
Abstract
Background Estimates from initial SARS-CoV-2 serological surveys were likely to be biased due to convenience sampling whereas large-scale population-based serosurveys could be biased due to non-response. This study aims to estimate the seroprevalence of SARS-CoV-2 infection in Saint Petersburg, Russia accounting for non-response bias.
Methods We recruited a random sample of adults residing in St. Petersburg with random digit dialling. Computer-assisted telephone interview was followed by an invitation for an antibody test with randomized rewards for participation. Blood samples collected between May 27, 2020 and June 26, 2020 were assessed for anti-SARS-CoV-2 antibodies using two tests — CMIA and ELISA. The seroprevalence estimates were corrected for non-response bias, test sensitivity, and specificity. Individual characteristics associated with seropositivity were assessed.
Findings 66,250 individuals were contacted, 6,440 adults agreed to be interviewed and were invited to participate in the serosurvey. Blood samples were obtained from 1038 participants. Naïve seroprevalence corrected for test characteristics was 9.0% [95% CI 7.2–10.8] by CMIA and 10.8% [8.8–12.7] by ELISA. Correction for non-response bias decreased seroprevalence estimates to 7.4% [5.7–9.2] for CMIA and to 9.3% [7.4–11.2] for ELISA. The most pronounced decrease in non-response bias-corrected seroprevalence was attributed to the history of any illnesses in the past 3 months and COVID-19 testing. Besides that seroconversion was negatively associated with smoking status, self-reported history of allergies and changes in hand-washing habits.
Interpretation These results suggest that even low estimates of seroprevalence in Europe’s fourth-largest city can be an overestimation in the presence of non-response bias. Serosurvey design should attempt to identify characteristics that are associated both with participation and seropositivity. Further population-based studies are required to explain the lower seroprevalence in smokers and participant reporting allergies.
Funding Polymetal International plc
Introduction
Serological surveys in the midst of COVID-19 pandemic address the issue of underestimation of the number of cases registered officially with RT-PCR using material from nasopharyngeal swabs [1; 2]. They use blood antibody tests that are markers of past infection. WHO recommends serological surveys to monitor COVID-19 spread [3]. However, estimates from serological surveys can be also biased. Estimates can be distorted by non-response bias, non-representativeness of the study sample, and imperfect test characteristics. Previous serological surveys so far have all but focused on the former [4–10]. This poses a significant problem when some observed factors that influence the decision to participate in the survey may be also associated with test results [11]. Non-response or self-selection bias has been widely acknowledged in descriptive epidemiology [12–15]. In particular, it has been predominantly addressed in seroprevalence surveys of HIV [16].
In this paper we present seroprevalence estimates coming from the first cross-sectional data of our longitudinal study with serial sampling to assess the spread COVID-19 in Saint Petersburg, Russia conducted between May 27 and June 26 2020. St. Petersburg is the second largest city in the country and fourth largest in Europe with the population of approximately 5.2 mln. The first case in the city was registered on 5 March, 2020 and 36,667 cases (7.1 per 1000) were reported as of 31 August, 2020. The study of the spread of COVID-19 in St. Petersburg was established to estimate the extent of epidemic in a population-based manner, and, to the best of our knowledge, this was the first COVID-19 serological survey in the country. Our primary aim was to compare naïve and non-response bias-adjusted seroprevalence to show the utmost importance of rigorous serosurvey designs. We report how various observable characteristics of individuals shift the naïve prevalence estimates when accounted for and carefully address possible sources of bias. Finally, we provide observable characteristics of surveyed individuals that are associated with risk of seroconversion in a population-based study.
Methods
Study design and participants
The St. Petersburg COVID-19 study is a population-based epidemiological survey of random sample from the adult population to assess the seroprevalence of anti-SARS-CoV-2 antibodies. The study is conducted as a longitudinal study with serial sampling from the same individuals. The study involved one phone-based survey followed by an individual invitation to the clinic, one paper-based survey, and blood sample collection for antibody testing. Interviews were carried out between May 21, 2020 and June 25, 2020. Blood samples were collected between May 27, 2020 and June 26, 2020.
Eligible individuals were adults residing in St. Petersburg older than 18 years and recruited using the random digit dialling (RDD) method. RDD was accompanied by the computer assisted telephone interviewing (CATI) in order to collect information on both individuals who accepted and declined invitation for testing. Residents of St. Petersburg are almost universal mobile phone users, with 99.5% of households having mobile phones as of 2016 (see Supplementary Appendix Table A3). Participants from six distant districts of the city located too far away from the test site were excluded leaving 12 central districts of the city with population of approximately 4.3 mln. The full study protocol is available online (https://eusp.org/sites/default/files/inline-files/EU_SG-Russian-Covid-Serosurvey-Protocol-CDRU-001_en.pdf).
Procedures
RDD was carried out using area prefixes of mobile phone numbers to include only mobile phone users in St. Petersburg. The individuals who had answered the call were asked to answer 25 questions on demographics, marital status, education level, income level, past history of illnesses, travelling abroad, household size, social contacts, and visits to public places during lockdown (see full questionnaire in the study protocol). Refusal to participate in blood sampling was also recorded. We have also randomly incentivized respondents to participate in the study by offering complimentary taxi transit to and from the clinic test site for approximately 25% of those who agreed to go through CATI.
Those who had agreed to take part in antibody testing were later contacted by the clinic call center and were assigned an appointment date for blood sampling. The participants signed consent forms and filled out additional paper-based survey forms in the clinic on the day of the visit. Forms included question on the medical history, history of allergies, smoking, alcohol consumption, chronic diseases and medication taken regularly. Blood sampling started on May 27, 2020 and was planned for two weeks but was prolonged till June 26, 2020 because of low participation rates.
Laboratory tests
We assessed anti-SARS-CoV-2 antibodies using two tests. Serum samples were tested using chemiluminescent microparticle immunoassay (CMIA) Abbott Architect SARS-CoV-2 IgG on the Abbott ARCHITECT® i2000sr platform (Abbott Laboratories, Chicago, USA) that detects immunoglobulin class G (IgG) antibodies to the nucleocapsid protein of SARS-CoV-2 (cutoff for positivity 1.4). In addition to that blood samples were also tested by enzyme-linked immunosorbent assay (ELISA) using CoronaPass total antibodies test (Genetico, Moscow, Russia) that detects total antibodies (cutoff for positivity 1.0) and is based on recombinant receptor binding domain of the spike protein of SARS-CoV-2 (Department of Microbiology, Icahn School of Medicine at Mount Sinai, New York, NY, USA). We simultaneously report seroprevalence based on CMIA and ELISA.
Sample size
Initial sample size of 1550 participants was calculated assuming prevalence of 20% and test sensitivity (100%) and specificity (99.6%) for our CMIA test with sampling error was 2% using a 95% confidence interval (see Supplementary Appendix Figure A1).[17] After receiving the preliminary results (for 500 individuals), we reduced the sample size by assuming 10% prevalence that gave us a target sample size of 882 participants, that was rounded to 1000 participants.
Statistical analysis
The primary aim of the study was to assess the seroprevalence of antibodies to SARS-CoV-2 in serum samples based on CMIA tests and ELISA tests accounting for non-response bias and test characteristics (sensitivity and specificity). Seroprevalence was defined as the proportion of those tested positive to all participants. Non-response was assessed by comparison of answers provided during the CATI by those visited the test site and all other surveyed.
To understand the direction of non-response bias in our data we estimated a binomial probit regression of individual agreement to participate in the study and offer his/her blood sample on observable characteristics. We used this fitted model to compute conditional probability to participate in the study (holding all but one variable at mean levels at a time). Our bivariate probit model is formally introduced in Statistical Appendix App. 1).
We analyse variables obtained from CATI and the clinic paper-based survey (ordered or unordered factor variables), and results of antibody tests (binary variables). Participant age was split into groups (18–34, 35–49, 50–64, or ≥65 years old).
In the secondary analyses we also assessed seroprevalence by week based on the date of interview and the date of blood sampling. In subgroup analysis we first compared seroprevalence estimates corrected for non-response between different groups of individuals based on their answers in CATI. To explore individual risk factors for test positivity and obtain prevalence ratios we estimated a generalised linear model with Poisson distribution and a log link restricted to data from participants who completed clinic paper-based survey. We have entertained the possibility to use robust variance-covariance matrix in our adjusted prevalence ratio analysis. However, such adjustment narrowed the confidence intervals rendering our adjusted estimates less conservative [18]. For this reason we report confidence intervals from the unadjusted variance-covariance matrix.
In sensitivity analysis we explored how inclusion of different sets of observable characteristics of individuals (namely, travel history, face mask use, public transport use, visits to public places and others) in the model that corrected seroprevalence for non-response influenced the results. We also applied alternative definitions of seroprevalence (test combination either favouring sensitivity or specificity). To account for possible sample non-representativeness in sensitivity analysis we computed raking weights to match the survey age group and educational attainment proportions in 2016 representative survey of adult city population (see Supplementary Appendix Table A3 for description of this survey and the target proportions). R package anesrake was used to compute the weights [19]. We then estimated seroprevalence on re-weighted data.
We treated refusals to answer certain phone or paper-based survey questions as missing data, for this reason the results onwards are considered after listwise deletion of observations with missing variables.
All reported seroprevalence results were also corrected for test characteristics using the manufacturer’s validation data — sensitivity (100% and 98.7%) and specificity (99.6% and 100%) for CMIA and ELISA test, respectively [20]. Standard errors were computed with delta method. Detailed description of statistical analysis is provided in Statistical Appendix App. 1).
Data sharing
All analyses were conducted in R with the aid of GJRM package [21], study data and code is available online (https://github.com/eusporg/spb_covid_study20).
Ethical considerations and study registration
The study was approved by the Research Planning Board of European University at St. Petersburg (on May 20, 2020) and the Ethic Committee of the Clinic “Scandinavia” (on May 26, 2020). The study was registered with the following identifiers: NCT04406038 and ISRCTN11060415.
Results
Participation rates
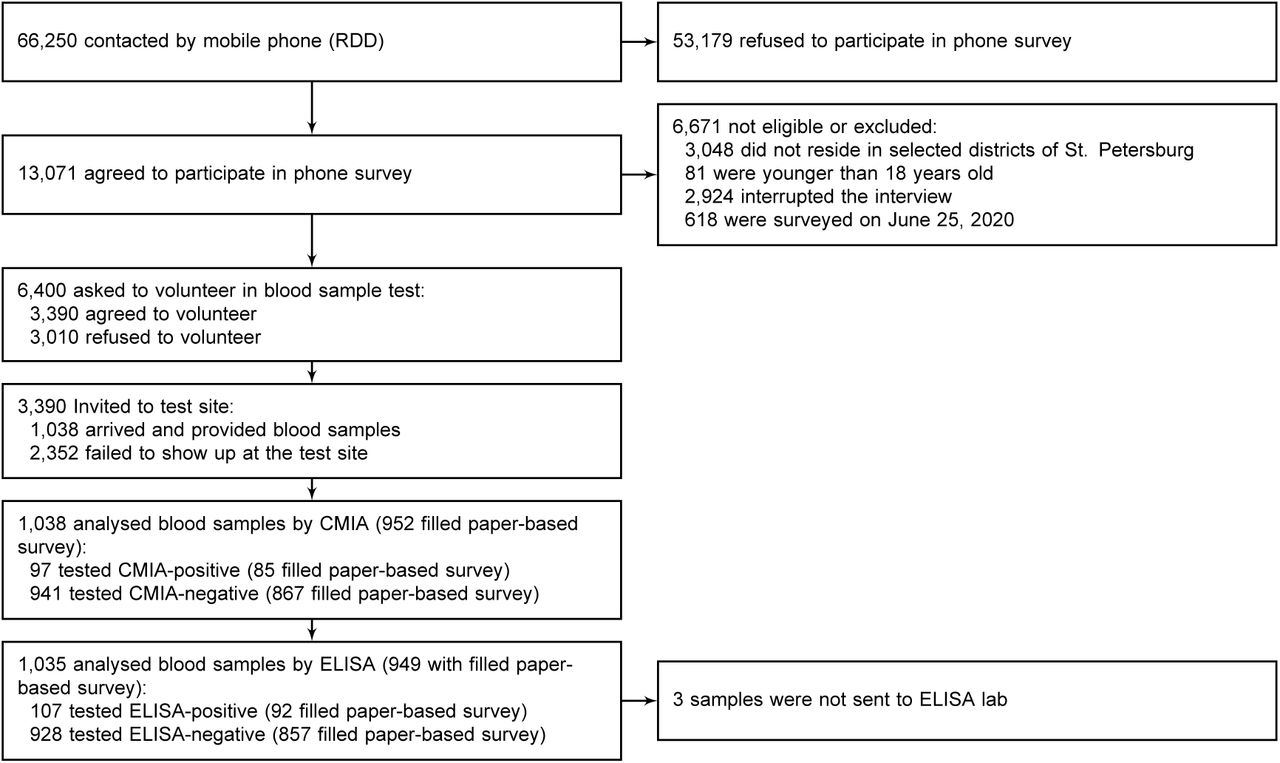
Between May 21 and June 25, 2020 66,250 individuals were reached using RDD. Of 13,071 respondents agreed to participate in the CATI 6,671 were excluded for various reasons (see Figure 1). The resulting 6,400 individuals responded to CATI questionnaire (see Supplementary Appendix Table A2 for details regarding missing records on variables of interest). The respondents were representative of the city population in terms of their gender, employment status, and house-hold size, but were younger than the adult city population as of 2016 and had higher levels of educational attainment (see Supplementary Appendix Table A3).

3,390 of surveyed individuals agreed to receive a phone call from the clinic and schedule a visit for antibody testing. Between May 27 and June 26, 2020 only 1038 individuals that satisfied eligibility criteria visited the clinic and provided blood samples (16.2% and 30.6% of those who were interviewed and agreed to participate in serosurvey, respectively). The rest declined the invitation or did not show up at the test site. 1038 CMIA tests and 1035 ELISA tests were eventually performed on eligible individuals. The clinic-visiting participants have also filled out 965 clinic paper-based survey forms.
652 (62.8%) of 1,038 participants were women; 396 (38.2%) were aged 18-34 years, 357 (34.4%) were aged 35-49 years, 218 (21.0%) were aged 50-64 years, and 67 (6.5%) were older than 65 years, the majority of participants lived in multiple-person households, 843 (81.2%) (see Supplementary Appendix Table A2 for summary statistics on phone survey respondents and tested individuals).
In the course of the study we observed the gradual attrition of participants. Compared with the individuals who limited their participation to the CATI, participants who took part in antibody testing were younger, more likely to be female, report a higher education level, experience illnesses in the previous 3 months, report a history of previous COVID-19 testing and a change in their hand-washing habits during the epidemic. Our attempt to randomly incentivize respondents to take part in the study by offering taxi did not reach its purpose. (see Supplementary Appendix Figure A2a).
Seroprevalence estimates
Between May 27 and June 26, 2020, 115 positive results were reported by any test (97 positive tests out of 1038 were reported by CMIA and 107 positive tests out of 1035 were reported by ELISA). 30 of these 115 (26.1%) individuals with any positive test result did not report any symptoms of past illnesses in the previous 3 months. Naïve seroprevalence corrected for test specificity and sensitivity was 9.0% (95% CI 7.2–10.8) by CMIA and 10.8% (8.8– 12.7) by ELISA (see Table 1). When we accounted for non-response bias with respect to demographic and socioeconomic characteristics our seroprevalence point estimates did not change considerably. Inclusion of characteristics associated with seroprevalence as regressors in our single imputation model shifted point estimates of seroprevalence downwards and after adjustment for all aforementioned characteristics in the model seroprevalence was 7.4% (95% CI 5.7–9.2) for CMIA and to 9.3% (7.4–11.2) for ELISA.
SARS-CoV-2 seroprevalence estimates from bivariate probit models with different sets of individual characteristics for non-response correction
Secondary subgroup analysis
Seroprevalence was similar between men and women and was slightly lower in the older (65+) age group (see Table 2). The seroprevalence was higher for individuals who reported past history of illnesses — (15.1% (95% CI 11.6–18.6) for CMIA and 20.0% (95% CI 14.8–25.2) for ELISA) compared to those who did not (3.8% (95% CI 2.1–5.5 for CMIA and 7.4% (95% CI 5.4–9.3 for ELISA). It was also higher for individuals who reported past history of COVID-19 tests, but was slightly lower in individuals who reported that they started washing hands more often since the onset of pandemic and lived alone. There was noticeable variation in seropositivity between city districts (see Figure 2).
Seroprevalence of SARS-CoV-2 in subgroups of participants
Prevalence ratios for self-reported characteristics of tested individuals in phone and paper-based surveys

This map shows CMIA-based prevalence estimates corrected for non-response bias by surveyed districts with 95% CIs in parentheses. Green dot is the clinic test site location. Remote districts excluded from survey are in grey. Map data copyrighted OpenStreetMap contributors.
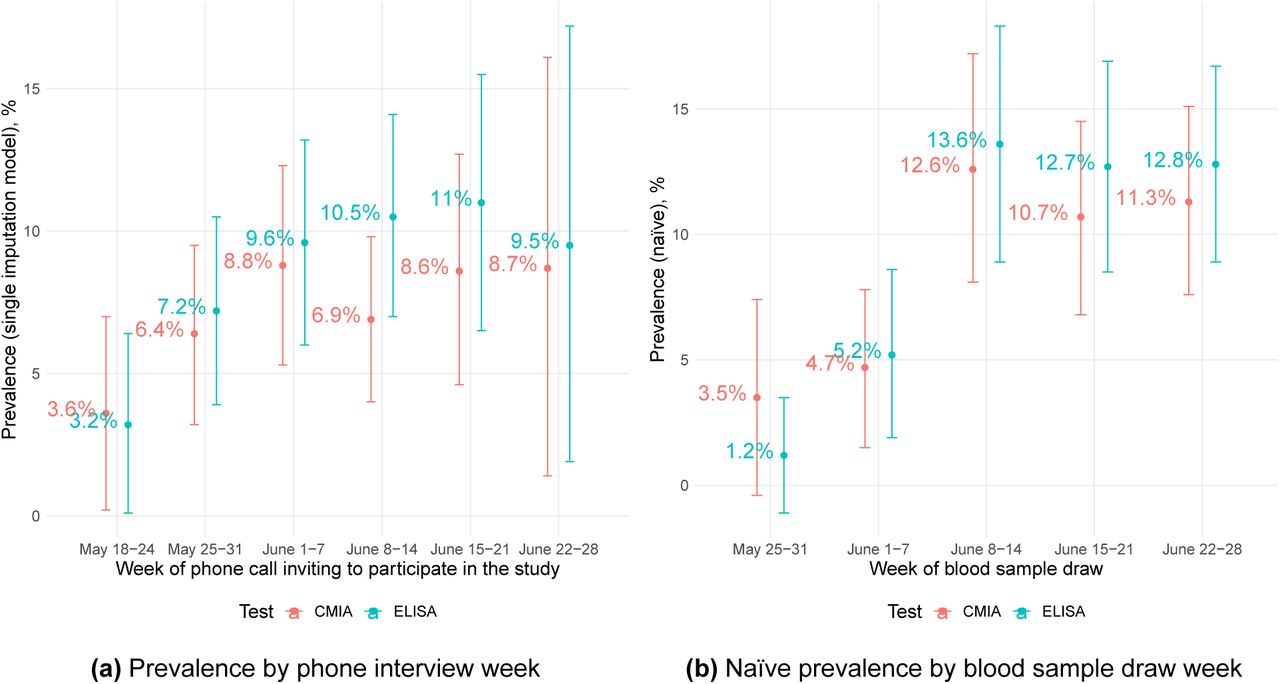
We observed a slight increase in seroprevalence by the week of the phone interview (see Figure 3a) and by the week of the blood draw (see Figure 3b).

Our secondary analysis of participants who filled out clinic paper-based survey forms revealed additional covariates associated with seroconversion. It was negatively associated with smoking status with prevalence ratios 0.46 (95%CI 0.22-0.87) and 0.34 (95%CI 0.14-0.72) (PR for current smokers vs non-smokers based on CMIA and ELISA, respectively), and self-reported history of allergies with prevalence ratios 0.54 (95%CI 0.30-0.90) and 0.53 (95%CI 0.28-0.93). (see Supplementary Appendix Table 3).
Sensitivity analysis
Alternative definitions of seroprevalence (test combination either favouring sensitivity or specificity) did not qualitatively change the effect of non-response bias (see Supplementary Appendix Table A4). Seroprevalence estimates obtained on re-weighted survey data (based on age group and education attainment level) were similar to estimates from the main analysis. (see Supplementary Appendix Table A5).
Discussion
Our study aimed to assess the spread of epidemic in the fourth largest European city — St. Petersburg. Although the seroprevalence estimate varied based on the test used and type of correction applied, the total number of population with detectable antibodies was still far lower than the proportion needed for herd immunity. Overall seroprevalence in the range between 7% and 10% was in line with the results obtained from the previous studies and provides evidence of the similar epidemic development across the world with less than one tenth of population affected in the first months [5; 6].
To the best of our knowledge, this is the first seroprevalence survey of COVID-19 that applied correction based on characteristics that are associated with the risk of seropositivity in combination with incentivised participation. Early COVID-19 serological surveys are likely to exhibit high sampling error because of recruitment methods.[22] Population based studies with random sampling relied on probability weighting obtained from the comparison with the source population [5–7].. Our findings show that even low estimates of seroprevalence (around or below 10%) obtained in population surveys can be an overestimation in populations with high risk of non-response bias.
We detected only a slight change in the estimate of seroprevalence when we corrected our estimated for non-response bias with respect to demographic or socioeconomic characteristics, but far more significant difference was detected when several behavioural characteristics were included in models and applied in the correction. In general, our analysis shows that naïve estimates that do not account for the non-response bias tend to drive prevalence estimates upward. In contrast to the findings in the literature examining the non-response bias in HIV serosurveys, on average participants who are more likely to have antibodies are more likely to participate in COVID-19 surveys [16; 23]. Participants with history of illness in the last 3 months or past history of tests for COVID-19 in the last 3 months were more likely to agree to antibody testing in our study probably seeking external confirmation.
In our sample of participants we did find only a slight age difference in the seropositivity rates, and there was no difference between men and women, which is in line with previous findings [6]. However, we observed several clear differences in seroprevalence estimates in a subgroup analysis. First of all, we detected an elevated seroprevalence in participants who reported history of illness and history of any COVID-19 test in the last 3 months, this association was seen regardless of the modelling approach. Second, seroprevalence was lower in participants who lived alone and reported that they started to wash their hands more often. Third, in the secondary analysis of participants who were tested we observed that seroprevalence was lower in current smokers compared to never smokers, it was also lower in participants who reported past history of allergies.
All associations revealed in our study should not be immediately regarded as causal due to limitations in the study design and analysis. History of testing and illness in the last 3 months can be easily interpreted. Seroprevalence among those reporting a history of COVID-19 testing was relatively low (around 20%), this can be explained by the high scale of testing in Russia since the onset of the epidemic. However, our study is not a direct evidence of the effectiveness of hand hygiene, as self-reported change in habits can reflect other differences between sub-populations. There is limited and conflicting evidence about the smoking rates in COVID-19 patients [24; 25]. While our study is the one of the first that compared population-based seroprevalence estimates between smokers and non-smokers there is a need for more studies to confirm this finding [9]. There are many examples when smoking effects were subject to structural epidemiological biases [26]. Even if this association is causal, then behavioural or biological mechanisms should be explored. Smoking is a well-established risk factor for many diseases and it is likely linked to COVID-19 severity regardless of the risk of infection [24].
It is also tempting to immediately search for biological explanation that link allergy status and risk of infection [27]. However, we should be very cautious due to limitations of study design and other possible explanations, e.g. people who self-report being allergic may behave in a way to minimize risk of being infected. The question about allergy was very general in our paper-based survey, that also limits the value of this finding.
Important source of bias in serological studies is the performance and the nature of the serological tests [28]. Possible explanation of the difference in our study includes different classes of Ig analysed — IgG in case of CMIA and IgG+IgM+IgA in case of ELISA. However, given the total seroprevalence of not more than 10% it seems that lack of IgM and IgA in CMIA test can only partially explain the difference. A recent study showed that seroconversion started on day 5 after disease onset and IgG level rose even earlier than IgM [29]. Another possible explanation for different seroprevalence estimates of two tests is the nature of antigen. SARS-CoV-2 antibody responses specific to the Spike (S) and/or the nucleocapsid (N) proteins are equally sensitive in the acute infection phase [30]. However, as compared to anti-S antibody responses, those against the N protein appear to wane in the post-infection [31]. Recent evaluations of CMIA test used in our study reported sensitivity far below 100% reported by manufacturer. This may also explain the difference [32; 33]. Another source of underestimation is a proportion of infected that do not seroconvert. Straightforward adjustments for this sort of biases are not available without additional laborious testing [34].
Our study has several other important limitations. We are addressing seroprevalence in adults only, while previous studies also included participants younger than 18 years old [5; 6]. Our study had a relatively low participation rate given the existing propensity to answer phone calls in the city. However, we assumed missingness at random for those who did not complete the interview or did not pick the phone. Comparison with the previous representative city survey showed that our sample was representative (see Supplementary Appendix Table A3). We have also excluded distant city districts from our sampling. Even though we observed statistically significant differences between by-district seroprevalence, the lion’s share of city residents (about 4.3 mln of 5.2 mln) live in the surveyed districts. Our randomized incentivisation scheme was not successful because randomly assigned taxi offer was not associated with participation agreement and failed to become a valid exclusion restriction. In our main analysis we did not apply post-stratification methods adopted previously [5]. However, application of raking weights estimated to match targets from a representative survey of adult city population showed little to no changes in weighted seroprevalence estimates. We explained this by little to no association between seroconversion and age or education level. Finally, we report cross-sectional results but longitudinal data are needed to offer additional insights to immunity waning and prolonged defence against re-infection.
Conclusion
COVID-19 pandemic has already affected at least 300 000 residents of St. Petersburg that can be extrapolated to millions in the whole country. However the vast majority of population does not carry antibodies to SARS-CoV-2. This highlights the need for further high-quality population based studies that can provide evidence for measures to diminish the impact of the pandemic.
Funding
The study was funded by Polymetal International plc. The main funder had no role in study design, data collection, data analysis, data interpretation, writing of the report or decision to submit the publication. The European University at St. Petersburg, clinic “Scandinavia” and Genetico had access to the study data and The European University at St. Petersburg had final responsibility for the decision to submit for publication.
Authors’ contributions
AB, DSk, VV, KT, LB, DSh and PT conceived the study. AB, DSk and VV drafted the first version of the manuscript. KT, YR, AN, EP and DSh contributed to drafting sections of the manuscript. DS, AB and DSh did data analyses. SZ and EP did lab analyses. All authors participated in the study design, helped to draft the manuscript, contributed to the interpretation of data and read and approved the final manuscript.
Declaration of interests
AB reports personal fees from MSD and Biocad outside the submitted work. AI, EP and SZ report a pending patent for the test system (ELISA) for detecting antibodies specific to the SARS-COV-2 in a biological sample. Other authors have no conflict of interest to declare.
Data sharing
All analyses were conducted in R with the aid of GJRM package [21], study data and code is available online (https://github.com/eusporg/spb_covid_study20).
Ethical considerations and study registration
The study was approved by the Research Planning Board of European University at St. Petersburg (on May 20, 2020) and the Ethic Committee of the Clinic “Scandinavia” (on May 26, 2020). The study was registered with the following identifiers: NCT04406038 and ISRCTN11060415.
Supplementary materials
Statistical appendix
Let adult population of St. Petersburg be of size N, indexed with i, and characterised by a triplet ⟨ Z, D, Y ⟩. Zi = 1 means that the i-th resident will be surveyed, with Zi = 0 otherwise. Let Z be a vector of size N, its i-th element equals Zi. In other words, Z indexes which city residents will be surveyed.
D marks the individual decision to participate in the survey when contacted: Di(Z) = 1: i-th individual volunteers to take part in the study, with Di(Z) = 0 otherwise. Let D be the volunteer vector of size N.
When participation is universal Di(Z) = Zi ∀i. In reality one could observe non-zero refusal rates. In what follows we assume one-sided noncompliance.
Variable Y characterises antibody status (seroconversion) of the i-th individual and takes the following values: { 1, 0 }, where 1 — has antibodies to SARS-CoV-2 and 0 — does not have antibodies. Antibody status can be both observed and unobserved: Yi ≡ Yi (Z, D). We are able to observe antibody status for Yi (Zi = 1, Di = 1), i.e. for the surveyed individuals who agreed to volunteer in the study and were tested.
We are interested in population seroprevalence estimate  Having conducted our study we can estimate the naïve seroprevalence
Having conducted our study we can estimate the naïve seroprevalence  , where n is the number of tested individuals. To arrive at population-level seroprevalence estimates the following assumptions are required:
, where n is the number of tested individuals. To arrive at population-level seroprevalence estimates the following assumptions are required:
Random sampling
The survey is conducted such that Pr (Z = c) = Pr Z = c′ where c and c′ are arbitrary survey vectors.
Stable unit treatment value assumption (SUTVA)
Both observed and unobserved individual antibody status depends only on his/her antibody status and decision to participate in the survey and not on the decision of other study participants. The surveyed individuals maintain no contacts or other social interactions that could influence their individual decisions to participate in the study. Such interactions might arise in case of household sampling where all household members are invited to participate in the survey.
No unobservable characteristics of study participants
Let X ∈ℝN×M be a matrix of observable individual characteristics. Its row Xi stores all characteristics of individual i that influence his/her decision to participate in the study when surveyed. Naïve seroprevalence estimate will be representative of the city population only when cov ([D | X], [Z| X]) = 0 and cov ([D| X], [Y| X]) = 0. That is, conditional on all observable characteristics of individuals, the decision to participate in the study is orthogonal to both the conditional-on-observables survey inclusion and conditional-on-observables antibody status. While the former orthogonality assumption [D| X] ⊥ [Z| X] is satisfied under random sampling of individuals, the latter is more problematic. First, no phone survey design could ensure full observability of all characteristics associated both with individual decision to volunteer and antibody status. Many variables might be left unobserved, rendering this orthogonality assumption unrealistic. Second, differing sets of observables can influence seroconversion and decision to volunteer. For instance, past travel history may be an important observable responsible for D = 1 while fully independent of actual antibody status Y = 1.
When the above assumptions are not satisfied the naïve seroprevalence estimate is biased. To account for this we rely on bivariate binary model with non-random selection in the spirit of Bä rnighausen et al. (2011) [1]. First we assume that decision of a surveyed individual to agree to participate in the survey and come to the clinic test site is determined by a latent variable
 such that Di = 1 if D∗> 0 and Di = 0 otherwise. Ti is a variable equal to unity if surveyed individual was offered free taxi to and from the clinic test site during the phone survey, εi is the error term. We observe D only for n out of N individuals in the population.
such that Di = 1 if D∗> 0 and Di = 0 otherwise. Ti is a variable equal to unity if surveyed individual was offered free taxi to and from the clinic test site during the phone survey, εi is the error term. We observe D only for n out of N individuals in the population.
We observe antibody status only for those with Di = 1 and assume that seroconversion is determined by a latent variable
 such that Yi = 1 if Y ∗> 0 and Yi = 0 otherwise. ζi is the error term. Since we have offered taxi to random phone survey participants we can safely assume that cov ([Y|X], T) = 0 and T becomes a valid exclusion restriction.
such that Yi = 1 if Y ∗> 0 and Yi = 0 otherwise. ζi is the error term. Since we have offered taxi to random phone survey participants we can safely assume that cov ([Y|X], T) = 0 and T becomes a valid exclusion restriction.
We impose a structural assumption of independent and identically Normal-distributed error terms εi and ζi with nil mean and unit variance. Their joint cumulative distribution function is given by Φ(εi, ζi, ρ) where ρ is covariance (correlation coefficient).
This bivariate probit is estimated with R package GJRM [2]. We use different definitions of seropositivity Y = 1 depending on antibody tests or combinations thereof and different set of variables in design matrix X.
Our first step is to estimate  and test whether it is statistically significantly different from zero. Estimates under different sets of variables are reported below with 95% CIs in parentheses are reported in Supplementary Appendix Table A1.
and test whether it is statistically significantly different from zero. Estimates under different sets of variables are reported below with 95% CIs in parentheses are reported in Supplementary Appendix Table A1.
As our baseline we adopt a model where a rich set of demographic, socioeconomic, and seropositivity-related characteristics is included in the design matrix X. In this model results from both the simulated CIs and Lagrange multiplier test with null ρ = 0 (not reported here, available at request) suggest that one cannot reject the null hypothesis of error term independence between the selection stage and antibody test result stage.
Under error term independence Heckman correction is not required to arrive at seroprevalence estimates for the entire city population when response is non-random. However, the naïve seroprevalence estimate can still be biased since the tested individuals are not representative of the city population. To circumvent this we use the estimated parameters from baseline seroconversion probit (see equation 2 above) and predict antibody status Y for all surveyed individuals regardless of their agreement to participate in the survey. Such (univariate) single imputation that assumes no unobserved confounders permits us to correct the naïve seroprevalence estimates for missing data for those individuals who have refused to get tested or did not visit the clinic.
Symmetric confidence intervals come from standard errors estimated with delta method. Results do not change qualitatively when we consider non-symmetric confidence intervals after Bayesian posterior simulation of the parameter vector estimate (not reported here, available at request).
Finally, we rely on manufacturers’ test characteristics to correct all reported prevalence estimates  using the formula
using the formula

Estimated error term correlation between selection stage and testing stage
STROBE checklist for cross-sectional studies

This chart reports the relationship between sampling error and sample size under different test characteristics and assumed hypothetical prevalence in the population. Calculations are made with the designated code [3].
Summary statistics of eligible phone survey respondents
Sample means across study stages and in relation to a representative survey
SARS-CoV-2 seroprevalence estimates from bivariate probit models with different sets of individual characteristics for non-response bias correction and alternative definitions of seropositivity
SARS-CoV-2 seroprevalence estimates from bivariate probit models after re-weighting the sample with raking weights (age group and educational attainment level) estimated to match a 2016 representative survey of adult city residents

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This figure reports adjusted predictions from probit model of individual visiting clinic test site (subfigure a) or being CMIA-seropositive (subfigure b) holding all but one regressor at mean levels. Horizontal lines are 95% CI. Dashed vertical red line is unconditional mean propensity.
Acknowledgements
We acknowledge personal support from Vitaly Nesis (Chief Executive Officer, Polymetal International, plc). We thank Alla Samoletova (European University at St. Petersburg) for administrative support and management of the study. We are also beholden to Dmitriy Serebrennikov (EU SPb) for managing paper-based survey data entry, Ruslan Kuchakov (EU SPb) for initial assistance with visualizations. We also gratefully acknowledge support from Yana Novikova and Aleksey Gladkikh (Invitro Laboratory) regarding the CMIA testing, Yulia Stepantsova (Chursina) regarding phone based interviewers, Maya Perestoronina (Clinic “Scandinavia”) for comments on the protocol, Lizaveta Dubovik and Irina Shubina for the science communication, and Sergey Nechiporenko for the protocol translation. We thank the interviewers, nurses, general practitioners, and administrative personnel of the Clinic “Scandinavia”. We also thank Ilya Fomintsev for his help and support during the initial stages of the study. We also thank all study participants.
References
Supplementary material references




Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
2
Blogs/Media
Author Videos