
Abstract
Background COVID-19 diagnosis is a critical problem, mainly due to the lack or delay in the test results. We aimed to obtain a model to predict SARS-CoV-2 infection in suspected patients reported to the Brazilian surveillance system.
Methods We analyzed suspected patients reported to the National Surveillance System that corresponded to the following case definition: patients with respiratory symptoms and fever, who traveled to regions with local or community transmission or who had close contact with a suspected or confirmed case. Based on variables routinely collected, we obtained a multiple model using logistic regression. The area under the receiver operating characteristic curve (AUC) and accuracy indicators were used for validation.
Results We described 1468 COVID-19 cases (confirmed by RT-PCR) and 4271 patients with other illnesses. With a data subset, including 80% of patients from Sao Paulo (SP) and Rio Janeiro (RJ), we obtained a function which reached an AUC of 95.54% (95% CI: 94.41% - 96.67%) for the diagnosis of COVID-19 and accuracy of 90.1% (sensitivity 87.62% and specificity 92.02%). In a validation dataset including the other 20% of patients from SP and RJ, this model exhibited an AUC of 95.01% (92.51% – 97.5%) and accuracy of 89.47% (sensitivity 87.32% and specificity 91.36%).
Conclusion We obtained a model suitable for the clinical diagnosis of COVID-19 based on routinely collected surveillance data. Applications of this tool include early identification for specific treatment and isolation, rational use of laboratory tests, and input for modeling epidemiological trends.
Introduction
The pandemic caused by the novel coronavirus, Sars-Cov-2, challenges the capabilities of health care services, especially in low- and middle-income countries.1 A major issue is to meet the diagnostic requirements of the suspected cases reported to the surveillance system.2 The proportion of suspected cases being tested in each country is not systematically presented in most of the epidemiological reports.3–5 However, with the increasing number of new suspected cases of the disease (COVID-19) worldwide, diagnosis has clearly become a growing problem, mainly due to the lack or delay in the test results.6,7
Clinical manifestations of COVID-19 are unspecific and include respiratory symptoms, fever, cough, dyspnea, and viral pneumonia.8,9 Polymerase chain reaction by real-time reverse transcriptase (RT-PCR) is considered the gold standard for the diagnosis of SARS-CoV-2 infection. However, its limited availability and the strict laboratory requirements delay diagnosis, which represents an unprecedented challenge to control transmission and provide timely health care.10,11
The incorporation of predictive diagnostic models based on surveillance data could help identify patients who could need specific treatment and early isolation. Consequently, we aimed to describe the profile of COVID-19 patients and to obtain a multiple model to predict the diagnosis among suspected cases reported in Brazil based on data routinely collected by the surveillance system.
Materials and methods
Study design and population
This observational study corresponded to a developing and evaluation of diagnostic technologies, nested in surveillance data obtained by the Brazilian Ministry of Health. We studied the reported cases, which corresponded to the following case definition: patients with respiratory symptoms and fever, who had traveled to regions with community or local transmission or who had close contact with a suspected or confirmed case. We did not establish restrictions based on age or underlying conditions for this study. Records with inconsistent or illogical data were excluded.
Procedures
We included the patients reported between 11/01/2020 and 25/03/2020. All data were collected from the national surveillance information form, created on RedCap® platform, which included demographic, temporal, and easy to obtain clinical information such as symptoms, signs, comorbidities, travel history, and contact information. Another variable considered was the time since notification of the first case that was subsequently confirmed in the corresponding Federal Unit (FU). In the FU without notification and for its first confirmed case, this variable was zero.
During the period of data collection analyzed, the ministry’s recommendation was to test all suspected cases, according to the definition presented above.12 SARS-CoV-2 infection was considered confirmed only by Real-time reverse-transcriptase polymerase chain reaction RT-PCR testing, following the WHO and CDC protocol result for pharyngeal swab specimens.11 Because the study population refers to symptomatic cases, in this paper we used the terms SARS-CoV-2 infection and COVID-19 interchangeably.
Data analysis
Demographic and clinical information was entered in an electronic database and then analyzed using Excel and STATA (version 15.0, Stata Corp LP, College Station, TX, USA). Data analysis included a description of the manifestations of the disease, according to etiology (COVID-19 vs. other illnesses [OI]). After descriptive analysis, the most functional form of the available variables was sought. This included the evaluation of composite variables for categorical predictors and the evaluation of the linear relationship between quantitative variables and the frequency of the outcome. Age showed a biological gradient with COVID-19; therefore, a simple imputation was made for cases with missing values of this variable, considering the frequency of the diagnosis. Thus, the value of 37.38 years was calculated to impute unregistered age (in 1.4% of patients with etiological diagnosis).
The information from São Paulo (SP) and Rio de Janeiro (RJ) was used to obtain and validate the predictive model. This choice was because these are the FUs with the largest number of confirmed cases and the earliest establishment of the surveillance system. Thus, we used a subset of 80% of randomly selected patients from SP and RJ (modeling dataset) to specify the multiple model. We selected the covariates by a non-automatic stepwise procedure using logistic regression. Age and days after notification of the first confirmed case (DNFCC) were used to create interaction terms with each other as an independent predictor. During modeling, a p-value of 0.15 was considered as a criterium to enter the variable and 0.20 to exclude it. After evaluating all the variables, exclusions were made until obtaining a model including only covariates with p <0.10.
The values predicted by the multiple model obtained were used to estimate the area under the ROC curve (AUC). We interpreted the AUC as an indicator of goodness of fit such that values between 0.9 and 0.99 are excellent, 0.8 – 0.89 good, 0.7 – 0.79 acceptable, and 0.51 – 0.69 are poor.13 Next, the model was applied to the 20% of patients from SP and RJ who were not included in the modeling dataset (validation dataset). Moreover, we applied it to those from FUs other than SP/RJ to evaluate the applicability in a very different scenario. We also calculated the accuracy to classify events of a predicted probability of ≥0.5.14
We presented some cut-off points of the predicted value based on optimized accuracy indicators (in SP/RJ patients). These cut-offs included: a preset predicted value of 0.5; the highest value with a sensitivity >95%; the lowest with specificity >95%; the value with the highest overall accuracy; and the value with the best balance between sensitivity and specificity (based on the product thereof). Accuracy indicators of these selected cutoffs were described for both the SP/RJ patients (modeling + validation dataset) and those from the other FUs.
Finally, by applying the sum of the predicted values and by using the chosen cut-off points, we calculated the probable number of COVID-19 cases in the total reported patients and among those who were reported as being hospitalized.
Results
Until March 25, 2020, the surveillance system had received 67,344 records of suspected cases, including 5674 with registered hospitalization. Of the total, 165 records were excluded because of inconsistent data. Overall, 5739 were tested by RT-PCR, of which 1468 were positive and 4271 negative.
COVID-19 cases were older and more frequently men compared with OI patients (Table 1). COVID-19 patients were reported in median 16 days after the first confirmed case, which was significantly later than OI patients were (median of seven days). Both age and time from the first confirmed case exhibited a gradient for the COVID-19 frequency (Figures 1 and 2).
Comparison of COVID-19 patients and other illnesses (OI) reported to the Brazilian surveillance system.


Most of the clinical manifestations were more frequent in OI patients than COVID-19 in the univariable analysis. Only the myalgia or arthralgia variable was significantly more frequent in COVID-19 than OI (30.7% vs. 23%, p<0.001). No COVID-19 infections were observed among patients with liver disease or among those that claimed not to have been in contact with a suspected case. On the other hand, COVID-19 patients less frequently referred to making a trip outside Brazil in the last 14 days (Table 1).
Multiple model
The states of SP and RJ jointly had 683 confirmed COVID-19 cases and 864 with OI, of which 541 and 702 were included in the modeling dataset, respectively. During the modeling, patients with liver disease (n = 4) and those who reported not having had contact with a suspected case (n = 69) were not considered, as these categories perfectly predicted absence of COVID-19 and were significantly more frequent in the OI group (Table 1).
We obtained a model integrating 15 covariates, including age, days from notification of the first confirmed case (DNFCC) in the corresponding FU, eight variables about clinical manifestations, two on comorbidities, trip history, and two interaction terms (Table 2). The AUC of this multiple model was estimated at 95.36% (95% CI: 94.2 – 96.52%) with an accuracy of 89.5%.
Predictive model for COVID-19 diagnoses among reported patients
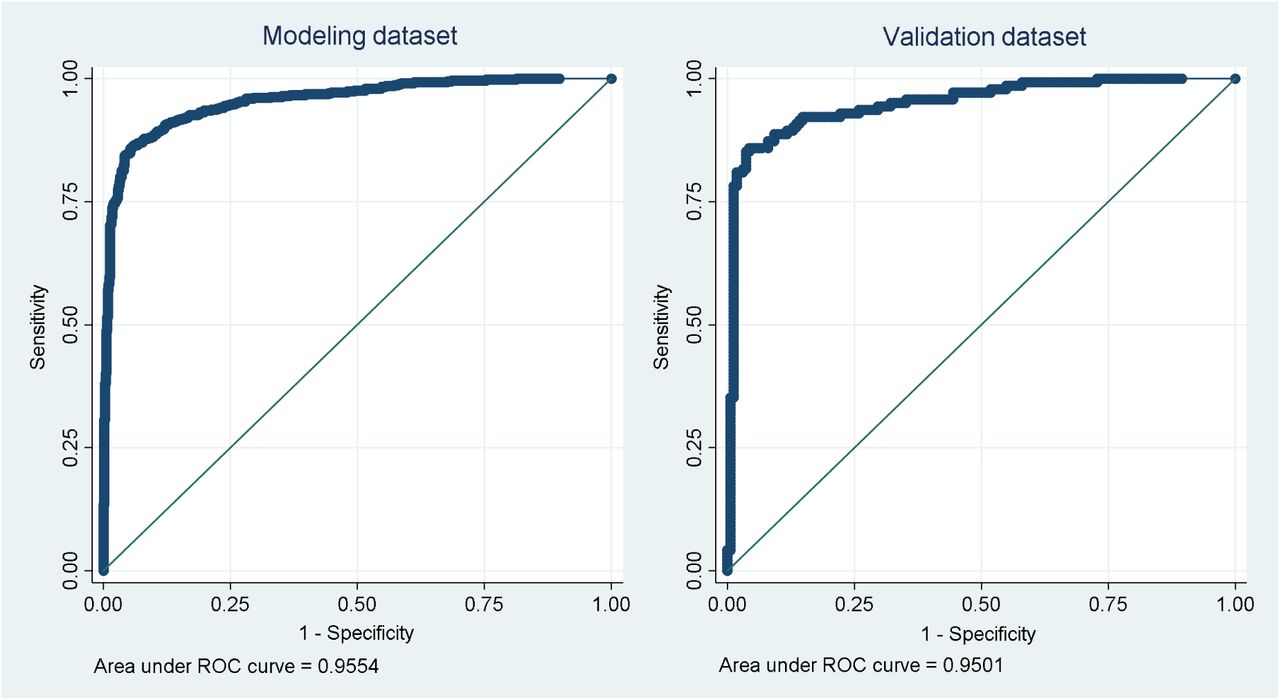
To obtain the final function, patients with a history of liver disease and those who denied having had any contact with a suspected case were considered with a predicted value equal to zero. With this inclusion, the area was 95.54% (95% CI: 94.41% – 96.67%) for the diagnosis of COVID-19 in the modeling dataset and 95.01% (92.51% – 97.5%) in the validation dataset (Figure 3). Accuracy in these datasets was 90.1% (sensitivity 87.62% and specificity 92.02%) and 89.47% (sensitivity 87.32% and specificity 91.36%), respectively.
{kind=link}
{kind=link}
{kind=link}
When this function was applied in patients from the other FUs, which included 785 cases of COVID-19 compared with 3407 with other diseases, the ROC area was 73.16% (95% CI: 71.35 – 74.96%), and the accuracy was 73.43% (sensitivity 46.37% and specificity 79.66%). In table 4, we described the diagnostic accuracy indicators of selected predicted-value cutoffs in both the SP/RJ and the other FU groups.
Diagnostic accuracy indicators of the selected predicted-value cutoff.
Predicted cases and under-confirmation estimates of COVID-19 among suspected patients reported in Brazil, according to criteria based on the clinical predictive model.
Considering the sum of predicted values as well as the different cutoffs, the number of COVID-19 cases among reported patients (adding together confirmed and predicted by our model) would be between 22826 and 25190 in SP/RJ, and between 22704 and 28837 in other FUs. Of them, between 2050 and 2196 were hospitalized in SP or RJ, and between 1657 and 2196 in the other FUs. All the calculations suggested that more than 95% of COVID-19 cases have not been confirmed.
Discussion
The growing number of cases suspected of COVID-19 is alarming.15 Moreover, we observed that only a small proportion of the cases have a laboratory study. Therefore, most cases are being left with an uncertain diagnosis, which limits establishing specific measures and estimating the burden of the disease. In this study, we identified a set of variables that may help differentiate COVID-19 cases from other diseases. The model obtained exhibited an excellent AUC in the SP/RJ dataset comparable to more complex tools, including imaging and laboratory tests.16,17 This is impressive, considering that it is based solely on variables collected by the surveillance system.
An essential caveat in these models is that the predictors should not be interpreted individually. However, some associations are consistent with what is known about this coronavirus. For example, age was directly associated with the diagnosis, which could be explained by the increased pathogenicity in older people. Therefore, an overrepresentation of the elderly is expected among the confirmed patients.
Another interesting finding is the relationship between the time since the notification of the first confirmed case and the probability of COVID-19. This association indicates the importance of contextualizing according to the timing of the epidemic. Furthermore, this demonstrates that these models should be continuously updated and adapted to the epidemiological situation.
Most of the clinical manifestations included in the model were negatively associated with the SARS-CoV-2 infection. It does not mean that they cannot be presented by patients with COVID-19, but that they are more frequent in other diseases. This finding highlights why the circulation of other infectious agents could be a determinant of the predictors’ discriminatory capacity, as has already been suggested for other conditions.18
Moreover, it is expected that variables determining the notification (e.g., respiratory symptoms and international travel) and, therefore, inclusion in the study, tend to be negatively associated with the outcome due to collider-like phenomena.19 For this reason, both causal inference interpretation, and extrapolation to the general population of the associations would be biased. Consequently, our model must be considered only for diagnostic prediction in the specific group of reported suspected patients.
The claim not to have had contact with an exposed case perfectly predicted the absence of COVID-19. This finding should be interpreted with caution because it is very likely that as the epidemic progresses, this variable could lose discrimination capacity once the prevalence of infectious hosts, including those undetectable, increases in the community.
Regarding external application, we observed that the model had a considerably lower AUC in FUs other than SP and RJ. This difference could occur due to the epidemiological context variability, as well as different recording quality and heterogeneity in using definitions and reporting tools. Despite this, the AUC in these other FUs can be considered acceptable, and although lower, the model proposed could also help guide the preliminary diagnosis in scenarios different than those obtained.
Applications of the proposed model include early case identification for specific treatment and isolation, as well as the rational use of laboratory tests. Moreover, this model may predict the number of both total cases and hospitalizations attributed to this infection based on the surveillance data. This application is relevant because one of the challenges that this pandemic represents is the organization of healthcare resources. In this way, our results may help to model and forecast the availability of funds for patient care.
Conclusions
This study obtained and validated a model function suitable for the clinical diagnosis of COVID-19 during the early stage of the Brazilian epidemic. This tool was entirely based on data routinely collected. Therefore, it may help early identification and treatment of patients, establish preventive measures, and improve the accuracy of epidemiological surveillance of this disease.
Data Availability
Data subject to third party restrictions.
Authors’ contributions
FADQ conceived the study, participated in its design and coordination, conducted the data analysis, and prepared the first draft of the manuscript. JMNS and ALVV helped plan the study, review of the literature, and variable codification. FG and SO worked on the collection and organization of the database. JC contributed in planning the study, database organization, and insights to the analysis process.
All authors provided relevant input for the writing, conducted reviews as well as read and approved the final manuscript. Thus, each author participated sufficiently in the work to take public responsibility for appropriate portions of the content and, therefore, agreed to be accountable for all aspects in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Funding
This work had no specific funding. FADQ and JC were granted a fellowship for research productivity from the Brazilian National Council for Scientific and Technological Development – CNPq, process/contract identification: 312656/2019-0 and 310551/2018-8, respectively.
Competing interest
No author has conflicts of interest related to this study.
Ethical approval
This study followed Brazilian and International legislation for conducting human research. This research project was approved by the National Research Ethics Committee (Comissão Nacional de Ética em Pesquisa, CONEP) in Brazil, Register number (CAAE): 11946619.5.0000.5421.
Acknowledgments
The authors thank Prof. Alexandre Dias Porto Chiavegatto Filho, director of the Big Data and Predictive Health Analysis Laboratory (Laboratório de Big Data e Análise Preditiva em Saúde - Labdaps) from FSP/USP, for his recommendations about the analysis plan.



