
Abstract
Background The main risk stratification tools for identifying high-risk individuals of cardiovascular disease (CVD) are based on Western populations. Few models are developed specifically for Asian populations and are not enhanced by artificial intelligence (AI). The aim of this study is to develop the first AI-powered quantitative predictive tool for CVD (PowerAI-CVD) incorporate physiological blood pressure measurements, existing diseases and medications, and laboratory tests from Chinese patients.
Methods The study analysed patients who attended family medicine clinics between 1st January 2000 and 31st December 2003. The primary outcome was major adverse cardiovascular events (MACE) defined as a composite of myocardial infarction, heart failure, transient ischaemic attack (TIA)/stroke or cardiovascular mortality, with follow-up until 31st December 2019. The performance of AI-driven models (CatBoost, XGBoost, Gradient Boosting, Multilayer Perceptron, Random Forest, Naïve Bayes, Decision Tree, k-Nearest Neighbor, AdaBoost, SVM-Sigmod) for predicting MACE was compared. Predicted probability (ranging between 0 and 1) of the best model (CatBoost) was used as the baseline in-silico marker to predict future MACE events during follow-up.
Results A total of 154,569 patients were included. Over a median follow-up of 16.1 (11.6-17.8) years, 31,061 (20.44%) suffered from MACE (annualised risk: 1.28%). The machine learning in-silico marker captured MACE risk from established risk variables (sex, age, mean systolic and diastolic blood pressure, existing cardiovascular diseases, medications (anticoagulants, antiplatelets, antihypertensive drugs, and statins) and laboratory tests (NLR, creatinine, ALP, AST, ALT, HbA1c, fasting glucose, triglyceride, LDL and HDL)). MACE incidences increased quantitatively with ascending quartiles of the in-silico marker. The CatBoost model showed the best performance with an area under the receiver operating characteristic curve of 0.869. The CatBoost model based in-silico marker shows significant prediction strength for future MACE events, across subgroups (age, sex, prior MACE, etc) and different follow-up durations.
Conclusions The AI-powered risk prediction tool can accurately forecast incident CVD events, allowing personalised risk prediction at the individual level. A dashboard for predictive analytics was developed, allowing real-time dynamic updates of risk estimates from new data. It can be easily incorporated into routine clinical use to aid clinicians and healthcare administrators to identify high-risk patients.

Introduction
Cardiovascular disease (CVD) is one of the leading causes of deaths globally, leading to health decline and increasing burdens of healthcare costs 1. The Global Burden of Diseases, Injuries, and Risk Factors Study (GBD) identified high systolic blood pressure as the leading modifiable risk factor for CVD, accounting for 10.8 million and 11.3 million deaths in 2021 2. In China alone, using the methods of GBD, stroke and ischaemic heart disease were identified as the major causes of death and disability-adjusted life-years (DALYs) 3. Therefore, there is a pressing need for effective risk stratification tools that enable clinicians to identify high-risk individuals and recommend treatment accordingly. Of the different tools, the Framingham CVD risk model 4, Systematic COronary Risk Evaluation (SCORE) 5, pooled cohort equations (PCEs)6, and QRisk 7were developed using data from Western populations.
However, Asian populations differ in terms of genetic background, environmental exposures and lifestyle choices, disease demographics and epidemiology. For example, Asians have a higher burden of stroke 8and hypertension 9 but lower burden of hyperlipidaemia 10. Whilst the risk factors for CVD are common to both Western and Asian populations, direct application of the above tools can lead to errors in risk estimates 11. Moreover, whilst calibration of existing tools is possible 12–14, even recalibration of the Framingham CVD risk model led to systematically overestimated CVD risk in older adults from Hong Kong, China 15. Yet, few models are specifically developed for Asian populations 16. These are Prediction for atherosclerotic CVD Risk in China (China-PAR) 17 and absolute risk score from the Japan Arteriosclerosis Longitudinal Study (JALS) 18. The limitation is that the China-PAR did not consider non-high-density lipoprotein cholesterol (non-HDL-C) or total cholesterol (TC), which are also important predictors 19. Furthermore, at the time of development, the application of artificial intelligence had not yet been popularised 20. AI approaches have indeed led to significant improvement in accuracy, sensitivity and specificity compared to regression-based models 21–23. Our team was the first to develop AI-based models for predicting adverse outcomes in patients with existing myocardial infarction 24, valvular heart disease 25, heart failure 26 and diabetes 27,28. In this study, we develop an AI-driven predictive model for forecasting first and recurrent cardiovascular events using a family medicine clinic cohort from Hong Kong. The novelty is that this model is the first Chinese-specific, validated AI-enhanced model that incorporates physiological blood pressure measurements, existing diseases and medications, and laboratory tests.
Methods
This study was approved by the Institutional Review Board of the University of Hong Kong/Hospital Authority Hong Kong West Cluster Institutional Review Board (HKU/HA HKWC IRB) (UW-20-250 and UW 23-339) and The Joint Chinese University of Hong Kong (CUHK) Hospital Authority New Territories East Cluster (NTEC) Clinical Research Ethics Committee (CREC) (2018.309 and 2018.643) and complied with the Declaration of Helsinki.
Study population
This was a retrospective population-based study of prospectively collected electronic health records using the Clinical Data Analysis and Reporting System (CDARS) managed by the Hong Kong Hospital Authority (HA). These records include information from public hospitals, their affiliated outpatient clinics, day-care centres and ambulatory care facilities. This system has been used extensively by local research teams 29–31. The inclusion criteria were patients who attended family medicine clinics in the Hong Kong Hospital Authority between 1st January 2000 to 31st December 2003. The exclusion criteria were patients who died within 30 days of the index date or those <18 years old.
Data extraction
The following clinical and laboratory data were extracted during the baseline period (1st January 2000 to 31st December 2003): demographics (sex and age), blood pressure (mean systolic blood pressure [SBP] and diastolic blood pressure [DBP]), prior comorbidities (diabetes, hypertension, chronic obstructive pulmonary disease, ischaemic heart disease, heart failure, myocardial infarction, and stroke/TIA), medication history and mortality outcomes, which are linked to the local government death registry. The diseases were identified based on International Classification of Diseases (ICD)-9 codes (Supplementary Appendix Table 1).
The following laboratory tests at the baseline period (January 1st, 2000 to December 31st, 2003) were extracted: neutrophil and lymphocyte count, x10^9/L; creatinine, μmol/L; alkaline phosphatase (ALP), U/L; aspartate transaminase, U/L; serum alanine aminotransferase (ALT), U/L; HbA1c, %; fasting glucose, mmol/L; low-density lipoprotein (LDL), high-density lipoprotein (HDL), triglyceride, mmol/L.
Outcome and statistical analysis
The primary outcome was MACE, defined as any of the following events: myocardial infarction, heart failure, TIA/stroke and cardiovascular mortality, with follow-up until 31st December 2019. Heart failure was included to capture the full spectrum of CVD development32. Continuous variables were presented as median (95% confidence interval [CI] or interquartile range [IQR]) and categorical variables were presented as frequency (%). The Mann-Whitney U test was used to compare continuous variables. The χ2 test with Yates’ correction was used for 2×2 contingency data, and Pearson’s χ2 test was used for contingency data for variables with more than two categories.
All significance tests were two-tailed and considered statistically significant when P-values <0.05. Data analyses were performed using RStudio software (Version: 1.1.456) and Python (Version: 3.6). Experiments were simulated on a 15-inch MacBook Pro with 2.2 GHz Intel Core i7 Processor and 16 GB RAM.
Model development
AL approaches have the advantages of directly considering the relationships and latent interactions between risk variables and outcomes, without requiring assumptions made in the Cox model. In this study, our objective was the development of an in-silico predictive marker utilizing machine learning techniques, amalgamating baseline clinical data points of family medicine patients. Our primary aim was to forecast the occurrence of Major Adverse Cardiovascular Events (MACE) during the follow-up period. The predictive model we constructed encompassed a diverse ensemble of machine learning algorithms, including CatBoost 33, XGBoost 34, Gradient Boosting 35, Multilayer Perceptron 36, Random Forest 37, Naïve Bayes 38, Decision Tree 39, k-Nearest Neighbor 40, AdaBoost 41, and SVM-Sigmod model42. We also incorporated logistic regression and a dummy classifier as baseline predictors to facilitate comparative analysis. The probability scores from the machine learning model were obtained for each patient as their in-silico marker of MACE event, which ranges from 0 (lowest probability) to 1 (highest probability), and was subsequently evaluated as a quantitative marker for future MACE events across subgroups (age, sex, prior MACE, etc) and different follow-up durations. Feature importance was calculated by both AUC reduction approach and SHAP tool 43, for cross-checking purpose.
Our workflow involved a random allocation of 80% of cases and an equal number of controls for training purposes, while the remaining 20% of cases and controls were reserved for validation. To mitigate potential sampling bias, this process was reiterated 100 times. To enhance model interpretability and reduce complexity 44, we applied the ReliefF feature selection method on the training dataset 45, and the resulting feature set was subsequently employed for validation. Additionally, we adopted a 10-fold cross-validation technique, utilizing a grid-search approach for hyperparameter optimization. The resultant predictive model demonstrated its efficacy in identifying MACE status within the validation dataset. Performance metrics were meticulously computed and reported as the mean, accompanied by a 95% confidence interval, across the 100 iterations of our analysis.
Results
Basic characteristics of the study cohort
A total of 155,066 patients who attended family medicine clinics managed by the Hong Kong Hospital Authority between 1st January 2000 and 31st December 2003 were included. Of these, 92 patients who died within 30 days after admission and 405 patients under 18 years old at admission were excluded (Figure 1). After exclusion, this cohort compromised a total of 154,569 patients (57.54% females, age at diagnosis: 65.85 [Interquartile range: 52.64-76.0 years old]; median follow-up duration: 15.66 years). The baseline characteristics of the cohort are presented in Table 1. Amongst the patients, 31,601 developed MACE, 6,704 developed new onset myocardial infarction, 13,826 developed new onset heart failure, and 10,446 developed stroke/TIA. Furthermore, 60,694 patients died during follow-up. The incidence of MACE and all-cause mortality are illustrated in Supplementary Figure 1.

MACE: Major adverse cardiovascular events; TIA: transient ischemic attack.
MACE: Major adverse cardiovascular events; TIA: transient ischemic attack; BP: Blood pressure; IQR: Interquartile range.
Comparison of different modelling approaches
The parameters that were significant in predicting specific MACE events in the univariate Cox model were identified as the key variables for inclusion (Supplementary Table 2). The variables that predict MACE and their optimal cut-off were identified (Supplementary Table 3). The relationship between the laboratory test results with MACE is illustrated in Supplementary Figure 2.
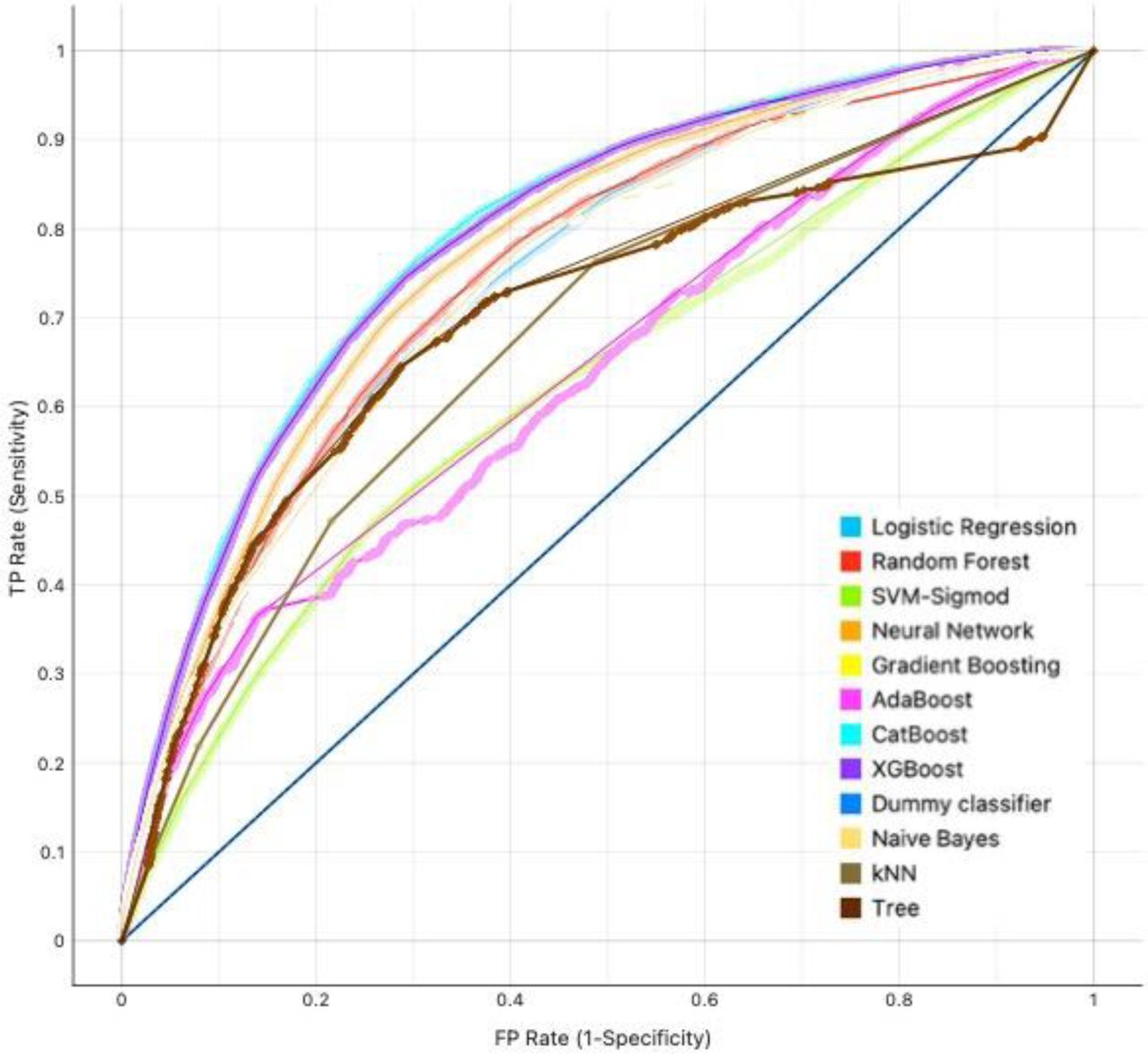
The performance of the logistic regression model and the different AI-driven models for the MACE and the specific MACE events were compared. CatBoost had the best performances compared to logistic regression and other AI-driven models in terms of area under the curve (AUC) (AUC: 0.868; 95% Confidence interval [CI]: 0.839-0.939]) (Table 2). The order in descending order of AUC: XGBoost, Gradient Boosting, Multilayer Perceptron, Random Forest, Logistic Regression, Naïve Bayes, Decision Tree, k-Nearest Neighbor, AdaBoost, SVM-Sigmod. CatBoost also had the best performances across all models in terms of CA (CA: 0.891; 95% Confidence interval [CI]: 0.856-0.925]), F1-score (F1: 0.836; 95% CI: 0.759-0.89), precision (Precision: 0.826; 95% CI: 0.733-0.889) and recall (Recall: 0.855; 95% CI: 0.842-0.882). The ROC curves for the different prediction models for the adverse outcomes are presented in Figure 2. Based on the above observations, the CatBoost model was selected as the most consistent modelling approach.
MACE: Major adverse cardiovascular events; AUC: Area under the curve; CI: Confidence interval.

AUC: Area under the curve; ROC: Receiver operating characteristic; CatBoost: Categorical boosting; XGboost: Extreme gradient boosting; kNN: k-nearest neighbour.
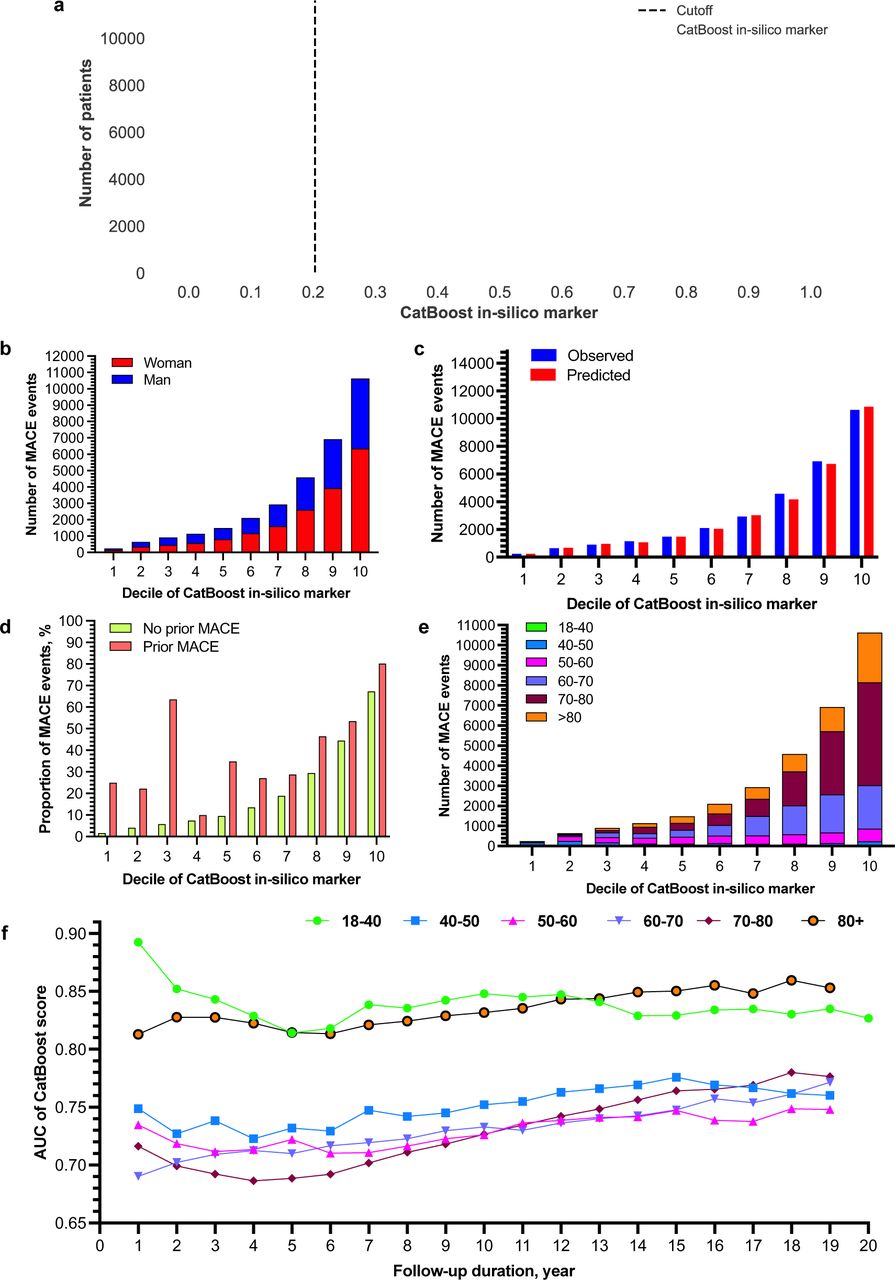
The derived CatBoost in-silico marker (Figure 3a) demonstrated good clarification ability to predict MACE events in men and women (Figure 3b), patients with/without prior MACE (Figure 3d), and in subgroups of patients by age admission (Figure 3e), stratified by ten deciles. The observed MACE events in each decile of the CatBoost in-silico marker was well predicted (Figure 3c), with the largest number of MACE events predicted in the 10th decile. The derived CatBoost in-silico marker had much better prediction performance for young patients (18-40 years old at admission) and the elderly patients (80+ years old at admission), with average AUC as 0.83 and 0.85 (Figure 3f), respectively. And the prediction performance across different age subgroups decreases slightly for those with less than 3-year follow-up duration, while increases afterwards.
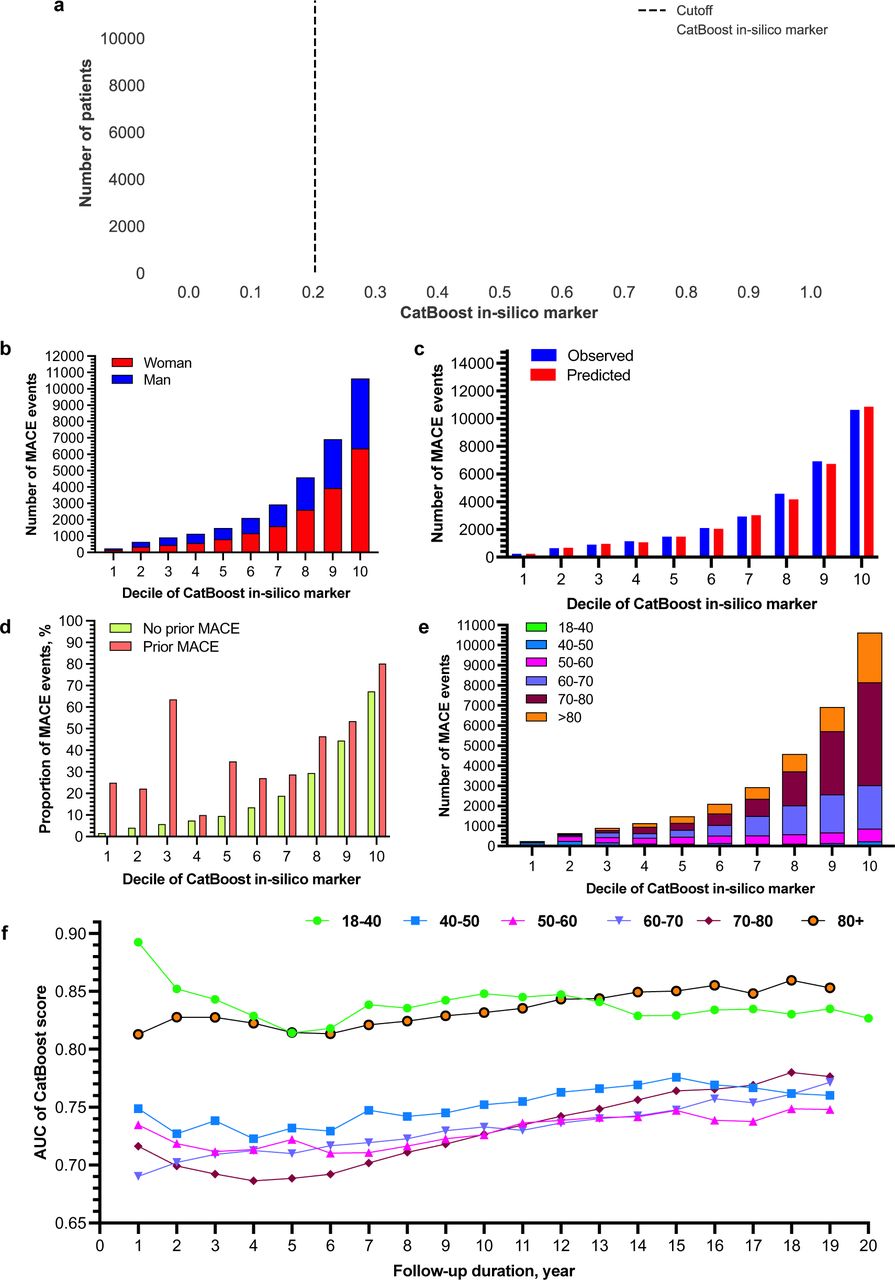
a. The number of patients cross the developed CatBoost model based in-silico marker and the cutoff. b. The number of MACE events amongst patients with different decile of CatBoost risk threshold values stratified by sex. c. Observed v.s. predicted number of MACE events by different decile of CatBoost risk threshold values. d. The number of MACE events amongst patients with different decile of CatBoost risk threshold values stratified by history of prior MACE. e. The number of MACE events amongst patients with different decile of CatBoost risk threshold values stratified by age. f. The AUC of the Catboost risk threshold values across the follow-up duration.
The prediction strength of the CatBoost model based in-silico marker
The distribution analysis demonstrated that the patients with new onset MACE had significantly higher risk threshold values in the CatBoost model compared to patients without new onset MACE (all P values <0.05) (Supplementary Table 4). The CatBoost model was evaluated on several partitions of the test population, including sex, age, history of prior MACE, and the follow-up duration. The results demonstrated that the CatBoost model was well-calibrated across both sexes. Meanwhile, the model was more well-calibrated amongst the older age group but less amongst patients younger than 60. Furthermore, the model was more well-calibrated amongst patients without prior MACE events. The predictive strength of the CatBoost model with different follow-up durations was calculated, and it was demonstrated that the risk of MACE prediction was significant across all years (all P value<0.05) (Supplementary Table 5). The AUC of the CatBoost model remained consistent across the follow-up durations (Figure 2e; Supplementary Figure 3). The predictive strength of the CatBoost model is illustrated in Figure 4. The increasing value of derived CatBoost in-silico marker indicate much predictive strength of future MACE events (and suboutcomes including cardiovascular mortality, myocardial infarction, heart failure, and stroke/TIA) and all-cause mortality by sex groups, which shows its usefulness in clinical practice as a good risk score system.

Prediction strength of the developed CatBoost model based in-silico marker (predicted probability within [0-1], with baseline and clinical characteristics) to predict future MACE in family medicine patients.
Important features for MACE using the CatBoost models
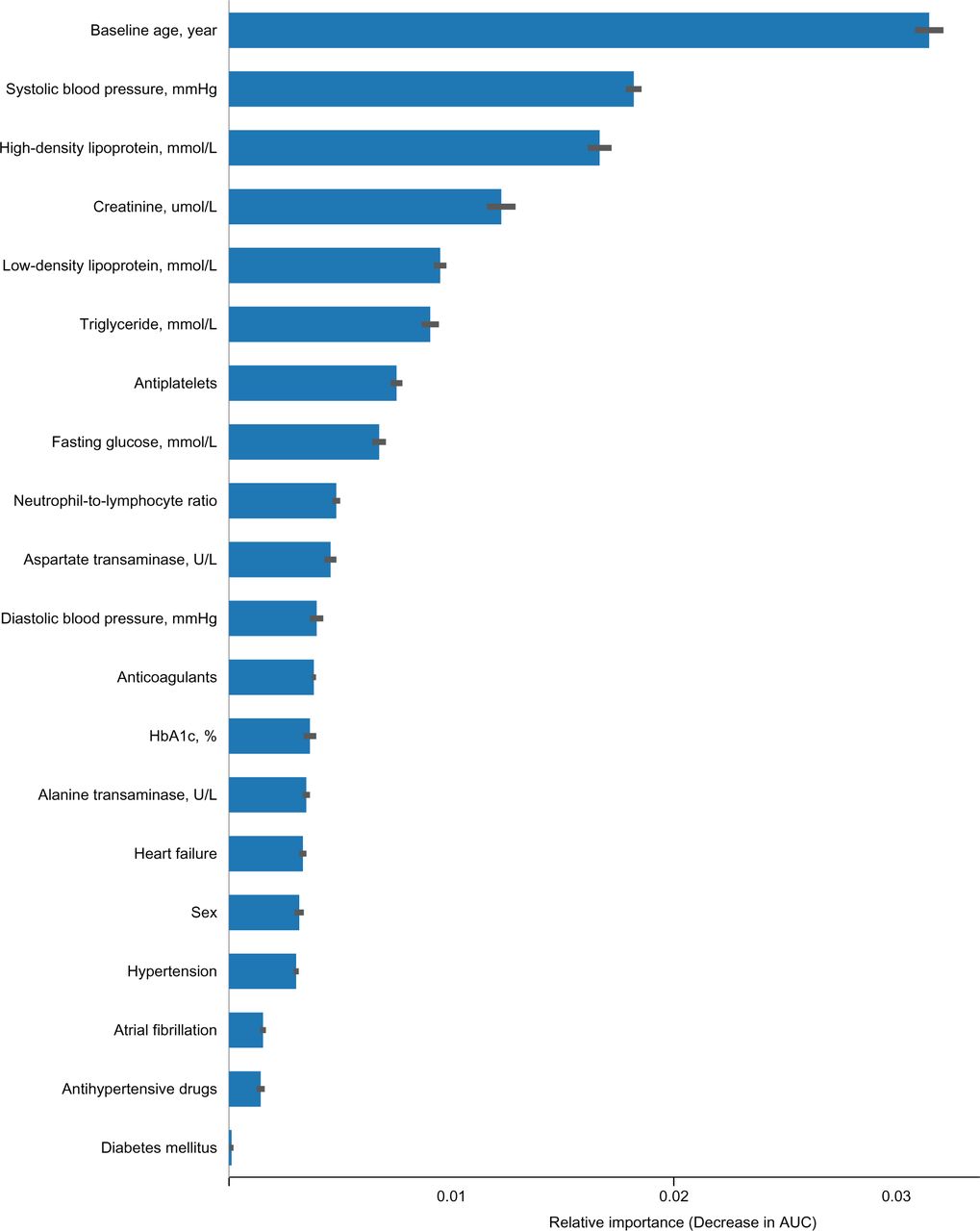
The feature importance was calculated using CatBoost to identify the variables with optimal effect when determining the MACE risk. The feature importance indicates how each variable contributes to the model’s accuracy. The 18 most influential predictors are presented in Figure 5. According to the result, baseline age was the most important feature of the model. The remaining top five important features included mean low-density lipoprotein, systolic blood pressure, creatinine level and mean triglyceride levels. The SHAP features importance for the CatBoost model was illustrated (Supplementary Figure 4). The relationship between age and MACE was demonstrated in the individual conditional expectation plot (Supplementary figure 5), which showed that most patients with the higher risk peaked at 80 years old and no obvious interaction was observed.

Importance ranking of the different features for the best machine learning model (CatBoost) to predict MACE in Hong Kong Chinese patients attending public family medicine clinics.
Dashboard for Model implementation
The PowerAI-CVD model supports clinical decision making by presenting key information on a dashboard (Figure 6). The most important input variables from current diseases, blood pressure, laboratory tests and existing medications are used for calculating the risk of MACE at 3, 5, 10 and 20 years. The trends of the different risk factors can aid clinicians and patients to monitor the effectiveness of ongoing lifestyle modifications and/or pharmacotherapy. The value of this dashboard is that appropriate recommendations for antihypertensive and lipid lowering drugs are available, with targets of blood pressure, lipid and glucose control. These functions can serve to facilitate guideline-directed treatment and improve adherence to best current practices to improve patient outcomes.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Model implementation. The dashboard shows the real-time risks using physiological blood pressure measurements, disease status, medications and laboratory findings.
Discussion
In this study, we developed the first AI-powered CVD model (PowerAI-CVD) to incorporate physiological blood pressure measurements, existing diseases and medications, and laboratory tests for predicting incident MACE using a big data approach. The main findings are that CatBoost significantly outperformed other machine learning and regression-based models.
Current risk models for CVD have been developed using Western cohort data. Yet, Chinese subjects have differing risks of different adverse events owing to differences in genetics, environment exposure, and disease status. For example, for stroke and TIA, the intracranial atherosclerosis more prevalent as an aetiology of stroke amongst Chinese46. Of the different risk factors, our analysis identified age, LDL and systolic blood pressure as the 3 most important risk factors. These findings are in line with the notion that age is the most determinant of a person’s cardiovascular health 47. For LDL, its concentration in the bloodstream and longer duration of exposure are both important predictive factors of CVD risk 48. Blood pressure influence local hemodynamics in the brain and the heart, leading to a higher translesional pressure gradient which is directly associated with risk of plaque rupture.
Accurate risk estimates are required to identify high-risk individuals who can benefit from treatment and prevent overtreatment of low-risk individuals. Given that prevention is better than cure, our tool can be used in primary care settings. A limited number of CVD risk models based on Asian cohort data are available 49. These have the major limitations of not having undergone validation, and not AI driven. By contrast, our team overcomes both limitations by developing the first AI-powered risk model for predicting new CVD events using territory-wide data from Hong Kong. Such a big data approach has the advantage of being highly generalisable as it is based on the entire population of Hong Kong, with the ability of analysing multiple clinically relevant outcomes. Our model is capable of considering new information with dynamic risk assessment 50. For example, with updated blood pressure and laboratory measurements, our dashboard can provide updated risks to the clinicians.
Clinical implications
The majority of the risk factors are modifiable, and by extension, CVD events are largely preventable. The predictors used in our PowerAI-CVD model do not require specialised testing, but rather demographics, disease status, medication history and routine laboratory parameters reflecting inflammatory, renal, liver, glycemic and lipid levels. The AI-powered risk prediction tool can accurately forecast incident CVD events, allowing personalised risk prediction at the individual level. A dashboard for predictive analytics was developed, allowing real-time dynamic updates of risk estimates from new data. Patients are also empowered as the dashboard provides information that is easy-to-understand. The model can thus be easily incorporated into routine clinical use to aid clinicians and healthcare administrators to identify high-risk patients. Personalised recommendations for lifestyle changes and suggested medications are provided, facilitating decision making and collaborative care between patients and their clinicians. In the long-run, implementation of this tool can reduce healthcare costs at the systems level, enabling sustainable development and healthy aging.
Limitations
As the aim of this the model was to provide long-term (>10 year) risk estimates, treatment effects from newer pharmacological agents such as proprotein convertase subtilisin/kexin type 9 (PCSK9) inhibitors and sodium-glucose cotransporter-2 (SGLT2) inhibitors are not considered. Future studies are underway to incorporate effects of these medication classes on CVD risk. Moreover, our team has previously reported the incremental value of incorporating visit-to-visit variability in blood pressure, lipid and glycaemic test results for improving risk stratification. Our subsequent studies will incorporate automated methods of considering such measures of variability to calculate not only the estimated future risks, but also likely trajectory of the risk estimates.
Conclusion
The first ever Chinese-specific, validated, CVD risk model with AI enhancement (PowerAI-CVD) was developed using a family medicine cohort of Chinese patients. It can accurately forecast incident CVD events, allowing personalised risk prediction at the individual level. A dashboard for predictive analytics was developed, allowing real-time dynamic updates of risk estimates from new data. It can be easily incorporated into routine clinical use to aid clinicians and healthcare administrators to identify high-risk patients.
Funding source
The authors received no funding for the research, authorship, and/or publication of this article.
Conflicts of Interest
The authors declare no conflict of interest.
Ethical approval statement
This study was approved by the Institutional Review Board of the University of Hong Kong/Hospital Authority Hong Kong West Cluster (HKU/HA HKWC IRB) (UW-20-250) and complied with the Declaration of Helsinki.
Availability of data and materials
An anonymised version without identifiable or personal information is available from the corresponding authors upon reasonable request for research purposes.
Guarantor Statement
All authors approved the final version of the manuscript. GT is the guarantor of this work and, as such, had full access to all the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis.
Author contributions
Data analysis: Lifang Li, Jiandong Zhou
Data review: Lei Lu, Gary Tse
Data acquisition: Carlin Chang, Teddy Tai Loy Lee, Hugo Hok Him Pui, Bosco Kwok Hei Leung
Data interpretation: All authors
Drafting of manuscript: Lifang Li, Oscar Chou, Gary Tse, Tong Liu, Jiandong Zhou Critical revision of manuscript: All authors
Study supervision: Carlin Chang, Abraham Ka Chung Wai, Bernard Man Yung Cheung, Gary Tse, Jiandong Zhou
Acknowledgements
This analysis uses data or information from the Harmonized CHARLS dataset and Codebook, Version D as of June 2021 developed by the Gateway to Global Aging Data. The development of the Harmonized CHARLS was funded by the National Institute on Aging (R01 AG030153, RC2 AG036619, R03 AG043052). For more information, please refer to https://g2aging.org/. The Authors are also grateful to The Chinese Longitudinal Healthy Longevity Survey (CLHLS) Team for making their datasets available to our team.
Footnotes
↵* Co-first authors
References




Subject Area
Reviews and Context
0
Comment
0
TRIP Peer Reviews
0
Community Reviews
0
Automated Services
0
Blogs/Media
Author Videos