
Abstract
Background As part of a concerted pandemic response to protect public health, businesses can enact non-pharmaceutical controls to minimise exposure to pathogens in workplaces and premises open to the public. Amendments to working practices can lead to the amount, duration and/or proximity of interactions being changed, ultimately altering the dynamics of disease spread. These modifications could be specific to the type of business being operated.
Methods We use a data-driven approach to parameterise an individual-based network model for transmission of SARS-CoV-2 amongst the working population, stratified into work sectors. The network is comprised of layered contacts to consider risk of spread in multiple encounter settings (work-places, households, social and other). We analyse several interventions targeted towards working practices: mandating a fraction of the population to work from home, using temporally asynchronous work patterns and introducing measures to create ‘COVID-secure’ workplaces. We also assess the general role of adherence to (or effectiveness of) isolation and test and trace measures and demonstrate the impact of all these interventions across a variety of relevant metrics.
Results The progress of the epidemic can be significantly hindered by instructing a significant proportion of the workforce to work from home. Furthermore, if required to be present at the workplace, asynchronous work patterns can help to reduce infections when compared with scenarios where all workers work on the same days, particularly for longer working weeks. When assessing COVID-secure workplace measures, we found that smaller work teams and a greater reduction in transmission risk led to a flatter temporal profile for both infections and the number of people isolating, and reduced the probability of large, long outbreaks. Finally, following isolation guidance and engaging with contact tracing alone is an effective tool to curb transmission, but is highly sensitive to adherence levels.
Conclusions In the absence of sufficient adherence to non-pharmaceutical interventions, our results indicate a high likelihood of SARS-CoV-2 spreading widely throughout a worker population. Given the heterogeneity of demographic attributes across worker roles, in addition to the individual nature of controls such as contact tracing, we demonstrate the utility of a network model approach to investigate workplace-targeted intervention strategies and the role of test, trace and isolation in tackling disease spread.
Introduction
Globally, many countries have employed social distancing measures and non-pharmaceutical interventions (NPIs) to curb the spread of SARS-CoV-2 [1]. For many individuals, infection develops into COVID-19 disease, with symptoms including fever, shortness of breath and altered sense of taste and smell, potentially escalating to a more severe state which may include pneumonia, sepsis, and kidney failure [2]. In the United Kingdom (UK), the enaction of lockdown on 23rd March 2020 saw the closure of workplaces, pubs and restaurants, and the restriction of a range of leisure activities. As the number of daily confirmed cases went into decline during April, May and into June [3], measures to ease lockdown restrictions began, with the re-opening of some non-essential businesses and allowing small groups of individuals from different households to meet up outdoors, whilst maintaining social distancing.
By the end of September 2020, exponential growth had returned in almost all regions of the UK [4, 5], with subsequent attempts to curtail growth by introducing stricter controls. Whilst lockdown has been a strategy used around the world to reduce the public health impacts of COVID-19, it is important to recognise that such strategies are very disruptive to multiple elements of society [6, 7], especially given that restrictions are largely unpredictable to the local populous and businesses.
As part of collective efforts to protect public health by disrupting viral transmission, businesses also need to act appropriately by taking all reasonable measures to minimise exposure to coronavirus in workplaces and premises open to the public. In the UK, each of the four nations (England, Wales, Scotland, Northern Ireland) has published guidance to help employers, employees and the self-employed to work safely [8–11]. Adjustments in working practices can result in changes to the amount, duration and/or proximity of interactions, thereby altering the dynamics of viral spread. These modifications could be variable depending upon the type of business being operated and may include limiting the number of workers attending a workplace on any given day, as well as introducing measures to make a workplace COVID-secure, such as compulsory mask wearing and the use of screens. For this particular paper, we are interested in how interventions targeting workplace practices may affect infectious disease control efforts, whilst accounting for the variation in employee demographics across working sectors.
As part of the response to the COVID-19 pandemic, modelling analyses have been carried out pertaining to transmission of SARS-CoV-2 within specific parts of society, including health care workers [12], care homes [13], university students [14–16] and school pupils and staff [17–19]. Similarly to these studies, we may view the contact structure for the adult workforce as being comprised of several distinct layers. Knowledge of the structure of the network allows models to compute the epidemic dynamics at the population scale from the individual-level behaviour of infections [20]. More generally, such models of infectious disease transmission are a tool that can be used to assess the impact of options seeking to control a disease outbreak.
In this study, we outline an individual-based network model for transmission of SARS-CoV-2 amongst the working population. Informed by UK data, the model takes into account work sector, workplace size and the division of time between work and home. In addition to workplace interactions, contacts also occur in household and social settings. Given the heterogeneity of demographic attributes across worker roles, as well as the individual-based NPIs such as contact tracing, we demonstrate the utility of a network model approach in investigating workplace-targeted control measures against infectious disease spread.
Methods
We used simulations of an epidemic process over a network model to explore the impact of workplace-targeted non-pharmaceutical interventions in suppressing transmission of SARS-CoV-2 within a population of workers. In this section we detail: (i) the structure of the network model; (ii) the data sources used to parameterise the network contact structure; (iii) the model for SARS-CoV-2 transmission and COVID-19 disease progression; and (iv) the simulation protocol employed to assess the scenarios of interest.
Network model description
We used a multi-layered network model to encapsulate identifiable groupings of contacts. Our model was comprised of four layers: (i) households; (ii) workplaces; (iii) social contacts; and (iv) other contacts.
Household contact layer
To allocate workers to households, we sampled from an empirical distribution based on data from the 2011 census in England [21]. To obtain this distribution, we calculated the proportion of households containing 1 to 6+ people between the ages of 20 - 70 (Fig. S8). Thus, we omit children and the elderly from our analysis, an acknowledged simplification of the system. When sampling from this distribution, we restricted the maximum household size to six people in an attempt to reduce the amount of overestimation of the number of active workers mixing within households, which results from the assumption that everyone in a household is an active worker. Within each household, members formed fully connected networks.
Workplace contact layer
To disaggregate working sectors, we used data from the 2020 edition of the ONS ‘UK business: activity, size and location database’ [22]. Specifically, we took counts (for the UK) of the number of workplaces stratified into 88 industry divisions/615 industry classes (Standard Industrial Classifications (UK SIC2007)) and by workforce size (0 - 4, 5 - 9, 10 - 19, 20 - 49, 50 - 99, 100 - 249, 250+).
We assigned the industry types into one of 41 sectors (see Table 1 for a listing of the work sectors). We generated a set of workplaces and workplace sizes for each of the 41 sectors in a two-step process: first, we sampled from the relevant empirical cumulative distribution function of the binned workplace size data to obtain the relevant range. For a bounded range (all but the largest bin), we then sampled an integer value according to a uniform distribution that spanned the selected range. Since the largest data bin (250+ employees) is unbounded, in this instance we instead sampled from a shifted Gamma(1,100) distribution (shape and scale parameterisation, shifted to 250).
Within the network model, workplaces were grouped into the following 41 industrial sectors.
We stratified workplace contacts into static contacts and dynamic contacts. For static contacts, we constructed the network to allow for contacts both within a worker’s workplace (most common) and to other workplaces in the same industrial sector (less common). These contacts occurred every workday, unless either person was working from home, and remained unchanged throughout the simulation. We generated static contacts using a ‘configuration model’ style algorithm, allowing the specification of a desired degree distribution for each sector. We adapted the standard configuration model to allow a variable amount of clustering, where a higher value of clustering led to more contacts being made within a workplace compared to between different workplaces. We subjectively assumed throughout that the probability of making contact with an individual in another workplace compared to an individual within the same workplace was 0.05. Unlike the standard configuration model, we did not allow edges to be made with oneself or repeated edges. As such, the resulting degree distribution was an approximation of the distribution used as an input. For the steps defining the algorithm, see Section 1.1 of Supporting Text S1.
Dynamic contacts represent those that may occur between workers and non-workers, though still in the workplace, for example contacts between retail workers and shoppers. These were regenerated every day: for each worker (not working from home), we generated a number of dynamic contacts from a sector-specific degree distribution and assigned the recipients at random. These were not clustered in any way; that is, every person in the population had an equal probability of being the recipient, though we do not allow repeated edges or edges with oneself. Given the number of dynamic contacts per person is small compared to the size of the population, the desired degree distribution was approximately preserved.
Social contacts
Social contacts were generated in two stages. First, we generated a ‘social group’ for each person. We used a similar configuration model style algorithm as for the generation of static workplace contacts, allowing the specification of a desired degree distribution. We adapted the standard configuration model to allow for greater clustering (which in this context relates to the probability that each contact is made with a friend-of-a-friend, compared to someone at random, set at 0.5) and did not allow edges with oneself or repeated edges. This resulted in an acceptable approximation of the desired degree distribution. The second step specified who a person socialises with each day: for each individual on each day, we sampled a subset of all possible social contacts to construct the social contacts made on that day. The number of social contacts made per day was specified by a degree distribution (but restricted by the size of their social group), which we allowed to differ between workdays and non-workdays. However, note that we did not enforce a correlation between the size of a person’s social group and the number of social contacts they made each day. We provide a description of the steps for constructing the social contact layer of the network in Section 1.2 of Supporting Text S1).
Other contacts
The final contact layer sought to capture random, dynamic, contacts made each day with any other individuals in the population (for example on public transport). We used a fixed daily probability of each individual interacting with any other individual in the network.
Contact parameterisation
We characterised the network structure across the various contact layers by applying a data-driven approach, using data from the University of Warwick Social Contact Survey [23, 24]. The Social Contact Survey was a paper-based and online survey of 5,388 participants in the United Kingdom conducted in 2010. We extracted records provided by 1,860 participants, with a total of 34,004 contacts (eligibility criteria are outlined in Supporting Text S2). These data informed the network construction parameters for the workplace and social layers, with stratification according to the work sector. We fit parameters for these contact distributions using maximum likelihood estimation via the FITDISTRPLUS package in R. We present a summary of network parameters in Table 2.
Description of network contact parameters. Lognormal distributions are described using a mean and standard deviation parameterisation. All values are given to 2d.p.
Workplace contacts
We also used the Warwick Social Contact Survey to parameterise the degree distributions for both static and dynamic contacts occurring in workplaces. For a full description of the workplace contact layer parameterisation, including the mapping between the ONS sectors and occupations listed in the Contact Survey, see Section 2.1 of Supporting Text S2.
We found that, in general across all work sectors, the daily number of workplace contacts displayed a heavy tail. Thus, we chose to fit (using maximum likelihood estimation) lognormal distributions to the data, which consistently provided stronger correspondence to the data than alternative choices of distribution across different occupations.
Social contacts
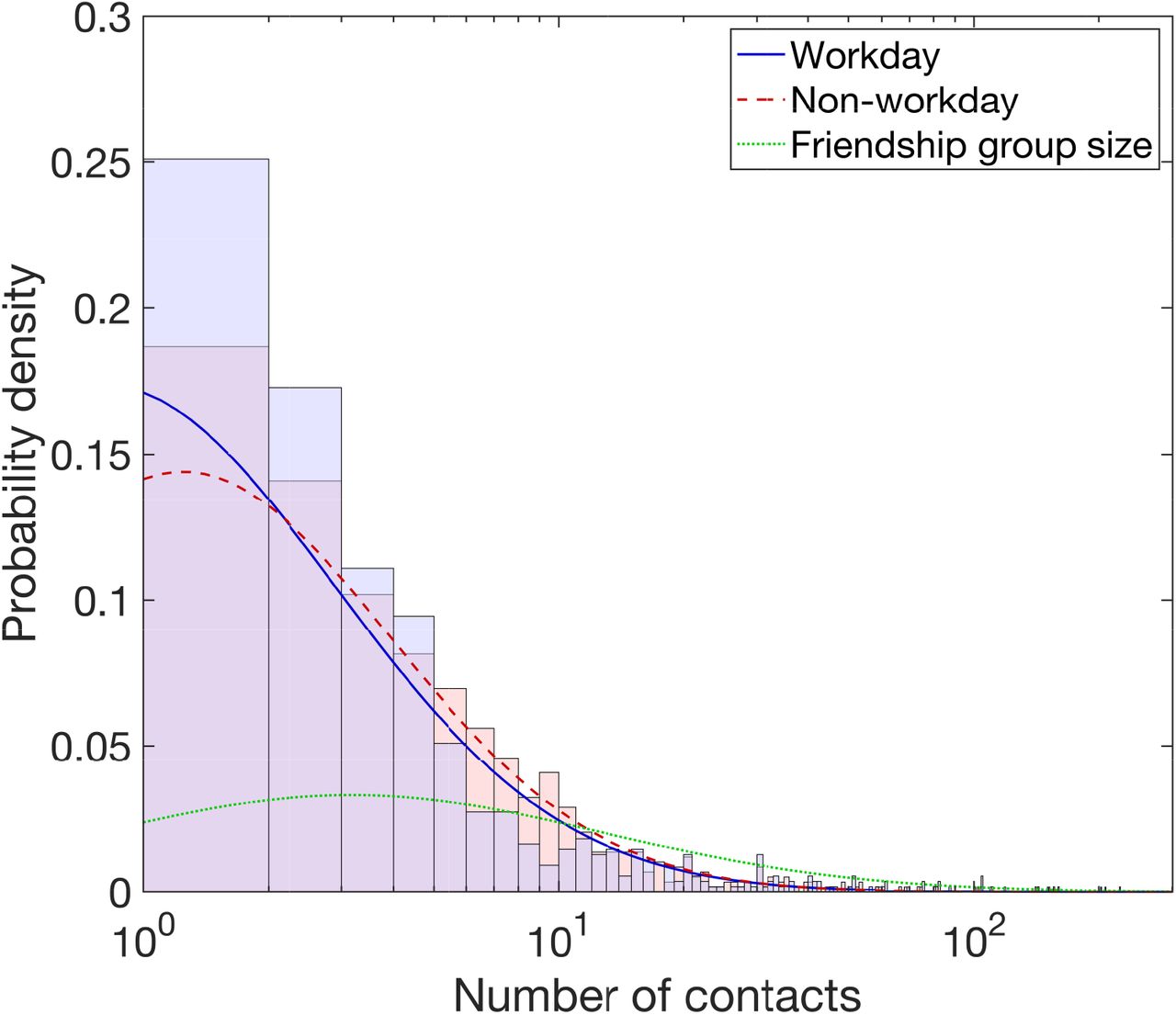
We used data from the Warwick Social Contact Survey to acquire a distribution of social group sizes and estimate the daily number of social contacts on both work and non-work days. To acquire a distribution of social group sizes, we scaled up the contacts recorded in the Warwick Social Contact Survey, resulting in a lognormal(3.14,1.41) distribution with a mean and standard deviation parameterisation (Fig. 1 and Table 2, full methodological details in Section 2.2 of Supporting Text S2).

All traces are plotted against the number of contacts, presented on a log scale. The stated lognormal distributions that follow are given under a mean and standard deviation parameterisation. We obtained a heavier tailed distribution for number of social contacts per day on non-workdays (red dashed line, lognormal(1.54, 1.15)) versus workdays (blue solid line, lognormal(1.40, 1.27)). The histograms show the associated empirical probability densities in a matching colour scheme. Friendship group sizes were sampled from a lognormal(3.14, 1.41) distribution, depicted by the green dotted trace.
Through fitting lognormal distributions in turn to the workday and non-workday data, we obtained lognormal(1.40,1.27) and lognormal(1.54,1.15) distributions for workday and non-workday social contacts, respectively (Fig. 1 and Table 2, for additional information see Section 2.3 of Supporting Text S2))
Other contacts
To capture individuals having other randomly occurring contacts, for each individual we sampled random connections according to a fixed daily probability of interacting with any other individual in the network. We parameterised the probability so each individual had, on average, one additional contact per day (Table 2). This results in a Poisson(1) distribution across the entire population.
Epidemiological model
Disease states
We ran a susceptible-latent-infectious-recovered (SEIR) type disease process on the network structure. Once infected, we assumed infectiousness could not start immediately (i.e. on the same day), with the earliest permitted moment being the following day. We assumed an Erlang-distributed incubation period, with shape parameter 6 and scale parameter 0.88 [25].
The distribution of infectiousness had a four day pre-symptomatic phase, followed by a seven day symptomatic phase. This gave a total of 11 days of infectivity and a minimum 12 day infection duration (for the full temporal profile, see Table 3). It was based on a Gamma(97.2, 0.2689) distribution, with shape and scale parameterisation, shifted by 25.6 days [26, 27]. Following completion of the infectious period, the individual entered the recovered state.
Description of epidemiological parameters.
Asymptomatic transmission
Infected individuals could be either asymptomatic or symptomatic, with an ascribed probability determining the chance of each individual being asymptomatic. There remains uncertainty in the fraction of COVID-19 cases that are asymptomatic and how that statistic may vary with age, however community surveillance studies have been performed to help reduce this uncertainty. Round 4 of the
REal-time Assessment of Community Transmission-1 (REACT-1) study found approximately 70% of swab-positive adults were asymptomatic at the time of swab and in the week prior [3]. To reflect the uncertainty in this value, which includes a portion of the previously stated estimate being presymptomatic infected individuals who would later go on to display symptoms, and the proportion of people who tested positive and were non-symptomatic being lower in round 5 at 50% [5], in each simulation we sampled the asymptomatic case probability from a uniform distribution within the interval 0.5 and 0.8.
There is currently limited data available to provide a robust quantitative estimate of the relative infectiousness of asymptomatic and symptomatic individuals infected with SARS-CoV-2, though there are some indications that asymptomatic individuals could be considered to be less infectious than symptomatic individuals [28, 29]. Therefore, we set an asymptomatic individual to have a lower risk of transmitting infection compared to a symptomatic individual, with the current uncertainty reflected by sampling the value for the relative infectiousness of an asymptomatic in each simulation replicate from a Uniform(0.3, 0.7) distribution. We applied the scaling consistently throughout the duration of infectiousness for asymptomatics, meaning there was no time dependence on the scaling term over the course of infectiousness.
Setting transmission risk
Attributing risk of transmission to any particular contact in a particular setting is complex. This is partly due to the huge heterogeneity in contact types, and partly due to the different scales of data: contact information is by its nature individual-based, whereas transmission rates are generally measured at the population level. Therefore, whilst we can attribute a relative risk to each contact type (home, work, social, other), there is an arbitrary scaling to translate these relative risks to an absolute growth rate of infection in the population.
For household transmission, we attributed a household secondary attack rate to each individual based on their household size. We sampled from a normal distribution whose mean value depended on the household size, based on estimates of adjusted household secondary attack rates from a UK based surveillance study [30]. The mean values used were: 0.48 for a household size of two, 0.40 for for a household size of three, 0.33 for a household size of four, 0.22 for a household size of five or above. The standard deviation of the normal distribution for households of size two or three was 0.06, and for households of four or above was 0.05.
For transmission risk in other settings, we performed a mapping from the Warwick Social Contact Survey [24] to obtain a relative transmission risk (see Supporting Text S3). To calibrate the relative transmission risks to achieve an uncontrolled reproductive number, Rt, with an average of approximately three for the initial phase of the outbreak, we applied a universal scaling of 0.8 to all of the above rates (see Supporting Text S4).
Isolation, test and trace
Testing and isolation measures
Upon symptom onset, workers adhering to guidance entered isolation for ten days. At that moment, fellow household members of the symptomatic case that adhere to guidance entered self-isolation for 14 days [31]. Individuals that are symptomatic and that will engage with the test and trace process undergo a test upon symptom onset. We included a two day delay before receiving the test result.
Adherence to isolation guidance and engagement with test and trace are defined by a specified probability that remains fixed throughout each simulation. For simplicity, we assumed that an individual either both adheres to guidance and engages with test and trace, or does neither.
Once isolation periods are begun they were seen out in full unless the test result was negative (false negative probability of 0.13 [32]). On occasions where a negative result was given, household members would be released from isolation, as long as no other symptomatic cases (that are confirmed positive or awaiting test result) were present in the household. The index case remained in self-isolation if they had independently been identified via contact tracing as a contact of a known infected; otherwise, that individual also left self-isolation.
Forward contact tracing
Identified contacts of a confirmed case that would adhere to self-isolation guidance, spent up to 14 days in self-isolation [33]; we set the time required to be spent in self-isolation to elapse 14 days from the day the index case became symptomatic.
The modelled tracing scheme looked up contacts for an index case up to two days before onset of symptoms. We assumed that the probability of an individual being able to recall their ‘dynamic’ contacts diminishes with time, from 0.5 one day previously, reducing in increments of 0.1, such that the probability of successfully tracing a contact five days prior to the tracing occurring is 0.1. Once again, other assumptions could be explored and a wider range of assumptions, collectively, would generate more variation in the results. We give an overview of isolation, test and trace related parameters in Table 4.
Description of isolation, test and trace related parameters.
Simulation outline
We used the described model framework to evaluate the transmission dynamics of SARS-CoV-2 amongst the workforce under different workplace-targeted NPIs. We also assessed the role of adherence to the underlying social distancing guidance and engagement with test-and-trace.
We ran all simulations with a population of 10,000 workers and a simulation time corresponding to 365 days. For the default working pattern, we applied a simplifying assumption that all workers had the same working pattern of five days at the workplace (that can be considered to be Monday to Friday) and two days off (Saturday and Sunday). All individuals began the simulation susceptible, with the exception of ten individuals seeded in an infectious state; of whom we set between five to eight individuals as being asymptomatically infected (randomly sampled), with the remaining individuals (between two to five) symptomatic.
Our assessment comprised four strands. First, we studied how alterations to the proportion of workers who were working from home may alter the course of an outbreak. Second, we inspected the role of different working patterns upon the spread of infection. Third, we considered an introduction of COVID-secure workplace measures by capping work contacts and imposing a potential reduction on transmission risk in work settings. Finally, we analysed the impact of the level of adherence to isolation measures and test and trace interventions.
We outline each of the four assessments in further detail below. Across all sections of analysis, we were interested in measures associated with outbreak severity (size and peak in cases), extent of isolation (cumulative isolation time and daily peak) and outbreak duration. For each parameter configuration we ran 1,000 simulations, amalgamating 50 batches of 20 replicates. Each batch of 20 replicates was obtained using a distinct network realisation. Unless stated otherwise, we assumed the measures being studied in each piece of analysis began from day 15 (i.e. the outbreak had been ongoing for two weeks). We performed the model simulations in Julia v1.5.
Proportion of the workforce working from home
We first investigated the impact of specified fractions of the workforce working from home full time (i.e. five days a week). Throughout, we assumed a 70% adherence to testing, tracing and isolation measures. We initially tested the proportion of the workforce working from home (consistent across all sectors) from none (value 0) to all (value 1) in increments of 0.1. We also looked at a situation where subjectively chosen proportions of workers within each work sector work from home. We set this highest in office based roles (70% working from home), at a moderate level in primary and manufacturing trade occupations (for example, repair with 50% working from home and construction with 30% working from home), lower again in sales and customer service roles such as retail (20% working from home) and assumed those in the education, health, care home and social work sectors continued duties at the workplace (0% working from home). Overall, approximately 35% of the workforce was working from home.
Role of worker patterns
We explored two alternative choices related to the scheduling of workers being present at their usual workplace: (i) synchronous work pattern - workers returned to work for a given number of days, but all workers were scheduled to work on the same days; or (ii) asynchronous working pattern - workers all returned to work for a given number of days per week, with the days of return randomly assigned to each worker. We assumed a 70% adherence to testing, tracing and isolation measures.
COVID-secure workplaces
We define a workplace to be ‘COVID-secure’ if measures have been taken to reduce the number of contacts workers have and decrease the risk of transmission for those contacts that remain. We assessed all workplaces undergoing changes to their contact structures, combined with a possible reduction in transmission risk across work based contacts. We simulated all combinations of work team sizes of 2, 5 or 10, in conjunction with the scaling of the baseline work sector transmission risks (for both static and dynamic work contacts) by a factor of either 0.25, 0.5, 0.75 or 1. We assumed that everyone within a team was connected with each other, but with no one else at the workplace. We did not amend the distributions of dynamic contacts occurring at the workplace.
We assumed all individuals were at the workplace five days a week (Monday to Friday). As well as the baseline assumption of 70% adherence to testing, tracing and isolation measures, to inform the effects brought about solely by COVID-secure measures (in the absence of other NPIs), we also considered runs with 0% adherence (i.e. in the absence of) to test, trace and isolate measures.
Adherence to isolation, test and trace
Finally, we analysed the sensitivity of our model to the underlying adherence parameter, which defines whether or not an individual will both adhere to isolation guidelines and engage with test-and-trace. We sampled adherence between 0 and 1 in increments of 0.1. We assumed an identical adherence to isolation restrictions independent of the cause (presence of symptoms, household member displaying symptoms, identified as a close contact of an infected by contact tracing). For this analysis, we assumed all individuals were at the workplace five days a week (Monday to Friday).
Results
Working from home
One potential control option, where implementable and appropriate, is to ask a proportion of the workforce to work from home.
Assuming a 70% adherence to testing, tracing and isolation measures, we found that a greater proportion of the workforce working from home led to a lower Rt value during the early stages of the epidemic, flattening both the epidemic and proportion in isolation curves (Fig. 2, left column). Working from home is also effective in reducing the final size of the outbreak and total-isolation days, but ineffective for reducing outbreak duration (Fig. 3).

We considered three work practice and scheduling assumptions: (left column) percentage of workers that work from home; (central column) synchronous work pattern; (right column) asynchronous work pattern. From day 15, test, trace and isolate guidance was introduced, with an adherence of 70%. For the statistics (row one) infectious case prevalence, (row two) proportion in isolation, and (row three) the effective reproduction number Rt (the number of people, on average, each person that became infected at time t passed the virus onto), we present median temporal traces (solid lines), with the shaded regions in rows one and two representing the 50% prediction intervals. Lighter intensities correspond to: a higher fraction of workers working from home (ranging from 0 to 1; left column); a greater number of days per week being spent working from home rather than spent at the workplace (ranging from 0 to 5 days; central and right column).

We introduced NPIs from day 15 onwards, with varying proportions of the workforce working from home. N-U corresponds to non-uniform proportions working from home across the work sectors (vector of values following the order of work sectors in Table 1: [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.5, 0.2, 0.2, 0.5, 0.5, 0.2, 0.2, 0.2, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.2, 0.7, 0.7, 0.7, 0.3, 0.5, 0.7, 0.7, 0.0, 0.0, 0.0, 0.0, 0.2, 0.2, 0.2, 0.3, 0.7, 0.5, 0.2, 0.2, 0.7]). Outputs are summarised from 1,000 simulations (20 runs per network for 50 separate network realisations). We assumed an adherence of 0.7 in all runs. The white markers denote medians and solid black lines span the 25th to 75th percentiles. We give central and 95% prediction intervals in Table S4. (a) Proportion of the network infectious post introduction of NPIs (day 15 onwards). (b) Peak proportion of new infectious individuals. (c) Total isolation-days. (d) Outbreak duration. (e) Fraction of simulations meeting specified threshold criteria (see Table S5 for percentile summary statistics).
While one approach to implementing work from home measures is to have a standardised approach across all work sectors, we demonstrated the flexibility of the model construction by also simulating one example of a scenario with a differing proportion of workers within each work sector reverting to working from home (labelled N-U in Fig. 3). While our example configuration had about 35% of the overall population of workers working from home, the uneven distribution across sectors meant the returned summary statistic distributions and threshold event probabilities were actually comparable to roughly 20% of workers in all work sectors switching to working from home from day 15. In addition, the estimated outbreak duration distribution was similar to the scenario of all workers carrying on working at the workplace.
Asynchronous work schedules
Rather than stipulating a proportion of the population to work from home full-time (five days a week), we can instead consider the case where workers only work from home on specified days, and are physically present at their workplace otherwise.
Workers present at the workplace for five days per work week (the default assumption) resulted in a sustained rapid growth of the outbreak and a large epidemic peak. As one would expect, reducing the number of days workers are present at the workplace results in a significantly smaller outbreak (Fig. 2, central and right columns). For asynchronous work patterns, we see fewer infections and a lower infection peak when compared with scenarios where all workers work on the same days, particularly for working weeks with the majority of days spent at the workplace (Figs. 4(a) and 4(b)). In contrast, with four or five days of the working week being undertaken at the workplace, asynchronous work patterns gave higher median and upper bound estimates for total isolation-days than synchronous worker patterns (Fig. 4(c)). We would also expect asynchronous worker patterns to deliver an extended outbreak duration (Fig. 4(d)).

We introduced, from day 15, test, trace and isolate guidance, with an adherence of 70%. We tested separately synchronous (brown) and asynchronous (cyan) worker patterns. In all panels, we summarise outputs from 1,000 simulations (with 20 runs per network, for 50 network realisations). The white markers denote medians and solid black lines span the 25th to 75th percentiles. We give central and 95% prediction intervals in Table S6. (a) Proportion of the network infected post introduction of NPIs (day 15 onwards). (b) Peak proportion of new infectious individuals. (c) Total isolation-days. (d) Outbreak duration. (e) Fraction of simulations meeting specified threshold criteria (see Table S7 for percentile summary statistics).
When workers return to work on different working days, we see a reduced likelihood of a large outbreak compared with when individuals all work on the same days, especially when workers spend a larger number of days at their workplace. Specifically, for a scenario of spending five days at the workplace, over half of the population were infected in 52% of our model simulations using a synchronised working schedule, versus 41% of model simulations using asynchronous working schedules. We also observe that the chance of each individual, on average, being required to isolate in excess of 1% of the year was marginally reduced for one to three asynchronous working days at the workplace (Fig. 4(e), Table S7).
COVID-secure workplaces
We assessed the impact of all workplaces undergoing changes to their contact structures, combined with a possible reduction in transmission risk across workplace contacts. Inspecting runs with 70% adherence to isolation and contact tracing based NPIs, for the tested combinations of work team size and adjustments to transmission risk across workplace setting contacts, we found that smaller teams and a greater reduction in transmission risk per contact led to a flattening of the temporal profile of infectious prevalence Fig. 5. The effect of team size was relatively small compared to that from scaling the transmission risk, and was most pronounced when the latter did not occur. For very low transmission risk settings, the team size appeared to have almost no effect. The relationship with the proportion of people isolating over time was comparable (Fig. 6).

We display outputs for combinations of, from day 15, work team sizes being capped at 2, 5 or 10 people, paired with scaling the transmission risk in COVID-secure workplaces by 0.25, 0.50, 0.75 or 1.00, respectively. Also from day 15, trace, trace and isolate measures were introduced and had an adherence percentage of 70%. We assumed all individuals were at the workplace five days a week (Monday to Friday). Traces and regions in grey correspond to the period where no interventions were in place (up to day 15). The solid line gives the median trace. Filled regions depict the 50%, 90% and 99% prediction intervals (with dark, moderate and light shading, respectively).

We display outputs for combinations of, from day 15, work team sizes being capped at 2, 5 or 10 people, paired with scaling the transmission risk in COVID-secure workplaces by 0.25, 0.50, 0.75 or 1.00, respectively. Also from day 15, trace, trace and isolate measures were introduced and had an adherence percentage of 70%. We assumed all individuals were at the workplace five days a week (Monday to Friday). Traces and regions in grey correspond to the period where no interventions were in place (up to day 15). The solid line gives the median trace. Filled regions depict the 50%, 90% and 99% prediction intervals (with dark, moderate and light shading, respectively).
If we allow for larger work team sizes and lower magnitudes of reduction in transmission risk, there was an increased probability of large outbreaks occurring (Fig. 7(a)). In particular, reducing the transmission risk by 75% led to no simulation runs with more than half the population of workers becoming infectious. On the other hand, with work teams sizes of up to 10 people and no reduction in work setting contact transmission risk, nearly half of all runs (48%) resulted in a cumulative infectious case proportion in excess of 0.5.

We display outputs for combinations of, from day 15, work team sizes being capped at 2, 5 or 10 people, paired with scaling the transmission risk in COVID-secure workplaces by 0.25, 0.50, 0.75 or 1.00, respectively. Also from day 15, trace, trace and isolate measures were introduced and had an adherence percentage of 70%. We assumed all individuals were at the workplace five days a week (Monday to Friday). In all panels, transitions from dark to light shading represents a shift from lower to higher values. (a) Cumulative infectious case proportion greater than 0.2. (b) The outbreak lasting longer than 150 days. (c) Proportion of time in isolation (average per individual) exceeding 1% of the year. (d) Peak in proportion isolated above 0.05. We list simulated probabilities in Table S8.
We found there was less relative change in the estimated probability of an outbreak lasting longer than 150 days (Fig. 7(b)), when considering the maximum work team size for unmodified transmission risk (0.98 for work team sizes up to 2, 0.97 for work team sizes of up to 10) than when reducing the transmission risk by 75% (0.87 for work team sizes up to 2, 0.93 for work team sizes of up to 10). Furthermore, the smaller, shorter epidemics brought about by capping work team sizes to a maximum of two people and a 75% reduction in transmission risk was reflected in reductions in the amount of isolation required (Figs. 7(c) and 7(d),Table S8).
However, solely implementing COVID-secure guidance (i.e. capped work team size and potential reduction in transmission risk across workplace contacts, but no use of isolation or contact tracing), had a more severe effect on the projected outbreak size. With work teams sizes of up to 10 people and no reduction in work setting contact transmission risk, all runs resulted in over half of the individuals in the network becoming infected (Fig S9, Table S9). For the measure of outbreak duration, across transmission risk scalings there were shorter epidemic tails when the permitted work team size was up to 10 people, with probabilities ranging from 0.10 to 0.63, compared to a maximum work team size of two (probability range 0.31-0.70) or five (probability range 0.22-0.68).
Adherence to isolation guidelines and engagement with test-and-trace
Finally, we assessed the sensitivity of our model set-up to different levels of adherence. This applied to both the adherence to isolation measures and engagement with test-and-trace.
With sufficiently high adherence, the introduction of test, trace and isolate measures alone was enough to significantly decrease the size of the epidemic, with a swift decline in the effective reproduction number Rt to below 1 (Fig. 8). However, this came at the cost of significantly more people being in isolation at any one time, and the total number of isolation days. Both these effects were less pronounced at lower adherence levels.

For the statistics (column one) infectious case prevalence, (column two) proportion in isolation, and (column three) the effective reproduction number Rt (the number of people, on average, each person that became infected at time t passed the virus onto), we present median temporal traces (solid lines), with lighter intensity corresponding to a higher adherence to the interventions (ranging from 0 to 1). In columns one and two, shaded regions represent 50% prediction intervals.
Unsurprisingly, when adherence to the NPIs was high we found that a lower proportion of the network became infected, with a correspondingly lower epidemic peak (Figs. 9(a) and 9(b)). For even higher levels of adherence, the smaller size of the outbreak offset the increase in isolation directly due to greater adherence (Fig. 9(c)). When adherence was low, we observed a large, rapidly spreading outbreak. For increased adherence, there was a relative decrease in the epidemic size and a slight slow down in spread across the network, resulting in the expected duration of the outbreak becoming longer (Figs. 9(d) and 9(e)).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Distributions produced for incremental levels of adherence to the isolation and contact tracing NPIs, introduced from day 15. In all panels, outputs are summarised from 1,000 simulations (with 20 runs per network, for 50 network realisations). The white markers denote medians and solid black lines span the 25th to 75th percentiles. We give central and 95% prediction intervals in Table S4. (a) Proportion of the network infected post introduction of NPIs (day 15 onwards). (b) Peak proportion of new infectious individuals. (c) Total isolation-days. (d) Outbreak duration. (e) Fraction of simulations meeting specified threshold criteria (see Table S5 for percentile summary statistics).
Discussion
In this study, we have developed a model to analyse the spread of SARS-CoV-2 in the working population, considering the risk of spread in workplaces, households, social and other settings. We have investigated the impact of working from home, temporally asynchronous working patterns and COVID-secure measures upon disease spread and illustrated how strong adherence to NPIs is predicted to interrupt transmission.
Under our selected model assumptions, ‘switching off’ network connections by having a significant portion of the population of workers working from home was effective in reducing the final size of the outbreak and total-isolation days; we also recognise that flattening the epidemic curve would typically result in a prolonged outbreak duration with lower prevalence. It can be seen from UK data that an instruction to work from home where possible to do so formed part of a collection of measures that were effective in sending the initial wave of SARS-CoV-2 infection into decline [34]. Further, we have demonstrated that a non-uniform adoption (of working from home) across work sectors will not necessarily translate to outcomes equivalent to the overall fraction of the labour market who revert to working from home. A sector-specific approach may be explored to determine optimal combinations of work from home percentage across applicable sectors (where working from home is possible), whilst maximising the overall proportion of workers able to attend the workplace.
Another approach to modifying work-associated mixing patterns is to alter the scheduling of when workers attend the workplace. For asynchronous work patterns we observed fewer infections and a lower infection peak. We postulate similar outcomes for flexible start and finish times that suits an employee’s needs. There are also indications some businesses envisage to retain flexible working habits longer-term [35], incorporating flexible work times and working from home [36], which would result in the percentage of the UK workforce reporting a flexible working pattern increasing above a October-December 2019 estimate of 28.5% [37].
It is clear that not all work sectors would be able to implement a work from home policy or allow flexible, asynchronous work patterns. In April, during the first wave of infection in the UK, 46.6% of respondents to a UK-based survey reported having done any work from home in the reference week [38]. However, we have shown that the introduction of COVID-secure measures in the workplace that reduce the number and transmission risk of contacts between workers can help to stem the spread of the virus in the population, especially if other NPIs are not possible.
The use of these workplace-targeted interventions should be carefully considered, and the effect and fallout from each weighed against each other. Every decision has an impact on people’s lives and livelihoods. In the event of enforced alterations to working practices, it is vital to consider harms to businesses and to personal well-being and mental health, with those affected being fully supported. We believe that a sector-specific combination of workplace-targeted policies could help to both slow the spread of SARS-CoV-2 and reduce the negative impact to workers, as well as the people and businesses that depend on them.
Prior modelling studies have indicated that nationally applied NPIs (such as social distancing, self-isolation upon symptom onset and household quarantine) may reduce the spread of SARS-CoV-2 [39 – 41]. Our analysis corroborates these findings, implying that high adherence to isolation and tracing measures can break chains of transmission by reducing the quantity and riskiness of contacts. The ultimate success of contact tracing operations is dependent on the rapid detection of cases and isolation of contacts (for simplicity we applied a consistent two day turnaround time for this process, though there is observed non-uniformity and temporal variation in these distributions [42]). Given the burden when tracing large numbers of contacts, there is the potential the system could be overwhelmed when the incidence of new cases occurs at a rapid rate [43].
Nonetheless, multiple studies have demonstrated, through applying stochastic branching-process models, that the use of backward contact tracing (as a complement to forward contact tracing) to identify infector individuals and their other infectees can robustly improve outbreak control [44, 45]. Naturally, identification of infectors, and subsequent forward tracing of their contacts were they to be identified, adds to operational pressures. These considerations need to be balanced against finite resources, suggesting the use of a coupled health economic analysis to determine under what circum-stances backward contact tracing would be most efficient. Other operational considerations include the adoption of digital approaches to enable the application of tracing at scale [46].
Our data-driven approach to parameterise the work sector populations and contact structures highlights the heterogeneities that are present in the system. However, there are characteristics of the underlying contact structure that our model formulation does not presently capture, whose inclusions may yield a better understanding of the impact of an infectious disease outbreak. We have not considered clustering of individuals within an individual workplace to capture the fact that, for example, individuals who share an office will be exposed to higher risk. We would expect this to have a stronger effect upon transmission within larger workplaces. In addition, the risk of contracting COVID-19 at work, and the risk of developing serious or fatal COVID-19 should infection occur, will also depend on personal vulnerability [47]. Strong determinants of individual risk are the presence of comorbidities and age, which could be correlated with job type. Furthermore, our system contained active workers only, with children and the elderly not present. The susceptibility to infection and severity of clinical outcomes generally differs in the youngest and eldest ages compared to those of adults. Thus, the in-corporation of age and risk stratification in an expanded network model and the consequential impact of the disease dynamics amongst the population merits further investigation.
Another aspect we have not included here is the presence of other respiratory infections. Such an extension would permit the study of test capacity requirements when levels of cough and fever are high due to non-COVID-19 causes. This is especially of concern during the winter period, with expectations of the national test and trace system being put under extra strain [48].
Lastly, while we have informed our model based on UK data, the model may be applied to other countries given the availability of the necessary data to parameterise the model. Modifying the framework to other contexts that have contacts occurring across several reasonably well-defined settings (such as school communities) we perceive as another viable extension.
Models of infectious disease transmission are one tool that can assess the impact of options seeking to control a disease outbreak. Here, we have presented a network model to study epidemic spread of SARS-CoV-2 amongst a population with layered contacts capturing multiple encounter settings, including distinct work sectors. Our work demonstrates the potential uses of this choice of model framework in generating a range of epidemiological measures, which may be analysed to assess the impact of interventions targeting the workforce.
Author contributions
Conceptualisation: Michael J. Tildesley; Louise Dyson; Matt J. Keeling; Edward M. Hill; Benjamin D. Atkins.
Data curation: Edward M. Hill; Benjamin D. Atkins; Louise Dyson; Michael J. Tildesley.
Formal analysis: Edward M. Hill; Benjamin D. Atkins; Louise Dyson; Michael J. Tildesley.
Funding acquisition: Michael J. Tildesley; Louise Dyson; Matt J. Keeling.
Investigation: Edward M. Hill; Benjamin D. Atkins; Louise Dyson; Michael J. Tildesley.
Methodology: Edward M. Hill; Benjamin D. Atkins; Matt J. Keeling; Louise Dyson; Michael J. Tildesley.
Software: Edward M. Hill; Benjamin D. Atkins; Louise Dyson; Michael J. Tildesley.
Supervision: Michael J. Tildesley; Louise Dyson.
Validation: Edward M. Hill; Benjamin D. Atkins; Louise Dyson; Michael J. Tildesley.
Visualisation: Edward M. Hill; Benjamin D. Atkins; Matt J. Keeling; Louise Dyson; Michael J. Tildesley.
Writing - original draft: Edward M. Hill; Benjamin D. Atkins.
Writing - review & editing: Edward M. Hill; Benjamin D. Atkins; Matt J. Keeling; Louise Dyson; Michael J. Tildesley.
Financial disclosure
This work has been supported by the Engineering and Physical Sciences Research Council through the MathSys CDT [grant number EP/S022244/1] and by the Medical Research Council through the COVID-19 Rapid Response Rolling Call [grant number MR/V009761/1]. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Data availability
The University of Warwick Social Contact Survey data contain confidential information, with public data deposition non-permissible for socioeconomic reasons. These data are available on request from the authors to researchers who meet the criteria for access to confidential data. All other data utilised in this study are publicly available, with relevant references and data repositories are stated within the main manuscript and Supporting Information. The code repository for the study is available at: https://github.com/EdMHill/covid19 worker network model.
Competing interests
All authors declare that they have no competing interests.
Supporting information items
Supporting Text S1
The process for generating the work and social contact layers of the network.
Supporting Text S2
A description of the data underpinning the contact distribution assumptions.
Supporting Text S3
Summary of the use of contact survey data to estimate the relative transmission risk across contacts between individuals occurring in household versus non-household settings.
Supporting Text S4
Overview of simulation outputs in the absence of any interventions.
Additional figures
Supplementary results.
Additional tables
Summary statistics to support the figures.
Footnotes
Supporting information updated
References




Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
0
Blogs/Media
Author Videos