
Abstract
Background Isolation of symptomatic cases and tracing of contacts has been used as an early COVID-19 containment measure in many countries, with additional physical distancing measures also introduced as outbreaks have grown. To maintain control of infection while also reducing disruption to populations, there is a need to understand what combination of measures – including novel digital tracing approaches and less intensive physical distancing – may be required to reduce transmission.
Methods Using a model of individual-level transmission stratified by setting (household, work, school, other) based on BBC Pandemic data from 40,162 UK participants, we simulated the impact of a range of different testing, isolation, tracing and physical distancing scenarios. As well as estimating reduction in effective reproduction number, we estimated, for a given level of COVID-19 incidence, the number of contacts that would be newly quarantined each day under different strategies.
Results Under optimistic but plausible assumptions, we estimated that combined testing and tracing strategies would reduce transmission more than mass testing or self-isolation alone (50–65% compared to 2–30%). If limits are placed on gatherings outside of home/school/work (e.g. maximum of 4 daily contacts in other settings), then manual contact tracing of acquaintances only could have a similar effect on transmission reduction as detailed contact tracing. In a scenario where there were 10,000 new symptomatic cases per day, we estimated in most contact tracing strategies, 140,000 to 390,000 contacts would be newly quarantined each day.
Conclusions Consistent with previous modelling studies and country-specific COVID-19 responses to date, our analysis estimates that a high proportion of cases would need to self-isolate and a high proportion of their contacts to be successfully traced to ensure an effective reproduction number that is below one in the absence of other measures. If combined with moderate physical distancing measures, self-isolation and contact tracing would be more likely to achieve control.
Funding Wellcome Trust, EPSRC, European Commission.
Introduction
The novel SARS-CoV-2 coronavirus spread rapidly across multiple countries in early 2020 (1–3). A staple public health control measure for outbreaks of emerging directly-transmitted infections involves isolation of symptomatic cases as well as tracing, testing and quarantine of their contacts (2). The effectiveness of this measure in containing new outbreaks depends both on the transmission dynamics of the infection and the proportion of transmission that occurs from infections without symptoms (4). There is evidence that SARS-CoV-2 has a reproduction number of around 2–3 in the early stages of an outbreak (1,5) and many infections can occur without symptoms (6), which means isolation of symptomatic cases and contact tracing alone are unlikely to contain an outbreak unless a high proportion of cases are isolated and contacts successfully traced and quarantined (7).
Several countries have used combinations of non-pharmaceutical interventions to reduce SARS-CoV-2 transmission (3,8–11). As well as isolation of symptomatic individuals and tracing and quarantine of their contacts, measures have included general physical distancing, school closures, remote working, community testing and cancellation of events. It has also been suggested that the effectiveness of contact tracing could be enhanced through app-based digital tracing (12,13). The effectiveness of contact tracing and the extent of resources required to implement it successfully will depend on the social interactions within a population (14). Targeted interventions such as contact tracing also need to consider individual-level variation in transmission: high variation can lead to superspreading events, which could result in larger numbers of contacts needing to be traced (15,16). There are several examples of such events occurring for COVID-19, including meals, parties and other social gatherings involving close contacts (17–19).
We used social contact data from a large-scale UK study of over 40,000 participants (20,21) to explore a range of different control measures for SARS-CoV-2, including: self-isolation of symptomatic cases; household quarantine; manual tracing of acquaintances (i.e. contacts that have been met before); manual tracing of all contacts; app-based tracing; mass testing regardless of symptoms; a limit on daily contacts made outside home, school and work; and having proportion of the adult population work from home. As well as estimating the reduction in transmission under different scenarios, we estimated how many primary cases and contacts would be quarantined per day in different strategies for a given level of symptomatic case incidence.
Research in context
Evidence before this study
There is an extensive literature on isolation and contact tracing for pathogens such as SARS, smallpox and Ebola. Early modelling studies of SARS-CoV-2 suggested that isolation and tracing alone may not be sufficient to control outbreaks, and additional measures may be required; these measures have since been explored in population-level models. However, there has not been an analysis using setting-specific social contact data to quantify the potential impact of combined contact tracing and physical distancing measures on reducing individual-level transmission of SARS-CoV-2.
Added value of this study
We use data from over 40,000 individuals to assess contact patterns and SARS-CoV-2 transmission in different settings, and compare how combinations of self-isolation, contact tracing and physical distancing could reduce secondary cases. We assessed a range of combined physical distancing and testing/tracing measures, including app-based tracing, remote working, limits on different sized gatherings, and mass population-based testing. We also estimated the number of contacts that would be quarantined under different strategies.
Implications of all the available evidence
Several characteristics of SARS-CoV-2 make effective isolation and contact tracing challenging, including high transmissibility, a relatively short serial interval, and transmission that can occur without symptoms. Combining isolation and contact tracing with physical distancing measures – particularly measures that reduce contacts in settings that would otherwise be difficult to trace – could therefore increase the likelihood of achieving sustained control.
Methods
Secondary attack rate data sources
To estimate the risk of transmission per contact in different community settings, we collated contact tracing studies for COVID-19 from multiple settings that stratified contacts within and outside households (Table 1). Across studies, the estimated secondary attack rate (SAR) within households was 10–20%, with a much smaller SAR among close contacts made outside households, with estimates of 0–5% across studies. However, all these studies were conducted in an ‘under control’ scenario (i.e. effective reproduction number R<1) and some reported relatively few contacts, which may omit superspreading events. This suggests that SARS-CoV-2 may be driven by community transmission events as well as household contacts (18). In our main analysis, we therefore assume 20% HH SAR and 6% among all contacts, which reflects the upper bound of estimates in observed studies (Table 1) and led to an overall reproduction number of 2.6 in our model (described in next section) when no control measures were in place.
Secondary attack rates estimated from COVID-19 contact tracing studies.
Transmission model
Our analysis is based on data on 40,162 UK participants with recorded social contacts in the BBC Pandemic dataset (20). Using these data, we simulated a large number of individual-level transmission events by repeatedly generating contact distributions for a primary case and randomly generating infections among these contacts. In each simulation, we randomly specify a primary case as either under 18 or 18 and over, based on UK demography, in which 21% of the population are under 18 (22). We then generate contacts by randomly sampling values from the marginal distributions of daily contacts made in three different settings for their age group (i.e. under 18 or adults): at home; at work & school; and in ‘other’ settings (Figure 1A–B). We used the marginal distributions rather than raw participant data to ensure non-identifiability and reproducibility in our model code.

A) Distribution of daily contacts made at home, work/school and other settings in the BBC Pandemic dataset. B) Examples of daily social contact patterns for four randomly selected individuals in the model. Black point shows the individual reporting contacts, with social contacts coloured as in A. C) Factors that influence whether an individual is isolated and whether contacts are successfully traced in the model (parameters in Table 2). D) Implementation of contact tracing in the model. Timeline shows a primary case with four daily contacts self-isolating either 1 or 3 days after onset of symptoms. We assume the household contact is the same person throughout, whereas other contacts are made independently. Had the primary case not been isolated, there would have been 7 secondary cases in this illustration (shown with circulations). For isolation 1 day after onset, 4 secondary infections are prevented immediately. Then 7 contacts are potentially traceable, 3 of whom are infected. In this example, two infected contacts pre-isolation are successfully traced and quarantined (i.e. one is missed), so overall the isolation-and-tracing control measure results in a 4+2 = 6 reduction in effective reproduction number. A similar illustration is shown for isolation 3 days after onset.
In the model, we assumed infected individuals had a certain probability of being symptomatic and of being tested if symptomatic, as well as an infectious period that depended on when/if they self-isolated following onset of symptoms (details and justification for model parameters provided in Table 2). We assumed a mean delay of 2.6 days from onset-to-isolation in our baseline scenario (Figure S1). We assumed individuals became infectious one day before onset of symptoms. During each day of the effective infectious period, individuals made a given number of contacts equal to their simulated daily contacts. To avoid double-counting household members, contacts made within the home were not tallied over the entire infectious period, but instead were fixed at the daily value. Once the individual-level contacts had been defined, we generated secondary infections at random based on assumed secondary attack rates among contacts made in different settings, and estimated how many contacts would be successfully traced in each of these settings under different scenarios. First, we generated the number of secondary cases without any control measures in place. Second, we randomly sampled the proportion of these secondary cases that were either successfully traced and quarantined, and hence removed from the potentially infectious pool, or averted through isolation of the primary case. The difference between these two values gave the overall number of secondary cases that would contribute to further transmission (Figure 1C–D).
Parameter definitions and assumptions for the baseline model.
In each simulation, for each of the four contact settings, the number of baseline secondary infections per primary case under no control measures were drawn from a binomial distribution Rbase = B(Nc, pinf), where Nc = (number of daily contacts) × (days infectious) and pinf = SAR × (relative infectiousness), where relative infectiousness = 1 if an individual is (pre-)symptomatic and 50% if asymptomatic. We then generated secondary infections accounting for reduction in Risol = B(Rbase, 1–pisol ), where pisol is the proportion of the infectious period spent in isolation. In the household setting, we assume Nc = (number of daily contacts) because the household contacts will be repeated each day. The number of infected contacts successfully traced were in turn drawn from a binomial distribution Rtraced = B(Risol, ptrace), where ptrace = P(successfully traced) × P(individual adheres full to quarantine). Hence the reduced effective individual-level secondary cases resulting from control measures was equal to Rcontrol = Rbase – Rtraced. The overall effective reproduction number Reff under different control scenarios was equal to the mean of Rcontrol across all simulations.
Scenarios
We considered several different scenarios, both individually and in combination. These included: no control measures; self-isolation of symptomatic cases away from their household; self-isolation and household quarantine after onset of symptoms in primary case; quarantine of work/school contacts; manual tracing of acquaintances (i.e. contacts that have been met before); manual tracing of all contacts; app-based tracing; mass testing of cases regardless of symptoms; a limit on daily contacts made in ‘other’ settings (with the baseline limit being 4 contacts, equal to the mean number reported by adults in the BBC data); and a proportion of the adult population working from home. In the self-isolation only scenario, we assumed individuals who were successfully isolated had no risk of onward transmission (even to household members). Otherwise we assumed household quarantine was in place alongside other measures. For app-based tracing to be successfully implemented in a given simulation, both the infectious individual and their contacts needed to have and use the app. We assumed individuals under age 10 or over 80 would not use a smartphone app (Table 2). In the scenario with mass testing of cases regardless of symptoms, we assumed infected individuals would be identified and immediately self-isolate at a random point during or after their 5 day infectious period. We assumed that infected individuals would not test positive if tested during the latent period (defined here as 1 day prior to symptoms onset). No other measures (e.g. self-isolation/quarantine) were in place for this scenario. For each intervention scenario, we simulated 20,000 primary cases, generating individual-level contact distributions and secondary cases with and without the control measure in place, as described in the previous section. Model code is available from: https://github.com/adamkucharski/2020-cov-tracing
Results
Under the control measures considered, we found that combined testing and tracing strategies reduced the effective reproduction number more than mass testing or self-isolation alone (Table 3). If only self-isolation of symptomatic cases was implemented in the model, it resulted in a mean reduction in transmission of 32%. The addition of household quarantine to self-isolation resulted in an overall mean reduction of 37%. In our simulations, self-isolation combined with manual contact tracing of all contacts reduced transmission by 61%; manual tracing of acquaintances only (i.e. contacts that had been met before) led to a 57% reduction in transmission. We estimated that self-isolation combined with app-based tracing with our baseline assumption of 53% coverage reduced transmission by around 44%, because both the primary case and contact would need to have the app to successfully quarantine an infected secondary case. Contact tracing measures also substantially reduced the probability that a primary symptomatic case would generate more than one secondary case (Table 3).
Results from 20,000 simulated setting-specific secondary transmission, assuming secondary attack rate of 20% among household contacts and 6% among other contacts. Results under the assumption of some workplace restrictions remaining in place are shown in Table 4. Estimates are shown to two significant figures. HH = household.
We estimated that if some level of physical distancing were maintained, it could supplement the reduction in transmission from contact tracing. For example, if daily contacts in ‘other’ settings (i.e. outside the home, work and school) were limited to four people (the mean number made in our dataset), our model suggested that manual tracing of acquaintances only could lead to a 64% reduction in transmission, and app-based tracing a 53% reduction. We estimated that mass random testing of 5% of the population each week would reduce transmission by only 2%, because relatively few infections would be detected and many of those that were would have already spread infection to others.
We also considered the number of contacts that would be traced under different strategies. In a scenario where there were 20,000 new symptomatic cases per day, most contact tracing strategies would require over 200,000 contacts to be newly quarantined each day on average as a result (Table 4). If incidence was at a lower level of 5,000 new symptomatic cases per day, there would be a corresponding four-fold reduction in the number of daily contacts that needed to be quarantined. Although there was a similar reduction in transmission from manual tracing of all contacts and manual tracing of only acquaintances with a limit to four daily contacts in other settings (Table 3), the latter combination required fewer people to be quarantined each day (Table 4). We obtained similar results for the relative reductions in transmission and number of contact traced when we assumed a higher secondary attack rate within-household or among other contacts, which corresponded to baseline reproduction numbers of 2.6–3 (Table S1).
We assume quarantined contacts are independent. Estimates shown to two significant figures, with median and 90% prediction interval given for additional contacts quarantined per detected symptomatic case.
We found that the effectiveness of manual contact tracing strategies were highly dependent on how many contacts were successfully traced, with a high level of tracing required to ensure Reff<1 in our baseline scenario (Figure 2A). If contact tracing were combined with a maximum limit to daily contacts made in other settings (e.g. by restricting events), we found that this limit would have to be relatively small (i.e. fewer than 10–20 contacts) before a discernible effect could be seen on Reff. The limit would have to be very small (i.e. fewer than around 10 contacts) to ensure Reff<1 for app-based tracing, even if half of adults also had no work contacts because remote working was in place (Figure 2B). When app-based tracing is in place, we estimated that if only work contacts are restricted, a substantial proportion of the adult population would need to have zero work contacts to ensure Reff<1 (Figure 2C). Under our baseline assumptions, we estimated that app-based tracing would require a high level of coverage to ensure Reff<1 (Figure 2D), because both primary case and contacts would need the app; this is consistent with our finding that manual tracing would require a high proportion of contacts to be traced.

A) Reduction in R under different strategies for different proportions of work/school/other contacts that are successfully traced. B) Effect of the maximum limit on the number of daily contacts in other settings and control tracing strategies on R, either when adults are working as normal, or when 50% have no work contacts (WFH=50%). C) Effect of proportion of population with no work contacts. D) Effect of app-based tracing under different assumptions about app coverage. In all panels, other parameters are as in Table 2.
We also considered the impact of assumptions about the proportion of infections which are symptomatic and the relative contribution of asymptomatic individuals to transmission. We estimated that if a high proportion of cases were symptomatic, self-isolation and contact tracing measures would lead to a greater relative reduction in transmission (Figure S2A); this is mostly because more primary cases would be detected. Control measures were slightly less effective if the relative transmissibility of asymptomatic infections was higher (Figure S2B), because it would mean more undetectable transmission. However, because our baseline scenario assumed 60% of cases were symptomatic, the overall effect was less than it would be if the majority of cases were asymptomatic. We estimated that if there was no pre-symptomatic transmission, or individuals self-isolated rapidly (i.e. with 1.2 days on average rather than 2.6 days), self-isolation and household quarantine would lead to a larger reduction in transmission (Table S2); correspondingly, if we assumed cases took longer to self-isolate after becoming symptomatic (i.e. 3.6 days on average), these measures were less effective. However, the estimated overall reduction from self-isolation and manual contact tracing was similar across the three scenarios, because although more secondary infections occurred before isolation, a large proportion of them would be traced under our baseline model assumptions.
Discussion
Using a model of setting-specific interactions, we estimated that strategies that combined isolation of symptomatic cases and tracing of their contacts reduced the effective reproduction number more than mass testing or self-isolation alone. The effectiveness of these isolation and tracing strategies was further enhanced when combined with physical distancing measures, such as a reduction in work contacts, or a limit to the number of contacts made outside of home, school or work settings. Several countries have achieved a prolonged suppression of SARS-CoV-2 transmission using a combination of case isolation, contact tracing and physical distancing. In Hong Kong, isolation of cases and tracing of contacts was combined with other physical distancing measures, which resulted in an estimated effective reproduction number near 1 throughout February and March 2020 (10). As well as early surveillance and containment measures (2), Singapore introduced additional ‘circuit breaker’ interventions to counter growing case numbers in April 2020 (23). In South Korea, testing and tracing has been combined with school closures and remote working (24,25).
In our analysis, we estimated that a large number of contacts would need to be traced and tested if incidence of symptomatic cases was high. This logistical constraint may influence how and when it is possible to transition from ensuring Reff<1 through extensive physical distancing measures to reducing transmission predominantly through targeted isolation and tracing-based measures. Our estimate of 20–30 median contacts being traced and tested per case in the manual tracing strategies we considered (Table 4) is reflected in the large scale testing being conducted per confirmed case in countries with a high estimated proportion of cases reported as of mid-April 2020, such as Australia (64 tests per case) and South Korea (52 tests per case) (26,27). This suggests any planning for ongoing control based on isolation and tracing should account for the likely need to conduct at least 30–50 additional tests for each case detected.
Our analysis has several limitations. We focused on individual-level transmission between a primary case and their contacts, rather than considering higher degree network effects. If contacts were clustered (i.e. know each other), it could reduce the number of contacts that need to be traced over multiple generations of transmission. We also assumed that contacts made within the home are the same people daily, but contacts outside home are made independently each day. Repeated contacts would also reduce the number that need to be traced. However, our estimates are consistent with the upper bound of numbers traced in empirical studies (Table 1), as well as analysis of UK social interactions that accounts for higher degree contacts (14). Because our data was not stratified beyond the four contact settings we considered (home, work, school, other), we could not consider further specific settings, e.g. mass gatherings. However, our finding that gatherings in other settings needed to be restricted to relatively small sizes before there was a noticeable impact on transmission is consistent with findings that groups between 10–50 people have a larger impact on SARS-CoV-2 dynamics than groups of more than 50 (28).
Our baseline assumptions were plausible but optimistic. In particular, we assume a delay of symptom onset to isolation of 2.6 days in the baseline scenario, and quarantine that was sufficiently fast to prevent any onwards transmission among successfully traced contacts, with 90% assumed to adhere to quarantine. Based on viral shedding dynamics, this would imply tracing and quarantine within around 2–3 days of exposure (6). We also assumed that routine self-isolation would not increase household transmission. However, our conclusions about onwards transmission in the different control tracing scenarios would not be affected if some limited household transmission did occur, because in these scenarios we assumed that household quarantine would be in place too. We also simulate contact patterns at random for each individual in our population, whereas in an outbreak, there is likely to be a correlation between degree and infection risk; individuals with multiple contacts may be more likely to acquire infection as well as transmit to others (29). If this were the case, and we assume the same secondary attack rates, the overall reduction may be lower than we have estimated; however, to keep the baseline reproduction number consistent, this correlation would have to be offset by a lower SAR among contacts.
Our results highlight the challenges involved in controlling SARS-CoV-2. Consistent with previous modelling studies (7,14) and observed early global outbreak dynamics, our analysis suggests that, depending on the overall effectiveness of testing, tracing, isolation and quarantine, a combination of self-isolation, contact tracing and physical distancing may be required to ensure Reff<1. Further, in a scenario where incidence is high, a considerable number of individuals may need to be quarantined to achieve control using strategies that involve contact tracing.
Supplementary Information
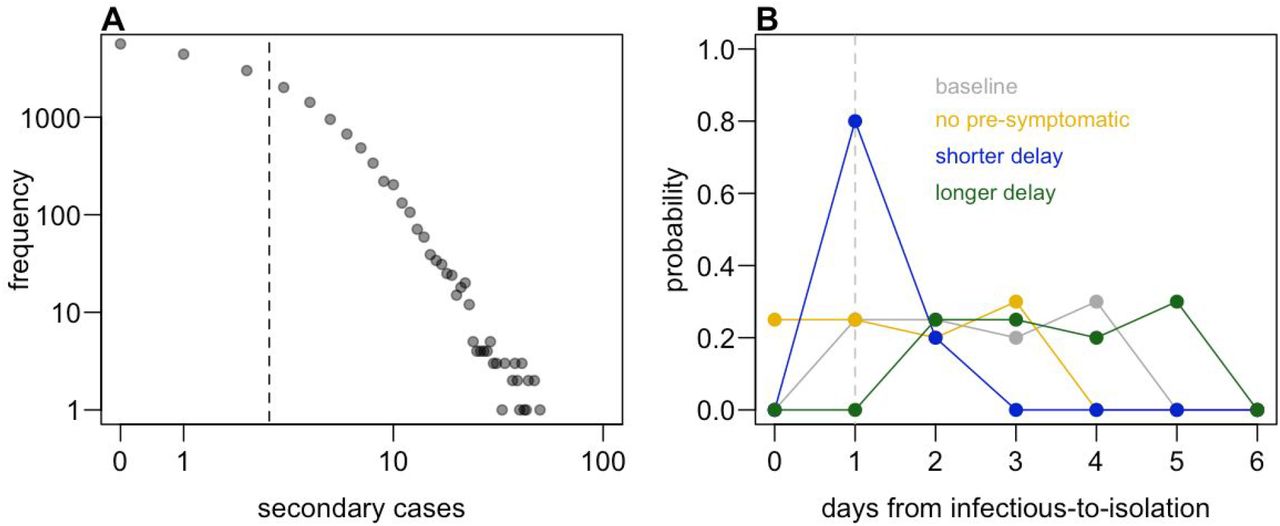
A) Individual-level distribution of secondary transmission in baseline scenario. Dashed line shows mean (i.e. Reff). B) Distribution scenarios for delay from infectious-to-isolation. In scenarios with pre-symptomatic transmission, we assume this period lasts one day; dashed line shows time of onset of symptoms in these scenarios.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
A) Relative reduction in the reproduction number (i.e. ratio between baseline R and R under control measures) when different proportions of the population are symptomatic. B) Relative transmission reduction when asymptomatic individuals have different relative transmission risks compared to symptomatic individuals. Dashed lines show baseline assumption.
Median and 90% prediction interval shown for contacts quarantined. HH SAR=20% and other contact SAR=7% corresponded to baseline Reff=3; HH SAR=40% and other contact SAR=5% corresponded to baseline Reff=2.6.
Assumptions about the distributions of delays shown in Figure S1. Median and 90% prediction interval shown for contacts quarantined.
Footnotes
CMMID COVID-19 working group members (order selected at random): Jon C Emery, Graham Medley, James D Munday, Timothy W Russell, Quentin J Leclerc, Charlie Diamond, Simon R Procter, Amy Gimma, Fiona Yueqian Sun, Hamish P Gibbs, Alicia Rosello, Kevin van Zandvoort, Stéphane Hué, Sophie R Meakin, Arminder K Deol, Gwen Knight, Thibaut Jombart, Anna M Foss, Nikos I Bosse, Katherine E. Atkins, Billy J Quilty, Rachel Lowe, Kiesha Prem, Stefan Flasche, Carl A B Pearson, Rein M G J Houben, Emily S Nightingale, Akira Endo, Damien C Tully, Yang Liu, Julian Villabona-Arenas, Kathleen O’Reilly, Sebastian Funk, Rosalind M Eggo, Mark Jit, Eleanor M Rees, Joel Hellewell, Samuel Clifford, Christopher I Jarvis, Sam Abbott, Megan Auzenbergs, Nicholas G. Davies, David Simons
References




Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
2
Blogs/Media
Author Videos