
Abstract
Introduction Researchers routinely evaluate novel biomarkers for incorporation into clinical risk models. Although of potential benefit, such emerging markers, which are often costly or not yet commercially available, are unlikely to enable the scalable risk assessment needed for population health strategies. In contrast, the ideal inputs for population approaches would be those already widely available for most patients. We hypothesized that simple hematologic markers, available in an outpatient complete blood count without differential, would be useful to develop risk models for cardiovascular events.
Methods Using routine laboratory measurements as predictors and neural network-based automated event adjudication of 1,072,348 discharge summaries, we developed and validated models for prediction of heart attack, ischemic stroke, heart failure hospitalization, revascularization, and all-cause mortality.
Results Models with hematology indices alone showed Harrell’s concordance index ranging from 0.60–0.80 on an external validation set. Hematology indices added significantly in terms of discrimination and calibration performance compared to models using only demographic data and diagnostic codes for coronary artery disease, heart failure, and ischemic stroke, with the concordance index of resulting models in the range 0.75–0.85 on an external validation set. Predictive features varied by outcome, and included red blood cell, leukocyte, and platelet indices.
Conclusion We conclude that low-cost ubiquitous inputs, if biologically informative, can provide population-level readouts of risk.
Introduction
Two approaches guide the development of clinical risk models1. One strategy focuses on evaluating innovative markers, typically biomolecular, in a research cohort where banked historical samples and adjudicated outcomes are available. Recent biomarker candidates include genetic variants2–4, protein biomarkers5, somatic mutations6 and serum metabolites7. The motivation for such an approach is to improve model performance, while proposing something new about disease mechanisms. One challenge for such a strategy is the lack of availability of such markers in other cohorts, making replication a challenge. The problem of predictor availability extends to model deployment, especially when considering the use of such models to guide population health initiatives. Moreover, given that contributors to disease may evolve over time, insights from a historical cohort may not be readily transportable to new settings8.
An alternative approach involves training models using existing low-cost data readily available on a high percentage of patients within a healthcare system. Such an approach is pragmatic and exploits model training as the first step in a systematic program to enable risk assessment for the maximal number of individuals. The output of the models could then be used to guide population health initiatives, hospital- or payer-level financial planning, or clinical trial enrollment9. The use of widely available inputs also facilitates iteratively updating models to match changing environments.
In this work, we focus on the latter approach, but use an unconventional choice of predictors: hematologic indices available in a complete blood count without differential (CBC). Moreover, in the spirit of enabling ease of re-training models in new settings, we use a machine-learning strategy for adjudication of acute coronary syndrome, coronary revascularization, heart failure hospitalization, and ischemic stroke, using discharge summaries from hospitalizations10. We describe discrimination and calibration performance of the models across two institutions.
Methods
Study design and source data
All patients in the model-derivation cohort had a non-urgent outpatient CBC recorded on a Sysmex XE-5000 Automated Hematology System at the Massachusetts General Hospital (MGH) during March 2016 - May 2017. Among 494,654 result-log files stored by the XE-5000s during this period, there were 469,543 unique lab-order identifiers. Where identifiers were associated with more than one file, their timestamps varied by less than 3 hours in 99% of cases. We thus interpreted such multiple readouts as mapping to a single blood sample, and we discarded all but the most recent file. We discarded another 26 files which had internally inconsistent data. Among the 469,517 files we retained for later processing, there were no missing data.
For each patient, we also accessed all diagnostic-code data from the Massachusetts General Brigham (MGB) Electronic Data Warehouse (EDW), including admit diagnoses, encounter diagnoses, medical history, and problem lists, as well as all discharge summaries and progress notes. Encounters, diagnostic codes, and notes could be from any of the institutions within MGB network of hospitals. We excluded all tests that occurred within 7 days prior to or 30 days following an emergency department visit or hospital admission, as defined by the date of a discharge summary note, so that the hematologic indices would more closely reflect the patient’s baseline values.
From the remaining CBCs for each patient, only the earliest one was included, and this CBC defined the patient’s time of entry into the survival study (see below). We excluded patients younger than 30 years at the time of entry into study. Follow-up time was defined from the date of the CBC to the last encounter or note within the MGB-EDW under the following categories: encounters coded as “office visit”, “system generated”, or “hospital encounter”; notes coded as “progress note”, “telephone encounter”, “assessment & plan”, “discharge summary”, “ED provider note”, “consult”, “MR AVS snapshot”, “plan of care”, “patient instruction”, “H&P”. Because of the dramatic change in hospital population caused by COVID-19 in the winter of 2020, we did not consider follow-up or events after 2019 Dec. 31. When a patient’s follow-up extended past this date or if a study outcome occurred after this date, we right censored the patient at 2020 Jan. 1. Patients with no follow-up in the MGB-EDW system were excluded.
The validation cohort consisted of all individuals who had a 10-parameter complete blood count (described below) collected at Brigham Women’s Hospital (BWH) between June 2015 and December 2016, and whose results were available within the MGB-EDW. As with the training data, we excluded laboratory values occurring close in time to emergency department or hospital discharges.
Artificial intelligence-enabled adjudication of cardiovascular outcomes
We recently trained neural network-based models to classify discharge summaries as associated with one the following four cardiovascular events: acute coronary syndromes (ACS), ischemic stroke (IS), heart-failure hospitalization (HF), and percutaneous coronary intervention/coronary artery bypass surgery (PCI/CABG)10. Briefly, after manually labeling 1,372 training notes + 592 validation notes + 1,003 testing notes across 17 institutions, we trained and validated models for event adjudication, with AUROC on the 1,003 test notes as follows: ACS, 0.967; HF, 0.965; IS, 0.980; PCI/CABG, 0.998. The fraction of all discharges in our test set which received labels for CVD events was as follows: ACS, 0.054; HF, 0.122; IS, 0.059; PCI/CABG, 0.054. The four types of events were not mutually exclusive, and a discharge summary could receive as many as four positive labels. For the current work, we selected classification thresholds to maximize F1 score (Supplementary Table 1A). The four event models were deployed on the 1,072,348 discharge summaries for the derivation and validation cohorts and a binary event status was determined by each model for each note.
The four AI-adjudicated clinical events, plus all-cause mortality, constituted the five primary outcomes for our survival analysis. In addition to these primary outcomes, we also defined two composite outcomes: 1) acute coronary syndrome or heart-failure hospitalization or ischemic stroke (“ACS/HF/IS”); and 2) ACS/HF/IS or death (“ACS/HF/IS/death”). Date of death was obtained from MGB-EDW, without mediation by statistical methods. We did not employ competing-risk models or exclude a patient from the dataset for outcome X if they also experienced outcome Y.
Prior history of CAD, IS, or HF was established using diagnostic codes, which we previously evaluated for performance on a set of manually labeled test notes10 (Supplementary Table 1B). In contrast to the event models above, which map a single discharge summary to the probability of an event immediately associated with that hospital discharge, ICD codes were taken in aggregate across a patient’s history, to generate a binary status of extant disease up to a certain date.
Predictors
Predictors used in the sex-specific survival models were:
Patient’s age at entry into study.
Binary diagnostic codes for history of each of three conditions, at time of entry into study: heart failure; ischemic stroke; coronary artery disease or myocardial infarction.
Ten hematologic indices obtained as routine values using the Sysmex XE-5000, at time of entry into study: hematocrit, whole-blood hemoglobin concentration, mean corpuscular hemoglobin, mean corpuscular hemoglobin concentration, mean corpuscular volume, platelet count, red blood cell count, red blood cell distribution width, mean platelet volume, white cell count.
All predictors were centered and scaled except the three binary flags for disease. Some predictor sets included 1st order interactions with age. When main effects were centered and scaled, this transformation was applied before computing interaction terms (Supplementary Table 3).
Derivation and validation of the models
For each of the seven outcomes, we used L1-penalized Cox proportional hazards models to estimate coefficients for each risk factor. For each outcome, we developed separate models for male and female patients. Penalty strength for each model was selected by optimizing Harrell’s concordance index (C-index)11 through k-fold cross validation (3 ≤ k ≤ 5). Ties were handled with Breslow’s method. Regression and penalty tuning were performed with the python package scikit-survival v0.14.012.
Each combination of outcome and sex was treated with five different models, each supported by a different set of predictors: set 1 consisted of the ten hematologic indices (“HEM”); set 2 added age to set 1 (“HEM-AGE”); set 3 added disease history to set 2 (“HEM-AGE-HX”); set 4 consisted of age and history (“AGE-HX”); set 5 consisted of just age (“AGE”). Whenever we included age in a predictor set, we also include first-order interactions between age and all main effects (Supplementary Table 3B).
To evaluate performance within the derivation set and provide a measure of uncertainty for the performance estimate, we repeated rounds of 5-fold cross validation, placing the penalty-tuning loop within the model-derivation step for each fold. We then trained final models on the entire derivation dataset. We externally validated each final model on the BWH dataset, having preprocessed the validation data in the same way as the training data. We removed any patients from the validation dataset who also appeared in the derivation dataset.
Evaluation of model performance
Each combination of outcome, predictors, and sex were evaluated by C-index and Brier score. Brier score was calculated using survival at 3 years post-CBC, using the IPCW method to address censoring13,14. Performance on the derivation dataset is presented with means and confidence intervals computed from repeated k-fold cross-validation (40 repeats of 5-fold cross validation). Performance on the validation dataset is presented with means and confidence intervals computed from bootstrapping the validation dataset (1000 bootstrapped samples). Coefficients for final models are estimated using the entire derivation dataset.
Where the performance of two different predictor sets is compared for a single event model (e.g., compare predictor sets HEM-AGE-HX and AGE-HX, for the time-to-death model on the female validation cohort), the comparison is reported as the difference between model scores, as evaluated on a given set of patients. For the derivation dataset, this means that model scores are computed during each fold of cross-validation and compared for the patients in that fold. For the validation dataset, this means that model scores are computed on each bootstrapped sample and compared for the patients in that sample. Thus, a distribution of comparisons is compiled for each type of performance metric.
We evaluate model calibration graphically by plotting deciles of observed event probability vs. predicted probability. Comparisons are made at 3 years of follow-up. Baseline hazard is estimated nonparametrically, using Breslow’s method15, and represents the hazard for a patient whose predictors are all zero. This is a patient with average hematologic indices, average age, and with no history of CAD or MI or heart failure or stroke.
Random Survival Forest
To explore the benefit of modeling high dimensional interactions, we employed an ensemble learning method, random survival forest (RSF)16 to train models for each combination of outcome, sex, and predictor set with the help of the Python package scikit-survival v0.14.0. We performed a single round of hyperparameter tuning using k-fold cross-validation (k = 5). Hyperparameters optimized included: trees per forest {50,150}; maximum depth of any tree {2,4,6,8}; number of features examined for splitting at each node {1,2,3,4}. We report the mean test-set C-index calculated over the k folds. The hyperparameter set represented by the reported C-index is the one that produced the highest mean C-index.
Results
Baseline characteristics
The derivation cohort included 11,056 males and 12,182 females, all of whom received at least one outpatient, non-urgent CBC between 2016-Apr-2 and 2017-May-16 (Table 1A, 1B). The external validation cohort, at a second institution, consisted of 10771 males and 18900 females, all of whom received at least one outpatient elective CBC between 2015-Jun-1 and 2017-Jan-1. All patients in this study were at least 30 years old at the time the CBC was performed. Unlike other risk-model efforts17,18, which have focused on a population free of CVD events and not taking statins, our focus was on a broader set of patients, likely at higher risk. Our rationale was that such individuals are responsible for high resource healthcare utilization, and so could benefit from triggered therapeutic innovations to reduce risk, whether they be novel medications or population-health initiatives.
Median follow-up time for the derivation cohort was 1,091 days, and for the validation cohort was 1,517 days (Supplementary Figures 1 and 2). The most notable differences between derivation and validation cohorts were a younger age in the female validation cohort compared to the derivation cohort (53.7 vs. 57.4 years) and greater racial diversity within the validation cohorts (e.g., 19.6% non-White in female validation vs. 12.3% in female derivation). Prevalence of cardiovascular disease in the male derivation cohort was similar to that in the male validation cohort, whereas prevalence in the female derivation cohort was higher than in the validation cohort.
CONSORT-type diagrams showing the flow of patients and their data through our analysis are available in the Supplement (Supplementary Figures 3 and 4).
Rates of cardiovascular disease and death
In the derivation cohort, the proportion of patients with one or more ACS events within the follow-up period was 0.019, with one or more HF hospitalizations was 0.046, with one or more ischemic strokes was 0.022, with one or more coronary revascularizations was 0.023 (Tables 2A, 2B). The fraction who died was 0.054. In the validation cohort, the proportion of patients with one or more ACS events was 0.013, with one or more HF hospitalizations was 0.045, with one or more ischemic strokes was 0.021, with one or more coronary revascularizations was 0.014. The fraction who died was 0.050.
Number of patients in (A) derivation and (B) validation cohorts, and number of each type of outcome observed, as well as the fraction of patients with each outcome. Fraction is reported as outcomes per 1000 patients, along with 95% confidence intervals for the fraction.
Model performance
Model performance was assessed in the derivation cohort using repeated 5-fold cross validation (Table 3). We refer to the held-out data defined by repeated k-fold cross validation as the internal test set (though, to be clear, the process of repeated k-fold cross validation operated on 100% of the derivation cohort). Results from the external validation cohort are obtained by the bootstrap method 19.
The relationship of age to cardiovascular outcomes: AGE predictor set
Age is a powerful predictor for cardiovascular outcomes. On the internal test set, the AGE models produced C-indices between 0.65 and 0.74, whereas in the external validation cohort, the AGE models produced C-indices between 0.64 and 0.78 (Table 3). Brier scores were < 0.15 for all models in this study, their low magnitude due primarily to the low frequency of events in this dataset (Supplementary Table 4).
The utility of hematologic predictors for predicting cardiovascular events: HEM, and HEM-AGE vs AGE
Hematologic predictors also had utility for predicting cardiovascular outcomes. On the internal test set, C-indices for the HEM models ranged from 0.59 to 0.80 whereas on the validation set, C-indices for the HEM models ranged from 0.61 to 0.80 (Table 3). For both cohorts, the best discrimination was seen for heart failure hospitalization, composite cardiovascular outcomes, and death for both sexes, whereas the worst prediction was seen for ACS risk in men.
In the internal test set, when we added hematologic predictors to the AGE models (thus making the HEM-AGE models), we observed superior discrimination for almost all of our outcomes compared to models predicting on age alone (Table 4). The only models that did not clearly benefit from adding the hematologic predictors were models for ACS and PCI/CABG, in which cases the improvement in C-index was small or not statistically significant. Out of 14 comparisons (7 outcomes × 2 sexes) for these two predictor sets, 11 showed a statistically significant change in C-index on the internal test set. Of those 11, 10 also showed a corroborating statistically significant change on the external validation set.
The addition of hematologic predictors to the AGE models improved (made smaller) Brier scores for almost all outcomes in the internal test set, for both men and women (Supplementary Table 4). Out of 14 comparisons for these two predictor sets, 11 showed a statistically significant change in Brier score on the internal test set. Of those 11, 10 also showed a corroborating statistically significant change on the external validation set. Only the ACS models and the female IS model and did not show a statistically significant change.
Incorporating disease history: AGE-HX vs AGE
We hypothesized that history for some diseases would be available in most EHRs, albeit with varying degrees of completeness, and so may be considered for a scalable risk-assessment strategy. Adding disease histories to the AGE predictor set (i.e., making the AGE-HX predictor set) resulted in superior discrimination: AGE-HX models had higher C-index compared to AGE models for all outcomes, for both sexes, and in both derivation and validation cohort (Table 4). On the internal test set, increases in C-index were in the range 0.026 to 0.126. On the external validation set, increases in C-index were in the range 0.020 to 0.108. AGE-HX models also had better (lower) Brier scores than the AGE models (Supplementary Table 4). Out of 14 comparisons on the internal test set, all 14 showed statistically significant improvement, and all 14 improvements were corroborated by statistically significant improvements in the external validation set.
Substitution of hematology for history: AGE-HEM vs AGE-HX
To address the scenario where these highly predictive diagnostic codes are unavailable (e.g., a population-health program initiated with the help of a diagnostic lab provider), we compared the utility of the AGE-HEM models to that of the AGE-HX models. Equivalence between the two predictor sets depended on the outcome considered. For HF, IS, and the composite outcomes, the drop in C-index associated with using AGE-HEM instead of AGE-HX was < 0.03, for men and women, on both internal and external cohorts (Table 4). For modeling death, AGE-HEM was in fact superior to AGE-HX by as much as 0.077. For ACS and PCI/CABG, the drop in C-index was between 0.062 and 0.127 and was significant in both sexes and datasets. Calibration showed minimal difference, though for all outcomes except death and ACS/HF/IS/death, using AGE-HEM instead of AGE-HX produced minimally inferior Brier scores (Supplementary Table 4), with the HF model showing the lowest magnitude change in performance (increase of 0.003 on the external dataset).
Incremental value of hematologic predictors to age + disease history: HEM-AGE-HX vs AGE-HX
As was the case when we added hematologic predictors to the AGE models, we found that adding hematologic predictors to the AGE-HX models (thus making the HEM-AGE-HX models) often yielded significantly higher C-indices than did the AGE-HX predictor set, both for men and for women (Table 4). For example, C-index for the male HF model was higher by 0.067 under the larger predictor set, and C-index for the male death model was higher by 0.080 under the larger predictor set. The incremental effect of hematologic predictors was usually smaller than the difference between HEM-AGE and AGE, and so effects were less often significant in both validation and derivation datasets. Models for HF, death, and the composite outcomes showed statistically significant improvements in both cohorts for both sexes. Improvements in Brier score followed almost the same pattern (Supplementary Table 4). On the validation cohort, the HEM-AGE-HX models demonstrated C-indices between 0.75 and 0.85 (Table 3).
Calibration curves
We examined calibration curves for the HEM-AGE-HX model for all outcomes (Figure 1), as measured on the validation cohort. For females, risk is calibrated well for the all but the highest-risk decile. Over-prediction of risk for high-risk patients is more pronounced among the male models than the female models, consistent with higher Brier scores for male models.

Calibration curves for the seven modeled outcomes, on female (A) and male (B) in the validation cohort. Predictor set is HEM-AGE-HX, which includes hematology and age and disease history, and interactions with age. Predicted risk is compared with observed outcomes at 3 years.
Survival by predicted-risk quartile
Discrimination was assessed visually using Kaplan-Meier curves for the seven outcomes, as modeled with the HEM-AGE-HX predictor set and measured on the external validation cohort (Figure 2). In each subplot, the cohort is split into quartiles, according to the predicted relative risk of the outcome for each patient.

Curves are shown for all seven outcomes in the validation cohort, females (A) and males (B). For each outcome, the cohort is split into quartiles, according to the risk model developed for that outcome on the derivation cohort. Lowest-risk quartile is shown in blue; highest-risk quartile is shown in red.
For all seven outcomes among men, the risk groups predicted by the models maintain proper rank by observed risk over the whole observation period, at least for the highest risk 3 quartiles. For the HF model, survival curves for the low-risk and lowest-risk quartiles intersect at a follow-up time of around 4 years, which can indicate poor calibration of this model for the healthiest patients, though given the low event rate after 4 years (< 10/month for the entire male cohort), this is also readily attributable to noise in the Kaplan-Meier estimator.
Performance for the female-cohort models is similar: survival curves for the riskiest three quartiles are properly ordered over the entire observation period, but the low-risk and lowest-risk curves are sometimes inverted for the HF model and for the two composite models. The only exception is the PCI/CABG model, for which the middle two risk groups are inverted at t < 2 years.
Parameter estimates
Proportional-hazards coefficients in the HEM-AGE-HX models were examined for the three outcomes (composites not included) where the HEM-AGE-HX predictor set had better discrimination than AGE-HX on the internal test set (Table 5). The L1 penalization selects approximately half of the ten hematologic indices for each of the final models. Among the highly correlated set {HCT, HGB, MCH, MCHC, MCV, RBC}, usually more than half are eliminated, with the most commonly retained being RBC and HGB. Two out of the ten hematologic indices appear in all six models in Table 8: platelet count (PLT) and red cell distribution width (RDW). White cell count (WBC) and red cell count (RBC) are retained in five out of six models. As expected, the disease-history terms and the age terms are extremely strong factors in most HEM-AGE-HX models.
Random Survival Forest
Discrimination of the Cox proportional hazards models was comparable to the discrimination of the random survival forests (Supplementary Table 6). Many of the optimized RSF models had slightly better discrimination than the Cox proportional hazards models, with advantages for RSF ranging from −0.009 to 0.050. The biggest advantage for RSF came when using the HEM predictor set, which does not include any explicit interaction terms, and which therefore might be harder for a linear model to learn from than for a tree-based model. Improvement was less apparent for the HEM-AGE-HX models.
Discussion
The objective of our work is fundamentally different from that of most efforts focused on training risk models: we sought to develop risk models for cardiovascular events based entirely on low-cost, widely available, well-calibrated20, and objective input features. Whereas most risk models have emphasized the utility of a diverse set of inputs, which will typically require providers to order specific laboratory tests, document an expansive set of diagnoses, and record candid responses of patients regarding such attributes as smoking status18, our approach deliberately attempts to minimize the burden on providers or dependence on costly elements of data collection. Our rationale is based in part on our own experience with EHR-based risk assessment: for example, the percentage of patients in our cohorts for which one can compute the Pooled-Cohort Equation risk score from structured data within the MGB-EDW is <30% (data not shown). Even when the relevant tests may have been ordered, they may not be available as structured data in the EHR, if, for example, they were collected outside of the system and were only available as scanned documents. Furthermore, most risk models focus on primary prevention – whereas our focus was on a broader patient population with anticipated high resource utilization.
We have used hematologic predictors based on an assumption that many contributors to chronic diseases such as cardiovascular disease are systemic and may be reflected across multiple tissue types. This hypothesis is supported by a large amount of prior data, both experimental and observational, including the ability to estimate cardiovascular outcomes from digital retinograms21, the association of somatic mutations in leukocytes with coronary artery disease and heart failure risk6,22, the association of a complete-blood count-based score with mortality23–27, and the modulation of cardiovascular disease through leukocyte-restricted gene knockouts28,29.
Others have shown association of hematologic indices with all-cause mortality and cardiovascular events, including a focus on red-cell distribution width23,30–34 and specific leukocyte subpopulations such as the neutrophil-to-lymphocyte ratio35. The utility of RDW for predicting outcomes may be related to its association with anemias of chronic disease or with clonal hematopoiesis of indeterminate potential6, which appear to predict similar patterns of events. In both cases, the biomarkers may primarily be providing a readout for underlying systemic pathway abnormalities, with the hematopoietic lineage representing a shared upstream pathway abnormality or an index of prior exposures.
Although our work demonstrated success primarily for heart failure, major adverse cardiovascular events, all-cause mortality, and to a lesser extent ischemic stroke, we had less success in predicting incident acute coronary syndromes beyond what is possible with age and prior diagnoses. Nonetheless, a model using hematologic indices alone was able to modestly predict incident acute coronary syndromes (C-index = 0.62 [95% CI 0.57 to 0.67] and 0.60 [95% CI 0.56 to 0.63] for women and men, respectively, on validation dataset, comparable to polygenic risk scores2) suggesting that some signal exists, but there is likely redundancy with age and existing CVD. Nonetheless, a strategy combining age and hematologic predictors may still be useful in situations where structured diagnoses are not available or as complete as found within the MGB-EDW.
The primary limitation of our work, which is also a strength, is a deliberate use of restricted numbers of inputs to the risk models. Our patient population may also exhibit some selection bias that could limit generalizability to other settings – though in such cases, our approach combining widely available inputs with automated adjudication should enable rescaling or retraining. We have also not looked at out how these measures of risk progress through time and in response to therapy in individual patients. Given the limited performance benefit of random survival forests for predicting outcomes with these same inputs, we chose not to explore other algorithms, though it is possible some would show superior performance.
There is no shortage of risk models available for cardiovascular outcomes – and the challenge is motivating their use. We suspect that models such as the ones described here will primarily be attractive at an institutional or payer level, where better estimation of risk for a very large percentage of a population has clear economic value. We are not aware of any comparable effort to deliberately push the limits of models with minimal low-cost input features. We see our approach as complementary to other models which typically rely on individual or provider-entered data and have focused on patients not currently taking statins and free of cardiovascular disease17,18,36. These approaches also lend themselves to the creation of continuously updating risk trajectories where the rates of change may have additional predictive utility. Our goal is to maximize the number of patients for which a system-level estimation of risk is feasible, with minimal disruption to the existing workflow of providers, a place where we see model deployment having the greatest impact.
Data Availability
The data that support the findings of this study are available on request from the corresponding author R.C.D. upon approval of the data sharing committees of the respective institutions. The data are not publicly available due to the presence of information that could compromise research participant privacy.
Supplementary Figures

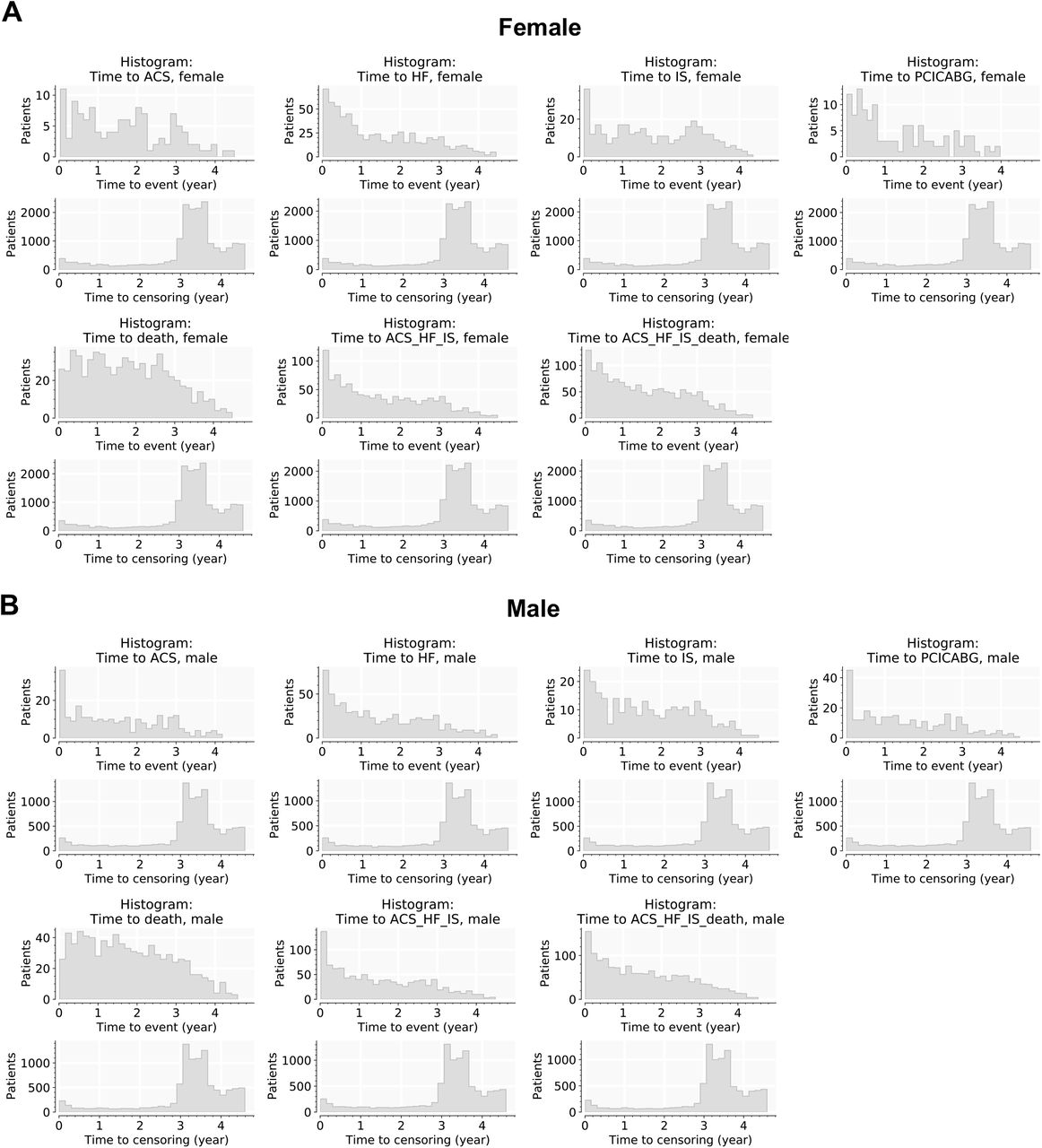
Time to 1st outcome, also time to right-censoring, for patients without outcomes in the observation period. Results broken down by the seven outcomes for female (A) and male (B) in this study. Derivation cohort.

Time to 1st outcome, also time to right-censoring, for patients without outcomes in the observation period. Results broken down by the seven outcomes for female (A) and male (B) in this study.

MGH patients and their data, used to model time-to-event for ACS, HF hospitalization, stroke, PCI/CABG

BWH patients and their data, used to model time-to-event for ACS, HF hospitalization, stroke, PCI/CABG
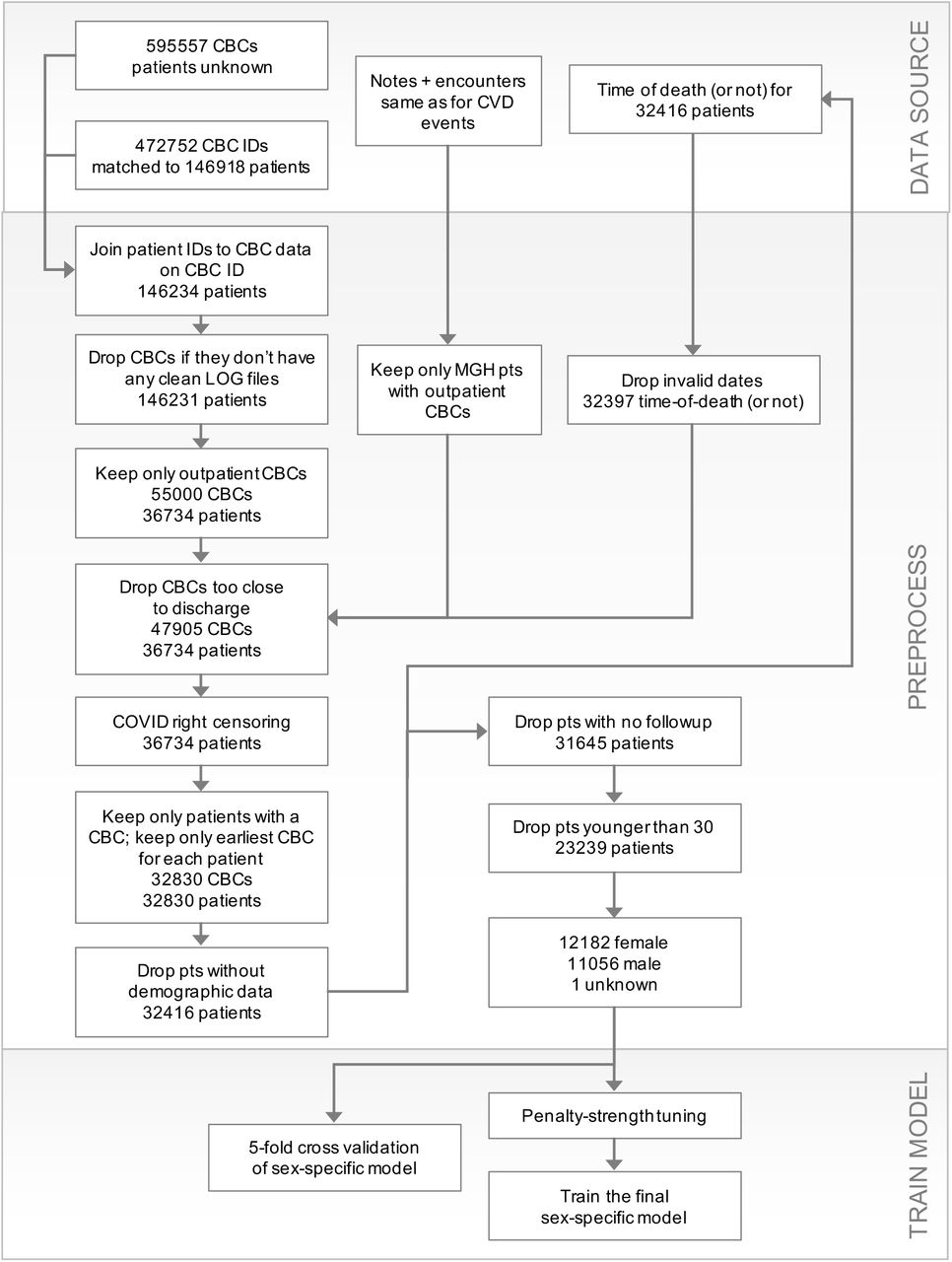
MGH patients and their data, used to model time-to-event for death

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
BWH patients and their data, used to model time-to-event for death
Supplementary Tables
Performance of classifier algorithms used to adjudicate outcomes for our study. Classification thresholds were chosen to maximize F1 score.
ICD codes can predict a patient’s history of disease at the time of their entry into the survival study.
Main effects of the proportional-hazards models referred to in this study. All main effects are unitless in the proportional-hazards model. Except for the three history predictors, all predictors are mean-centered and scaled by their standard deviation, as measured in the derivation cohort. The history variables are binary (0 for no history; 1 for yes history of disease) and are not scaled or centered.
The elements in each list are the terms, Xi, in the linear predictor of the Cox proportional-hazards model.
References



