again assume that we have a limited set of n phenotype-labeled patients and a much larger set of N − n unlabeled ones.
denote patient i’s log mean visit count during time period t – a measure of healthcare utilization. Finally, we once again assume that we have a limited set of n phenotype-labeled patients and a much larger set of N − n unlabeled ones.
Producing Patient-Timepoint Embeddings
We compute patient-timepoint embeddings, denoted by Xi,t, as a weighted sum over feature embedding vectors:
 where Ci,t represents the feature log count vector for patient i at timepoint t, W is the p × p diagonal matrix with feature weights on the diagonal, Ti is the total number of timepoints for patient i, N is the total sample size, and Vm×p is the matrix of p m-dimensional embedding vectors. See the Supplementary Materials for details on how feature embeddings are generated. We choose W via L1-regularized linear discriminant analysis minimizing:
where Ci,t represents the feature log count vector for patient i at timepoint t, W is the p × p diagonal matrix with feature weights on the diagonal, Ti is the total number of timepoints for patient i, N is the total sample size, and Vm×p is the matrix of p m-dimensional embedding vectors. See the Supplementary Materials for details on how feature embeddings are generated. We choose W via L1-regularized linear discriminant analysis minimizing:
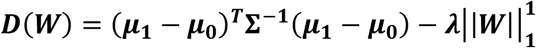 Where
Where
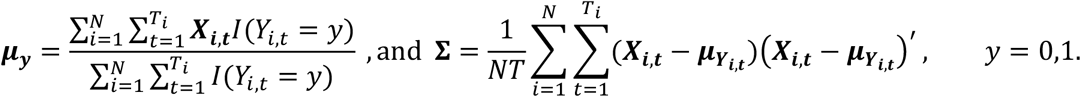 The L1-term imposes sparsity, driving the weights for empirically uninformative features to zero. We optimize W using projected gradient ascent with the constraint W1,1 = 1 to enable identifiability, where without loss of generality we assume that the first feature is a known highly predictive feature. The step-size at each iteration of ascent is chosen by line search. We optimize the regularization hyperparameter λ using 10-fold cross-validation within the labeled set.
The L1-term imposes sparsity, driving the weights for empirically uninformative features to zero. We optimize W using projected gradient ascent with the constraint W1,1 = 1 to enable identifiability, where without loss of generality we assume that the first feature is a known highly predictive feature. The step-size at each iteration of ascent is chosen by line search. We optimize the regularization hyperparameter λ using 10-fold cross-validation within the labeled set.
Fitting Markov Gaussian Process
Markov Gaussian Process (MGP) is a generative mixture-like model that combines two key assumptions: 1) Yi,1,…, Yi,T(i) follows a discrete time markov process, and 2) the patient embedding vectors over time Xi,1,…, Xi,T(i) | Yi,1,…, Yi,T(i) follow a Gaussian Process. This generative framework primes SAMGEP for the semi-supervised setting in which we have a large amount of EHR data of which only a limited subset has the longitudinal outcome {Yi,1,…, Yi,T(i)} labeled.
Discrete Time Markov Process Assumption
We assume a markov process model for Yi,1,…, Yi,T(i) conditional on healthcare utilization Hi such that P(Yi,t = y|Yi,1,…, Yi,t−1, Hi) = P(Yi,t = y|Yi,t−1, Hi), where Hi is obtained as the log-count of all encounters throughout a patient’s record. This model can be alternatively specified by two rules:
 where {πinit, πt(yt−1), t > 1} are unknown transition probabilities that fully specify the markov model. We further assume that for some λmarkov = {λinit, λ0, λ1, λ2, λ3, λH 0, λH},
where {πinit, πt(yt−1), t > 1} are unknown transition probabilities that fully specify the markov model. We further assume that for some λmarkov = {λinit, λ0, λ1, λ2, λ3, λH 0, λH},
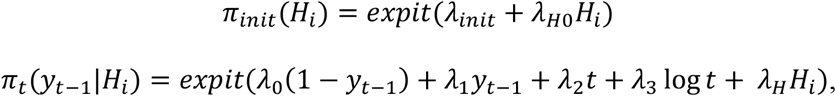 Here we include both linear and log-linear effects for time on πt(yt−1|Hi) to better capture how event risk may change over time without overfitting.
Here we include both linear and log-linear effects for time on πt(yt−1|Hi) to better capture how event risk may change over time without overfitting.
Gaussian Process Assumption
A Gaussian process is a stochastic process wherein any finite collection of observations follows a multivariate normal distribution. Here, we assume that the patient embeddings over time follow a Gaussian process:
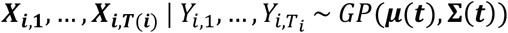 We further specify the mean and covariance functions μ(t) and Σ(t) respectively. For some θGP = {μ0, μ1, μH, μYH, μ2, μ3, σk, αk, τk, ρkl, k =1,…, p; l =1,…, p}, we assume that:
We further specify the mean and covariance functions μ(t) and Σ(t) respectively. For some θGP = {μ0, μ1, μH, μYH, μ2, μ3, σk, αk, τk, ρkl, k =1,…, p; l =1,…, p}, we assume that:
 In summary, we assume that patient i’s expected embedding at timepoint t, μi(t), is a function of his/her contemporaneous phenotype state Yit, overall healthcare utilization Hi, and time t. We assume that the marginal variance of embedding component k can be represented by some baseline
In summary, we assume that patient i’s expected embedding at timepoint t, μi(t), is a function of his/her contemporaneous phenotype state Yit, overall healthcare utilization Hi, and time t. We assume that the marginal variance of embedding component k can be represented by some baseline 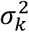 scaled by the effect of healthcare utilization. We denote the correlation between embedding components k and l as ρkl, which we assume to be constant over time. Between timepoints, we employ a first-order univariate autoregressive (AR(1)) kernel structure such that the residual at timepoint t, ϵi,t,k = Xi,t,k − E(Xi,t,k|Yi, Hi), is a linear function of its temporally previous value ϵi,t−1,k with autocorrelation coefficient τk:
scaled by the effect of healthcare utilization. We denote the correlation between embedding components k and l as ρkl, which we assume to be constant over time. Between timepoints, we employ a first-order univariate autoregressive (AR(1)) kernel structure such that the residual at timepoint t, ϵi,t,k = Xi,t,k − E(Xi,t,k|Yi, Hi), is a linear function of its temporally previous value ϵi,t−1,k with autocorrelation coefficient τk:
 r ∈ [0,1] is an autoregression regularization hyperparameter separately trained by 10-fold cross-validation: r = 0 ignores intertemporal correlation while r = 1 results in undampened autoregression. We chose first-degree autoregression over higher-degree models due to computational ease and mitigation of overfitting.
r ∈ [0,1] is an autoregression regularization hyperparameter separately trained by 10-fold cross-validation: r = 0 ignores intertemporal correlation while r = 1 results in undampened autoregression. We chose first-degree autoregression over higher-degree models due to computational ease and mitigation of overfitting.
Implementation and Inference
MGP is fit via one iteration of an approximating expectation-maximization (EM) algorithm. An EM algorithm iteratively derives an expression for the expected log-likelihood given the current parameter estimates (E-step), and re-computes parameter estimates that maximizes this expected log-likelihood (M-step). Our implementation approximates the expected log-likelihood in the E-step by deriving the marginal posteriors of each latent phenotype state, Ŷi,t|Xi, rather than the more complex joint posterior Ŷi|Xi. Before we fit MGP, we optimize the r hyperparameter using 10-fold cross-validation on the labeled set. We then initialize the EM by optimizing the model parameters {λmarkov, θGP} on the labeled set only and using this model to impute labels for the unlabeled set. We refer to predictions made using this initial model as MGP’s supervised estimator 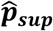 . Finally, we re-optimize {λmarkov, θGP} using both observed and imputed phenotype labels. We refer to predictions made using this re-trained model as MGP’s semi-supervised estimator
. Finally, we re-optimize {λmarkov, θGP} using both observed and imputed phenotype labels. We refer to predictions made using this re-trained model as MGP’s semi-supervised estimator 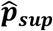 . In this study we evaluated the supervised and semi-supervised models on the unlabeled set itself (for which we masked the gold-standard labels), though the models can also be applied to a separate dataset. Specific details of our fitting procedure are supplied in the Supplementary Materials.
. In this study we evaluated the supervised and semi-supervised models on the unlabeled set itself (for which we masked the gold-standard labels), though the models can also be applied to a separate dataset. Specific details of our fitting procedure are supplied in the Supplementary Materials.
Combining Semi-supervised and Supervised Predictions
Theoretically, semi-supervised generative models such as markov gaussian process should benefit from the additional information in the unlabeled set if the model is correctly specified. However, semi-supervised predictors have been shown to be more sensitive to model misspecification than their supervised counterparts. To mitigate this effect, SAMGEP returns a weighted average of 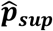 and
and 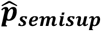 , with mixture weight α optimized by 10-fold cross-validation maximizing the area under the receiver operating curve (AUC) of held-out Yi,t predictions:
, with mixture weight α optimized by 10-fold cross-validation maximizing the area under the receiver operating curve (AUC) of held-out Yi,t predictions:
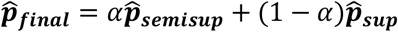 Our results on a real world EHR-based event prediction task demonstrate that this weighted average outperforms both
Our results on a real world EHR-based event prediction task demonstrate that this weighted average outperforms both  and
and 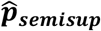 (Figure S1).
(Figure S1).
Data and Metrics for Evaluation
Simulation Study
To evaluate the SAMGEP algorithm with simulated data, we generated datasets of p = 150 count features along with H for a variable number of patients, each with a mean of 25 timepoints. To assess our method’s robustness to various model specifications, we varied the following generative parameters: (i) Y|T where ‘independent’ indicates Y ⊥ T, ‘correct’ follows SAMGEP’s generative model, and ‘complex’ denotes over-parametrization of Y(T); and (ii) C|Y (marginally lognormal vs. logt with 5 df) with intra-temporal correlation matrix fixed at the observed correlation of our real-world dataset and inter-temporal correlation parameter ρ varied from 0 to 0.8. We considered n = {50,100} and N = {1000,5000,20000}. Moreover, we let the number of informative features vary from 5 to 100. Details of our simulation generative mechanisms are supplied in the Supplementary Materials.
Real EHR Data Analysis
We collected longitudinal EHR data between January 1, 2006 and December 31, 2016 for 4,706 patients with at least one ICD-9 code for multiple sclerosis (340) from the Partners HealthCare system, which includes Brigham and Women’s Hospital and Massachusetts General Hospital in Boston, MA. We derived neurologist-confirmed multiple sclerosis relapse events and dates for 1,435 patients from the Comprehensive Longitudinal Investigation of Multiple Sclerosis at Brigham and Women’s Hospital (CLIMB) research registry. CLIMB participants have at least one annual clinic visit during the study period. The Partners HealthCare IRB approved the use of both research registry and EHR data.
We defined a relapse event as a clinical and/or radiological relapse. Clinical relapse was defined as having new or recurrent neurological symptoms lasting at least 24 hours without concurrent fever or infection. Radiological relapse was defined as having a new T1-enhancing lesion and/or a new or enlarging T2-FLAIR hyperintense lesion on brain, orbit, or spinal cord MRI.
From the EHR dataset we extracted pertinent demographic information, including age, sex, and race/ethnicity. We also extracted patient-level occurrences of billing codes, including International Classification of Disease 9th/10th edition (ICD-9/10) and Current Procedural Terminology (CPT) codes. We mapped ICD codes to PheCodes using the established PheWAS mapping.[35] To mitigate sparsity, we consolidated CPT codes according to groupings defined by the American Medical Association. Finally, from free-text clinical narratives (i.e. discharge summaries) we extracted patient-level occurrences of clinical terms, which we mapped to CUIs using the Natural Language Processing (NLP)-based Narrative Information Linear Extraction (NILE) method.[36]
Benchmark Methods for Comparison
We considered as benchmarks five supervised methods using the labeled set alone: (i) LASSO-penalized logistic regression [16,17,34,37–39], (ii) random forest (RF) [40,41], (iii) linear discriminant analysis (LDA) [42], and (iv) LSTM-gated recurrent neural network (RNN) [24,39,43,44] trained with raw feature counts Ci,t, as well as (v) LDA trained with patient-timepoint embeddings generated without weights 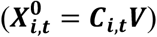 , which we refer to as LDAembed. In addition, we considered a semi-supervised benchmark: hidden markov model (HMM) [26–29,45,46] with a multivariate gaussian emission trained with the weight-free embeddings
, which we refer to as LDAembed. In addition, we considered a semi-supervised benchmark: hidden markov model (HMM) [26–29,45,46] with a multivariate gaussian emission trained with the weight-free embeddings 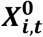 . Only HMM and RNN leverage the longitudinal nature of the data, while all other comparator methods train models for predicting Yt based only on concurrent features (Ci,t or
. Only HMM and RNN leverage the longitudinal nature of the data, while all other comparator methods train models for predicting Yt based only on concurrent features (Ci,t or  ) without considering the time sequence. Hyperparameters for LASSO, random forest, and RNN were optimized by 10-fold cross-validation maximizing AUC. As a baseline we also included predictions based only on the multiple sclerosis PheCode (355). While not as meaningful for multiple sclerosis relapse, the closest PheCode is meaningful in situations where the target phenotype is reasonably well coded in the EHR, such as congestive heart failure.
) without considering the time sequence. Hyperparameters for LASSO, random forest, and RNN were optimized by 10-fold cross-validation maximizing AUC. As a baseline we also included predictions based only on the multiple sclerosis PheCode (355). While not as meaningful for multiple sclerosis relapse, the closest PheCode is meaningful in situations where the target phenotype is reasonably well coded in the EHR, such as congestive heart failure.
Evaluation Metrics
To quantify the accuracy of SAMGEP and its comparators’ predictions for the binary phenotype Yi,t, we computed (i) AUC, and (ii) F1 score choosing a cutoff value that achieves 95% specificity. Whereas AUC reflects tradeoff of sensitivity and specificity, F1 score reflects that of sensitivity and positive predictive value. Neither AUC not F1 score consider the sequence of Ŷi,t predictions over time for a given patient.
Since the ultimate objective of SAMGEP is to predict the precise timings of phenotype events over the course of a patient’s observed record, as well as the time to first event for survival analysis, we also evaluated the methods’ longitudinal phenotype curve predictions. To this end, we defined the observed all-event counting process (i.e. a patient’s relapse count so far) as Ni(t) = ∑k≤t Yi,k(1 − Yi,k−1), where Yi,0 = 0, and the first-event process (i.e. whether a patient has had a relapse yet) as Fi(t) = 1 − Πk≤t(1 − Yi,k), We defined the all-event counting process this way rather than as Ni(t) = ∑k≤t Yi,k since for an appropriately chosen time window, two consecutive event-positive timepoints {Yi,k = 1, Yi,k+1 = 1} should correspond to the same event. We evaluated each method’s ability to predict longitudinal phenotype counts by computing the area between Ni(t) and the predicted counting process 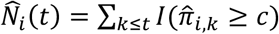 , denoted as ABCcount, where
, denoted as ABCcount, where  denotes a method’s predicted probability that Yi,k = 1 and c is chosen such that in labeled set
denotes a method’s predicted probability that Yi,k = 1 and c is chosen such that in labeled set
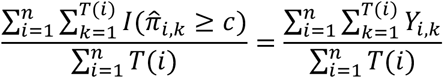 For time to first event, we computed the area between Fi(t) and the predicted cumulative probability
For time to first event, we computed the area between Fi(t) and the predicted cumulative probability 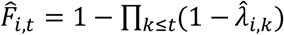 , denoted by ABCcdf, where λi,k denotes patient i’s true hazard at time k and
, denoted by ABCcdf, where λi,k denotes patient i’s true hazard at time k and  denotes a predictor thereof. Since SAMGEP and HMM jointly model the longitudinal outcome sequence {Yi,1,…, Yi,T(i)}, we could use these methods to directly estimate
denotes a predictor thereof. Since SAMGEP and HMM jointly model the longitudinal outcome sequence {Yi,1,…, Yi,T(i)}, we could use these methods to directly estimate  . Other methods only predict marginal probabilities
. Other methods only predict marginal probabilities  so we assumed that
so we assumed that 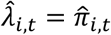 , or equivalently that event status labels are independent over time. Rather than report the raw ABC quantities – which don’t have a meaningful scale – we report methods’ percent decrease in the two below those of the null model that sets
, or equivalently that event status labels are independent over time. Rather than report the raw ABC quantities – which don’t have a meaningful scale – we report methods’ percent decrease in the two below those of the null model that sets 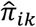 to the prevalence at time k:
to the prevalence at time k:

RESULTS
Robustness to Data Generative Characteristics
Figure 3 explores SAMGEP and its comparators’ robustness to various generative model specifications. Note that only relative performance between methods, not absolute performance, is meaningful as different generative settings may portend disparate inherent levels of information. Panels A and B reassuringly indicate that SAMGEP, like its comparators, is robust to (A) variations in how phenotype risk changes over time and (B) wide-tailed feature distributions – both realistic misspecifications. Panel C suggests that the benefit of explictly modeling the inter-temporal correlation ρ counter-intuitively breaks down at a very high ρ of 0.8. At the more realistic ρ = 0.4, however, SAMGEP appears more robust than HMM, which assumes that all intertemporal feature correlation is captured by the Markov chain on Y. Panel D suggests that SAMGEP’s use of sparse weights in mapping feature counts C to patient-timepoint embeddings X makes the method robust to sparse distribution of information (i.e. 5 or 20 informative features out of 150) at the expense of increased bias in the case of dense information distribution (i.e. 100 informative features), similarly to LASSO. Given that information sparsity is the norm for EHR data, this attribute is well conditioned to EHR modeling. Panel E unsurprisingly demonstrates that larger labeled sets improve predictive AUC, though SAMGEP improves disproportionately between n = 50 and n = 100. This suggests that while SAMGEP is robust to very low n, its true value is unlocked at a labeled set size of ∼100 patients. Finally, panel F shows that SAMGEP singularly benefits from increasing the unlabeled set from N = 1000 to N = 5000 but not to N = 20000. This suggests that SAMGEP is able to effectively extract information from unlabeled patients, though having too many such patients may paradoxically attenuate this benefit.

Robustness of SAMGEP and comparator methods’ AUCs, F scores, ABCcdf gains, and ABCcount gains to various generative parameters, including the (A) specification of Y|T, (B) specification of X|Y, (C) inter-temporal correlation parameter ρ, (D) number of informative (i.e. non-sparse) features, (E) number of labeled patients n, and (F) total number of patients N. Details of the experiment are delineated in the Simulation Study subsection of the Methods.
Prediction of MS Relapse using Real-World EHR Data
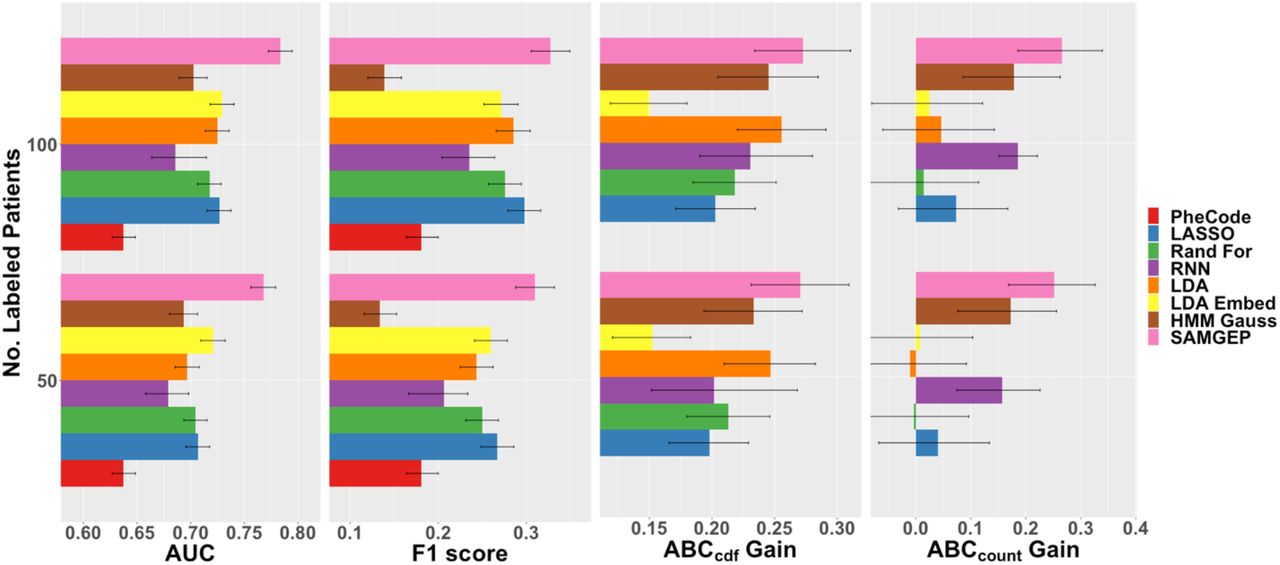
Figure 4 depicts mean AUCs, F1 scores, ABCcdf gains, and ABCcount gains for SAMGEP and various comparator methods predicting MS relapse using real-world EHR data. SAMGEP achieved significantly higher mean AUCs and F1 scores than all other methods for both n = 50 and n = 100 observed labels. RNN on the other hand achieved lackluster AUCs and F1 scores with relatively wide confidence intervals, an unsurprising observation given that such complex neural networks typically require far more than 100 observations to achieve sufficient variance mitigation. SAMGEP also achieved the highest ABCcdf gains, though not significantly so relative to LDA and HMM for n = 50, or relative to LDA, HMM, and RNN for n = 100. Finally, SAMGEP achieved the highest ABCcount gains, though statistically equivalent to RNN and only marginally superior to HMM for both n = 50 and n = 100. The fact that SAMGEP, HMM, and RNN were among the top performers by both ABC metrics, despite HMM and RNN’s unremarkable AUCs and F1 scores, suggests that jointly modeling {Yi,1,…, Yi,T(i)} is singularly beneficial for longitudinal phenotype process prediction. On the other hand, LASSO, random forest, LDA, and LDAembed do not even significantly improve upon the null model counting process estimator, showing that accurately predicting phenotype states at individual timepoints does not necessarily translate into accurate phenotype process prediction.

AUCs, F1 scores, ABCcdf gains, and ABCcount gains for SAMGEP and various comparator methods predicting MS relapse using real-world EHR data. 95% confidence intervals were empirically estimated by bootstrapping with 100 replicates. See the Evaluation Metrics subsection of the Methods for details about the evaluation metrics.
While SAMGEP does not achieve signficant improvement over all comparator methods per all four accuracy metrics, its consistency across metrics is notable. Indeed, while HMM and RNN perform dismally per AUC and F1 score but well per ABCcdf and ABCcount, and other methods perform better per AUC and F1 score but poorly per ABCcount, SAMGEP consistently achieves the highest mean accuracy across metrics. It thus demonstrates proficiency at predicting both phenotype states at individual timepoints and phenotype processes across a patient’s record.
Finally, Figure S1 demonstrates that SAMGEP’s mechanism for adaptively weighting MGP’s supervised and semi-supervised predictors improves upon both individual predictors, albeit not significantly. Whereas the supervised predictor tends to achieve higher AUCs and F1 scores, the semi-supervised one tends to perform better per ABCcdf and ABCcount. Taking a weighted average of the two appears to achieve the best of both worlds.
Estimation of CDF and Count Process Curves
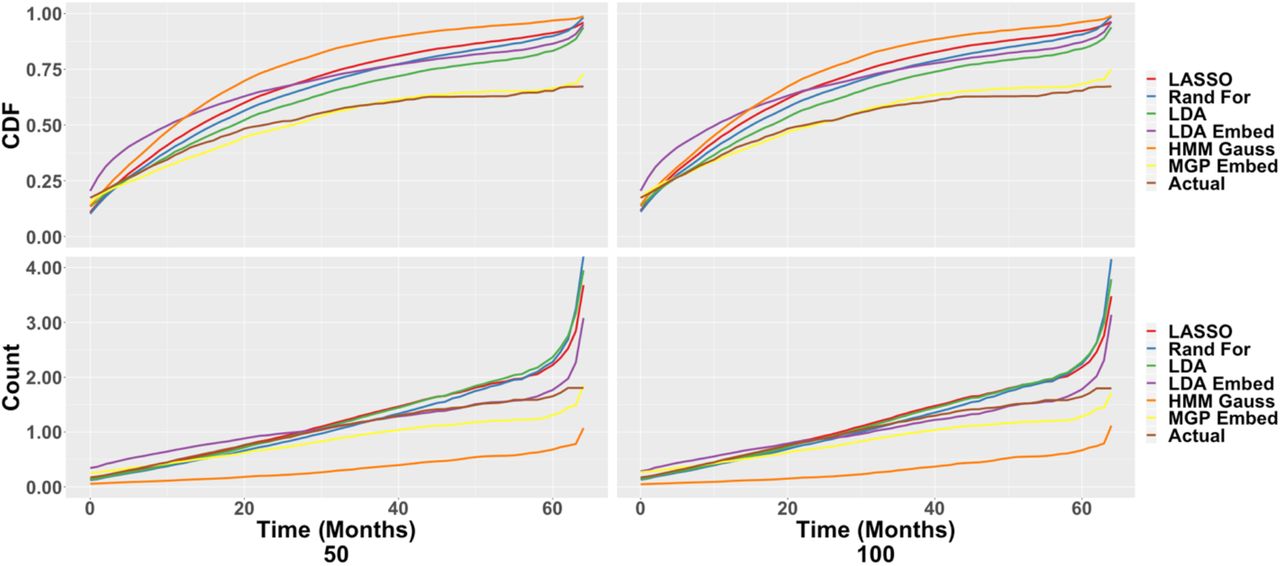
Figure 5 depicts the estimated population-wide first-relapse CDF, obtained as 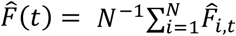 , and all-relapse count process, obtained as
, and all-relapse count process, obtained as 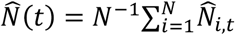 , based on the predictions of SAMGEP and comparator methods. Notably, CDF estimation using SAMGEP’s predictions is relatively unbiased, whereas comparator methods all markedly over-estimate the relapse rate. Not shown is the fact that SAMGEP’s confidence intervals are wider than those of LASSO, random forest, LDA, and embedded LDA, explaining why our method does not outperform comparators per the ABCcdf gain metric as significantly as Figure 5 might suggest. The precision of all methods markedly improves from n = 50 to n = 100, explaining the significant increases we observe in ABCcdf gain despite no apparent improvement in CDF estimation bias.
, based on the predictions of SAMGEP and comparator methods. Notably, CDF estimation using SAMGEP’s predictions is relatively unbiased, whereas comparator methods all markedly over-estimate the relapse rate. Not shown is the fact that SAMGEP’s confidence intervals are wider than those of LASSO, random forest, LDA, and embedded LDA, explaining why our method does not outperform comparators per the ABCcdf gain metric as significantly as Figure 5 might suggest. The precision of all methods markedly improves from n = 50 to n = 100, explaining the significant increases we observe in ABCcdf gain despite no apparent improvement in CDF estimation bias.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Estimation of population-level MS relapse cumulative probability (top) and count process (bottom) curves as a function of MS disease duration using the predictions of SAMGEP and comparators trained with 50 (left) and 100 (right) labeled patients.
Counting process estimation using SAMGEP’s predictions appears to systematically but slightly underestimate the truth. SAMGEP significantly improves upon comparators later in patients’ disease courses, where all other methods except HMM (which systematically underestimates the true function) exponentially overestimate the mean relapse count. Thus, SAMGEP’s predictions appear to once again improve bias at the expense of increased variance, on the whole significantly improving ABCcount gain.
DISCUSSION
While prediction of binary phenotypes using EHR data is pervasive in the literature, prediction of longitudinal phenotype state progression, or equivalently phenotype event times, remains underdeveloped. As our results demonstrate in concordance with prior studies, accurate prediction of a patient’s overall phenotype status – or even phenotype state at a given timepoint – does not necessarily translate into accurate prediction of phenotype progression. SAMGEP accurately predicts phenotype process functions by effectively leveraging a variety of EHR features with relatively limited expert intervention.
SAMGEP is singularly adept at estimating the cumulative event probability and counting process curves of a binary relapsing-and-remitting phenotype. It thus appears well suited for a study involving survival analysis or estimation of disease progression. For instance, researchers aiming to compare the efficacy of two multiple sclerosis treatments using EHR data could 1) annotate the relapse histories of 50-100 patients via chart review, 2) use SAMGEP to predict relapse probability and count curves for all remaining patients, and 3) use these predictions as features in a survival model such as Cox Proportional Hazards to estimate a population survival function. Further research is warranted to ascertain whether such a workflow affords increased power relative to traditional survival methods using the limited labeled set alone.
The main shortcoming of SAMGEP and other supervised/semi-supervised learning methods is its reliance on gold-standard phenotype event labels. Manually annotating these labels via chart review is particularly labor intensive, requiring an expert to review a patient’s entire chart rather than snapshots thereof. Modifying SAMGEP to handle current status labels – indicators of phenotype status at censor time only – would greatly diminish the manual labor required to utilize SAMGEP for a survival study. Further work is warranted to explore this possibility.
CONCLUSION
In this study we introduce SAMGEP, a semi-supervised machine learning method that predicts phenotype event times using EHR data and a limited set of gold-standard labels. Singularly adept at estimating event CDF and counting process curves, SAMGEP promises to enable more powerful use of EHR data for epidemological research involving event outcomes, such as survival analysis.
Data Availability
The datasets used in this paper are proprietary, and as such we unfortunately cannot make them available publicly.
REFERENCES



