
Abstract
Background The triage of patients in pre-hospital care is a difficult task, and improved risk assessment tools are needed both at the dispatch center and on the ambulance to differentiate between low- and high-risk patients. This study develops and validates a machine learning-based approach to predicting hospital outcomes based on routinely collected prehospital data.
Methods Dispatch, ambulance, and hospital data were collected in one Swedish region from 2016 - 2017. Dispatch center and ambulance records were used to develop gradient boosting models predicting hospital admission, critical care (defined as admission to an intensive care unit or in-hospital mortality), and two-day mortality. Model predictions were used to generate composite risk scores which were compared to National Early Warning System (NEWS) scores and actual dispatched priorities in a similar but prospectively gathered dataset from 2018.
Results A total of 38203 patients were included from 2016-2018. Concordance indexes (or area under the receiver operating characteristics curve) for dispatched priorities ranged from 0.51 – 0.66, while those for NEWS scores ranged from 0.66 - 0.85. Concordance ranged from 0.71 – 0.80 for risk scores based only on dispatch data, and 0.79 – 0.89 for risk scores including ambulance data. Dispatch data-based risk scores consistently outperformed dispatched priorities in predicting hospital outcomes, while models including ambulance data also consistently outperformed NEWS scores. Model performance in the prospective test dataset was similar to that found using cross-validation, and calibration was comparable to that of NEWS scores.
Conclusions Machine learning-based risk scores outperformed a widely-used rule-based triage algorithm and human prioritization decisions in predicting hospital outcomes. Performance was robust in a prospectively gathered dataset, and scores demonstrated adequate calibration. Future research should investigate the generality of these results to prehospital triage in other settings, and establish the impact of triage tools based on these methods by means of randomized trial.
Introduction
Emergency care systems in the developed world face increasing burdens due to an aging population [1–4], and in prehospital care it is often necessary to prioritize high-risk patients in situations where resources are scarce. Prehospital care systems have also increasingly sought to identify patients not in need of emergency care, and to direct these patients to appropriate forms of alternative care both upon contact via telephone with the dispatch center, and upon the arrival of an ambulance to a patient [5–12]. Performing these tasks safely and efficiently requires not only well-trained prehospital care providers and carefully considered clinical guidelines, but also the employment of triage algorithms able to perform risk differentiation across the diverse cohort of patients presenting to prehospital care systems.
Systems to differentiate high- and low-risk patients in prehospital care have typically relied on rule-based algorithms. Many common algorithms seek to identify specific high-acuity conditions within certain subsets of patients such as cardiac arrest, trauma, or stroke [13–15]. Other algorithms are intended for use within a broader cohort of patients, including Critical Illness Prediction (CIP) scores and the National Early Warning System (NEWS) [16–19], and the Medical Priority Dispatching System (MPDS) [20] for Emergency Medical Dispatching (EMD). In applying such tools, providers commonly “over-triage” patients, as false negatives are thought to be associated with far greater costs than false positive findings [21–24]. In the context of trauma care, the American College of Surgeons Committee on Trauma (ACS-CoT) recommend that decision rules to identify patients suitable for direct transport to a level-1 trauma center have a sensitivity of 95%, while an appropriate level of specificity may be as low as 65% [24,25]. We identified no guidelines establishing appropriate levels of sensitivity for decision rules intended to identify patients suitable for referral to alternate forms of care by prehospital care providers. Given the costs of missing true emergencies in this application, the required level of sensitivity may be similarly high.
In the context of Emergency Department (ED) triage, Machine Learning (ML) based triage algorithms can out-perform their rule-based counterparts in predicting general measures of patient outcome [26–29]. We identified no research relating to the ability of prehospital data to similarly predict hospital outcomes, though there are indications that ML techniques may be effective in identifying specific high-acuity conditions such as cardiac arrest at the dispatch center [30]. ML-based approaches offer the potential to integrate large and complex sets of predictors, and automatically calculate risk scores for use by care providers. By using prehospital data to predict hospital outcomes, it may be possible to enhance the ability of prehospital care providers to safely identify patients not in need of hospital care. Such low-risk patients could then be directed to less intensive forms of care (e.g. transport to a primary care facility or a home visit by a mobile care physician), thus alleviating the increasingly vexing problem of overcrowding at EDs [31–33]. Such scores could also be used to improve the overall accuracy of ambulance dispatching systems, ensuring that high-risk patients are prioritized over those with less need for emergency care.
In this study, we developed machine learning models to predict patient outcomes in a broad cohort of patients at two distinct points in the chain of emergency care: In the EMD center prior to ambulance dispatch, and on the ambulance after making contact with the patient. We investigated the feasibility of using these methods to improve the decisional capacity prehospital care providers in these settings by comparing their accuracy with a previously validated triage algorithm (NEWS), and with prioritization decisions made by nurses at the EMD center per current clinical practice.
Methods
Source of Data
This study took place in the region of Uppsala, Sweden, with a size of 8 209 km2, and a population of 376 354 in 2018. The region is served by two hospital-based EDs, a single regional EMD center staffed by Registered Nurses (RNs) employing a self-developed Clinical Decision Support System (CDSS), and 18 RN-staffed ambulances. The CDSS consists of an interface wherein dispatchers first seek to identify a set life-threatening conditions (cardiac/respiratory arrest or unconsciousness), and then document the primary complaint of the patient. Based on the documented complaint, a battery of questions is presented, the answers to which determine the priority of the call, or open additional complaints. While the specific set of questions are idiosyncratic to this and 3 other Swedish regions, its structure is similar to other dispatch CDSS such as the widely-used MPDS [20].
Ambulance responses are triaged by an RN to one of four priority levels, with 1A representing the highest priority calls (e.g. cardiac/respiratory arrest), and 1B representing less emergent calls still receiving a “lights and sirens” (L&S) response. Calls with a priority of 2A represent urgent, but non-emergent ambulance responses, while 2B calls may be held to ensure resource availability.
Records from January 2016 to December 2017 were extracted to serve as the basis for all model development. Upon finalizing the methods to be reported upon, records from January to December 2018 were extracted to form a test dataset to investigate the prospective performance of the models. The data in this study were extracted from databases owned by the Uppsala ambulance service containing dispatch, ambulance, and hospital outcome data collected routinely for quality assurance and improvement purposes. Ambulance records were deterministically linked to dispatch records based on unique record identifiers available in both systems. Hospital records were extracted from the regional Electronic Medical Records (EMR) system based on patient Personal Identification Numbers (PINs) collected either by dispatchers or ambulance crews. This study was approved by the Uppsala regional ethics review board (dnr 2018/133).
Participants
Inclusion and exclusion criteria were defined so as to enable comparison with other studies of ML based triage systems in the ED, and with previously validated risk assessment instruments. All dispatch records associated with a primary ambulance response to a single-patient incident (i.e., excluding multi-patient traffic accidents and planned inter-facility transports) were selected for inclusion. Records lacking documentation in the CDSS used at the EMD center were excluded, as were records in which an invalid PIN or multiple PINs were documented. Dispatch records with no associated ambulance journal (e.g. calls cancelled en route, or where no patient was found), and records indicating that the patient was treated and left at the scene of the incident were excluded. We further excluded records where no EMR system entry associated with the patient at the appropriate time could be identified (typically due to documentation errors, or transports to facilities outside of the studied region), and EMR system records indicating that the patient was transported to a non-ED destination (e.g. a primary/urgent care facility, or a direct admission to a hospital ward). We also excluded patients with ambulance records missing measurements of more than two of the vital signs necessary to calculate a NEWS score. Patients under the age of 18 were excluded as NEWS scores are not valid predictors of risk for pediatric patients.
Outcomes
We selected three outcome measures based on their face validity in representing a range of outcome acuity levels, and based to their use in previous studies; 1) patient admission to a hospital ward [26–28,34], 2) the provision of critical care, defined as admission to an Intensive Care Unit (ICU) or in-hospital mortality [26,28], and 3) all-cause patient mortality within two days [18,19].
While each of these outcomes represent an important aspect of the overall risks associated with a patient, no single outcome measure was thought to provide a full picture of patient acuity. As such, we chose to combine these outcomes by predicting the likelihood of each outcome occurring independently, and then combining predictions into a single composite risk score. This is a novel approach, as previous researchers have either investigated only single measures of patient outcome [27,28], or binned scores across specific ranges of predicted likelihoods [26,34]. The method we propose results in composite risk scores reflecting the normalized mean likelihood of several outcomes with face validity as being representative of patient acuity occurring, without incurring the loss of information associated with binning continuous variables. We applied no weights in the compositing process, as the relative importance of these measures in in establishing the overall acuity of the patient is not known.
Predictors
Predictors extracted from the dispatch system included patient demographics (age and gender), the operational characteristics of the call (Hour and month that the call was received, haversine distance to the nearest ED, and prior contacts with the EMD center by the patient), and the clinical characteristics of the call as documented in the existing rule-based CDSS. We included the 59 complaint categories, and the 1592 distinct question and answer combinations available in the CDSS as potential predictors in our models. Each of the questions in the CDSS was encoded with a 1 representing a positive answer to the question, and 0 representing a negative answer to the question. Questions with multiple potential answers were encoded on a numerical scale in cases where the answers were ordinal (e.g., “How long have the symptoms lasted?”), and as dummy variables if the answers were non-ordered. The recommended priority of the call based on the existing rule-based triage system was also included as a predictor in the dispatch dataset.
Predictors extracted from ambulance records represented the information which would be available at the time of patient hand-over to ED staff, and included the primary and secondary complaints, additional operational characteristics (times to reach the incident, on scene, and to the hospital), vital signs, patient history, medications and procedures administered, and the clinical findings of ambulance staff. Descriptive statistics for the included predictors are reported in S1 Table.
To provide a basis for comparison, we extracted the dispatched priority of the call as determined by the RN handling the call at the EMD center, and retrospectively calculated NEWS scores for each included patient. If multiple vital sign measurements were taken, the first set was used both as model predictors and to calculate NEWS scores.
Missing data
Missing vital sign measurements in ambulance records are not likely to be missing completely at random, and must be considered carefully [35,36]. Based on exploratory analysis and clinical judgement, we surmised that records missing at most two of the vital signs constituting the NEWS score fulfilled the missing at random assumption necessary to perform multiple imputation. Missing vitals were multiply imputed five times using predictive mean matching over 20 iterations as implemented in the ‘mice’ R package [37]. The characteristics of the imputed data were examined, and we chose to use the median of the imputed vital signs to calculate NEWS scores. Multiply imputed data were not used as predictors, with missing data handled natively by the ML models used here.
Statistical analysis
We entered each set of predictors transformed as previously described into gradient boosting models as implemented in the XGBoost R package [38]. This algorithm involves the sequential estimation of multiple weak decision trees, with each additional tree reducing the error associated with the previously estimated trees [39]. Model predictions were combined into composite risk scores by scaling each set of outcome predictions to have a population mean of zero and a standard deviation of one. These were then averaged and a log transformation was applied to improve calibration, resulting in a composite risk score following a normal distribution.
We investigated model discrimination using Receiver Operating Characteristics (ROC) curves, using the area under these curves (a measure equivalent to the concordance index, or c-index of the model) as summary performance measures [39].
Precision/Recall curves and their corresponding areas under the curve are included in S2 Analysis. 95% confidence intervals for descriptive statistics and c-index values were generated based on the percentiles of 1000 basic bootstrap samples (using stratified resampling for c-index values) as implemented in the ‘boot’ R package [40]. Model calibration overall and in a number of sub-populations was investigated visually using lowess smoothed calibration curves, and summarized using the mean absolute error between predicted and ideally calibrated probabilities using the ‘val.prob’ function from the ‘rms’ R package [41].
We considered the performance of the models in the prospective dataset to be the best metric of future model performance, though results in this field have previously been reported based on cross-validation [26,34] or randomly selected hold-out samples [28]. In this paper we report our main findings based on model performance in a prospective test dataset, an include results based on cross-validation for comparison. Model performance in the training dataset was estimated using 5-fold cross-validation (CV), and model performance in the testing dataset was based on models estimated using the full training dataset.
Readers interested in further details of the methods employed to produce the results reported here are encouraged to peruse the commented source code found in S6 Code. All model development and validation was performed using R version 3.5.3 [42].
Results
Participants
A total of 68 668 records were collected, of which 45 045 were in the training dataset, and 23 623 were in the test dataset as reported in Table 1. Overall, 30 465 records (44%) were excluded due all criteria. A lower proportion of records were excluded from the test dataset, primarily due to fewer non-matched ambulance and hospital records.
Summary statistics describing the characteristics of all patients included in the study (across both training and testing sets), both in total and stratified by dispatched priority are presented in table 2. We found that ambulance predictors and outcomes were generally distributed such that higher priority calls had higher levels of patient acuity, with the notable exception of hospital admission which remained constant at around 50% regardless of dispatched priority. Higher priority patients were generally younger, more often male, and had a higher proportion of missing vital signs. Overall, at least one vital sign was missing in a quarter of ambulance records, with the most commonly missing vital sign measurement being the patient’s body temperature. Temperature was missing in 15% of cases, and other vital signs were missing in less than 5% of cases as reported in S1 Table. Multiple imputation of these vital signs resulted in good convergence and similarity to non-imputed data, and NEWS scores based on sets of imputed scores did not differ significantly in terms of predictive value.
Model performance
Receiver operating characteristics curves across the three hospital outcomes for each of the risk prediction scores, as well as for the dispatched priority of the call are presented in fig 1. We found that for all investigated outcomes, risk scores based on ambulance data outperformed all other instruments investigated. NEWS scores had a greater overall c-index than dispatch data-based models for critical care and two-day morality, but at threshold values corresponding to high levels of sensitivity, dispatch data-based risk predictions provided similar levels of specificity. In predicting critical care, NEWS scores were unable to achieve a level of sensitivity corresponding to ACS-CoT guidelines, with a decision rule based on a NEWS score of 1 or more yielding a sensitivity (and 95% CI) of 0.92 (0.90 - 0.94) and a specificity of 0.24 (0.24 - 0.25). At the same level of sensitivity, the dispatch and ambulance data-based risk score yielded specificities of 0.27 (0.27 - 0.28) and 0.36 (0.35 - 0.37) respectively. With regards to 2-day mortality, a decision rule based on NEWS score of 2 or above yields a sensitivity of 0.95 (0.92 - 0.98), corresponding to the ACS-CoT recommendation, while providing a specificity of 0.41 (0.40 - 0.42). At equivalent levels of sensitivity, the dispatch and ambulance based risk scores provide specificities of 0.28 (0.27 - 0.28) and 0.52 (0.51 - 0.53) respectively.

Dotted line corresponds to 95% sensitivity as recommended by the ACS-CoT
Table 3 summarizes the discrimination of the risk assessment instruments for each outcome in the test dataset using the c-index of the model and its 95% confidence interval. ML models based on ambulance data outperformed NEWS scores in terms of c-index for all outcomes. The dispatch data based risk predictions outperformed NEWS in predicting hospital admission, while NEWS scores outperformed the dispatch data based predictions for critical care and two-day mortality in terms of overall discrimination. All risk assessment instruments outperformed dispatched priorities in predicting hospital outcomes, which were found to have some predictive power for critical care and two day mortality, but none for hospital admission. We found no significant differences between model performance using cross-validation and validation in the test dataset.
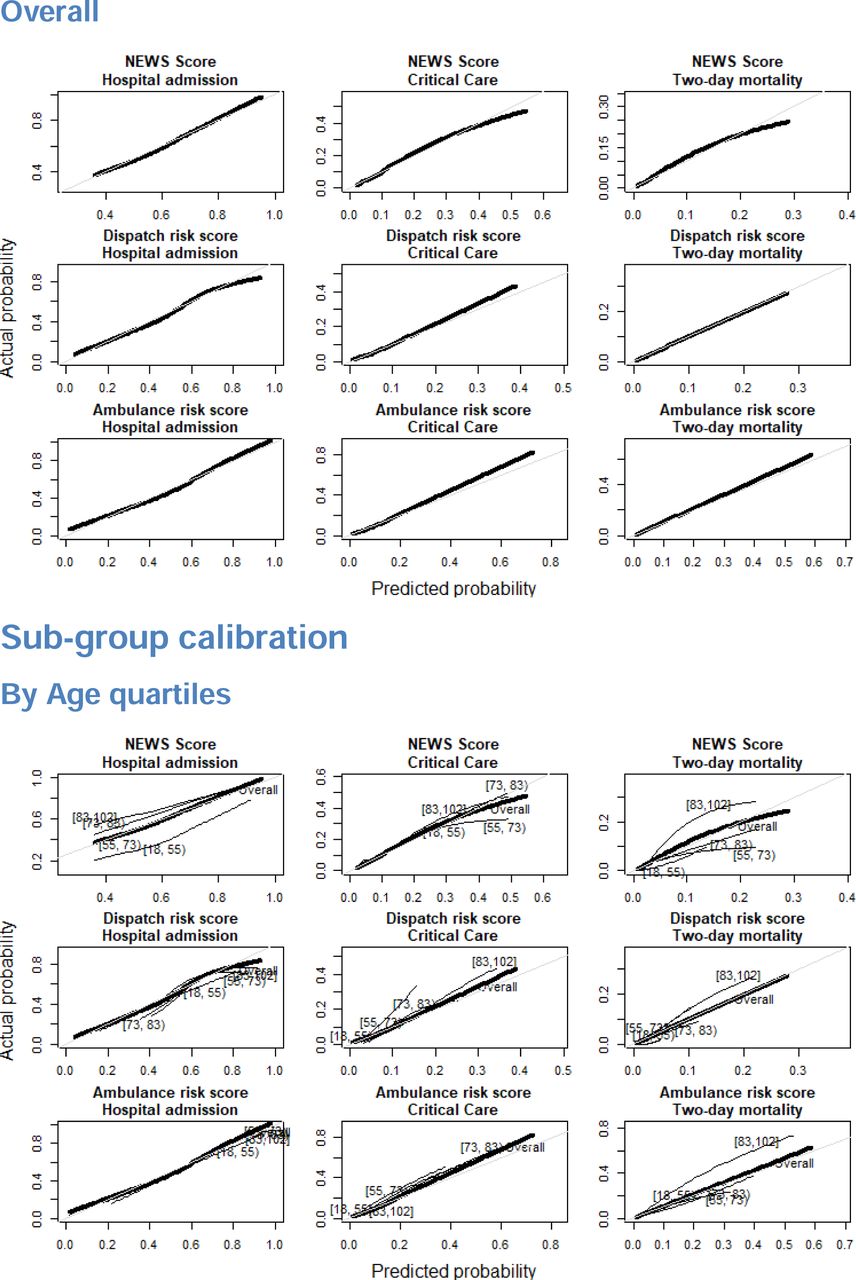
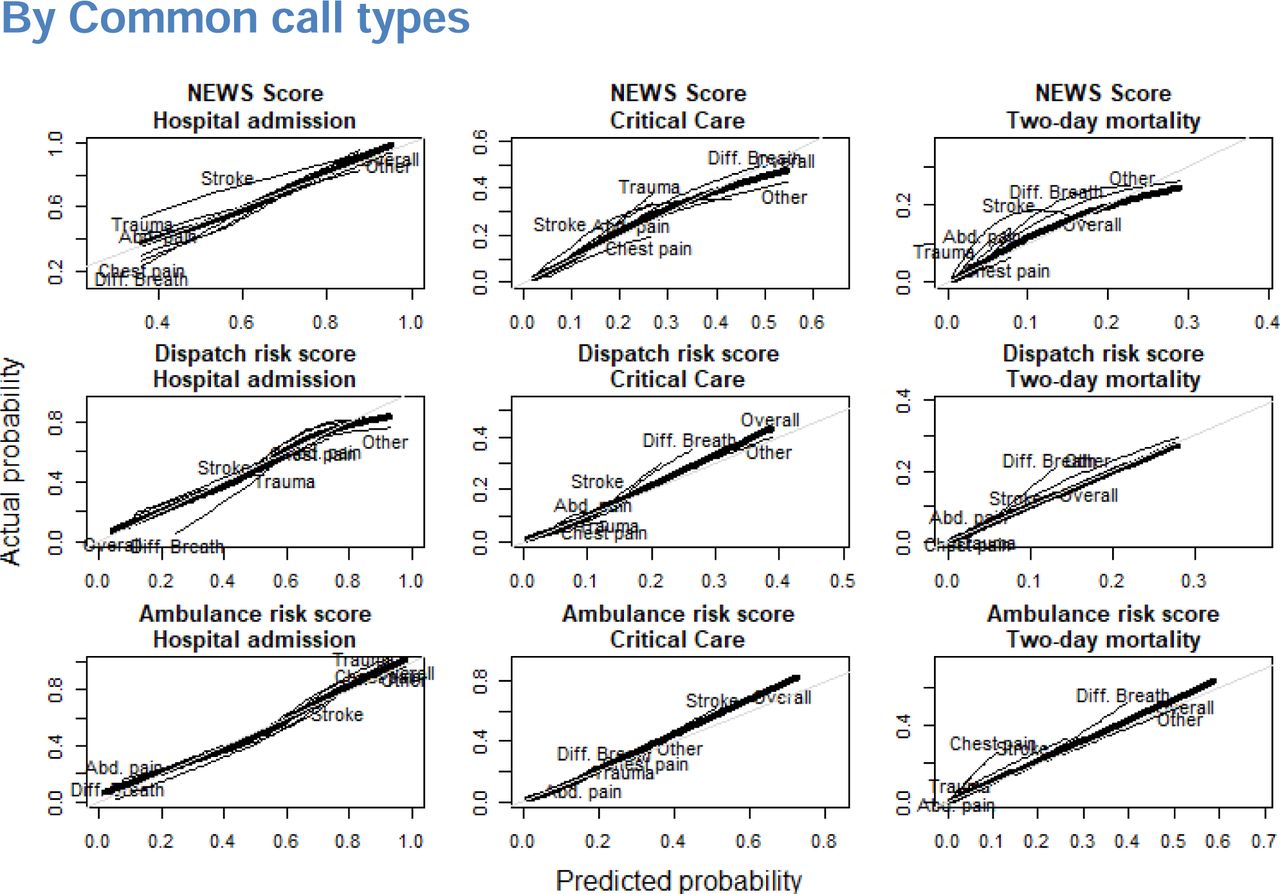
We found that both NEWS and ML-based risk scores demonstrated some deviation from ideal calibration as reported in S3 Fig. In terms of mean average error, NEWS scores demonstrated better overall calibration in predicting hospital admission and critical care, but not two-day mortality as reported in S4 Table. In investigating model calibration in sub-populations stratified by age, gender, dispatched priority and patient complaint, some sub-populations did deviate from ideal calibration among both NEWS scores and ML risk scores, though deviations were not consistent across outcomes.
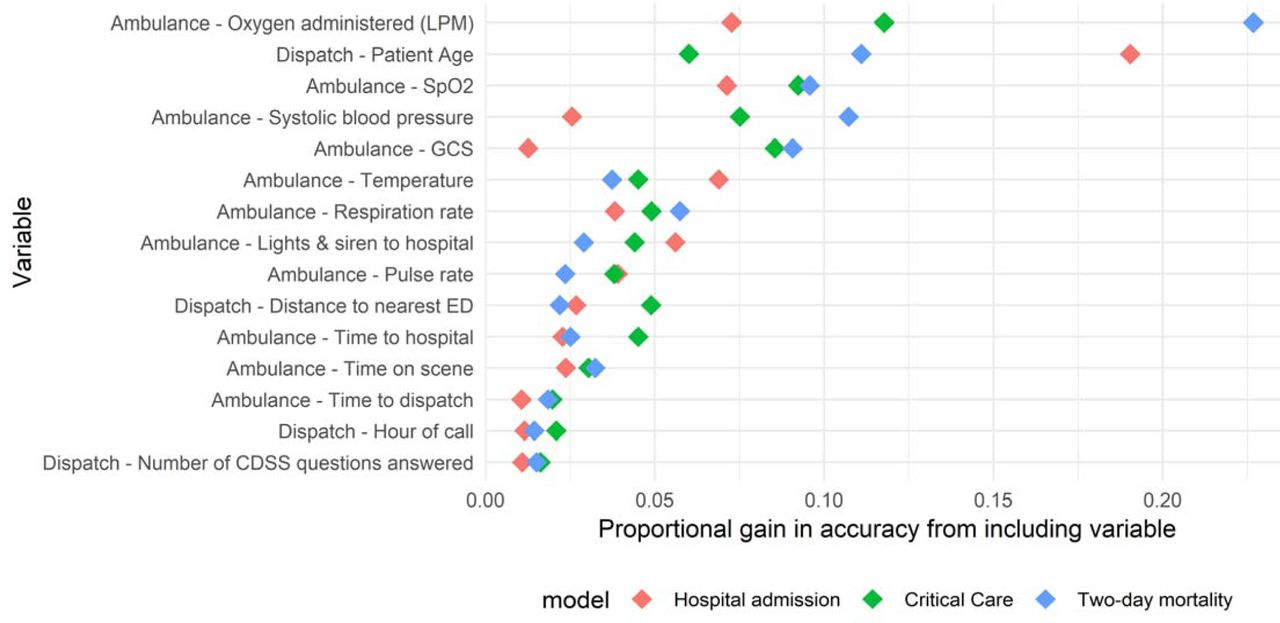
The relative gain in predictive value provided by the 15 most important predictors included in the ambulance data-based models is reported in Fig 2, in order of descending mean gain across the 3 outcomes. Patient age and the provision of oxygen (coded as the liter per minute flow) ranked highest, followed by a number of patient vital signs. Whether or not the patient was transported using lights and sirens to the hospital was a strong predictor of outcomes. A number of measures of call duration (time to the hospital, time on-scene, and time between call receipt and ambulance dispatch), the distance to the nearest ED, and time of day of the call also ranked highly. A summary of the gain provided by all included variables is provided in S1 Table.

Variables are arranged in order of descending mean gain across the models predicting the outcomes luded in the ambulance data-based risk score
Discussion
Limitations
We limited this study to the investigation of a composite score based on an unweighted average of model predictions for three specific hospital outcomes. In doing so, we make the assumption that each of these outcomes is equally important in determining the overall risks associated with the patient. A sensitivity analysis provided in S5 Table demonstrated that while the predictive value of the risk scores did shift in favor of more heavily weighted outcomes across a range of weights, the differences did not impact the main findings of this study. The unweighted average furthermore offered a good compromise in terms of discrimination for each of the constituent outcomes. The most appropriate set of outcomes and associated weights to employ is nevertheless dependent on the intended application of the risk scores, and we recognize that we have examined only one of many potentially valid sets of outcome measures to employ in prehospital risk assessment.
We observed a rate of loss to follow up of around 5-10% upon the application of each of our exclusion criteria. To assess and ameliorate risks associated with data quality issues, we manually spot-checked records to ensure the accuracy of our automated data extraction methods and addressed systematic data extraction issues where we found them, which could account for the lower rate of loss to follow-up we observed in the test dataset as reported in Table 1. The linkage rates found in this study were similar or superior to other studies of prehospital data [43–45]. We also observed c-index values for NEWS scores similar to those found in previous studies; Lane et al. [18] identified c-indexes of 0.85 for NEWS scores in predicting two-day mortality, similar to our value of 0.85 (0.82-0.86). Results were also similar to those identified by Pirneskoski et al. [19], who found a c-index value of 0.84 for NEWS scores in predicting 1-day mortality. Such agreement suggests that the quality of the data in this study is comparable to that of previously published research in the field.
While the ML models reported on in this single-site study performed well in prospective validation, they are not likely to generalize well if applied directly to other contexts. Guidelines regarding hospital admission and intensive care for instance may vary, potentially biasing outcome predictions if these models were applied directly in other settings. Such idiosyncrasies are likely to exist among predictor variables as well: Oxygen was found to have been administered to 17% of patients in this study for instance, a rate which appears to be lower than that found in other contexts [46,47]. In settings where oxygen is administered more liberally, it is not likely to be as strongly associated with patient acuity. The ML framework we employ is however highly flexible, and is likely to produce good results if models were to be trained “from scratch” on other similar datasets. As such, rather than seek to apply the specific models developed in this study to other settings, we encourage researchers to generate and validate novel models based on the framework we propose in other settings. To enhance reproducibility, we sought to adhere to TRIPOD guidelines in reporting our results regarding the development and validation of these models [48], and it is hoped that the source code found in S6 Code will facilitate the replication of-, and improvement upon our results.
Interpretation
In this study, we found that risk scores generated using ML models based on ambulance data outperformed NEWS scores in predicting hospital outcomes. Risk scores based on data gathered at the EMD center outperformed the prioritizations made by dispatch nurses, and performed comparably to NEWS scores (which are based on physiological data gathered upon patient contact) in settings where high sensitivity is demanded. Model performance was similar when validated internally using cross-validation and when evaluated in a prospectively gathered dataset, suggesting that the performance of the models is likely to remain stable upon being implemented within the studied context. ML-based risk scores demonstrated acceptable levels of calibration both overall and stratified by age, gender, priority and common call types, and were only mildly sensitive to the selection of alternate sets of weights. Overall, these findings suggest that the application of machine learning methods to routinely collected dispatch and ambulance data is a feasible approach to improving the ability of prehospital care providers to assess the risks associated with their patients in terms of the need for hospital care.
During the development of the methods reported here, we investigated the performance of a number of ML techniques including regularized logistic regression, support vector machines, random forests, gradient boosting, and deep neural networks in the training dataset. As in previous studies [27,49–51], we found that the XGBoost algorithm performed at least as well as other methods we applied to these data in terms of discrimination. We also found that the XGBoost algorithm had several practical benefits, including being invariant to monotonic transformations of the predictors (thus simplifying the data transformation pipeline) [39], and appropriately handling missing data using a sparsity-aware splitting algorithm [38]. While providing good discrimination, the approach does have some drawbacks including being somewhat difficult to interpret, the inability to update models without access to the full original dataset, and that the models are not inherently well calibrated as logistic regression for instance is.
We found the overall calibration of our composite risk scores to be satisfactory, despite their nature as an average of multiple outcomes. Examination of calibration across sub-populations yielded interesting results which could be further examined. We found NEWS scores for instance to systematically under-estimate the probability of hospital admission among older patients - Such miscalibration could be the result of an over-estimation of risks among older patients in the hospital admission process, but could also represent an underlying bias in NEWS scores as currently calculated. Interestingly, all risk scores tended to underestimate the probability of two-day mortality for the oldest quartile of patients. While the usual caution in interpreting post-hoc sub-group analyses is warranted, we found analyses of this type to be useful in developing the models reported here, and in considering how to proceed with their application to clinical practice.
While dispatcher prioritizations did have a statistically significant predictive value for critical care and two-day mortality, their discrimination was poor in comparison with all other risk assessment instruments with regards to hospital outcomes. This may in part be due to dispatchers prioritizing ambulance responses with an eye to the need for prehospital rather than in-hospital care. These aspects of patient care often coincide, but can in some cases differ. Cases of severe allergic reactions for instance call for a high priority ambulance response, but following treatment in the field by ambulance staff, often require only minimal in-hospital care. Effectively capturing this dimension of patient risk necessitates the definition of a different set of outcome measures than those reported here, and should be investigated in further studies.
We limited our analysis to hospital outcomes in order to allow for the direct comparison of models based on data collected at multiple points in the prehospital chain of care, and to facilitate comparison with other published research based on ED data. We also considered outcome measures based on ambulance data to be at greater risk for bias, as we suspect that the behavior of ambulance nurses may to some extent be influenced by the triage decisions of dispatch nurses. It should also be noted that the inclusion criteria used in this study were restrictive in that they excluded patients left at the scene of the incident, and patients transported to non-ED destinations. Upon implementation of these methods, care must be taken to ensure that the criteria used to include patients in a training dataset results in a population of patients similar to those upon whom the risk assessment tools will be applied.
Our models generally had lower levels of overall predictive value than found in previous studies investigating these outcomes based on data collected at the ED. This could in part be explained by population differences, given that the population of ambulance-transported patients investigated here constitutes a sum-population of the highest-acuity patients cared for at the ED [52–54]. The population in this study for instance had an average rate of in-hospital mortality of 4%, compared with the 0.5% rate found by Levin et al. [26], while our hospital admission rate was 52% as compared with the 30% found by Hong et al. [27], both of whom studied the full population of ED patients. It is also the case that the data available in records of prehospital care tend to be less detailed, lacking granular information regarding for instance the patient’s past medical history and laboratory test results. Such data have been found to provide substantial improvements to patient outcome predictions [27,29]. This study demonstrates that despite these barriers, prehospital data does have value in predicting hospital outcomes. We identified no studies of ED triage models which included prehospital data and as such, we suggest that one avenue for improving the performance of in-hospital triage models may be to include variables drawn from dispatch and ambulance records.
In conclusion, these results demonstrate that machine learning offers a viable approach to improving the accuracy of prehospital risk assessments, both in relation to existing rule-based triage algorithms, and current practice. Further research should investigate if the inclusion of additional unstructured data such as free-text notes and dispatch center call recordings could further improve the predictive value of the models reported here. Studies to investigate the attitudes of care providers with regards to risk assessments using ML may also prove fruitful; while ML methods can provide prehospital care providers with a more accurate risk score, the lack of direct interpretability often associated with such models may prove to be a barrier to acceptance. This study establishes only the feasibility of this approach to prehospital risk assessment, and further studies must establish the ability to influence the decisions of care providers and impact patient outcomes in prehospital care by means of prospective, preferably randomized, trial.
Data Availability
Our ethics approval limits us to the publication of results at the aggregate level only, precluding us from publishing individual-level patient data. The Swedish Data Protection Authority has furthermore not yet endorsed a process for the anonymization of individually identifiable data which could be applied to ensure compliance with the EU General Data Protection Regulation in publishing this type of sensitive data. Data underlying the results are owned by the Uppsala Ambulance Service, and are available for researchers who meet the criteria for access to confidential data. Please contact the Uppsala Ambulance Service at ambulanssjukvard{at}akademiska.se to arrange access to the data underlying this study.
Supporting Information
Descriptions of each set of predictors included in gradient boosting models, providing information regarding the number of non-missing, non-zero values among included calls, the average gain provided by the predictor, and the number of dummy-encoded variables included from the predictor in the models.

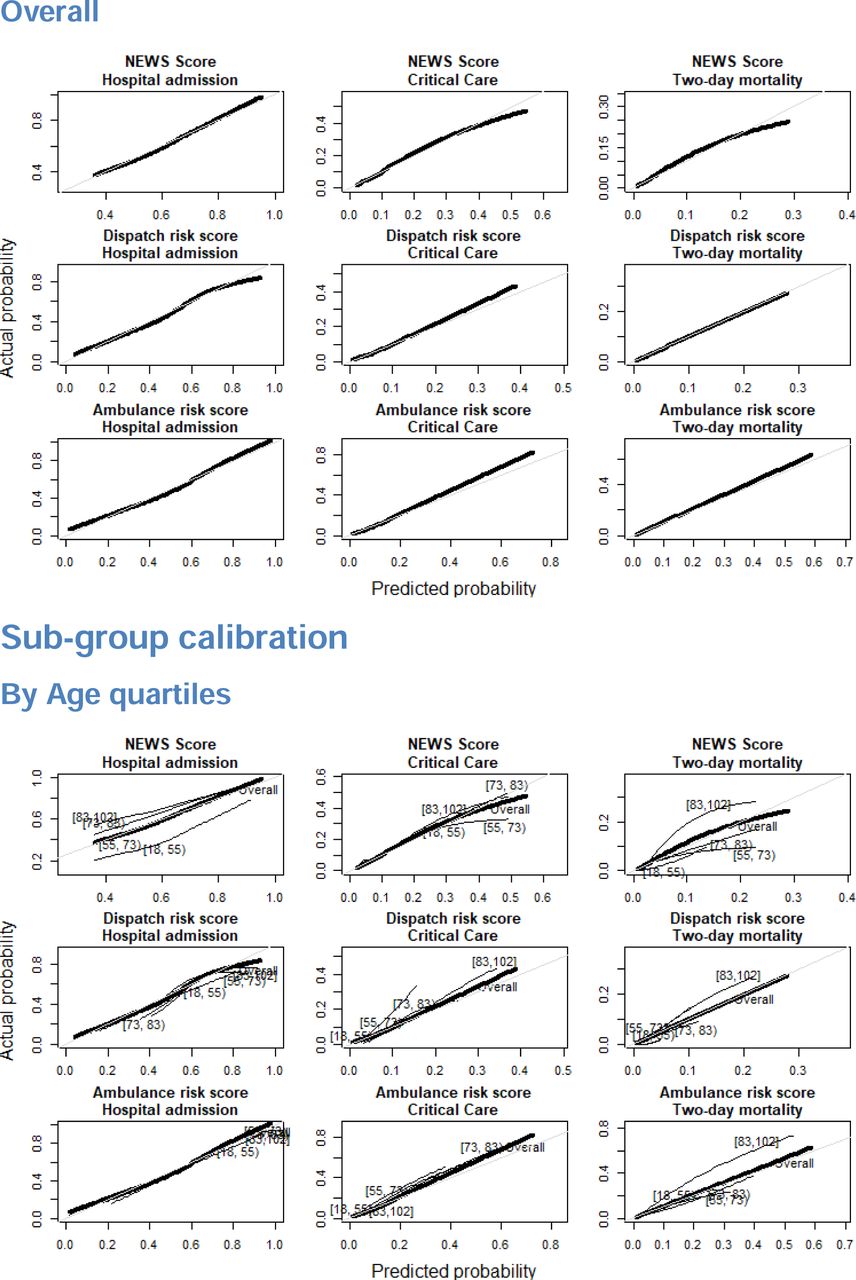
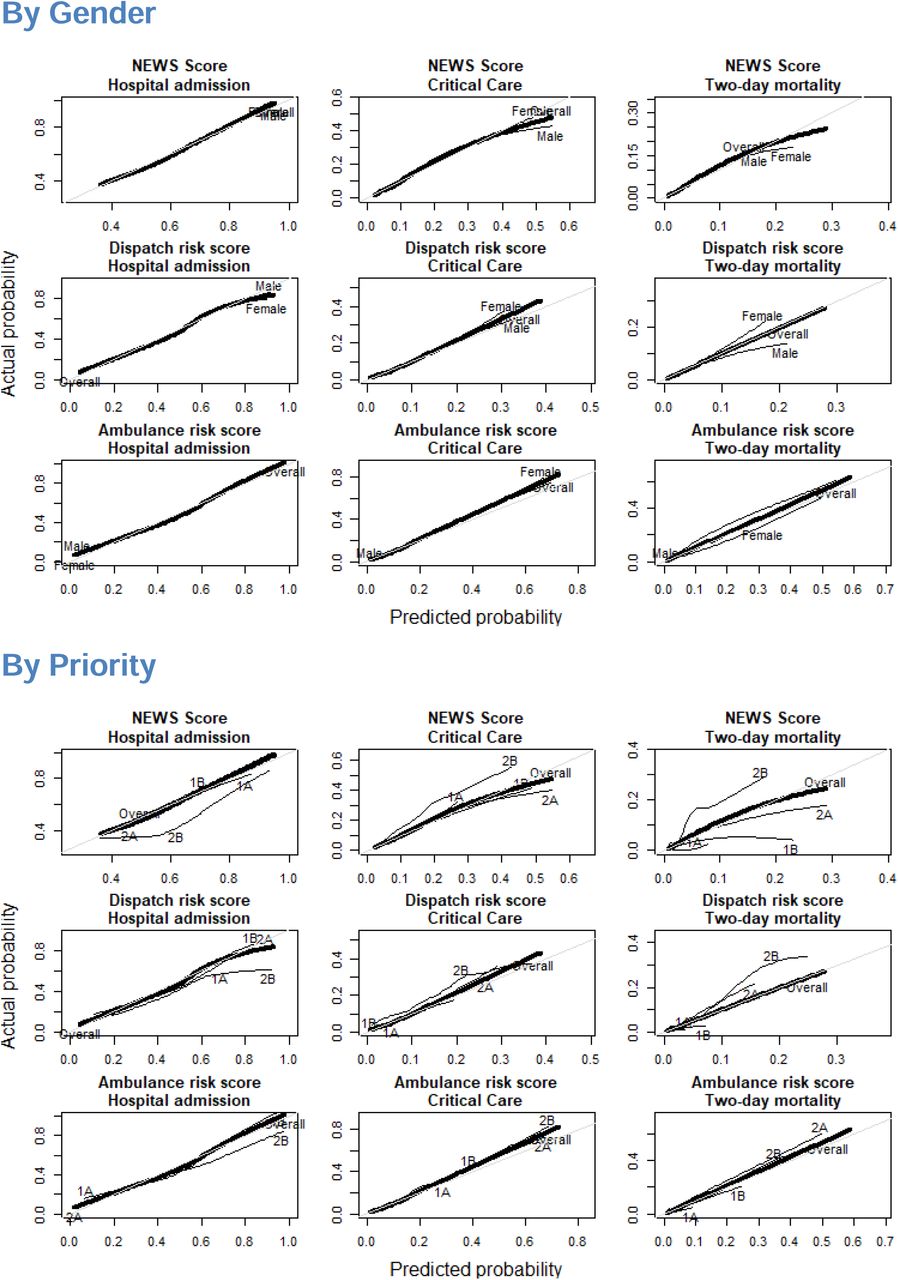

Provides the results of model calibration analyses using lowess smoothed calibration curves for both overall calibration, and calibration among sub-populations divided by age quartile, gender, call priority, and the 5 most common call types.
Provides summary statistics in the form of the mean average calibration error for NEWS and ML risk scores both in the full population, and the weighted average of all investigated sub-populations.
Reports c-indexes for risk scores across a range of alternate weighting schemes, including the performance of individual model predictions across all investigated outcomes.
S6 Code. R Source code
Provides all R code necessary to replicate the results reported in this manuscript in a user-provided dataset. If no dataset is provided, results are calculated in a randomly generated synthetic dataset mimicking the univariate properties of our data. Be aware that the instruments will demonstrate essentially no predictive power if data is not provided. Note to editor: Upon publication, a link to a github repository containing a maintained version of the code will be placed here. Note to preprint readers: We’ll be releasing the source code upon publication – Who knows if some eagle-eyed reviewer will spot some error?




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}