
Abstract
We introduce a deterministic model that partitions the total population into the susceptible, infected, quarantined, and those traced after exposure, the recovered and the deceased. We hypothesize ‘accessible population for transmission of the disease’ to be a small fraction of the total population, for instance when interventions are in force. This hypothesis, together with the structure of the set of coupled nonlinear ordinary differential equations for the populations, allows us to decouple the equations into just two equations. This further reduces to a logistic type of equation for the total infected population. The equation can be solved analytically and therefore allows for a clear interpretation of the growth and inhibiting factors in terms of the parameters in the full model. The validity of the ‘accessible population’ hypothesis and the efficacy of the reduced logistic model is demonstrated by the ease of fitting the United Kingdom data for the cumulative infected and daily new infected cases. The model can also be used to forecast further progression of the disease. In an effort to find optimized parameter values compatible with the United Kingdom coronavirus data, we first determine the relative importance of the various transition rates participating in the original model. Using this we show that the original model equations provide a very good fit with the United Kingdom data for the cumulative number of infections and the daily new cases. The fact that the model calculated daily new cases exhibits a turning point, suggests the beginning of a slow-down in the spread of infections. However, since the rate of slowing down beyond the turning point is small, the cumulative number of infections is likely to saturate to about 3.52 × 105 around late July, provided the lock-down conditions continue to prevail. Noting that the fit obtained from the reduced logistic equation is comparable to that with the full model equations, the underlying causes for the limited forecasting ability of the reduced logistic equation are elucidated. The model and the procedure adopted here are expected to be useful in fitting the data for other countries and in forecasting the progression of the disease.
I. INTRODUCTION
The highly contagious SARS-CoV-2 has infected more than six million people worldwide since its first detection in China on December 31 [1]. The novel coronavirus is the fourth wave in the class of coronaviruses. In less than two months, the virus has spread all over the world, posing serious threats to healthcare systems and economies. The alarming speed of transmission, the virulence of the disease, and the unprecedented high proportion of fatalities even in countries with high healthcare indices have raised questions about what kind of interventions are appropriate for a given setting. The wide variability in infected numbers and fatalities in different countries and settings has also brought into sharp focus a debate about the underlying causes of the variability. In the absence of any treatment for the disease and non-availability of vaccines in the near future, policy makers have resorted to standard epidemiological interventions, such as social distancing, isolation, contact tracing, and quarantining, and more recently a complete lock-down.
At a basic level, the purpose of all non-pharmacological interventions is to control disease transmission by limiting the proportion of the population exposed to the virus as much as possible. Furthermore, inherent in the process of implementation of these interventions are delays at each stage. The delay time-scales are specific to the particular intervention.
The importance of mathematical models describing the spreading dynamics of infectious diseases has been recognized since early days [2]. In particular, the fact that timely models that include realistic features have often been helpful in decision making on healthcare issues is well recognized [2–4]. In the short period since the emergence of the coronavirus, there have been several mathematical models [5–17], to name a few. Some of these models attempt to evaluate the contribution from different transmission routes, such as contact tracing and isolation [10, 11, 18], travel restrictions [16, 17] social distancing [19, 20], lock-down measures [16, 21, 22], and a combination of these interventions [12, 23–26]. These models broadly fall into three categories, deterministic, stochastic, and simulations. Several new mathematical techniques used in different disciplines have been employed to gain insights, which would not be possible with the traditional approaches in the field. These include the human mobility model [16], differential evolution[19], heuristic optimization technique [19], stochastic agent-based discrete time simulation [27], supply chain risk simulations [28], etc.
One class of epidemiological models attempts to describe the transmission dynamics by partitioning the population into smaller subsets based on the disease status such as the susceptible, exposed, infected, quarantined, recovered, etc [5–9]. Most models of this kind ignore age-dependent infection and fatality rates, and the heterogeneous spatial distribution of the population. In a sense, these models describe the evolution of the mean response of each type of population. Despite these limitations, these models have the ability to include several realistic features.
In the compartment type of models, the disease status of individuals changes with the development of the disease, i.e., transitions occur between two compartments either due to interaction of the infected with the susceptible or due to interventional actions. These models include delay time-scales inherent in the dynamics of transmission, for instance, the period spent in quarantine and the time required for tracing individuals exposed to the infected. These models have the ability to include several realistic features, such as the response of the population to interventional measures. However, generally, inclusion of more and more realistic features requires a larger number of partitions. Then, the number of differential equations increases and so does the number of parameters, making calibration of the parameters difficult [5–9, 13].
Motivated by the complexity of such models, we have devised a compartment-based model having the susceptible, infected, quarantined, traced, recovered, and the deceased populations. The susceptible and the infected form the core populations in the sense that it is through these two populations that inward/outward transitions occur with other populations. However, even this simple model contains several parameters, leaving numerical solutions as the only option for further analysis. Considering the fact that the model equations form a coupled set of nonlinear differential equations, we adopt mathematical methods drawn from nonlinear dynamical systems most appropriate for analyzing such equations [29]. We hypothesize ‘accessible population for infection’ to be a small fraction of the total population. The validity of this hypothesis can be appreciated by noting that the purpose of interventions is to minimize the exposure of the population to virus transmission, thereby limiting the spread of infection. We further assume that the order of magnitude of the accessible population is similar to that of the infected population. This assumption is made more quantitative. This, together with the structure of the model equations, allows us to decouple them into two equations. These two equations further reduce to a logistic type of equation for the total infected population with well defined parameters namely, the ‘testing rate’ and ‘contact transmission rate’ parameters [30, 31]. The equation can be solved analytically, thereby allowing for a clear interpretation of the parameters controlling the growth and inhibiting factors. The validity of the ‘accessible population’ hypothesis and the efficacy of the reduced logistic model is demonstrated by the ease of fitting the cumulative number of infections and daily new cases for the United Kingdom (UK). The procedure further allows us to forecast the progression of the disease. Using this information and calibrating the relative importance of the various transition rates (equivalently the associated parameters), we optimize the parameter values specific to the UK. This procedure allows us to delineate the various time scales contributing to the various regions in the time development of the disease. Using this, we numerically solve the full model equations. The calculated total infected population fits very well with the available data for the UK [32]. (UK does not publish data on the recovered and the active populations.) The model exhibits a turning point in the active infected population around May 15. However, since the rate of slowing down beyond the turning point is poor, the projected end time of the epidemic would be around late July with the predicted saturation level of the total number of infections ~ 3.52 × 105 assuming lock-down conditions continue.
II. THE MODEL
The total population N is partitioned into the susceptible S, active infected I, quarantined Q, those traced T after being exposed to the infected, recovered R, and the deceased D. The respective populations are denoted by Ns, Ni, Nq, Ntr, Nr and Nd.
Testing is one of the standard protocols used for identifying the infected. If αs is the rate of testing per day per million and ps is the probability of testing positive, then αspsNs is the transition rate from S to I. Infected individuals coming into contact with the susceptible class can transmit the virus. If βi is the transmission rate per contact, pi is the probability of transmission of the disease and F(di) is a distance-dependent interaction, then, piβiF(di)NiNs is the transition rate from S to I. Considering the fact that one of the primary routes of transmission is through airborne aerosols generated by the infected, larger separation is known to reduce the risk of transmission [19, 20, 33]. This distance-dependence of F(di) is generally expressed as  . However, in the present context where we will be dealing with a lock-down situation for most part of the progression of the disease, we set F(di) = 1.
. However, in the present context where we will be dealing with a lock-down situation for most part of the progression of the disease, we set F(di) = 1.
During testing, some individuals would always exhibit mild or ambiguous symptoms. These are identified as pre-symptomatic. If the probability of finding the pre-symptomatic is pq, then, αspqNs transition out of S to Q. Subsequently, when tested again, say after a quarantine duration [5, 34, 35], some of them may either test positive with a probability q1 or negative with a probability (1 − q1). If positive, the transition out of Q (to I) is q1λqNq. Here, 1/λq is the quarantine duration, usually of the order of the incubation period [34, 35]. Similarly, if tested negative, the transition rate out of Q into S is (1 − q1)λqNq. The total loss rate to Nq is λqNq.
Tracing those exposed to the infected, and testing to find if they are infected, are important steps in controlling the spread of the disease. Inherent in tracing such individuals are delays in tracing. Such delays cause increased transmission of the disease. If pt is the probability of tracing such individuals, then, αtptNs is the transition rate from S to T. Subsequently, individuals testing positive will move to the infected compartment I with a probability q2 and the rest with a probability (1 − q2) move to S. The total transition out of T is equal to λtNtr, where 1/λt is the time taken to trace the individuals. (There is also another possibility, namely, some individuals may show mild symptoms. Then, there would be a transition into Q. For the sake of simplicity, we have ignored this route.) Finally, the outward transitions from I are the recovery and death rates respectively, γr Ni and κdNi.
Collecting these terms, we have the following set of coupled nonlinear ordinary differential equations
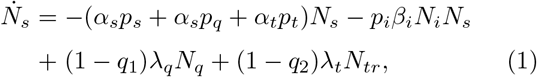
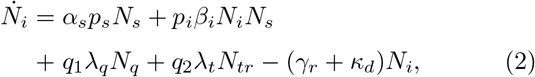




(Here, we have suppressed F(di) factor since it has been set equal to unity. Definitions of the notations are given in Table I). Note that the total infected population is given by Nt = Ni + Nr + Nd.
Definitions of the notations for our calculation.
To begin with, we highlight a few features of the model equations. Our model, much as other compartment-type models, has several parameters. However, several of these are directly measurable and therefore can be obtained from the literature. A few others are related to testing protocols and again can be obtained from the literature or from relevant open sources [32]. For instance, αsps, αspq and αtpt are directly related to testing rates and therefore, these are known for a given situation. A few other rate parameters such as λq, λt, λr and κd, are inversely related to measurable time-scales, such as the duration of quarantine τq, time required for tracing τt, time for recovery starting from illness τr and the time from illness to death τd, respectively [35, 36].
The present model includes two delay loops defined by Eqs. (3) and (4). These delays are natural to the implementation of the protocols. For instance, once quarantined, subsequent tests are conducted after quarantine duration to identify if quarantined individuals test positive or negative. Similarly, delays in tracing individuals are common. A more transparent way to describe these delay loops is through the integral representation of Eqs. (3) and (4), which forms the definitions of the two populations Nq and Ntr, respectively. For instance,
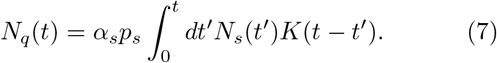
When the kernel K(t) is modeled using an exponential form with a single time scale 1/λq, i.e., 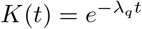 , one can easily verify that differentiating Eq. (7) (using the Leibniz rule) leads to Eqs. (3). The convoluted nature of the integral physically implies that those quarantined earlier will leave the quarantine sooner than those quarantined later.
, one can easily verify that differentiating Eq. (7) (using the Leibniz rule) leads to Eqs. (3). The convoluted nature of the integral physically implies that those quarantined earlier will leave the quarantine sooner than those quarantined later.
Equations (1-6) constitute a set of coupled nonlinear differential equations. A standard procedure for further analysis of such equations is through numerical integration. While this is a necessary step, here we adopt a reductive analysis of the model equations by exploiting the fact that there are two main populations, namely, the susceptible (Eqs. 1) and the infected (Eq. 2). Furthermore, Eqs. (5,6) are essentially decoupled from the rest (transitions to R and D are from I). These two features suggest that Eqs. (1,2) can be decoupled from the rest of the equations. We refer to the decoupled equations as the reduced model equations. Since the two equations can be further reduced to a logistic-type equation (referred to as the reduced logistic equation), it can be analytically solved. As we shall see, analysis of this equation provides insights that prove to be useful for the analysis of the full model Eqs. (1-6). (We shall often refer to Eqs. (1-6) as “full model equations” to avoid confusion.)
III. CONCEPT OF ACCESSIBLE POPULATION: THE REDUCED MODEL
We now introduce the concept of ‘accessible population for transmission of the disease’. To appreciate this concept, consider the spreading dynamics of a contagious disease in the absence of any interventions. Then, in principle, the entire population is exposed to the disease, and it may spread to the entire population (barring the possibility of the population acquiring herd immunity). In this case, the entire population is the accessible population. However, since no Government would like to see the entire population infected, interventional measures are enforced precisely to mitigate the risk of transmission and limit the population exposed to the disease to a minimum. In this case, the accessible population is expected to be a small fraction of the total population. These two limiting cases can be accommodated by hypothesizing the accessible population to be a fraction of the total population, where the fraction is determined by whether interventional measures are imposed or not.
Consider dropping all terms except αspsNs and piβiNiNs in Eqs. (1,2). Then, these two equations get decoupled from the rest of the equations. Further, because all other inward/ outward transitions are removed, the character of the compartment I changes from the active infected to the cumulative infected It with Nt denoting the corresponding population. Then, we have
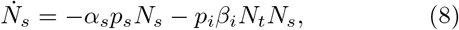
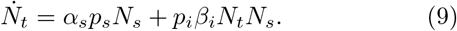
Noting that
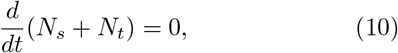 we have Nt + Ns = constant. Without loss of generality, we set Nt + Ns = Ns(0), the total population. Then, we get a single equation governing the cumulative infected population, given by
we have Nt + Ns = constant. Without loss of generality, we set Nt + Ns = Ns(0), the total population. Then, we get a single equation governing the cumulative infected population, given by
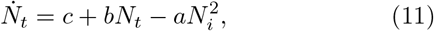

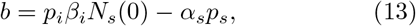

Equation (11) has the well known form of logistic equation, extensively studied in the context of population dynamics [37], with a notable difference, namely, the parameters a, b and c have a well defined interpretation as discussed above. We refer to Eq. (11) as the reduced logistic equation. (For brevity we often refer to αsps and αiβi as testing and contact transmission rates, respectively.)
We begin with a few observations on the relative magnitudes of the model parameters in the absence and the presence of interventions. Consider a situation when there are no constraints. Then, one should expect that the testing rate (αsps) to be low (compared to the lockdown period) due to absence of any guidelines from policy makers. Similarly, since infected individuals carry on with their routine activity, the number of contact transmissions is high and hence, the contact transmission rate (piβi) is expected to be high (compared to when interventions are in place). Then, the total accessible population denoted by Na(0) is the entire population of the region or the country, i.e., Na(0) = Ns(0). In contrast, when interventions are in place, testing rates are high to ensure identification of the infected, therefore, αsps is high. In this situation, since the mobility of individuals is restricted, the number of contacts is severely limited, i.e., piβi will be small. Therefore, the accessible population Na(0) is expected to be small compared to the total population Ns(0). These two limiting cases can be written as 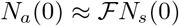 . These qualitative statements about the accessible population will be made quantitative by carrying out a detailed analysis of Eq. (11).
. These qualitative statements about the accessible population will be made quantitative by carrying out a detailed analysis of Eq. (11).
Consider the initial growth of Eq. (11) by dropping the quadratic term. Then, we have

The solution is given by
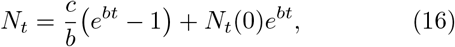 where Nt(0) is the initial number of infections. As can be seen, the growth rate given by b ≈ piβiNs (0) depends on Ns(0), the total population. Therefore, the growth rate can be high. In addition, the pre-factor for the exponential growth term (in Eq. 16) depends not only on Nt(0) but also on c/b = αsps/piβi. Thus, the initial growth depends on relative magnitudes of Nt(0) and asps/piβi.
where Nt(0) is the initial number of infections. As can be seen, the growth rate given by b ≈ piβiNs (0) depends on Ns(0), the total population. Therefore, the growth rate can be high. In addition, the pre-factor for the exponential growth term (in Eq. 16) depends not only on Nt(0) but also on c/b = αsps/piβi. Thus, the initial growth depends on relative magnitudes of Nt(0) and asps/piβi.
It is straightforward to obtain the solution of Eq. (11). (See Appendix for details.) Here, it is adequate to consider the solution in terms of the parameters a, b, and c, given by
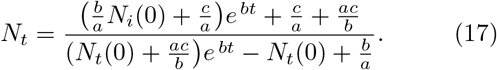
We now examine two limiting cases. For short times, Nt tends to 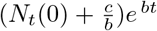 (since the denominator is dominated by b/a = Ns(0)), consistent with the short time solution given by Eq. (16). For long times however, Nt tends to b/a = Ns (0), the total population.
(since the denominator is dominated by b/a = Ns(0)), consistent with the short time solution given by Eq. (16). For long times however, Nt tends to b/a = Ns (0), the total population.
The self-limiting nature of Eq. (17), a characteristic feature of logistic equations, is evident from the fact that Nt tends to Ns(0). In other words, the entire population becomes accessible for transmission of the disease. Clearly, the situation can only represent the growth of infection in the absence of any kind of interventions.
On the other hand, the effect of all interventions is to limit the contact transmission rate, thereby limiting the proportion of the exposed population to the disease to a small fraction. It is this that we call the accessible population. In other words, the accessible population Na(0) is of the same order as the infected population. This can be written as  , where
, where 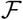 is a small fraction. It must be noted here that the value of the fraction
is a small fraction. It must be noted here that the value of the fraction 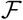 depends on the nature of interventions in force.
depends on the nature of interventions in force.
However, within the scope of the reduced logistic model, the evolution of Nt is independent of the values of the parameters αsps and piβi during the absence or presence of interventions. As a consequence, the asymptotic value of the cumulative infected population is always Nt = Ns (0), the entire population. Therefore, demonstrating the accessible population is a small fraction of the total population is outside the scope of Eq. (11) and the full model Eqs. (1- 6). An independent way of demonstrating 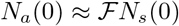 is desirable.
is desirable.
A. Quantitative estimate of the accessible population
Since the factor 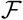 is not well determined, there is a necessity to get a better estimate of this parameter or the accessible population Na (0). Assuming that the accessible population is of the order of Nt, we assume that
is not well determined, there is a necessity to get a better estimate of this parameter or the accessible population Na (0). Assuming that the accessible population is of the order of Nt, we assume that 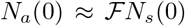 . This is equivalent to using Na(0) in place of Ns(0) in Eq. (17). Then we numerically evaluate the dependence of Nt on the parameters on Na (0), αsps, and piβi. Given the fact that the disease evolves, we expect that the accessible population Na(0) also evolves with time and in the early stages of evolution, Na (0) will be small, even in the absence of interventions.
. This is equivalent to using Na(0) in place of Ns(0) in Eq. (17). Then we numerically evaluate the dependence of Nt on the parameters on Na (0), αsps, and piβi. Given the fact that the disease evolves, we expect that the accessible population Na(0) also evolves with time and in the early stages of evolution, Na (0) will be small, even in the absence of interventions.
Consider the dependence of Nt on Na (0), keeping αsps and piβi fixed. We find that even for relatively large values Na(0), Nt grows exponentially; for intermediate values, a near saturation value is reached in a relatively short duration of 10-15 days; and for small values, the saturation value is not reached even after 100 days. These features are illustrated in Fig. 1(a) in plots (i-iii) for Na (0) = 8 × 105, 2.8 × 105 and Na (0) = 1.45 × 105 respectively, keeping piβi = 3.3913 × 10−7 and αsps = 1.0 × 10−4. We have also examined the influence of piβi,
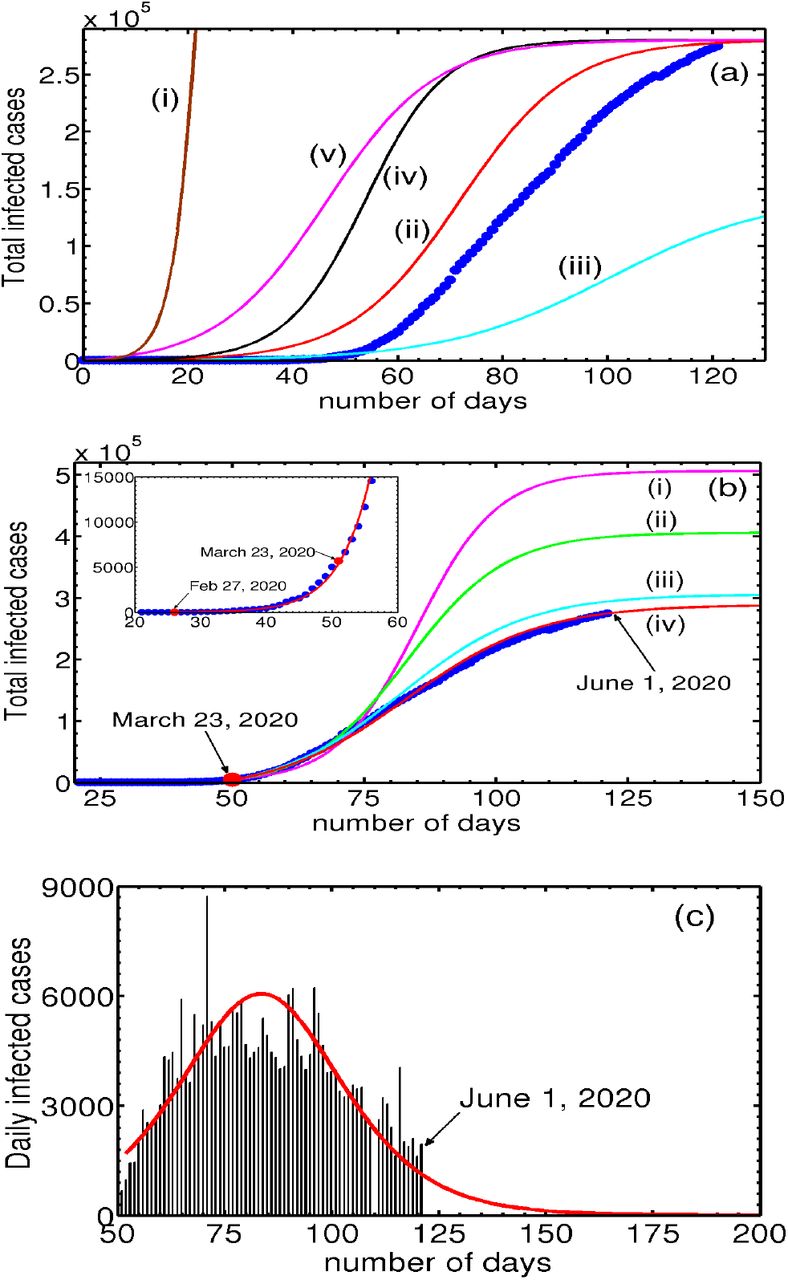
(Color online) (a) Plots of Nt for decreasing values of Na (0) as a function of time: (i) Na (0) = 8 × 105, (ii) 2.8 × 105, and (iii) 1.45 × 105 respectively, keeping piβi = 3.3913 × 10−7 and αsps = 1.0 × 10−4 fixed. (ii) shows decreasing Na(0) by a factor of 5.51 leads to slow increase in Nt. (iv) Plot of Nt for piβi = 4.752 × 10−7, keeping Na(0) = 2.8 × 105 and αsps = 1.0 × 10−4. Smaller values of piβi take longer time for Nt to grow as is clear (see (ii) and (iv)). (v) Plot of Nt for αsPs = 1.1 × 10−3, keeping Na(0) = 2.8 × 105 and piβi = 3.3913 × 10−7 fixed. Increase in αsps leads to a faster initial growth seen in (v) and (iii). Also shown is the cumulative number of infections (●) for the UK. (b) Figure shows the two-phase evolution of the disease. The inset shows the good fit using Eq. (17) with the cumulative infected cases for the UK (●) prior to March 23, 2020. Parameter used are Na(0) = 3.27 × 105, Nt(0) = 13, αsps = 1.0 × 10−5, psβi = 6.4622 × 10−6. Post lock-down period: The four curves (i-iv) correspond to the four iterations of Na(0) values. (i) Na(0) = 5.0 × 105,αsps =0.0, (ii) Na(0) =4.0 × 105, αsps = 1.8 × 10−3, (iii) Na(0) = 3.0 × 105, and (iv) Na(0) = 2.8 × 105, with αsps = 4.83 × 10−3 for latter two. The initial value of Nt(0) = 5687 on March 23, 2020. (c) Plots of daily new cases for the UK and the calculated daily new cases using the reduced logistic model predicted. keeping Na(0) = 2.8 × 105 and αsps = 1.1 × 10−3. Smaller values of piβi, Ni take longer time for the infection (Nt) to grow. This feature can be seen from the curves (iv) and (iii) for piβi = 4.7522 × 10−7 and 3.3913 × 10−7 respectively. We have also examined the growth dependence of Nt on asps, keeping the other two parameters fixed. The dependence of Nt on this parameter is similar to that on piβi. The curve (v) taken together with (ii) shows that increasing αsps also leads to faster initial growth of Nt. In the same plot, we have also plotted the total number of infected cases (●) for the UK.
A careful scrutiny of the total coronavirus cases (●) in the UK shows that it is similar- both in magnitude and shape -to the plot of Nt corresponding to Na(0) = 0.28 × 106 marked (ii) shown in Fig. (1a). This similarity suggests two important points. First, noting that the UK is under lock-down, one expects that the accessible population is a small fraction of the total population, and therefore we see that the order of magnitude of the accessible population Na(0) used is comparable to that of the infected population Nt shown in curve (ii). The figure also shows that as much as all populations dynamically evolve during the development of the pandemic, Na(0) also keeps evolving with time. Second, the similarity in shape of the UK data (●) with the sigmoidal shape of the logistic solution raises a question whether the similarity is accidental. If not, can this be used to fit the UK data?
B. Data Assimilation and fitting
However, considering the complex dynamics of the highly contagious virus and the fact that logistic equation can at best represent simple situations, any attempt to fit the data appears ambitious. Even so, it is tempting to examine if Eq. (17) could be used to fit the coronavirus data for some country/region. To do this, we first note that the reduced model equation contains just three parameters and the dependence of Nt on these parameters has already been examined [see Fig. 1(a)].
In most countries, the development of the disease falls into two phases, namely, the initial period when Governmental constraints are absent, referred to as phase one and the period beyond the lock-down date, called phase two. In the case of the UK, the first case was reported on January 31, 2020. Subsequently, the lock-down was imposed on March 23. Thus, we need to fit the data for the period January 31 to March 23 and then the rest.
Consider the period between January 31 and March 23, 2020. Briefly, the fitting procedure adopted here is to equate the initial growth rate of infections obtained from the coronavirus data with the model growth rate given by Eq. (16) (or Eq. 17). Using the fact that the accessible population is of the order of the total number of infections, we use a trial value of Na(0) (assumed to be a few times larger than the infected population) to fix the parameter βi. Then, the correct value of Na(0) that provides the best fit for the entire data is found iteratively by decreasing Na(0) so as to fit an increasing number of data points. The procedure is illustrated below.
Here, we use the analytical solution given by Eq. (17) (or solving Eqs. 8-9) with parameters and initial conditions appropriate for the unconstrained growth. Recall that the testing rate parameter αsps is low during the initial period and the contact transmission rate parameter piβi would be high. The values of these two parameters in the lock-down period are just the opposite.
Consider the first phase where virus transmission is unconstrained. A careful perusal of the UK data shows that a smooth increase in the infected numbers starts on Feb. 26, 2020, when the number infected stood at Nt = 13. The local growth rate obtained from the data over 8 days was found to be 0.25849/day. Equating this with the model growth rate given by piβiNa(0) (in Eq. 16), with a trial value of Na(0) = 4.0 × 105 fixes a value of βi = 6.4622 × 10−6. The solution of Eq. (17) (or Eqs. 8-9) obtained using the initial condition Nt = 13 keeping αsps = 0, passes through several more data points than 8. In the next iterations, we reduce Na(0), keeping in mind that the solution should pass through a larger number of data points. In addition, since the initial growth rate (Eq. 16) depends also on c/b = αsps/piβi, a proper value of αsps is required for a good fit. We find that just one iteration of reducing Na(0) to Na(0) = 3.27 × 105 with αsps = 1 × 10−5 fits the data well for the period from Feb. 27 to March 23, 2020, as shown in the inset of Fig. 1(b).
Fitting the data for the second phase follows the same iterative procedure except that the number of iterations is greater for the second phase due to the large number of data points. The number of infections as on March 23 stood at Nt = 5687. This number matches with the predicted value of Nt as on March 23, 2020, obtained from Eq. (17) for the first phase. (See the inset in Fig. 1(b)). Since the effect of lock-down is expected to take some time to manifest, we have taken the local slope over 17 points from the lock-down day is 0.13/day. This slope is equated with model growth rate using a trial value of Na(0) = 5.0 × 105 (αsps = 0) to obtain βi = 2.602 × 10−6. Using the initial condition Nt = 5687 in Eq. (17) (or solving Eqs. 8-9), we find that the solution (i) (with αsps = 0) passes through a few more than 17 points. In the next iterations, we reduce Na(0) = 4.0 × 105 and compute the solution taking into account the contribution from αsps = 1.8 × 10−3. The solution (ii) passes through several more data points. Two further iterations for successively smaller values of Na(0) = 3.00 × 105 and Na(0) = 2.9 × 105 are used to obtain the solution marked (iii) and (iv), respectively. (αsps = 4.83 × 10−3 is used in both cases.) This is shown in Fig. 1(b). As is clear from the Fig. 1(b), solutions (ii) and (iii) are seen to pass through successively larger number of points. Surprisingly, the solution curve labeled (iv) with Na(0) = 2.9 × 105 fits the entire data fairly well. Note the increasing trend of the values of αsps for successive iterations. This feature is consistent with the steadily increasing testing rates routinely used for proper enforcement of lock-down. This feature is easily incorporated by parameterizing αsps with time.
Now consider the estimation of the end time of the epidemic, usually defined as the time when no new infected cases are reported. Noting the close fit of the model predicted cumulative infected population Nt with the UK data seen in Fig. 1(a), 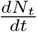 gives the model calculated new infected cases. This can be compared with the UK data for the daily new cases. This is shown in Fig. 1(c). As can be seen from the figure the general profile of the model predicted daily new infected cases matches well with the published data for the UK. The estimated end time of the epidemic to be last week of June.
gives the model calculated new infected cases. This can be compared with the UK data for the daily new cases. This is shown in Fig. 1(c). As can be seen from the figure the general profile of the model predicted daily new infected cases matches well with the published data for the UK. The estimated end time of the epidemic to be last week of June.
Apart from providing a close fit for the entire data, the method appears to have predictive power, as is clear from the curve (iv), which shows that the rate of slowing of the total number of infections is decreasing. The predicted saturation value is ~ 2.9 × 105. A near-saturation value is likely to be seen by the second week of June. These results suggest that the reduced logistic model can be used for obtaining fit for the COVID-19 data for other countries as well. The close fit in itself is attributable to the fact that the dominant contribution to the growth of the total infected population Nt comes from the two direct transitions. On the other hand, Eq. (17) does not include outward transitions (the recovered and the dead), and also the inward quarantine and tracing transitions. Therefore, the estimated saturation value and the projected future development should be taken with some reservations. This will be clear once the full model equations are analyzed and a fit with COVID-19 data for the UK is accomplished. Despite these limitations, because the reduced logistic equation retains basic growth contributions to the cumulative infected Nt, the fit with the data appears reasonable.
There are attempts to use logistic equations to get insights into the dynamics of COVID-19 transmission [30, 31]. For instance, a five-parameter hierarchical logistic model has been used to fit the observed data to project the cumulative number of cases for several countries [31]. The parameters entering in the model are determined by the fitting procedure.
IV. THE FULL MODEL
One of the challenges of compartmental models is the difficulty associated in making accurate predictions, mainly attributable to the uncertainties in obtaining proper estimates of the parameters [13–15, 35, 36]. For the same reason, forecasting is even more challenging. Often, several factors may also contribute to the same parameter, making it difficult for proper interpretation. In our model, however, several parameters in Eqs. (16) are related to measurable quantities. For instance, the parameters αsps, aspq and atpt respectively represent rates of testing positive, rates identified as pre-symptomatic, and tracing rate of those exposed to the infected. Similarly, parameters λq, λt, λr and κd are inversely related to quarantine duration τq = 1/λq and time required for tracing τt = 1/λt, time from illness to recovery τr = 1/γr, and time from illness to death Td = 1/κd. Though these quantities are country/region-specific, their values have been estimated in the literature [5, 6, 8, 35, 36, 38–42]. Some values are also available in the public domain [32, 43]. One parameter that is hard to estimate is the contact transmission rate βi, which is already estimated in the context of the reduced logistic equation.
A. Calibration of relative strengths of the parameters: insights into disease evolution number of days
However, the dynamical evolution of a nonlinear coupled set of equations such as Eqs. (1- 6) is necessarily complex. Therefore, in the absence of appropriate values relevant for the country/region, a systematic method of finding optimized values of parameters that fit the data under consideration requires calibration of all parameters in the model. This will also help us to delineate the different time-scales participating in Eqs. (1- 6). For instance, several of these parameters represent the growth or decay rates of these populations. Our model contains eight time-scales which are inversely related to the transition rates. These are βi, αsps, αspq, αtpt, λq, λt, λr and κd. These time scales control how these populations evolve with time. From the structure of Eqs. (1-6), it is clear that Ni, Nq and Ntr exhibit peaks as a function of time (days) whereas Nr and Nd grow monotonically. However, at what point of time do the peaks appear in these populations with the progression of the disease cannot be easily determined since these are coupled nonlinear differential equations where the evolution of any population depends on the evolution of all other populations [29]. More importantly, if one is interested in fitting the model predicted growth of populations, which convey the disease status (such as the total infected, active, recovered and dead), estimating the relative proportion of the populations as the disease evolves is necessary. Further, the total infected population commonly used to convey the disease status in daily briefings has contributions from all populations. Therefore, delineating and determining at what points of time each of these populations contribute to the total populations would provide required insight into further analysis.
Following the recently developed method in the area of plasticity [44–46], we investigate the influence of the parameters to identify the relative importance of the transition rates. Since it is a multi-parameter space, we vary each parameter, keeping all other parameters fixed at the reference set of values listed in Table II. The results are illustrated using plots of the active infected population Ni. The dotted curve shown in Fig. 2 is the reference curve corresponding to the reference set of parameters given in Table II. As in the case of the reduced logistic model, the growth of Ni depends sensitively on the contact transmission parameter piβi. (Note that in our model, this is the only parameter that directly contributes to growth of infections.) A 50% increase in the parameter induces a substantial increase (38%) in the peak height with the position shifting towards earlier time (by 25 days) as is clear from the curve (i). Noting that the position of the peak, i.e., the turning point of Ni is indicative of slowing down of the rate of infection, increasing peak height of Ni suggests slowing down of infections occurs at higher values of infections, where as a shift towards shorter times implies that slowing down occurs earlier. A similar effect but of lesser magnitude (20%) is seen when testing rate αsps is increased by a factor 8 as is clear from (ii).
Post lock-down period: Select set of parameter values serving as a reference set. q1 = q2 = 0.08 and pi = 0.1.

(Color online) Calibration of parameters for identifying the relative importance of transitions contributing to Ni by varying one parameter, keeping all others parameters fixed at reference values listed in Table II. The dotted curve is the reference plot for the active infected population Ni corresponding to the values in the Table II. (i) Plot of Ni for a 50% increase in piβi showing a substantial increase in the peak height (38%) and a shift by 25 days. (ii) Similar effects are seen when αsps is increased by a factor 8. (iii) The plot shows a substantial decrease in the peak height with a marginal shift in its position when αspq is increased by a factor of 2. (iv) The plot shows a decrease in the peak height as is increased by 60%. (v) Similar effect is seen when the recovery rate γr is increased by 60%.
In contrast, an increase in the quarantining rate αspq by a factor 2 decreases the peak height comparable in magnitude to that induced by βi with a shift in the peak position away from the origin by 20 days (see iii). A similar effect, but of lesser magnitude, is seen when αtpt is increased (not shown). The reduction in the peak height of Ni is understandable because the total inward transition is αsps + αspq + αtpt, and therefore increasing one of these changes the relative weights. Physically, the decrease in the peak height (commonly referred to as ‘flattening the curve’) accompanied by a shift in the peak position for longer times implies that as more individuals are quarantined, the disease control is facilitated.
We have also investigated the dependence of the recovery (γr) and death rate (κd) parameters on Ni. An increase in γr by 60% decreases the peak height substantially as is clear from (iv). Similarly, increase in the death rate κd leads to a decrease in the peak heights of Ni as is clear from (v). Clearly, increased recovery rate, a desirable feature, also leads to a decrease in the number of active infections. This feature is also intuitively obvious. On the other hand, increased death rate, though not desirable, also leads to decrease in Ni. We have also investigated the influence of other parameters and find that Ni is relatively insensitive to these parameters. Noting that any change in the parameter values relative to those corresponding to the reference curve changes the peak position and height, we conclude that the parameters listed in Table II are close to the optimized values.
The above analysis on the relative importance of the transition rates (equivalently the corresponding parameters), and the accompanying discussions, can now be used to delineate the contributions from different time scales participating in the transmission dynamics of the virus. As discussed above, the direct transitions from S to I, namely, piβi, to a lesser extent αsps, control the initial growth of Ni. The same also to the initial growth of the total infected population Nt. Similarly, the delayed routes, namely, the quarantine S and tracing T contribute to the mid region of the evolution of Ni and to therefore to the total population Nt also. Recall that the turning point of Ni is controlled by the balance between all inward transitions (from S to I, and Q and T to I) and outward transitions (I to R and D compartments). Then, the peak position of Ni can be identified with the inflection point of Nt. Therefore, the time development beyond the point of inflection of Nt is controlled by a balance of all inward and outward transitions. The insights from the above analysis identify three distinct stages in the evolutionary period of the disease, namely, the initial growth period, the mid developmental period and the final approach to saturation. As we shall see, this identification will be helpful in obtaining a good fit to the UK data.
B. Data assimilation and forecast
Having demonstrated that the two direct transition rates piβi and αsps are the dominant contributions to the growth of Ni and having assessed the relative importance of other transitions, we now consider the solution of the full model Eqs. (1- 6) with a view to obtaining the best possible fit with the COVID-19 United Kingdom data. Attempt will also be made to forecast the future progression of the disease.
Recall that the spread of coronavirus in the UK falls into two phases of development. During the first phase prior to March 23, 2020, there were no constraints and the disease transmission was free. After the lock-down date, the transmission is restricted. Therefore, the model parameters and the initial conditions relevant for the two phases are different. As in the reduced model, we assume that the dynamics of the disease transmission is limited by the accessible population Na(0) and not by the total population Ns(0), i.e., 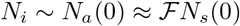 . Note that both Ni and therefore Na(0) depend on whether there are any interventions or not, and also on the type of interventions.
. Note that both Ni and therefore Na(0) depend on whether there are any interventions or not, and also on the type of interventions.
Consider the period between January 31 and March 23 corresponding to the initial phase. Here, we note that prior to the lock-down date, there would be no quarantining and tracing procedures and therefore, it is adequate to solve Eqs. (1,2,5,6), More specifically, we ignore the delayed inward transitions into I. Furthermore, in the first few days of the development of the disease, we may assume that the total number of the infected cases Nt is equal to the active infections Ni. Finally, since, we plan to fit the model solution with the UK data [32], publicly available coronavirus data for the total number infected, active infected, recovered and the dead are useful in further optimizing the parameters. Unfortunately however, only the total numbers of the infected and the dead are made available in the UK.
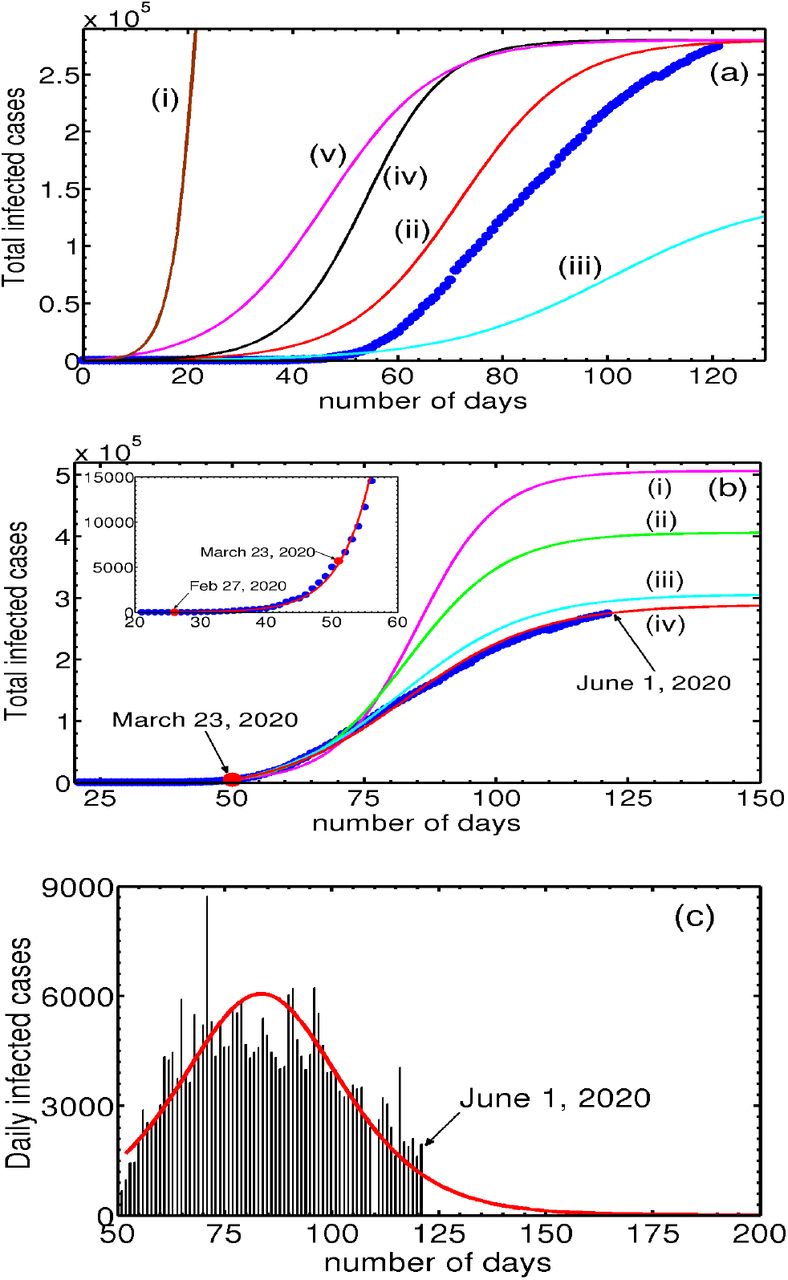
Now we are in a position to solve the relevant equations for the first phase. As discussed in Section III B, we use February 27, 2020 as the starting day for the first phase evolution of Eqs. (1,2,5,6). The local growth rate of 0.25849/day (on the starting day) over 8 days obtained from the log-linear plot of the cumulative infected cases for the UK is equated with the model growth rate given by piβiNa(0) to fix βi = 6.4622 × 10−6 by using the initial value of Na(0) = 4.0 × 105. Further, using the initial conditions for Nt(0) = Ni(0) = 13, Nr(0) = 0 and Nd(0) = 0, we solve Eqs. (1,2,5,6) from February 27 to March 23 by choosing a value for αsps that gives the best fit to the data for the period. (Here, αsps = 3.6 × 10−6 and the values of other relevant parameters are those listed in Table II.) The model-predicted total infected population Nt (continuous curve) along with the data points (●) is shown in the inset of Fig. 3(a). Clearly, the match is seen to be very good. Also shown is a plot of active infections Ni (dotted curve). Equations (1,2,5,6) also provide the values of Ni, Nr and Nd on March 23, 2020. These are Ni = 5407, Nr = 400, Nd = 285.

{kind=link}
{kind=link}
{kind=link}
(a) Inset: Plot of the total infected population (continuous curve), along with the UK data (●) from February 27, 2020 till March 31. Also shown is the active infected Ni (dotted curve). Post Lock-down period: Plots of the total infected population (curve marked i) along with the corresponding data for the UK (●) from March 23, 2020. Curve marked (ii) shows the active infected population. (b) Plots of the reported daily new cases for the UK along with the model predicted daily new cases. (c) Plots of the infected (i), quarantined (ii), traced (iii), recovered (iv) and deceased (v), starting from March 23, 2020. The values of the parameters used are given in Table II.
Now we consider the solution of Eqs. (1- 6) with a view to obtaining the best fit for the UK data for the period starting from March 23, 2020. Here again, we first find the growth rate from the data and equate it with the model growth rate. Here, we note that the effect of lock-down is expected to manifest after some time. For this reason, we use a 17-point slope in the log-linear plot. Equating 0.13/day with piβiNa(0) and using Ng(0) = 3.75 × 105 we get βi = 3.4693 × 10−6. The initial values used for evolving Eqs. (1- 6) are Ni(0) = 5407, Nq(0) = 0, Ntr(0) = 0, Nr(0) = 0, Nd(0) = 0. (The reason for using zero initial conditions for Nq(0), Ntr(0), Nr(0) and Nd(0) is that the values of these populations would not be recorded during the first phase. However, using the values obtained from the first phase for Nr and Nd makes little difference. Note that Ni(0) = 5407 is smaller than the total number of infected cases. Again, using Ni(0) = 5687 does not alter the results.) The parameters values used are those listed in Table II. Figure 3(a) shows plots of the calculated total infected population Nt and the total infected cases in the UK (●). Clearly, the fit is very good. The asymptotic saturation value of the total number of infections Nt turns out to be 3.52 × 105. Also shown is the active infected Ni labeled (ii). Further, the plot of the model predicted active infected population Ni (ii) exhibits a turning point (peak) around May 15. Subsequent decrease in Ni is seen to be slow. At this rate of slowing-down, the model predicts that a near saturation value of 3.52 × 105.
Now consider the estimation of the end time of the epidemic. A natural candidate for estimating this is the daily new infections. Considering the close fit of the model predicted cumulative infected population Nt with the UK data (see Fig. 3a), the model calculated daily new infections 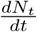 can be compared with the UK data for the daily new cases. This is shown in Fig. 3(b). As can be seen the general profile of the model predicted daily new infected cases matches well with the published data. Recall that the end time of the epidemic is defined as the time at which no new cases are reported. This definition is clearly impractical for forecasting since the state of saturation is always reached asymptotically. For this reason, we use an arbitrarily small value, say 300 new cases as the end date of the epidemic. Then, the estimated end time is late July.
can be compared with the UK data for the daily new cases. This is shown in Fig. 3(b). As can be seen the general profile of the model predicted daily new infected cases matches well with the published data. Recall that the end time of the epidemic is defined as the time at which no new cases are reported. This definition is clearly impractical for forecasting since the state of saturation is always reached asymptotically. For this reason, we use an arbitrarily small value, say 300 new cases as the end date of the epidemic. Then, the estimated end time is late July.
To the best of our knowledge, we are not aware of any model that fits the COVID-19 data for any country as has been done here, particularly over such long periods with the ability to forecast the future progression of the disease. However, there have been some efforts to fit data for the initial periods [8, 21, 22, 24, 26, 38, 47]. In view of the good fit for the UK data, the model can be used to fit the COVID-19 data for other countries and also to forecast the progression of the disease.
V. SUMMARY, DISCUSSION AND CONCLUSIONS
Recent literature has focused on abstracting the effect of various types of interventions through epidemiological models to make projections of how the disease progresses under different conditions. Recall that one limitation particularly applicable to the deterministic compartmental models is the difficulty in getting proper estimates of the parameters, particularly when the number of compartments is large. In this respect, simpler models with fewer compartments have an advantage. However, several factors may contribute to a single parameter. This is also a model-dependent feature. Therefore the ability of such parameters to represent the mitigating efficacy of interventions appears limited (see below). Furthermore, the number of parameters in such models is not necessarily small, making numerical solutions often the only choice. Therefore, any method - whether mathematical or conceptual - which simplifies analysis and easy interpretation is welcome.
Motivated by this, we hypothesize accessible population for transmission of the disease that can be the total or a small fraction of the total population depending on whether the transmission dynamics evolves in the absence or presence of interventions. Indeed, the effect of lock-down is evident in all counties where the disease has been controlled or nearly eliminated. At the mathematical level, we introduce a decoupling scheme to aid mathematical analysis that also helps easy interpretation. The model equations have been devised in such a way that the susceptible and active infected populations form the main populations. The decoupling is affected by dropping all inward and outward transitions excepting the direct transitions (piβiNa(0) and αspsNa(0)). Because, all outward transitions from I are ignored under this decoupling, the active infected population Ni takes the role of the cumulative infected population Nt. The simplicity of the reduced logistic equation (Eq. 11) allows easy identification of the growth and inhibiting factors in terms of the dominant growth factors (direct inwards transitions or parameters). Surprisingly, this simple equation provides a good fit to the reported cumulative number of infections for the United Kingdom, as is clear in Fig. 1(b).
The full model Eqs. (1- 6) contain several parameters whose range has been estimated in a number of studies[8, 21, 22, 24, 38, 40–42, 47]. However, when it comes to explaining or capturing the growth characteristics for a specific country, optimized parameters suitable for the situation are required. Following [44–46], we have determined the relative importance of the various transition rates (equivalently the associated parameters) subject to the constraint that the parameter values provide the best fit for the given data. In this work, we have made use of publicly available data on the total infected and daily new infected cases for the United Kingdom [32].
Figure 3(a) shows the fit obtained for the period till March 23, 2020 (shown in the inset) and for the period beyond. Clearly, the fit is seen to be very good for both the period till the lock-down date and the period thereafter. Comparing Fig. 3(a) with Fig. 1(b) for the reduced logistic map, we see that while the fits in both cases are comparable, the projections of the future progressions are significantly different. The saturation value predicted by the full model (shown in Fig. 3(a) is close to 3.52 × 105, whereas that predicted by the reduced logistic equation in Fig. 1(b) is ~ 2.9 × 105. Conventionally, the end time of epidemic is defined as the day on which no new infections are reported. However, since the approach to the end point is generally slow, a better variable to predict the end point of the epidemic is by comparing the model computed daily new case with the reported data on the daily new cases for the UK. Then, the end time of the epidemic predicted by the full model turns out be late July (see Fig. 3b). In contrast, the end time for the epidemic predicted by the reduced logistic model is late June. Clearly, the results obtained from the full model emphasize the limitations of the reduced model. A natural question is: what are the underlying causes?
The fact that the reduced logistic model provides a good fit also means that the major contributing factors for the growth of infection are included in Eq. (2). To see this, consider Eqs. (1-6). The growth of Ni(t) or more appropriately the daily new infected cases 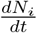 has two types of inward transitions, namely, direct and delayed. However, the dominant direct transition from S to I given by piβi controls the growth rate of Ni. The other direct transition αsps into I also contributes to a lesser extent. Now, consider the delayed inward transitions to I coming from Q and T. These transitions are smaller in magnitude and contribute to sub-exponential growth of Ni in time. More importantly, the turning point in Ni or
has two types of inward transitions, namely, direct and delayed. However, the dominant direct transition from S to I given by piβi controls the growth rate of Ni. The other direct transition αsps into I also contributes to a lesser extent. Now, consider the delayed inward transitions to I coming from Q and T. These transitions are smaller in magnitude and contribute to sub-exponential growth of Ni in time. More importantly, the turning point in Ni or  is due to a competition between the growth factors (all inward transitions) and the outward transitions (recovery and fatality terms). Further, since the time evolution beyond the turning point of
is due to a competition between the growth factors (all inward transitions) and the outward transitions (recovery and fatality terms). Further, since the time evolution beyond the turning point of 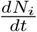 is controlled by a balance between all inward and all outward transitions, the approach towards the state of no infections or the saturation value of Nt is slow in our case. These features are clear from Fig. 3(a,b). Note that the fit, till June 1, is just two weeks beyond the turn point of
is controlled by a balance between all inward and all outward transitions, the approach towards the state of no infections or the saturation value of Nt is slow in our case. These features are clear from Fig. 3(a,b). Note that the fit, till June 1, is just two weeks beyond the turn point of 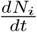 . and it has a long way to evolve to the end point of the epidemic.
. and it has a long way to evolve to the end point of the epidemic.
These arguments clarify two features of the data fit obtained using the reduced logistic equation. Because the total number of infected cases Nt has the dominant growth contributions, the good fit is not surprising. On the other hand, growth dynamics beyond the turning point in the daily new infected cases (i.e., 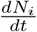 ) is controlled by a balance between growth factors (all inward transitions) and inhibiting factors (the rate of recovery and dead). However, these competing time scales are absent in the logistic equation. This clarifies why the projected saturation value of Nt and the end time of the epidemic is not well captured.
) is controlled by a balance between growth factors (all inward transitions) and inhibiting factors (the rate of recovery and dead). However, these competing time scales are absent in the logistic equation. This clarifies why the projected saturation value of Nt and the end time of the epidemic is not well captured.
A few comments above model are in order. As stated in the introduction, the standard compartmental models ignore both age dependence and the heterogeneous spatial distribution of the population, and therefore cannot abstract the aspects that depend fundamentally on these two features. For the same reason, the populations in these models represent only the mean response of each of these populations. From this point of view, the good fit obtained by the full model, to lesser extent by the reduced logistic model, may come as a surprise. However, the success story of the mean field approaches has been established in physics literature [29, 44–46] and the limitations of the approach has also been well established. To this extent, the success of the present model can be attributed to the way the model equations are structured and the underlying nonlinear dynamical methods used for analysis.
Here, we mention that the parameter values used for fitting have been obtained using an optimization procedure subject to the constraint that the optimized values should fit the data for the cumulative infected cases for the UK. Although, each parameter is varied within the range of values estimated in the literature (and open sources), since the optimization has been carried out subject to only one constraint, the values may not be unique. From this point of view, more number of constraints such as the data for the active infected, recovered, quarantines etc., would be helpful in removing the non-uniqueness of the optimized values, at least partially.
As stated in the text, the contact transmission rate parameter βi is one of the crucial parameter in the model because this parameter largely controls the time development of the disease. In our approach, this parameter has been estimated by using the local initial slope in the log-linear plot of the UK data. The slope itself, however, depends on whether the disease development occurs in the absence or presence of interventions, which in turn depends on the accessible population Na(0). Since the model growth rate depends on piβiNa(0), the value of βi depends inversely on Ng(0) corresponding to the absence or presence of interventions. However, the value reported by Tang et al. [6] is two orders smaller than that estimated in our paper. However, in both cases, the value of βi is inversely proportional to the relevant population used for modeling. In this context, we mention that there is only independent estimate both under free evolution [5]. Such an independent estimates are desirable.
One point that needs some discussion is about the values of the recovery γr and the death rates obtained from the optimization procedure used that fit the UK data very well (see Table II). These rates are inversely related to the time duration between detection of illness till recovery and death respectively. While these values are within the published range of values [40–42], they appear to be on the lower side of the mean. However, in principle, the parameter values depend on the structure of model equations. In our model, the recovery and fatality are outward transitions from a single compartment, namely, I to R and D. This feature is clearly because our model equations were structured to have only two core populations. However, the recoveries can occur if other kinds of compartments (populations) are included [5]. Thus, the best fit for lower values may be the result of simplicity of the model.
In conclusion, the simple compartmental model not only provides a good fit to the United Kingdom coronavirus data but also makes concrete long term predictions for the future. We believe that these results have been made possible due to the reductive approach adopted here.
Appendix
Recall the equation governing the cumulative infected population Ns(t) from Eqs. (8-9) is given by
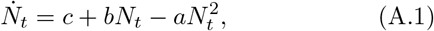

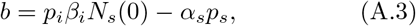

Equation (A.1) has the well known form of the logistic equation extensively studied in the context of population dynamics. However, the parameters a, b, and c have a well defined interpretation.
Now consider the solution of Eq. (A.1). Let a12  be the roots of the quadratic equation. Then, in terms of a, b and c, the two roots can be written as
be the roots of the quadratic equation. Then, in terms of a, b and c, the two roots can be written as 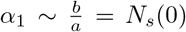 and
and 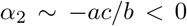 , which is small compared to b. Then the solution is given by
, which is small compared to b. Then the solution is given by
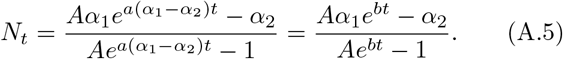
The constant A is given by
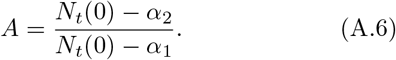
Then, we have
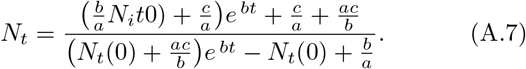
For short times, Nt tends to 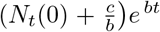 (since the denominator is dominated by b/a = Ns(0)), consistent with Eq. (16), the short time solution. For long times however, Nt tends to b/a = Ns(0)), the total population.
(since the denominator is dominated by b/a = Ns(0)), consistent with Eq. (16), the short time solution. For long times however, Nt tends to b/a = Ns(0)), the total population.
References




Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
0
Blogs/Media
Author Videos