
Abstract
Coronavirus Disease 2019 (COVID-19) spread globally in early 2020, causing the world to face an existential health crisis. Automated detection of lung infections from computed tomography (CT) images offers a great potential to augment the traditional healthcare strategy for tackling COVID-19. However, segmenting infected regions from CT scans faces several challenges, including high variation in infection characteristics, and low intensity contrast between infections and normal tissues. Further, collecting a large amount of data is impractical within a short time period, inhibiting the training of a deep model. To address these challenges, a novel COVID-19 Lung Infection Segmentation Deep Network (Inf-Net) is proposed to automatically identify infected regions from chest CT scans. In our Inf-Net, a parallel partial decoder is used to aggregate the high-level features and generate a global map. Then, the implicit reverse attention and explicit edge-attention are utilized to model the boundaries and enhance the representations. Moreover, to alleviate the shortage of labeled data, we present a semi-supervised segmentation framework based on a randomly selected propagation strategy, which only requires a few labeled images and leverages primarily unlabeled data. Our semi-supervised framework can improve the learning ability and achieve a higher performance. Extensive experiments on a COVID-19 infection dataset demonstrate that the proposed Inf-Net outperforms most cutting-edge segmentation models and advances the state-of-the-art performance.
I. Introduction
SINCE December 2019, the world has been facing a global health crisis: the pandemic of a novel Coronavirus Disease (COVID-19) [1], [2]. According to the global case count from the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU) [3] (updated April 12th, 2020), 1,777,666 identified cases of COVID-19 have been reported so far, including 108,867 deaths and impacting more than 180 countries/regions. For COVID-19 screening, the reverse-transcription polymerase chain reaction (RT-PCR) has been considered the gold standard. However, the shortage of equipment and strict requirements for testing environments limit the rapid and accurate screening of suspected subjects. Further, RT-PCR testing is also reported to suffer from high false negative rates [4]. As an important complement to RT-PCR tests, the radiological imaging techniques, e.g., X-rays and computed tomography (CT), have also demonstrated effectiveness in both current diagnosis, including follow-up assessment and evaluation of disease evolution [5], [6]. Moreover, a clinical study with 1014 patients in Wuhan China, has shown that chest CT analysis can achieve 0.97 of sensitivity, 0.25 of specificity, and 0.68 of accuracy for the detection of COVID-19, with RT-PCR results for reference [4]. Similar observations were also reported in other studies [7], [8], suggesting that radiological imaging may be helpful in supporting early screening of COVID-19.
Compared to X-rays, CT screening is widely preferred due to its merit and three-dimensional view of the lung. In recent studies [4], [10], the typical signs of infection could be observed from CT scans, e.g., ground-glass opacity (GGO) in the early stage, and pulmonary consolidation in the late stage, as shown in Fig. 1. The qualitative evaluation of infection and longitudinal changes in CT scans could thus provide useful and important information in fighting against COVID-19. However, the manual delineation of lung infections is tedious and time-consuming work. In addition, infection annotation by radiologists is a highly subjective task, often influenced by individual bias and clinical experiences.

Example of COVID-19 infected regions (B) in CT axial slice (A), where the red and green masks denote the GGO and consolidation, respectively. The images are collected from [9].
Recently, deep learning systems have been proposed to detect patients infected with COVID-19 via radiological imaging [6], [15]. For example, a COVID-Net was proposed to detect COVID-19 cases from chest radiography images [16]. An anomaly detection model was designed to assist radiologists in analyzing the vast amounts of chest X-ray images [17]. For CT imaging, a location-attention oriented model was employed in [18] to calculate the infection probability of COVID-19. A weakly-supervised deep learning-based software system was developed in [19] using 3D CT volumes to detect COVID-19. A paper list for COVID19 imaging-based AI works could be found in [20]. Although plenty of AI systems have been proposed to provide assistance in diagnosing COVID-19 in clinical practice, there are only a few works related infection segmentation in CT scans [21], [22]. COVID-19 infection detection in CT scans is still a challenging task, for several issues: 1) The high variation in texture, size and position of infections in CT scans is challenging for detection. For example, consolidations are tiny/small, which easily results in the false-negative detection from a whole CT scans. 2) The inter-class variance is small. For example, GGO boundaries often have low contrast and blurred appearances, making them difficult to identify. 3) Due to the emergency of COVID-19, it is difficult to collect sufficient labeled data within a short time for training deep model. Further, acquiring high-quality pixel-level annotation of lung infections in CT scans is expensive and time-consuming. Table I reports a list of the public COVID-19 imaging datasets, most of which focus on diagnosis, with only one dataset providing segmentation labels.
To address above issues, we propose a novel COVID-19 Lung Infection Segmentation Deep Network (Inf-Net) for CT Scans. Our motivation stems from the fact that, during lung infection detection, clinicians first roughly locate an infected region and then accurately extract its contour according to the local appearances. We therefore argue that the area and boundary are two key characteristics that distinguish normal tissues and infection. Thus, our Inf-Net first predicts the coarse areas and then implicitly models the boundaries by means of reverse attention and edge constraint guidance to explicitly enhance the boundary identification. Moreover, to alleviate the shortage of labeled data, we also provide a semi-supervised segmentation system, which only requires a few labeled COVID-19 infection images and then enables the model to leverage unlabeled data. Specifically, our semi-supervised system utilizes a randomly selected propagation of unlabeled data to improve the learning capability and obtain a higher performance than some cutting edge models. In a nutshell, our contributions in this paper are threefold:
A summary of public COVID-19 imaging datasets. #Cov and #Non-COV denote the numbers of COVID-19 and Non-COVID-19 cases. † denotes the number is presented from corresponding github link.
We present a novel COVID-19 Lung Infection Segmentation Deep Network (Inf-Net) for CT Scans. By aggregating features from high-level layers using a parallel partial decoder (PPD), the combined feature takes contextual information and generates a global map as the initial guidance areas for the subsequent steps. To further mine the boundary cues, we leverage a set of implicitly recurrent reverse attention (RA) modules and explicit edge-attention guidance to establish the relationship between areas and boundary cues.
A semi-supervised segmentation system for COVID-19 infection segmentation is introduced to alleviate the short-age of labeled data. Based on a randomly selected propagation, our semi-supervised system has better learning ability (see § IV).
We also build a semi-supervised COVID-19 infection segmentation (COVID-SemiSeg) dataset, with 100 labeled CT scans from the COVID-19 CT Segmentation dataset [9] and 1600 unlabeled images from the COVID-19 CT Collection dataset [11]. Extensive experiments on this dataset demonstrate that the proposed Inf-Net and Semi-Inf-Net outperform most cutting-edge segmentation models and advances the state-of-the-art performance. The code and dataset will be released at: https://github.com/DengPingFan/Inf-Net
II. Related works
In this section, we discuss three types of works that are most related to our work, including: segmentation in chest CT, semi-supervised learning, and artificial intelligence for COVID-19.
A. Segmentation in Chest CT
CT imaging is a popular technique for the diagnosis of lung diseases [23], [24]. In practice, segmenting different organs and lesions from chest CT scans can provide crucial information for doctors to diagnose and quantify lung diseases [25], [26]. Recently, many works have been provided and obtained promising performances. These algorithms often employ a classifier with extracted features for nodule segmentation in chest CT. For example, Keshani et al. [27] utilized the support vector machine (SVM) classifier to detect the lung nodule from CT scans. Shen et al. [28] presented an automated lung segmentation system based on bidirectional chain code to improve the performance. However, the similar visual appearances of nodules and background makes it difficult for extracting the nodule regions. To overcome this issue, several deep learning algorithms have been proposed to learn a powerful visual representations [29]–[31]. For instance, Wang et al. [29] developed a central focused convolutional neural network to segment lung nodules from heterogeneous CT scans. Jin et al. [30] utilized GAN-synthesized data to improve the training of a discriminative model for pathological lung segmentation. Jiang et al. [31] designed two deep networks to segment lung tumors from CT scans by adding multiple residual streams of varying resolutions.
B. Semi-supervised Learning
Due to the challenge in obtaining full labels for large-scale data, more attention has been drawn to semi-supervised learning (SSL), and the main goal of SSL is to improve model performance using a limited number of labeled data and a large amount of unlabeled data [32]. Currently, there is increasing focus on training deep neural network using the SSL strategy [33]. These methods often optimize a supervised loss on labeled data along with an unsupervised loss imposed on either unlabeled data [34] or both the labeled and unlabeled data [35], [36]. Lee et al. [34] provided to utilize a cross-entropy loss by computing on the pseudo labels of unlabeled data, which is considered as an additional supervision loss. In summary, existing deep SSL algorithms regularize the network by enforcing smooth and consistent classification boundaries, which are robust to a random perturbation [36], and other approaches enrich the supervision signals by exploring the knowledge learned, e.g., based on the temporally ensembled prediction [35] and pseudo label [34].
C. Artificial Intelligence for COVID-19
Artificial intelligence technologies have been employed in a large number of applications against COVID-19 [6], [15]. Joseph et al. [15] categorized these applications into three scales, including patient scale (e.g., medical imaging for diagnosis [37], [38]), molecular scale (e.g., protein structure prediction [39]), and societal scale (e.g., epidemiology [40]). In this work, we focus on patient scale applications [18], [22], [37], [38], [41]–[44], especially those based on CT scans. For instance, Wang et al. [37] proposed a modified inception neural network [45] for classifying COVID-19 patients and normal controls. Instead of directly training on complete CT images, they trained the network on the regions of interest, which are identified by two radiologists based on the features of pneumonia. Chen et al. [38] collected 46,096 CT image slices from COVID-19 patients and control patients of other disease. The CT images collected were utilized to train a U-Net++ [46] for identifying COVID-19 patients. Their experimental results suggest that the trained model performs comparably with expert radiologists in terms of COVID-19 diagnosis. In addition, other network architectures have also been considered in developing AI-assisted COVID-19 diagnosis systems. Typical examples include ResNet, used in [18], [41], and U-Net [47], used in [42]. Finally, deep learning has been employed to segment the infection regions in lung CT scans so that the resulting quantitative features can be utilized for severity assessment [43], large-scale screening [44], and lung infection quantification [15], [21], [22] of COVID-19.
III. Proposed Method
In this section, we first provide details of our Inf-Net in terms of network architecture, core network components, and loss function. We then present the semi-supervised version of Inf-Net and clarify how to use a semi-supervised learning framework to enlarge the limited number of training samples for improving the segmentation accuracy. We also show an extension of our framework for the multi-class labeling of different types of lung infections. Finally, we provide the implementation details.
A. Lung Infection Segmentation Network (Inf-Net)
Overview of Network
The architecture of our Inf-Net is shown in Fig. 2. As can be observed, CT images are first fed to two convolutional layers to extract high-resolution, semantically weak (i.e., low-level) features. Herein, we add an edge attention module to explicitly improve the representation of objective region boundaries. Then, the low-level features f2 obtained are fed to three convolutional layers for extracting the high-level features, which are used for two purposes. First, we utilize a parallel partial decoder (PPD) to aggregate these features and generate a global map Sg for the coarse localization of lung infections. Second, these features combined with f2 are fed to multiple reverse attention (RA) modules under the guidance of the Sg. It is worth noting that the RA modules are organized in a cascaded fashion. For instance, as shown in Fig. 2, R4 relies on the output of another RA R5. Finally, the output of the last RA, i.e., S3, is fed to a sigmoid activation function for the final prediction of lung infection regions. We now detail the key components of Inf-Net and our loss function.

The architecture of our proposed Inf-Net model, which consists of three reverse attention (RA) modules connected to the paralleled partial decoder (PPD). See § III-A for details.
Edge Attention Module
Several works have shown that edge information can provide useful constraints to guide feature extraction for segmentation [48]–[50]. Thus, considering that the low-level features (e.g., f2 in our model) preserve some sufficient edge information, we feed the low-level feature f2 with moderate resolution to the proposed edge attention (EA) module to explicitly learn an edge-attention representation. Specifically, the feature f2 is fed to a convolutional layer with one filter to produce the edge map. Then, we can measure the dissimilarity of the EA module between the produced edge map and the edge map Ge derived from the ground-truth (GT), which is constrained by the standard Binary Cross Entropy (BCE) loss function:
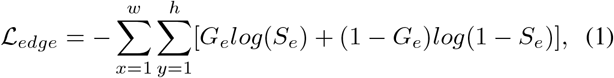 where (x, y) are the coordinates of each pixel in the predicted edge map Se and edge ground-truth map Ge. The Ge is calculated using the gradient of the ground-truth map Gs. Additionally, w and h denote the width and height of corresponding map, respectively.
where (x, y) are the coordinates of each pixel in the predicted edge map Se and edge ground-truth map Ge. The Ge is calculated using the gradient of the ground-truth map Gs. Additionally, w and h denote the width and height of corresponding map, respectively.
Parallel Partial Decoder
Most existing medical image segmentation networks, e.g., U-Net [47], U-Net++ [46], etc, segment interested organs/lesions using all high- and low-level features in the encoder branch. However, Wu et al. [51] pointed out that, compared with high-level features, low-level features demand more computational resources due to larger spatial resolutions, but contribute less to the performance. Inspired by this observation, we propose to only aggregate high-level features with a parallel partial decoder component. Specifically, for an input CT image I, we first extract two sets of low-level features {fi, i = 1, 2} and three sets of high-level features {fi, i = 3, 4, 5} using the first five convolutional blocks of Res2Net [52]. We then utilize the partial decoder pd() [51], a novel decoder component, to aggregate the high-level features with a paralleled connection. The partial decoder yields a coarse global map Sg = pd(f3, f4, f5), which then serves as global guidance in our RA modules.
Reverse Attention Module
In clinical practice, clinicians usually segment lung infection regions via a two-step procedure, by roughly localizing the infection regions and then accurately labeling these regions by inspecting the local tissue structures. Inspired by this procedure, we design Inf-Net using two different network components that act as a rough locator and a fine labeler, respectively. First, the PPD acts as the rough locator and yields a global map Sg, which provides the rough location of lung infection regions, without structural details (see Fig. 2). Second, we propose a progressive framework, acting as the fine labeler, to mine discriminative infection regions in an erasing manner [53], [54]. Specifically, instead of simply aggregating features from all levels [54], we propose to adaptively learn the reverse attention in three parallel high-level features. Our architecture can sequentially exploit complementary regions and details by erasing the estimated infection regions from high-level side-output features, where the existing estimation is up-sampled from the deeper layer.
We obtain the output RA features Ri by multiplying (element-wise ⊙) the fusion of high-level side-output features {fi, i = 3, 4, 5} and edge attention features eatt = f2 with RA weights Ai, i.e.,
 where Dow(·)denotes the down-sampling operation, 𝒞 (·) denotes the concatenation operation follow by two 2-D convolutional layers with 64 filters.
where Dow(·)denotes the down-sampling operation, 𝒞 (·) denotes the concatenation operation follow by two 2-D convolutional layers with 64 filters.
The RA weight Ai is de-facto for salient object detection in the computer vision community [54], and it is defined as:
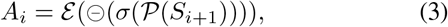 where 𝒫 (·) denotes an up-sampling operation, σ(·) is a sigmoid activation function, and ⊝ (·) is a reverse operation subtracting the input from matrix E, in which all the elements are 1. Symbol denotes ε expanding a single channel feature to 64 repeated tensors, which involves reversing each channel of the candidate tensor in Eq. (2). Details of this procedure are shown in Fig. 3. It is worth noting that the erasing strategy driven by RA can eventually refine the imprecise and coarse estimation into an accurate and complete prediction map.
where 𝒫 (·) denotes an up-sampling operation, σ(·) is a sigmoid activation function, and ⊝ (·) is a reverse operation subtracting the input from matrix E, in which all the elements are 1. Symbol denotes ε expanding a single channel feature to 64 repeated tensors, which involves reversing each channel of the candidate tensor in Eq. (2). Details of this procedure are shown in Fig. 3. It is worth noting that the erasing strategy driven by RA can eventually refine the imprecise and coarse estimation into an accurate and complete prediction map.

Reverse Attention Module is utilized to implicitly learning edge features.
Loss Function
As mentioned above in Eq. (1), we propose the loss function ℒ edge for edge supervision. Here, we define our loss function ℒ seg as a combination of a weighted IoU loss 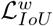 and a weighted binary cross entropy (BCE) loss
and a weighted binary cross entropy (BCE) loss 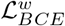 for each segmentation supervision, i.e.,
for each segmentation supervision, i.e.,

The two parts of ℒ seg provide effective global (image-level) and local (pixel-level) supervision for accurate segmentation. Unlike the standard IoU loss, which has been widely adopted in segmentation tasks, the weighted IoU loss increases the weights of hard pixels to highlight their importance. In addition, compared with the standard BCE loss,  puts more emphasis on hard pixels rather than assigning all pixels equal weights. The definitions of these losses are the same as in [55], [56] and their effectiveness has been validated in the field of salient object detection.
puts more emphasis on hard pixels rather than assigning all pixels equal weights. The definitions of these losses are the same as in [55], [56] and their effectiveness has been validated in the field of salient object detection.
Finally, we adopt deep supervision for the three side-outputs (i.e., S3, S4, and S5) and the global map Sg. Each map is up-sampled (e.g.,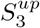 ) to the same size as the object-level segmentation ground-truth map Gs. Thus, the total loss in Eq. (4) is extended to
) to the same size as the object-level segmentation ground-truth map Gs. Thus, the total loss in Eq. (4) is extended to

B. Semi-Supervised Inf-Net
Currently, there is very limited number of CT images with segmentation annotations, since manually segmenting lung infection regions are difficult and time-consuming, and the disease is at an early stage of outbreak. To resolve this issue, we improve Inf-Net using a semi-supervised learning strategy, which leverages a large number of unlabeled CT images to effectively augment the training dataset. An overview of our semi-supervised learning framework is shown in Fig. 4. Our framework is mainly inspired by the work in [57], which is based on a random sampling strategy for progressively enlarging the training dataset with unlabeled data. Specifically, we generate the pseudo labels for unlabeled CT images using the procedure described in Algorithm 1. The resulting CT images with pseudo labels are then utilized to train our model using a two-step strategy detailed in Section III-D.


Overview of the proposed Semi-supervised Inf-Net framework. Please refer to § III-B for more details.
The advantages of our framework, called Semi-Inf-Net, lie in two aspects. First, the training and selection strategy is simple and easy to implement. It does not require measures to assess the predicted label, and it is also threshold-free. Second, this strategy can provide more robust performance than other semi-supervised learning methods and prevent over-fitting. This conclusion is confirmed by recently released studies [57].
C. Extension to Multi-Class Infection Labeling
Our Semi-Inf-Net is a powerful tool that can provide crucial information for evaluating overall lung infections. However, we are aware that, in a clinical setting, in addition to the overall evaluation, clinicians might also be interested in the quantitative evaluation of different kinds of lung infections, e.g., GGO and consolidation. Therefore, we extend Semi-Inf-Net to a multi-class lung infection labeling framework so that it can provide richer information for the further diagnosis and treatment of COVID-19. The extension of Semi-Inf-Net is based on an infection region guided multi-class labeling framework, which is illustrated in Fig. 5. Specifically, we utilize the infection segmentation results provided by Semi-Inf-Net to guide the multi-class labeling of different types of lung infections. For this purpose, we feed both the infection segmentation results and the corresponding CT images to a multi-class labeling network (FCN8s [58] in our case, which is popular in medical image segmentation tasks [59], [60]). This framework can take full advantage of the infection segmentation results provided by Semi-Inf-Net and effectively improve the performance of multi-class infection labeling.

Illustration of infection region guided FCN8s [58] for multi-class labeling task. We feed both the infection segmentation results provided by Inf-Net and the CT images into FCN8s for improving the accuracy of multi-class infection labeling.
D. Implementation Details
Our model is implemented in PyTorch, and is accelerated by an NVIDIA TITAN RTX GPU. We describe the implementation details as follows.
Pseudo label generation
We generate pseudo labels for unlabeled CT images using the protocol described in Algorithm 1. The number of randomly selected CT images is set to 5, i.e., K = 5. For 1600 unlabeled images, we need to perform 320 iterations with a batch size of 16. The entire procedure takes about 50 hours to complete.
Semi-supervised Inf-Net
Before training, we uniformly resize all the inputs to 352×352. We train Inf-Net using a multi-scale strategy with different scale ratios 0.75, 1, 1.25. The Adam optimizer is employed for training and the learning rate is set to 1e−4. Our training phase consists of two steps: (i) Pre-training on 1600 CT images with pseudo labels, which takes about 180 minutes to converge over 100 epochs with a batch size of 24. (ii) Fine-tuning on 50 CT images with the ground-truth labels, which takes about 15 minutes to converge over 100 epochs with a batch size of 16. For a fair comparison, the training procedure of Inf-Net follows the same setting described in the second step.
Semi-Inf-Net+FCN8s
Follow the default settings of FCN8s [58], we resize all the inputs to 512×512 before training. The network is initialized by a uniform Xavier, and trained using an SGD optimizer with a learning rate of 1e−10, weight decay of 5e−4, and momentum of 0.99. The entire training procedure takes about 45 minutes to complete.
IV. Experiments
A. COVID-19 Segmentation Dataset
As shown in Table I, there is only one segmentation dataset for CT data, i.e., the COVID-19 CT Segmentation dataset [9]1, which consists of 100 axial CT images from different COVID-19 patients. All the CT images were collected by the Italian Society of Medical and Interventional Radiology, and are available at here2. A radiologist segmented the CT images using different labels for identifying lung infections. Although this is the first open-access COVID-19 dataset for lung infection segmentation, it suffers from a small sample size, i.e., only 100 labeled images are available.
Quantitative results of infection regions on our COVID-SemiSeg dataset. The best two results are shown in red and blue fonts.
In this work, we collected a semi-supervised COVID-19 infection segmentation dataset (COVID-SemiSeg), to leverage large-scale unlabeled CT images for augmenting the training dataset. We employ COVID-19 CT Segmentation [9] as the labeled data 𝒟Labeled, which consists of 45 CT images randomly selected as training samples, 5 CT images for validation, and the remaining 50 images for testing. The unlabeled CT images are extracted from the COVID-19 CT Collection [11] dataset, which consists of 20 CT volumes from different COVID-19 patients. We extracted 1,600 2D CT axial slices from the 3D volumes, removed non-lung regions, and constructed an unlabeled training dataset 𝒟Unlabeled for effective semi-supervised segmentation.
B. Experimental Settings
Baselines
For the infection region experiments, we compare the proposed Inf-Net and Semi-Inf-Net with two classical segmentation models in the medical domain, i.e., U-Net [47] and U-Net++ [46]. For the multi-class labeling experiments, we compare our model with two cutting-edge models from the computer vision community: DeepLabV3+ [61] and FCN8s [58].
Evaluation Metrics
Following [22], [44], we use three widely adopted metrics, i.e., the Dice similarity coefficient, Sensitivity (Sen.), and Specificity (Spec.). We also introduce three golden metrics from the object detection field, i.e., Structure Measure [62], Enhance-alignment Measure [63], and Mean Absolute Error. In our evaluation, we choose S3 with sigmoid function as the final prediction Sp. Thus, we measure the similarity/dissimilarity between final the prediction map and object-level segmentation ground-truth G, which can be formulated as follows:
1) Structure Measure (Sα)
This was proposed to measure the structural similarity between a prediction map and ground-truth mask, which is more consistent with the human visual system:
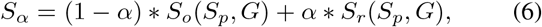 where α is a balance factor between object-aware similarity So and region-aware similarity Sr. We report Sα using the default setting (α = 0.5) suggested in the original paper [62].
where α is a balance factor between object-aware similarity So and region-aware similarity Sr. We report Sα using the default setting (α = 0.5) suggested in the original paper [62].
2) Enhanced-alignment Measure 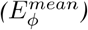 : This is a recently proposed metric for evaluating both local and global similarity between two binary maps. The formulation is as follows:
: This is a recently proposed metric for evaluating both local and global similarity between two binary maps. The formulation is as follows:
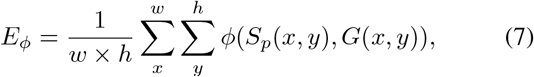 where w and h are the width and height of ground-truth G, and (x, y) denotes the coordinate of each pixel in G. Symbol ϕ is the enhanced alignment matrix. We obtain a set of Eϕ by converting the prediction Sp into a binary mask with a threshold from 0 to 255. In our experiments, we report the mean of Eξ computed from all the thresholds.
where w and h are the width and height of ground-truth G, and (x, y) denotes the coordinate of each pixel in G. Symbol ϕ is the enhanced alignment matrix. We obtain a set of Eϕ by converting the prediction Sp into a binary mask with a threshold from 0 to 255. In our experiments, we report the mean of Eξ computed from all the thresholds.
3) Mean Absolute Error (MAE)
This measures the pixel-wise error between Sp and G, which is defined as:
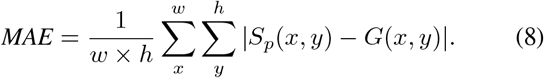
C. Segmentation Results
1) Quantitative Results
To compare the infection segmentation performance, we consider the two state-of-the-art models U-Net and U-Net++. Quantitative results are shown in Table II. As can be seen, the proposed Inf-Net outperforms U-Net and U-Net++ in terms of Dice, Sα,  , and MAE by a large margin. We attribute this improvement to our implicit reverse attention and explicit edge-attention modeling, which provide robust feature representations. In addition, by introducing the semi-supervised learning strategy into our framework, we can further boost the performance with a 5.7% improvement in terms of Dice.
, and MAE by a large margin. We attribute this improvement to our implicit reverse attention and explicit edge-attention modeling, which provide robust feature representations. In addition, by introducing the semi-supervised learning strategy into our framework, we can further boost the performance with a 5.7% improvement in terms of Dice.
Quantitative results of ground-glass opacities and consolidation on our COVID-SemiSeg dataset. the best two results are shown in red and blue fonts.
As an assistant diagnostic tool, the model is expected to provide more detailed information regarding the infected areas. Therefore, we extent to our model to the multi-class (i.e., GGO and consolidation segmentation) labeling. Table III shows the quantitative evaluation on our COVID-SemiSeg dataset, which indicate that our Semi-Inf-Net&FCN8s pipeline achieves the state-of-the-art performance on GGO segmentation in most evaluation metrics. For more challenging consolidation segmentation, the proposed pipeline also achieves competitive results. For instance, in terms of Dice, our method outper-forms the cutting-edge model, FCN8s, by 1.7%. Overall, the proposed pipeline performs better than existing state-of-the-art models on multi-class labeling in terms of Dice, Sα, 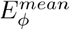 , and MAE. Our method also performs very well in the specificity metric. However, for the sensitivity metric, our model still has room for improvement.
, and MAE. Our method also performs very well in the specificity metric. However, for the sensitivity metric, our model still has room for improvement.
2) Qualitative Results
The lung infection segmentation results, shown in Fig. 6, indicate that our Semi-Inf-Net and Inf-Net outperform the baseline methods remarkably. Specifically, they yield segmentation results that are close to the ground truth with much less mis-segmented tissue. In contrast, U-Net gives unsatisfactory results, where a large number of mis-segmented tissues exist. U-Net++ improves the results, but the performance is still not promising. The success of Inf-Net is owed to our coarse-to-fine segmentation strategy, where a parallel partial decoder first roughly locates lung infection regions and then multiple edge attention modules are employed for fine segmentation. This strategy mimics how real clinicians segment lung infection regions from CT scans, and therefore achieves promising performance. In addition, the advantage of our semi-supervised learning strategy is also confirmed by Fig. 6. As can be observed, compared with Inf-Net, Semi-Inf-Net yields segmentation results with more accurate boundaries. In contrast, Inf-Net gives relatively fuzzy boundaries, especially in the subtle infection regions.

Visual comparison of lung infection segmentation results.
We also show the multi-class infection labeling results in Fig. 7. As can be observed, our model, Semi-Inf-Net & FCN8s, consistently performs the best among all methods. It is worth noting that both GGO and consolidation infections are accurately segmented by Semi-Inf-Net & FCN8s, which further demonstrates the advantage of our model. In contrast, the baseline methods, DeepLabV3+ with different strides and FCNs, all obtain unsatisfactory results, where neither GGO and consolidation infections can be accurately segmented.

Visual comparison of multi-class lung infection segmentation results, where the red and green labels indicate the GGO and consolidation, respectively.
D. Ablation Study
In this subsection, we conduct several experiments to validate the performance of each key component of our Semi-Inf-Net, including the PPD, RA, and EA modules.
1) Effectiveness of PPD
To explore the contribution of the parallel partial decoder, we derive two baselines: No.1 (back-bone only) & No.2 (backbone+PPD) in Table IV. The results clearly show that PPD is necessary for boosting performance.
Ablation studies of our Semi-Inf-Net. The best two results are shown in red and blue fonts.
2) Effectiveness of RA
We investigate the importance of the RA module. From Table IV, we observe that No.3 (back-bone + RA) increases the backbone performance (No.1) in terms of major metrics, e.g., Dice, Sensitivity, MAE, etc. This suggests that introducing the RA component can enable our model to accurately distinguish true infected areas.
3) Effectiveness of PPD & RA
We also investigate the importance of the combination of the PPD and RA component (No.4). As shown in Table IV, No.4 performs better than other settings (i.e., No.1∼No.3) in most metrics. These improvements demonstrate that the reverse attention together with the parallel partial decoder are the two central components responsible for the good performance of Inf-Net.
4) Effectiveness of EA
Finally, we investigate the importance of the EA module. As shown in Table IV, No.5 performances better than the setting (i.e., No.4) in most of metrics. This improvement validates that EA module further improves the segmentation performance in our Inf-Net.
V. Conclusion
In this paper, we have proposed a novel COVID-19 lung CT infection segmentation network, named Inf-Net, which utilizes an implicit reverse attention and explicit edge-attention to improve the identification of infected regions. Moreover, we have also provided a semi-supervised solution, Semi-Inf-Net, to alleviate the shortage of high quality labeled data. Extensive experiments on our COVID-SemiSeg dataset have demonstrated that the proposed Inf-Net and Semi-Inf-Net out-perform the cutting-edge segmentation models and advance the state-of-the-art performances. Our system has great potential to be applied in assessing the diagnosis of COVID-19, e.g., quantifying the infected regions, monitoring the longitudinal disease changes, and mass screening processing.
Data Availability
Data and code could be found in: https://github.com/DengPingFan/Inf-Net
Footnotes
(e-mail: dengpfan{at}gmail.com), (e-mail:gepengai.ji{at}gmail.com), (e-mails: {tao.zhou{at}inceptioniai.org, yi.zhou{at}inceptioniai.org, ling.shao{at}inceptioniai.org})
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].
- [13].
- [14].
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}