
Abstract
The high proportion of transmission events derived from asymptomatic or presymptomatic infections make SARS-CoV-2, the causative agent in COVID-19, difficult to control through the traditional non-pharmaceutical interventions (NPIs) of symptom-based isolation and contact tracing. As a consequence, many US universities are developing asymptomatic surveillance testing labs, to augment existing NPIs and control outbreaks on campus. We built a stochastic branching process model of COVID-19 dynamics at UC Berkeley to advise optimal control strategies in a university environment. Our model combines behavioral interventions in the form of group size limits to deter superspreading, symptom-based isolation, and contact tracing, with asymptomatic surveillance testing. We find that behavioral interventions offer a cost-effective means of epidemic control: group size limits of twelve or fewer greatly reduce superspreading, and rapid isolation of symptomatic infections can halt rising epidemics, depending on the frequency of asymptomatic transmission in the population. Surveillance testing can overcome uncertainty surrounding asymptomatic infections, with the most effective approaches prioritizing frequent testing with rapid turnaround time to isolation over test sensitivity. Importantly, contact tracing amplifies population-level impacts of all infection isolations, making even delayed interventions effective. Combination of behavior-based NPIs and asymptomatic surveillance also reduces variation in daily case counts to produce more predictable epidemics. Furthermore, targeted, intensive testing of a minority of high transmission risk individuals can effectively control the COVID-19 epidemic for the surrounding population. We offer this blueprint and easy-to-implement modeling tool to other academic or professional communities navigating optimal return-to-work strategies for the 2021 year.
Significance Statement We built a COVID-19 dynamical model to advise strategies for optimal epidemic control in a university environment. Unique from previous work, our model combines behavior-based non-pharmaceutical interventions with asymptomatic surveillance; we find that a multi-factorial intervention approach uniting group size limits to deter superspreading, rapid symptom-based isolation, and contact tracing, with asymptomatic surveillance that prioritizes test frequency and turnaround time over test sensitivity, offers the most effective COVID-19 control. Contact tracing can amplify intervention gains from even extensively delayed isolations, and targeted, intensive testing of a high transmission risk minority can control epidemics for the surrounding community. We provide reopening recommendations and an easy-to-implement modeling tool to other academic or professional communities navigating optimal return-to-work strategies in the upcoming year.
Introduction
Non-pharmaceutical interventions (NPIs) to control the spread of infectious diseases vary in efficacy depending on the natural history of pathogen that is targeted (1). Highly transmissible pathogens and pathogens for which the majority of onward transmission events take place prior to the onset of symptoms are notoriously difficult to control with standard public health approaches, such as isolation of symptomatic individuals and contact tracing (1). SARS-CoV-2, the causative agent in COVID-19, is a now a clear example of one of these difficult-to-control pathogens (2). While the first SARS-CoV was effectively contained via the isolation of symptomatic individuals following emergence in 2002 (3), at the time of writing, SARS-CoV-2 remains an ongoing public health menace that has infected more than 43 million people worldwide (4). Though the two coronaviruses are epidemiologically comparable in their basic reproduction numbers (R0) (3), SARS-CoV-2 has evaded control efforts largely because the majority of virus transmission events occur prior to the onset of clinical symptoms in infected persons (2)—in stark contrast to infections with the first SARS-CoV (3). Indeed, in many cases, SARS-CoV-2-infected individuals never experience symptoms at all (5–8) but, nonetheless, remain capable of transmitting the infection to others (9–13). Due to the challenges associated with asymptomatic and presymptomatic transmission (10), surveillance testing of asymptomatic individuals has the potential to play a critical role in COVID-19 epidemic control (14–16). Surveillance testing is always valuable for research purposes, but its efficacy as a public health intervention will depend on both the epidemiology of the focal infection and the characteristics of the testing regime. Here, we explore the effects of both behavior-based NPIs and asymptomatic surveillance testing on COVID-19 control in a university environment.
As the North American autumn advances, the United States leads the globe with over 9 million reported cases of COVID-19 (4), and universities across the nation continue to struggle to control epidemics in their campus communities (17). To combat this challenge, colleges have adopted a variety of largely independent COVID-19 control tactics, ranging from entirely virtual formats to a mix of in-person and remote learning, paired with strict behavioral regulations, and—in some cases—in-house asymptomatic surveillance testing (18). As the 2021 year draws closer, asymptomatic surveillance testing is likely to play a key role in university plans for expanding reopening in the new semester (18, 19). In March 2020, shortly after the World Health Organization declared COVID-19 to be a global pandemic (20), the University of California, Berkeley, launched its own pop-up SARS-CoV-2 testing lab in the Innovative Genomics Institute (IGI) (21) with the aim of providing COVID diagnostic services to the UC Berkeley community and underserved populations in the surrounding East Bay region. Though the IGI RT-qPCR-based pipeline was initially developed to service clinical, symptomatic nasopharyngeal and oropharyngeal swab samples (21), the IGI subsequently inaugurated an asymptomatic surveillance testing program for the UC Berkeley community, through which—at the time of this writing—over 13,000 faculty, students, and staff in the UC Berkeley community have since been serviced with over 60,000 asymptomatic surveillance tests and counting (22).
Here we developed a stochastic, agent-based branching process model of COVID-19 spread in a university environment to advise UC Berkeley on best-practice approaches for surveillance testing in our community and to offer guidelines for optimal control in university settings more broadly. Previous modeling efforts have used similar approaches to advocate for more frequent testing with more rapid turnaround times at the expense of heightened test sensitivity (14, 15) or to weigh the cost-effectiveness of various testing regimes against symptom-based screening in closed university or professional environments (16). Our model is unique in combining both behavioral interventions with optimal testing design in a real-world setting, offering important insights into efficient mechanisms of epidemic control.
Model design
Our model takes the form of a stochastic branching process model, in which a subset population of exposed individuals (0.5%, derived from the mean percentage of positive tests in our UC Berkeley community (22)) is introduced into a hypothetical 20,000 person community that approximates the campus utilization goals for our university in spring 2021. With each timestep, the disease parameters for each infected case are drawn stochastically from distributions representing the natural history of the SARS-CoV-2 virus, paired with realistic estimates of the timeline of corresponding public health interventions (2, 16, 23) (Fig. 1). Our flexible model (published here with open-access R-code (24)) allows for the introduction of NPIs for COVID-19 control in four different forms: (1) group size limits, (2) symptom-based isolations, (3) surveillance testing isolations, and (4) contact tracing isolations that follow after cases are identified through screening from symptomatic or surveillance testing. Because we focus our efforts on optimal surveillance testing regimes, we do not explicitly model other NPIs, such as social distancing and mask wearing; however, the effects of these behaviors are captured in our representation of R-effective (hereafter, RE) for both within-campus and out-of-campus transmission. RE is the product of the pathogen basic reproduction number (R0, approximately 2.2 for SARS-CoV-2(2)) and the proportion of the population that is susceptible to disease. RE is thus a dynamic value which corresponds to the number of new infections caused by a single infection at a given timepoint within a specified community.

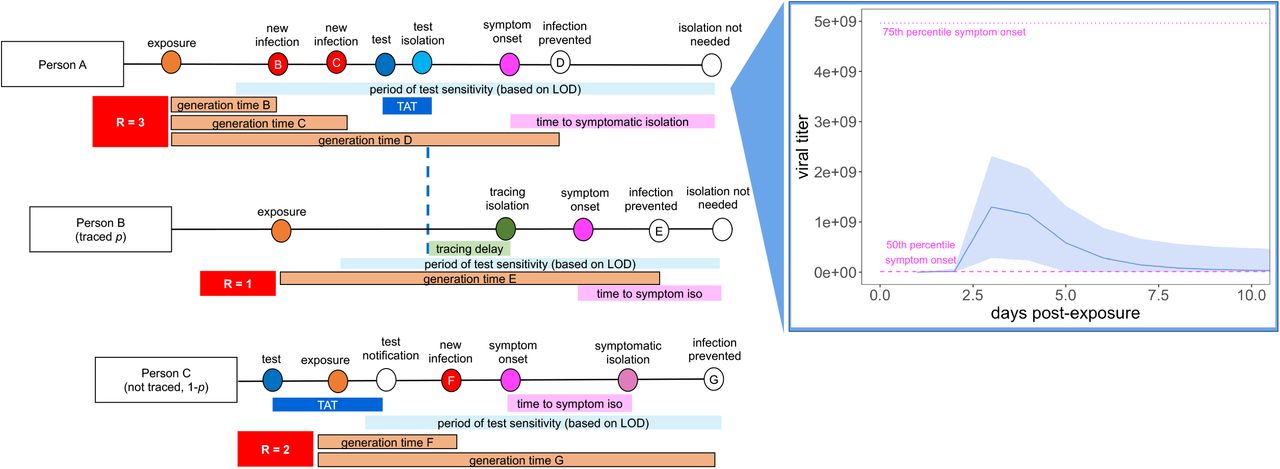
Person A is isolated through testing after exposing Person B and Person C. Person B is then isolated through contact tracing, while Person C is not traced but is nonetheless ultimately isolated through symptomatic surveillance. A viral titer trajectory (right) is derived from a within-host viral kinetics model (SI Appendiz), yielding the mean titer trajectory and 95% confidence interval shown here. The 25th and 75th titer threshold percentile for the onset of symptoms are depicted in pink, such that 30% of individuals modeled in our simulations did not present symptoms. Schematic is adapted in concept from Hellewell et al. (2020) (43).
For each infectious case, we generate an independent virus trajectory, using a within-host viral kinetics model structured after the classic target cell model (25–27). From each trajectory, we then infer both a timing of symptom onset and a time-varying transmissibility, which each manifest as a function of viral load. The timing of symptom onset corresponds to the timepoint at which an infectious individual’s virus trajectory crosses some threshold value for presentation of symptoms, which we draw randomly from a log-normal distribution with a mean of 107 virus copies per μl of RNA (patients with fewer than 106 cp/μl are generally not considered infectious (28–30)). By these metrics, roughly 30% of our modeled population presents as asymptomatic, in keeping with published estimates for SARS-CoV-2 (6, 7). We simulate dynamics for each infection by drawing a case-specific value for RE; a minority (10%) of cases are lost to the external community (e.g. an infectious UC Berkeley community member infects someone outside the UC Berkeley community) and are not tracked in our model, such that we report within-campus RE as the number of onward cases that a single infectious UC Berkeley community member causes within the same community (SI Appendix). In line with published estimates of Bay Area RE and initial asymptomatic test results in our community (22, 31), we represent within-campus RE as approximately one. For all onward transmission events, we compute a generation time based on each individual’s viral load trajectory (2); the majority of transmission events occur when the infectious host has higher viral titers, thus biasing new case generations towards earlier timesteps in an individual’s infection trajectory, as is realistic for COVID-19 (23) (Fig. 1) (SI Appendix).
Our model deviates from previous surveillance testing models by drawing RE from a negative binomial distribution (rather than a log-normal distribution (2, 14, 16)), with a dispersion parameter (k) equal to 0.16, corresponding to that estimated for the original SARS-CoV epidemic (32, 33). Though representation of RE in log-normal vs. negative binomial form will not change the average number of cases generated per epidemic, the negative binomial distribution replicates the dynamics of superspreading events, which are known to play an important role in SARS-CoV-2 dynamics (33–38). There is growing direct empirical evidence that COVID-19 epidemiology exhibits a negative binomial RE across multiple systems (38–41).
In addition to within-community transmissions, all individuals in the modeled population are also subjected to a daily hazard (0.15%) of becoming infected from an external source, based on published estimates of RE and COVID-19 prevalence in Alameda County (31). We report the mean results of 100 stochastic runs of each proposed intervention.
Results
Comparing behavioral NPIs for COVID-19 control
We first ran a series of epidemic simulations using a completely mixed population of 20,000 individuals subject to the infection dynamics outlined above to compare and contrast the impacts of our four NPIs on COVID-19 control. We introduced an initial population of 100 infectious individuals (0.5%) at timestep 0 and compared the effects of a single target intervention on epidemic trajectories after the first 50 days of simulation. Less intensive or intervention-absent scenarios allowed infectious cases to grow at unimpeded exponential rates, rapidly exhausting our susceptible supply and making it necessary to compare results at a consistent (and early) timepoint in our simulated epidemics.
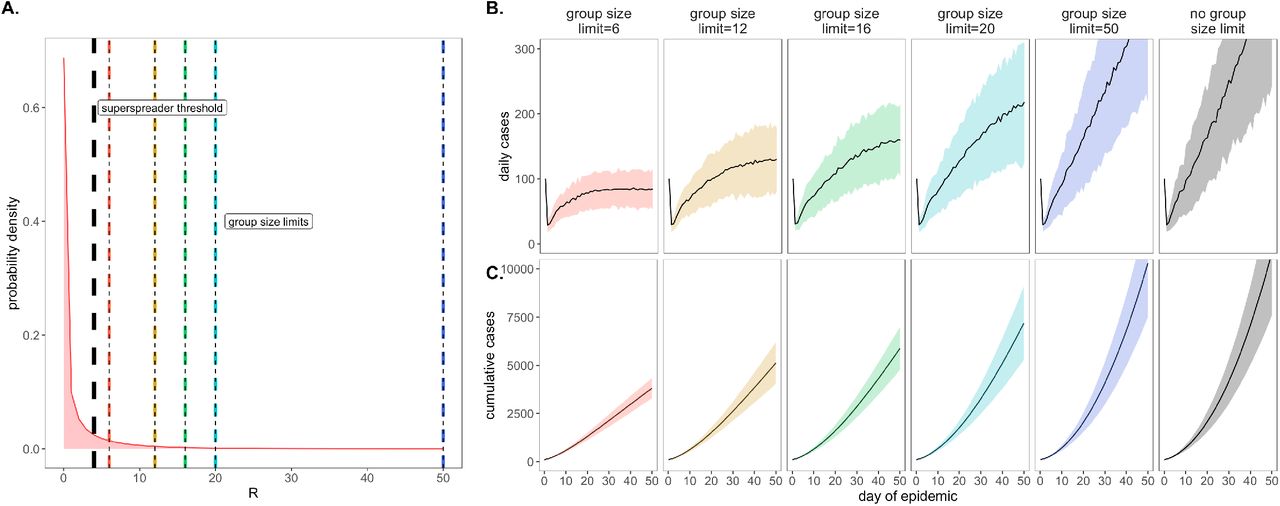
As a consequence of our representation of RE in negative binomial form (unique from other surveillance testing models), we first considered the COVID-19 control effectiveness of group size limits on in-person gatherings, which doubled as upper thresholds in transmission capacity (Fig. 2). Assuming that 90% of the modeled population adhered to assumed group size regulations, we found that limiting outdoor gatherings to groups of twelve or fewer individuals (the current regulation imposed by the City of Berkeley Public Health Office (42)), saved a mean of ∼5,700 cases per 50-day simulation (in a 20,000 person population) and corresponded to an RE reduction of nearly 0.25 (reducing RE from 1 to subclinical 0.75; Fig. 3; SI Appendix – Dataset S1). Even stricter group size limits of six or fewer individuals resulted in greater numbers of cases saved. By contrast, a large group size limit of 50 persons had no effect on epidemic dynamics; under assumptions of negative binomial RE, a group size limit of 50 will restrict transmission from only 0.018% of infectious individuals (Fig. 2). Gains in epidemic control from group size limits resulted from avoidance of superspreading events, an approach that was effective for negative binomial but not log-normal representations of RE that lack the transmission “tail” characteristic of a superspreader distribution (SI Appendix – Fig. S1).
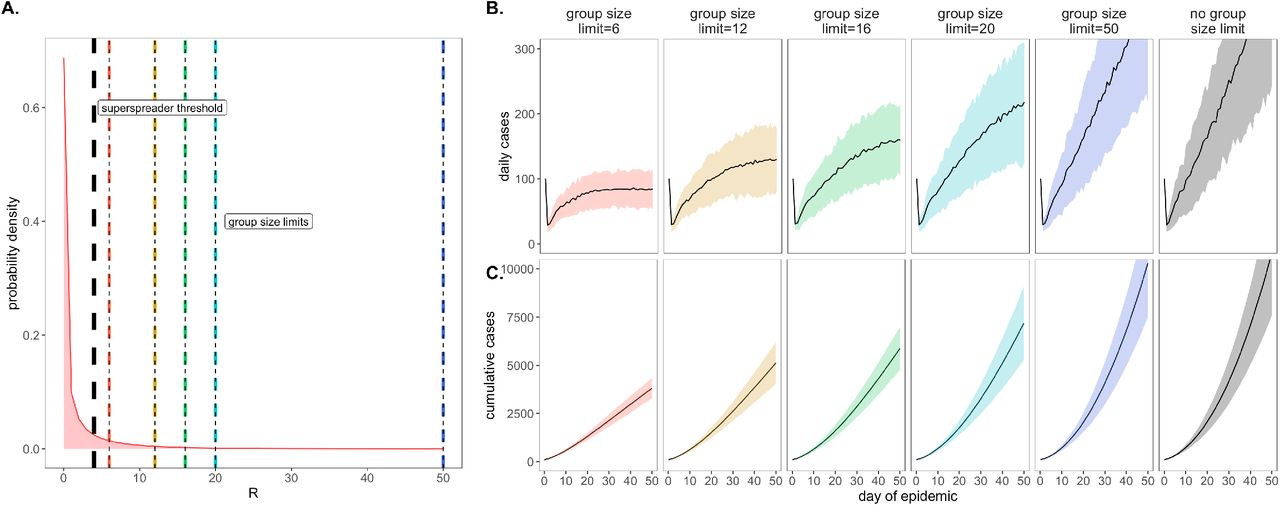
A. Negative binomial RE distribution with mean = 1.5 and dispersion parameter (k) = 0.16 (from this distribution, RE was further reduced to a mean of one via within-host viral titer dynamics; SI Appendix). The black vertical dashed line indicates the superspreader threshold of 4, above which all cases generated from a single individual are derived from the same transmission event (e.g. a superspreading event) and allocated the same generation time. The colored vertical dashes indicate group size limits that ‘chop the tail’ on the RE distribution. B. Daily new cases and, C. Cumulative cases, across a 50-day time series under corresponding, color-coded group size limits.
*Note: We assume that 80% of individuals at a gathering where a superspreading event takes place will become infected; thus, a group size limit of 50 will affect RE draws of 44 or higher: 4 independent transmission events will be allowed, but any superspreading event of 40+ generated cases will be removed from simulation. Only one superspreading event was permitted per infectious individual in our simulations.

A. Mean reduction in RE* and B. cumulative cases saved across 50-day simulated epidemics under assumptions of differing non-pharmacological interventions (NPIs). NPIs are color-coded by threshold number of persons for group-size limits, lag-time for symptom-based isolations, and mean turnaround time from test positivity to isolation of infectious individuals for testing isolations. For testing isolations, shading hue corresponds to test limit of detection (LOD) with the darkest colors indicating the most sensitive tests with an LOD of 101 virus copies/μl of RNA. Progressively lighter shading corresponds to LOD = 103, 105, and 107 cp/μl.
*Note: RE reduction (panel A) is calculated as the difference in mean RE in the absence vs. presence of a given NPI. The upper confidence limit (uci) in RE reduction is calculated as the difference in uci RE in the absence vs. presence of NPI. In our model, mean RE in the absence of NPI equals one and uci RE in the absence of NPI equals 7.6.
Importantly, by avoiding superspreading events, group size limits also reduced variance in daily case counts, yielding more predictable epidemics, which are easier to control through testing and contact tracing (2, 23, 43). Over the July 4 weekend, surveillance testing resources in our UC Berkeley community were overwhelmed and containment efforts challenged after a single superspreading event on campus (44).
We next investigated the impacts of variation in lag time to self-isolation post-symptom onset for the approximately 70% of individuals likely to present with COVID-19 symptoms in our modeled population (Fig. 3). At UC Berkeley, all essential students, faculty, and staff must complete a digital ‘Daily Symptom Screener’ before being cleared to work on campus; here, we effectively model the delay post-initial symptom onset to the time at which each individual recognizes symptoms sufficiently to report to the Screener and isolate. For each infected individual in our population, we drew a symptom-based isolation lag from a log-normal distribution centered on a mean of one to five days and assumed the entire population to be compliant with the selected lag.
A rapid, one day lag in symptom-based isolation was the single most effective intervention in our study, with a mean of more than 8,200 cases saved in a 50-day simulation (again, in a 20,000 person population), corresponding to an RE reduction of 0.68, from 1 to 0.32 (SI Appendix – Dataset S1). Longer lag times to isolation produced less dramatic results, but even an average five-day lag to isolation post-symptom onset nonetheless yielded more than 2,800 cases saved and reduced RE by a mean of 0.08. The efficacy of this intervention decreased at higher virus titer thresholds for symptom presentation, corresponding to a higher asymptomatic proportion (∼50%) of the population (SI Appendix – Fig. S2); some empirical findings suggest that these higher titer thresholds for symptom onset may more accurately reflect COVID-19 epidemiology (45). Because both group size limits and daily screening surveys to facilitate symptom-based isolation can be implemented without expending substantial resources, we advocate for these two approaches as particularly cost-effective COVID-19 control strategies for all university and small community environments—especially those lacking an on-site surveillance testing lab.
Comparing surveillance testing NPIs for COVID-19 control
Our primary motivation in developing this model was to advise UC Berkeley on best-practices for asymptomatic surveillance testing. As such, we focused efforts on determining the most effective use of testing resources by comparing surveillance testing across a range of approaches that varied test frequency, test turnaround time (TAT, the time from which the test was administered to the timing of positive case isolation), and test sensitivity (based on the limit of detection, LOD, or the minimum number of virus copies per μl of RNA detectable through asymptomatic surveillance testing).
We compared all permutations of surveillance testing NPIs, varying test frequency across biweekly, weekly, and every-two-week regimes, investigating TAT across delays of one to five and ten days, and exploring LODs of 101, 103, 105, and 107 virus copies per μl of RNA. These test frequency regimes reflect those under consideration at UC Berkeley today: from August-October 2020, UC Berkeley undergraduates residing in university residence halls have been subject to compulsory biweekly asymptomatic surveillance testing, while all other campus community members have been permitted to take part in voluntary testing with a recommended weekly or every-two-week frequency. TAT values in our model reflect the reality in range of testing turnaround times from in-house university labs like that at UC Berkeley to institutions forced to outsource testing to commercial suppliers (46), and LOD values span the range in sensitivity of available SARS-CoV-2 tests. The IGI’s RT-qPCR-based testing pipeline has a published sensitivity of 1 cp/μl (21), while the majority of SARS-CoV-2 RT-qPCR tests nationally are reliable above a 103 cp/μl threshold (47); less-sensitive antigen-based and LAMP assays report detection limits around 105 cp/μl (48, 49). Thus, in our model, only the purely hypothetical 107 cp/μl LOD (to our knowledge, no currently available test is so insensitive) should miss a substantial portion of infectious individuals, who typically present viral titers >106 cp/μl (28–30).
Across testing regimes broadly, we found test frequency and TAT to be the most influential parameters, with LOD exerting substantially less influence on epidemic dynamics, consistent with findings published elsewhere (14, 15). The top three most effective testing regimes incorporated assumptions of biweekly testing and one day TAT across LODs ranging from 101 to 105 cp/μl. These three scenarios yielded mean cases saved ranging from just over 8,100 to just over 7,600 in the first 50 days of simulation and produced an RE reduction capacity between 0.64 and 0.51 (Fig. 3; SI Appendix – Dataset S1). Halving test frequency to a weekly regimen, under assumptions of TAT=1 and LOD=101, resulted in a nearly 33% decrease in the NPI’s RE reduction capacity. Even more starkly, a single extra day lag from one to two-day TAT under biweekly testing conditions at LOD=101 cp/μl yielded a 28% decrease in RE reduction capacity. Indeed, testing turnaround times of ten days or more—not unusual in our current national environment (46)—were not significantly different from scenarios in which no intervention was applied at all. This result is a product of the rapid generation time of SARS-CoV-2 (2); most infectious individuals will have already completed the majority of subsequent transmissions by the time a testing isolation with a 10-day TAT is implemented. Nonetheless, encouragingly, reducing test sensitivity from 101 to 103 under a biweekly, TAT=1 regime decreased RE reduction capacity by a mere 1.4%, offering support to advocates for more frequent but less sensitive tests (50). Only the 107 cp/μl LOD appeared to significantly impact the effectiveness of the testing intervention regime (SI Appendix – Dataset S1).
Addition of a contact tracing intervention, in which 90% of infectious contacts were traced and isolated within a day of the source host isolation, to NPI scenarios already featuring either symptom-based or surveillance testing isolation enhanced each intervention’s capacity for epidemic control (SI Appendix – Fig. S3). Of note, contact tracing boosted performance of some of the poorest performing testing interventions, such that even those previously ineffective surveillance regimens with 10-day TAT nonetheless averted cases and significantly reduced RE when infectious contacts could be isolated. For a biweekly testing regime at LOD=101 cp/μl and TAT=10 days, the addition of contact tracing increased mean cases saved from ∼330 to >5,000 and increased RE reduction capacity from 0.00012 to 0.28 (SI Appendix – Dataset S2).
Optimizing combined NPIs for COVID-19 control
Our modeled simulations indicate that it is possible to achieve largely equivalent gains in COVID-19 control from NPIs in the form of group size limits, symptom-based isolations, and surveillance testing isolations—though gains from symptom-based behavioral isolations are jeopardized under assumptions of a higher proportion of asymptomatic individuals (SI Appendix – Fig. S2). Nonetheless, the most effective interventions are realized when behavioral control mechanisms are combined with surveillance testing (Fig. 4). Assuming a one day TAT and 101 cp/μl LOD, we found that adding (a) contact tracing with 90% adherence and a one-day lag, plus (b) symptom-based isolation with a one-day lag, plus (c) a group size limit of twelve persons to an every-two-week surveillance testing regimen could elevate the RE reduction capacity from 0.18 to 0.91 and almost double the ∼4,800 cases saved from the testing intervention alone (SI Appendix – Dataset S3). Combining interventions enabled less rigorous testing regimes to rival the effectiveness of biweekly surveillance testing without expending additional resources. In addition, combining interventions resulted in less variation in the cumulative case count, as many layers of opportunity for infection isolation helped limit the likelihood of a superspreading event spiraling out of control (SI Appendix – Fig. S4).

A. Mean reduction in RE, B. cumulative cases saved, and C. daily case counts for the first 50 days of the epidemic, across regimes of differing testing frequency and a combination of surveillance testing, contact tracing, symptomatic isolation, and group size limit interventions. All scenarios depicted here assumed test TAT, symptomatic isolation lags, and contact tracing lags drawn from a log-normal distribution with mean=1. LOD was fixed at 101 and group size limits at 12. Dynamics shown here are from biweekly testing simulations in which testing was limited to two test days per week.
Following on this theme, we also experimented with varying the distribution of days allocated to surveillance testing, without changing the frequency with which each individual was tested. Specifically, we explored biweekly, weekly, and every-two-week testing regimens in which tests were administered across two, five, and seven available testing days per week. More broadly distributed test days corresponded to fewer tests per day at a population level but, as with more intervention layers, resulted in less variation in the cumulative total cases because testing isolations more closely tracked daily exposures (SI Appendix – Fig. S4).
Modeling COVID-19 dynamics in the campus community
In our final analysis, we sought to advise the IGI explicitly by simulating epidemics in a more realistic, heterogeneous population modeled after the UC Berkeley campus community (Fig. 5). To this end, we subdivided our 20,000 person university population into a 5,000 person “high transmission risk” cohort and a 15,000 person “low transmission risk” cohort, assuming “high transmission risk” status to correspond to individuals (such as undergraduates), living in high density housing with a majority of contacts (90%) concentrated within the UCB community and “low transmission risk status” to correspond to individuals (such as faculty members or postdoctoral scholars) with only limited contacts (40%) in the UCB community. To add additional realism, we enrolled only 50% of each transmission risk group in our modeled surveillance testing program (to mimic adherence—though surveillance testing is compulsory for undergraduates residing in residence halls at UC Berkeley (22)). We found that targeted, biweekly testing of 50% of individuals in the high transmission risk cohort, paired with every-three-week testing of enrolled individuals in the low transmission risk cohort yielded mean RE reduction and cumulative cases saved on par with that achieved from weekly testing (and better than that achieved from every-two-week testing) of 50% of individuals in the population at large (Fig. 5). Targeting the highest transmission-risk populations with testing surveillance allowed us to save valuable testing resources while simultaneously controlling the epidemic for the entire community.
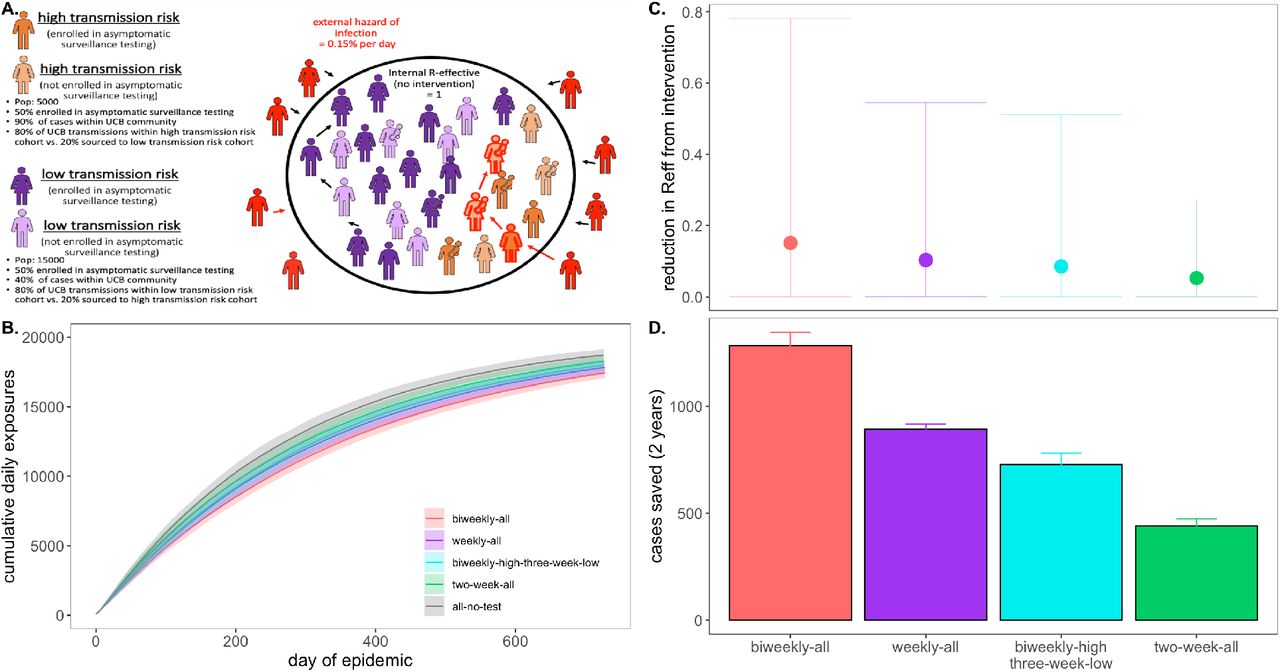
A. Schematic of transmission risk group cohorts in the heterogenous model. The population is divided into 5,000 “high transmission risk” and 15,000 “low transmission risk” individuals, for which, 90% and 40% of the proportion of transmission events take place within the UC Berkeley community, respectively. Of those transmission events within the Berkeley community, the majority (80%) are restricted within the same transmission risk group as the infector, while 20% are sourced to the opposing risk group. Half of each cohort is assumed to be enrolled in asymptomatic surveillance testing and subjected to the differing test frequency regimes depicted in panels B. through D. Panel B. shows the progression of cumulative cases across 730 days of simulation for each testing regime, while panel C. and D. give, respectively, the reduction in RE and the total cases saved achieved by each test regime vs. a no intervention baseline
Critically, our modeled interventions in the heterogeneous population simulations considered testing surveillance only; if additional behavioral NPIs were introduced—especially if applied to the 50% of the population not enrolled in asymptomatic testing—transmission reductions would be even more extensive. Notably, irrespective of intervention, the diminished transmissibility of the “low transmission risk” population in this heterogeneous model structure greatly reduced epidemic spread in subsequent simulations as compared with those presented previously in the perfectly mixed environment; as a result, we here compared interventions at the end of two years (730 days) of simulation, rather than following the first 50 days. The heightened realism of our heterogenous population generated slow-moving epidemics more closely resembling those we are currently witnessing in our university environment.
Discussion
We built a stochastic branching process model of SARS-CoV-2 spread in a university environment to advise UC Berkeley on best-practice strategies for effective asymptomatic surveillance in our pop-up IGI testing lab—and to offer a model for other institutions attempting to control the COVID-19 epidemic in their communities. While previous work has explored the isolated effects of specific NPIs—including group association limits (33), symptomatic isolation (2, 14–16, 23, 43), asymptomatic surveillance testing (14–16), and contact tracing (2, 23, 43)— on COVID-19 control, ours is the only model to date which investigates these interventions simultaneously and does so in a realistic and easily applicable setting. We offer an easy-to-implement modeling tool that can be applied in other educational and workplace settings to provide NPI recommendations tailored to the COVID-19 epidemiology of a specific environment.
Results from our analysis of behavior-based NPIs support previous work (2, 14–16, 23, 33, 43) in showing that stringent group size limitations to minimize superspreading events and rapid symptom-based isolations offer an effective means of epidemic control in the absence of surveillance testing resources. However, because of the unique natural history of the SARS-CoV-2 virus, for which the majority of transmission events result from asymptomatic or presymptomatic infections (2, 43), symptom-based NPIs cannot reduce epidemic spread completely, and small community environments will always remain vulnerable to asymptomatic case importation. Moreover, symptom-based NPIs pose less effective means of epidemic control under scenarios assuming a higher proportion of asymptomatic individuals; empirical evidence suggests that SARS-CoV-2 infection may result in asymptomatic infection in up to nearly 70% of the population in select environments (45). For this reason, our results emphasize the importance of asymptomatic surveillance testing to prevent ongoing epidemics in universities and other small community environments. As more data becomes available on both the proportion of asymptomatic infections and their contributions to SARS-CoV-2 transmission, the relative importance of group size interventions, symptom-based isolation, and asymptomatic surveillance testing in different epidemiological contexts will be possible to determine from our modeling framework.
As with behavioral interventions, our exploration of optimal surveillance testing regimes supports findings that have been published previously but with a few key extensions and critical novel insights. As has been recently highlighted (14, 15), we find that the most cases are saved under asymptomatic testing regimes that prioritize heightened test frequency and rapid turnaround time over test sensitivity. Importantly, we extend previous work to highlight how more rigorous testing regimes—and those combined with one or more behavioral interventions—greatly reduce variance in daily case counts, leading to more predictable epidemics. We find that the reduction in daily case variation is even more pronounced when test regimes of equivalent frequency are distributed more broadly in time (i.e. tests are offered across more days of the week), thus minimizing the likelihood of compounding transmission chains that may follow upon a superspreading event. Additionally, we demonstrate how a focused stringent testing regime for a subset of “high transmission risk” individuals can effectively control a COVID-19 epidemic for the broader community. Taken together, our model shows the utility of a multi-faceted approach to COVID-19 control and offers a flexible tool to aid in prioritization of interventions in different university or workplace settings.
Finally, our paper presents the only COVID-19 surveillance model published to date that combines asymptomatic testing with contact tracing, thus highlighting the compounding gains effected by these two interventions: contact tracing amplifies the control impacts of both symptom-based and surveillance testing-based isolations, such that even intervention scenarios assuming long delays in isolation after symptom onset or slow turnaround-times for test results can nonetheless greatly reduce the transmission capacity of COVID-19. These findings further emphasize the critical role that asymptomatic surveillance testing is likely to play in ongoing efforts to control COVID-19 epidemics into the 2021 year. Even limited surveillance testing may offer substantial gains in case reduction for university and workplace settings that already have efficient symptomatic isolation and contact tracing programs in place. Our model allows us to prioritize when and where these gains are most likely to be achieved.
Because we do not explicitly model SARS-CoV-2 transmission in a mechanistic, compartmental framework (51, 52), our analysis may overlook some more subtle insights into long-term disease dynamics. More complex analyses of interacting epidemics across larger spatial scales or investigations of vaccination delivery and the duration of immunity will necessitate implementation of a complete compartmental transmission model. However, our use of a stochastic branching process framework makes our model simple to implement and easily transferrable to other semi-contained small community environments, including a wide range of academic settings and workplaces (24). We make this tool available to others interested in exploring the impacts of targeted public health interventions—in particular, surveillance testing regimes—on COVID-19 control in more specific settings in the upcoming 2021 year. We at the University of California, Berkeley are committed to maintaining the safest campus environment possible for our community, using all intervention tools at our disposal. We advise those in similar positions at other institutions to employ the behavioral interventions outlined here, in concert with effective surveillance testing regimes, to reduce community epidemics of COVID-19 in the upcoming winter and spring seasons.
Data Availability
All code and corresponding data are made available in the article itself and in the cited open-access Github repository.
Supplementary Text
Text S1. Model Description
Our publicly-available Github repository (1) provides opensource code to reproduce all simulations and analyses presented in our paper. We summarize the practical implementation details of our modeling design for ease-of-access here.
Our model takes the form of a stochastic branching process model, in which a subset population of exposed individuals (0.5%, derived from the mean percentage of positive tests in our UC Berkeley community (2)) is introduced into a hypothetical 20,000 person community that approximates the campus utilization goals for our university in spring 2021. The model code builds up to a single function ‘replicate.epidemic()’ which runs a specified number of stochastic simulations from a defined parameter set, using the function ‘simulate.epidemic()’. Within the ‘simulate.epidemic()’ function, we first construct a population of 20,000 persons in the sub-function, ‘initiate.pop()’. Within this initiation function, each person in our population is individually numbered, assigned a viral titer trajectory that will be followed if that individual becomes infected (Text S2), and assigned a suite of disease metrics drawn stochastically from a specified set of parameter distributions, as outlined in Text S3.
Text S2. Within-host viral dynamics
For computational efficiency, we pre-generated 20,000 50-day individual titer trajectories and saved them as an .Rdata file, ‘”titer.dat.20K.Rdata”’. To generate these trajectories, we used a within-host viral kinetics model structured after the classic target cell model (3–5). Code for this model is available in the ‘model-sandbox’ folder of our Github release, under file ‘viral-load.R’, which iterates the following simple model and parameter values derived from Baccam et al. (2006) (6) for influenza:
 where Tc corresponds to the target cell population, β is the transmission rate of free virus to target cell invasion, k corresponds to the inverse of the duration of the virus eclipse phase, and σ corresponds to the inverse of the incubation period of an infected cell. p -then gives the burst size of a virus-infected cell and. equals the inverse of the lifespan of free virus subject to natural virus mortality and immune predation. Parameter values used to generate each titer trajectory (with a standard deviation of .3x the value of each parameter introduced to add stochasticity in each iteration) are derived from Baccam et al. (2006) and offer a reasonable approximation of the viral load trajectory for an infection with SARS-CoV-2 (7):
where Tc corresponds to the target cell population, β is the transmission rate of free virus to target cell invasion, k corresponds to the inverse of the duration of the virus eclipse phase, and σ corresponds to the inverse of the incubation period of an infected cell. p -then gives the burst size of a virus-infected cell and. equals the inverse of the lifespan of free virus subject to natural virus mortality and immune predation. Parameter values used to generate each titer trajectory (with a standard deviation of .3x the value of each parameter introduced to add stochasticity in each iteration) are derived from Baccam et al. (2006) and offer a reasonable approximation of the viral load trajectory for an infection with SARS-CoV-2 (7):

Text S3. Individual disease metrics
Figures in our paper are derived from 100x replications of each set of parameter values, which we manipulate to explore a range of non-pharmaceutical interventions (NPIs) to combat COVID-19 dynamics in our system. Our flexible model allows for the introduction of NPIs for COVID-19 control in four different forms: (1) group size limits, (2) symptom-based isolations, (3)surveillance testing isolations, and (4) contact tracing isolations that follow after cases are identified through screening from symptomatic or surveillance testing. These interventions modify the suite of disease metrics drawn upon model initiation for each numbered individual in the dataset. We summarize the disease metrics drawn at initiation for all members of the population here:
Time of next test: allocated based on the selected asymptomatic surveillance testing regime. We assume the week starts with day 1 on Saturday and day 7 on Friday. If n.test.days =2, then tests are distributed on Monday (day 3) and Friday (day 7) of each week. As timesteps advance and individuals reach their respective test days, the next test day is updated based on the testing regime (if biweekly, the next test day is advanced 3 days; if weekly, the next test day is advanced 7 days; if every-two-weeks, the next test day is advanced 14 days).
Beginning/end time of test sensitivity: based on test limit of detection (LOD) as specified at model outset, this corresponds to the timestep post exposure at which an individual viral titer crosses the threshold for being detectable by the chosen test, both as titers increase at the beginning of a disease trajectory and decrease at the end.
Adherence with testing regime: Y/N, allocated randomly across individuals based on the proportion of the population modeled as complying with the surveillance testing intervention (90% of individuals in all scenarios modeled in our paper).
Adherence with group limit: Y/N, allocated randomly across individuals based on the proportion of the population modeled as complying with the group size limits imposed at outset (90% of individuals in all scenarios modeled in our paper; see ‘number of potential onward cases generated for’ for how group size interacts with cases).
Adherence with contact tracing regimen: Y/N, allocated randomly across individuals based on the proportion of the population modeled as complying with the contact tracing intervention imposed at outset (90% of individuals in all scenarios modeled in our paper).
Time of symptom onset: determined by randomly drawing a titer limit for symptom onset for each individual from a lognormal distribution with a mean of 1e+07 cp/μl RNA and a standard deviation of 1e+04 cp/μl (8–10). The timing of symptom onset then corresponds to the time post-exposure at which each individual’s titer trajectory crosses the corresponding titer limit. According to this approach, under default parameter values, symptom onset occurred between 2 and 3 days post-exposure in our model, and ∼30% of the population never presented with symptoms at all (Fig. 1, main text).
Time of symptom-based isolation: based on delay lag post-symptom onset, drawn from a lognormal distribution with a mean of the specified number of days of symptom isolation lag (1-5 or infinity) and a standard deviation of 0.5 days.
Time of tracing-based isolation: based on contact tracing lag for those adhering to the contact tracing regimen in place. Parameter must be updated with each timestep until individual becomes infected; value then becomes fixed at time of infector isolation, plus corresponding lag drawn from a lognormal distribution with a mean of one day and a standard deviation of 0.5 days.
Time of testing-based isolation: based on turnaround time (TAT) to isolation post testing, drawn from a lognormal distribution with a mean of the specified number of delay days (1-5, 10, or infinity) and a standard deviation of 0.5 days. Parameter is updated when ‘time of next test’ is updated for each individual in our model.
Disease status: ‘susceptible’ = 0, ‘exposed’ = 3, ‘infectious’ = 1, ‘recovered’ =5. At onset, all individuals are modeled as susceptible, excepting the 0.5% which are introduced as infectious (1) to seed the epidemic.
Number of potential onward cases generated: Several figures in the main text of our manuscript present the RE reduction capacity of a specified intervention, which we calculate as the difference between the average of the number of potential onward cases generated and the number of actual onward cases generated for each individual after an intervention is adopted. To compute the number of potential onward cases generated for each individual, we first draw a number of possible cases from a negative binomial distribution with a mean of 1.5 and a dispersion parameter (k) of 0.16, based on the distribution of cases in the original SARS-CoV epidemic (11, 12). For each case generated from this draw, we next draw a generation time for that potential case, based on a weibull distribution with a shape parameter = 2.826 and a scale parameter = 5.665, as specified in Ferretti et al. (2020) (13), which biases infections early in an individual’s disease trajectory. We model ‘superspreading’ by assigning the same generation time to any cases exceeding four, assuming those cases to have been generated in the same transmission event. For example, if an individual draws a potential of five onward cases, each of those will be assigned an independent generation time, but if an individual draws a potential of eight onward cases, four of those will be assigned independent generation times, and four will be assigned the same generation time. Only one transmission event is permitted per infectious individual in our model.
Since each individual is already pre-assigned a within-host viral titer trajectory in our modeling framework, we next examine the viral load specified at the generation time of each potential onward transmission and determine if that case actually occurs probabilistically based on the value of the titer (higher titer infections are more likely to generate onward transmission events). We assume that an average dose of >106 cp/μl generates a successful transmission event (8–10) and determine the probability of exposure as
 , corresponding to a 63% probability of causing an onward infection for an individual with a viral load of 106 cp/μl. We then assess the probability of each of our possible cases occurring at the specified generation time, then re-compute the potential cases generated based on those which are permissible based on within-host titer trajectories. This results in an average of one onward transmission event per infectious individual in the absence of the NPIs examined here (but reflecting social distancing and mask wearing), which, as specified in the main text, is in line with current estimates from Alameda County, CA (14).
, corresponding to a 63% probability of causing an onward infection for an individual with a viral load of 106 cp/μl. We then assess the probability of each of our possible cases occurring at the specified generation time, then re-compute the potential cases generated based on those which are permissible based on within-host titer trajectories. This results in an average of one onward transmission event per infectious individual in the absence of the NPIs examined here (but reflecting social distancing and mask wearing), which, as specified in the main text, is in line with current estimates from Alameda County, CA (14).Number of actual onward cases generated: From the number of possible cases generated, we next apply the relevant intervention and iterate forward in time to determine the actual number of cases generated by each infectious individual across the time course of our modeled epidemics. For symptom and surveillance testing-based isolations, as well as contact tracing, no cases are generated if an infectious individual is isolated prior to the generation time of any possible onward cases. For NPIs in the form of group size limits, case reduction in our model is performed prior to the initiation of the epidemic time series. We assume that 80% of individuals present at a superspreading gathering could become infected, and for every individual abiding by a group size limit intervention, potential onward cases are removed from that individual’s total if they exceed 80% of the imposed group size limit in the simulation. For example, at a group size limit of 20, we assume that it would be possible for 16 people (80%) to become infected in a single instance, so an infectious individual who generates four independent transmissions and a four-person single-event superspreading transmission would be unaffected by this intervention. By contrast, an individual who generates four independent transmissions and a 20-person single-event superspreading transmission would be reduced to only causing those four independent transmissions. Our model is conservative in assuming that the group size limit-abiding individual does not attend any gatherings in excess of group size at all, thereby avoiding the entire superspreading event altogether (instead of allowing for 16 transmissions to take place in lieu of 20).

Following onset of infection, the timings of symptom-, tracing-, and asymptomatic testing-based isolations are then compared and the earliest time is selected as the actual mechanism (if any) of isolation for that individual. The number of actual onward cases generated is then updated if isolation occurs prior to some new case generations. Additionally, all individuals identified as infectious are additionally assigned the following metrics:
Isolation time of infector
Source of infection (external Alameda County vs. UC Berkeley community member)
ID number of infector, if from UC Berkeley
The cycle then repeats in the next timestep when all “actual infections” for each infectious individual are then assigned to new susceptible individuals. The epidemic continues with updated parameters for all newly exposed individuals until either the end of the time series is reached or no more susceptible individuals remain in the population.
Supplementary Figures

Figure replicates Fig. 2 (main text) at a log-normal distribution for RE, instead of negative binomial. A. Log-normal RE distribution with a mean of 1.5 and a standard deviation of 1.233. The black vertical dashed line indicates the superspreader threshold of 4, above which all cases generated from a single individual are derived from the same transmission event (e.g. a superspreading event) and allocated the same generation time. The colored vertical dashes indicate the group size limits that ‘chop the tail’ on the RE distribution. B. Daily new cases and, C. cumulative cases, across a 50-day time series under corresponding, color-coded group size limits.

Figure replicates symptom-isolation panels from Fig. 3 (main text) in top row, showing A. mean reduction in RE and B. cumulative cases saved across 50-day simulated epidemics under differing lag times to isolation, assuming a threshold titer for symptom onset by which ∼30% of the population presents as asymptomatic. A comparison at a titer threshold for which ∼50% of the population presents as asymptomatic demonstrates how a higher proportion of asymptomatic individuals in the population erodes the effectiveness of the symptom-based isolation intervention; asymptomatic status has no impact on the effectiveness of group size limits or asymptomatic surveillance testing interventions.

Figure replicates symptom-isolation panels from Fig. 3 (main text) in top row, showing A. mean reduction in RE and B. cumulative cases saved across 50-day simulated epidemics for NPIs of both symptom-based and testing-based isolation, across a range of different lag times or turnaround times to isolation (for, respectively symptom- or testing-based isolations). All testing-based interventions depicted are shown at a LOD=101 cp/μl. In the bottom row, A. mean reduction in RE and B. cumulative cases saved are depicted for a comparative intervention which adds an additional single-day lag in contact tracing to the respective symptom-based or testing-based isolation. Under these combined interventions, even previously ineffective testing interventions with 10-day TAT show gains beyond no intervention at all.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure extends results from Fig. 4 (main text), showing the standard deviation in cumulative cases from 50-day simulated epidemics, across regimes of differing testing frequency and a combination of surveillance testing, contact tracing, symptomatic isolation, and group size limit interventions. All scenarios depicted here assume test TAT, symptomatic isolation lags, and contact tracing lags drawn from a log-normal distribution with mean=1. LOD is fixed at 101 and group size limits at 12. Dynamics compare tests of differing frequency (biweekly, weekly, every two weeks) distributed across variable numbers of days in a given week (2,5,7). Additional layers of intervention and more testing days per week reduce the standard deviation in cumulative cases.
Legends for Datasets S1 to D3
Dataset S1. Averaged total cases saved and mean RE reduction across group size limit, symptomatic isolation, and surveillance testing NPIs. Summarized model output from 100x simulations across all NPIs presented in Fig. 2 and Fig. 3, main text. Confidence intervals represent 1.96*standard deviation in case reduction or RE reduction.
Dataset S2. Averaged total cases saved and mean RE reduction across symptomatic isolation, and surveillance testing NPIs, under regimes with and without contact tracing. Summarized model output from 100x simulations across all NPIs presented in SI-Appendix, Fig. S3.
Dataset S3. Averaged total cases saved and mean RE reduction across combined intervention approaches. Summarized model output from 100x simulations across all NPIs presented in Fig. 4, main text.
All other model output available as saved .Rdata files in our publicly-available Github repository (1).
Acknowledgments and Funding Sources
CEB was funded by the Miller Institute for Basic Research at the University of California, Berkeley, the Branco Weiss Society in Science Fellowship from ETH Zurich, a DARPA PREEMPT Cooperative Grant (no. D18AC00031), and a COVID-19 Rapid Response Research grant from the Innovative Genomics Institute at the University of California, Berkeley. MB was supported by NIH grant no. R01-GM122061-03 and NSF EEID grant no. 2011109.
References



