
Abstract
Since the initial outbreak in Wuhan (Hubei, China) in December 2019, severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the virus responsible for coronavirus disease 2019 (COVID-19), has rapidly spread to cause one of the most pressing challenges facing our world today: the COVID-19 pandemic. Within four months of the first reported cases, more than two and a half million cases were confirmed with over two hundred thousand deaths globally, and many countries had taken extreme measures to stop the spread. In this work, we analyse the response to the COVID-19 outbreak for 103 countries over the period 22 January to 13 April 2020. We utilise a novel stochastic epidemiological model that includes a regulatory mechanism that captures the level of tolerance to rising confirmed cases within the response behaviour. Using approximate Bayesian computation, we identify that the top ten outbreaks as of 31 March are characterised by a high tolerance to rising cases tallies, whereas countries that avoided severe outbreak have a low tolerance. Countries that recovered rapidly also have a higher identification rate. As of 13 April, almost all countries show declines in transmission rates and basic reproductive numbers. Furthermore, countries approaching recovery also increased their identification rate between 31 March and 13 April. We also demonstrate that uncertainty in undocumented infections dramatically impacts uncertainty in predictions. Overall, we recommend that broader testing is required to understand the magnitude of undocumented infections.
Introduction
The world is at war with the coronavirus disease 2019 (COVID-19) [9], which was officially declared a pandemic by the World Health Organization (WHO) on 11 March 2020 [42]. From the earliest cases reported in December 2019 (Hubei, China), severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) spread rapidly throughout the world [37,45]. On 3 April 2020, the global tally of confirmed cases exceeded one million with over 50,000 fatalities [11,17]. The challenge faced by healthcare systems worldwide cannot be understated [19,21,29,36].
Travel restrictions, increased hygiene education, social distancing, school and business closures, and even complete lockdowns [9, 36] are now all-too-familiar concepts. These are examples of non-pharmaceutical intervention (NPI) strategies that many countries have introduced to slow transmission rates and relieve pressure on healthcare systems in the absence of a vaccine or treatment for COVID-19 [?, 14]. Modelling and simulation are at the forefront of determining the efficacy of these measures in reducing SARS-CoV-2 transmission and quantifying risk of future outbreaks along with their potential severity [2, 8, 16, 31]. Understanding of these effects is crucial given the potential deleterious sociological and economic impacts of many NPIs [3–5, 9].
The global modelling community has responded rapidly to the COVID-19 situation and has provided insight into the transmissibility of SARS-CoV-2 [25, 26, 32], global risk of spread through transport networks [17, 44], forecasting and prediction [20, 28, 33], and evaluation of interventions [16]. A variety of modelling strategies have been applied. Techniques include: empirical approaches such as phenomenological growth curves [33]; data-driven, statistical approaches using non-linear autoregressive models [1]; and mechanistic models based on epidemiological theory [22] with various extensions [7, 34].
Here, we consider a stochastic epidemiological model in which the true infected population is unobservable and a regulatory mechanism on the virus transmission process is included to capture the community response to a COVID-19 outbreak. There is a large body of literature related to modelling specific intervention strategies [16]. We take a unique approach that does not explicitly model specific interventions. Instead, our model captures a general tendency for the transmission rate to decline as the number of confirmed cases increases. Through the inclusion of a utility function, the model also allows for more general responses incorporating deaths and recoveries to reflect alternative imperatives for intervention. With this model we can identify key features differentiating countries that have experienced a severe outbreak from those that have managed to contain the spread.
Within a Bayesian framework, we characterise 103 countries using COVID-19 time-series data, provided by Johns Hopkins University [11, 17], over two time periods, 22 Jan–31 Mar 2020, and 22 Jan–13 Apr 2020. Our characterisation is a broad assessment of the global response to the COVID-19 pandemic, and reflects how countries in early phases of outbreak may have adjusted their strategies to reduce the time to recovery. In particular, we find that very severe outbreaks are characterised by a high tolerance to rising confirmed case numbers before significant reductions in transmission rates occur. Of the top ten severely affected countries (in terms of cumulative cases), the only countries that observed a decrease in active cases during the period of study (China and South Korea) are characterised by high identification rates; the result of highly effective identification and quarantine programs. We also find that, for many countries, the transmission rates in the later period of the study are declining. However, large unobserved infected population counts are also estimated. Our analysis shows that increased testing, contact tracing, isolation and quarantine measures are effective in reducing the severity of COVID-19 outbreaks world-wide. We also demonstrate that the unknown magnitude of undocumented cases substantively impacts uncertainty in predictions and we conclude that wider testing is also essential to reduce this uncertainty.
Results
Our model is a stochastic epidemiological model (See Materials and Methods) that describes the evolution of six sub-populations over time: susceptible St; undocumented infected It; confirmed active At; confirmed recovered 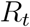 ; confirmed deceased Dt; and undocumented recovered
; confirmed deceased Dt; and undocumented recovered 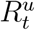 . The cumulative confirmed cases can be recovered from the model as Ct = At + Rt + Dt. Importantly, the true values of St, It, and
. The cumulative confirmed cases can be recovered from the model as Ct = At + Rt + Dt. Importantly, the true values of St, It, and 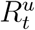 are not observable in reality and are latent variables in our model. This explicit treatment of an undocumented infected population is essential for more realistic uncertainty quantification. A novel feature of our model is the transmission rate of SARS-CoV-2 that depends on a utility function of the observable states, At, Rt, and Dt. For the presented results, this rate is a monotonically decreasing function in the cumulative confirmed cases Ct, representing the overall population response to rising confirmed case numbers. This effectively approximates the combined effect of NPI introduction, community compliance with various interventions, and a general change in social behaviour as media outlets report higher case and fatality statistics. However, it is important to note that our framework allows for other utility functions that lead to other functional forms for the transmission rate (See Materials and Methods, and Supplementary Material).
are not observable in reality and are latent variables in our model. This explicit treatment of an undocumented infected population is essential for more realistic uncertainty quantification. A novel feature of our model is the transmission rate of SARS-CoV-2 that depends on a utility function of the observable states, At, Rt, and Dt. For the presented results, this rate is a monotonically decreasing function in the cumulative confirmed cases Ct, representing the overall population response to rising confirmed case numbers. This effectively approximates the combined effect of NPI introduction, community compliance with various interventions, and a general change in social behaviour as media outlets report higher case and fatality statistics. However, it is important to note that our framework allows for other utility functions that lead to other functional forms for the transmission rate (See Materials and Methods, and Supplementary Material).
Our model has eight parameters to be estimated: two transmission rates, α0 and α, where α can be regulated but α0 cannot (i.e., residual unavoidable transmission); case recovery rate β; case identification rate γ; case death rate δ; relative latent recovery rate η; regulatory parameter n; and the initial infected scale factor κ. While details are provided in the Materials and Methods section, the parameters n and κ deserve some interpretation here. The regulation parameter n controls the rate at which the transmission rate α is scaled down as the cumulative cases increase. In general, n ≥ 1 represents a response with a low tolerance to increasing cases, 0 < n < 1 is a response with a higher tolerance for larger case numbers, and n = 0 indicates no regulatory effect at all (See Material and Methods for more details). Throughout, we refer to n ≥ 1 as a low tolerance response, and n < 1 as a high tolerance response. Importantly, n does not provide information on the timescale in which the community responds, nor the overall efficacy of interventions and management. Rather, n is an indicator of how tolerant a community has been to growing case numbers. The parameter κ estimates the number of undocumented infections relative to confirmed cases on the first day that exceeds 100 confirmed cases (t = 0), that is, κ = I0/C0. Higher values for κ imply greater levels of undocumented spread ahead of the earliest reported cases, and smaller values of κ represents effective identification, quarantine and early contact tracing.
Using data obtained from the Johns Hopkins University (See Materials and Methods), Bayesian parameter inference is applied to 103 countries over the period 22 January–31 March 2020 and again over the period 22 January–13 April 2020 (See Materials and Methods for our inclusion criteria). Approximate Bayesian computation (Materials and Methods) [12] is applied to adaptively sample the approximate posterior distributions for all eight model parameters and posterior predictive distributions for the number of active confirmed cases, recoveries and deaths over time. Note that we analyse each country independently, although a global model could also be considered (See Discussion).
Model fit
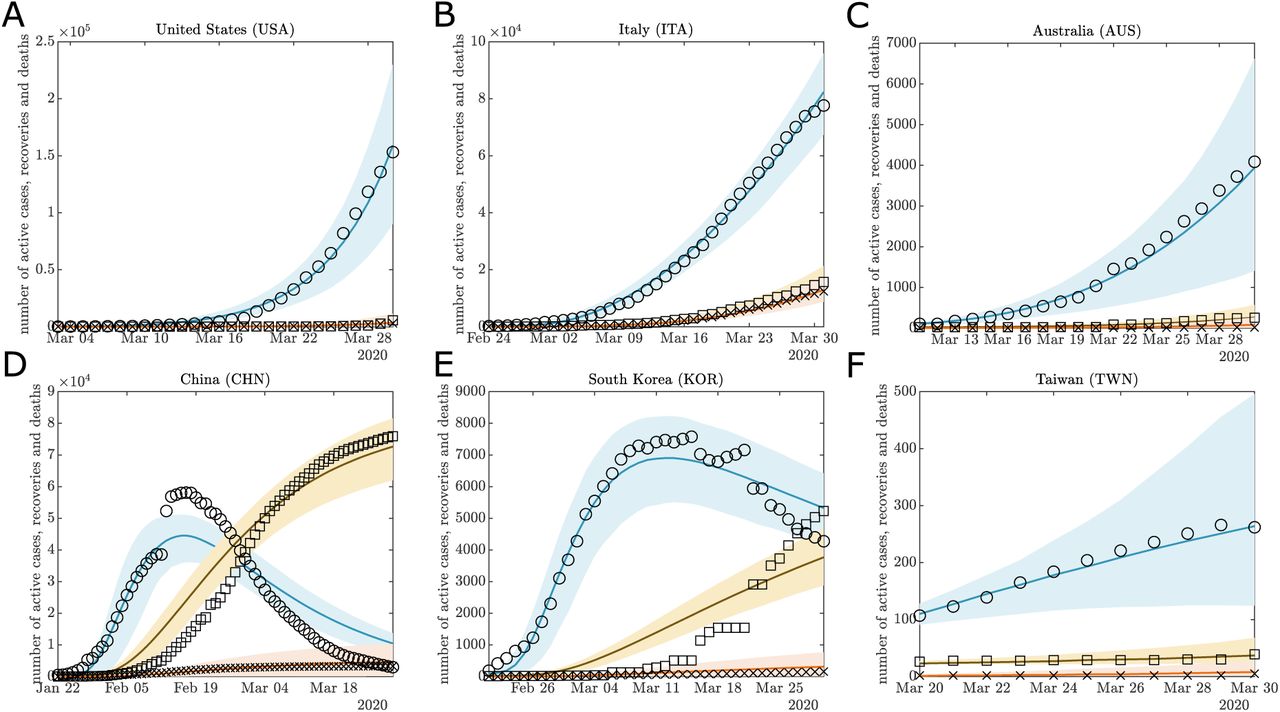
For almost all countries, the posterior predictive median lies close to the observed time series, and is almost always contained within the 95% credible intervals. Fig. 1 provides examples of the model performance for the United States (Fig. 1(A)), Italy (Fig. 1(B)), Australia (Fig. 1(C)), China (Fig. 1(D)), South Korea (Fig. 1(E)), and Taiwan (Fig. 1(F)). Fig. 1(A)-(C),(F) are representative of the accurate results we achieve across almost all 103 countries in this study. The model fits for China (Fig. 1(D)) and South Korea (Fig. 1(E)) are the only exceptions. The inaccuracy of the active trajectory for China is, at least, partly due to the changes in reporting methodology from China on 13 February [43]; however, this does not explain the overestimation of the early recovery period for both China and South Korea. We discuss potential model improvements to account for this in the Discussion section. Notwithstanding this, our model appears to be sufficiently accurate for a broad comparative analysis of global responses to COVID-19 during this period.

Examples of model fit for (A) United States, (B) Italy, (C) Australia, (D) China, (E) South Korea, and (F) Taiwan for COVID-19 data up to 31 March. The median (solid lines), and 95% credible interval (shaded region) of the posterior predictive distributions is plotted for active cases (blue), recoveries (yellow), and deaths (red). This is compared against observations as recorded in data for active cases (circles), recoveries (squares), and deaths (crosses).
Assessing global response up to 31 March 2020
The marginal posterior distributions for the parameters α0 (residual transmission rate), α (regulated transmission rate), β (case recovery rate), and δ (case fatality rate) (See Figs. S1 and S2 in Supplementary material) are similar across countries. This is expected as these parameters mainly describe the SARS-CoV-2 infection itself, rather than differing national responses. For the period up to 31 March, exceptions include: a higher uncertainty in death rate for Honduras, higher uncertainty in recovery rate for Nigeria and Venezuela, and increased uncertainty in the α0 parameter of Afghanistan, Cameroon, Cuba, Honduras, Cambodia, Mauritius, Nigeria, Palestine, and Venezuela. The data also appear to be uninformative for the relative recovery rate, η since the posterior is very close to the prior (Fig. S3). The posterior marginals for the identification rate, γ, the regulatory parameter, n, and the initial infected scale parameter κ, relate to the nature of the initial outbreak and subsequent response. As a result, there is significant variation in these distributions across countries (Figs. S3 and S4).
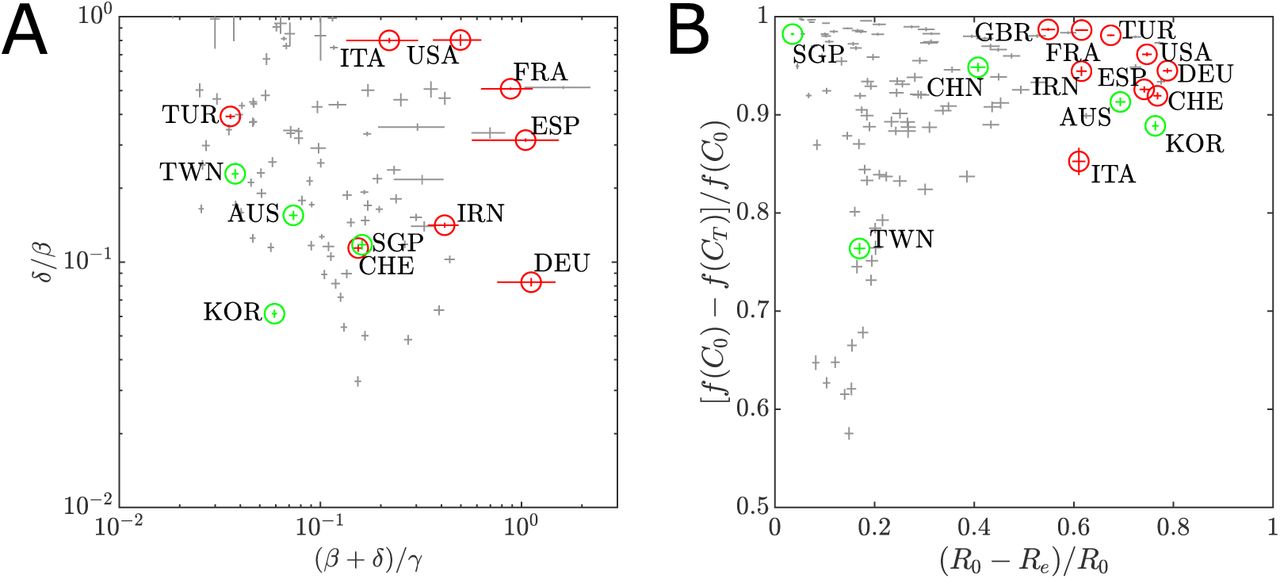
To investigate global patterns, we compute, for each country, the marginal posterior means for the parameters γ, n, and κ. Fig. 2 shows the distribution of these point estimates across all countries, and highlights countries having the highest cumulative confirmed cases to date (31 March 2020) without a decline in active cases: the United States (USA), Spain (ESP), Italy (ITA), Germany (DEU), France (FRA), United Kingdom (GBR), Iran (IRN), and Switzerland (CHE). Fig. 2 also highlights countries that are recovering from the outbreak or prevented a severe outbreak as of 31 March: China (CHN) [23], South Korea (KOR) [30], Singapore (SGP) [41] and Taiwan (TWN) [39]. Australia (AUS) is also included as it was still undergoing an outbreak on 31 March, but significantly reduced transmission by 13 April.

Pairwise scatter plots of point estimates of each assessed country (grey points, with lines to indicate 95% CI) for the key parameters related to the management of an COVID-19 outbreak up to 31 March 2020: regulatory parameter n; detection rate γ; and the relative initial undocumented cases κ. (A) n versus γ; (B) κ versus γ; and (C) κ versus n. The top ten countries for confirmed case counts are highlighted (red) along with countries that have managed to control the outbreak are highlighted (green). Labels identify the country by ISO-3166 alpha-3 code.
Excluding the United Kingdom, all of the countries undergoing a severe outbreak (in terms of cumulative confirmed cases) have point estimates of n < 1 (Fig. 2(A), (D)). This indicates a high tolerance response in which the transmission rate did not decline significantly until cases increased to larger numbers (See Fig. 6 in Materials and Methods). This is consistent with reported delays in response across Europe and the United States [9]. However, it is important to restate that a high tolerance response n < 1 is not equivalent to a slow response in time. In ascending order, the five smallest values for n are: China (n = 0.471; 95% CI: [0.464,0.477]), South Korea (n = 0.559; 95% CI: [0.551,0.567]), Italy (n = 0.618; 95% CI: [0.610,0.625]), Spain (n = 0.638; 95% CI: [0.630,0.647]), then Germany (n = 0.673; 95% CI: [0.663,0.683]). Of these five, China and South Korea are characterised by a higher identification rate γ > 0.5 (China γ = 0.549; 95% CI:[0.535,0.562]; South Korea γ = 0.632; 95% [0.619,0.644]) which is indicative of their strict testing, isolation, and tracing regimes [6, 23]. It is unexpected that the value of n for China is low, since strong lockdown measures were taken in Hubei [23]; we expect this is due to the absence of clinically diagnosed cases reported before to 13 February [43]. It is also important to note that small n does not mean that NPIs were not effective, but rather that they became effective at higher tallies of confirmed cases. France, Iran, Turkey, and the United States also have comparable values for γ, but did not experience a decline in active cases in the time frame of the study. These countries have a larger value for κ, indicating a large number of latent infections at an earlier stage of the outbreak, therefore a delay in the effect is expected. With κ = 1.586 (95% CI: [1.567, 1.606]), Iran is a particularly extreme example of this, as there was significant undetected spread of SARS-CoV-2 through the volumes of pilgrims passing through the city of Qom [15]. Of the severely affected countries, the United Kingdom has the closest signature to Taiwan and Singapore, albeit with a higher κ and lower n. The larger κ likely implies early unobserved transmission prior to abandonment of “herd immunity” targets in favour of social distancing, and closing of non-essential business and schools [16,27]. Australia has a very similar characterisation to the United Kingdom, with higher κ, but also higher n that likely reflects the introduction of travel bans and social gathering restrictions introduced in the second half of March.
Overall, our modelling approach identifies features of how communities globally respond to the COVID-19 pandemic. Without explicit modelling of specific NPIs, we obtain results that are consistent with the intervention strategies of the most severely affected countries. Globally, we see a low tolerance regulatory response with many countries having high values of n. Unfortunately, most countries also have large values of κ, indicating that delays in early detection have lead to a larger unobserved infectious population. As a result, the active case curve will take longer to turn around. This downturn could be brought forward by increasing γ through increased identification and quarantine/isolation capacity.
These results are for the period 22 Jan–31 March. In the next section, we consider an additional two weeks of data (the period 1-13 Apr), provide refined parameter estimates and offer insights into the evolution of the pandemic.
Re-assessing global response up to 13 April 2020
The fast moving evolution of epidemics and pandemics such as COVID-19 demand that model outputs and the corresponding effectiveness of mitigating measures are regularly re-assessed. We re-evaluate our model estimates and inferences for 103 countries that satisfied our inclusion criteria (See Materials and Methods) over the period 22 January–13 April 2020. These results reveal that as the pandemic evolves, we can learn more about the possible response histories and latent infected populations.
Updated point estimates, based on marginal posterior means, are computed for the parameters γ, n and k. The distribution of these point estimates is shown in Fig. 3(A)-(C) with the same countries highlighted as in Fig. 2. For the top eight countries still experiencing severe outbreaks on 31 March, there is a significant shift in these parameter estimates using data for the period 22 January-13 April. There is also a reduction in the uncertainty for some parameters overall (See Supplementary Material Fig. S5-S8). These shifts, demonstrated in Fig. 3(D)-(F), have some broad trends. In Fig. 3(D) and (F), all eight countries show a decrease in the parameter n, with France, Iran, Turkey, the United Kingdom, and the United States having the most substantial declines. This indicates that, in light of more recent data, the community response to the outbreak had a higher tolerance to growing case numbers than earlier data indicated. Fig. 3(D) and (E) indicate that most of these countries have a lower identification rate. However, it is promising to see a small increase in γ for Germany and Switzerland, and a large increase in γ for Italy and Spain; this is possibly a reflection of increased testing capabilities within these countries between 31 March to 13 April (https://ourworldindata.org/coronavirus; Accessed 14 April). Overall, there is also a decrease in κ, indicating that the number of early undocumented cases could be lower than previously thought. One concerning exception is Italy, with an increase in the point estimate with κ = 0.956 (95% CI: [0.924, 0.988]). Australia also shows a decrease in the value of n = 0.703 (95% CI: [0.693, 0.713]), but also a decrease in κ = 0.259 (95% CI: [0.240, 0.278]). This suggests the Australian community was overall more tolerant of higher case numbers, but the undocumented case numbers were lower than previously expected. Australia shows an increase in γ = 0.456 (95% CI:[0.440,0.472]) which is consistent with a high identification rate of symptomatic cases [32]. Comparing Fig 2(A)-(C) with Fig 3(A)-(C) highlights the dynamical nature on the COVID-19 pandemic. In particular, changes in the parameters n and κ indicate that our understanding of the past trajectory of the outbreak is also evolving. This is a particular strength of our modelling approach in that we can characterise how sensitive a community response is to growing case numbers. Our framework is also flexible enough to include community responses to other factors that may be prescribed through an arbitrary utility metric (see Materials and Methods, and Supplementary Material).

Pairwise scatter plots of point estimates of each assessed country (blue points, with lines to indicate 95% CI) for the key parameters related to the management of an COVID-19 outbreak up to 13 April 2020: regulatory parameter n; detection rate γ; and the relative initial undocumented cases κ. (A) n versus 7; (B) κ versus 7; and (C) κ versus n. Highlighted countries are the same as in Fig. 2. Labels identify the country by ISO-3166 alpha-3 code. (D)-(F) Indication of parameter estimate shifts in light of new data up to 13 April 2020, for the severe outbreaks identified on 31 March 2020.
Assessment of outbreak management
As stated above, the regulatory parameter n does not provide insight into the full management of the outbreak. It simply provides a measure of how the transmission rate declines as a function of confirmed case counts (see Materials and Methods). We compute several derived quantities that provide a more complete view of how countries are managing the pandemic. Specifically, we consider the following quantities: the case death rate relative to the case recovery rate, δ/β; the case removal rate relative to identification rate, (β + δ)/γ; the relative strength of transmission rate regulation, 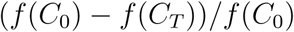 , where f (·) is the transmission rate regulatory function (see Materials and Methods), and respectively C0, and CT, are the number of confirmed cases at the start of the outbreak (first day exceeding 100 confirmed cases) and at the end of the data period (13 April); and the relative reduction in the basic reproduction number [10],
, where f (·) is the transmission rate regulatory function (see Materials and Methods), and respectively C0, and CT, are the number of confirmed cases at the start of the outbreak (first day exceeding 100 confirmed cases) and at the end of the data period (13 April); and the relative reduction in the basic reproduction number [10], 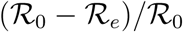 , where unfigure
, where unfigure 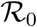 is the basic reproductive number at the start of the outbreak and unfigure
is the basic reproductive number at the start of the outbreak and unfigure 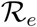 is the basic reproduction number at the end of the data period (See Supplementary Material). Point estimates of these ratios are computed through expectations with respect to the full joint parameter posterior distributions (See Materials and Methods, and Supplementary Material) for each country.
is the basic reproduction number at the end of the data period (See Supplementary Material). Point estimates of these ratios are computed through expectations with respect to the full joint parameter posterior distributions (See Materials and Methods, and Supplementary Material) for each country.
Fig. 4(A) shows the distribution of point estimates related to management and treatment of confirmed cases. The effective management of COVID-19 cases within Germany can be inferred by a low value for the relative case fatality rate δ/β = 0.083 (95% CI [0.070,0.086]) and high value for the case removal rate relative to identification rate (β + δ)/γ = 1.12 (95% CI [0.76,1.48]). The United Kingdom is an outlier with a very high δ/β = 41.32 (95% CI:[2.64, 80.01]); we expect this is due to a discrepancy in the data for recoveries in the United Kingdom (with only 626 recoveries recorded). China is another outlier with (β + δ)/γ = 6.66 (95% CI: [0, 13.73]) due to relatively poor model fit for China as discussed above. Fig. 4(B) shows that globally there is a high level of regulation with (f (C0) — f (CT))/f (C0) > 0.7 (that is, regulatory strength greater than 70% of maximum) for nearly all countries. Despite this, there are many countries with only moderate reductions in the basic reproductive number, indicating that more testing is required or a higher level of residual transmission a0. In particular, the second outbreak occurring within Singapore in the later period of study is identified by a high level regulation but very little decrease in the basic reproductive number. Fortunately, the basic reproduction number reduced by at least 50% for all of the most severely affected countries.

Scatter plots of point estimates of each assessed country (blue points, with lines to indicate 95% CI) for derived quantities from epidemiological rate parameters. (A) Comparison of the ratio δ/β with the ratio (β + δ)/γ, outliers not shown (China with (β + δ)/γ = 6.66 (95% CI: [0, 13.73]) and United Kingdom with δ/β = 41.32 (95% CI:[2.64, 80.01])). (B) reduction in effective reproduction number Re on 13 April 2020 relative to the basic reproduction number R0 compared with the relative strength of transmission rate regulation f (CT) on 13 April 2020 relative to the transmission rate at the start of the outbreak. Highlighted countries are the same as in Fig. 2. Labels identify the country by ISO-3166 alpha-3 code.
Uncertainty quantification for predictions
The primary purpose of our model is to analyse the historical trajectory and community response to the COVID-19 pandemic. However, our approach also enables predictions that account for uncertainty in the undocumented infected population and in the community tolerance of rising cases. There are many unknowns within the current pandemic that affect the accuracy of model prediction [20,28]. In particular, we have no estimates for the number of undocumented cases world wide. Furthermore, inadequate uncertainty quantification can lead to unrealistic credible prediction intervals [28]. We use our Bayesian framework to handle both uncertainty in model parameters and uncertainty in undocumented infected population. Regarding prediction uncertainty, we take a conservative approach that provides predictions accounting for uncertainty in the evolution up to the current time. We perform this by sampling from the posterior predictive distribution and continue model evolution to the prediction horizon. In this way, we consider uncertainty in all possible histories (parameter values and latent population evolution) to quantify uncertainty in predictions conditional on the model formulation.
Using posterior distributions of parameters computed using data up to 13 April, we quantify prediction uncertainty over a 7 day prediction horizon. Example predictions for active cases, recoveries and deaths (median and 95% credible interval) are shown in Fig. 5 for the United States (Fig. 5(A)), Italy (Fig. 5(B)), Spain (Fig. 5(C)), Germany (Fig. 5(D)), Taiwan (Fig. 5(E)) and Australia (Fig. 5(F)). Our approach produced wide credible intervals as a result of parameter uncertainty and uncertainty in undocumented infections. There is a wide range of possible scenarios for undocumented infection populations sizes that are completely consistent with the data [26]. By continuing simulations from the posterior predictive distribution we take an ensemble of these scenarios into account.

Examples of uncertainty quantification over γ day prediction horizon for (A) the United States, (B) Italy, (C) Spain, (D) Germany, (E) Taiwan and (F) Australia using COVID-19 data up to 13 April 2020. The median (solid lines), and 95% credible interval (shaded region) of the posterior predictive distributions is plotted for active cases (blue), recoveries (yellow), and deaths (red). Data used for predictions are also shown: active cases (circles), recoveries (squares), and deaths (crosses).
Our predictions for the United States show a continuing increase in the number of active cases (Fig 5(A)). An increase in active cases is predicted for Italy (Fig 5(B)), although the decline in the lower bound of the credible interval indicates the possibility of a flattening of active case counts in future weeks. Predictions for Spain and Germany (Fig 5(C),(D)) also indicate a flattening out in the number of active cases over the prediction horizon. For Taiwan and Australia (Fig 5(E), (F)) the median predictions show a decline in active cases; however, the uncertainty is still substantial.
The key message from this analysis is to highlight the importance of conservative uncertainties in the future evolution of the pandemic. It is encouraging to see predictions that indicate potential future declines in active cases counts. However, uncertainties in the number of undocumented cases and model parameters indicate caution in predicting the timing of consistent declines in active case numbers. Therefore, it is essential that communities remain vigilant in fast-evolving situations such as this.
Discussion
We have applied a novel stochastic epidemiological model to characterise the response to the COVID-19 pandemic for 103 countries worldwide over the period 22 January-13 April 2020. We find that the worst affected countries (in terms of confirmed case numbers), including the United States, Italy, Spain and Germany, are characterised by a response with high tolerance to rising case numbers (i.e., small n). However, increased testing and isolation protocols (large γ) have demonstrably reduced the longer term impact, as demonstrated by China and South Korea. Many countries seem to be learning from these collective experiences, as many countries have a low tolerance for rising case numbers (large n). Unfortunately, we also identify that the number of undocumented cases likely exceeded the confirmed cases for many countries (large κ). It is important to emphasise that we do not make any specific guidelines for particular countries in improving specific non-pharmaceutical intervention (NPI) or testing strategies. However, through the lens of our model, we advise that effective actions should begin at lower case numbers rather than having a high tolerance to rising cases.
Our model, like any model, has fundamental assumptions that are necessarily introduced. We treat each country as a single well-mixed population. While our approach does include important features such as undocumented infections and a variable transmission rate, more advanced analysis could be performed by considering disease spread through a network [8,13,24,38] of well-mixed populations, such as provinces and states. We also treat each country as a closed system, whereas realistic sources and sinks through inclusion of an international travel network could enable us to track the impact of decisions of one country on connected countries.
Other details of the model could also be extended. We treat active confirmed cases as non-infectious due to quarantine and isolation. In reality, active confirmed cases can still spread the virus to medical staff. We also apply the reasonable approximation that there is no re-detection or re-infection, however, new evidence is questioning the validity of this assumption [27]. A finer granularity of classes of susceptible individuals (i.e., at risk), incubation periods, and severity of symptoms would also enable more detailed analysis for an individual country [20,32]. However, our reduced set of classes is a trade-off between realism and broad applicability to worldwide data. A Bayesian hierarchical modelling approach could also be applied to better capture heterogeneity across countries.
Our model framework is flexible through the inclusion of a utility function, U (At, Rt, Dt) (See Materials and Methods), in the regulatory mechanism and may be extended to other scenarios. We have only considered the case of a utility dependent on cumulative cases, U (At, Rt, Dt) = At + Rt + Dt = Ct, or deaths only, U (At, Rt, Dt) = Dt (See Materials and Methods, and Supplementary Material). However, the utility function could include economical factors or be modified to be a function of state and time. This would enable a wide range of behaviours to be explored, such as specific timings of enforced NPIs, and subsequent lifting of restrictions when active case go below a threshold.
It is hoped that our work might be used to inform future responses to outbreaks of COVID-19 or other pandemics. The message is clear, we must not be complacent in response to an outbreak as the earliest confirmed cases arise. While many countries have managed to reduce transmission and basic reproductive numbers, a response with a lower tolerance to rising confirmed case numbers is recommended for the future. We also highlight the importance of wider testing to effectively reduce uncertainty in predictions of case numbers, recoveries and deaths.
Materials and Methods
This section presents details on the data, mathematical model, and statistical methods applied in this work.
Data summary
Daily counts of reported confirmed COVID-19 cases, recoveries and deaths for each country are obtained from the Johns Hopkins University coronavirus resource center (coronavirus.jhu.edu/; Accessed 14 April 2020) for the period of 22 January 2020 to 13 April 2020. Population data for each country for 2020 were obtained from United Nations Population Division estimates (www.worldometers.info/world-population/population-by-country/; Accessed 14 April 2020).
Our analysis is performed over two different periods: i) 22 January-31 March 2020; and ii) 22 January-13 April. Our inclusion criteria for period i) are countries for which there was at least one day exceeding 100 confirmed cases of COVID-19 between before 30 March 2020. Of all countries with confirmed cases, N = 103 countries satisfied our criteria for period i). Similarly, for period ii) we include countries with at least one day exceeding 100 confirmed cases of COVID-19 before 12 April 2020.
For each country, i = 1, 2, …, N, we process the raw data to produce a time-series, 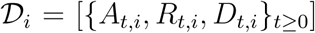 , where At,i, Rt,i, and Dt,i are the active cases, recoveries and deaths on day t in country i. Here, day t = 0 is the first day to exceed 100 active cases. While it is known that there are variations in reporting protocols across countries and time, we make the necessary simplifying assumption in our analysis that the quantities At,i, Rt,i, and Dt,i have an equivalent interpretation across all countries over time.
, where At,i, Rt,i, and Dt,i are the active cases, recoveries and deaths on day t in country i. Here, day t = 0 is the first day to exceed 100 active cases. While it is known that there are variations in reporting protocols across countries and time, we make the necessary simplifying assumption in our analysis that the quantities At,i, Rt,i, and Dt,i have an equivalent interpretation across all countries over time.
Mathematical model
We apply a stochastic epidemiological model to describe the spread of COVID-19 within a single country that is a assumed to have a well-mixed population. Here, S is the population of those susceptible to SARS-CoV-2 infection, I is the latent infected population, A are the active confirmed cases of COVID-19, R are confirmed recoveries, D are confirmed deaths caused by COVID-19, and Ru are those that recover from COVID-19 but where never confirmed. The cumulative confirmed cases are given by C = A + R + D. The individual counts within each population are updated according to the following transition events,
 where
where 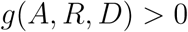 is the effective transmission rate function, γ > 0 is the identification rate, β > 0 is the case recovery rate, δ > 0 is the case fatality rate, and n is the latent recovery rate relative to the case recovery rate. At time t > 0 (days), the system state is given by the population counts St, It, At, Rt, Dt, and
is the effective transmission rate function, γ > 0 is the identification rate, β > 0 is the case recovery rate, δ > 0 is the case fatality rate, and n is the latent recovery rate relative to the case recovery rate. At time t > 0 (days), the system state is given by the population counts St, It, At, Rt, Dt, and 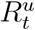 and evolves according to a discrete-state continuous-time Markov process (Supplementary Material). We apply the tau-leaping numerical scheme [18] (Supplementary Material), as exact stochastic simulation was computationally infeasible. At time t = 0 (first day exceeding 100 active cases), A0, R0, and D0 are obtained from time-series data. For unobserved states we initially set, I0 = κA0,
and evolves according to a discrete-state continuous-time Markov process (Supplementary Material). We apply the tau-leaping numerical scheme [18] (Supplementary Material), as exact stochastic simulation was computationally infeasible. At time t = 0 (first day exceeding 100 active cases), A0, R0, and D0 are obtained from time-series data. For unobserved states we initially set, I0 = κA0, 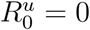 , and S0 = P — C0 — I0 where, P is total population record for the country and κ ≥ 0 is the number of unobserved cases relative to active cases at t = 0.
, and S0 = P — C0 — I0 where, P is total population record for the country and κ ≥ 0 is the number of unobserved cases relative to active cases at t = 0.
The transmission rate is described as a function of observables of the form 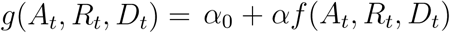 . Here, f (At,Rt,Dt) is a decreasing function in a measure of utility U(At,Rt,Dt), a is a scale factor such that αf(At,Rt,Dt) is a transmission rate that decreases as the utility function increases and α0 is the residual transmission rate as f (At, Rt, Dt) → 0. We assume the form f (At, Rt, Dt) = 1/(1 + U(At, Rt, Dt)n).
. Here, f (At,Rt,Dt) is a decreasing function in a measure of utility U(At,Rt,Dt), a is a scale factor such that αf(At,Rt,Dt) is a transmission rate that decreases as the utility function increases and α0 is the residual transmission rate as f (At, Rt, Dt) → 0. We assume the form f (At, Rt, Dt) = 1/(1 + U(At, Rt, Dt)n).
We find a utility function based on cumulative confirmed case numbers, U(At, Rt, Dt) = At + Rt + Dt = Ct, provides a good fit across all countries that we consider (excepting changes in reporting methodology for China on 13 Feb [43]). However, we also investigate a utility function that only considers deaths, U(At,Rt,Dt) = Dt, but model fitting was inferior (See Supplementary Material). There is a wide variety of utility functions that could be considered to model specific country NPIs and behaviours.
Therefore, we simplify our notation and consider 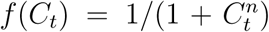 where the parameter n ≥ 0 controls the rate of decrease as shown in Fig. 6. Given an initial number of confirmed cases, C0, we have
where the parameter n ≥ 0 controls the rate of decrease as shown in Fig. 6. Given an initial number of confirmed cases, C0, we have 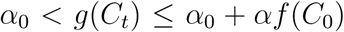 . Note the shape of f (Ct) starts to decline rapidly before starting to level out. Increasing n shifts the initial decline to the left, effectively altering the critical values of Ct in which a population begins to maximise efforts to “flatten the curve”. For example, small n describes a population that does not significantly reduce the transmission rate until the confirmed case tally is large. Conversely, larger n describes a population that acts decisively as a response to very early stages of the outbreak. Importantly, our approach does not distinguish between different NPIs and voluntary population behaviour, but rather models the net effect of rising confirmed cases on transmission rates.
. Note the shape of f (Ct) starts to decline rapidly before starting to level out. Increasing n shifts the initial decline to the left, effectively altering the critical values of Ct in which a population begins to maximise efforts to “flatten the curve”. For example, small n describes a population that does not significantly reduce the transmission rate until the confirmed case tally is large. Conversely, larger n describes a population that acts decisively as a response to very early stages of the outbreak. Importantly, our approach does not distinguish between different NPIs and voluntary population behaviour, but rather models the net effect of rising confirmed cases on transmission rates.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The effect of the regulatory parameter n on the regulation function. Higher values of n lead to a rapid decrease in transmission as Ct increases, whereas smaller n requires many more cases to reduce the transmission rate. (A) linear scale; (B) logarithmic scale.
The parameter κ is used to initialise the unobserved infected population, I0 = κA0, and indicates the outbreak extent within the community at time t = 0. Small κ indicates that efforts of testing and contact tracing have been very effective at early time, whereas large κ implies the virus has spread extensively without early intervention.
Bayesian Analysis
Using time-series data unfigure 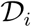 for each country i ϵ [1, 2, …, N], we infer model parameters θi within a Bayesian framework. For notational convenience, we will omit the subscript i for the remainder of this section. We sample the joint posterior distribution for θ = [α0, α, β, γ, δ, η, n, κ],
for each country i ϵ [1, 2, …, N], we infer model parameters θi within a Bayesian framework. For notational convenience, we will omit the subscript i for the remainder of this section. We sample the joint posterior distribution for θ = [α0, α, β, γ, δ, η, n, κ],
 where
where 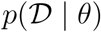 is the likelihood function and p(θ) is the prior distribution. The likelihood function is intractable, due to the unobserved populations St, It, and
is the likelihood function and p(θ) is the prior distribution. The likelihood function is intractable, due to the unobserved populations St, It, and 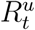 . Therefore, we rely on adaptive sequential Monte Carlo for approximate Bayesian computation (SMC-ABC) [12,35,40] to obtain accurate approximate posterior samples (Supplementary Material). We use independent uniform priors,
. Therefore, we rely on adaptive sequential Monte Carlo for approximate Bayesian computation (SMC-ABC) [12,35,40] to obtain accurate approximate posterior samples (Supplementary Material). We use independent uniform priors, 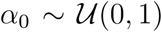 ,
, 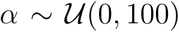 ,
, 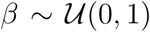 ,
, 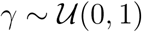 ,
, 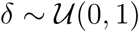 ,
, 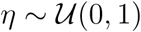 ,
, 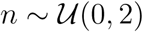 and
and 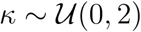 .
.
Model fit is assessed though sampling the posterior predictive distribution
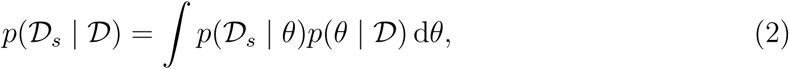 where
where 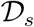 is simulated data as generated by the model. We compute the mean and the 95% credible region of unfigure
is simulated data as generated by the model. We compute the mean and the 95% credible region of unfigure 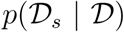 through generating a single model simulation for each posterior sample generated by the SMC-ABC sampler and computing quantiles of the simulation state distribution at each observation time. For prediction, each stochastic simulation is continued in time up to the prediction horizon.
through generating a single model simulation for each posterior sample generated by the SMC-ABC sampler and computing quantiles of the simulation state distribution at each observation time. For prediction, each stochastic simulation is continued in time up to the prediction horizon.
Parameter point estimates are obtained using the marginal posterior means and uncertainty is quantified using the marginal posterior variance. Point estimates of derived quantities, δ/β, (β + β)/γ, (f(C0) — /(CT))/f(C0), and unfigure 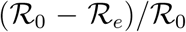 are computed through evaluating expectations with respect to the full joint posterior distribution.
are computed through evaluating expectations with respect to the full joint posterior distribution.
Data Availability
Data is all available in the public domain.
Competing interests
We have no competing interests.
Author contributions
AM and KM designed the research. AM, KM, CD and DJW provided analytical tools. AE, CD, and DJW contributed computational tools. AE processed data. AE and DJW performed simulations and inference. AM, KM, CD, AE, and DJW wrote the paper.
Acknowledgements
Computational resources were provided by the eResearch Office, Queensland Univeristy of Technology. DJW, KM and CD are members of the Australian Research Council (ARC) Centre of Excellence for Mathematical and Statistical Frontiers (ACEMS; CE140100049). AE is supported by a SNF grant (105218_163196). CD is supported by an ARC Discovery Project (DP200102101). KM is supported by an ARC Laureate grant (LF150100150).
References



