
Abstract
Mobility, awareness, and weather are suspected to be causal drivers for new cases of COVID-19 infection. Correcting for possible confounders, we estimated their causal effects on reported case numbers. To this end, we used a directed acyclic graph (DAG) as a graphical representation of the hypothesized causal effects of the aforementioned determinants on new reported cases of COVID-19. Based on this, we computed valid adjustment sets of the possible confounding factors. We collected data for Germany from publicly available sources (e.g. Robert Koch Institute, Germany’s National Meteorological Service, Google) for 401 German districts over the period of 15 February to 8 July 2020, and estimated total causal effects based on our DAG analysis by negative binomial regression. Our analysis revealed favorable causal effects of increasing temperature, increased public mobility for essential shopping (grocery and pharmacy), and awareness measured by COVID-19 burden, all of them reducing the outcome of newly reported COVID-19 cases. Conversely, we saw adverse effects of public mobility in retail and recreational areas, awareness measured by searches for “corona” in Google, and higher rainfall, leading to an increase in new COVID-19 cases. This comprehensive causal analysis of a variety of determinants affecting COVID-19 progression gives strong evidence for the driving forces of mobility, public awareness, and temperature, whose implications need to be taken into account for future decisions regarding pandemic management.
1. Introduction
As the COVID-19 pandemic progresses, research on mechanisms behind the transmission of SARS-CoV-2 shows conflicting evidence [59, 9, 24]. While effects of mobility have been extensively discussed, less is known on other factors such as changing awareness in the population [26, 36, 64] or the effects of temperature [4, 12, 39]. A limiting factor in many studies is the lack of a causal approach to assess the causal contributions of various factors [23]. This can lead to distorted estimates of the causal factors with observational data [23, 50, 54].
With COVID-19, we find ourselves in a situation in which information on the causal contribution of various influencing factors in the population is urgently needed to inform politicians and health authories. On the other hand, trials cannot be carried out for obvious ethical and legal reasons. Therefore, when assessing the effects of determinants of SARS-CoV-2 spread, special attention must be paid to strategies for the selection of confounding factors.
Another problem with assessing the effects of various determinants of SARS-CoV-2 spread is the heterogeneity of the countries and regions examined for example in the Johns Hopkins University (JHU) COVID-19 database [7]. The comparison of time series of case numbers from different countries and observational periods can be strongly distorted by different factors like testing capacities and regional variations.
Our objective is to provide estimates of the causal effects of the main drivers of the pandemic with reduced bias. We conducted a scoping review of the available studies regarding signaling pathways and determinants of the spread of SARS-CoV-2 infections and the reported new COVID-19 cases. Then we integrated the current findings into a directed acyclic graph for the progress of the pandemic at the regional level. Using the resulting model and the do-calculus we found identifiable effects without blocked causal paths whose effects can be analyzed with observational data [45]. We used regional time series data of all German districts (401) from various publicly available sources to analyze these questions on a regional level. Germany is a good choice in this regard, because it has ample data on contributing factors on the regional level and has had high testing and treatment capacities from early on in the pandemic.
2. Causal Model
We used a directed acyclic graph (DAG) [50, 54] as a tool to analyze the causal relationships between several exposures and SARS-CoV-2 spread. To get an overview on published associations, a scoping review was conducted from 20th to 22nd of May 2020 within Pubmed and Google scholar. Restrictions were applied to English and German language and the publication date in the last one year. The following search terms were applied to abstracts and title in Pubmed (“COVID-19” OR “COVID19” OR “Corona” OR “Coronavirus” OR “SARS-CoV-2”) and connected separately in each case with the exposure variables (“mobility”, “public awareness”, “awareness”, “google trends”,”ambient temperature”, “temperature”). For “mobility”, we analyzed n = 8 studies, N = 103 were scanned in Pubmed, together with the first ten pages (100 results) in Google scholar (“awareness”/”public awareness”/”google trends” n = 9, N = 215; “temperature”/”ambient temperature” n = 16, N = 235). We integrated these findings where possible into the construction of our DAG, which can be seen in Figure 1.

DAG of determinants of reported COVID-19 cases on the district level. Unobserved variables are light gray, variables marked with an asterisk (*) are confounded by weekday/holiday.
A number of studies report a strong association of mobility restrictions on the number of new COVID-19 cases: Restrictive measures (e.g. “stay-at-home” orders, travel bans, or school closures) are shown to possibly reduce the COVID-19 incidence [8, 9, 18, 33, 35, 38, 41, 62]. However, some studies point out the combination of various non-pharmaceutical interventions (NPIs) is decisive to prevent new infections [30, 34].
Google Trends [21] data can be used as a tool to get insights into public interest (awareness) in the coronavirus disease. Several recent studies imply a connection of relative search volumes (RSV) indices and reported new COVID-19 cases [3, 16, 26, 36, 37, 40, 57, 64, 65]. Some search terms e.g. “COVID-19” or “coronavirus” predated newly infected cases/total number of cases by roughly 7 to 14 days for different countries [16, 26, 36, 64]. Additionally, we acknowledged that individual risk-aware behavior might be a reaction to the current COVID-19 burden (measured as reported cases at the day of exposure).
Mixed evidence is available regarding the effect of temperature: On the one hand several papers report an association between increase in temperature and decrease in newly infected COVID-19 cases [4, 12, 39, 47, 51, 52, 55, 58, 60]. On the other hand, also the opposite has been found [2, 61]. Some studies found no association at all [5, 28, 29, 30, 63]. It should be noted that few studies considered other confounding variables than meteorological ones (especially age and population density among others [5, 30, 60]). In addition, the transferability of results between different climate zones is questionable. To avoid possible bias caused by weather variables other than temperature, we included rain, wind, and humidity in our model.
When investigating causal determinants of SARS-CoV-2 infections, a number of confounders have to be considered. Well-known risk factors for SARS-CoV-2 as well as for other infections are demographic factors such as age, gender, socio-economic status (SES), population density, and foreign citizenship/ethnicity [11, 15, 7]. In Germany along with other countries (i.e. Brazil, USA, or the UK), populist parties or politicians and their electorate tend to be more sceptical about effects of containment measures than the other part of the electorate [14, 17]. Therefore we considered both “right-wing populist party votes” and “voter turnout” as possible confounders. Public health interventions were also taken into account (contact restrictions, school closures etc.), as their implementation showed strong correlations with controlling the spread of SARS-CoV-2 [10, 30, 34]. To avoid bias due to reporting delay of case numbers we had to include weekday and German holidays. We include some unobserved variables in our DAG (e.g. “Herd immunity”), too. Please note that “Exposure to SARS-CoV-2” is itself an unobserved variable: German case numbers are reported with delay after date of exposure and symptom onset. Exposure to the virus should not be confused with the formal exposure variables of the DAG (mobility, awareness, temperature).
3. Data
We collected and aggregated data on reported COVID-19 cases, regional socio-demographic factors, weather, and general mobility on district and state level in Germany for the period of 15 February 2020 to 8 July 2020. Our observation period for the outcome consisted of all dates from 23 February 2020 to 8 July 2020 (T = 137), since we used a lag of 8 days for all confounders. We did not exclude any states or districts (K = 401). We analyzed the daily reported number of new cases as outcome (K · T = 54 937 observations). The set of possible predictors was derived from our causal DAG (see Table 1 and Figure 1). Due to modelling and data limitations, some of the predictors were unobserved or were modelled as a construct consisting of several variables. For our causal analysis, we computed adjustment sets in three different scenarios for separate exposures within the DAG: i) mobility of population, ii) awareness of COVID-19 (i.e. Google searches for “corona”), iii) weather (i.e. temperature).
Observed model variables
3.1 Variables
We downloaded German daily case numbers on district level reported by Robert Koch Institute (RKI, [49], acquired on 12 July 2020) and aggregated them by date. The number of daily active cases for day d was derived by subtracting the total number of reported cases on day d and day d − 14 (14 days as a conservative estimate for the infectious period, which corresponds here to the required quarantine time in Germany).
To assess the mobility of the German population, we used data publicly available on German state level from Google [20]. Measurements are daily relative changes of mobility in percent compared to the period of 3 January 2020 to 6 February 2020. Missing values (25 out of 13 488) were imputed with value 0 and the state level measurements were passed onto districts within the corresponding state. Google mobility data was available for six different sectors of daily life (“retail and recreation”, “grocery and pharmacy”, “parks”, “transit stations”, “workplaces”, “residential”) which means that “mobility” is a construct consisting of several variables. All variables but “residential” mobility are relative changes of daily visitor numbers to the corresponding sectors compared to the reference period. “Residential” mobility is the relative change of daily time spent at residential areas.
The notion of awareness in the population of COVID-19 describes the general state of alertness about the new infectious disease. As such, it was hard to measure directly. As a proxy, we used the relative interest in the topic term “corona” as indicated by Google searches. The daily data was available on state level [21] and passed onto district level. As a second proxy for awareness, we used the daily reported number of COVID-19 cases on the day of the exposure: Since media reported case numbers prominently, we assumed that this could reflect individual awareness, too.
We constructed daily weather from four variables (“temperature”, “rainfall”, “humidity”, “wind”). Weather data was downloaded from Deutscher Wetterdienst (DWD, [13]) for all weather stations in Germany below 1000 meters altitude with daily records in 2020 until 8 July 2020. District level daily weather data was aggregated per district by averaging the data from the three nearest weather stations (which includes weather stations inside the district). Missing values were imputed with mean values (n = 59 for wind).
The reported number of COVID-19 cases varied strongly by day of the week. Thus, we included “weekday” as a categorical variable. Similarly, the reported cases and the exposure to the virus were affected by official holidays. Within the observation period, this included among others Good Friday, Easter Monday, and Labor Day. To correct for effects of these days, we included two variables in the model, “Holiday (report)” (indicates if the day of the report was a holiday, because governmental health departments were less likely to be on full duty) and “Holiday (exposure)” (indicates if the day of exposure to the virus was a holiday, because the population behaves differently on holidays).
For different official and political measures we used one-hot encoded daily variables, i.e. ban of mass gatherings, school and kindergarten closures and their gradual reopening, contact restrictions, and mandatory face masks for shopping and public transport.
We included several social, economic, and demographic factors on the district level with direct or indirect influence on the risk of exposure to SARS-CoV-2 in our analysis. All are readily available from INKAR database [6]. We used the share of population that is 65 years or older and the share of population that is younger than 18 years (Age), the share of females in population (Gender), the population density, the share of foreign citizenships and the share of the population seeking refuge (Foreign citizenship), the share of low-income households (Socio-economic status), voter turnout, share of right-wing populist party votes, and the number of nursing (retirement) homes.
All variables but the outcome “Reported new cases of COVID-19” and the offset “Active cases” were centered for numerical stability. We did not scale variables to unit variance to maintain interpretability of effects on the original scale of variables. Additionally, we lagged the effect of all variables (but outcome, offset, and the non-dynamic socio-demographic variables) by 8 days (see Section 5) which means that we assumed that their effects on the outcome will be visible after 8 days.
4. Methods
4.1. Causal analysis with DAG and adjustment sets
We used a directed acyclic graph as a graphical representation of the hypothesized causal reasoning that leads to exposure to the SARS-CoV-2 virus, onset of COVID-19, and finally reports of COVID-19 cases. Every node vi in the graph is the graphical representation of an observed or unobserved variable xi, a directed edge eij is an arrow from node vi to vj that implies a direct causal relationship from variable xi onto variable xj. The set of all nodes is denoted by V, the set of all edges by E, as such, the complete DAG is the tuple G = (V, E). The seminal works of Spirtes and Pearl [53, 44] introduce the theory of causal analysis, do-calculus, and how to analyze a DAG to estimate the total or direct causal effect from a variable xi onto a variable xj. The direct effect is the effect associated with the edge eij only (if it exists), while the total effect takes indirect effects via other paths from vi to vj into account, too. Here we estimated total effects only, since most of our variables were not hypothesized to have a direct effect on the reported number of new COVID-19 cases. In contrast to prediction tasks, where one would include all variables available, it is actually ill-advised to use all available variables to estimate causal effects, due to introducing bias by adjusting for unnecessary variables within the causal DAG. This is why we need to identify a valid set of necessary variables (an adjustment set) to estimate the proper causal effect [44]. The “minimal adjustment set” [22] is a valid adjustment set of variables that does not contain another valid adjustment set as a subset. However, identifying a minimal adjustment set might not be enough to reliably estimate the causal effect. Thus, we identified the “optimal adjustment set” [25] as the set of variables which is a valid adjustment set while having the lowest asymptotic variance in the resulting causal effect estimates.
We analyzed the DAG from Section 2 with the R Software [48] and the R packages dagitty (formal representation of the graph and minimal adjustment sets [54]) and pcalg (for finding an optimal adjustment set [31]). For the defined exposures and the outcome “Reported new cases of COVID-19”, we computed the minimal and optimal adjustment sets. Since it was possible that these sets contained unobserved variables that needed to be left out of the regression model, we chose the valid set with the highest pseudo-R2 (see next section) to estimate the final total causal effect from exposure to outcome.
4.2. Regression with negative binomial model
We can estimate the causal effect from exposure to outcome by regression [44]. Since the outcome “Reported new cases of COVID-19” is a count variable, one should not employ a linear regression model with Gaussian errors, but instead we assumed a log-linear relationship between the expected value of the outcome Y (new cases) and regressors x, as well as a Poisson or negative binomial distribution for Y :
 where α is the regression intercept, S is the set of adjustment variables for the exposure i*including the exposure variable itself, βi are the regression coefficients corresponding to the variables xi. As such βi* is the total causal effect from exposure variable xi* on the outcome Y.
where α is the regression intercept, S is the set of adjustment variables for the exposure i*including the exposure variable itself, βi are the regression coefficients corresponding to the variables xi. As such βi* is the total causal effect from exposure variable xi* on the outcome Y.
The Poisson regression assumes equality of mean and variance. If this is not the case one observes so-called overdispersion (the variance is higher than the mean), this indicates one should use regression with a negative binomial distribution instead to estimate the variance parameter separately from the mean.
We needed to account for the fact that our outcome is not counted per time unit (one day) only, but depends on the number of active COVID-19 cases: Holding all other variables fixed, the number of new cases Y is a constant proportion of the number of active cases A. This was modeled by including an offset log(A + 1) in the regression model (1):
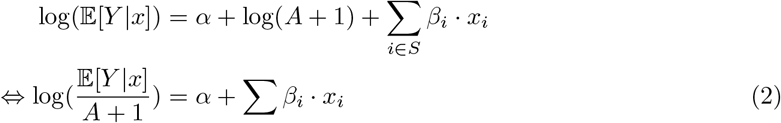
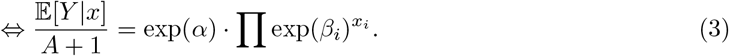
Here we added a pseudocount “+1” to ensure a finite logarithm and avoid division by 0.
One can interpret the model as approximating the log-ratio of new cases and active cases by a linear combination of the regressor variables (2). If all variables xi are centered in (3), we have for the baseline ∀i xi = 0⇒ 𝔼 [Y |x = 0] = exp(α) · (A + 1). In other words, the exponentiated intercept is the baseline daily infection rate (how many people does one infected individual infect in one day). If we hold all variables xi fixed (e.g. at baseline 0) in (3) but now increase the exposure variable xi* = 0 by one unit to xi* + 1 = 0 + 1, we have 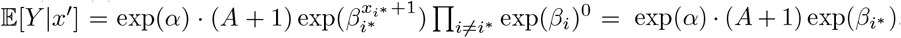 , which means the exponentiated coefficient βi* describes the rate change of the outcome by one unit increase of the exposure.
, which means the exponentiated coefficient βi* describes the rate change of the outcome by one unit increase of the exposure.
In practice, given observations of Y and x we estimate the regression coefficients α and βi by maximum likelihood [27]. Our observational measurements are ykt and xikt, where k indicates the corresponding district and t the date of measurement.
When we analyzed different adjustment sets given by analysis of the causal DAG (i.e. the minimal and optimal adjustment sets), we first checked if the set included unobserved variables. If this was the case for the optimal adjustment set, we discarded the unobserved variables from the set and checked if it was still a valid adjustment set (function gac in package pcalg [46]). If a minimal adjustment set contained unobserved variables, we discarded the whole set. We conducted a log-linear regression (function glm with family=poisson() for Poisson regression, and glm.nb from the MASS package for the negative binomial regression [56]) for every remaining valid adjustment set as regressors and calculated a Pseudo-R2 given by 1− Vm/V0, where Vm is the sum of squared prediction errors of the current model and V0 is the sum of squared prediction errors of the null model (intercept and offset only). That is, our Pseudo-R2 is 1 minus the fraction of variance unexplained. Finally, we decided for the model/adjustment set with the highest pseudo-R2. We report the exponentiated estimated coefficients along with 99 percent confidence intervals of the estimates.
5. Results
Descriptive statistics for the included variables are presented in Table 2.
Descriptive Statistics for observed variables
In the observational period, the number of daily reported COVID-19 cases increased till the end of March/beginning of April and continually decreased afterwards till the beginning of June 2020 with a slight increase and decrease afterwards (Figure 2A). On the other hand, the (log-)ratio of reported cases over active cases decreased steeply till the mid of April and increased steadily afterwards with a slight decrease close to the end of the observation period (Figure 2B). Both figures examplify a considerable variation among the districts (light blue points are individual district’s data).

Temporal and district level variation of outcome (log-scale)
In Germany, we observed a rebound in mobility after the initial political measures, reductions in incident cases were associated with a diminishing public interest in COVID-19, and temperatures were overall increasing (cf. Figure 3); with correlations between temporal progression and mobility in retail and recreation rA,D = −0.02, awareness (“Searches corona”) rA,C = −0.29, and temperature rA,B = 0.79.

Temporal variation of outcome and main determinants
5.1 Main results
We list the results of our causal analysis for the effects of our variables in Table 3. The estimates are multiplicative rates of increase/decrease for a one unit increase of the respective variable: Values above 1 lead to an increase, below 1 to a decrease of the infection rate. To put these estimates into perspective, Figure 4 shows the relative causal effect of the different exposure variables on the number of reported COVID-19 cases on a range of sensible values of the exposure variables (95 percent quantiles of data points).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Relative causal effects of exposures
Causal effect estimates with 99 percent confidence bands
Within our framework, we saw strong effects for mobility in retail/recreational areas and essential shopping (grocery and pharmacy). In the former, an increase of 1 percent point mobility compared to the reference period (03 January to 06 February 2020) leads to an increase of the daily reported case number by about 0.8 percent. Contrarily, a corresponding increase of 1 percent point for the areas of grocery/pharmacy leads to a decrease in the reported case number by approximately 0.5 percent. Mobility on workplaces showed a small effect of 0.3 increase in case numbers for every 1 percent point increase in mobility. Other causal effects of mobility were insubstantial and not consistent in their direction (99 percent confidence intervals of estimates include 1). Figure 4 shows the effects of mobility on a range of possible values. Thus, we expect an increase of daily cases by approximately 23 percent if mobility in retail/recreation reaches baseline levels of 0 percent difference to the reference period. On the other hand, an increase of mobility for grocery/pharmacy by 10 percent points compared to the reference period leads to a reduction of the infection rate by approximately 7 percent.
“Awareness” had two opposite effects on the outcome in our DAG. Awareness measured by Google searches for corona had a positive effect on the number of reported cases. An one percent point increase of the state’s Google searches (relative to other states and the observation period) leads to an increase of approximately 1 percent. For example, if a district shows 10 percent points more relative searches for corona then another one, we expect approximately 11 percent more infections for this district after 8 days. COVID-19 burden (reported number of cases on day of exposure) affected the outcome negatively, where every additional daily case in the district leads to a 0.6 percent decrease in newly reported case numbers. The last plot in Figure 4 visualizes this relationship: For a local outbreak with 20 daily cases as COVID-19 burden, we estimate as total causal effect a subsequent reduction of infection rate by 9 percent.
Within our model, we observed a causal effect of temperature and all other weather variables. Every increase of 1 degree Celsius in temperature leads to a reduction of the daily reported case numbers by approximately 0.8 percent. Similarly strong was the effect of rainfall: One millimeter (=1 liter per square meter) more rainfall leads to an increase of reported case numbers by approximately 1.1 percent. We observe small effects for humidity and wind as well (higher humidity leading to fewer cases, stronger wind leading to less cases). In perspective (Figure 4), with temperature we expect an increase by approximately 9 percent at a daily average temperature of 0°C. For rainfall, we expect on a very rainy day with 10 mm rainfall a corresponding increase of the infection rate by approximately 2 percent.
In all cases we opted to use the reduced optimal adjustment set over the minimal adjustment sets because of higher pseudo-R2 values (mostly above 0.3), except for mobility, where the minimal adjustment set had a higher pseudo-R2. Notably, these sets always include most of our socio-demographic variables as confounders (cf. Table 4) as well as the policy variables (except for COVID-19 burden). We also decided for the lag of 8 days based on the highest pseudo-R2 values compared to other lags on the chosen adjustment sets. Similarly, negative binomial regression was chosen over Poisson regression, because the latter showed overdispersion and overall lower pseudo-R2 values.
Final adjustment sets for causal analysis
6. Discussion
6.1. Main findings
Our objective was to identify causal effects for COVID-19 cases. We found that weather affects the reported number of infections, especially temperature (which has a reducing effect on case numbers) and rainfall (which increases case numbers). We saw that reports of high case numbers in districts led to a reduction in new infection numbers, which indicates risk-averse awareness in the population. The overall effect of mobility showed no consistent effect, however, in specific areas significant causal effects could be measured: Increasing activity in retail and recreational areas increased reported case numbers, while increased movement for essential shopping (grocery and pharmacy) led to reduced case numbers.
Furthermore, we made a strong case for the use of causal DAGs in epidemiology and a pandemic like COVID-19: DAGs allow to choose confounders for the analysis in a principled and statistically correct way while reducing possible causes for bias. Also, the DAG formalization allows for discussion about the underlying causal structure.
6.2. Comparison with previous research
Most research on determinants affecting case numbers of COVID-19 is restricted to single aspects [18, 36, 51, 58]. To reliably identify causal drivers, one needs to adjust for confounders. To this end, we used an integrated model with variables from different aspects like mobility, awareness, weather, or socio-demographics and identified confounders by causal analysis with a directed acyclic graph. A causal approach is used in another current COVID-19 analysis [19]. There, however, they identify the causal relationships (reconstruct a DAG), while we estimated causal effects for a given hypothesized DAG.
Several studies assessing the impact of public health measures on mobility have each observed a downward trend accompanied by a decrease in the number of newly reported cases [8, 10, 18, 33, 34, 38].
Our findings regarding awareness/Google Trends analysis are in good agreement with the correlations found by Effenberger et al. [16], Higgins et al. [26], and Yuan et al. [64], who conclude that alertness to COVID-19 rises several days before the highest number of cases are reported. At this point it should be noted, that awareness is substantially influenced by public media coverage, which should be considered, if possible, in future studies [26]. As such, awareness is difficult to measure and here the number of Google searches for “corona” could only be a proxy for this concept.
In addition, in alignment with other recent published studies, our results confirm evidence which associated a negative effect of temperature on new COVID-19 cases [4, 12, 39, 47, 51, 52, 55, 58, 60]. It is however controversial to other scientific literature describing no effects [5, 28, 29, 30, 63] or even converse correlations [2, 61]. The conflicting results might be explained by different climates and characteristics of the populations under study. While we are confident that our strict causal analysis resulted in effect estimates as undistorted as possible, there might be unconsidered bias in those other studies. Further research needs to be done to elucidate the biological characteristics of the novel virus SARS-CoV-2 regarding its ambient temperature survival and transmission. In regards of humidity, our findings (higher humidity leading to increased case numbers) are in agreement with previous research [47, 60, 30]. Finally, we found a positive causal effect of increment precipitation and a raise in COVID-19 cases, which supports previous observations [52].
6.3. Limitations and strengths
While use of a causal DAG is itself a strong tool to identify causal effects (and not just statistical associations), it introduces two limitations: causal assumptions within the graph (depicted by edges) need to be well justified, and the statistical regression model that calculates total causal effects needs to be appropriate for the task at hand. We endorse our graph as a basis for discussion on residual confounding.
We observed overdispersion and a substantial increase in model performance with a negative binomial regression compared to Poisson regression, which is in line with the results on COVID-19 daily case counts of Kraemer et al. [33] and others [39, 4]. We did not model case counts with a differential equation model like the classic SIR-model [32] and its successors, since these are more suited to prediction [e.g. 1] while our choice of a negative binomial regression framework allowed us to estimate the effects of confounders more reliably. There are more advanced statistical methods for count data, e.g. zero-inflated models and mixed models. We tested both approaches as extensions to the negative binomial regression and experienced numerical problems and increased computing time, along with an insubstantial increase in model performance. Furthermore, our model assumed that all variables have effects proportional to the size of their measurements. It is possible that some variables show saturation effects or opposite effects for lower, medium, or high values. This could be modelled with polynomial or other transformations of the variables, which we did not employ due to limited temporal and spatial data availability.
As we were using administrative data for our analysis, the results are susceptible to the Modifiable Area Unit Problem (MAUP) [43]. The MAUP postulates that different regional aggregations of the units of observation may lead to different results and conclusions. Due to limited available data for the different variables, there is currently no way to overcome this.
Our observation period was restricted to succession from late winter to spring and summer (February to July). Nevertheless, this transition with increasing temperature was a natural experiment that allowed clues on weather effects.
We could not include data on health care utilization during the pandemic into our models due to the lack of available resources. This is planned for a later follow up to this paper since we rank health care utilization and mobility within health care facilities among the strong factors for COVID-19 progression: personnel in hospitals and private practices is particularly exposed to infection, while the lack of adequate care for other diseases has severe effects on general health of the population. At the same time, health care facilities are key for testing and surveillance of COVID-19 patients.
While our analysis focused on Germany and its districts, we assume that results may be transferred to other countries by adjusting for their respective weather conditions, mobility habits, socio-demographic characteristics, and other determining factors.
The code and resources for our analysis are available on Github, we invite other researchers to replicate our analysis with different assumptions using the files provided in the repository1 of the article.
6.4. Discussion of causal effects
In our analysis, the adverse effect of mobility in retail/recreation and the favorable effect of mobility in grocery/pharmacy make a strong case for the successful implementation of policies like contact restrictions which limit the number of individual interactions that lead to infections. This is due to retail/recreational areas encompassing mostly places of social gatherings like restaurants and bars, malls, sports and music venues, among others, while if people are doing more of their essential shopping at supermarkets, they will most likely stay at home with less contact to other people.
The causal effects of awareness measured via searches for “corona” and the COVID-19 burden are harder to interpret. We assume that within our model, the searches for “corona” are an insufficient proxy for awareness, while the decreasing effect for future case numbers of high daily COVID-19 burden numbers indicates it affects individual risk-behavior as a deterrent.
Similarly, the effects of temperature and rainfall can be interpreted as causal effects for indoor and outdoor activities, such that higher temperatures and low rainfall indicate more people spending time outdoor while lower temperatures and high rainfall result in indoor activities, which lead to more infections. In this light, we advocate for precautious measures like increased hygiene, face masks, and air ventilation for unavoidable indoor activities.
6.5. Conclusions
To the best of our knowledge, this is the most comprehensive analysis of causes for COVID-19 infections which integrates different data sources (all publicly available). Causal reasoning with a DAG allows us to estimate the causal effects reliably.
Our findings suggest that the causal effects of mobility, awareness, and weather need to be taken strongly into account when deciding for mitigation and suppression measures, depending on the recent and future COVID-19 pandemic development.
Data Availability
All data gathered from publicly available sources, see Github repository pertaining to the manuscript.
Footnotes
Email addresses: esteiger{at}zi.de (Edgar Steiger), tmussgnug{at}zi.de (Tobias Mußgnug), lkroll{at}zi.de (Lars Eric Kroll)
↵1 The repository is located here: https://github.com/zidatalab/causalcovid19
References
- [1].
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵



