
Abstract
At the outbreak of a virus, data on cases is sparse and commonly severe cases, with a higher probability of a fatal resolution, are detected at a larger rate than mild cases. In addition, in an under-sampling situation, the number of total cases is under-estimated leading to a biased case fatality rate estimation, most likely inflating the virus mortality. In this communication, we present a method to estimate the sub-report in a country that accounts for both the delay time between symptoms onset to death and the country’s demographics. The method is based on the comparison of the corrected case fatality rate (CFR) of the target country with the one of a benchmark country. Using reported data from Instituto Nacional de Salud up to December 28, we utilize our method to provide a comprehensive estimate of the Covid-19 sub-report in Colombia, its regions and some of its cities during 2020.
I. INTRODUCTION
Since March 6, when Colombia confirmed its first case of the coronavirus disease (Covid-19), the country healthcare system, with a limited testing capability, has struggled to monitor and report current cases. Keeping track of active cases in a pandemic is of paramount importance for epidemiological tracing in the early stages of the contagion spread. In more advanced stages of a pandemic, when epidemiological routes cannot be constructed, effectively testing the population becomes a challenging task that must thrive to keep the cases reported as high as possible. The accuracy in measuring case incidence and prevalence, as well as mortality rates is decisive for high-quality epidemiological modelling that enables governments to propose and implement public policies to mitigate the impact of the pandemic [1–3].
Throughout the current Covid-19 pandemic, governments have compiled extensive databases with information on infected people. In particular, data on positive cases and deaths are relevant for tracking the infection evolution. Commonly, however, tests are performed only on a subset of the total country’s population. How this subset is selected varies according to the country’s resources and the chosen strategy, but no matter how effective this strategy turns out to be, there are always some infected individuals that do not ever get tested for the disease and, therefore, are not registered as a positive Covid-19 case in the database. This phenomenon is known as under-reporting, and its magnitude varies especially in relation with the effectiveness of epidemiological tracing strategies, as well as tests availability [4].
In this work we propose a method to estimate the sub-report in a country from disease case databases. The value of the percentage of cases reported found in this way can then be used to obtain better quality figures for the incidence of cases and mortality rates. In particular, we analyze the data reported for Colombia, one of the most affected countries by the pandemic, its departments and some of its regions during 2020. Unlike seroprevalence studies, the proposed method needs not perform further tests than the ones already conducted, and whose results are contained in the cases databases.
Central to our method is the comparison of the case fatality ratio (CFR) of a target country, which in our case is Colombia, to the CFR of a benchmark country, which in this work is the Republic of Korea. A criterion for its selection as a benchmark, is that the track and testing strategy followed by the country has been effective, leading to a low under-reporting of Covid-19 cases. In order to account for differences between the population age distribution of the target and the benchmark country our method also incorporates the demographics of the countries. In this sense, the method answers the question of how many positive cases would be detected in the target country if it were using the testing strategy of the benchmark country?
The outline of the paper is as follows. The details of the method as well as a description of the data used are presented in Section II. Our estimates of the sub-report of Covid-19 for Colombia and its regions are reported in Section III, and are further discussed in section IV, where we also compare our work with other studies. The limitations of our approach are listed in section V. Finally, we conclude in section VI.
II. METHODS AND MATERIALS
A. Data
We use two datasets for our analysis. The first one is the data published by the Instituto Nacional de Salud (INS) [5], which is updated every day and reports all known Covid-19 cases in Colombia. For each case it provides its date of notification, location city, department or district, current status (recovered, recovery from home, being treated in an intensive care unit and passed away), age, sex, country of provenance, symptom onset date, date of death, date of diagnosis, date of recovery and the web report date. To construct the case and death incidence time-series (see fig. 1) we used data up to December 28, 2020. In addition, we also keep information about age and location of each case.

Covid-19 cases and deaths incidence in Colombia. Up to December 28, 2020 there have been 1’594,497 confirmed cases and 47,175 confirmed deaths.
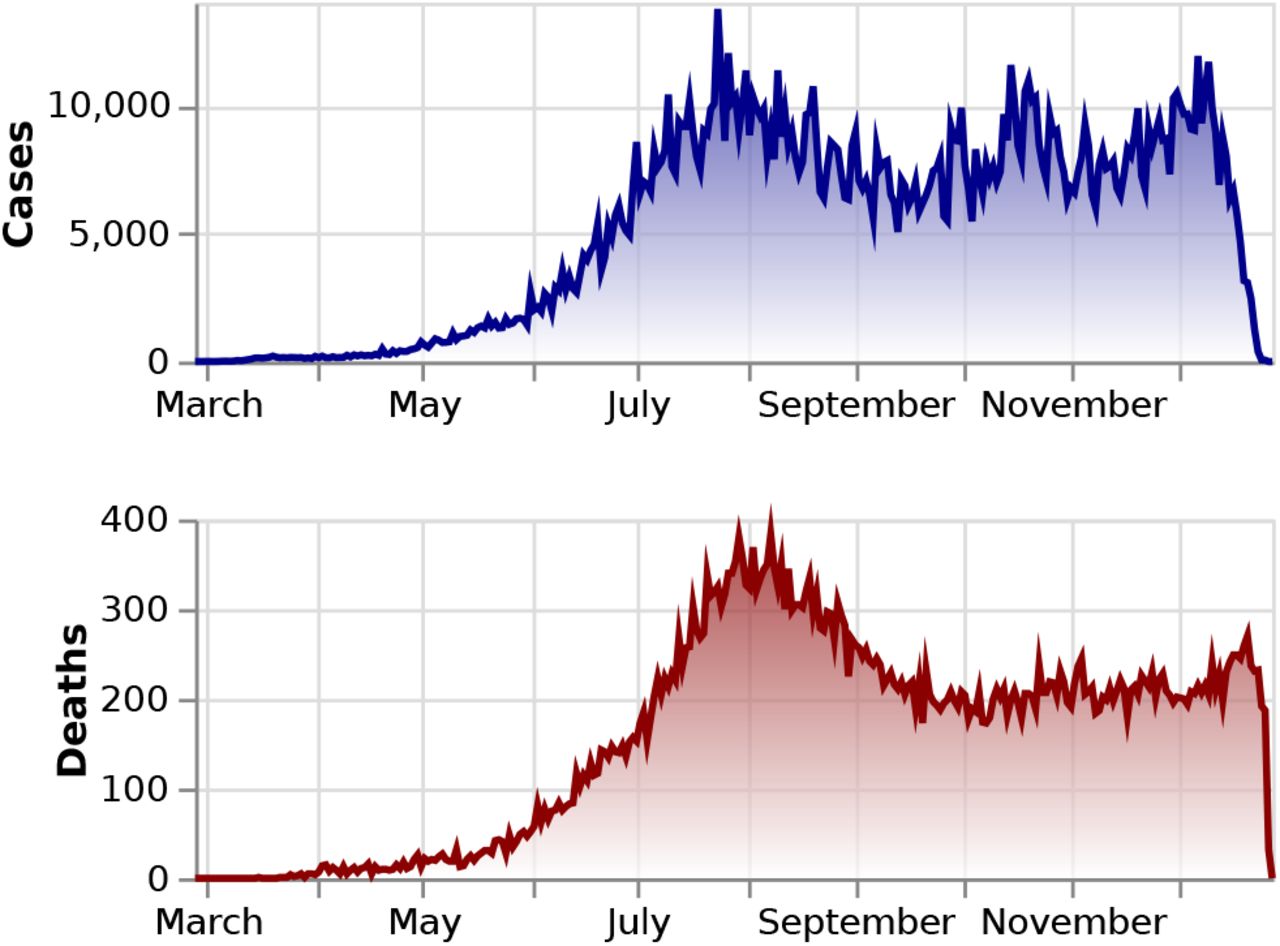
The other dataset is extracted from the demographic database maintained by the Departamento Administrativo Nacional de Estadística (DANE) [6]. We retrieve data containing the most recent projection for the year 2020 of the number of individuals per age group for all regions and cities of Colombia (see fig. 2). We make use of this information to assess the vulnerability of each region to Covid-19.
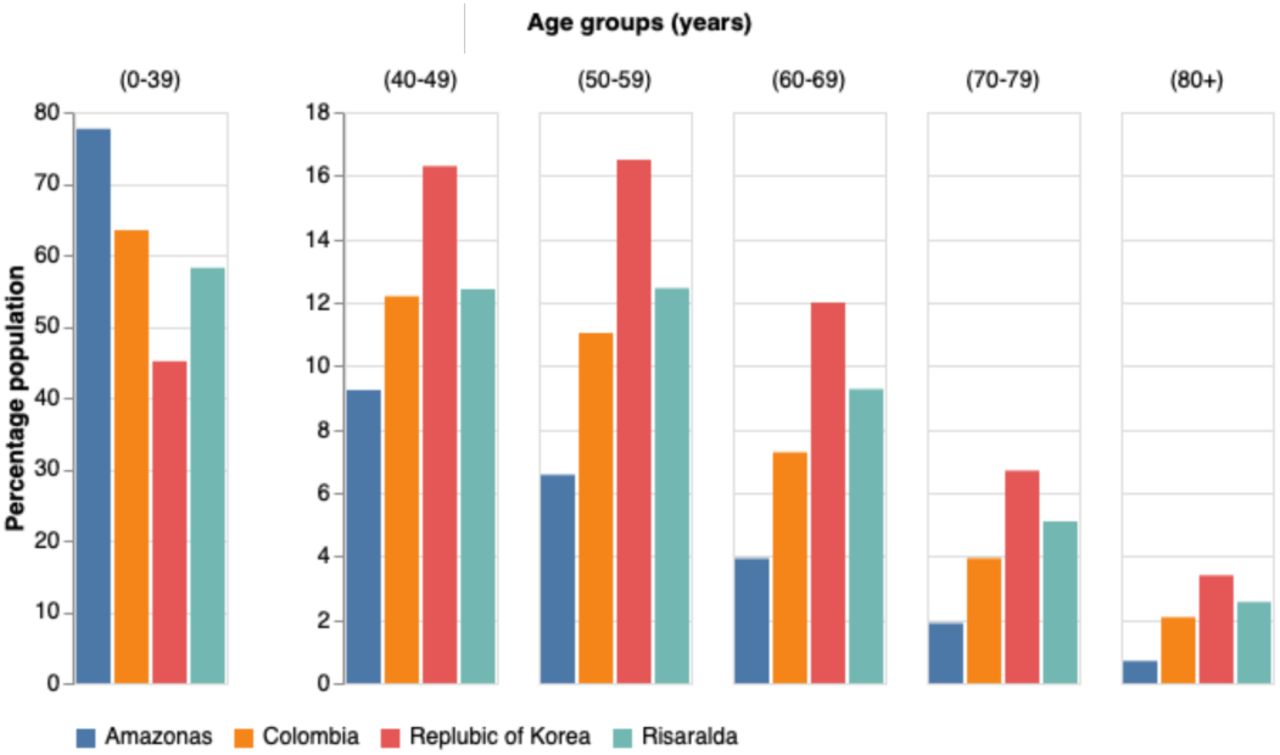
Population demographic comparison by age-group between Amazonas (one of the youngest populations in Colombia), Risaralda (one of the oldest populations in Colombia), Colombia and the Republic of Korea.
B. Delay adjusted case fatality rate estimate
Dividing deaths-to-date by cases-to-date to compute the CFR (from now on, nCFR indicates this naïve determination of the CFR) tends to yield a biased result, usually underestimating its true value [7, 8]. This happens because the outcome of active cases (i.e. recovery or death) is still not known. An improved calculation of the CFR can be done by accounting for the delay from onset-to-death to estimate the number of cases expected to have a known outcome.
1. Evaluating the delay time distribution between onset-to-death
We used the reported dates to calculate the time interval from illness onset to death of the confirmed 29,480 cases that resolved in death from March 16 to September 19 2020 in Colombia. The totality of cases in this period were already resolved (i.e. recovered or dead). We fit the conditional probability density f (t) of the time between onset-to-death given death to Weibull, gamma, and lognormal distributions [9, 10]. In all cases we use the maximum likelihood estimation (MLE) to determine the parameters and obtain confidence intervals using PyMC3 [11]. In addition, we include a gaussian kernel density estimation (KDE). We select the best fit model by using the Akaike information criterion (AIC). Table I shows estimates for the three models plus the KDE. In fig. 3 we show our gaussian KDE approximation to the onset-to-death distribution, with a mean time of 22.4 days and a standard deviation of 12.7 days. Our results for Colombia differ with distributions that were reported earlier in the pandemic [9, 10].
Illness onset to death time-delay distribution for Covid-19 outbreak in Colombia. 95% confidence intervals are displayed inside parenthesis.
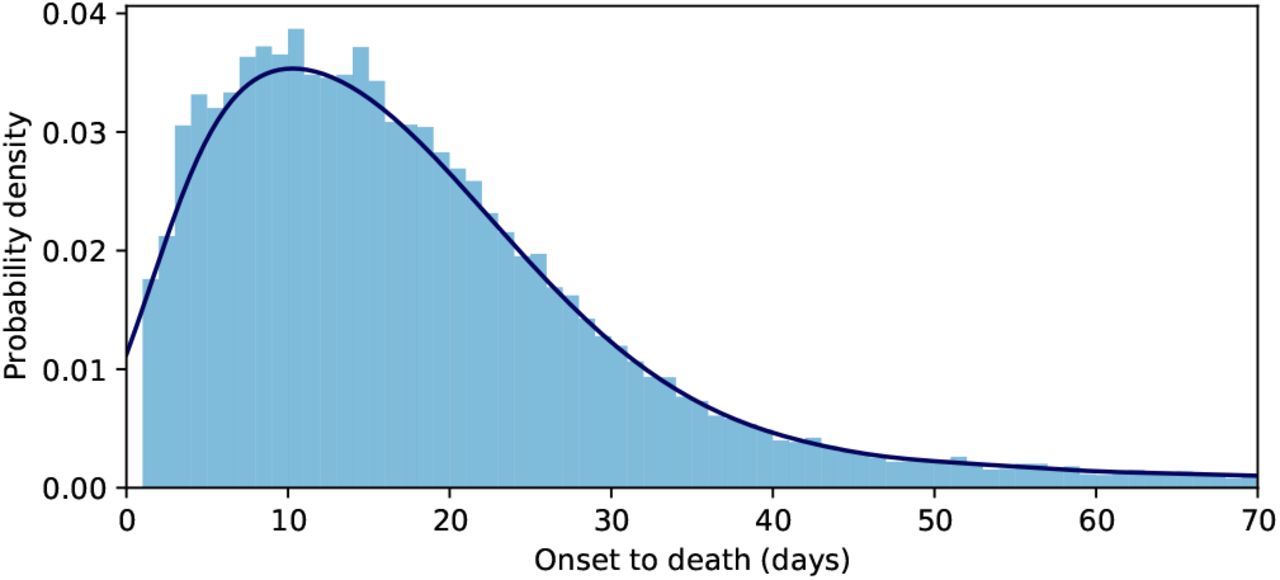
Probability density distribution of the time from illness onset to death f (t). The continuous line corresponds to a KDE fit with mean delay of 22.4 days and standard deviation of 12.7 days.
2. Adjusted case fatality ratio
The CFR is adjusted following the method proposed by Nishiura et al. [7]. We estimate the proportion of cases resolved using the case and death incidence to modify the CFR in order to account for delay outcome (cCFR). The underestimation factor [7, 8, 12–14],
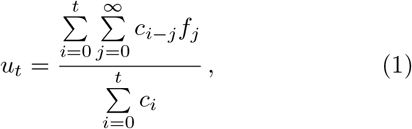 scales the cumulative number of cases in the denominator of the cCFR, and makes up for the adjustment. Here ct is the daily case incidence (see top panel of fig. 1) at time t and ft = f (t) is the conditional probability density of the delay-time from onset-to-death (see fig. 3).
scales the cumulative number of cases in the denominator of the cCFR, and makes up for the adjustment. Here ct is the daily case incidence (see top panel of fig. 1) at time t and ft = f (t) is the conditional probability density of the delay-time from onset-to-death (see fig. 3).
The severity of the Covid-19 is highly correlated to the age of the infected individual [10], hence, for each region or city, we evaluate age-stratified estimates of the adjusted case fatality rate, 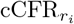 , where r stands for the region and i labels the age group. The age aggregated cCFR for a region is adjusted for the population demographics,
, where r stands for the region and i labels the age group. The age aggregated cCFR for a region is adjusted for the population demographics,
 Here,
Here,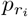 is the fraction of the population with age i for the region r.
is the fraction of the population with age i for the region r.
C. Percentage of cases reported
The adjusted cCFR does not account for under-reporting. In order to obtain an estimate of the potential level of under-reporting in Colombia and its regions our model follows the method proposed by Russell et al. [12], further adjusting for the demographics of the country.
We assume a baseline CFR (blCFR), taken from a bench-mark country, and compare it with the estimated cCFR for Colombia and some of its regions and cities. We do an age-stratified analysis. If the 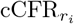 is higher than the age-group baseline, blCFRi, it indicates that only a portion of the real number of cases in this age group have been reported so far. The fraction of reported cases in region r and age group i is given by
is higher than the age-group baseline, blCFRi, it indicates that only a portion of the real number of cases in this age group have been reported so far. The fraction of reported cases in region r and age group i is given by
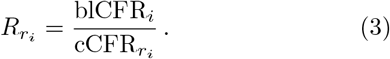 We also evaluate the fraction of cases reported in a region aggregated over age Rr. For this, we introduce the region baseline CFR,
We also evaluate the fraction of cases reported in a region aggregated over age Rr. For this, we introduce the region baseline CFR,
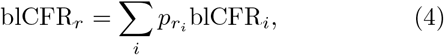 which accounts for the region population demographics through
which accounts for the region population demographics through 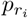 , and obtain
, and obtain
 The most recent literature offers several estimates of CFR for Covid-19. Among those adjusting or controlling for under-reporting, we mention those by Verity et al. [10], Russell et al. [13], Shim et al. [14], Guan et al. [15]. In our analysis, we use as benchmark country the Re-public of Korea. As baseline for this work we take the age stratified CFR data of July 14, 2020 [16], listed in Table II, since most of the cases from the first peak had already been resolved by this date.
The most recent literature offers several estimates of CFR for Covid-19. Among those adjusting or controlling for under-reporting, we mention those by Verity et al. [10], Russell et al. [13], Shim et al. [14], Guan et al. [15]. In our analysis, we use as benchmark country the Re-public of Korea. As baseline for this work we take the age stratified CFR data of July 14, 2020 [16], listed in Table II, since most of the cases from the first peak had already been resolved by this date.
Covid-19 case fatality rates stratified by age groups as of July 14, 2020 in the Republic of Korea.
III. RESULTS
In this study we consider all regions and cities in Colombia that have reported at least 40 fatal Covid-19 cases as of December 28, 2020. Table III shows the percentage of cases reported, the cCFR, blCFR and the total cases and deaths for all regions and some cities of Colombia. For the country the blCFR obtained is 1.2% (95% CI: 0.9-1.5) while its cCFR value is 2.7% (95% CI: 2.7-2.8) leading to a percentage of cases reported of 43% (95% CI: 43-43). It is worth remarking that Colombia’s blCFR is lower than the Republic of Korea’s, 1.9% (95% CI: 1.5-2.3) [17], due to its younger population. At the level of regions and cities these values fluctuate appreciably.
Percentage of Covid-19 cases reported in Colombia and its regions until December 28, 2020 with 95% confidence intervals. The corrected and baseline CFRs are also shown, along with the total number of positive cases and deaths to date. Regions are numbered to later compare with fig. 4 (N.S. identifies regions that are not shown in fig. 4 because they are districts and not a departments).
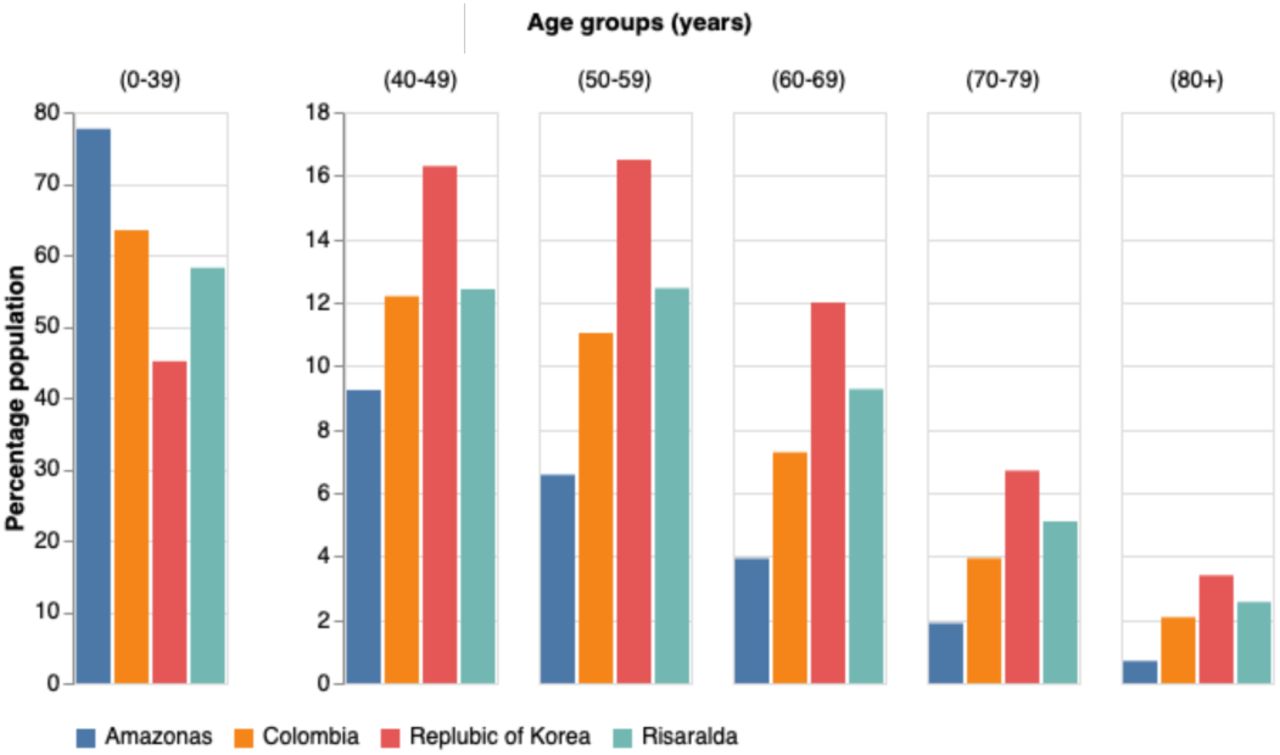
Because the severity of Covid-19 varies for different age groups [10], the blCFR reflects the differences in population demographics between regions. Regions and cities in which the fraction of the population with age above 60 years is more significant display a higher blCFR compared to the value for the country. On the contrary, in those regions or cities with a younger population than the average of the country the blCFR is lower than the country’s value. We illustrate this in fig. 2, where the population age distribution of Risaralda, the department with the oldest population, Amazonas, the department with the youngest population, and the country are compared. The corresponding blCFRs mirror the demographics, Amazonas’ blCFR is 0.5% (95% CI: 0.4-0.7) while Risaralda’s is 1.4% (95% CI: 1.1-1.8). These trends are followed in specific regions of the country. Hence, Arauca (3), Caquetá (9), Casanare (10), Guainía (16), Guaviare (18), Putumayo (24), Vaupés (31) and Vichada (32) located to the east and southeast of the country, in the region of the eastern plains and the Amazon, are sparsely populated areas with a young population and a low blCFR (cf.Table III and right panel of fig. 4). In contrast, departments such as Boyacá (7), Caldas (8), Quindío (25), Risaralda (26), Tolima (29) and Valle (30), located in the densely populated Andean region, and having a considerable population of elder people, present a high blCFR (cf.Table III and right panel of fig. 4).

Maps of the departments of Colombia, coloured by reporting percentage (left panel), mean age (central panel), and population density (right panel).
The department with the highest percentage of cases reported are San Andrés, 78% (95% CI: 58-100), and Caldas (8), 66% (95% CI: 62-71). They are followed by Vaupés (31), 63% (95% CI: 38-100), which is the department with the smallest number of reported cases and deaths. In contrast, Magdalena (20) with a value of 21% (95% CI: 19-23), and the largest cCFR, 4.4% (95% CI: 3.6-5.4), is the department with the lowest percentage of cases reported. Bogotá (5), the capital city, where 28% of the reported cases in the country are concentrated, has a reporting percentage of 48% (95% CI: 47-49), pulling the country’s percentage of report up. Furthermore, our results show that the country can be clearly divided in regions were the reporting percentage is above or below the country’s value, revealing places where the infection has been better tracked than in others, as shown in the left panel of fig. 4. Thus, in the Andean region, where most of the country population inhabit, the majority of the departments have a percentage of cases reported above 48%. Besides Caldas (8) and the city of Bogotá (5), these also include Antioquia (2), Boyacá (7), Quindío (25), Risaralda (26), and Tolima (29). Away from the center of the country most of the regions have a low reporting percentage. Conspicuously, all departments in the Atlantic coast region have a value below 40%. To this group belong the departments of Atlántico (4), Bolívar (6), Cesar (12), Córdoba (14), Guajira (17), Magdalena (20), and Sucre (28), as well as the cities of Barranquilla and Santa Marta. An important exception is the city of Cartagena, with a reporting percentage of 57% (95% CI: 53-61); one of the highest in the country. The same behaviour is observed in the east and southeast of the country, where the departments of Amazonas (1), Arauca (3), Caquetá (9), Casanare (10), Guainía (16), Guaviare (18) and Meta (21) have a reporting percentage below 40%. In this region only the departments of Vaupés (31) and Vichada (32) set themselves apart with reporting percentages above 57%.
We present age-stratified reporting percentages in Table IV. An overall trend is noticeable: the percentage of cases reported is higher for the elder population than for the younger population (cf. central panel of fig. 4). At the country level, the percentage of reporting for the age-group > 80 is 75% (95% CI: 65-87), with all the regions and cities, except Magdalena, 50% (95% CI: 42-60), with a percentage of reporting higher than 60%. For the age group of 70-79 years, the percentage of cases reported in the country is 49% (95% CI: 40-60), with a distinct gap of more that 20 percentage points with all other age groups of younger population, and percentages of report below 15% for the groups of age below 50 years, which account for more than 70% of the country total population (see fig. 2).
Age-stratified percentage of Covid-19 cases reported in Colombia until December 28, 2020. For the country and its regions the age-stratified percentage of reported cases are shown with a 95% confidence interval.
As the pandemic deepened during the year, the number of tests as well as the number of positive Covid-19 increased. The evolution of the percentage of cases reported for Colombia and some its regions during the year 2020 is presented in fig. 5. Besides the pandemic outbreak date being different in each region, we consider data for a department or city only after it has reported its first 40 fatal cases, resulting in different initial dates in the time axis for different regions. Due to the delay between onset-to-death, in most of the regions already a number of cases had been registered before the first death was reported, explaining the initial decay during the first weeks of the pandemic of the percentage of cases reported. Afterwards, the most important feature in all cases is the steady rising during the year of the percentage of reporting, yet reaching beyond the 50% only in a few regions, and the narrowing of the confidence intervals as the number of cases reported increased. This behavior goes hand in hand with the rising in the number of daily test for Covid-19 in the country during that period. Colombian testing capability has been insufficient during the pandemic, with an accumulated positivity rate of 23% and a daily percent positive that, except during the first two months of the pandemic, has remained above 10% [18]. Nonetheless, the country has increased its testing capacity considerably, going from 2000 daily tests at the end of March to being able to perform around 45000 in July and more than 50000 by the end of 2020. It can be seen that by the last week of April the percentage of cases reported in Colombia starts to rise from 22% to reach 43% by the end of December 2020. The observed plateau between June and August coincides with a peak of positive cases reported in Colombia. Even though the number of daily tests also incremented on those dates, its rate did not match the rate at which new cases and, more importantly, new deaths rose. The effect of this peak of detected cases is apparent in almost all regions, where after September a continuous increment in the percentage of report is noticeable.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Evolution of the percentage of cases reported for Colombia and some its regions during the year 2020. For each region the 95% confidence interval of age-aggregated percentage of reported cases is shown.
At the level of regions, our results show correlations with local public policies that had being carried out. Some examples can be clearly identify from fig. 5. For instance, early on in the pandemic Boyacá closed its borders [19], reopening them only during the second semester of 2020. This caused a surge in the number of cases by the end of October and beginning of November. Nonetheless, despite the pronounced peak in the number of cases, the testing capacity was enough to keep level the reporting percentage over the course of those months. Amazonas, the largest department in Colombia by area and one of the less populated, constitutes another interesting example. It hit the headlines several times because it had the largest number of deaths per inhabitant at the beginning of the pandemic [20]. As a consequence, the number of test in the region was increased to the point that it became the region with more performed tests per inhabitant in the country. The percentage of cases report sharply increased during these early months, only to stagnate in July at a level well below the country’s average.
IV. DISCUSSION
Our results present a detailed picture of how the Covid-19 infection has been tracked in Colombia during the year 2020. Yet, before commenting on some of the issues that they rise, a few words on their stability are called for. We notice that the figures in our analysis are sensitive to the chosen baseline CFR. For this work we selected the data reported by the Republic of Korea [16] (see also Table II), as this country tracking of the Covid-19 infections for the time span studied was considered thorough. A selection of a different benchmark country should lead to changes in the values present here, nevertheless, we expect the observed trends to remain the same. Furthermore, taking into account Colombia’s demographics should damps those effects. This, as we noticed before, yields, for example, a lower blCFR for Colombia as compared to the one of the Republic of Korea.
The inclusion of the country’s demographics to estimate its CFR and those of its regions is the most relevant feature of our work. This allows us to deal with Covid-19’s mortality variability in different age-groups, arguably one of the main factors driving the pandemic, and to account for its effects in the sub-report estimation. In particular, the larger vulnerability of older population compared to younger population explains the observed tendency of Colombia’s departments with a younger populations towards a lower blCFR than the country’s value (see Table III). Its effects on the corrected CFR and the percentage of cases reported, though less intuitive, are appreciable too. Despite the testing strategies implemented in Colombia not having uniformly sampled the population [18], the majority of it has been done on the population under 50 years old. This notwith-standing, and contrary to the expectations, there is a higher percentage of cases reported for the population with 70 years or more, and a noticeable gap between it and the percentage of report in the younger population. The higher vulnerability of the older age-groups helps explaining this behaviour too. Firstly, as we already clarified, for these age groups the blCFR is larger. Secondly, contrary to what happens to the younger population, in which most of the infected individuals only develop mild symptoms [21, 22] and many of the cases pass undetected, in the older population most of the infected individuals present clear symptoms, are therefore tested and their cases detected.
To conclude, we remark that our results are qualitatively consistent with the ones reported by Russell et al. [12] for Colombia. The differences in scales both in time and percentage of report are due to the different choice on benchmarks. While our delay density distribution f (t) is modeled from the the onset-to-death data for Colombia, in their work they use hospitalisation-to-death data from Wuhan [23], which may explain the shift in time of the first peak of reporting. They also use the CFR of Covid-19 for China [23], whereas our accounting of the country’s demographics, noticing that Colombia’s population is younger, leads to a lower baseline CFR, ultimately leading to our lower estimation of the percentage of cases reported.
V. LIMITATIONS
Our study relays on some assumptions that limit the reach of our results:
All of our estimations are linked and biased by the CFR of the benchmark country. In particular, our determination of the blCFR is very sensitive to it. Hence, small changes in the benchmark CFR can lead to considerable changes in the percentage of cases reported.
We assume under-reporting is the only ground for the deviation of the CFR from the baseline CFR. A more comprehensive approach should consider additional factors, like the burden of the health-care system and other socio-economical factors that can influence the capacity of a country or region to track the Covid-19 pandemic.
We do not account for comorbidities of the population which can influence the vulnerability (i.e. the baseline CFR) of a country or a region [24].
Our results ignore fatal cases under-counting. A factor that could be relevant for the case of Colombia [25].
We do not take into account different strains of Covid-19 and the different CFRs for each type [26, 27].
VI. CONCLUSIONS
In this study we present a comprehensive analysis of the percentage of Covid-19 cases reported in Colombia, providing a clearer picture of the magnitude of the pandemic in this country as of December 28, 2020. Specifically, we estimate that the 1’594.497 of confirmed positive cases reported during 2020 represents only the 44% of the total number of infected people in Colombia during this period. In Bogotá, which accounts for around a third of the reported cases in the country, the percentage of report was only of 48%.
Our estimation accounts for both the time delay between symptom’s onset and death caused by the Covid-19 disease, and the country’s, its regions’ and cities’ demographics in order to estimate their local CFR. It is worth stressing, that this last feature in our method provides it with a sensitive account of the age-dependent effects of Covid-19, not present, for instance, in [12], which allows us to study the under-reporting of cases in each of the regions of the country accounting for their demographic particularities. Thus, we were able to identify more vulnerable departments, having a large CFR, from those expected to have a lower mortality.
We show that the overall value of the percentage of cases reported by the country conceals the large inhomogeneity of its efforts to trace the infection in its territory, with a marked tendency for departments lying outside the Andean region to have a lower percentage of report. We provide a twofold explanation for the observed sub-report differences in Colombia’s regions. The first relevant factor was the country’s policy to track the infection. In it, much of the Covid-19 testing was concentrated in the Andean region, where the largest fraction of the population lives, leaving the departments in the periphery with smaller testing programs. The second factor is less evident and closely linked with the regions demographics. Due to the greater vulnerability of the older population against Covid-19, the CFR for this group is larger than for other groups in the population, making the percentage of reported cases for older population in all regions to be significantly higher than that for the younger population.Therefore, in departments far from the center of the country, where older age-groups correspond to smaller fractions of the population, this factor pushes the percentage of report towards lower values.
Finally, our results could be of use to contrast with seroprevalence studies for Colombia during the 2020 [28, 29] in order to estimate the real size of the pandemic in the country. A relevant information in the present stage for the planning of the vaccination program of the Country.
Data Availability
We developed a Python library that eases the extraction, load and transformation of raw data from the INS database. The code is freely available at https://gitlab.com/hubrain/covid19. Also, we designed a dashboard were we keep a daily record of how reporting percentages are changing at each region which can be found at http://covid19.hubrain.co. Furthermore, the code to reproduce the figures and tables here presented is in https://gitlab.com/hubrain/covid19-paper.
DATA AVAILABILITY
We developed a Python library that eases the extraction, load and transformation of raw data from the INS database. The code is freely available at https://gitlab.com/hubrain/covid19. We also maintain a dashboard, where a daily record of how percentage of cases reported is changing in Colombia and its regions, at http://covid19.hubrain.co. The code to reproduce the figures and tables presented in this document can be found at https://gitlab.com/hubrain/covid19-paper.
ACKNOWLEDGMENTS
We kindly acknowledge stimulating discussions with Luis Fernando García Moreno, Marcela Henao Tamayo, and Rafael Hurtado.
Footnotes
We improved the overall writing quality of the paper. Also, we added some geographical analysis.
References



