
Abstract
After the introduction of drastic containment measures aimed at stopping the epidemic contagion from SARS-CoV2, many governments have adopted a strategy based on a periodic relaxation of such measures in the face of a severe economic crisis caused by lockdowns. Assessing the impact of such openings in relation to the risk of a resumption of the spread of the disease is an extremely difficult problem due to the many unknowns concerning the actual number of people infected, the actual reproduction number and infection fatality rate of the disease. In this work, starting from a compartmental model with a social structure and stochastic inputs, we derive models with multiple feedback controls depending on the social activities that allow to assess the impact of a selective relaxation of the containment measures in the presence of uncertain data. Specific contact patterns in the home, work, school and other locations have been considered. Results from different scenarios concerning the first wave of the epidemic in some major countries, including Germany, France, Italy, Spain, the United Kingdom and the United States, are presented and discussed.
1. Introduction
It is now clear that the end of the pandemic will not immediately correspond to the disappearance of SARS-CoV2 and that until a vaccination campaign is completed on a global scale we will have to deal with several measures of social distancing and containment. This is why various intermediate phases have been carefully considered, with some activities that can be resumed, regulating the reintegration of workers, for example through indicators measuring the impact of work activities on potential infections, increasing prevention measures, or through so-called immunity passports. It is essential to build scenarios that will help us understand how the situation might evolve in the future.
Among the many controversial aspects are, for example, the reopening of schools, sport activities and other social activities at different levels, which, while having less economic impact, have a very high social cost. Indeed, it is clear that it is difficult for the population to sustain an excessively long period of lockdown. It is therefore of primary importance to analyze the impact of relaxing the control measures put in place by many countries in order to make them more sustainable on the socio-economic front, keeping the reproductive rate of the epidemic under control and without incurring health risks [18, 23, 27, 49].
The problem is clearly very challenging, traditional epidemiological models based on the assumption of homogeneous population mixing are inadequate, since the whole social and economic structure of the country is involved [12, 25, 30–32, 34]. On the other hand, interventions involving the whole population allow to use mathematical descriptions in analogy with classical statistical physics drawing on the statistical characteristics of a very large system of interacting individuals [1–3,8,21,51].
A further problem that cannot be ignored is the uncertainty present in the official data provided by the different countries in relation to the number of infected people. The heterogeneity of the procedures used to carry out the disease positivity tests, the delays in recording and reporting the results, and the large percentage of asymptomatic patients (in varying percentages depending on the studies and the countries but estimated by WHO at an average of around 80% of cases) make the construction of predictive scenarios affected by high uncertainty [33, 41, 54]. As a consequence, the actual number of infected and recovered people is typically underestimated, causing fatal delays in the implementation of public health policies facing the propagation of epidemic fronts.
In this research, we try to make a contribution to these problems starting from a description of the spread of the epidemic based on a compartmental model with social structure in the presence of uncertain data. The presence of a social characteristic such as the age of individuals is, in fact, essential in the case of the COVID-19 outbreak to characterize the heterogeneity of the impact of infection in relation to age. In addition, the model allows to take into account the specific nature of the different activities involved through appropriate interaction functions derived from experimental interaction matrices [6, 29, 43, 45] and to systematically include the uncertainty present in the data [9, 11, 15, 33, 41, 47].
The latter property is achieved by increasing the dimensionality of the problem adding the possible sources of uncertainty from the very beginning of the modelling. Hence, we extrapolate statistics by looking at the so-called quantities of interest, i.e. statistical quantities that can be obtained from the solution and that give some global information with respect to the input parameters. Several techniques can be adopted for the approximation of the quantities of interest. Here, following [4] we adopt stochastic Galerkin methods that allow to reduce the problem to a set of deterministic equations for the numerical evaluation of the solution in presence of uncertainties [17, 44, 52].
The main assumption made in this study is that the control measures adopted by the different countries cannot be described by the standard compartmental model but must necessarily be seen as external actions carried out by policy makers in order to reduce the epidemic peak. Most current research in this direction has focused on control procedures aimed at optimizing the use of vaccinations and medical treatments [5,7,14,16,20,37] and only recently the problem has been tackled from the perspective of non-pharmaceutical interventions [4, 22, 24, 26, 38, 42]. For this purpose we derive new models based on multiple feedback controls that act selectively on each specific contact function and therefore social activity. Based on the data in [45] this allows to analyze the impact of containment measures in a differentiated way on family, work, school, and other activities.
In our line of approach, the classical epidemiological parameters that define the rate of reproduction of the infectious disease are therefore estimated only in the regime prior to the first lockdown and define an estimate of the reproductive rate in the absence of control. At this stage the estimation mainly serves to calibrate the model parameters and its variability will then be considered in the intrinsic uncertainty of these values. In particular, this makes it possible to introduce the role of the asymptomatic population without adding additional compartments but directly via the stochastic component in the number of infected persons. The control action is then estimated in the first lockdown phase using the data available. On the modelling front, we next focus our interest on the phase following the first lockdown period, in which social characteristics become essential to quantify the impact of possible government decisions.
This makes it possible to carry out a systematic analysis for different countries and to observe the different behaviour of the control action in line with the dynamics observed and the measures taken by different governments. Of course, a realistic comparison between countries is an extremely difficult problem that would require a complex phase of renormalization of the data according to the different recording and acquisition methods used. In an attempt to provide comparative results altered as little as possible by assumptions that cannot be justified, we decided to adopt the same criteria for each country and therefore the scenarios presented, although based on realistic values, maintain a primarily qualitative rather than quantitative nature.
We present different simulation scenarios for various countries where the first wave of the epidemic showed some similarities, including Germany, France, Italy, Spain, the United Kingdom and the United States analyzing the effect of relaxing the lockdown measures in a selective way on the various social activities. Although the choice of which specific activities to reopen remains mainly a political decision, numerical simulations show that a progressive loosening strategy in subsequent phases, as adopted by some governments, may be capable to keep the epidemic under control by restarting various productive activities.
The rest of the manuscript is organized as follows. In Section 2 we present compartmental models with social structure and with uncertainties where interaction matrices depend on various social activities. Next, a selective control mimicking containment measures in relation to a specific social activity and in presence of model uncertainty is derived in Section 3. Finally, in Section 3.2 we propose various numerical experiments based on several countries highlighting the importance of the social structure to evaluate possible relaxations in relation to specific social activities.
2. The epidemiological model
The starting model in our discussion is a SEIRD-type compartmental model with a social structure and uncertain inputs. The presence of a social structure is in fact essential in deriving appropriate sustainable control techniques from the population for a protracted period, as in the case of the recent COVID-19 epidemic. In addition we include the effects on the dynamics of uncertain data, such as the initial conditions on the number of infected people or the interaction and recovery rates. This permits to include the role of the asymptomatic population directly in the uncertainty.
2.1. A socially structured compartmental model with uncertainty
The heterogeneity of the social structure, which impacts the diffusion of the infective disease, is characterized by a ∈Λ ⊂ℝ+ representing the age of the individual [30, 31]. We assume that the rapid spread of the disease and the low mortality rate allows to ignore changes in the social structure, such as the aging process, births and deaths. Furthermore, we introduce the random vector 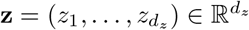 whose components are assumed to be independent real valued random variables taking into account various possible sources of uncertainty in the model. We assume to know the probability density
whose components are assumed to be independent real valued random variables taking into account various possible sources of uncertainty in the model. We assume to know the probability density 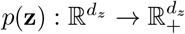 characterizing the distribution of z.
characterizing the distribution of z.
We denote by s(z, a, t), e(z, a, t), i(z, a, t), r(z, a, t) and d(z, a, t) the densities at time t ≥0 of susceptible, exposed, infectious, recovered and dead individuals, respectively in relation to their age a and the source of uncertainty z. The density of individuals of a given age a and the total population number N are deterministic conserved quantities in time, i.e.
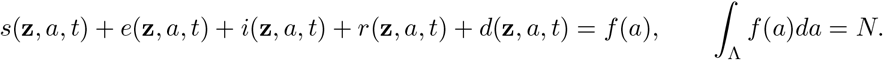 Hence, the quantities
Hence, the quantities
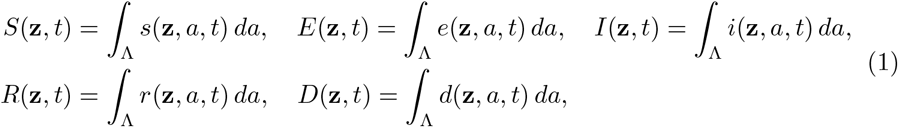 denote the uncertain fractions of the population that are susceptible, exposed, infectious, recovered and dead respectively.
denote the uncertain fractions of the population that are susceptible, exposed, infectious, recovered and dead respectively.
In a situation where changes in the social features act on a slower scale with respect to the spread of the disease, the socially structured compartmental model with uncertainties follows the dynamics
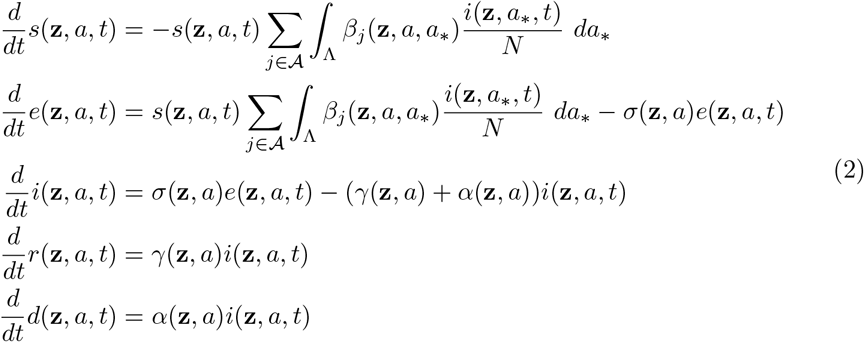 with initial condition s(z, a, 0) = s0(z, a), e(z, a, 0) = e0(z, a), i(z, a, 0) = i0(z, a), r(z, a, 0) = r0(z, a) and d(z, a, 0) = d0(z, a). In (2) we assume age-dependent contact rates βj(z, a, a∗) ≥0, j ∈𝒜, representing transmission rates among individuals related to a specific activity characterized by the set 𝒜, such as home, work, school, etc., γ(z, a) ≥0 is the recovery rate which may be age dependent, σ(z, a) ≥0 is the transition rate of exposed individuals to the infected class, and α(z, a) ≥0 is the disease-induced death rate of infectious individuals.
with initial condition s(z, a, 0) = s0(z, a), e(z, a, 0) = e0(z, a), i(z, a, 0) = i0(z, a), r(z, a, 0) = r0(z, a) and d(z, a, 0) = d0(z, a). In (2) we assume age-dependent contact rates βj(z, a, a∗) ≥0, j ∈𝒜, representing transmission rates among individuals related to a specific activity characterized by the set 𝒜, such as home, work, school, etc., γ(z, a) ≥0 is the recovery rate which may be age dependent, σ(z, a) ≥0 is the transition rate of exposed individuals to the infected class, and α(z, a) ≥0 is the disease-induced death rate of infectious individuals.
In the following, we introduce the usual normalization scaling
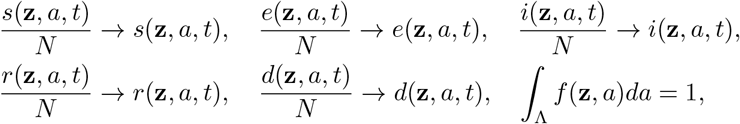 and observe that the quantities S(t), E(t), I(t), R(t) and D(t) satisfy the uncertain SEIRD dynamics
and observe that the quantities S(t), E(t), I(t), R(t) and D(t) satisfy the uncertain SEIRD dynamics
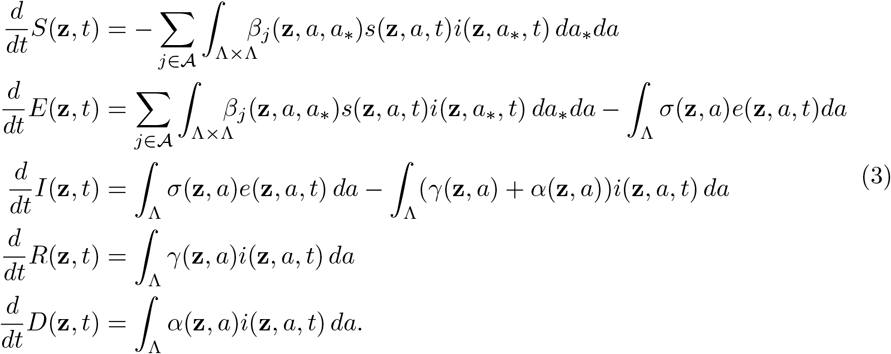 We refer to [25, 30–32] for analytical results concerning model (2) and (3) in a deterministic setting.
We refer to [25, 30–32] for analytical results concerning model (2) and (3) in a deterministic setting.
Before entering the discussion of the control problem that formalizes the action of a policy maker aimed at reducing the epidemic impact, we discuss the role of the uncertainty in the model and how it relates to other compartmental models including the asymptomatic population.
2.2. Relationship to compartmental models including undetected infectious
One of the main difficulties in mathematical modelling of the COVID-19 epidemic is due to the presence of a large number of undetected (asymptomatic) infected individuals. This has motivated the construction of various models in which the infected population is subdivided into further compartments with different roles in the spread of the disease [24,27,28,49]. To clarify the relationships to such models, let us consider model (3) in absence of a social structure and social activities
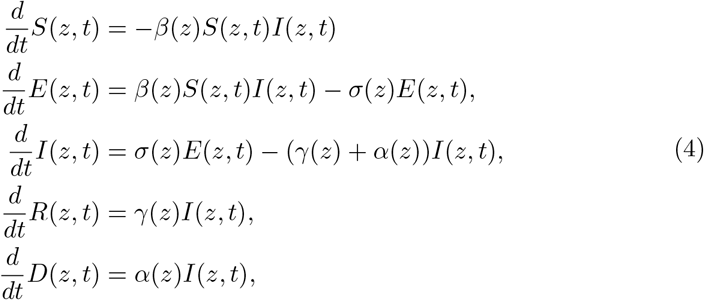 and with a one-dimensional random input z ∈ℝ distributed as p(z). Furthermore, for a function F (z, t) we will denote its expected value as
and with a one-dimensional random input z ∈ℝ distributed as p(z). Furthermore, for a function F (z, t) we will denote its expected value as 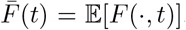 . Now, starting from a discrete probability density function
. Now, starting from a discrete probability density function
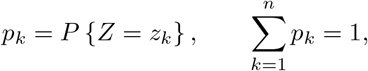 we have
we have 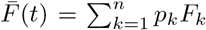 , with Fk = F (zk). Taking the expectation in (4), we can write
, with Fk = F (zk). Taking the expectation in (4), we can write
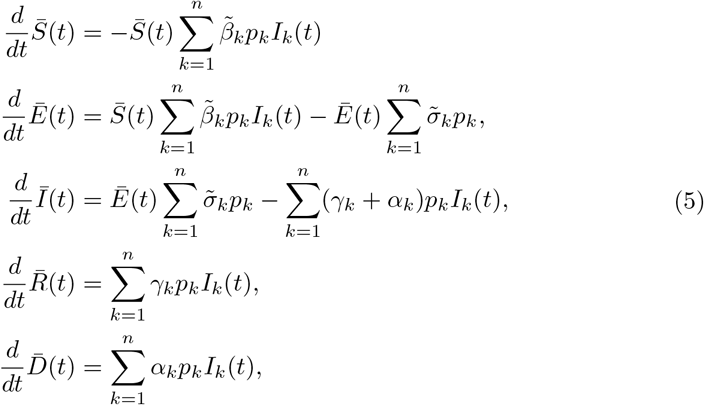 with
with 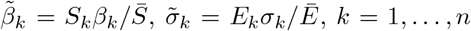 . For example, in the case n = 2, by identifying Id = p1I1 and Iu = p2I2 with the compartments of detected and undetected infectious individuals, assuming
. For example, in the case n = 2, by identifying Id = p1I1 and Iu = p2I2 with the compartments of detected and undetected infectious individuals, assuming 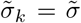 , and denoting p1 = ρ we can write
, and denoting p1 = ρ we can write
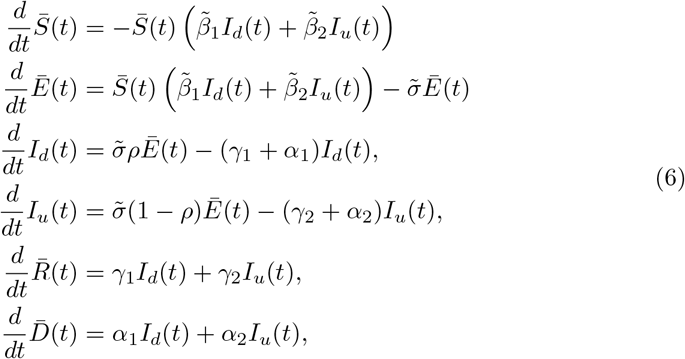 which has the same structure of a SEIARD-type compartmental model including the undetected (or the asymptomatic) class [27, 49].
which has the same structure of a SEIARD-type compartmental model including the undetected (or the asymptomatic) class [27, 49].
3. Multiple control of structured compartmental model
In order to characterize the action of a policy maker introducing a control over the system based on selective containment measures in relation to a specific social activity we consider the following optimal control setting
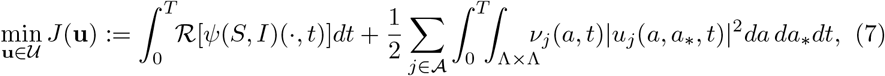 where u = (u1, …, uL) is a vector of controls acting locally on the interaction between individuals of ages a and a∗, the function νj(a, t) > 0 is a selective penalization term and ℛ [·] is a suitable statistical operator taking into account the presence of the uncertainties, and ψ(S, I), s.t. ∂Iψ(S, I) ≥0, is a function characterizing the policy maker’s perception of the impact of the epidemic.
where u = (u1, …, uL) is a vector of controls acting locally on the interaction between individuals of ages a and a∗, the function νj(a, t) > 0 is a selective penalization term and ℛ [·] is a suitable statistical operator taking into account the presence of the uncertainties, and ψ(S, I), s.t. ∂Iψ(S, I) ≥0, is a function characterizing the policy maker’s perception of the impact of the epidemic.
Examples of such operator that are of interest in epidemic modelling are the expectation with respect to uncertainties
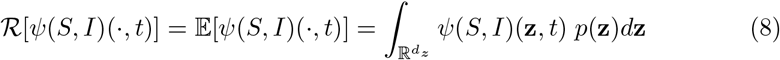 or relying on deterministic data which underestimate the number of infected
or relying on deterministic data which underestimate the number of infected
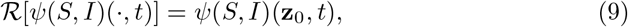 where z0 is a given value such that
where z0 is a given value such that 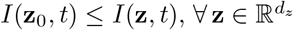 and t > 0. Concerning the perception function, in the sequel we will consider two relevant examples given by a convex function underestimating the number of infected
and t > 0. Concerning the perception function, in the sequel we will consider two relevant examples given by a convex function underestimating the number of infected
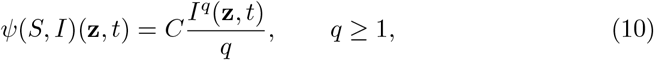 and a concave function overestimating such number
and a concave function overestimating such number
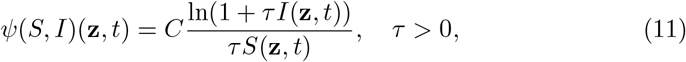 with C > 0 a suitable renormalization constant. The function in (10) has been introduced in [4] and we will rely on the same arguments in deriving the corresponding feedback controlled model, whereas the function in (11) permits to recover as feedback controlled models well-known epidemic models with nonlinear transmission rates [26, 35].
with C > 0 a suitable renormalization constant. The function in (10) has been introduced in [4] and we will rely on the same arguments in deriving the corresponding feedback controlled model, whereas the function in (11) permits to recover as feedback controlled models well-known epidemic models with nonlinear transmission rates [26, 35].
In (7) the set 𝒰⊆ℝL is the space of admissible controls uj, j ∈𝒜 defined as
 where
where
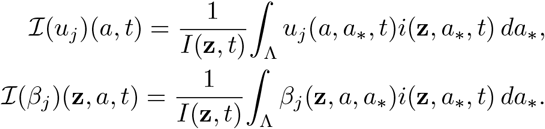 Note that, here we are considering less restrictive conditions on the space of admissible controls than in [4]. The above minimization is subject to the following dynamics
Note that, here we are considering less restrictive conditions on the space of admissible controls than in [4]. The above minimization is subject to the following dynamics
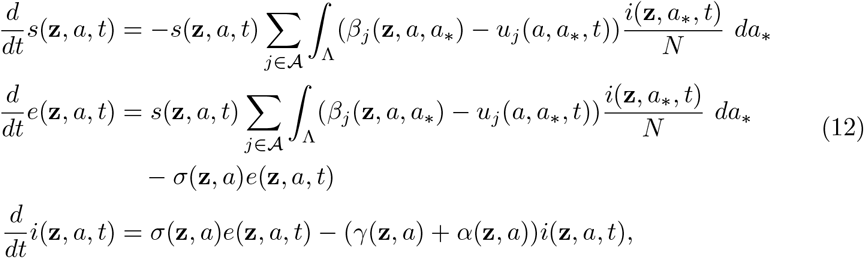 where for simplicity we omitted the equations for r(z, a, t) and d(z, a, t) since they do not affect directly the above system.
where for simplicity we omitted the equations for r(z, a, t) and d(z, a, t) since they do not affect directly the above system.
Solving the above optimization problem, however, is generally quite complicated and computationally demanding when there are uncertainties as it involves solving simultaneously the forward problem (7)- (12) and the backward problem derived from the optimality conditions [4]. Furthermore, the assumption that the policy maker follows an optimal strategy over a long time horizon seems rather unrealistic in the case of a rapidly spreading disease such as the COVID-19 epidemic.
3.1. Feedback controlled compartmental models with uncertainty
In this section we consider short time horizon strategies which permits to derive suitable feedback controlled models. These strategies are suboptimal with respect the original problem (7)-(12) but they have proved to be very successful in several social modeling problems [1–3, 21]. To this aim, we consider a short time horizon of length h > 0 and formulate a time discretize optimal control problem through the functional Jh(u) restricted to the interval [t, t + h], as follows
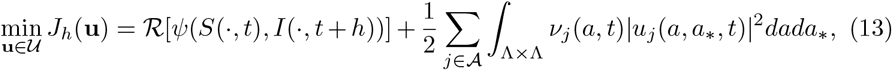 subject to
subject to
 Recalling that the macroscopic information on the infected is
Recalling that the macroscopic information on the infected is
 we can derive the minimizer of Jh computing ∇uJh(u) ≡ 0 or equivalently
we can derive the minimizer of Jh computing ∇uJh(u) ≡ 0 or equivalently
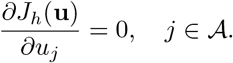 Using (13) we can compute
Using (13) we can compute
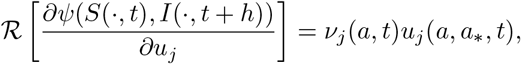 where we assumed ∂ℛ [ψ(,)]/∂uj = ℛ [∂ψ(,)/∂uj], to obtain the following non-linear identities
where we assumed ∂ℛ [ψ(,)]/∂uj = ℛ [∂ψ(,)/∂uj], to obtain the following non-linear identities
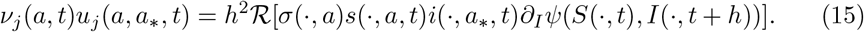 The above assumption on ℛ [·] is clearly satisfied by (8) and (9). Introducing the scaling νj(a, t) = h2κj(a, a∗, t) we obtain the instantaneous control
The above assumption on ℛ [·] is clearly satisfied by (8) and (9). Introducing the scaling νj(a, t) = h2κj(a, a∗, t) we obtain the instantaneous control
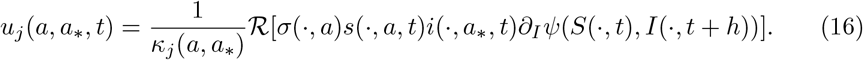 Now, passing to the limit for h →0 into the discrete system (14) we obtain the feedback controlled system (12) with the instantaneous control term (16).
Now, passing to the limit for h →0 into the discrete system (14) we obtain the feedback controlled system (12) with the instantaneous control term (16).
Let us now, report explicit expressions of the control term for the perception function (10) and (11). In the convex case we have
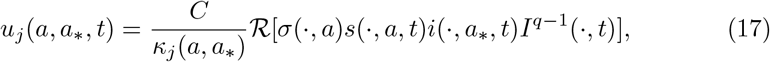 whereas in the logarithmic case
whereas in the logarithmic case
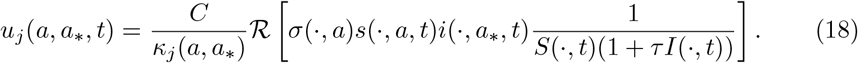 In the sequel we will restrict our attention to feedback controlled models of the form (17) for q = 1, namely there is no bias in the perception of the infectious disease from the policy maker, and where ℛ [·] is given by (9) corresponding to the number of reported cases.
In the sequel we will restrict our attention to feedback controlled models of the form (17) for q = 1, namely there is no bias in the perception of the infectious disease from the policy maker, and where ℛ [·] is given by (9) corresponding to the number of reported cases.
To understand the action of the feedback controls (17)-(18), let us consider the simplest case of a standard SEIRD model without age dependence, specific social interactions and uncertainty. In this simplified setting, it is easy to verify that the corresponding feedback controlled model has the same SEIRD structure with the modified transmission rate
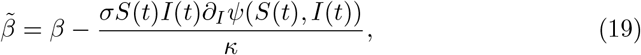 that takes the specific form
that takes the specific form
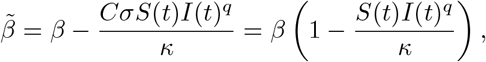 in the case (10) assuming C = β/σ, and
in the case (10) assuming C = β/σ, and
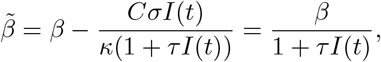 in the case (11) taking τ = 1/κ, C = β/σ. These correspond to the nonlinear incidence transmissions considered in [4, 39] and [10, 26, 35], respectively. Other nonlinear incidence rates may be obtained similarly by considering different perception functions (see [39] and the references therein).
in the case (11) taking τ = 1/κ, C = β/σ. These correspond to the nonlinear incidence transmissions considered in [4, 39] and [10, 26, 35], respectively. Other nonlinear incidence rates may be obtained similarly by considering different perception functions (see [39] and the references therein).
3.2. Application to the COVID-19 outbreak
In this section, we first present a comparison between different control strategies considering both a SEIR and SIR compartmentalization. Subsequently, we focus on the application of the feedback controlled models with uncertain data, that takes into account the presence of unreported symptomatic and asymptomatic cases, to the first wave of the COVID-19 pandemic in different countries. Details of the stochastic Galerkin method used to deal efficiently with uncertain data may be found in [4, 44]. The data concerning the actual number of infected, recovered and deaths in the various country have been taken from the Johns Hopkins University Github repository [19] ad for the specific case of Italy from the Github repository of the Italian Civil Protection Department 1. The social interaction functions βj have been reconstructed from the dataset of age and location specific contact matrices related to home, work, school and other activities in [45]. Finally, the demographic characteristics of the population for the various country have been taken from the United Nations World Populations Prospects 2. Other sources of data which have been used include the Coronavirus disease (COVID-2019) situation reports of the WHO 3 and the Statistic and Research Coronavirus Pandemic (COVID-19) from OWD 4.
3.3. Containment in homogeneous social mixing
In the first test case, we will not attempt to analyze the data in a quantitative setting, but will compare the behaviour of the feedback controlled models with different controls of the form defined in (17)-(18). Furthermore, to simplify the modeling we neglect any dependence on uncertainties and we consider the case of homogeneous social mixing.
In the SEIR case we consider a population of size N = 60·106 where at time t = 0 the initial number of exposed is given by 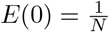 and the number of susceptibles is
and the number of susceptibles is  , whereas I(0) = R(0) = 0. To exemplify the possible evolution of the pandemic we consider β = 0.25, γ = 0.1, corresponding to a recovery rate of 10 days, so that R0 = 2.5. Furthermore, we assume a latency period of 3.32 days, leading to σ ≈0.3012, see [27].
, whereas I(0) = R(0) = 0. To exemplify the possible evolution of the pandemic we consider β = 0.25, γ = 0.1, corresponding to a recovery rate of 10 days, so that R0 = 2.5. Furthermore, we assume a latency period of 3.32 days, leading to σ ≈0.3012, see [27].
In Figure 1 we report the dynamics of infected and recovered based on the activation of the control in the time frame t ∈ [60, 200], meaning that the control is activated after 60 days the first exposed and after 200 days we suppose that all the restrictions are cancelled. We may easily observe how the delation of social restrictions leads for both controls to a restart of the epidemic and therefore to a second wave of infection. Both the controls have comparable costs but the perception function ψ(S, I) = CIq/q is more capable to flatten the curve of infection. After the deactivation of the control we may observe how the number of recovered for large times does not significantly change with respect to the unconstrained dynamics.

Evolution fo the fraction of infected (left) and recovered (right) based on the two different feedback controls defined in (17) with q = 1 (first row) and (18) (second row) for the SEIR model with homogeneous mixing. We considered different penalizations κ = 10−2, 10−1. The choice κ = + ∞ corresponds to the uncon-strained case. Bottom figure: evaluation of the cost functional J for the introduced controls.
We perform a similar test in the case of SIR compartimentalization. Therefore we assume a population of the same size N = 60 · 106 of the previous test where at time t = 0 the initial number of infected is 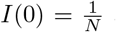 and
and 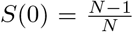 . We considered epidemiological parameters that are compatible with the ones considered above and leading to R0 = 2.5, i.e. β = 0.25 and γ = 0.1. We remark that in presence of a SIRD-type compartmentalization we obtain a feedback control compatible with (17) with σ = 1 for a perception function ψ(S, I) = CIq/q, whereas in the logarithmic case we can derive a feedback control compartible with (18) with σ = 1, we point the interested reader to [4] for more details. In Figure 2 we report the dynamics of infected and recovered with an activation of the control in the time interval [60, 200]. Interestingly enough, the logarithmic perception function is in this case more effective in the reduction of the number of recovered, that is the total number of infected of the population.
. We considered epidemiological parameters that are compatible with the ones considered above and leading to R0 = 2.5, i.e. β = 0.25 and γ = 0.1. We remark that in presence of a SIRD-type compartmentalization we obtain a feedback control compatible with (17) with σ = 1 for a perception function ψ(S, I) = CIq/q, whereas in the logarithmic case we can derive a feedback control compartible with (18) with σ = 1, we point the interested reader to [4] for more details. In Figure 2 we report the dynamics of infected and recovered with an activation of the control in the time interval [60, 200]. Interestingly enough, the logarithmic perception function is in this case more effective in the reduction of the number of recovered, that is the total number of infected of the population.

Evolution fo the fraction of infected (left) and recovered (right) based on the two different feedback controls defined in (17) with q = 1 (first row) and (18) (second row) for the SIR model with homogeneous mixing. We considered different penalizations κ = 10−2, 10−1. The choice κ = + ∞ corresponds to the unconstrained case. Bottom figure: evaluation of the cost functional J for the introduced controls.
3.4. Model calibration
Estimating epidemiological parameters is a very difficult problem that can be addressed with different approaches [9, 15, 47]. In the case of COVID-19 due to the limited number of data and their great heterogeneity is an even bigger problem that can easily lead to wrong results. Here, we restrict ourselves to identifying the deterministic parameters of the model through a suitable fitting procedure, considering the possible uncertainties due to such estimation as part of the subsequent uncertainty quantification process. For this reason in the sequel we will neglect the presence of the exposed population and thus consider the feedback controlled SIR model.
More precisely, we have adopted the following two-level approach in estimating the parameters. In the phase preceding the lockdown we estimated the epidemic parameters, and hence the model reproduction number R0, in an uncontrolled regime. This estimate was then kept in the subsequent lockdown phase where we estimated as a function of time the value of the control penalty parameter. Both these two calibration steps were analyzed under the assumption of homogeneous mixing.
Thua, we solved two separate constrained optimization problems. First we estimated βe > 0 and γe > 0 in each country by solving in the uncontrolled time interval t ∈ [t0, tu] a least square problem based on minimizing the relative L2 norm of the difference between the reported number of infected Î(t) and recovered 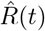 , and the theoretical evolution of the unconstrained model I(t) and R(t). In details, we considered the following minimization problem
, and the theoretical evolution of the unconstrained model I(t) and R(t). In details, we considered the following minimization problem
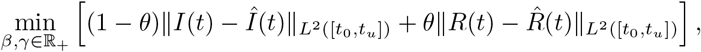 where θ ∈ [0, 1] is a penalization parameter and
where θ ∈ [0, 1] is a penalization parameter and 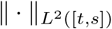 denotes the relative L2 norm over the time horizon [t, s]. It is worth to remark that the lack of reliable informations concerning the recovered in early stages of the disease suggests to adapt the model mainly to the curve of infectious and to introduce the uncertainty in the reproductive number using this estimated value as an upper bound of the reproduction number.
denotes the relative L2 norm over the time horizon [t, s]. It is worth to remark that the lack of reliable informations concerning the recovered in early stages of the disease suggests to adapt the model mainly to the curve of infectious and to introduce the uncertainty in the reproductive number using this estimated value as an upper bound of the reproduction number.
Due to the heterogeneity of the data between the different countries, we constrained the value of β ∈ [0, 1] and the value of 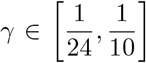 . Indeed, according to clinical studies, time to viral clearance during the early phases of the epidemic, i.e. the time from the first positive test to the first negative test, can approximately span from 10 to 24 days, see [13, 27, 36]. At the end of this optimization procedure, we obtain the values βe, γe for each country reported in Table (1). The results have been obtained by averaging the optimization outputs with penalization factors θ = 10−2 and θ = 10−6, respectively. The choice of small values for θ is due to the increased heterogeneity in data for recovered in this early stages of the epidemic.
. Indeed, according to clinical studies, time to viral clearance during the early phases of the epidemic, i.e. the time from the first positive test to the first negative test, can approximately span from 10 to 24 days, see [13, 27, 36]. At the end of this optimization procedure, we obtain the values βe, γe for each country reported in Table (1). The results have been obtained by averaging the optimization outputs with penalization factors θ = 10−2 and θ = 10−6, respectively. The choice of small values for θ is due to the increased heterogeneity in data for recovered in this early stages of the epidemic.
Next, we estimate the penalization κ = κ(t) > 0 in time by solving in the controlled time interval t ∈ (tu, tc] for a sequence of unitary time steps ti the corresponding least square problems in [ti − kl, ti + kr], kl, kr ≥ 1 integers, and where for the evolution we consider the values βe and γe estimated in the first optimization step using the curve of infectious. In details we solve the following minimization problem
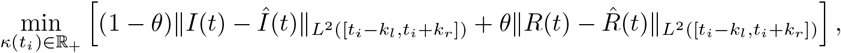 over a window of seven days (kl = 3, kr = 4) for regularization along one week of available data. For consistency we performed the same optimization process used to estimate β and γ, namely using two different penalization factors and then averaging the results. These optimization problems have been solved testing different optimization methods in combination with adaptive solvers for the system of ODEs. The results reported have been obtained using the Matlab functions fmincon in combination with ode45.
over a window of seven days (kl = 3, kr = 4) for regularization along one week of available data. For consistency we performed the same optimization process used to estimate β and γ, namely using two different penalization factors and then averaging the results. These optimization problems have been solved testing different optimization methods in combination with adaptive solvers for the system of ODEs. The results reported have been obtained using the Matlab functions fmincon in combination with ode45.
The corresponding time dependent values for the controls as well as results of the model fitting with the actual trends of infectious are reported in Figure 3. The trends have been computed using a weighted least square fitting with the model function k(t) = aebt(1 − ect).

Model behavior with fitting parameters and actual trends in the number of reported infectious using the estimated control penalization terms after lockdown over time in the various countries.
For some countries, like France, Spain and Italy after an initial adjustment phase the penalty term converged towards a peak and has just started to decrease. This is consistent with a situation in which data concerning the number of reported infectious needs a certain period of time before being affected by the lockdown policy and can also be considered as an indicator of an unstable situation where reducing control could lead to a potential restart of the infectious curve. The penalty terms for the US and the UK clearly indicates that the pandemic was still in its growing phase. In the case of Germany the dynamics highlight a significative decrease in the penalization term, this fact is coherent with the timely implementation of social distancing measures. Note that, see figure 3, the behavior of the model is able to fairly realistically describe the observed data for a time window of about one month after calibration. On the other hand, a larger time window, up to the end of June, clearly presents significant deviations from the expected behavior due to the restart of the pandemic wave as in France, Spain and the US or a drop down in the number of cases as in Italy and the UK.
3.5. Estimating actual infection trends with uncertain data
Next we focus on the influence of uncertain quantities on the controlled system with homogeneous mixing. According to recent results on the diffusion of COVID-19 in many countries the number of infected, and therefore recovered, is largely underestimated on the official reports, see e.g. [33, 41]. One possible way to understand this is based on a renormalization process of the reported data based on the estimated infection fatality rate (IFR) of Covid-19. Although estimating the true IFR is generally hazardous while an epidemic is underway, some studies have estimated an overall IFR around 1.3% with an age dependent credible interval [46, 48]. In the sequel we consider a range spanning between 0.9% − 2.0%. On the contrary the current fatality rate (CFR) may vary strongly from country to country accordingly to the differences in the number of people tested, demographics, health care system. One way to have in insight in the uncertainty of data is to use the estimated IFR ranges as normalization factors for the current data reported of total cases Itot. This is done computing an estimated number of total confirmed cases as Îtot = 100 × Dr/IFR, where Dr is the total number of confirmed deaths. The results of the variations Îtot/Itot for the various countries are summarized in Figure 4 and are directly proportional to the CFR of the country. We are aware that the estimate obtained is certainly coarse, nevertheless it allows to get an idea of the disagreement between the data observed and expected in the various countries and therefore to be able to define a common scenario between the various countries.
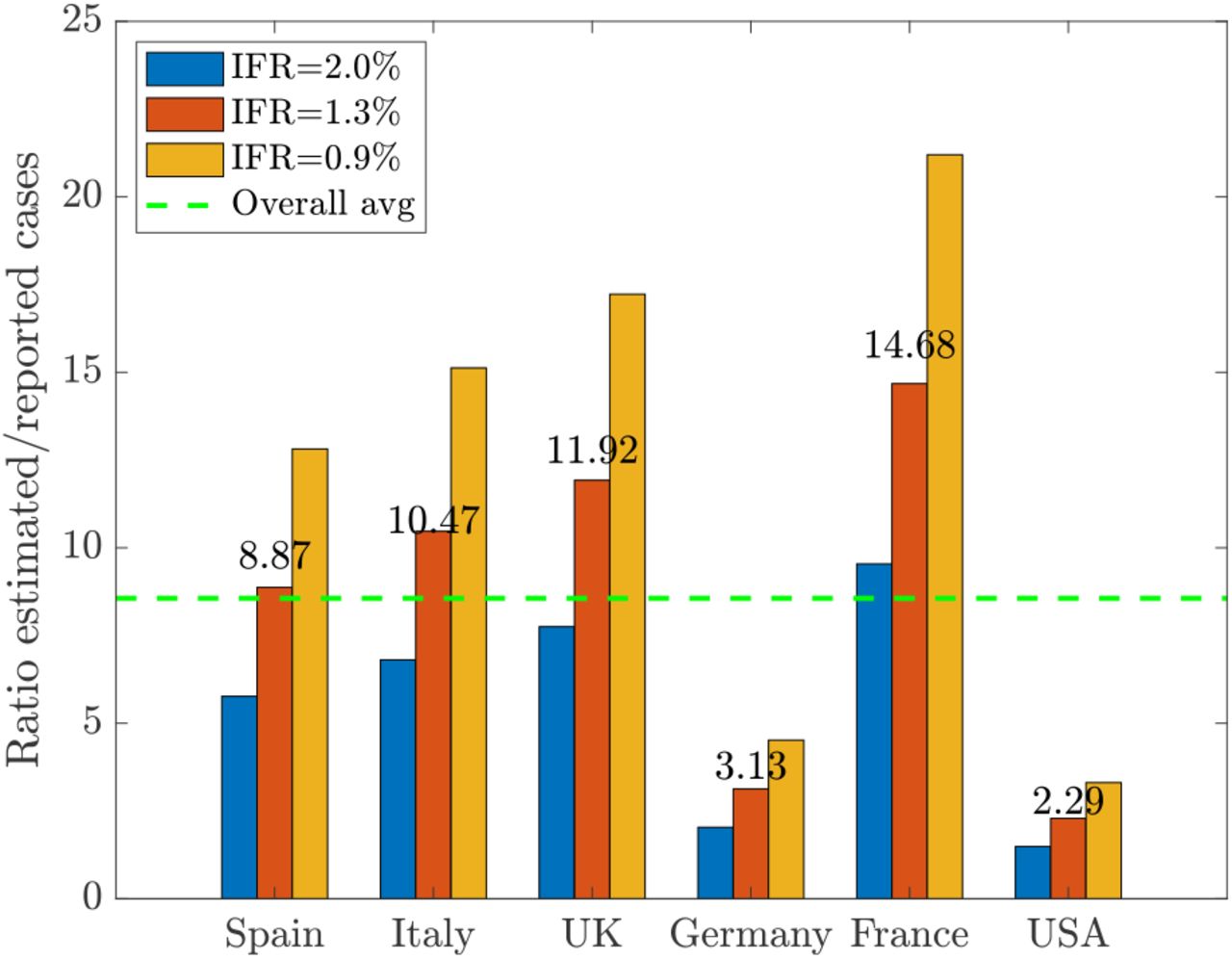
Estimated disagreement in the total number of cases based on an IFR of 1.3% in the range 0.9%-2.0%. The uncertainty is measured as the estimated values divided by the reported cases. The country specific values are given on the top of each red bar, the average value of c = 8.56 is reported as a dashed green line.
In order to have an insight on global impact of uncertain parameters we consider a two-dimensional uncertainty z = (z1, z2) with independent components such that
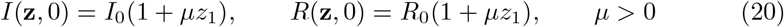 and
and
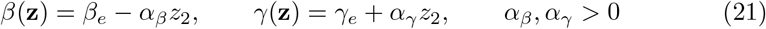 where z1, z2 are chosen distributed as symmetric Beta functions in [0, 1], i0 and r0 are the initial number of reported cases and recovered taken from [13] and βe, γe are the fitted values given in Table 1. In the following we will consider µ = 2(c −1) common for all countries such that 𝔼 [I(z, 0)] = cI(0), 𝔼 [R(z, 0)] = cR(0) where c = 8.56, the average value from Figure 4.
where z1, z2 are chosen distributed as symmetric Beta functions in [0, 1], i0 and r0 are the initial number of reported cases and recovered taken from [13] and βe, γe are the fitted values given in Table 1. In the following we will consider µ = 2(c −1) common for all countries such that 𝔼 [I(z, 0)] = cI(0), 𝔼 [R(z, 0)] = cR(0) where c = 8.56, the average value from Figure 4.
From a computational viewpoint we adopted the method developed in [4] based on a stochastic Galerkin approach. The feedback controlled model has been computed using an estimation of the total number of susceptible and infected reported, namely we have the control term
 where Sr(t) and Ir(t) are the model solution obtained from the registered data, and thus Ir(t) represents a lower bound for the uncertain solution I(z, t).
where Sr(t) and Ir(t) are the model solution obtained from the registered data, and thus Ir(t) represents a lower bound for the uncertain solution I(z, t).
In Figure 5 we report the results concerning the evolution of estimated current infectious cases from the beginning of the pandemic in the reference countries using z1 ∼B(10, 10) and αβ = αγ = 0. In the inset figures the evolution of total cases is reported. The expected number of infectious is plotted with blue continuous line. Furthermore, to highlight the country-dependent underestimation of cases we report with dash-dotted lines both the expected evolutions, where the uncertain parameter c > 0 varies from country to country accordingly to the numbers on the top of the red bars in Figure 4.
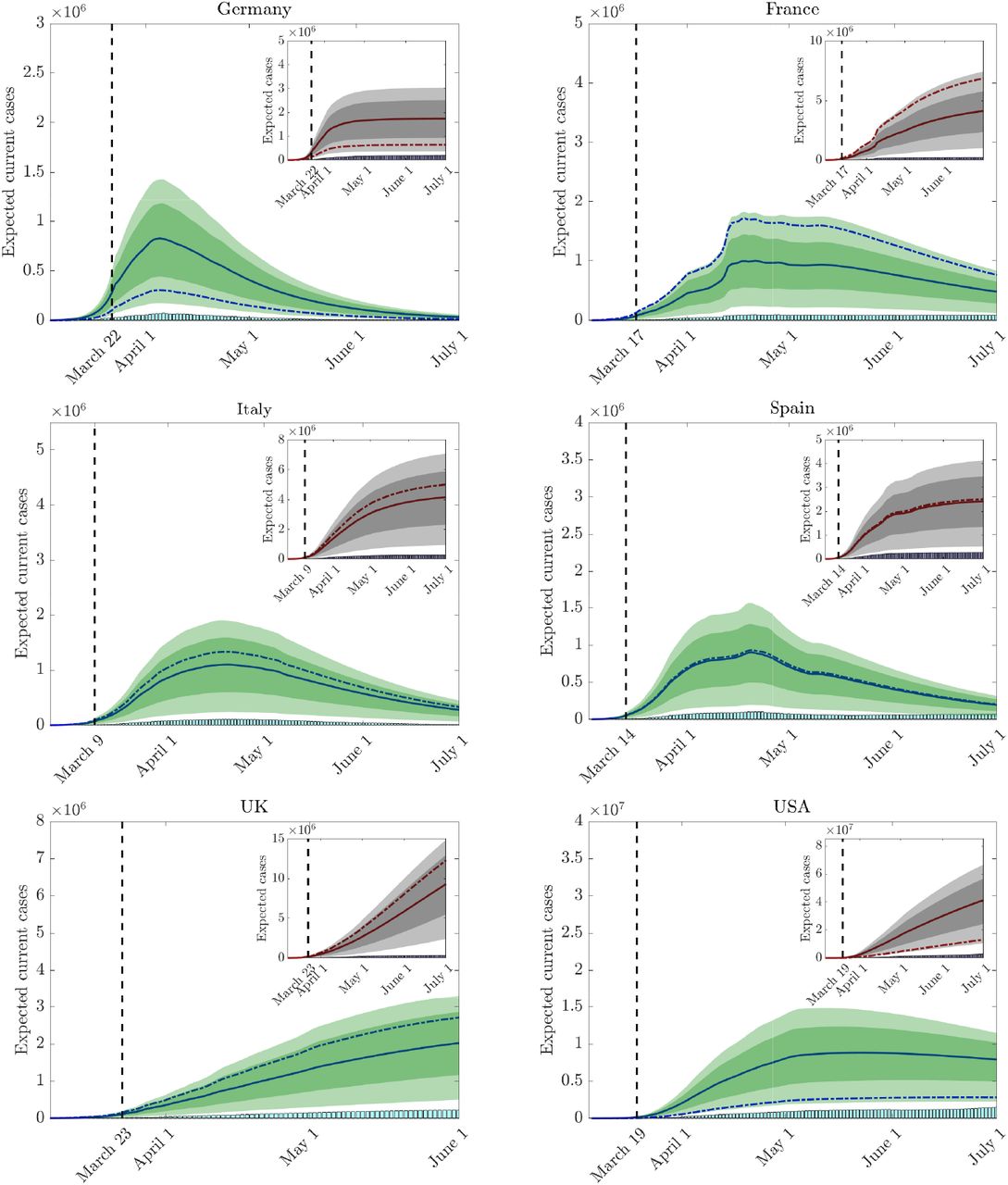
Evolution of current and total cases for each country with uncertain initial data as in (20) based on the average uncertainty between countries. The 95% and 50% confidence levels are represented as shaded and darker shaded areas respectively. The dash-dotted lines denote the expected trends with a country dependent uncertainty from Figure 4.
In Figure 6 we report the evolution of reproduction number R0 for the considered countries under the uncertainties in (21) obtained with αβ = 0.03, αγ = 0.05 and z2 ∼B(2, 2). It has been reported, in fact, that deterministic methods based on compartmental models overestimate the effective reproduction number [40]. The reproduction number is estimated from

Evolution of estimated reproduction number R0 and its confidence bands for uncertain data in as in (21). The 95% and 50% confidence levels are represented as shaded and darker shaded areas respectively. The green zones denote the interval between the first day the 50% confidence band and the expected value fall below 1.
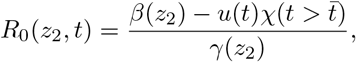 being the control u(t) defined in (22) and
being the control u(t) defined in (22) and  is the country-dependent lockdown time. The estimated reproduction number relative to data is reported with x-marked symbols and represents an upper bound for R0(z2, t). The first day that the 50% confidence interval and the expected value fall below 1 is highlighted with a shaded green region. We can observe how the model estimates that for most countries in the first days of April the reproduction number R0 has fallen below the threshold of 1. On the other hand, in the UK and the US the same condition was reached between the end of April and the beginning of May. In realistic terms these dates should be considered as overestimates as they are essentially based on observations without taking into account the delay in the data reported.
is the country-dependent lockdown time. The estimated reproduction number relative to data is reported with x-marked symbols and represents an upper bound for R0(z2, t). The first day that the 50% confidence interval and the expected value fall below 1 is highlighted with a shaded green region. We can observe how the model estimates that for most countries in the first days of April the reproduction number R0 has fallen below the threshold of 1. On the other hand, in the UK and the US the same condition was reached between the end of April and the beginning of May. In realistic terms these dates should be considered as overestimates as they are essentially based on observations without taking into account the delay in the data reported.
3.6. Relaxing control on the various social activities
We analyze the effects of the inclusion of age dependence and social interactions in the above scenario. The number of contacts per person generally shows considerable variability depending on age, occupation, country, in relation to the social habits of the population. However, some universal features can be extracted, which emerge as a function of specific social activities.
More precisely, we consider the social interaction functions corresponding to the contact matrices in [45] for the various countries. As a result we have four interaction functions characterized by 𝒜 = {F, E, P, O}, where we identify family and home contacts with βF, education and school contacts with βE, professional and work contacts with βP, and other contacts with βO. These functions have been reconstructed over the age interval Λ = [0, amax], amax = 100 using linear interpolation. We report in Figure 7, as an example, the total social interaction functions for the various countries. The functions share a similar structure but with different scalings accordingly to the country specific features identified in [45].
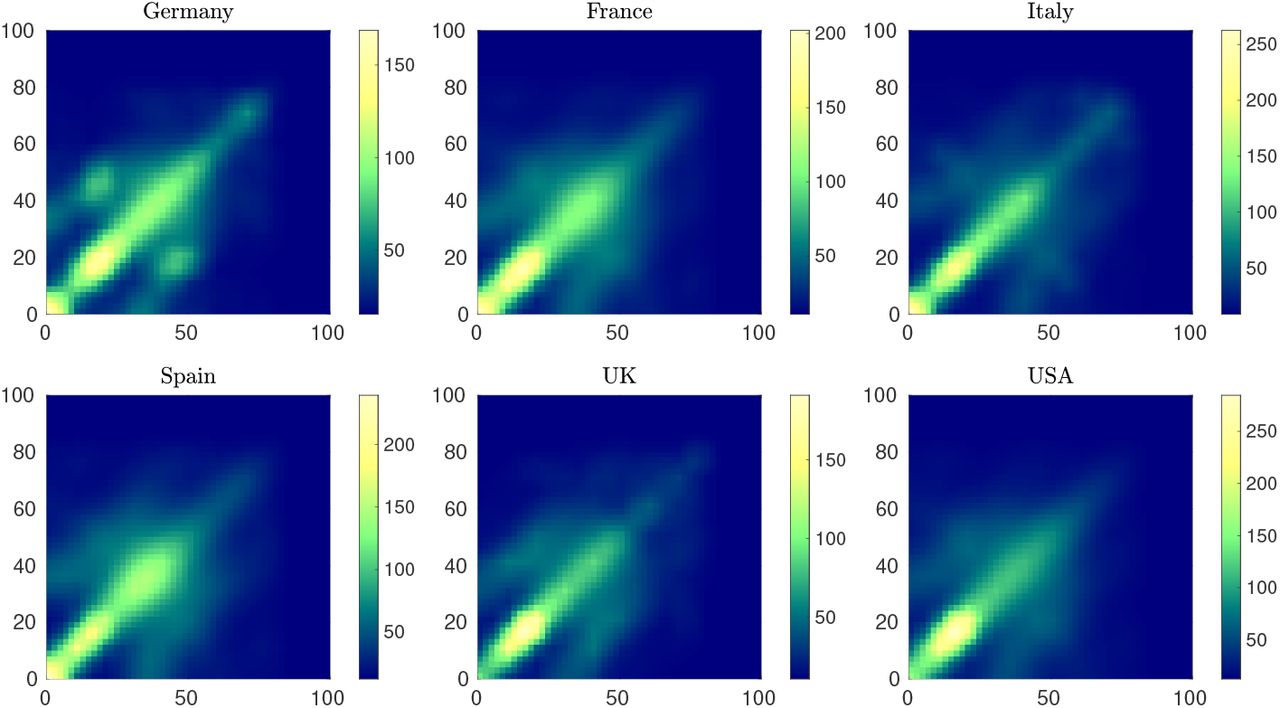
The total contact interaction function β = βF + βE + βP + βO taking into account the contact rates of people with different ages. Family and home contacts are characterized by βF, education and school contacts by βE, professional and work contacts by βP, and other contacts by βO.
In order to match the age-structured model with the homogeneous mixing model the social functions were normalized using the previously estimated parameters βe and γe in accordance with
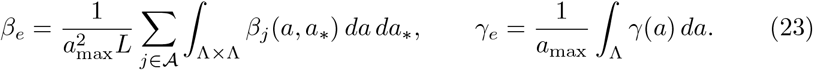 We considered both a uniform and an age-related recovery rate [50, 53] as a decreasing function of the age in the form
We considered both a uniform and an age-related recovery rate [50, 53] as a decreasing function of the age in the form
 with r = 5 and C ∈ℝ such that (23) holds. Clearly, this choice involves a certain degree of arbitrariness since there are not yet sufficient studies on the subject, nevertheless, as we will see in the simulations, it is able to reproduce more realistic scenarios in terms of age distribution of the infected without significantly altering the behaviour relative to the total number of infected.
with r = 5 and C ∈ℝ such that (23) holds. Clearly, this choice involves a certain degree of arbitrariness since there are not yet sufficient studies on the subject, nevertheless, as we will see in the simulations, it is able to reproduce more realistic scenarios in terms of age distribution of the infected without significantly altering the behaviour relative to the total number of infected.
In a similar spirit, to match the single control applied in the extrapolation of the penalization term κ(t) to age dependent penalization factors κj(a, t) we redistribute their values as
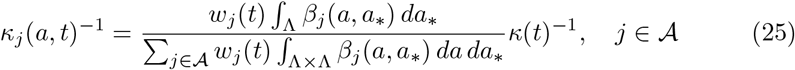 where wj(t) ≥ 0, are weight factors denoting the relative amount of control on a specific activity. In the lockdown period accordingly to other studies [45] we assume wE = 1.5, wH = 0.2, wP = 0.5, wO = 0.6, namely the largest effort of the control is due to the school closure which as a consequence implies more interactions at home. Work and other activities are equally impacted by the lockdown. In particular, these initial lockdown choices make it possible to have a good correspondence between the infectivity curves expected in the age dependent case and in the homogeneous mixing case. Therefore, these values have been set homogeneously for each country and correspond to the situation in the first lockdown period. We will discuss possible changes to these choices following a relaxation of the lockdown in the different scenarios presented below.
where wj(t) ≥ 0, are weight factors denoting the relative amount of control on a specific activity. In the lockdown period accordingly to other studies [45] we assume wE = 1.5, wH = 0.2, wP = 0.5, wO = 0.6, namely the largest effort of the control is due to the school closure which as a consequence implies more interactions at home. Work and other activities are equally impacted by the lockdown. In particular, these initial lockdown choices make it possible to have a good correspondence between the infectivity curves expected in the age dependent case and in the homogeneous mixing case. Therefore, these values have been set homogeneously for each country and correspond to the situation in the first lockdown period. We will discuss possible changes to these choices following a relaxation of the lockdown in the different scenarios presented below.
We divided the computation time frame into two zones and used different models in each zone, in accordance with the policy adopted by the various countries. The first time interval defines the period without any form of containment, the second the lockdown period. In the first zone we adopted the uncontrolled model with homogeneous mixing for the estimation of epidemiological parameters. Hence, in the second zone we compute the evolution of the feedback controlled age dependent model (17) with matching (on average) interaction and recovery rates (23) and with the estimated control penalization κ(t). The initial values for the age distributions of susceptible have been taken from the specific demographic distribution of each country. More difficult is to get the same informations for the infected, since reported data are rather heterogeneous for the various country and the initial number of individuals is very small (we selected a time frame where the reported number of infectious is larger than 200). Therefore, we tested the available data against a uniform distribution. As there were no particular differences in the results, we decided to adopt a uniform initial distribution of the infected for all countries. In Figure 8 we report the age distribution of infected computed for each country at the end of the lockdown period using an age dependent recovery and a constant recovery. The differences in the resulting age distributions are evident. In subsequent simulations, to avoid an unrealistic peak of infection among young people, we decided to adopt an age-dependent recovery [50].

Age distribution of infected using constant and age dependent recovery rates as in (24) at the end of the lockdown period in different countries.
3.6.1. Scenario 1: Relaxing lockdown measures at different times
In the first scenario we analyze the effects on each country of the same relaxation of the lockdown measures at two different times. The first date is country specific accordingly to current available informations, the second is June 1st for all countries. For all countries we assumed a reduction of individual controls on the different activities by 20% on family activities, 35% on work activities and 30% on other activities without changing the control over the school. The behaviors of the curves of infected people together with the relative 95% confidence bands are reported in Figure 9.
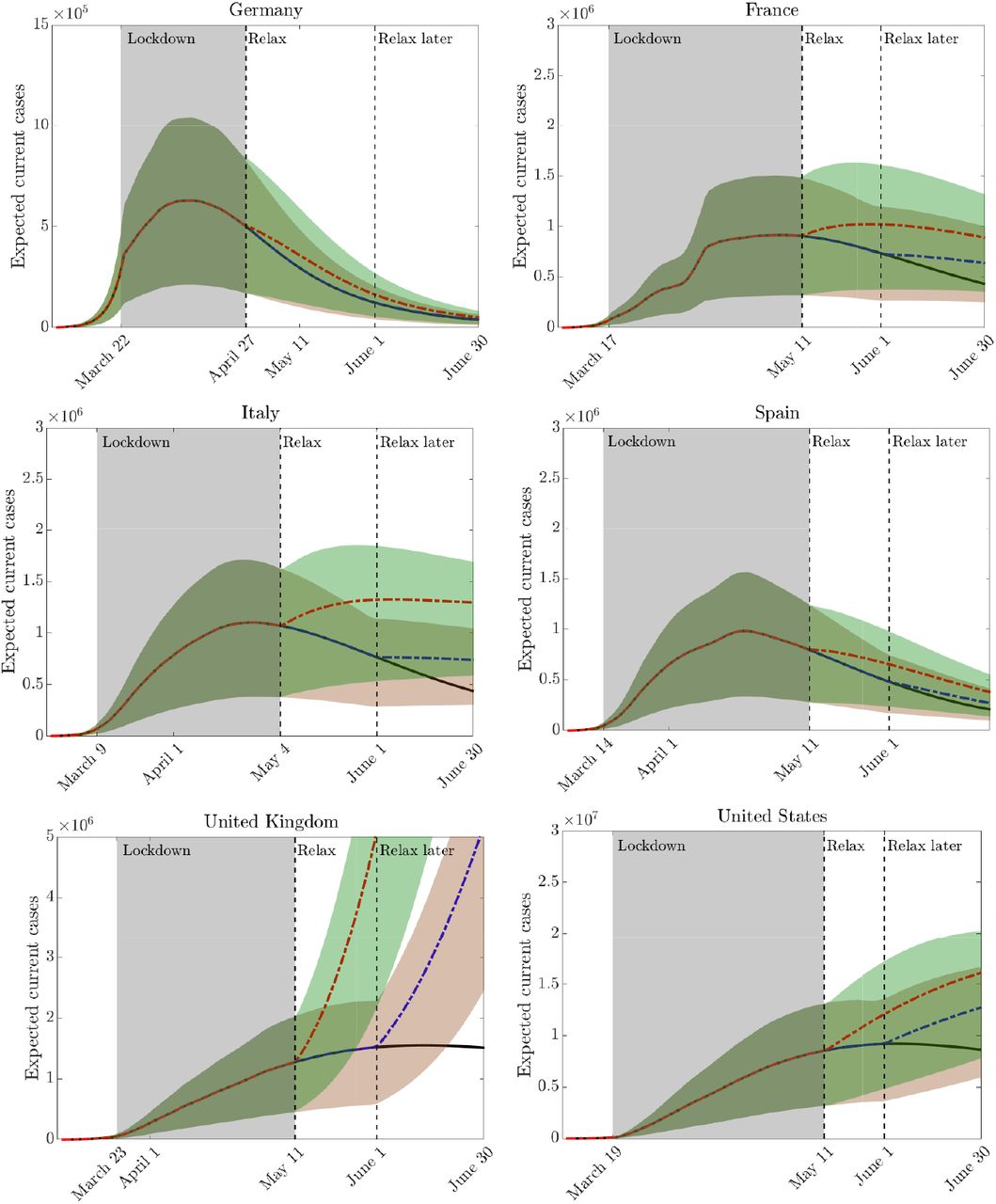
Scenario 1: Effect on releasing containment measures in various countries at two different times. In all countries after lockdown we assumed a reduction of individual controls on the different activities by 20% on family activities, 35% on work activities and 30% on other activities by keeping the lockdown over the school.
The results show well the substantial differences between the different countries, with a situation in the UK and US that highlight that the relaxation of lockdown measures could lead to a resurgence of the infection. On the contrary, Germany and, to some extent Spain, were in the most favorable situation to ease the lockdown without risking a new start of the infection.
3.6.2. Scenario 2: Impact of school and work activities
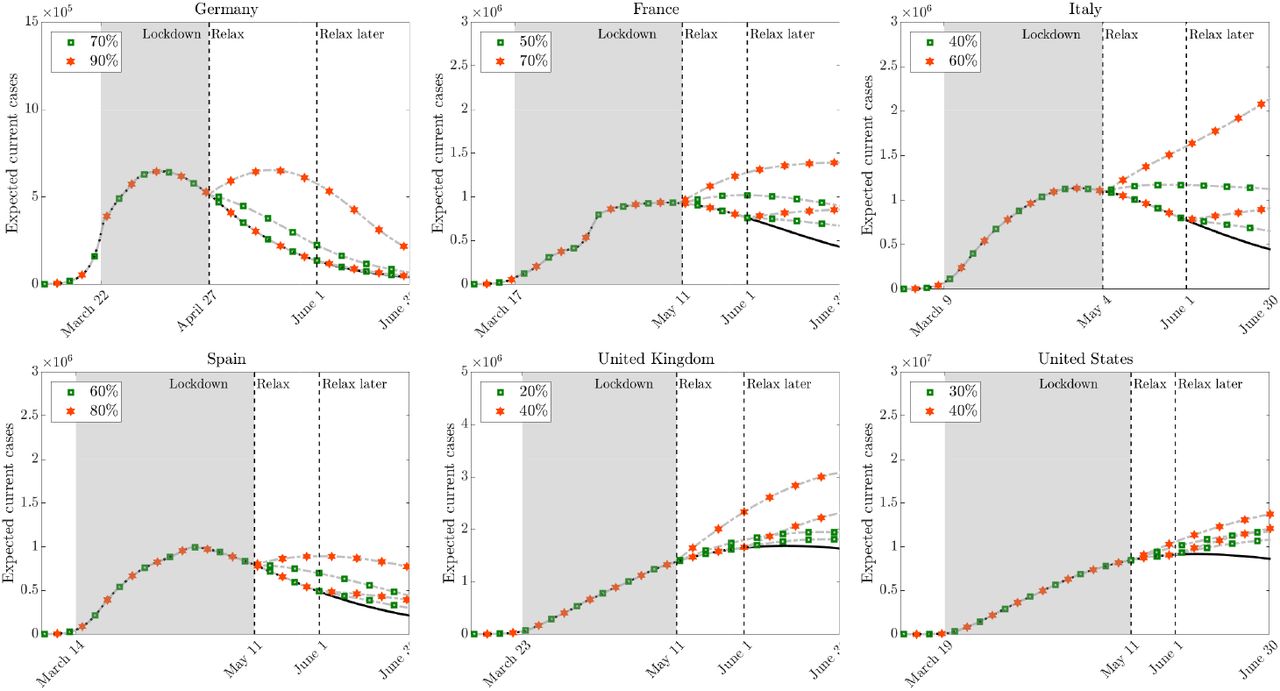
In order to highlight the differences in the infection dynamics according to the choices related to specific activities, such as school and work, we have considered the effects of a specific lockdown relaxation in these directions. Precisely for each country we have identified a range for such loosening which gives an indication of the maximum allowed opening of the activities before a strong departure of the infection.
It was assumed to relax the lockdown of the school with a mild resumption of family, work and other activities interactions by 5% for each 10% release of the school. The results are reported in Figure 10. Next, we perform a similar relaxation process oriented towards productive activities with a reduction of control on such activities at various percentages. Here we assumed no impact on school activities and a mild impact on family and other activities with a loosening at 5% for each 10% release of the work. The results are given in Figure 11. In both cases, the results show different infection dynamics in the selected countries as a consequence of the relaxation of lockdown policies. In particular, in the UK and USA any relaxation could determine a strong restart of the epidemic.

Scenario 2 - school: Effect on releasing containment measures for school activities in various countries at two different times. Family, work and other activities are relaxed by 5% for each 10% release of the school activity.

Scenario 2 - work: Effect on releasing containment measures for productive activities in various countries at two different times. School is kept in lockdown. Family, and other activities are relaxed by 5% for each 10% release of the productive activity.
3.6.3. Scenario 3: Restarting activities while keeping the curve under control
One of the major problems in the application of very strong containment strategies, like lockdown measures, is the difficulty in maintaining them over a long period, both for the economic impact and for the impact on the population from a social point of view.
The results presented in Section 3.6.2 that the impact of relaxation policies may strongly differ one country from another.
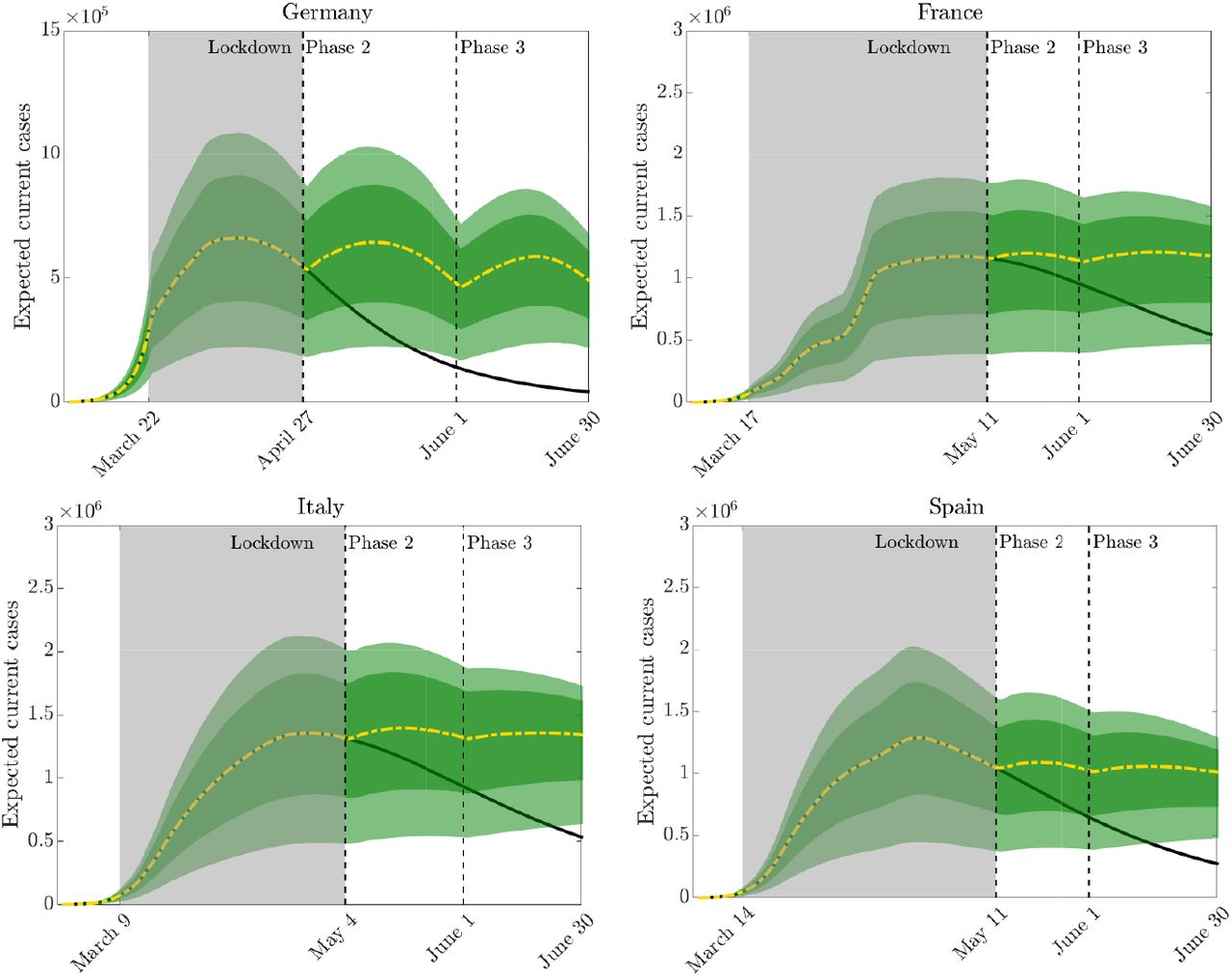
In this latter scenario, we consider a strategy based on a two-stage opening of the blocking measures with a progressive approach. This possibility is analysed for the four countries where the infection curve appears less sensitive to relaxation policies, i.e. Germany, Spain, France, and Italy. For each country we have selected a progressive lockdown relaxation focused mainly on the opening of productive activities in the second phase and with a partial reprise of school activities in the third phase. The reduction of the controls are now country specific and the values are reported in Table 2. In Figure 12 we plot the resulting behavior for the expected number of current infectious. The simulations show that for all these countries, the relaxation of containment measures was possible while keeping the infection curve under control. However, timing and intensity of the relaxation choices play a fundamental rule in the process.
Scenario 3: Progressive relaxation of lockdown measures for different countries as specific control reduction percentages. Results are reported in Figure 12.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Scenario 3: Relaxing lockdown measures in a pro-gressive way in two subsequent phases while keeping the epidemic peak under control. In the second phase only productive activities are restarted and partially home interactions and other activities. In a third phase school activities are also partially reopened (see Table 2).
4. Conclusions
In order to contain epidemic dynamics, it is essential to have models capable of describing the impact of non pharmaceutical interventions, such as lockdown policies, based on specific social characteristics of the country and the containment actions implemented. In this work, aware of the complexity of the problem, we have tried to provide a suitable modeling context to describe possible scenarios in this direction. More precisely, with the aid of compartmental models incorporating specific feedback controls on social interactions capable to describe the selective action of a government in opening certain activities such as home, work, school and other activities, we can simulate their impact with respect to the epidemic trend. In particular, in an effort to take into account the high uncertainty in the data, the model has been formalized in the presence of uncertain input parameters that allow to explore hypothetical scenarios with appropriate confidence bands. Applications to the first wave of the COVID-19 pandemic to different countries, including Germany, France, Italy, Spain, the United Kingdom and the United States, has been considered. The results, in accordance with the observations, show situations with different levels of sensitivity to a hypothetical reopening of certain activities Further studies are being conducted on geographical dependence through spatial variables. This would make it possible to characterize control measures on a local rather than global basis.
Data Availability
All data referred to in the manuscript are available.
Acknowledgements
This work has been written within the activities of GNFM and GNCS groups of INdAM (National Institute of High Mathematics). G. Albi and L. Pareschi acknowledge the support of MIUR-PRIN Project 2017, No. 2017KKJP4X “Innovative numerical methods for evolutionary partial differential equations and applications” and G. Albi partial support of RIBA 2019, No. RBVR199YFL “Geometric Evolution of Multi Agent Systems”. M. Zanella was partially supported by the MIUR - “Dipartimenti di Eccellenza” Program (2018-2022) – Department of Mathematics “F. Casorati”, University of Pavia.
Footnotes
E-mail address: lorenzo.pareschi{at}unife.it
E-mail address: mattia.zanella{at}unipv.it
↵1 Presidenza del Consiglio dei Ministri, Dipartimento della Protezione Civile. GitHub: COVID-19 Italia - Monitoraggio situazione, https://github.com/pcm-dpc/COVID-19, 2020
↵3 https://www.who.int/emergencies/diseases/novel-coronavirus-2019/
REFERENCES
- [1].↵
- [2].
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵



