
Abstract
Background The 2019 coronavirus disease (COVID-19) represents a significant public health threat globally. Here we describe efforts to compare epidemic growth, size and peaking time for countries in Asia, Europe, North America, South America and Australia in the early epidemic phase.
Methods Using the time series of cases reported from January 20, 2020 to February 13, 2020 and transportation data from December 1, 2019 to January 23, 2020 we have built a novel time-varying growth model to predict the epidemic trend in China. We extended our method, using cases reported from January 26, 2020 - or the date of the earliest case reported, to April 9, 2020 to predict future epidemic trend and size in 41 countries. We estimated the impact of control measures on the epidemic trend.
Results Our time-varying growth model yielded high concordance in the predicted epidemic size and trend with the observed figures in C hina. Among the other 41 countries, the peak time has been observed in 28 countries before or around April 9, 2020; the peak date and epidemic size were highly consistent with our estimates. We predicted the remaining countries would peak in April or May 2020, except India in July and Pakistan in August. The epidemic trajectory would reach the plateau in May or June for the majority of countries in the current wave. Countries that could emerge to be new epidemic centers are India, Pakistan, Brazil, Mexico, and Russia with a prediction of 105 cases for these countries. The effective reproduction number Rt displayed a downward trend with time across countries, revealing the impact of the intervention remeasures i.e. social distancing. Rt remained the highest in the UK (median 2.62) and the US (median 2.19) in the fourth week after the epidemic onset.
Conclusions New epidemic centers are expected to continue to emerge across the whole world. Greater challenges such as those in the healthcare system would be faced by developing countries in hotspots. A domestic approach to curb the pandemic must align with joint international efforts to effectively control the spread of COVID-19. Our model promotes a reliable transmissibility characterization and epidemic forecasting using the incidence of cases in the early epidemic phase.
1. Introduction
In early December 2019, a novel severe acute respiratory syndrome coronavirus, SARS-COV-2, emerged into the human population in Wuhan, China1–7. The first coronavirus disease 2019 (COVID-19) case outside China was reported on January 13, 2020 in Thailand. In just several weeks, the local transmission started rapidly in a broad array of countries in Asia, Europe, North America, South America and Australia, with the emergence of new epicenters of spread, such as the US, Italy, Spain, and France (https://www.who.int). The rapid spreading of SARS-COV-2 has led to a major global public health threat. The World Health Organization (WHO) declared the spread of COVID-19 a pandemic on March 11, 2020.
Early epidemic forecasts consisting of the likely trajectory of an unfolding outbreak can help guide the type and intensity of interventions8–10. The vast majority of these approaches considered early exponential growth dynamics, an assumption that could lead to substantial overestimation of epidemic size and peak timing. To enhance the ability to forecast epidemics, it is crucial to characterize the shape of epidemic growth and accurately assess early trends of sub-exponential growth phenomenon11–13. Currently, the global case count continues to rise, but there is a limited understanding of the extent of the outbreak and epidemic growth profile, particularly for the new emerging epicenters.
In this study, we attempt to assess and compare the extent of the outbreak across countries, draw preliminary conclusions about the impact of control measures, and characterize real-time effective reproduction number Rt. Our model, without making explicit assumptions about the epidemic growth profile, is a generalizable framework to estimate the early dynamic trends of COVID-19 from the incidences of cases. We estimated the epidemic trend and size in China using the cases reported from January 20, 2020 to February 13, 2020, and in other 41 countries using data from January 26, 2020, - or the date of the earliest case reported, to April 9, 2020.
2. Methods
2.1. Sources of Data
We obtained the number of COVID-19 confirmed cases of time series data between January 20, 2020 to February 13, 2020 in China from the official websites of the National Health Commission of China and Provincial Health Committees (http://www.nhc.gov.cn). The data of cases for each of the 29 provinces (25 provinces plus 4 municipalities including Beijing, Shanghai, Chongqing and Tianjin) at 23 time points were included, as well as for Wuhan and major cities in Hubei. The start date of January 20 was chosen because the official diagnostic protocol released by WHO on January 17 allows the new COVID-19 cases to be diagnosed accurately and rapidly. All cases were laboratory-confirmed with the detection of viral nucleic acid following the case definition by the National Health Commission of China.
Wuhan is connected to other cities in China via high-speed railway, highway, and airplane flights. Population mobility statistics to estimate the exposed sizes in cities outside Wuhan were based on transport-related databases below: 1) Railway and airline travel data: the daily numbers of outbound high-speed trains from Wuhan with corresponding travelling hours were obtained from the high-speed rail network (http://shike.gaotie.cn) from December 1, 2019 to January 23, 2020, and similarly daily numbers of outbound flight and hours for air transport were obtained from the Citytrip network (https://www.ctrip.com) from December 1, 2019 to January 23, 2020. We calculated daily travelling hours which equal to the product of the outbound trip counts and the travelling hours for rail and air transport respectively from Wuhan to each major city. For a given province, we summarized the total number of travelling hours across all cities in that province. 2) Highway mileage data: we collected highway mileage data from bus station networks at https://www.qichezhan.cn. It contains the highway mileage from Wuhan to 16 cities in the Hubei Province. 3) Migration data: we obtained population migration data from the Baidu Migration Map (http://qianxi.baidu.com) which includes both the percentages and volumes of migration from Wuhan to other cities and provinces from January 1 to 28, 2020. Total travelling hours for rail and air flight, and migration scales are plotted by the province in Supplementary Figure 1. Accumulated time on trains, on airplanes, highway mileage and population migration scales were used to model the underlying epidemic sizes in the provinces or cities outside Wuhan at the time 0 of this study which is on January 20, 2020.
From Supplementary Figure 1, we observed that Guangdong has the largest traveling hours through railway and airplane outbound from Wuhan among the provinces. Also, the largest population has immigrated from Wuhan to Henan. In Hubei province, Cities of Huanggang and Xiaogan are the closest to Wuhan in terms of mileage and the scale of migration. These simple observations are consistent with our result that Guangdong, Henan, Huanggang and Xiaogan have the largest number of estimated primary infected cases imported from Wuhan on January 20, 2020.
We obtained the number of COVID-19 confirmed cases in 41 countries using data from January 23, 2020, or the date of the earliest case reported, to April 9, 2020 from the offical websites of WHO at https://www.who.int. We included 41 countries with at least confirmed cases on April 9 2020 in five continents: Asia, Europe, North America, South America, and Australia.
2.2. Modelling the transmissibility of COVID-19
We introduce the main notation here. All times are calendar times, measured in days since the start of the epidemic.
Ykt number of accumulated diagnosed case till day t,
TRk daily traveling hours on trains from Wuhan,
FLk daily traveling hours on airplane from Wuhan,
RMk highway mileage from Wuhan,
MIk volumes of migration from Wuhan from January 1 to 28, 2020,
αk number of underlying primary infected cases,
Wkt underline number of infected individuals who are infectious,
m duration of infectious period (day),
where the subscript k represents country, province or city k, the subscript t represents day t. TRk and FLk are constructed based on the two reasons. One is that the longer people stay on the train or plane, the more likely he(she) is to get infected. Another is that the infection happens in local area, hence the number of trains or planes has more information than the population taking trains or planes. In addition, in Hubei province, most people left Wuhan by cars, we use RMk as one of measurement for the spatial distance between city k and Wuhan.
2.2.1. Modeling for 28 provinces
First, we build an index αk to represent the baseline infected cases in province k on 20 January, 2020. Particularly, we will use TRk, FLk and MIk to measure the relationship between provice k and Wuhan. We suppose
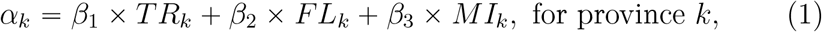 where β = (β1, β2, β3)′ are estimated by the observed Ykt in provinces k = 1, …, K and t = 1, …, T.
where β = (β1, β2, β3)′ are estimated by the observed Ykt in provinces k = 1, …, K and t = 1, …, T.
So far, we are not sure the key epidemiological parameters that affected spread and persistence. We hence make assumptions as least as possible. It is obvious that the average cases in province k diagnosed at day t is proportional to the scale of infectious cases on day t − 1, Wk,t − 1. We then assume a Poisson distribution for the new cases diagnosed in province k at day t with mean γktWk,t − 1, that is
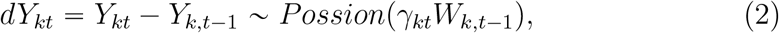 where ‘∼’ means ‘distributed as’.
where ‘∼’ means ‘distributed as’.
Under the unified leadership of the central goverment, we suppose the trend of γkt over day t is the same for 28 provinces, that is, ηkt = ηt is independent of k so that

To avoid strong assumptions about the evolution of the epidemic, we allow ηt to be arbitray function of t. We determine the functional form of ηt by pointwise estimating ηt and checking the resulting pattern over t. Denote the resulting functional form for ηt by ηt = ηt(a).
The new cases diagnosed at day t may be not reported fully. That is, E(dYkt) = pdWkt and p < 1. The estimation for p need more information except that we have. Fortunately, simple mathematical derivation shows that the value of p may influence the prediction of the absolute epidemic size but will not affect the trend of the epdimic, for example, the reproduction number, the duration and the peak time of the epidemic and relative epidemic size, in which we are interested. Hence, we suppose p = 1 in the paper. Since
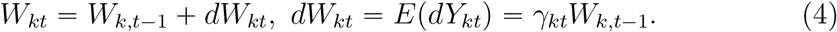
With the chain calculation, we have 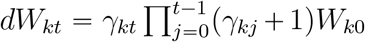 .and
.and 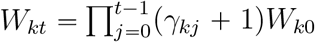 ,where Wk0 = αk and γk0 = 0. In practice, the infected patients will be isolated and removed from the infectious source. With the notation m of duration of infectious period, we hence have
,where Wk0 = αk and γk0 = 0. In practice, the infected patients will be isolated and removed from the infectious source. With the notation m of duration of infectious period, we hence have
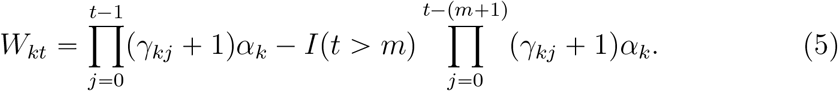
Denote γ1 = (γ11, …, γK1)′ and all of the parameters by 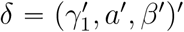 . Taken (1), (2), (3) and (5) together, the loglikelihood function was
. Taken (1), (2), (3) and (5) together, the loglikelihood function was
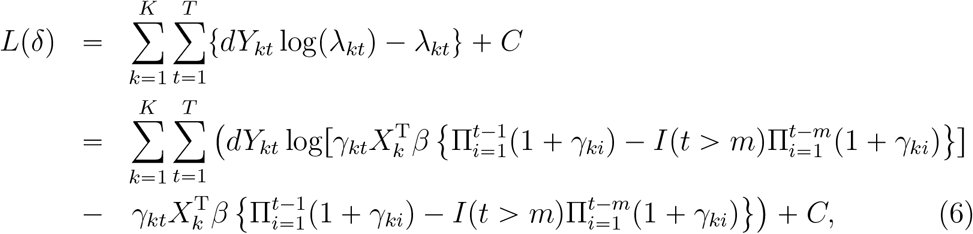 where C is a constant independent of δ, m is determined by minimizing the prediction error. The confidence intervals were obtained based on 200 bootstrap resampling14, 15.
where C is a constant independent of δ, m is determined by minimizing the prediction error. The confidence intervals were obtained based on 200 bootstrap resampling14, 15.
2.2.2. Modeling for Hubei, Wuhan and the other countries
The modeling and the loglikelihood function for Hubei are similar with those for 28 provinces except that FLk is replaced by RMk and provinces are replaced by cities, because there are not flights between the cities in Hubei and Wuhan, and the most people leave Wuhan by cars or buses. Specifically,
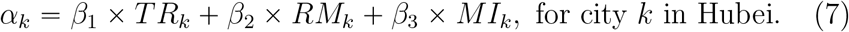
The modeling and the likelihood function for Wuhan and countries, including Singapore, South Korea, Japan, Italy, German, Span, France and Iran, are similar with those for 28 provinces except that αk is directly estimated by the diagnosed cases in Wuhan and other 41 countries respectively.
2.2.3. The calculation of the time-dependent reproduction number Rt
The equation dWkt = γktWk,t−1 implies that, when Wk,t−1 = 1 we have γkt = dWkt. Hence γkt is the average number of new infections created by an infectious individual in one day, then 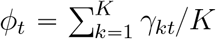 is the corresponding average number across provinces or cities. Since one infectious individual can make infection for m days, an infectious individual then can lead to Rt mϕt new infections, which indeed is the time-dependent reproduction number16, 17.
is the corresponding average number across provinces or cities. Since one infectious individual can make infection for m days, an infectious individual then can lead to Rt mϕt new infections, which indeed is the time-dependent reproduction number16, 17.
2.2.4. Predication of potential peak time and turning point in COVID-19 outbreak
With the estimated parameters by maximizing the loglikehood (6), we can estimate and predict the average new cases 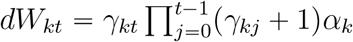 , then the cumulative cases
, then the cumulative cases 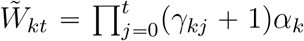 . Based on the new cases and cumulative cases, we can predict the peak time and the turning point in the COVID-19 outbreak. In the paper, we defined the peak time to be the day at which the incidence cases began to decline, and the turning point to be the day when the number of the cumulative cases reached a plateau, which satisfying ∣∂f(v)/∂v∣ ⩽ c0, where
. Based on the new cases and cumulative cases, we can predict the peak time and the turning point in the COVID-19 outbreak. In the paper, we defined the peak time to be the day at which the incidence cases began to decline, and the turning point to be the day when the number of the cumulative cases reached a plateau, which satisfying ∣∂f(v)/∂v∣ ⩽ c0, where 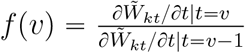 and c0 is a prespecified small number. We take c0 = 2e − 03 through the analysis.
and c0 is a prespecified small number. We take c0 = 2e − 03 through the analysis.
3. Results
3.1. Fitting a generalized growth model using a time-series data
We fit the time-varying generalized growth model using the early stage outbreak series data for Wuhan, Hubei province, China, and other 41 countries with at least 2,000 confirmed cases on the date of April 9 2020. The optimal fitted model for each country or region was chosen based on the prediction error of the lowest values (Supplementary Figures 2 to 4). The corresponding empirical distributions of the parameters are shown in Table 1. The parameter m, the estimated mean infectious duration, ranged from 4 to 13 days, with the highest value of 13 for the epidemic in Italy. The short duration of 4 days was estimated for South Korea. The value of m reflects the duration of infectious period, which in practice could be intervened by control measures such as early diagnosis and isolation. Another parameter η t quantifies how rapidly the growth rate γ(t) at time t changed; the functional form of η(t) was estimated by pointwise estimation using data till t for each model respectively. The growth rates declined most rapidly in China and Thailand (median η: 0.86 to 0.89), and most slowly in India, Mexico, Singapore and Sweden (median η: 0.98 to 0.99).
Summary of fitting parameters for the selected model in 10 countries in 2020.
3.2. Predictive performance of model fitting
Using the calibrated model based on m and the form of η(t), we estimated the real-time growth rates based on the number of confirmed cases at t 1, …, T by maximizing the likelihood function displayed in the Method section. The underlying growth process was lower than the constant exponential growth rate as medium η(t) was consistently estimated at less than 1(Supplementary figure 3), similar to findings of sub-exponential growth dynamics for epidemics of influenza, Ebola etc with the deceleration growth factor below 1 18, 19.
For China, we used case incidence data from January 20 to February 13 as the epidemic reporting period to fit the model for trajectory predictions. The observed values fall within 95% CI of the prediction band in general, suggesting a good model fitting (Figure 1 and Supplementary Figures 8-9). We predicted that the epidemics would fade out around February 19 to 24 across the 28 provinces, about 4 weeks after the intervention starting from January 20; this is in concordance with the actual timing in which no more new cases were observed at the end of February (http://www.nhc.gov.cn). For 28 provinces in China, the estimated size was at 8553 to 9460 and 11,000 to 12,600 for Hubei province; both 95% CI estimates cover the observed figures (Table 2). For Wuhan, due to the changes in the diagnosis criteria, the predicted number of cases was not comparable after February 13. We estimated the epidemic would fade out around the end of February, which is close to the final date in which no more new cases were observed in Wuhan.

The estimated (red-solid) and observed (black-dotted) cumulative number of infectious over time t, as well as 95% CI (red-dashed) of the estimators. In addition, the green dots in the plot for Beijing and Guangdong in China refer to the number of reported cases which were not included for the model fitting.

{kind=link}
{kind=link}
The proportion of epidemic size when the duration of infectious period m is reduced by 1 and 2. The reduction of infectious duration refers to shorten the time from the infection onset (symptomatic or asymptomatic) to isolation by intervention measures.
Estimation of median growth rate, final epidemic size and ending date for each country
Within each province, the observed final epidemic size was within the 95% CIs of prediction except 5 provinces, yet the prediction was still within 10% +/− flanking the upper or lower bound (Supplementary Table 1). Given the intervention measures are similar across provinces in China besides Hubei, it is not surprising that we observed the trend that the provinces with a higher estimated risk of imported cases alpha from Wuhan had an increased epidemic size. However, there were some exceptions. For example, Beijing (α = 28; 95%CI : 7 − 49) and Shanghai (α = 16; 4 − 28) were in the high-risk group but the final infection numbers were 286 and 261. On the contrary, Heilongjiang was in the low-risk group (α = 4 : 1 − 6) whereas the final infections were at 252. This implies the stronger intervention locally or compliance in densely populated municipalities (Beijing or Shanghai), than that in Heilongjiang, the north-east region far away from Wuhan. Overall our time-varying growth model provides a good fitting using time-series confirmed cases for the epidemic of COVID-19 in China.
3.3. Projection of the epidemic and final size in 41 countries
We projected the future growth trajectory underlying the outbreak using the daily confirmed case data from January 23, 2020 - or the date of the earliest case reported - to April 9, 2020 in 42 countries across Asia, Europe, North America, South America and Australia. Our prediction is based on the estimated parameters assuming the sustainability of intervention measures. The time-varying growth model fitting to the time-series data performed well as shown by the observed cases generally falling in the 95% CI of the prediction bound in each plot (Figure 1 and Supplementary Figures 8-12), except for South Korea in the very early phase. The predicted cases were higher than the observed number of infections from February 8 to 25, likely due to a proportion of infections being greatly understated - the hiding cases from the religious group.
We predicted the epidemic size and duration of the outbreak with the assumption of current model fitting parameters (Table 2). In Asia, the epidemic will continue until May in Philippine, Malaysia and Iran, and July in Indonesia. Strikingly, the epidemic would have the longest outbreak spread until February or March 2021 in Indian and Pakistan, with the final infections at more than a million. For Japan and Singapore, we were not able to do predictions on the epidemic sizes and duration because the estimated time-varying growth rates kept on increasing at the end of the study period – which is concordant to the big daily jump in cases observed in these two countries recently; thus incidence case data in a longer period are required for valid predictions using our model. In Europe, the epidemic will not fade out until May or June for the majority of countries. However the epidemic may last until August (Russia and Sweden). In North America, the epidemic will continue until May (Canada, Dominican Republic), June (US) and October (Mexico), and the infection are estimated to be around 1 million in the US, and 105 in Mexico. In South America, the epidemic will continue until May (Chile) and June (Brazil, Colombia and Panama). Among them, Brazil has the largest estimated infections with more than 105.
3.4. Estimation of peak time
We estimated the peak time, the day at which the incidence cases began to decline based on the estimated daily cases dWkt (see Methods). Among 41 countries, the peak time has been observed in 28 countries before or around April 9, 2020 (Table 3 & Supplementary Figures 13-15). The estimations in the above countries are concordant to the observed period during which incidence cases declined. For other countries, under the current parameters with continuity of intervention measures, we estimated the epidemic would peak in April or May 2020 for the majority of countries, except for India (July) and Pakistan (August). The predicted numbers of accumulated cases at the peak point were also consistent with the observed figures. Based on the predicted number of infections, we estimated the maximum number of ventilators for the peak requirement. For example, at least 500,000 ventilators need to be prepared for the epidemic peak in India, ∼ 100, 000 for Pakistan. Considering the death or recovery rate, the number is regarded as the upper bound in practice.
The predicted or observed peak date and the corresponding cumulated size among the different countries
3.5. Impact of the reduction of the infectious period
Shortening the time from the infection onset (symptomatic or asymptomatic) to isolation, termed as ‘infectious period’ in this paper, is vital as it will reduce transmission. The control strategies could rely on social distancing, earlier isolation of cases and population-based testing to identify the presymptomatic or asymptomatic cases. Here we evaluated the impact of shortening the infectious period on the epidemics, showings the epidemic curve for each country, assumed to be 1 or 2 days shorter in the duration of infectivity infectious period (Supplementary Figures 13-15). A reduction of the infectious period by 1 or 2 days would have a negligible effect on the peak time, as the estimation was essentially the same. The reduction of the infectious period by 1 or 2 days would lead to a significantly flatted epidemic curve across all the countries. For example, the 2-days decrease in the infectious period would result in a significant reduction of the final epidemic size in India (31.1%), Pakistan (39.3%), Russia (22.6%), Brazil (26.8%), and Mexico(18.0%).
3.6. Estimation of real-time effective reproduction number Rt
We quantified the real-time reproduction number Rt (see Method section)17, 20, 21, based on the estimation parameters of growth rates γ and the infectious period m. The Rt exhibited a declining trend with time and variability in the estimates across countries (Table 4). The uncertainty of Rt was largest in the first week and gradually became smaller with time (Table 4). In the first week, 28 countries displayed Rt below 5 while 14 exhibited large Rt above 5. Italy and Spain displayed the highest Rt at 12.36, and 9.26 respectively. Rt estimations become closer ranging from 0.95 (Singapore) to 5.54 (Spain) in the second week. During the first month of the epidemic period, all countries displayed a declined trend towards 1 in the epidemic period with varying deceleration rates, revealing the impacts of the intervention strategies. In the fourth week, 14 countries exhibited Rt below 1, the highest in UK (2.62) and the US (2.19). For Singapore and Japan, although both displayed the declining trend in the first month, there is an inclining trend starting from April, implying the intervention could not be effective in the late stage (Supplementary Figure 16). Rt displayed the fastest deceleration in China with the most pronounced changes during the third to fourth weeks; this may reveal the significant impact of intervention measures implemented since January 20, 2020 in the first week.
Estimated Medium Rt (95%CI) in the subsequent week
4. Discussions
Here we predicted that the COVID-19 pandemic will persistently spread over many countries and will last on average 5 to 6 months since January 2020 for the current wave. We estimated, given no further intervention measures, that India would emerge to be a new epidemic center, as well as Pakistan, Brazil, Russia and Mexico. Effective intervention measures by reducing the infectious period would result in an 50% reduction in the final epidemic sizes. Rt had a declining trend in almost all countries, revealing the impact of the intervention measures i.e. social distancing.
Our real-time estimation framework can yield a reliable prediction of the final epidemic size using the data from the early phase of the epidemic. We evaluated the performance of our model using incident case data from January 20 to February 13, 2020 in China. We predicted the epidemic would fade out on February 19 to 24 across 28 provinces in China with a one-week lag in Wuhan; the epidemic size was estimated at 8,500 to 9,500, and 11,000 to 12,600 in 28 provinces and Hubei respectively. The outbreak size and epidemic duration estimated are found to be highly consistent with the observed figures (https://www.who.int). The prediction of the final epidemic size based on the model that assumes early exponential growth could tend to overestimate the epidemic size, which has been shown in the previous studies10,23-28
We estimated that the most affected countries in the next wave of the pandemic will be India, Pakistan, Brazil, Mexico as well as Russia. All these countries are currently undergoing regional or national lockdown except Mexico. Given that thousands of ventilators are needed for the peak around May to July, it is immediately important for these countries to prepare the ICU beds. In Europe, most countries have peaked in the curve, and the final outbreak size was estimated to exceed 105 in Italy, France, UK, Germany and Spain. For the United States, the estimated final epidemic size will surpass 1 million, peaking around July 2020. A recent report calculated that 81% of British and the United States populations would be infected, with approximately a half and 2.2 million deaths respectively29. The high value is based on the assumption of R0 at 2.4, while our results demonstrate that real-time Rt decelerated under interventions. Thus, their estimates are likely to be the higher bound of the true value. In Asia, besides China, South Korea and Iran, Thailand and Malaysia have peaked in March. Indonesia and Saudi Arabia would peak in April. Singapore and Japan recently implemented lockdown and more data will be needed for the epidemic prediction. Given the case-fatality rate at 2.3%6, we estimated around 23,000 deaths in India and Pakistan, and around 2,300 in Mexico and Brazil, and 6,900 in Russia.
This is the first study to compare country-specific temporal Rt. It is natural to expect a declining trend of Rt to 1 owing to stochastic effects for epidemics governed by subexponential growth18, 30, while a faster decline may suggest a larger impact of intervention measures or behavior changes31. A majority of countries displayed Rt below 5 in the first week of the epidemic period. Several countries exhibited large Rt, ie. Italy or Spain, suggesting a rapid increase of cases at the beginning or a large variation in the under-reporting rates in the early epidemic phase. For Wuhan, Rt declined from the median 2.5 to 0.3 within a month, which is compatible with the R0 estimation in a range of 2.2 to 3.6 in Wuhan2, 10, 12, 13, 16, 23, 31, and below 1 after interventions32. All countries displayed a declined trend towards 1 in the epidemic period with varying deceleration rates, revealing the variation in the impact of the intervention strategies. For further research on the intervention effectiveness, individual data, as well as a series of intervention measures for each country, may be required to quantify the effects in detail.
Our study showed that by shortening the infectious period by two days, we could effectively reduce the final epidemic size by up to 50%. What strategies can effectively reduce the infectious period? Usually, it can be done - similar to the other coronaviruses - by early detection and isolation of symptomatic patients and tracing of close contacts. However, the presymptomatic transmission has been reported in many countries such as China, the US, and Singapore33–36, etc. The existence of presymptomatic or asymptomatic transmission would present difficult challenges for disease control, which underscores the importance of social distancing. For instance, at the onset of the epidemic, the spread has been well controlled in Singapore, accounted for by a range of intervention measures, such as contact tracing and quarantining, that were instituted from January 23-the onset of the first case in Singapore37. However, the recent increase in cases in Singapore, initially starting from the imported cases followed by the outbreak in dormitories of immigration workers, led to its circuit period from April 7 to May 4. Quarantine measures for the infected regions or at the national scale, either a complete lockdown as in China or partial lockdown such as in Europe, are effective in flattening the curve38. Besides the quarantine measures, South Korea was also successful in suppressing the outbreak, attributed to the rapid measures to perform large-scale diagnostic testing for the public for case isolation39.
During the early phase of the epidemic, we forecasted the epidemic size as a function of the time-varying growth model, similar but more flexible to the previous approaches to model sub-exponential growth dynamics18–21, 40, without relying on any epidemiological parameter assumptions. The traditional transmission epidemiological model is defined through a susceptible, exposure, infectious, removed (SEIR) scheme, which requires epidemiological parameters from detailed case studies2, 10, 31, 41. Furthermore, given the variation of the transmissibility, mostly due to the intervention strategies implemented and behavioral changes in the population, it is desirable to quantify the dynamics of Rt over time20,42-44. Several studies attempted to forecast the number of epidemics for COVID-19 in China using the constant growth rate27, 45, 46, which is not the case in our model of nonmonotonic behavior of the growth rate. Our model, compared to previous studies, has greater flexibility in a data-mining manner to fit and predict future trajectories.
In summary, we compared the epidemic trajectory, characterized dynamic Rt in 42 countries, and predicted that the new epidemic centers will continue to emerge in the next wave. Meanwhile, we highlighted the importance of various effective interventions in flattening the epidemic curve, such as social distancing, to shorten the infectious period. By carefully characterizing the shape of the epidemic growth phase, we believe our study represents a significant step in modeling real-time transmission and providing accurate forecasts of epidemics.
Our study has several limitations. Firstly, the projection of the temporal trend of an outbreak using the early-stage dataset could be dramatically influenced by the changes in the intervention strategies later on. For example, using data up to March 15, our previous analysis overestimated the epidemic size in U.S as the social distance measures (i.e. quarantine) were implemented starting from March 21. The performance of models used in this work will be continuously improved with data coming in from an ongoing outbreak, thus real-time estimates of key epidemiological parameters can be available before the epidemic fully ends. Secondly, the number of infections estimated might not be comparable across the countries; for example, the number of infections in Germany is not comparable to the number of infections in Italy or China, as the latter did not perform large-scale population-based testing and thus the cases could be more severe. Lastly, the analyses are highly reliant on the reporting criteria and quality of the data. The under-reporting of infection is likely a common scenario in the majority of countries. For example, a recent study showed that the reported number of confirmed positive cases was 50-85-fold lower than the actual number of infections in 3330 people in Santa Clara County, US47. A more realistic and comprehensive analysis could be performed that includes accurate epidemic data and information. In current imperfect situation, our model could still be used for more advanced analyses, including estimations of the epidemic size, peak points and dynamic Rt.
Data Availability
The data used in this article is publicly available, see the data links in the article for details.
Declaration of interests
We declare no competing interests.
Acknowledgments
The research were partially supported by National Natural Science Foundation of China (Nos. 11931014 and 11829101) and Fundamental Research Funds for the Central Universities (No. JBK1806002) of China.
Footnotes
Email addresses: linhz{at}swufe.edu.cn (Huazhen Lin), qiao.fan{at}duke-nus.edu.sg (Qiao Fan)
References



