
Abstract
Background The spread of coronavirus in the United States with nearly one million confirmed cases and over 53,000 deaths has strained public health and health care systems. While many have focused on clinical outcomes, less attention has been paid to vulnerability and risk of infection. In this study, we developed a planning tool that examines factors that affect vulnerability to COVID-19.
Methods Across 46 variables, we defined five broad categories: 1) access to medical, 2) underlying health conditions, 3) environmental exposures, 4) vulnerability to natural disasters, and 5) sociodemographic, behavioral, and lifestyle factors. We also used reported rates for morbidity, hospitalization, and mortality in other regions to estimate risk at the county (Harris County) and census tract levels.
Analysis A principal component analysis was undertaken to reduce the dimensions. Then, to identify vulnerable census tracts, we conducted rank-based exceedance and K-means cluster analyses.
Results Our study showed a total of 722,357 (~17% of the County population) people, including 171,403 between the ages of 45-65 (~4% of County’s population), and 76,719 seniors (~2% of County population), are at a higher risk based on the aforementioned categories. The exceedance and K-means cluster analysis demonstrated that census tracts in the northeastern, eastern, southeastern and northwestern regions of the county are at highest risk. The results of age-based estimations of hospitalization rates showed the western part of the County might be in greater need of hospital beds. However, cross-referencing the vulnerability model with the estimation of potential hospitalized patients showed that part of the County has the least access to medical facilities.
Conclusion Policy makers can use this planning tool to identify neighborhoods at high risk for becoming hot spots; efficiently match community resources with needs, and ensure that the most vulnerable have access to equipment, personnel, and medical interventions.
Introduction
The outbreak of the novel Coronavirus was first reported in Wuhan, China but has since spread to almost every country in the world. The highest number of cases and deaths, as of this writing, has been reported in the U. S. [1] Within the 50 states, there is an apparent disparity in the number and causes of infections and their spread within each state. However, what is common to all cases reported thus far, is the rates of mortality and hospitalizations that appear to be highest among relatively older populations and populations with underlying medical conditions that facilitate morbidity due to COVID-19 [2–8].
Much research has focused on clinical outcomes, epidemiological modeling, and transmission dynamics of the novel coronavirus (see for example, [9–12]), but less focus has been placed on risk and vulnerability to contracting the disease. Emerging studies have begun to report on the impacts of social vulnerability on COVID-19 from an incidence and outcome standpoint [2–7,13]. However, the spatial resolution of most studies to date has been at the global or country level, and less attention has been paid to finer spatial resolutions such as the census tract scale within a county. A finer spatial resolution is important from a vulnerability and risk standpoint as demonstrated in a recent study that showed that the poorest neighborhoods in Houston, Texas, might be at a higher risk of hospitalization from COVID-19 [14] based on an analysis of the Centers for Disease Control (CDC) underlying risk factors for severe COVID-19 cases [4] that include: asthma, Chronic Obstructive Pulmonary Disease (COPD), heart disease, hypertension, diabetes, and a history of heart attacks or strokes.
While the aforementioned underlying medical conditions are important risk factors, they weigh in on the risk of hospitalization but not necessarily on the risk of contracting the disease. As such, underlying medical conditions and sociodemographic variables may not fully represent the magnitude of the risk and the challenge in managing and mitigating disease in affected populations from pandemics such as COVID-19. Environmental pollutants such as air quality [15], CO2 emissions [13], and ambient conditions such as temperature and humidity [5,16] showed correlations with COVID-19 morbidity. Furthermore, environmental exposures due to proximity to contaminated areas such as Superfund sites, hazardous waste sites, landfills, and leaky petroleum tanks has long-term adverse effects on public health, immune systems, and vulnerability to certain diseases [17–21]. Public health is further exacerbated by natural disasters, such as hurricanes and severe storms [22–24] that expose populations to pathogens and pollutants in floodwater and their flooded homes and potentially contribute to weakened immune systems. Behavioral and lifestyle factors could also affect the vulnerability of a population to an infectious disease such as COVID-19. Obesity, in recent COVID-19 data, has been shown to be prevalent in hospitalized patients [7], and smoking has been associated with disease progression [25]. Finally, it should be noted that because the risk is unevenly distributed, shortages in hospital beds, personal protective equipment (PPE), and medications have emerged in some but not all communities [26–28], thereby widening disparities and exposing systemic shortcomings [29]. Limited access to medical facilities, especially with less than fully-functional transportation systems combined with lack of insurance coverage, could worsen the impact of COVID-19 for people with less favorable sociodemographic metrics and people in rural regions. Thus, a more holistic view of the vulnerability of communities to COVID-19 that considers all of the aforementioned variables is needed to guide decision-makers in identifying the areas and populations in their jurisdictions that require specific resources, response, and mitigation actions.
In this study, we develop a rigorous planning tool at the census tract level that examines influential determinants of vulnerability to COVID-19 in 5 broad categories (with 46 variables) that include: 1) access to medical, 2) underlying medical conditions, 3) environmental exposures, 4) vulnerability to natural disasters and 5) sociodemographic, behavioral, and lifestyle factors. However, understanding the vulnerability of a population to COVID-19 is only one aspect of planning for such a pandemic. Other aspects include expected morbidities, mortalities, and hospitalization rates. Thus, the goals for developing the planning tool are to better understand medical access gaps and demands for hospitalization, identify parts of the county where more protective measures and response actions need to be put in place, and have a data-driven framework for estimating case numbers, hospitalizations, and deaths by census tract. Another goal is to have a better sense of the number of persons that may be affected broadly and more specifically as authorities lift or modify current policies such as the Stay Home Work Safe policy in place for Harris County and the City of Houston.
Such a planning tool is critical in order to mitigate the impact of COVID-19 and prepare for future pandemics. Using this tool, policymakers can identify neighborhoods with a higher potential for becoming the next hot spots, efficiently match community resources with community needs, and ensure that equipment, personnel, medications, and support are available to everyone, particularly the most vulnerable and those in greatest need. This strategy is essential to address historical trends that have preferentially delivered resources to those with means resulting in gaps in quality [30–32]. The planning framework developed in the study is readily transferable to other counties in the US and can be expanded to the state level for decision-making on a short-term or long-term basis towards improving the overall health of communities in each state.
Methods
Study Region
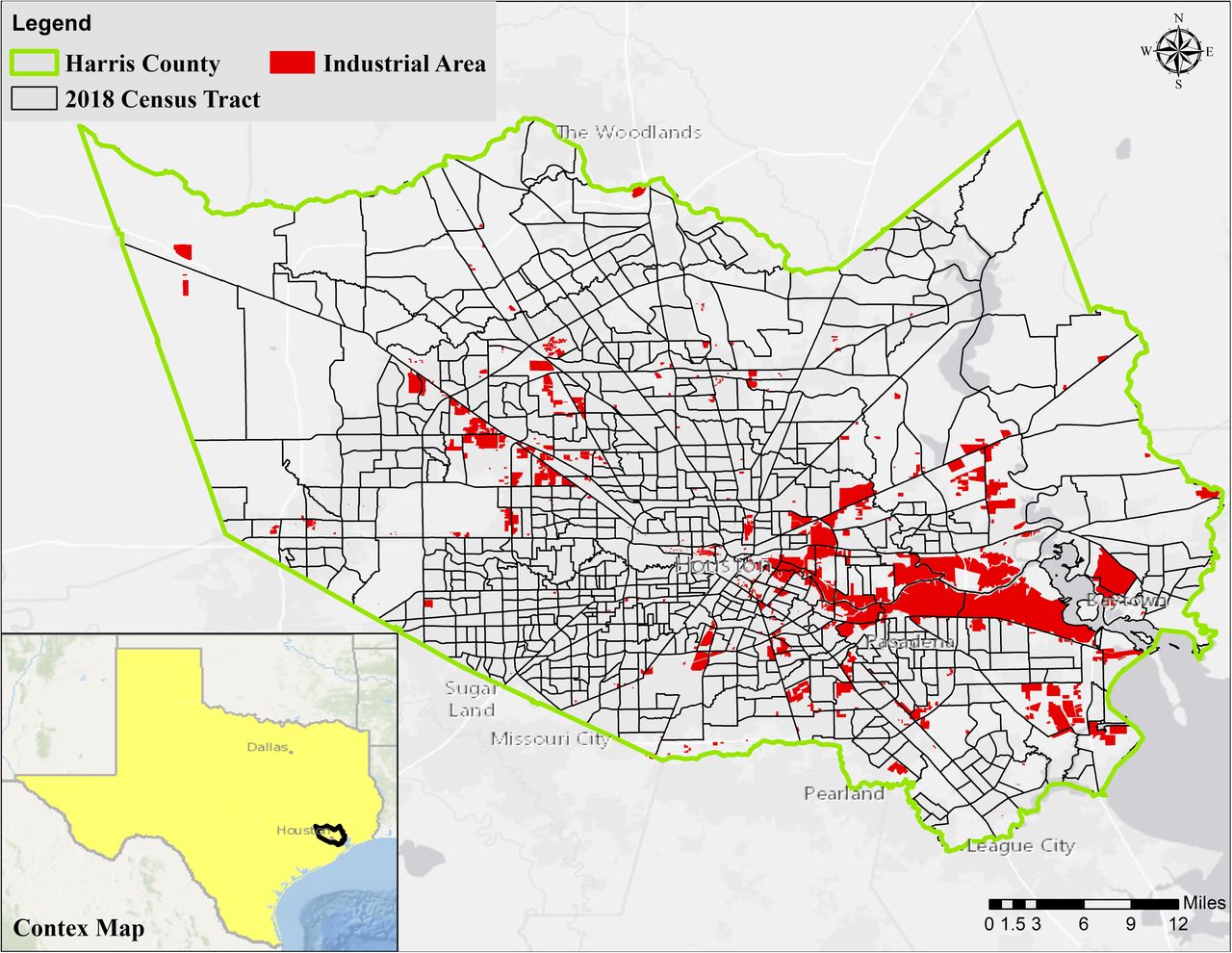
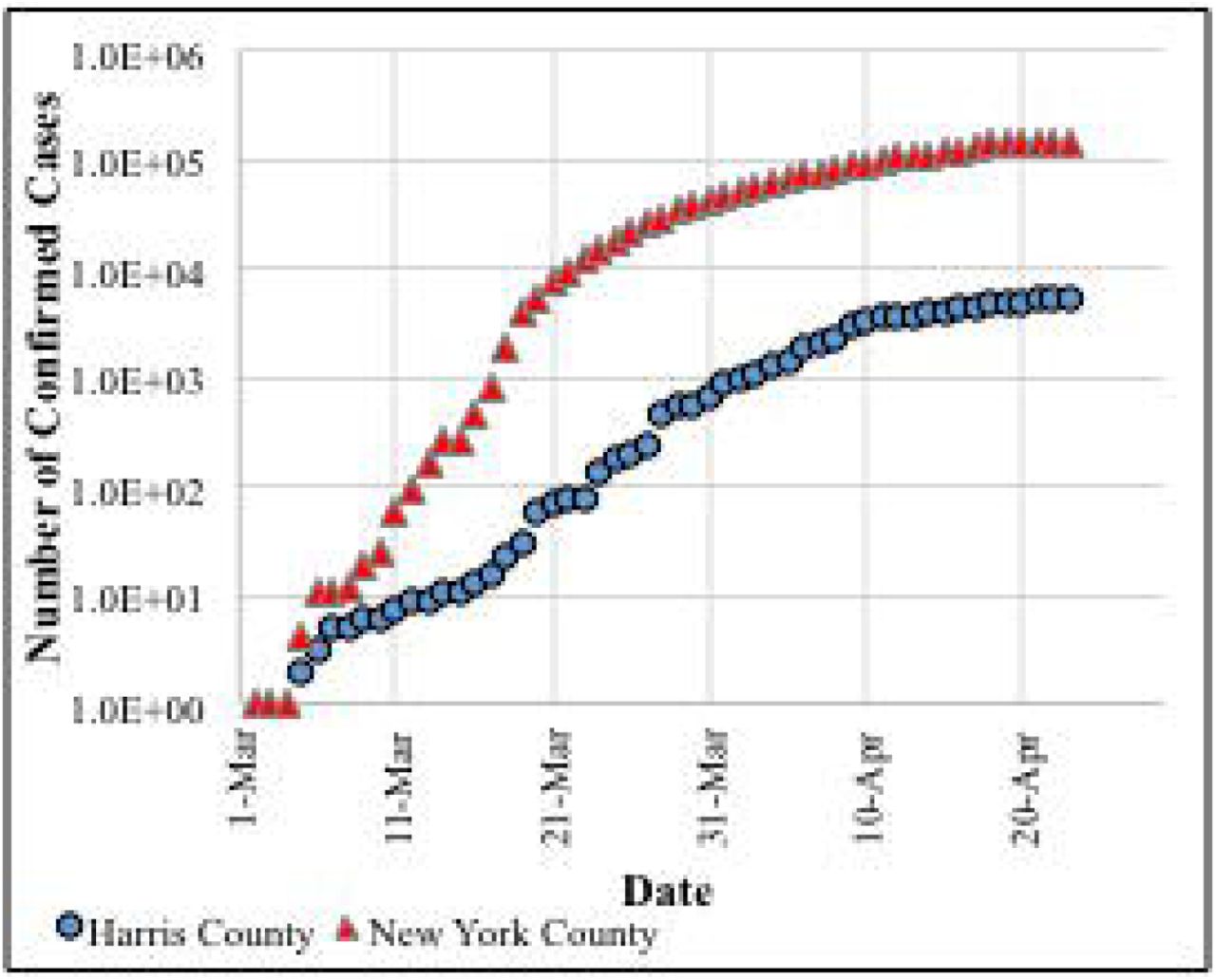
Harris County, located in the southeastern part of Texas (Fig 1), is the third-most populous county in the U.S., with more than 4.7 million residents [33]. While ranked number 2 in the nation in terms of Gross Domestic Product (GDP) growth, the County exhibits geospatial socioeconomic disparities among its population. The County is experiencing fewer cases, and lower rates of transmission relative to the rest of the U.S. Fig 2 shows the number of confirmed cases of COVID-19 in Harris County compared to New York County, for example. As shown in Fig 2, both the total number of confirmed cases and the slope of the spread are significantly higher in New York compared to Harris County. This is important to note because it potentially offers the County the opportunity for using the developed tool for improved long-term planning to respond to community health needs and disparities in response to COVID-19 and other pandemics or natural disasters.
Data Acquisition and Processing
All census data (2018) at the census tract level were compiled from the National Historical Geographic Information System (NHGIS) database [34]. Total population, the number of households, median income and income per capita (adjusted to 2018 US dollars), percent of the population below the poverty line, with cash public assistance or food stamps/SNAP (Supplemental Nutrition Assistance Program), living alone, with health insurance coverage, with a disability, education, and age distribution for each tract in Harris County were accessed. Using the detailed variables in the census data, education in this study was defined as the percent of the population with high school diplomas or higher degrees. Due to the importance of age in the vulnerability to COVID-19, both median age and the percent of the population in decadal age intervals were calculated. The percent of the population below the poverty line was chosen as the main economic variable, and the household density was calculated by dividing the total number of households by the area of each census tract.
Two measures of vulnerability to flooding were defined, using data from Hurricane Harvey that had severe impacts on Harris County in 2017: i) the ratio of the number of households that filed damage claims based on Federal Emergency Management Agency (FEMA) data [35] to the total number of houses in each tract, and ii) the ratio of the wetted areas (with water depth greater than zero) during Hurricane Harvey in a census tract to the total area of the tract (the specific methodology for this approach is described in [36]).
Locations and types of medical facilities including nursing facilities, federally qualified health centers, hospitals, rural health clinics, urgent care centers, and Harris County Health System facilities were obtained from the Health Resources and Services Administration (HRSA) query data explorer tool [37], Harris County Health System [38], and the Homeland Infrastructure Foundation-Level Data (HIFLD) database [39]. The Microsoft Bing Maps Platform APIs [40] was used to estimate the drive time from the centroid of each tract to all of the available medical facilities nearby. ArcMap was used to extract the coordinates of both origins (centroids) and destinations (medical facilities), and the minimum travel time in minutes was then recorded for each tract in Microsoft Excel.
The underlying conditions that might affect the vulnerability to COVID-19 (arthritis, asthma, high blood pressure (HBP), cancer (except skin cancer), high cholesterol, chronic kidney and heart diseases, COPD, diabetes, poor physical and mental health, and stroke); as well as increased-risk behaviors/conditions (binge drinking, smoking, no leisure time physical activity, obesity, sleep less than 7 hours), and preventive indicators (annual doctor and dentist checkups, medication for high blood pressure (HBP), cholesterol screening, and routine physical exams) were all acquired from the 500 cities mapper database [41] (Table 1), which draws from the Centers for Disease Control and Prevention’s (CDC) Behavioral Risk Factor Surveillance System. It should be noted that data from [41] were only available at 584 out of 786 (73.8%) census tracts in Harris County. Census tracts without data are clearly identified in all figures.
As noted before, ambient conditions such as temperature and humidity could affect the spread of COVID-19; however, in this study, an ambient gradient in Harris County was neglected as the spatial change over the County is expected to be minimal. Three indicators of air quality: ozone, nitrogen dioxide (NO2), and particulate matter smaller than 2.5 micrometers (PM2.5), were downloaded from the Texas Air Monitoring Information System (TAMIS) database [42]. For ozone, the 8-hour average concentrations were calculated using IBM SPSS (version 26) for all of the available monitoring stations (40) and compared with the 70 ppb standard established by the United States Environmental Protection Agency (EPA). The number of exceedances of the EPA standard for each monitoring station over the period of 2000-2019 was then calculated. Interpolation tools in ArcMap were used to convert the median measured concentration for each station to a continuous raster to overcome the spatial sparsity in measurements. The generated raster was then used to calculate the concentration of ozone for each census tract using the zonal statistics tool in ArcMap. One particular station (695: UH Moody Tower) was removed from the ozone calculation due to its extremely low temporal resolution compared to the other stations. Similar approaches were taken for NO2 (hourly measurements for 21 stations with 100 ppm standard) and PM2.5 (averaged daily data for 12 stations with a 35 μg/m3 standard).
Environmental releases from various sources to air, water, soils in Harris County were obtained from the United States Coast Guard National Response Center database [43]. The total number of emissions, pollution spills, or contaminant discharge events that occurred during the period between 2000 and 2020 for each zip code was extracted from the database by combining different years, filtering the actual events for Harris County, and removing redundant data points. The spatial join tool in ArcMap was used to convert the total number of events in each zip code to a summed total number of events for each census tract. The resulting value was added to the number of leaking petroleum storage tanks (underground and aboveground tanks) reported by the Texas Commission on Environmental Quality (TCEQ) [44] in the tract. A hazardous sites shapefile was developed by merging two databases: the EPA Superfund Enterprise Management System database [45], and the Texas Commission on Environmental Quality (TCEQ) GIS database [44]. From the latter source, the locations of municipal solid waste sites/landfills were acquired. The Near tool in Arcmap was used to calculate the distance between the centroid of each census tract to the nearest aforementioned hazardous sites. A second environmental variable was defined as the sum of the total number of dry cleaners, petroleum storage tanks (all underground and aboveground tanks), and sites that are part of an Industrial and Hazardous Waste Corrective Action (IHWCA) program located within each census tract; data for those was obtained from [44]. Both Shapiro-Wilk and Kolmogorov-Smirnov tests conducted in IBM SPSS showed that none of the datasets were normally distributed.
Defining Categories
A Principal Component Analysis (PCA) with orthogonal rotation (Varimax with Kaiser Normalization) was conducted in IBM SPSS as the first step to reduce the dimensions. Due to the limitation in data availability, as noted before, the PCA was performed for data from 584 tracts with all available data. Eigenvalues from random values were generated and compared with the values in this study using a parallel analysis engine [46]. This comparison was made to determine the number of components that should be retained in the analysis; components with eigenvalues greater than the randomized method were kept. The first five components that could explain ~ 80% of the variability in the 46 variables showed eigenvalues larger than the ones generated by the engine. S1 Table in the Supplementary Information (SI) shows the most dominant variables in each component (category).
The choice of variables for the study (Table 1) was based on the results of the PCA in addition to findings reported in previous studies, and data availability. Category 1 includes access to medical care, including medical facilities, medications, and insurance coverage, routine checkups, and physical exams, as well as household density as a surrogate for interaction among individuals within each tract (e.g., how crowded grocery stores could be in the tract). Category 2 includes chronic diseases, medical conditions, disability that could potentially affect the vulnerability to COVID-19, and age distribution. For environmental exposure, pollution events from various sources, the 3-air quality indicators, and the presence of hazardous sites were included. Flooding from Hurricane Harvey was the only metric in Category 4, although this could be expanded in future work to include heat, drought, wildfires, and other natural disasters. Finally and for Category 5, a combination of social, economic, behavioral, and lifestyle factors that could potentially threaten the health of individuals during the COVID-19 pandemic was considered.
Statistical Analyses
Vulnerability Analysis
Two classification approaches were used in the study with the goal of identifying the most vulnerable populations to COVID-19; a rank-based exceedance method developed in Microsoft Excel, and a standard K-Means Cluster Analysis (K=3) using IBM SPSS. Validation of any developed models for the vulnerability was not possible due to lack of data at the desired spatial resolution and the fact that the pandemic is still developing. Thus, the second model (K-means) was used as a benchmark for the first model for comparison purposes.
In the rank-based exceedance method, for each variable, sorting the data in Microsoft Excel developed the rank of each census tract relative to other tracts within Harris County. The exceedance rate (percentile) was calculated as follows:

Where m is the rank, and n is the total number of tracts (786 in Harris County). The calculated exceedance for a given tract represents the percent of tracts that have a better condition than the selected one. To ensure that the direction of exceedance is the same among all variables, (1 – exceedance) was used for variables with positive nature such as insurance coverage, education, access to medication, and preventive tests. For each category, the average value of exceedance for all of the variables within that category was calculated and reported. In addition to classifying the tracts for each of the aforementioned categories, an overall vulnerability was defined by averaging the exceedance rates of the five defined categories. The percentile associated with each averaged value (for each category and for the overall vulnerability) was calculated and exported to ArcMap to generate decision-support level maps.
In the K-means cluster analysis (K-means is an unsupervised machine learning algorithm), three classes were defined for each category. As a result, the output classes were ordered as high (severe), average, and low depending on the order of the final cluster centers. The ANOVA test was conducted on the clusters to ensure that the values of the different variables were significantly different between clusters. Similar to the exceedance method, an overall vulnerability for each census tract was determined by averaging the five output class numbers (i.e., 1, 2, and 3) associated with the five categories. For illustration purposes, the percentile rank for each of the tracts was calculated and exported to ArcMap.
Although it is possible to assign weights to the categories and calculate a weighted average, equal importance for the categories was assumed in this study. Assigning weights is beyond the scope of this paper as there is not enough evidence to support such assignments as of this writing.
Morbidity, Hospitalization, and Mortality Rates
As of April 23rd, 2020, the total number of confirmed cases and deaths in Harris County were 5,330 and 82 [47], respectively, which translates to a morbidity rate of 121.83 per 100,000 persons, and 1.54% mortality rate. The COVID-19 hospitalization rates for the two Trauma Service areas Q and R (comprising the southeast region of Texas) are 7.86 and 9.84 per 100,000 persons [48]. It is noted that predicting the risk of infection, morbidity, and mortality rates in Harris County requires a more extensive dataset and would involve considerable uncertainty due to limited knowledge of the SARS-CoV-2 virus and the relatively limited number of tests that have been administered thus far. In this study, the distribution of COVID-19 by sex and age was the only metric considered for predicting the risk of hospitalization, morbidity, and mortality in Harris County. This is mainly due to limited access to health information for individuals in the County, such as comorbidities and the unknown effect of underlying medical or other lifestyle conditions on the risk of infection and potential complications from COVID-19.
According to the data obtained from the New York Department of Health and Mental Hygiene [49], the morbidity rates (using the reported number of cases) observed in New York City (NYC) were 171.46, 1554.45, 2529.03, 2552.64, 2976.74, and 1687.8 per 100,000 population for age groups of 0-17, 18-44, 45-64, 65-74, and +75 years, respectively. Although the nature of the spread of COVID-19 could be substantially different in New York City compared to Harris County, the NY City rates were applied in this study to develop a worst-case scenario estimate. Age data from [34] were re-classified to align with the intervals defined by the New York Department of Health and Mental Hygiene [49].
As of April 11th, 2020, the hospitalization rates among people with laboratory-confirmed COVID-19 in the U.S., based on data from the CDC [50], were 1.1, 0.3, 10, 32.8, 45.8, 76, and 110 per 100,000 population for age groups of 0-4, 5-17, 18-49, 50-64, 65-74, 75-85, and +85 years, respectively. However, substantially higher rates were reported in New York City [49]; 13.55, 153.69, 630.34, 1192.5, 1830.07, and 437.24 per 100,000 population for age groups of 0-17, 18-44, 45-64, 65-74, and +75 years, respectively. For the CDC rates, the population with age under five years old was used instead of 0-4 years.
Three separate studies, one with 3,665 cases in mainland China and 1,334 cases detected outside of mainland China [51], another one with 73,780 cases in Italy [52] and the latest with 141,754 cases in New York [49] reported different mortality rates among different age intervals. Both studies in China and Italy reported the mortality rates among confirmed COVID-19 cases while the New York study reported the total of deaths per 100,000 persons within each age interval. In this study, rates from all three studies, as shown in Table 2, were used to calculate the mortality rates associated with COVID-19 in Harris County. Multiplying the rates in each study by the associated number and percentages of the population in each age group was used to calculate the risk of morbidity, hospitalization, and mortality rates for each census tract.
An important caveat of the approach used in this study is the emerging realization of underreported positive cases in the US and potentially undercounting deaths by not testing all persons who have died in the US since December 2019. A second important caveat is that the true rate of infection is currently unknown. The third caveat is that Texas, as of this writing, has had one of the lowest rates of testing in the US.
Results and Discussion
Geospatial Distribution of Determinants in the 5 Categories
S2 Table provides a summary of statistics for all of the 46 variables used in the study. Among the 46 variables, maps are only presented for those that were not based on publicly available data. Fig 3 shows the locations of medical facilities (all types as described in Methods) within and around Harris County as well as the drive time to the nearest facility for each census tract. The drive time varies from seconds to 25.23 minutes, with a median of 4.74 minutes (S2 Table). As can be seen from Fig 3, people who live in areas located farther away from the center of the County, especially in the western and northeastern parts, have a longer drive time to a medical care facility. This longer drive time becomes even more critical if an individual does not have a personal car and needs to use the less than a fully functional transportation system. The travel time is even longer to facilities managed by the Harris Health system (typically used by individuals with no insurance or documentation). From a planning standpoint, Fig 3 below, when combined with vulnerabilities, can be used to drive decisions related to the establishment of field hospitals during periods of widespread transmission. Importantly, the data can be used to develop a more holistic response plan directing persons with various severity or symptoms of the disease to different types of medical intervention facilities.

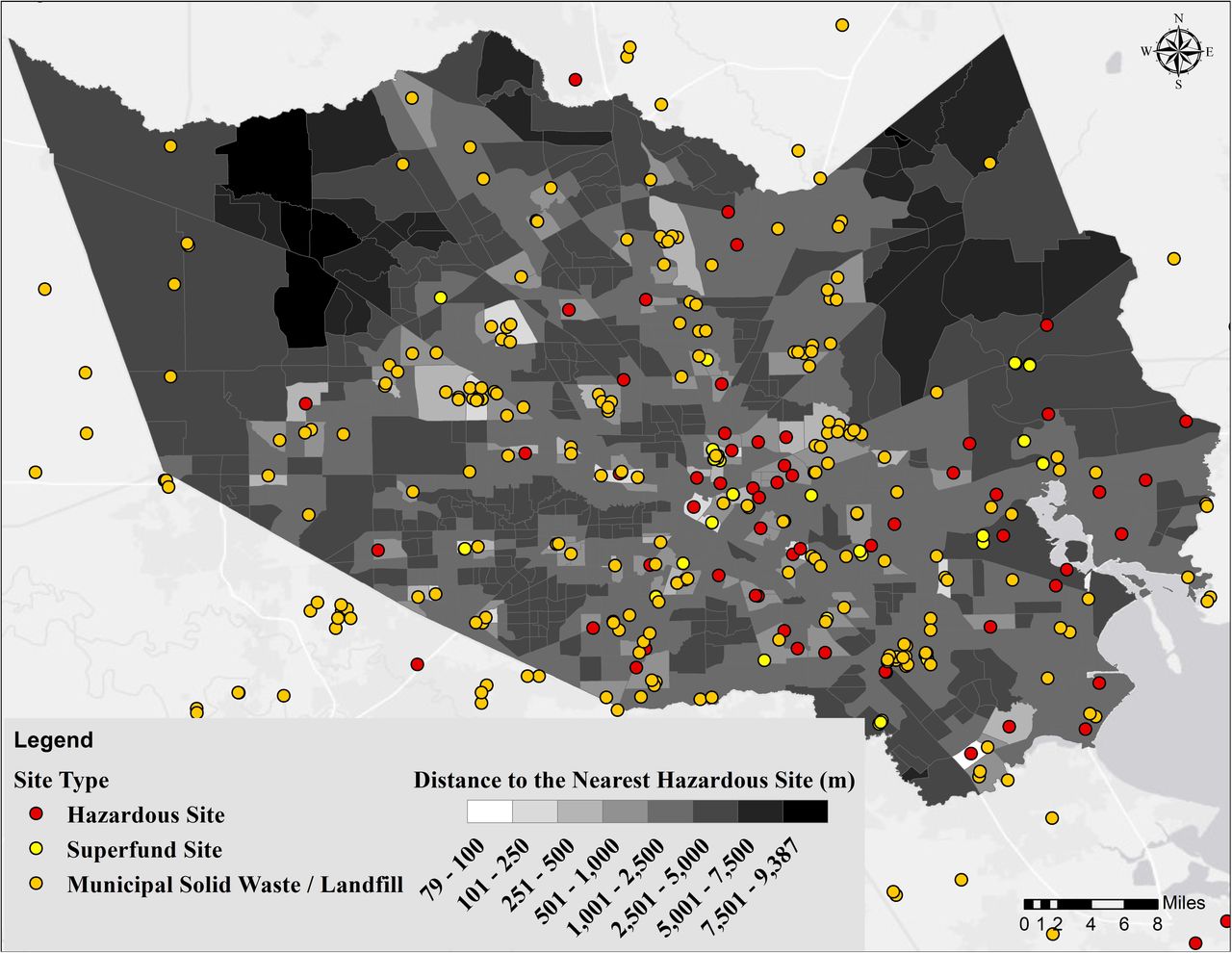
The distance to and location of hazardous sites (Superfund sites, landfills, and industrial hazards) are shown in Fig 4. The distance ranges from 79 to 9,386 m with a median of 2,105 m. The hazardous sites are spread over the entire County but are more concentrated closer to the industrial areas (see Fig 1), water bodies (Houston Ship Channel (HSC), and Galveston Bay (GB)). The tracts in less developed areas have the longest distance to a hazardous site indicating a higher potential vulnerability to pollution in the more developed parts of Harris County.
S1-S3 Figs show the median concentration of ozone, NO2, and PM2.5 for each tract in addition to the number of times during 2000-2019 that a monitoring station exceeded the EPA standard. It should be noted that the number of stations and, consequently, the geospatial coverage was significantly lower for NO2 and PM2.5 when compared to ozone. Stations with the highest number of exceedances of EPA standards for all three measures are located near industrial areas (see Fig 1). While the central parts of the County showed the highest concentration of NO2 and PM2.5, ozone concentrations were highest closer to the industrial areas. The higher levels of NO2 in central parts of Harris County could be attributed to emissions from mobile sources that are more abundant in downtown Houston [53]. The observed pattern for ozone is a result of industrial activities, the ozone-NO2 relationship, and the wind pattern in Houston [54,55]. In the case of PM2.5, the higher concentrations in Harris County have been associated with regional aerosols, biomass burning, and gasoline combustion [56] that are higher in the central part of the County. The median concentrations for ozone, NO2, and PM2.5 were 21.24 ppb, 8.32 ppm, and 9.98 μg/m3, respectively, for the period of 2000-2019. What is interesting to note is the fact that the three variables have different spatial distributions thereby indicating potentially more important involvement in COVID-19 based on recent research showing increased vulnerability due to PM2.5 pollution in COVID-19 patients [57] and CDC’s indication that “people with moderate to severe asthma may be at higher risk of getting very sick from COVID-19.”
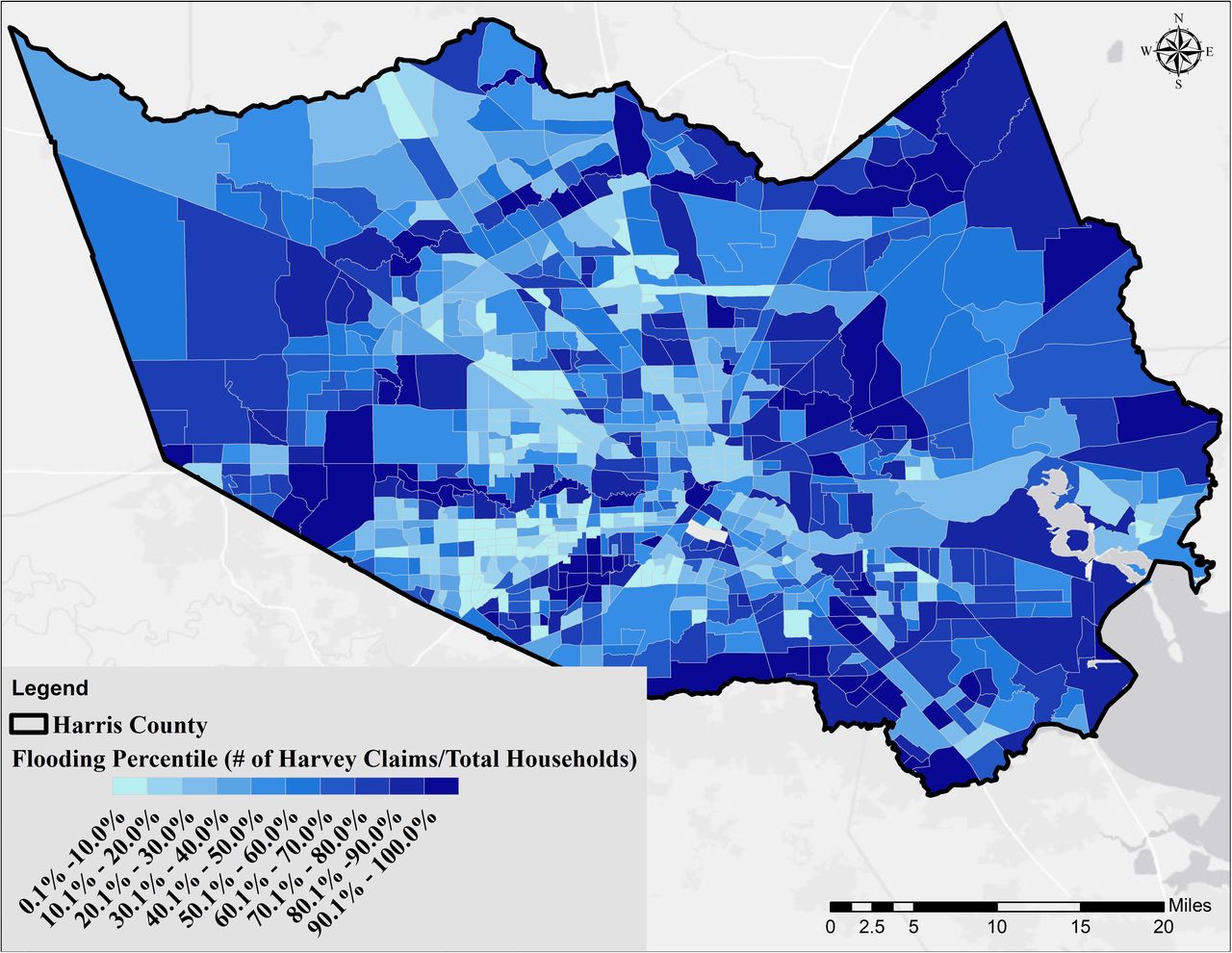
Contaminant discharge events (S4 Fig) and the second environmental variable representing dry cleaners, petroleum storage tanks, and IHWCA sites (S5 Fig) were substantially higher in industrial areas close to the HSC and GB: La Porte, Baytown, Deer Park, and Channelview, with the number of events as high as 1,449 (2000-present). The median was 12 events across all census tracts. Fig 5 shows the percentile of flooding across Harris County based on the filed claims to FEMA. Areas closer to the bayous/streams and flood control dams showed a higher vulnerability. A similar distribution was observed using the geospatial inundation modeling approach (S6 Fig). Finally, S7 Fig shows the distribution of educated persons in Harris County, defined as the ratio of age 25 years and over with a high school diploma or higher degree to the total population for each census tract.

Vulnerability in Census Tracts
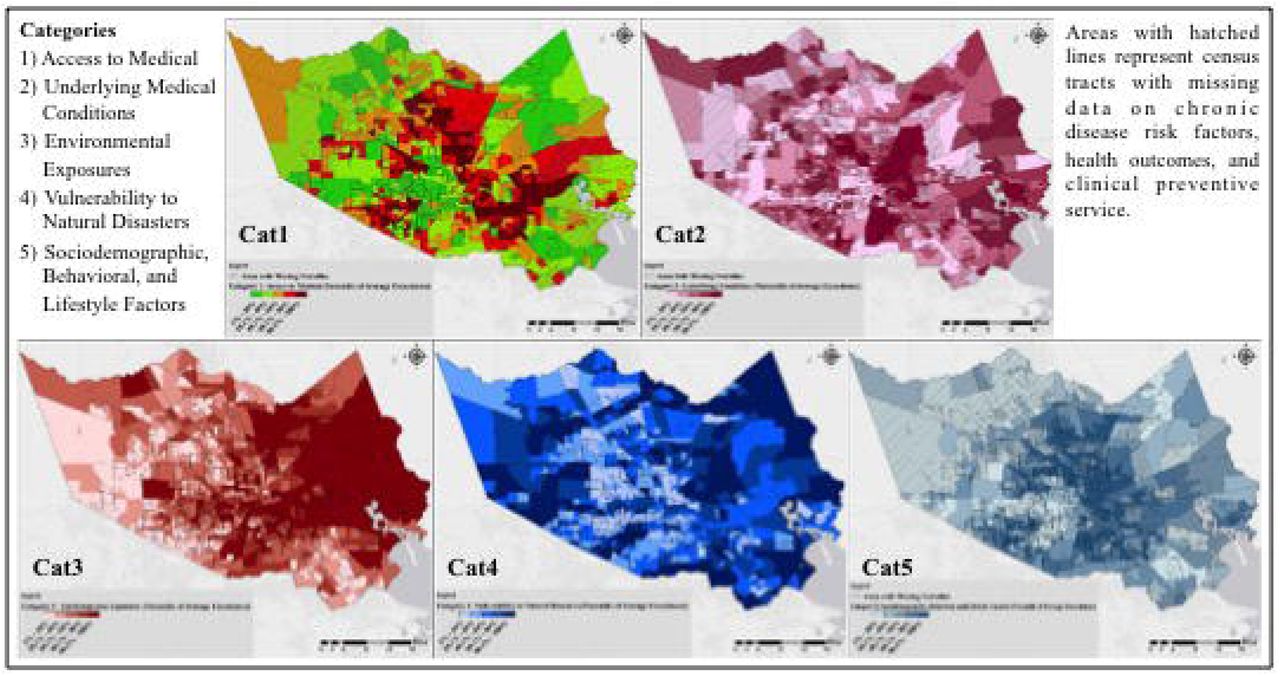
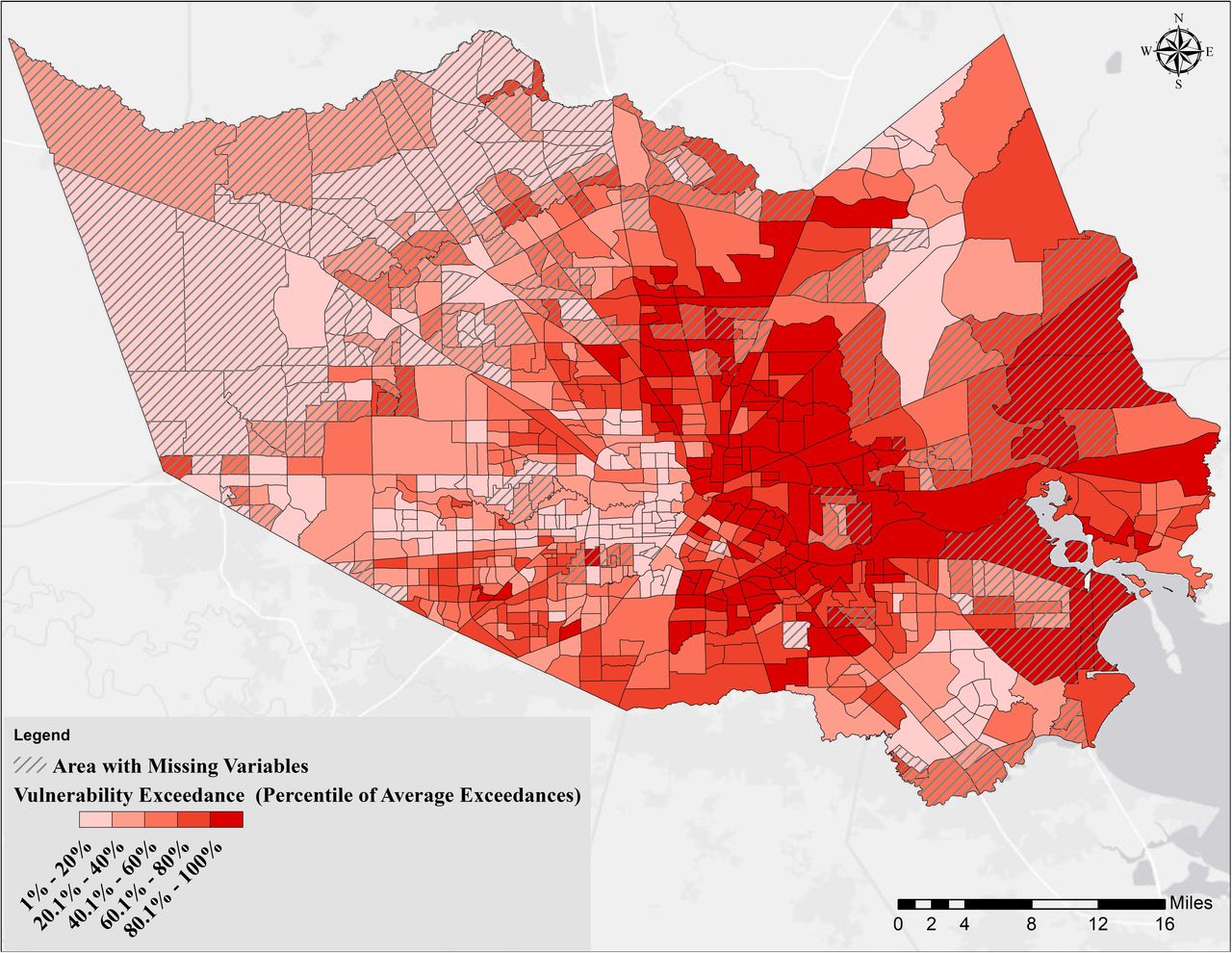
Fig 6 represents the average exceedance for variables within Category 1 through Category 5 (values are reported in percentiles for the purpose of comparison among tracts), respectively, and Fig 7 shows the overall vulnerability for all variables in the five categories. Overall, the vulnerabilities associated with each Category exhibited varying geospatial distributions with some commonality (i.e., some census tracks had elevated vulnerabilities in each Category). Category 1, 2, and 5 vulnerabilities shown in Fig 6 (access to medical, underlying medical conditions, and sociodemographic, respectively) indicated a similar finding; the most severe vulnerability can be observed in areas with the least favorable conditions represented by the three categories (lowest income, lower education levels, less insurance coverage, unhealthy diet and lifestyles, and more underlying medical conditions). Category 3 (Vulnerability to Environmental) showed a spatially declining gradient from east to west with some hotspots around downtown Houston. This gradient could be explained by the presence of the majority of industrial activities in the eastern part of Harris County, and worse air quality near downtown Houston. Category 4 (vulnerability to natural disasters) showed the highest risk in the vicinity of major bayous/streams in the County, as discussed before.


Looking at Fig 7, it could be concluded that the most vulnerable persons to COVID-19 in Harris County, are living in the eastern part of the County, specifically areas next to the HSC and GB, and areas identified as opportunity zones [58]. The residents in these neighborhoods are individuals with the least favorable sociodemographics, are exposed to several chemicals (with industrial sources), and subject to flooding both from rainfall and storm surge (such as what was experienced during Hurricane Ike in 2008). Individuals living in the western and southeastern fringe of the County are least vulnerable. However, it is noted that the underlying medical condition data were not available for those tracts. It is also noted that individuals in those areas, if infected, especially in the western fringe, will have significantly limited access to medical facilities compared to the other parts of the County.
The developed tool can be used to look at the tracts individually and compare their vulnerability with other tracts. A spider chart, for example, enables users to look at all five categories at the same time and determine which category has the most influence on vulnerability within a given tract; S8 Fig shows the status of the tracts with the highest and lowest overall vulnerability in each category.
The final cluster centers for different variables for each category (K-means method) are represented in the S3 Table. S9-S13 Figs show the class of each tract (i.e., high/severe, average, and low) for Category 1 through Category 5, respectively. The results in all categories were similar to the exceedance methods, validating the choice of methodology. The overall vulnerability generated by the K-means methods led to a very similar map (S14 Fig) to the exceedance approach (Fig 7).
Vulnerable Population Estimates in Harris County
For each category, the total population and the distribution of population in two age intervals, 45-65 (the age group with the highest number of reported COVID-19 cases), and +65 (the age group with the highest mortality rate), over different percentiles (from low to high with regards to the severity of conditions within each category) is shown in Table 3. Using the vulnerability findings presented above for Harris County (Fig 6, and yellow highlighted values in Table 3); a total of 59,307, 98,702, 78,723, 105,431, and 59,624 seniors (+65 years), who are at most risk of COVID-19 mortality, are living in areas with the highest vulnerability in Category 1 through 5, respectively. Considering the fact that Harris County is prone to flooding and the hurricane season is in progress from May through the end of November, a potential hurricane combined with the COVID-19 pandemic could lead to a compound natural disaster event affecting significant numbers of senior citizens as shown in Table 3. Decision-makers, to prepare for the worst-case pandemic scenario and occurrence of a hurricane, in particular, could use the numbers in Category 1 and 4 for planning response and recovery measures that take into account flooding and increased vulnerability to COVID-19. For overall vulnerability (Fig 7 and cyan highlights in Table 3), a total of 722,357 persons (~17% of the population of the County) including 171,403 with ages between 45-65 (~4% of the total population of Harris County), and 76,719 seniors (~2% of the population of the County), are at a higher overall risk.
Vulnerability Association with Morbidity, Hospitalization, and Mortality
Fig 8 presents the geospatial distribution of averaged vulnerability across Categories 1 through 5, morbidity, mortality, and death estimates. The calculated morbidity rates, using NYC estimates [49], across the County, are shown in Fig 8B. This worst-case scenario would lead to a total estimated number of 70,018 COVID-19 cases with a morbidity rate of ~ 552 cases per 100,000 population (this is substantially higher than the reported cases to date of 5,330 as of April 23rd, 2020 [48]). There are 452,327 senior residents living in Harris County (10.3% of the total population). Among the seniors, for the NYC worst-case scenario, a total of 12,267 (2.71% of seniors and 0.28% of the total population) could be infected with COVID-19. By comparing the morbidity (age-based) and vulnerability results, as shown in Fig 8A and B, it could be concluded that ~ 10.0% of the total population and ~16% of seniors at the highest risk level (80%-100% percentile overall vulnerability) could contract COVID-19. While the actual morbidity rates in Harris County, to date, are lower than New York, China, and Italy, the specific reasons for this are unknown. This could be due to lower population density, relatively higher temperatures, or the fact that New York, China, and Italy had earlier reported and imported cases than Harris County, and social distancing was not deployed immediately or soon after. As mentioned previously, one caveat that places greater uncertainty for Harris County reported rates is the fact that Texas is listed as the 46th state in terms of rates of testing (~542 per 100,000 population as of this writing [47]).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Estimating hospitalizations based on age distributions and hospitalization rates reported by CDC [50] resulted in a total of 672 hospitalized patients (S15 Fig) and a rate of 15.37 per 100,000 population over the County (this estimate is also in excess of the reported data for Harris County on a daily basis that is between 7.86 and 9.84 per 100,000 persons (obtained by dividing the current day number of hospitalized patients to the total population, [48]). A worst-case scenario using NYC data leads to 16,200 hospitalizations and a rate of ~366 per 100,000 persons (S16 Fig). As shown in S16 Fig, the highest rate of hospitalization is predicted for the northeast and northwest parts of Harris County, where people have the least access to medical facilities (Fig 3) and are prone to flooding (Fig 5).
Fig 8C (based on [51]) and S17 Fig (based on [52]) show the calculated mortality rates in Harris County census tracts. The average mortality rates (ratio of the number of total deaths to the number of confirmed COVID-19 cases) in Harris County, calculated based on the rates from China [51] and Italy [52] were 1.39% and 1.28%, respectively, which are both lower than the current rate of 1.54% in the County. Fig 8D shows the total deaths estimated in individual tracts in Harris County based on the rates reported by the New York Department of Health and Mental Hygiene [49]. A total of 4,020 deaths with a rate of 92.65 per 100,000 persons were estimated based on the age distribution (this is higher than the reported 82 deaths in Harris County as of April 23rd, 2020).
Limitations
A number of limitations are noted that should be considered when interpreting these results. First, data was lacking for some of the variables for a number of census tracts in Harris County; the CDC’s 500 Cities dataset [41] is such an example. The analysis findings might change if a Houston-specific dataset is used. However, the downside is that the approach would not incorporate County level considerations. Second, and most important (this generally is true of numerous other COVID-19 studies), granular sub-county data about COVID-19 cases, hospitalizations, and deaths are lacking (at the zip code or census tract levels). It would be essential to have such granularity to validate/compare projections based on determinants against actual morbidities and mortalities. Using morbidity, hospitalization, and mortality rates reported in other regions places undue levels of uncertainty in the findings that would be substantially reduced when such data are available, or a national surveillance system [60] is in place.
Conclusions
In this novel project, we develop a planning tool that can help identify populations at higher risk of infection, morbidity, and mortality from COVID-19 at the census tract level. These findings can guide the allocation of scarce resources, and thus, are relevant to policymakers at all levels of government. Effectively using the results from the planning tool to inform actions could mean the difference between suppressing the virus and allowing it to re-emerge. Studies, for example, would be needed to validate projections and findings. However, to do so, sub-county incidence, hospitalization, and mortality data describing COVID-19 cases in Harris County would be needed. In comparison, it is noted that studies that map the geospatial spread of coronavirus from Wuhan to neighboring communities are starting to emerge [59,60], and similar efforts need to be launched in the US. The application of geospatial methods to case data, enables significantly more rigor in understanding the confluence of various factors that jointly increase vulnerabilities and reduce resilience to COVID-19 spread, impact, re-emergence in new hot spots or on a seasonal basis. While geospatial indices exist [61,62], they are not tailored to the unique features of this virus. Lastly, the findings from geospatial analyses such as this study enable public health departments to efficiently and equitably allocate resources such as testing, contact tracing, and medical interventions to areas in greatest need.
Competing Interests
The authors have no competing interests.
Supporting information
S1 Fig. Map showing the median of averaged 8-hr concentration of Ozone (ppb) in Harris County. The yellow dots show the location of air quality monitoring stations maintained by the TCEQ. The magnitude of the dots shows how many times the averaged 8-hr ozone concentration in a specific station exceeded the 70 ppb standard established by EPA from 2000-2019
S2 Fig. Map showing the median of hourly concentration of NO2 in Harris County. The yellow dots show the location of air quality monitoring stations maintained by TCEQ. The magnitude of the dots shows how many times the hourly NO2 concentration in a specific station exceeded the 100 ppb standard established by EPA from 2000-2019
S3 Fig. Map showing the median of averaged daily concentration of PM2.5 in Harris County. The yellow dots show the location of air quality monitoring stations maintained by TCEQ. The magnitude of the dots shows how many times the averaged daily PM2.5 concentration in a specific station exceeded the 35 μg/m3 standard established by EPA from 2000-2019
S4 Fig. Map showing the sum of reported environmental release events from 2000-2020 and leaking petroleum tanks within each census tract
S5 Fig. Map showing the second environmental variable, which is the sum of the number of dry cleaners, petroleum tanks, and sites that are part of an Industrial and Hazardous Waste Corrective Action (IHWCA) program defined by the TCEQ within each census tract
S6 Fig. Map showing flood vulnerability based on the inundation method
S7 Fig. Map showing the percentage of age 25 years and over to the total population in each census tract with a high school diploma or higher degree
S8 Fig. The averaged exceedance in the 5 categories for the tracts with the highest and lowest overall vulnerability (highest averaged exceedance in 5 categories) within Harris County
S9 Fig. Results of the K-means cluster analysis. Different colors reflect the belongingness of tracts to the three classes defined in the method for Category 1: Access to Medical (see Table 1 for more details). Areas with hatched lines represent census tracts with missing data on chronic disease risk factors, health outcomes, and clinical preventive service form [41]
S10 Fig. Results of the K-means cluster analysis. Different colors reflect the belongingness of tracts to the three classes defined in the method for Category 2: Underlying Conditions (see Table 1 for more details). Areas with hatched lines represent census tracts with missing data on chronic disease risk factors, health outcomes, and clinical preventive service form [41]
S11 Fig. Results of the K-means cluster analysis. Different colors reflect the belongingness of tracts to the three classes defined in the method for Category 3: Environmental Exposures (see Table 1 for more details)
S12 Fig. Results of the K-means cluster analysis. Different colors reflect the belongingness of tracts to the three classes defined in the method for Category 4: Vulnerability to Natural Disasters (see Table 1 for more details)
S13 Fig. Results of the K-means cluster analysis. Different colors reflect the belongingness of tracts to the three classes defined in the method for Category 5: Sociodemographic, Behavioral, and Lifestyle Factors (see Table 1 for more details). Areas with hatched lines represent census tracts with missing data on chronic disease risk factors, health outcomes, and clinical preventive service form [41]
S14 Fig. Results of the K-means analysis method. The graduated colors reflect the percentile of the overall vulnerability. Areas with hatched lines represent census tracts with missing data on chronic disease risk factors, health outcomes, and clinical preventive service form [41]
S15 Fig. Number of potential hospitalized COVID-19 patients based on age distribution and rates reported by the CDC [50]
S16 Fig. Number of potential hospitalized COVID-19 patients based on age distribution and rates reported by the New York Department of Health and Mental Hygiene [49]
S17 Fig. The mortality rate for each census tract based on age and sex distribution. Rates associated with each age interval were extracted from [52]
S1 Table. Rotated component matrix from the Principal Component Analysis. Varimax with Kaiser Normalization was chosen as the rotation method. Highlighted values show values greater than 0.5 or the maximum among the components
S2 Table. Descriptive summary statistics for all 46 variables. Median and median absolute deviation are reported instead of mean and standard deviation because none of the datasets were normally distributed
S3 Table: Results of the K-Means analysis: final cluster centers for different variables at each category
Acknowledgments
This research was funded by the Hurricane Resilience Research Institute (HuRRI), an interdisciplinary research institute at the University of Houston focused on resilience to natural disasters and RAPID grant # 1759440 and grant # 1840607 from the National Science Foundation. Their support is gratefully acknowledged.
References




Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
1
Blogs/Media
Author Videos