
Abstract
Suppressing SARS-CoV-2 will likely require the rapid identification and isolation of infected individuals, on an ongoing basis. RT-PCR (reverse transcription polymerase chain reaction) tests are accurate but costly, making regular testing of every individual expensive. The costs are a challenge for all countries and particularly for developing countries. Cost reductions can be achieved by pooling (or combining) subsamples and testing them in groups. We propose an algorithm for pooling subsamples based on the geometry of a hypercube that, at low prevalence, uniquely identifies infected individuals in a small number of tests. We discuss the optimal group size and explain why, given the highly infectious nature of the disease, largely parallel searches are preferred. We report proof of concept experiments in which a positive subsample was detected even when diluted a hundred-fold with negative subsamples. Using these methods, the costs of mass testing could be reduced by a large factor. If infected individuals are quickly and effectively quarantined, the prevalence will fall and so will the cost of regular, mass testing. Such a strategy provides a possible pathway to the longterm elimination of SARS-CoV-2. Field trials of our approach are now under way in Rwanda.
I. INTRODUCTION
SARS-CoV-2 represents a major threat to global health. Rapidly identifying and quarantining infected individuals is one of the most important available strategies for containing the virus. However, each diagnostic SARS-CoV-2 test costs 30-50 US dollars [1]. Therefore, testing every individual regularly, as may be required to eliminate the virus, is expensive. The costs are unaffordable for most low-income countries, which have limited available resources for massive SARS-CoV-2 testing. It is therefore important to ask: are there more efficient ways to find infected people?
The first step in testing, swab collection, is labour intensive but does not require expensive chemicals or equipment. It may therefore be feasible to collect swabs regularly from everyone. The next step involves RT-PCR machines [2]. These require expensive chemical reagents, currently in short supply, as well as skilled personnel. Reducing the cost requires that we minimize the total number of tests. Testing rapidly is also vital because SARS-CoV-2 is so infectious. Each RT-PCR test takes several hours in the lab, time during which the virus can spread [3].
To find infected individuals, the naive approach is to test everyone. This requires one test per person. However, far fewer tests are actually needed, especially at low prevalence where it is much more efficient to pool (or combine) samples and test them together. This idea of group testing dates back to a paper of Dorfman in 1943 [4] (see [5]). Dorfman’s algorithm reduces the number of tests per person, required to find all infected individuals, to  at low prevalence p (see Appendix A). The algorithm we present represents a substantial improvement, requiring only ≈ ep ln(1/p) tests per person at low p, where e = 2.718 … is Euler’s number. Measurements in Iceland, early in the pandemic gave p ≈ 0.8% [8]. Recently, in England, following months of lockdown, the prevalence has been estimated (in private-residential households) at a much lower value, p ∼ 0.05 − 0.12% (95%CI) [9]. For p = 0.1%, Dorfman’s strategy yields a cost savings of over 15, while ours achieves over 50. If the prevalence is reduced, these relative cost savings will grow even further. Group testing is therefore rightly attracting renewed interest as countries prepare for widespread SARS-CoV-2 testing in order to contain the outbreak. The Government of Rwanda, in particular, has adopted group testing as a national strategy. All passengers on flights entering or leaving Rwanda must now be tested locally. In order to fly, they must have received a negative test result within the past 72 hours. These tests are being made affordable through group testing.
at low prevalence p (see Appendix A). The algorithm we present represents a substantial improvement, requiring only ≈ ep ln(1/p) tests per person at low p, where e = 2.718 … is Euler’s number. Measurements in Iceland, early in the pandemic gave p ≈ 0.8% [8]. Recently, in England, following months of lockdown, the prevalence has been estimated (in private-residential households) at a much lower value, p ∼ 0.05 − 0.12% (95%CI) [9]. For p = 0.1%, Dorfman’s strategy yields a cost savings of over 15, while ours achieves over 50. If the prevalence is reduced, these relative cost savings will grow even further. Group testing is therefore rightly attracting renewed interest as countries prepare for widespread SARS-CoV-2 testing in order to contain the outbreak. The Government of Rwanda, in particular, has adopted group testing as a national strategy. All passengers on flights entering or leaving Rwanda must now be tested locally. In order to fly, they must have received a negative test result within the past 72 hours. These tests are being made affordable through group testing.
Dorfman’s algorithm requires two rounds of testing – the first in which groups are tested, and the second in which every member of every positive group is then tested. Our algorithm involves a similar round of group tests although the optimal group size is larger. The second round consists of “slicing tests” conducted on the positive groups. Usually, this second round suffices to identify all infected individuals without any individual tests being performed. For less than one positive group in ten, one more round of slicing tests is needed. We shall compare our approach with other approaches in some detail. There are algorithms which require fewer tests, but which involve many, adaptive rounds of testing. Every extra round consumes significant time, during which the viral prevalence grows. We show that, for this reason, adaptive searches are disfavoured at low prevalence (see Section VI and Appendix B). There are also non-adaptive algorithms which require, in principle, only one round of testing and hence are faster than ours or Dorfman’s. However, they have a significantly higher failure rate for a comparable number of tests (see Appendix C).
Group testing is most obviously effective when there are no infected individuals in the group: just one test suffices to show that no-one is infected. Our algorithm takes full advantage of this powerful result. In the first round of tests, subsamples from all group members are pooled and tested together. As we shall show, the optimal group size N ≈ 0.35/p: the expected number of infected individuals in a group is 0.35 and a group will test negative over 70% of the time. Groups that test positive are passed on to the first round of slicing tests, which we now describe.
II. WHEN ONE MEMBER OF A GROUP IS INFECTED
Consider the case where only one member of the group is infected. The idea behind our algorithm is geometrical: the group of individuals to be tested is represented by a set of N points on a cubic lattice in D dimensions, organized in the form of a hypercube with L points on a side, so that

Instead of directly testing the samples taken from every individual, we first divide each of them into D equal subsamples. These DN subsamples are recombined as follows. Slice the hypercube into L planar slices, perpendicular to one of the principal directions on the lattice. Form such a set of slices in each of the D principal directions and pool the LD−1 subsamples corresponding to each slice. Altogether, DL slices, each slice combining N/L = LD−1 subsamples, are tested in parallel, in a round of slicing tests. If there is one infected individual, then one slice out of the L slices, in each of the D directions, will yield a positive result. That slice indicates the coordinate of the point corresponding to the infected individual, along the associated principal direction.
Therefore the number of tests required to uniquely identify the infected individual is
 where we used (1). Treating D as a continuous variable, the right hand side of (2) diverges at both small and large D, possessing a minimum at
where we used (1). Treating D as a continuous variable, the right hand side of (2) diverges at both small and large D, possessing a minimum at
 corresponding to L = e and a total of e ln N trials. In reality, D and L must be integers, but using L = 3 achieves almost the same efficiency (in the total number of trials, e is replaced with 3/ ln 3 ≈ 2.73, less than half a per cent larger, whereas using L = 2 or 4 gives 2/ ln 2 = 4/ ln 4 ≈ 2.89, more than 5 per cent larger). With no further constraint, finding one infected person in a population of a million, using L = 3, requires only 39 tests, performed in one round of testing. (To see this, note that 313 > 106, so a hypercube of side L = 3 in dimension D = 13 contains over a million points. A round of slicing tests on this hypercube consists of DL = 13 × 3 = 39 slice tests.)
corresponding to L = e and a total of e ln N trials. In reality, D and L must be integers, but using L = 3 achieves almost the same efficiency (in the total number of trials, e is replaced with 3/ ln 3 ≈ 2.73, less than half a per cent larger, whereas using L = 2 or 4 gives 2/ ln 2 = 4/ ln 4 ≈ 2.89, more than 5 per cent larger). With no further constraint, finding one infected person in a population of a million, using L = 3, requires only 39 tests, performed in one round of testing. (To see this, note that 313 > 106, so a hypercube of side L = 3 in dimension D = 13 contains over a million points. A round of slicing tests on this hypercube consists of DL = 13 × 3 = 39 slice tests.)
III. PROOF OF CONCEPT
In practice, we are limited by the capacity of the testing machine. A typical swab yields 105 viral RNA molecules/ml [10]. For each slice of the hypercube, we combine N/L subsamples of the virus, each of volume v. If the volume of each combined sample, V = Nv/L, exceeds the capacity of the PCR we will have to only use a portion of it. We should also keep in mind that at least one viral RNA is needed for an unambiguous result, and we must remain well above this limit.
Setting L = 3 and N = 3D, we find

For example, if V/υ = 100 then (4) yields D ≈ 5, from which (3) yields N = 243. If υ is a microliter, then V is 100 microliters. In a positive combined sample, there would be 100 viral RNA molecules. Even if only 10 microliters are used in the PCR machine, it would contain 10 viral RNA molecules, sufficient for a positive result. The typical number of tests required to find the infected individual is then only 3 ln N ≈ 17, a 14-fold improvement in efficiency over naive testing.
Note that the viral load found in a swab specimen is relatively low if collected during the early stages of viral replication [10]. Therefore, swabs taken during this period may contain insufficient virus to yield a positive result. The sensitivity of the test is typically increased by testing specimens collected at sequential time points. Methods like the one we describe here facilitate such sequential testing on a massive scale by drastically reducing the associated costs. In view of the large potential efficiency gains, it is worth exploring whether testing machines could be engineered to accommodate larger test volumes V.
As a proof of concept, using oropharyngeal swab specimens collected during COVID-19 surveillance in Rwanda, we investigated whether known positive specimens still test positive after they are diluted 20-, 50-, or 100-fold (i.e., V/υ = 20, 50, 100), through pooling with negative specimens (see Appendix I). We used a RT-PCR test targetting the N and Orf genes of SARS-CoV-2, which is used routinely for diagnostic screening for COVID-19 in Rwanda. The test is considered to be positive if PCR amplification of both target genes produces an above-background fluorescence signal at a PCR cycle number, i.e., a Ct value, that is ≤ 40. Our key finding is that positive specimens can still be detected even after they are diluted up to 100-fold (see Fig. 2). (For recent experiments demonstrating positive sample detection after 30- and 32-fold dilution, see Refs. [11, 12]). As a consistency check, we determined the change in Ct value (ΔCt) that occurs when going from a 50- to a 100-fold dilution. In a perfectly efficient PCR test, the number of target molecules is expected to double after each PCR cycle. Therefore, the 100-fold diluted positive sample in principle requires one more cycle of PCR amplification than the 50-fold diluted sample, to produce the minimum number of target molecules needed to yield an above-background fluorescence signal. This implies that ΔCt ≈ 1.0. Consistent with this expectation, we find that, on average ΔCt ≈ 1.0 (s.e. 0.15), for the N gene, and ΔCt ≈ 1.1 (s.e. 0.14), for the Orf gene. The changes in Ct values for the other dilutions are consistent with this interpretation.
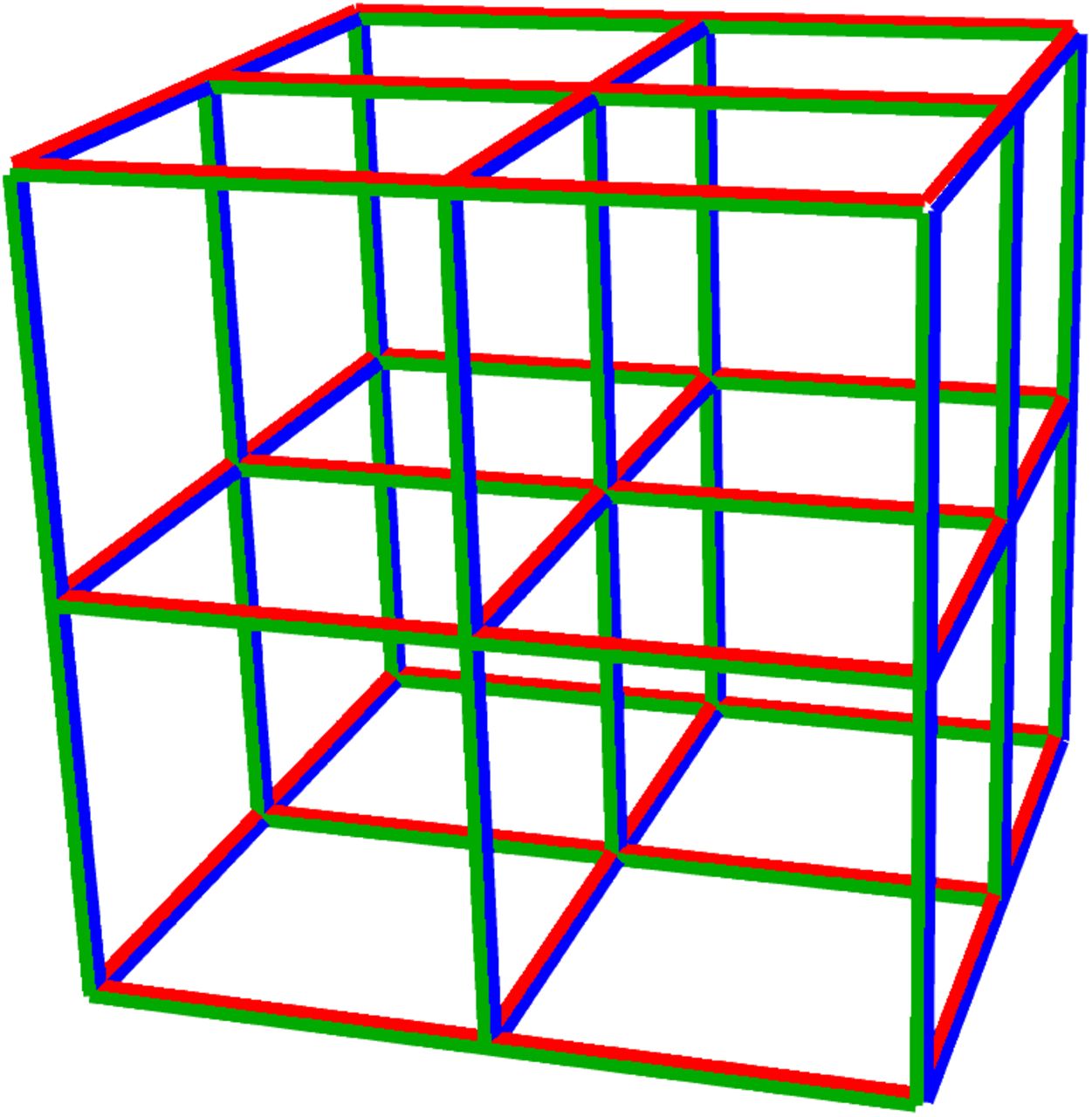
Illustration of subsample pooling in the hypercube algorithm, for D = L = 3 and N = 27 = 33. Each vertex represents an individual. The hypercube is sliced into L slices, in each of the D principal directions. Samples from N/L individuals are pooled into a sample for each slice. For this example, the 3 sets of slices are shown in blue, red and green. If one infected individual is present, tests on each set of slices identify their coordinate in that direction. Hence only 9 tests uniquely identify them. As the viral prevalence falls, the optimal group size N and dimension D grow, and the efficiency gain rises.
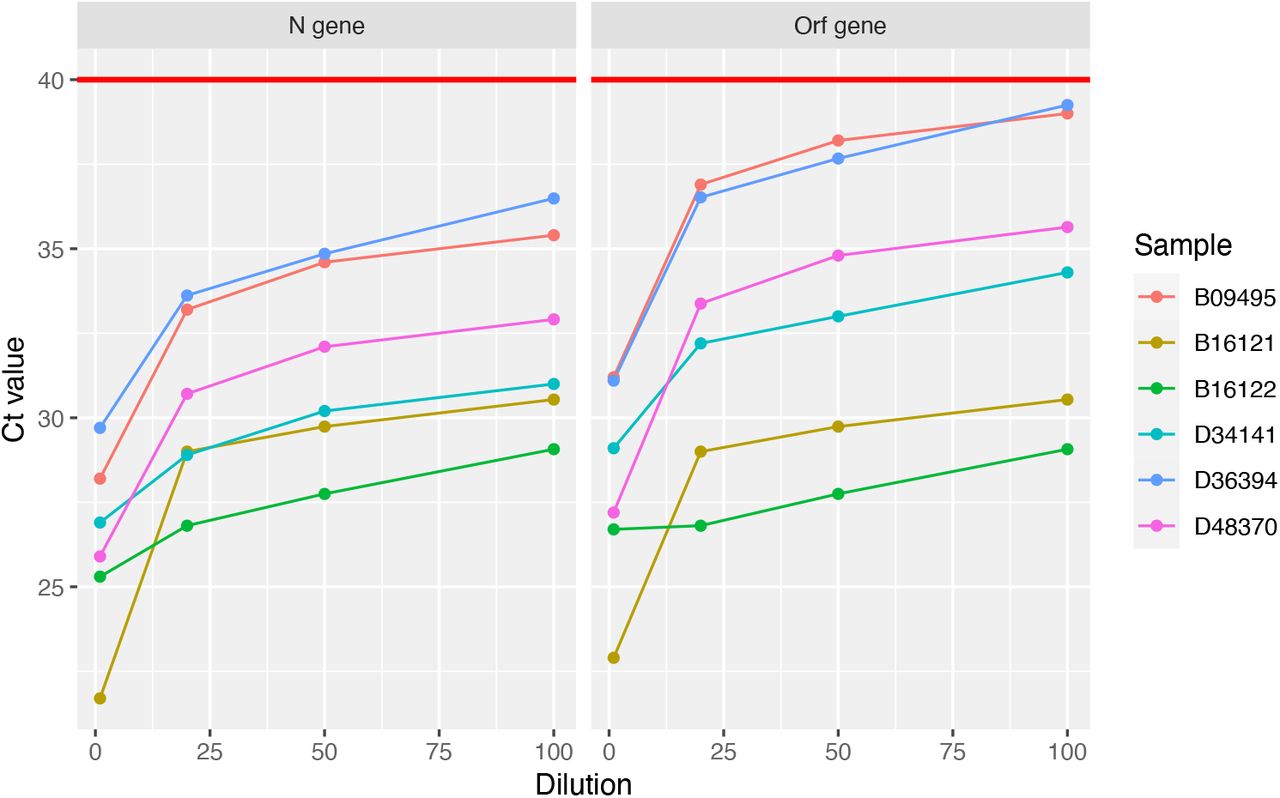
Each of six SARS-CoV-2-positive specimens was diluted through pooling with 19, 49, or 99 negative specimens. A Ct value (i.e. the PCR cycle at which the fluorescence signal generated by a specimen exceeds the baseline signal) was determined for each pool through RT-PCR amplification of the N and Orf genes of SARS-CoV-2. For each gene, the Ct values are plotted (on the y-axis) against the dilution factor (on the x-axis). The red horizontal lines indicate the Ct value (40) at or below which a pool is considered positive. All Ct curves stay below the red lines even as the positive specimens are diluted up to 100-fold. See Appendix C for further experimental details.
Using the measured values of ΔCt together with the Ct values of a representative sample of positive specimens identified during clinical screening for COVID-19 in Rwanda, we estimated a 95% confidence interval for the Ct values expected after a 20-, 50-, or 100-fold sample dilution (see Appendix I). Interestingly, for the N gene, we find that a 100-fold dilution produces Ct values with an upper 95% confidence bound of 37.6, below the threshold for positive samples (i.e. Ct = 40). In contrast, for the Orf gene, while the upper 95% confidence bound for Ct values expected after a 50-fold dilution (39.6) is below 40, the corresponding bound for Ct values expected after a 100-fold dilution (40.6) is not. The latter upper confidence bound drops below 40 when the confidence level is reduced to 90%. Together, these results indicate that the RT-PCR test used for diagnostic screening for COVID-19 in Rwanda retains a high sensitivity of ≥ 90% if a positive sample is pooled with up to 99 negative samples.
Sample pooling is now used for cost-effective, large scale testing in Rwanda to understand the spatial spread of SARS-Cov-2 nationally, to quickly identify new infections and to enable a rapid response by public health officials. For example, using sample pooling, we recently screened 1,280 individuals using only 64 tests, a 20-fold efficiency gain compared to naive testing (see Figures 5 and 6 in Appendix I). The cost was thereby reduced to around 3,200 US dollars. Note that, if we had used a single round, non-adaptive testing algorithm (such as the DD algorithm described in Appendix C), assuming a prevalence of 2%, the total cost (based on the best information rate achieved by the DD algorithm) would have been at least 12,900 US dollars. By spending 3 hours checking whether an infected sample was indeed present, more than 9,700 US dollars was saved. Of course, as the number of rounds of testing increases, the cost of delays might eventually offset any accrued savings. The best testing strategy is one that achieves an optimal balance between speed and efficiency.

The expected number of tests per person to find all infected individuals using the hypercube algorithm (log-log plot). The dashed grey curve shows the result ep ln(0.734/p) for the optimal group size N ≈ 0.35/p, obtained in large D approximation (see Appendix B). The coloured curves show the results obtained from a detailed analysis when the group size N = 3D with D an integer (see Appendices D–G). Where 0.35/p is an exact power of 3, as at the left end of each coloured curve, optimal performance is attained. As p is increased, a growing fraction of sites in the 3D hypercube are left empty, until the next exact power of 3.

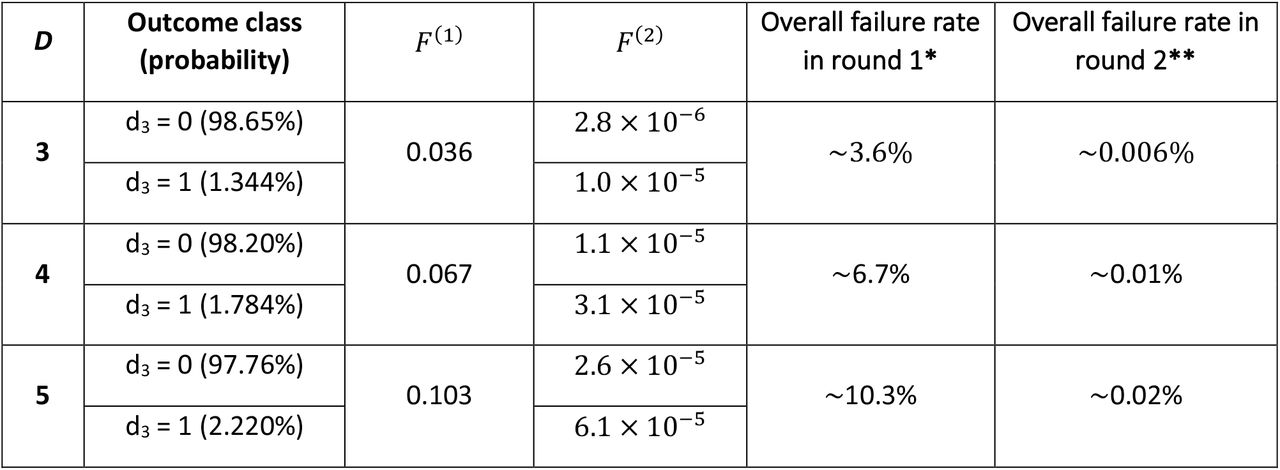
for D = 3, 4, 5. When λ(1) = 0.35, one round of slicing tests suffices to find all infected samples in ≈ 96.4%, 93.3% and 89.7% of cases, for D = 3, 4 and 5 respectively. Hence the hypercube algorithm is largely parallel. Clarifications: ∗ This is the probability that the first round of slicing tests yields σ > 1 in more than one direction. ∗∗ This is an upper bound on the probability that positive samples may remain unidentified after the second round. Because F (2) is so small for d3 = 0 and d3 = 1, the reported value is effectively the probability that d3 > 1. With some effort, our analysis could be extended to d3 > 1, and to a third round of slicing tests, to further reduce the bound on the failure rate.

for D = 3, 4 and 5, in the working example presented in Section V. Also shown is the “rate” of the search, defined in Ref. [16] as the information gained per test, in bits. Note that for the hypercube algorithm, this rate increases as D falls, even exceeding that for one of the best non-adaptive algorithms known in the computer science literature (See Appendix C for discussion).

Each of 64 the sample pools described in the text tests negative for SARS-CoV-2: the RT-PCR fluorescence curves show below-threshold net fluorescence values. In contrast, for both target genes of the positive control, the fluorescence curves cross the threshold after 32 PCR cycles. ΔRn denotes the difference between the fluorescence signal generated by a sample and a baseline signal. The yellow curves reaching ΔRn ∼ 2, 000, 000) and 1, 750, 000 represent the positive control for the N and Orf genes, respectively. The other yellow and orange curves represent internal controls.
IV. WHEN MORE THAN ONE MEMBER OF A GROUP IS INFECTED
So far, we have assumed only one member of the group is infected. But what if 2, 3 or more members are infected? In normal circumstances, all we will have is an estimate of the prevalence p of the virus in the population from which the group has been drawn, i.e., the probability that a person chosen at random is infected. A feature of group testing is that the first round of group tests, relatively few in number, allows us to conveniently update our knowledge of p, even before any infected individuals have been identified (see Appendix H).
Given p, the probability that k members of a group of size N are infected can be described by a Poisson distribution with mean λ = pN. For λ well below unity, the probability falls rapidly with increasing k. As we shall see, this is the regime in which our algorithm operates optimally. At very low prevalence, the optimal N is very large, so D = logL N ≫ 1. The advantages of the hypercube algorithm are particularly obvious in this limit. Therefore, we describe the large D limit first before detailing the algorithm’s performance for realistic values of D.
The first round of slicing tests, as described in Section II, yield, for L = 3, a set of triples of zeros and ones, i.e., {1, 0, 0}, {1, 1, 0} or {1, 1, 1} and permutations thereof, for every principal direction of the lattice. Let σ be the sum of the three values (so σ = 1, 2 or 3) and dσ the number of directions in which the value σ occurs, so d1 + d2 + d3 = D. For D ≫ 1, the number of infected individuals k may be accurately inferred from the observed values of dσ, even before any infected individuals are identified. Knowing k, we then find all infected individuals as follows:
If k = 1, then d1 = D. Each positive slice indicates the coordinate of the infected individual in that direction. Hence, the infected individual is identified in one round of slicing tests.
If k = 2, d2 > 0 but d3 = 0. If d2 = 1, the two infected individuals are immediately identified. If d2 > 1, we choose one of the directions with σ = 2, and treat the two positive slices as smaller hypercubes, each containing one infected individual. A further round of slicing tests identifies one of them and the other is found by elimination.
If k = 3 then, at large D, at least one direction has σ = 3. Choose one such direction and treat two of the positive slices as smaller hypercubes, each containing one infected individual. A slicing test on each identifies two infected individuals and the third is found by elimination.
If k > 3, the number of rounds of slicing tests required to identify all infected individuals is slightly larger than k (see Appendix B). However, for the optimal value of group size, the probability to have k > 3 infected members in a group is negligible.
Hence, in the large D limit, approximately k rounds of slicing tests are required to identify k infected individuals. In Appendix B we compute the expected total number of tests T. At low p the number of tests per person is minimised for a group size N ≈ 0.350/p. At the minimum, ⟨T ⟩/N ≈ ep ln(0.734/p) which is plotted as the dashed grey line in Fig. 3. The inverse of this number is the efficiency gain relative to naive testing.
For practical applications, we are interested in the efficiency of the algorithm at modest values of D such as 3, 4 or 5. This requires a more intricate analysis, the details of which we relegate to a set of Appendices D-G. However, some simple and general statements may be made. First, when all directions yield σ = 1, only one individual is infected and they are immediately and uniquely identified. This is the most probable outcome of a slicing test. Second, when σ > 1 in only one direction then, if σ = 2, two infected individuals are uniquely identified and for σ = 3 three infected individuals are identified, without the need for any further tests. If σ > 1 in more than one direction, we have to perform a second round of slicing tests. We can reduce the number of required tests by eliminating samples from any slice which tested negative in the first round. In effect, we work with a smaller hypercube, requiring significantly fewer slice tests. We make only one approximation in our analysis, namely we assume the infected samples are rare among the points in the hypercube. It is then an excellent approximation to treat them as independent, randomly chosen points (see Appendix D). Within this approximation, we have computed the probabilities for slice outcomes analytically and followed them through the second round of slice testing. Strikingly, we find that the hypercube algorithm performs better as D is decreased. For λ = 0.35 and D = 4, for example, in 93.3% of cases the slicing tests will end after one round with all infected individuals identified, as explained. For the remaining 6.7% of cases, one additional round of slicing tests suffices to reduce the failure rate to below 0.01% (see Appendix F). We calculate the expected total number of tests in Appendix G. For λ = 0.35 and D = 4, the expected number is 12.3, only marginally higher than DL. The expected number of tests per person, for D = 3, 4 and 5, are plotted in Fig. 3. Where 0.35/p is an exact power of 3, as at the left end of each coloured curve, optimal performance is attained. As p is increased, an increasing fraction of sites in the 3D hypercube are left empty, until the next exact power is reached. Nevertheless, pooling still results in a high efficiency gain.‡ From Fig. 3, it is evident that the large D approximation provides a surprisingly good (and very convenient) fit to the low D results.
V. A WORKED EXAMPLE
It may be helpful to present a worked example, such as might occur in a field trial. Suppose that we want to identify positive samples among 1,200 samples collected from a population in which the prevalence is estimated at p = 0.4%. We first pool subsamples into 15 groups of 80 members, so the expected number of positive samples in each group, λ = (0.004 × 1200)/15 = 0.32, is close to the optimal value of 0.35. We then conduct a single round of 15 tests to identify positive groups. Assuming Poisson statistics, we expect only 27% of the groups to test positive. If we obtain a very different result, we can revise our estimate of λ (see Appendix H) and, if necessary, re-group the samples before further testing. Assuming no re-grouping is needed, we place the 80 samples from each of the positive groups in hypercubes with L = 3 and D = 4. In 93% of cases, one round of slicing tests will suffice to identify all positive samples. In the remaining 7% of cases, a second round will find the rest, with a failure rate of less than 0.01%. The expected number of slicing tests per positive group is 12.2. Hence the total number of tests is 15 × (1 + 0.27 × 12.2) = 64.4, a cost saving, relative to naive testing, of nearly a factor of 20. Looking to the future, if the re-design of RT-PCR machines allows for the pooled testing of larger groups, and if p falls to 0.15%, the collection of 1,200 samples could be divided into 5 groups of 240 each (corresponding to λ = 0.36). We would then require only 5 × (1 + 0.30 × 15.4) = 28.2 tests to identify the expected 1.8 infected individuals. This represents a cost saving, relative to naive testing, of over 40.
VI. LARGELY PARALLEL SEARCHES ARE PREFERRED
As mentioned in the introduction, there are search methods which require fewer tests. However, they require more rounds of testing. For example, a binary search [13, 14] finds an infected individual in a group of size N in just log2 N tests, fewer by a factor of e ln 2 ≈ 1.88 than our hypercube algorithm. However, a binary search is adaptive, requiring an iterated sequence of tests. At low prevalence p, the optimal group size N scales as 1/p (see Appendix A) so a binary search takes ∼ log2(1/p) rounds of testing. For p = 0.4% (or 0.15%) a binary search takes 8 (or over 9) rounds of testing whereas a hypercube search takes 2 or at most 3 (see Appendix F). When considering a rapidly spreading infectious disease like COVID-19, saving time is critically important because infected individuals who are still at large can infect others. A parallel, or largely parallel, strategy such as ours reduces this risk. Each RT-PCR test takes several hours, to which must be added any time taken for subsample sorting and selection. So, multiple of rounds of testing would consume significant time. During this period, the prevalence p of the virus grows exponentially. The doubling time for the virus is somewhat uncertain but it has been estimated, using data from China [3], to be τ2 ≈ 2.4 days (a recent analysis gives τ2 ≈ 1.9 days for New York and 2.9 days for Los Angeles [15]). If each RT-PCR test takes τ days, the viral prevalence grows by  during an adaptive search. It follows that, at fixed τ/τ2, the adaptive algorithms do worse at low p. For example, if we assume that at most 3 rounds of adaptive RT-PCR tests may be performed in a working day, then τ = 1/3 day. For prevalences p below
during an adaptive search. It follows that, at fixed τ/τ2, the adaptive algorithms do worse at low p. For example, if we assume that at most 3 rounds of adaptive RT-PCR tests may be performed in a working day, then τ = 1/3 day. For prevalences p below  per cent, a largely parallel approach like ours is then preferred. Reducing the costs of staff and lab time also favours a largely parallel strategy. Non-adaptive, parallel search algorithms have also been extensively explored in the literature (see Ref. [16]). In Appendices C and G, we show in some detail how the hypercube algorithm outperforms one of the best of these, the DD algorithm with near-constant column weight. Finally, the hypercube algorithm allows for many consistency checks which help to reduce false positives or negatives. For example, if σ = 1 in only one direction, this is very likely to be a false-positive result. In contrast, binary searches rely on repeated testing of the positive sample, making errors harder to identify.
per cent, a largely parallel approach like ours is then preferred. Reducing the costs of staff and lab time also favours a largely parallel strategy. Non-adaptive, parallel search algorithms have also been extensively explored in the literature (see Ref. [16]). In Appendices C and G, we show in some detail how the hypercube algorithm outperforms one of the best of these, the DD algorithm with near-constant column weight. Finally, the hypercube algorithm allows for many consistency checks which help to reduce false positives or negatives. For example, if σ = 1 in only one direction, this is very likely to be a false-positive result. In contrast, binary searches rely on repeated testing of the positive sample, making errors harder to identify.
Implementing the hypercube testing strategy in the lab certainly poses challenges. To mitigate human error, the pooling of samples will need to be automated, specially for the second round of slicing tests where the test must be adapted to a greater extent. Our lab in Rwanda already employs a robot for pooling and we are developing custom software to guide lab procedures. A side benefit will be an ongoing update of the estimated prevalence (see Appendix H), among populations being tested. The incorporation of these mathematical technologies into biological laboratories is a welcome development from which many future benefits may accrue.
VII. CONCLUSIONS
The hypercube algorithm presented here offers, we believe, an attractive compromise between two critically important and competing objectives: minimising the total number of tests to reduce costs and maximising the speed of the testing process to reduce viral spread. We have demonstrated its viability experimentally for group sizes up to 100 and shown that, in principle, one can already achieve cost savings of almost a factor of 20 compared to naive testing (see Fig. 3), in no more than two rounds of slicing tests, with a failure rate of less than 0.01%. We pointed out the importance of increasing the sample volume in RT-PCR machines to enable pooled testing of larger group sizes. This could enable even greater cost savings at lower prevalence. In fact, the most striking consequence of our approach is how quickly the cost of testing the whole population falls, advances in RT-PCR machines allowing, with decreasing prevalence. This should incentivise decision-makers to act firmly to test, track and isolate in order to drive the prevalence down. Although mass testing is initially costly, maintaining a low prevalence and, indeed, eliminating COVID-19 will, with the implementation of group testing, become progressively more affordable.
Data Availability
Data presented in Appendix on Methods and Supplementary Information
Contributions
L.M., S.N. coordinated the experiments; P.N., T.N., E.N., M.S., C.M., D.N., M.N. contributed to patient recruitment and data collection from the community; P.N., Y.B., J.S., A.U., R.R., E.L.N., E.M., E.M., N.R., I.E.M., J.B.M., C.M.M. and E.U. contributed to laboratory RT-PCR test validation, data analysis and interpretation. W.N. and N.T. contributed to the theory.
Statistical analysis
Ct values were tested for normality by using the Shapiro-Wilk test. A confidence bound for a sample of n Ct values was calculated as  , where
, where  is the sample mean, s is the sample standard error, and
is the sample mean, s is the sample standard error, and  is an appropriate quantile of the Student’s t distribution with n − 1 degrees of freedom, df. A confidence bound for the sum of the means of two samples of Ct values of sizes n1 and n2, respectively, was calculated using the same formula, with
is an appropriate quantile of the Student’s t distribution with n − 1 degrees of freedom, df. A confidence bound for the sum of the means of two samples of Ct values of sizes n1 and n2, respectively, was calculated using the same formula, with  set to the sum of the individual sample means, s set to the sum of the individual sample standard errors, and df set to the smaller of n1 − 1 and n2 − 1. Statistical analysis was done using the R statistical computing environment (https://www.r-project.org/).
set to the sum of the individual sample means, s set to the sum of the individual sample standard errors, and df set to the smaller of n1 − 1 and n2 − 1. Statistical analysis was done using the R statistical computing environment (https://www.r-project.org/).
Ethics approval
Ethics approval was obtained from the Rwanda National Ethics Committee (Ref: FWA Assurance No. 00001973 IRB 00001497 of IORG0001100/20March2020) and written informed consents were obtained from the patients.
Data availability
All data are available from the corresponding authors upon reasonable request.
Acknowledgments
We thank the Rwanda Ministry of Health through RBC for stimulating discussions and correspondence. Kendrick Smith and Corinne Squire provided valuable encouragement and helpful references. Research at AIMS is supported in part by the Carnegie Corporation of New York and by the Government of Canada through the International Development Research Centre and Global Affairs Canada. Research at Perimeter Institute is supported in part by the Government of Canada through the Department of Innovation, Science and Economic Development Canada and by the Province of Ontario through the Ministry of Colleges and Universities.
Appendix A: Comparison with Dorfman
In a landmark paper in 1943, R. Dorfman considered the problem of searching for infected individuals by grouping (or pooling) samples. His approach remains influential (see, e.g., Refs. [17–20]). Consider a population of n individuals, broken up into groups of N members each. If the probability that any individual is infected (the prevalence) is p, the probability that a group is free of infection is (1 − p)N. Conversely, the probability that at least one member is infected is p′ = 1 − (1 − p)N. Dorfman’s strategy was to test all groups, and then to test every member of every infected group. The expected number of tests is then
 and the number of tests required per person is
and the number of tests required per person is

In the last step, we assumed that p ≪ 1. The number of tests per person is minimised when the group size  . The expected number of tests per person, at the optimal group size, is approximately
. The expected number of tests per person, at the optimal group size, is approximately  .
.
Let us compare these results with those obtained using our hypercube algorithm at large D. Assuming Poisson statistics for the number of infected individuals k in a group of size N, with λ = pN, the expected number of tests per person is given by
 where rk denotes the number of rounds of slicing tests, and e ln N is the number of tests in each round as explained in Section II. In the second, approximate equation, we have set rk ≈ k. For k = 1 − 3 this is exact, as explained in Section IV. For k > 3 more than k rounds may be needed. Let rk = k + ck where ck is the average excess number of rounds of slicing tests (and is nonzero only for k > 3). These numbers are tedious but straightforward to compute. The first few are:
where rk denotes the number of rounds of slicing tests, and e ln N is the number of tests in each round as explained in Section II. In the second, approximate equation, we have set rk ≈ k. For k = 1 − 3 this is exact, as explained in Section IV. For k > 3 more than k rounds may be needed. Let rk = k + ck where ck is the average excess number of rounds of slicing tests (and is nonzero only for k > 3). These numbers are tedious but straightforward to compute. The first few are:  . In any case, they turn out to be unimportant because the minimum of (A3) is dominated by contributions from lower k. Note that, in the large D approximation, we ignore any changes in the argument of the logarithm due to fewer than N tests sometimes being needed. These changes are unimportant at large D but become important at lower D and are carefully taken into account in Appendices D-G.
. In any case, they turn out to be unimportant because the minimum of (A3) is dominated by contributions from lower k. Note that, in the large D approximation, we ignore any changes in the argument of the logarithm due to fewer than N tests sometimes being needed. These changes are unimportant at large D but become important at lower D and are carefully taken into account in Appendices D-G.
The last expression in (A3) represents the approximation that the ck corrections are neglected. The first term diverges at small N, and the second diverges at large N. Thus, a minimum exists. It is located at λ = pN ≈ 0.350, independent of p. For such a small value of λ, contributions from k > 3 are strongly suppressed. One subtlety is that, at very low p, since N = λ/p, for the relevant values of λ the argument of the logarithm becomes very large, so its derivative with respect to λ becomes suppressed with respect to its value. This effect means that, for extremely small p, the derivative of the corrections can compete with the derivative of the logarithm. We have checked that only for p < 10−10 does this alter the minimum value of λ by more than 0.01. Hence, for all practical purposes, we can safely ignore the ck corrections.
The optimal group size and the corresponding minimal number of tests per person are thus given, to an excellent approximation, by

For a prevalence p of 1 per cent, Dorfman’s approach yields a group size of approximately 10 and approximately 0.2 tests per person, whereas ours yields a group size of 35 and 0.12 tests per person. For a prevalence of 0.1 per cent, Dorfman’s optimal group size is 32 whereas ours is 350. His approach requires 0.06 tests per person, whereas ours needs only 0.018. For all lower, but still reasonable, values of p our approach prevails by an increasing margin.
Further geometrical insight into our approach and its relation to Dorfman’s may be gained by considering its generalization to a hypercuboid. A set of n people to be tested may be represented as a rectangular volume in a D-dimensional cubic lattice with L1, L2,…, LD points on a side, constrained to obey L1L2…LD = n. For simplicity, consider the case when there is exactly one infected individual to be found. Our approach is to group the points in slices taken along each of the principal directions of the lattice, and to test each slice. The required number of tests is L1 + L2 +…+ LD. This is minimized, for fixed n, when the Li are all equal, i.e., for a hypercube. One can think of Dorfman’s approach to the same problem as a reduced D = 2 version, with L1 the number of groups and L2 the group size so L1L2 = n. Dorfman’s approach is first to test the L1 groups, and then the L2 members of the positive group (this is the sense in which it is reduced: in the second step, he tests individuals not groups). The namber of tests required is L1 + L2 which is minimized, at fixed n = L1L2, by taking  so this is the optimal group size. Setting the prevalence p = 1/n, we recover the results noted for Dorfman’s algorithm above. The advantage of our approach over Dorfman’s is that of going to higher dimensions. Similarly, in other testing algorithms, test matrices are designed using arguments which are essentially two dimensional [16] where in our approach, the higher dimensional viewpoint is key.
so this is the optimal group size. Setting the prevalence p = 1/n, we recover the results noted for Dorfman’s algorithm above. The advantage of our approach over Dorfman’s is that of going to higher dimensions. Similarly, in other testing algorithms, test matrices are designed using arguments which are essentially two dimensional [16] where in our approach, the higher dimensional viewpoint is key.
Appendix B: Information theory bounds
Information theory sets a lower bound on the number of tests required to uniquely identify all infected individuals. The uncertainty in who is infected is associated with an entropy,
 where the sum is over all possible states and the pi are the corresponding probabilities. If a test outputs a zero or a one then for t tests the number of possible test outputs is 2t and the corresponding information gained is at most t ln 2. In order to learn everything about the system, one requires an information gain of at least S, hence
where the sum is over all possible states and the pi are the corresponding probabilities. If a test outputs a zero or a one then for t tests the number of possible test outputs is 2t and the corresponding information gained is at most t ln 2. In order to learn everything about the system, one requires an information gain of at least S, hence

Consider a sample of size n, with k infected individuals chosen at random. The number of such states is  . Therefore, from (B2), the minimum number of tests required is
. Therefore, from (B2), the minimum number of tests required is  for k ≪ n. Assuming a binomial distribution with prevalence p, and replacing k with its expectation p n, we find the expected number of tests per person is ∼ p log2(1/p). Binary searches can approach this limit by performing an adaptive series of tests (see, e.g, Refs. [13, 14]). However, binary searches are adaptive, requiring an iterated series of tests. The number of rounds of testing ∼ log2 n ∼ log2(1/p) for the optimal value of n, at low p. Parallel searches, called “noiseless, nonadaptive” tests in Ref. [16], are faster but require more tests as we discuss in Appendix C.
for k ≪ n. Assuming a binomial distribution with prevalence p, and replacing k with its expectation p n, we find the expected number of tests per person is ∼ p log2(1/p). Binary searches can approach this limit by performing an adaptive series of tests (see, e.g, Refs. [13, 14]). However, binary searches are adaptive, requiring an iterated series of tests. The number of rounds of testing ∼ log2 n ∼ log2(1/p) for the optimal value of n, at low p. Parallel searches, called “noiseless, nonadaptive” tests in Ref. [16], are faster but require more tests as we discuss in Appendix C.
Appendix C: Comparison with non-adaptive test matrix searches
Proposals for group testing have been extensively explored in the computer science literature - see Ref. [16] for an excellent recent review. The “noiseless, non-adaptive” tests described in Chapter 2 there are most relevant. Our hypercube algorithm should be viewed as semi-adaptive because it sometimes takes two rounds of slicing tests to achieve a very low failure rate. As we shall explain, the best non-adaptive tests discussed in Ref. [16] are not directly applicable to the problem considered here. These methods rely on building a T by N “test matrix” of zeros and ones, where T is the number of tests and N is the number of samples to be tested. When applied to a column vector of candidate samples, each row of the matrix selects those which are to be pooled in the corresponding test. The zeros and ones of the test matrix are chosen at random according to some probability distribution. In the simplest case this is a Bernoulli distribution, with p being the probability to be one and 1 − p the probability to be zero. An important improvement is known as the “near-constant column weight” design. The idea is to ensure that every sample participates in a similar number of tests, by choosing a fixed number of entries (called the weight) of each column uniformly at random with replacement and setting them to one, while setting all other elements zero. The weight, which in practice provides an upper bound to the number of nonzero column entries (because of the choice with replacement - hence the term ‘near-constant’) is adjusted to optimise the search.
With the test matrix fixed, the next step is to interpret the test outcomes. One of the best- performing algorithms is the “definitely defective” or DD algorithm due to Aldridge, Baldassini and Johnson [21]. The terminology arises from Dorfman’s original paper where infected samples were termed “defective.” The DD algorithm proceeds in two steps: a) eliminate all samples which were included in negative tests (because they are definitely non-defective) and label the remainder as “possibly defective” and b) identify all samples which are the only “possibly defective” samples included in a positive test, as “definitely defective.” The DD algorithm outputs a set of definitely defective samples which may or may not be the complete set of defectives. If some defectives have been missed, the algorithm has failed. The DD algorithm with near-constant column weight design performs particularly well in simulations when the weight is suitably optimised. The algorithm is also tractable analytically in the limit where the number of defectives k ∼ Θ(nα) and n → ∞ with α a constant. For small α, the DD algorithm with near-constant column weight design has a rate of at least ln 2 ≈ 0.693 bits (see Theorem 2.8 and Eq. (2.18) in Ref. [16]), where the “rate” of an algorithm is defined to be the information gained per test, in bits. While these results are instructive they are, unfortunately, not directly relevant. As the authors of [16] explain, the optimal weight for the DD algorithm is the closest integer to (T/k) ln 2 where T is the number of tests and k is the number of defectives. So k must be known in advance, which is an unrealistic requirement in our context. Second, we are interested in optimal performance at fixed prevalence p, not fixed α. With these caveats, it is interesting nevertheless that the information rate achieved by the DD algorithm with near-constant column weight design and in the analytical limit they discuss, is larger by a factor of e(ln 2)2 ≈ 1.3 than that achieved by our method at large D. Equally interesting, we have found the performance of the hypercube algorithm to improve as D decreases. In Appendix G, we show that the”rate” (in the sense of [16]) achieved by the hypercube algorithm with no prior knowledge of k other than the prevalence p which is used to set the group size, increases with decreasing D. For D = 3 it actually exceeds the above mentioned “rate” of 0.693 bits.
Another key performance indicator is a test’s failure rate. To compare the hypercube algorithm with the DD algorithm with near-constant column weight design, we have implemented a numerical code for the latter. Our code accurately reproduces the performance as plotted in Figure 2.3 of Ref. [16], on a test problem with k = 10 and n = 500. We then used the same code to study the success rate for the following test problem, chosen to correspond as closely as possible to the problem of interest here but still be addressable using their algorithm. First, we consider groups of size N, with a single infected member. (This is unrealistic, of course, but allows us to select the optimal weight for the DD algorithm, and ensures the hypercube algorithm always succeeds). For N = 81, the hypercube algorithm requires only 12 tests to identify the infected sample. In contrast, we find the DD algorithm on average requires more than 18 tests to achieve a failure rate below 0.1%‡ Likewise, for N = 243, our algorithm requires 15 tests whereas the DD algorithm requires more than 21 tests to achieve a failure rate below 0.1%. For this problem, both algorithms take only one round of testing, so they are equally fast. Next, we examine the more realistic situation, where only the prevalence is known. Setting p = 0.35/N, we generate a set of randomly chosen groups of size N, having a Poisson distribution for the number k of infected members. In Appendix G, we show that the hypercube algorithm requires at most two rounds of slicing tests to achieve a failure rate below 0.01%. When it fails, it informs us that it has failed so that, if necessary, we can run further tests. However, the DD algorithm can fail to identify a positive sample (because it is not yet “definitely defective”), without providing any indication of this failure. For the DD algorithm applied to a Poisson distribution of infected groups, if we choose the column weight to be that for the mean value of k, we find a large deterioration in its performance, with a much higher failure rate. This is not surprising since, when k deviates from the mean, as it usually does, the column weight is sub-optimal. Finally, let us also mention the recent work of Ref. [23]. From the data they present, their algorithm produces false positives at a rate which exceeds the experimental error.‡ There are other significant differences with our approach - for example, they use continuous data from the RT-PCR tests. It will be interesting to compare the efficiency and failure rates of their algorithm with those of ours on test problems and we intend to do so in the near future.
For the problem at hand, we conclude that the semi-adaptive hypercube search algorithm has multiple advantages over the DD algorithm with near-constant column weight design. These arise from its formulation in higher dimensions.
Appendix D: Probabilities of slice outcomes given k
As discussed in Section IV, the output of the first round of slicing tests on positive groups is, for L = 3, a set of triples with σ = 1, 2 or 3. Given a population of interest (more precisely, a sample of individuals drawn from the population) and an assumed prevalence p, we form groups of size ≈ 0.35/p for hypercube screening. It is convenient to compute the probabilities for obtaining each value of σ in any given hypercube direction, in a “dilute gas” approximation. Namely, we assume that infected samples are each placed at a random point in the hypercube corresponding to the group. This approximation ignores the constraint that no two infected samples may occupy the same point. But since this circumstance is very rare at low viral prevalence, at even modest values of D, the approximation is excellent. In this approximation, if there are k infected individuals in the population, the probability that an infected sample is placed in a given slice is just 1/3. Let PL(σ|k) be the probability of obtaining σ given k (at fixed L). Then

Similarly,
 and finally,
and finally,

In subsequent Appendices, we shall need these formulae both for estimating the viral prevalence or for identifying infected group members. In particular, we shall need conditional probabilities where we make use of the results of previous tests. In this case, we need to normalize the probabilities for the allowed values of σ to ensure they sum to unity. So, for example, if we know that σ ≠ 3 in any direction, then we obtain;

Also, in subsequent rounds of slicing tests, we need the probabilities for smaller hypercubes with L = 2,

Appendix E: Probabilities of slice outcomes given λ
Typically, when a positive group is detected, we will not know k, the number of infected samples it contains. We will, however, have available the updated estimate of the number of infected individuals expected in the hypercube, λ(1) (see the first paragraph in Appendix H). This allows us to compute probabilities for the results of the first round of slicing tests. For the second round of slicing, we will subdivide the original hypercube into a number of smaller ones. We shall reestimate the number of infected individuals in these smaller hypercubes, λ(2), in the light of the first round of slicing test results, and so on.
Let PL(σ|λ(1)) be the probability of obtaining σ in any given hypercube direction, in the first round of slicing tests, in any group. Since only positive groups are tested, for any given group we have
 where, because of the restriction k > 0, P (k|λ(1)) is a truncated Poisson distribution hence the additional factor of
where, because of the restriction k > 0, P (k|λ(1)) is a truncated Poisson distribution hence the additional factor of  in the denominator. Similarly,
in the denominator. Similarly,
 and
and

Satisfying  . It will be convenient in what follows to also have the probabilities for σ = 1 and σ = 2, conditioned on d3 = 0 or d3 = 1. For example, making use of (D4) we have
. It will be convenient in what follows to also have the probabilities for σ = 1 and σ = 2, conditioned on d3 = 0 or d3 = 1. For example, making use of (D4) we have

For understanding the failure rate of our algorithm in subsequent rounds of slicing tests, j > 1, we will need the probabilities of obtaining σ = 1 or 2 in a smaller hypercube of length L = 2. Using (D5), these are given by
 where we again renormalised the Poisson distribution because k > 0 in each of the smaller hypercubes. We compute the relevant values of λ(j) in Appendix F. From the dependence on λ(j) it should always be clear to which round of testing the probabilities apply.
where we again renormalised the Poisson distribution because k > 0 in each of the smaller hypercubes. We compute the relevant values of λ(j) in Appendix F. From the dependence on λ(j) it should always be clear to which round of testing the probabilities apply.
Appendix F: Expected Failure Rate
If, after the first round of slicing tests, σ > 1 in more than one hypercube direction, we will be unable to uniquely identify the coordinates of all infected samples. The failure rate for our algorithm in this first round is the corresponding probability, which may be expressed as one minus the probability that σ = 1 in all but one direction, namely
 where Pr(d, D, p) ≡ pd(1 − p)D−dD!/(d!(D − d)!) is the binomial probability distribution and P (1|λ(1)) is given in (E1).
where Pr(d, D, p) ≡ pd(1 − p)D−dD!/(d!(D − d)!) is the binomial probability distribution and P (1|λ(1)) is given in (E1).
To compute the failure rate in subsequent rounds of slicing tests, it is helpful to separate the possible outcomes of the first test into three classes: d3 = 0, d3 = 1 and d3 > 1. For realistic values of D, and λ ≈ 0.35, the outcomes with d3 = 0 strongly predominate, followed by those with d3 = 1 which in turn predominate over higher values of d3. More precisely,
 for all practical values of D and λ(1). For example, for λ(1) = 0.35 and D = 4, of the first round of slicing tests, 98.2% give d3 = 0, 1.78% give d3 = 1 and only 0.012% give d3 > 1. (Even for D = 10, the probability that d3 > 1 is less than 0.1%.) The strong dominance of d3 = 0 and d3 = 1 over other values allows us to focus our effort on these cases.
for all practical values of D and λ(1). For example, for λ(1) = 0.35 and D = 4, of the first round of slicing tests, 98.2% give d3 = 0, 1.78% give d3 = 1 and only 0.012% give d3 > 1. (Even for D = 10, the probability that d3 > 1 is less than 0.1%.) The strong dominance of d3 = 0 and d3 = 1 over other values allows us to focus our effort on these cases.
If d3 = 0, all of the positive sample coordinates reside in a smaller hypercube with volume  . We divide it in two along any one of its principal directions, forming two hypercubes of dimension d2 − 1. Should we require further rounds of testing, this subdivision will be iterated so that the j’th round of testing will involve 2j−1 hypercubes of length L = 2. Because the positive samples are distributed randomly among the hypercubes, in the j’th round the number of positive samples expected in each smaller hypercube is
. We divide it in two along any one of its principal directions, forming two hypercubes of dimension d2 − 1. Should we require further rounds of testing, this subdivision will be iterated so that the j’th round of testing will involve 2j−1 hypercubes of length L = 2. Because the positive samples are distributed randomly among the hypercubes, in the j’th round the number of positive samples expected in each smaller hypercube is

If d3 = 1, all unknown positive sample coordinates reside in a hypercuboid with volume  . We divide this into three along the single direction with σ = 3, forming three hypercuboids with L = 2. In this case, we obtain
. We divide this into three along the single direction with σ = 3, forming three hypercuboids with L = 2. In this case, we obtain

We are now ready to calculate the failure rate for the second round of slicing tests (assuming failure in the first round). This is the probability that σ > 1 along more than one direction after the second round. Notice that, if d3 = 0, because we subdivide the hypercube along one σ = 2 direction, only if d2 is greater than two in the first round, can we fail to identify all infected individuals in the second. Using a similar argument to that used in deriving (F1), we obtain
 where P2(1|λ(2)) is obtained from (E5) and P3(2|λ(1)) from (E4). If d3 = 1,
where P2(1|λ(2)) is obtained from (E5) and P3(2|λ(1)) from (E4). If d3 = 1,

For practical values of D and λ, both of these values are negligible (see Table 4) so execution beyond round two is unnecessary. Nevertheless, for the sake of completeness, we provide the failure rate for round j > 2, namely

Appendix G: Expected number of tests
When d3 = 0, as noted earlier, the second round of testing involves two hypercubes of dimension  . Testing them requires testing
. Testing them requires testing  slices. If needed, the third round will involve testing
slices. If needed, the third round will involve testing  slices and so on. Therefore the expected number of tests conducted in the j’th round of slicing tests, with j > 1, is given by
slices and so on. Therefore the expected number of tests conducted in the j’th round of slicing tests, with j > 1, is given by
 where
where
 and
and

The expected total number of tests conducted up to and including the j’th round is given by

When d3 = 1, however, the second round of slicing tests involves 3 hypercubes and  slices.
slices.
The third round involves 6 hypercubes,  slices and so on.
slices and so on.
The expected number of tests in the second round is:
 and in round j > 2 is
and in round j > 2 is

The total expected number of tests conducted up to and including the j’th round is given by substituting (G5) and (G6) into (G4).
When λ(1) = 0.35 and D = 4, in the 98.2% of cases where the first round produces d3 = 0, an average of 12.29 tests will be conducted up to and including the second round. In the remaining 1.8% of cases, an average of 12.44 tests will be conducted up to and including the second round.
Table 5 shows examples of possible field trials, as discussed in Section V of the main text. The middle three columns show the expected total number of tests needed and the right three columns show the “rate” of the search in bits per test, as defined by Aldridge et al., in Ref. [16]. Note that this rate increases with decreasing D. For D = 3, it exceeds even the rate for the DD algorithm with near-constant column weight design which (for a somewhat different problem, requiring more input) achieves one of the highest rates known among known for non-adaptive test matrix algorithms (see the discussion in Appendix C).
Appendix H: Estimating the viral prevalence p from test results
Let p be an estimate of the viral prevalence in the considered population and let λ(0) = pn be the expected number of positive samples, among n samples taken from the population. Before applying the hypercube algorithm, we divide the n samples into g groups, where g is chosen so that the expected number of positive samples in each group, λ(1) = λ(0)/g is close to the optimal value of 0.35. Each sample is then subdivided into a number of smaller samples, to be used in subsequent pooled tests.
The first round of tests is used to identify positive groups. The fraction of groups that test negative, f, can be used to re-estimate p using the maximum likelihood method. The result is p = 1 − f 1/N where N is the group size. If this estimate differs significantly from the original one, we may decide to use a different group size g in what follows, or even to repeat this first round of group tests since it is relatively inexpensive.
Once the group testing phase is completed, the samples from every positive group are placed in a hypercube for further slicing tests. Suppose that, in the first round of slicing tests, we observe n1, n2 and n3 instances of σ = 1, 2 and 3, respectively, across all positive groups. The posterior probability of k, conditioned on these observations is then given from Bayes’ theorem by
 where
where
 and the prior probability is given by the Poisson distribution,
and the prior probability is given by the Poisson distribution,

The normalisation factor P (obs) is then determined by requiring that  . The required summations converge rapidly at large k. Using (H1) the expected value of k is determined,
. The required summations converge rapidly at large k. Using (H1) the expected value of k is determined,
 and the estimate of the prevalence is
and the estimate of the prevalence is  where n is the initial population sample size. A credible interval (e.g., a 95% Cl) for k and hence for p can be easily computed from (H1). A refinement, taking into account that the triples are taken from a set of g indistinguishable groups of size N, will be presented elsewhere.
where n is the initial population sample size. A credible interval (e.g., a 95% Cl) for k and hence for p can be easily computed from (H1). A refinement, taking into account that the triples are taken from a set of g indistinguishable groups of size N, will be presented elsewhere.
Appendix I: Experimental Methods and Supplementary Information
Observational study design
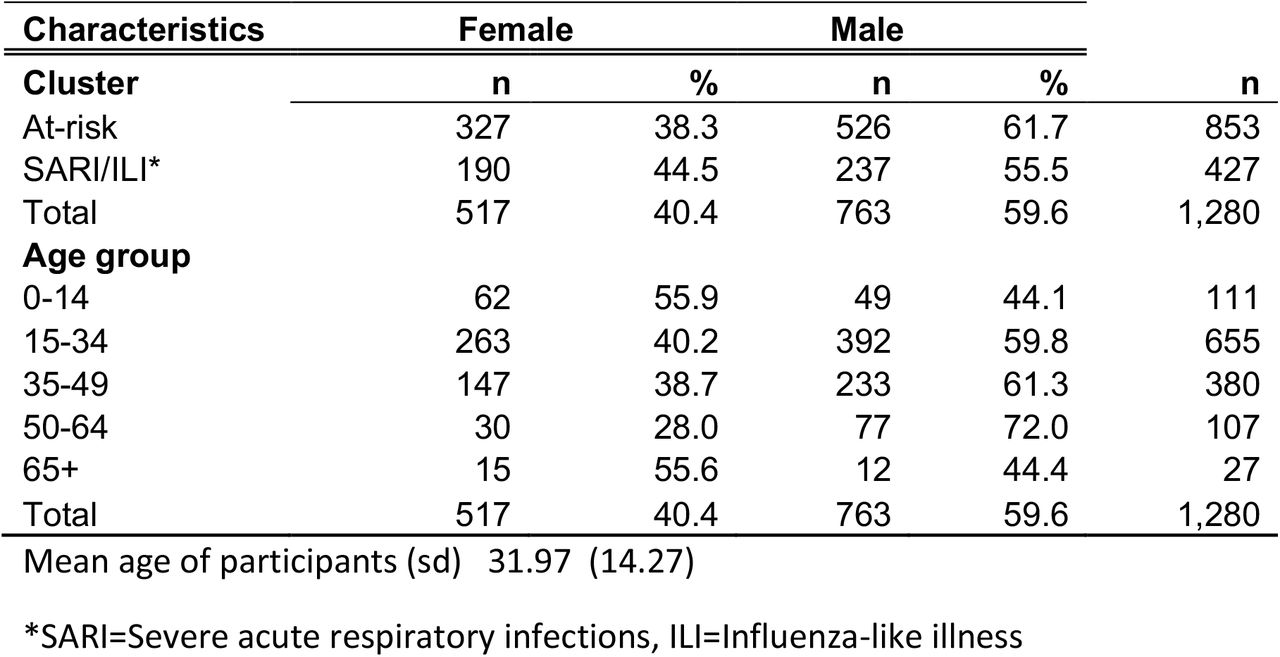
We conducted an experiment to evaluate the hypothesis that known SARS-CoV-2 positive oropharyngeal swab specimens collected during COVID-19 surveillance in Rwanda will test positive after they are combined with as many as 99 known SARS-CoV-2 negative specimens. This was followed by an observational study that aimed to apply our hypercube algorithm to increase the efficiency of community testing for COVID-19 in Rwanda. In the experiment, two different sets of sample pools were tested for SARS-CoV-2 using RT-PCR. Each set consisted of three sample pools containing one known SARS-CoV-2 positive sample diluted in ratios of 1:20, 1:50, and 1:100 by combining it with equivalent amounts of 19, 49, and 99 known SARS-CoV-2 negative samples, respectively (see Fig. 2). In the observational study, 1280 individuals selected from the community were tested for SARS-CoV-2 using RT-PCR. One third of the individuals were participants in a screening for Severe Acute Respiratory Infections (SARI) and Influenza Like Illness (ILI) conducted in 30 per cent of the health facilities found across the 30 districts of Rwanda. The remaining two thirds were from COVID-19 screening of at-risk groups in the capital city of Kigali. The latter group is comprised mainly of people (market vendors, bank agents, and supermarket agents) who remained active during the lockdown imposed by the Government of Rwanda to contain COVID-19. Figure 7 summarises the characteristics of the study participants.
For more information, see Observational study design.

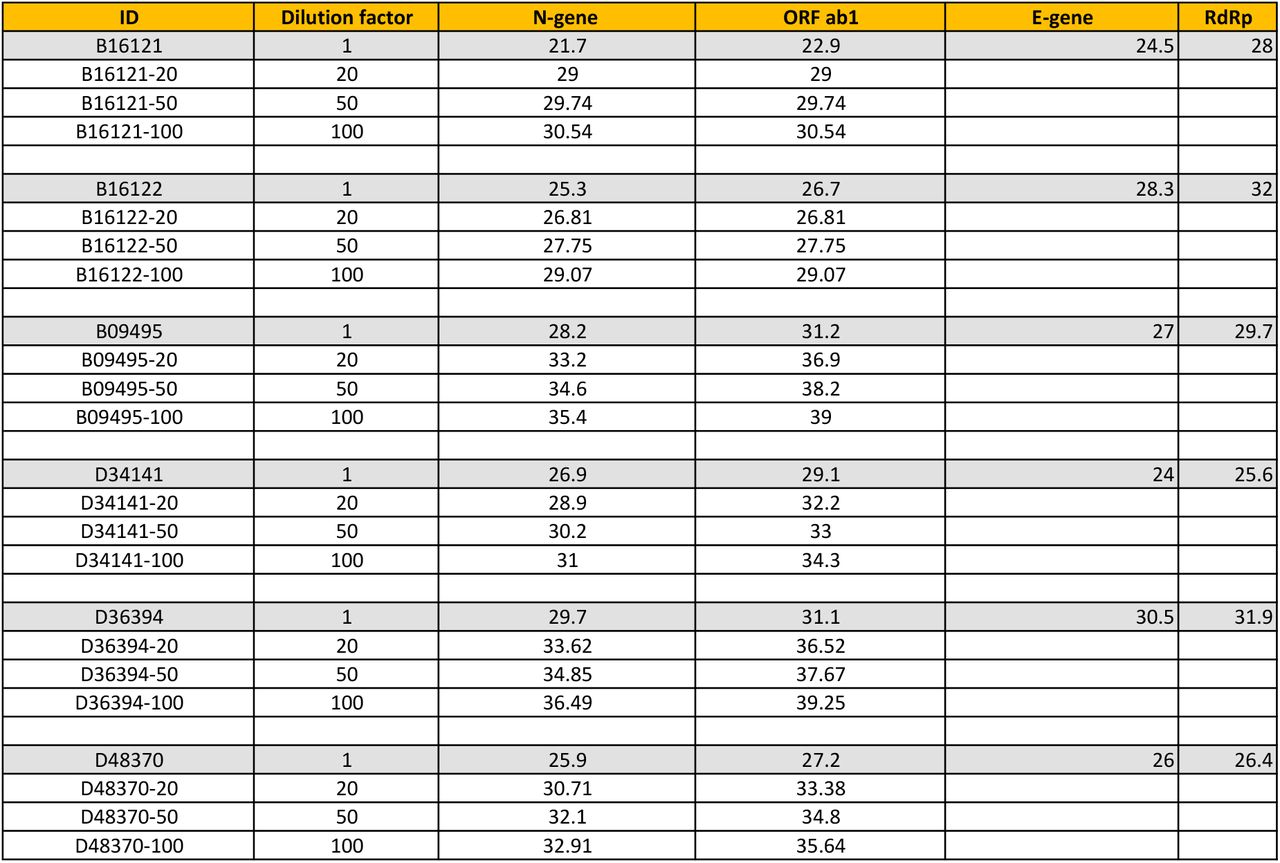
Six SARS-CoV-2 positive specimens detected during COVID-19 screening in Rwanda were analysed. The positive specimens were detected by using a screening RT-PCR test targeting the N and Orf1ab genes of SARS-CoV-2 (Ct values from this test are reported in columns 3 and 4), and confirmed by using another RT-PCR test targeting the E and RdRp genes (Ct values reported in columns 5 and 6). We determined whether the screening test would have detected the positive specimens if they had been combined with 19, 49 or 99 known SARS-CoV-2 negative specimens. Three pools were thus formed per sample, with dilution factors given in column 2. For all 18 pools, fluorescence from RT-PCR reactions exceeded background levels at Ct values below 40 (columns 3 and 4), implying that all the positive samples would have been detected even if they were diluted by up to 100 fold. See Methods for details of the experimental methods.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The specimens were detected by using a screening RT-PCR test targeting the N and Orf1ab genes of SARS-CoV-2 (Ct values from this test are reported in columns 3 and 5). They were subsequently confirmed as positive by using another RT-PCR test targeting the E and RdRp genes (Ct values are reported in columns 7 and 9).
The positive fraction of RT-PCR tests for SARS-CoV-2 conducted in Rwanda in March 2020 suggests an upper-bound of 2 per cent for the virus prevalence in the country. Using p =2 per cent in the hypercube algorithm indicated an optimal sample group size of 17.5. For convenience, the 1280 individual samples were combined in 64 groups of 20 samples before testing for SARS-CoV-2 (see Fig. 6 for the experimental results).
We used two established experimental protocols for SARS-CoV-2 testing, namely 1) a protocol by DAAN Gene Co., Ltd., Sun Yat-sen University, which is available online [24], and is also under review by the WHO [25], and 2) another by Corman et al., [2] which is widely used by the scientific community. The first protocol is used for routine screening for SARS-CoV-2, while the second protocol is used only if the first one produces a positive result and confirmation is thus required.
Sample collection and pool design
Oropharyngeal swabs were collected by wiping the tonsils and posterior pharynx wall with two swabs, and the swab heads were immersed in 3 ml Viral Transport Medium (VTM). Samples were transported in VTM to the Rwanda National Reference Laboratory (NRL) immediately after collection. Samples that had to be transported over a long distance were stored in dry ice. Each sample had a volume of 3 ml, of which 200 µl were used for pool testing, and the remainder was temporarily stored at −20°C until the result of the pool testing was known. 200 µl of each sample were mixed with the same volume of other samples of the same pool in a FalconTM 15 ml conical tube and, after vortexing for 5 seconds, 200 µl of the mixture were pipetted for downstream RNA extraction. 5 µl of the extracted RNA were added to 20 µl of master mix to make 25 µl of total solution to be amplified by RT-PCR. If a pool tested positive, stored samples from that pool were processed to identify the positive ones. Individual samples were bar coded, making it easy to trace individuals that tested positive and minimising the risk of confusion of samples. Pool design and subsequent experimental analysis (see RT-PCR for SARS-CoV-2 below) were implemented with the aid of a robot to reduce human error.
RT-PCR for SARS-CoV-2
Total viral RNA was extracted from swab specimens using the QIAamp Viral RNA 91 Mini Kit (Qiagen, Hilden, Germany), according to the manufacturer’s instructions. RNA samples were screened for SARS-CoV-2 using a 2019-nCoV RNA RT-PCR test targeting two genes respectively encoding an open reading frame (denoted Orf1ab) and nucleocapsid protein (denoted N) (DAAN Gene Co., Ltd. Of Sun Yat-sen University, 19, Xiangshan Road, Guangzhou Hi-Tech Industrial Development Zone, China). For Orf1ab, CCCT- GTGGGTTTTACACTTAA and ACGATTGTGCATCAGCTGA were used as forward and reverse primers, respectively, together with a 5’-VIC CCGTCTGCGGTATGTGGAAAGGTTATGG- BHQ1-3’ probe. For N, GGGGAACTTCTCCTGCTAGAAT and CAGACATTTTGCTCT- CAAGCTG were used as forward and reverse primers, respectively, together with a 5’-FAM- TTGCTGCTGCTTGACAGATT-TAMRA-3’ probe. The RT-PCR reaction was set up according to the manufacturer’s protocol, with a total volume of 25 µL. The reaction was run on the ABI Prism 7500 SDS Instrument (Applied Biosystems) at 50°C for 15 min for reverse transcription, denatured at 95°C for 15 min, followed by 45 PCR cycles of 94°C for 15 sec and 55°C for 45 sec. A threshold cycle (Ct value) <40 indicated a positive test, while Ct value >40 indicated a negative test. Positive controls for the reaction showed amplification as determined by curves for FAM and VIC detection channels, and a Ct value ≤ 32. Positive tests were confirmed using LightMix SarbecoV E-gene and LightMix Modular SARS-CoV-2 RdRp RT-PCRs targeting the envelope (E) and RNA directed RNA Polymerase (RdRp) genes, respectively, as described by the manufacturer (TIB MOLBIOL Syntheselabor GmbH, Eresburgstr. 22-23, D-12103 Berlin, Germany). Both the primers used and the RT-PCR reaction conditions were previously described [2].
Footnotes
↵† nturok{at}perimeterinstitute.ca
Revised manuscript with many improvements including: additional experimental data; detailed theoretical analysis of currently realistic group sizes (expected number of tests, upper bound on failure rate); comparison with state-of-the-art methods in computer science. New Figures 2 and 3, six new Appendices and additional Supplementary Materials.
‡ Further modest efficiency gains could be made by allowing hypercuboids with side lengths of 2 as well as 3.
‡ It would be unreasonable, in our view, to use a search algorithm which introduced theoretical errors comparable in magnitude to the smallest experimental error because analysis is cheap compared to experiment. In the case of RT-PCR tests, the smallest error is the probability for false positives, which is known to be < 0.1%[22]. We insist that search method errors should be smaller.



