
Abstract
Background Delay in diagnosing sepsis results in potentially preventable deaths. Mainly due to their complexity or limited applicability, machine learning (ML) models to predict sepsis have not yet become part of clinical routines. For this reason, we created a ML model that only requires complete blood count (CBC) diagnostics.
Methods Non-intensive care unit (non-ICU) data from a German tertiary care centre were collected from January 2014 to December 2021. Patient age, sex, and CBC parameters (haemoglobin, platelets, mean corpuscular volume, white and red blood cells) were utilised to train a boosted random forest, which predicts sepsis with ICU admission. Two external validations were conducted using data from another German tertiary care centre and the Medical Information Mart for Intensive Care IV database (MIMIC-IV). Using the subset of laboratory orders also including procalcitonin (PCT), an analogous model was trained with PCT as an additional feature.
Findings After exclusion, 1,381,358 laboratory requests (2016 from sepsis cases) were available. The derived CBC model shows an area under the receiver operating characteristic (AUROC) of 0.872 (95% CI, 0.857–0.887) for predicting sepsis. External validations show AUROCs of 0.805 (95% CI, 0.787–0.824) and 0.845 (95% CI, 0.837–0.852) for MIMIC-IV. The model including PCT revealed a significantly higher performance (AUROC: 0.857; 95% CI, 0.836–0.877) than PCT alone (AUROC: 0.790; 95% CI, 0.759–0.821; p<0.001).
Interpretation Our results demonstrate that routine CBC results could significantly improve diagnosis of sepsis when combined with ML. The CBC model can facilitate early sepsis prediction in non-ICU patients with high robustness in external validations. Its implementation in clinical decision support systems has strong potential to provide an essential time advantage and increase patient safety.
Funding The study was part of the AMPEL project (www.ampel.care), which is co-financed through public funds according to the budget decided by the Saxon State Parliament under the RL eHealthSax 2017/18 grant number 100331796.
Introduction
Sepsis is the cause of an estimated 20% of deaths worldwide.1 Early detection and treatment of sepsis substantially improves outcome.2–4 Several screening tools have been developed to identify septic patients in a timely fashion. Score-based early warning systems, such as Systemic Inflammatory Response Syndrome (SIRS), quick Sepsis-related Organ Failure Assessment (qSOFA), and National Early Warning Score (NEWS), lack either specificity or sensitivity outside the intensive care unit (ICU) and are usually performed only in cases of clinical suspicion.4–6 Though numerous biomarkers (over 250 by 2019) associated with sepsis have been identified, most are poorly evaluated for their role in clinical practice.7 Only procalcitonin (PCT) is implemented in current clinical sepsis guidelines, but its use is recommended only for discontinuation of antibiotic therapy.4
Screening tools based on machine learning (ML) have outperformed the traditional screening methods mentioned above in detecting and predicting sepsis, when focused on ICU data.8,9 Nearly all these models require various input features, including vital signs and clinical observations, that are often not available in electronic health records (EHRs), particularly in low- and middle-income countries where the incidence and mortality of sepsis is also high.1,9,10 A suitable prediction tool should predict sepsis early, ideally before ICU admission, and require only easily accessible clinical data. However, no corresponding ML model trained only on non-ICU data and not relying on vital signs has yet been published. With high applicability even in situations with missing further clinical information in mind, we describe here the application of ML to develop a precise prediction model from complete blood counts (CBCs) that enables early and reliable prediction of patients at risk of sepsis and ICU admission.
External validation is crucial for the assessment of model performance.11 In our study, we validated the model on an internal hold-out dataset, a large independent cohort from another tertiary care centre and the Medical Information Mart for Intensive Care IV database (MIMIC-IV). This dataset has been recently published and is the only public dataset that includes non-ICU data.12 To enable future development of related models, we make our data publicly available, which contains over 850,000 admissions to non-ICU wards.
Methods
In this retrospective cohort study, we included all in- and outpatients aged 18 or older of the University of Leipzig Medical Centre (UML) between January 2014 and December 2021, for whom we acquired age, sex, ICD-10 coded diagnoses, and, if applicable, time of admission to an ICU. Additionally, we collected the results of CBCs taken on all non-ICU wards and outpatient clinics. Blood samples were taken on normal wards on behalf of the attending physicians either routinely (in general, two to three times a week) or based on acute orders. Patients with incomplete CBCs or without a CBC were excluded.
The Ethics Committee at the Leipzig University Faculty of Medicine approved the study (reference number: 214/18-ek). This study is published in accordance with the Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) statement.13
Data Processing and Model Development
All data preprocessing was performed using R version 4.2.0 and the data.table R package version 1.14.2.14,15 Summary tables were built using the gtsummary R package version 1.6.0.16 The ML was carried out using MATLAB version 9.7.0.1247435 (R2019b).17
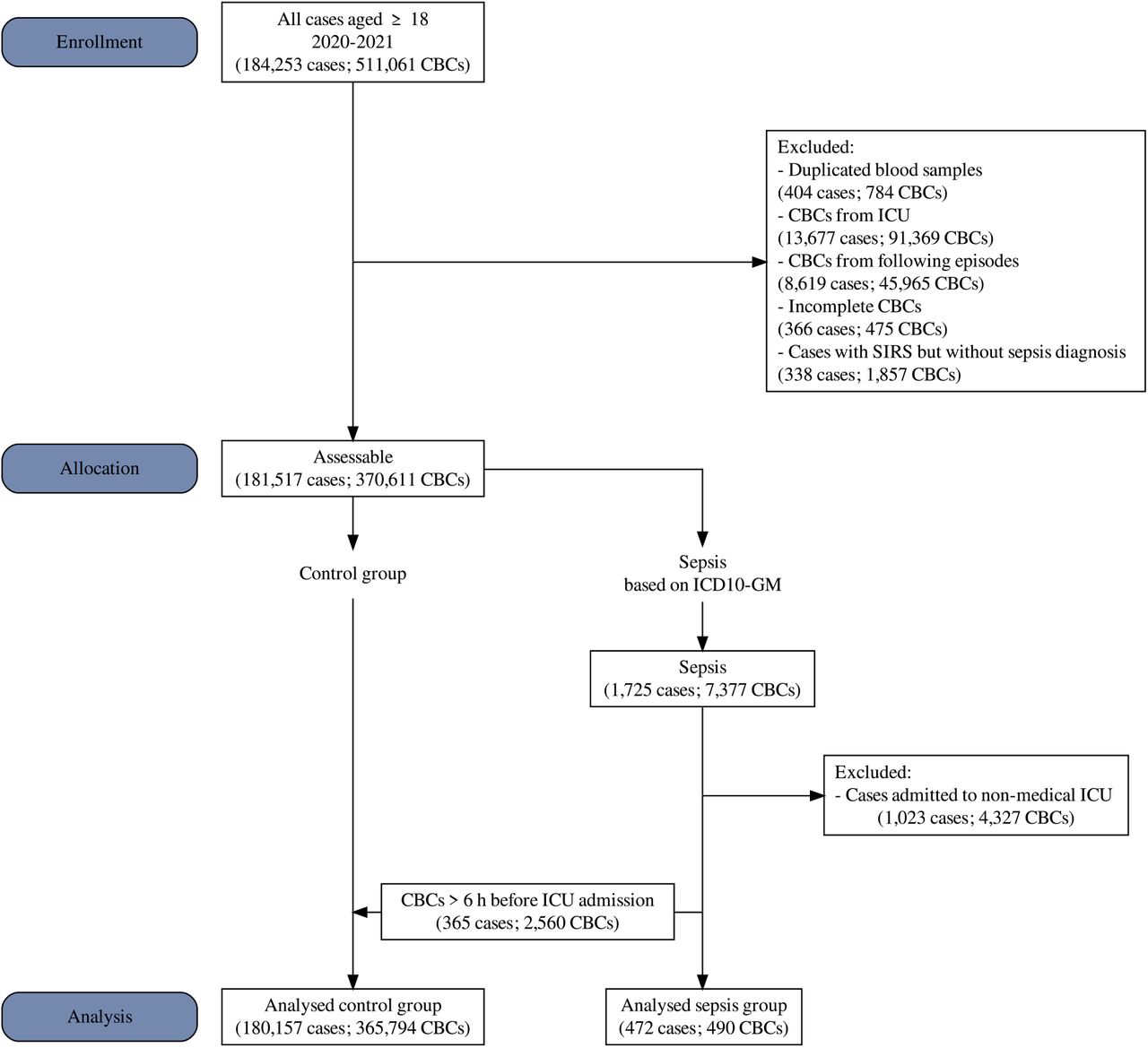
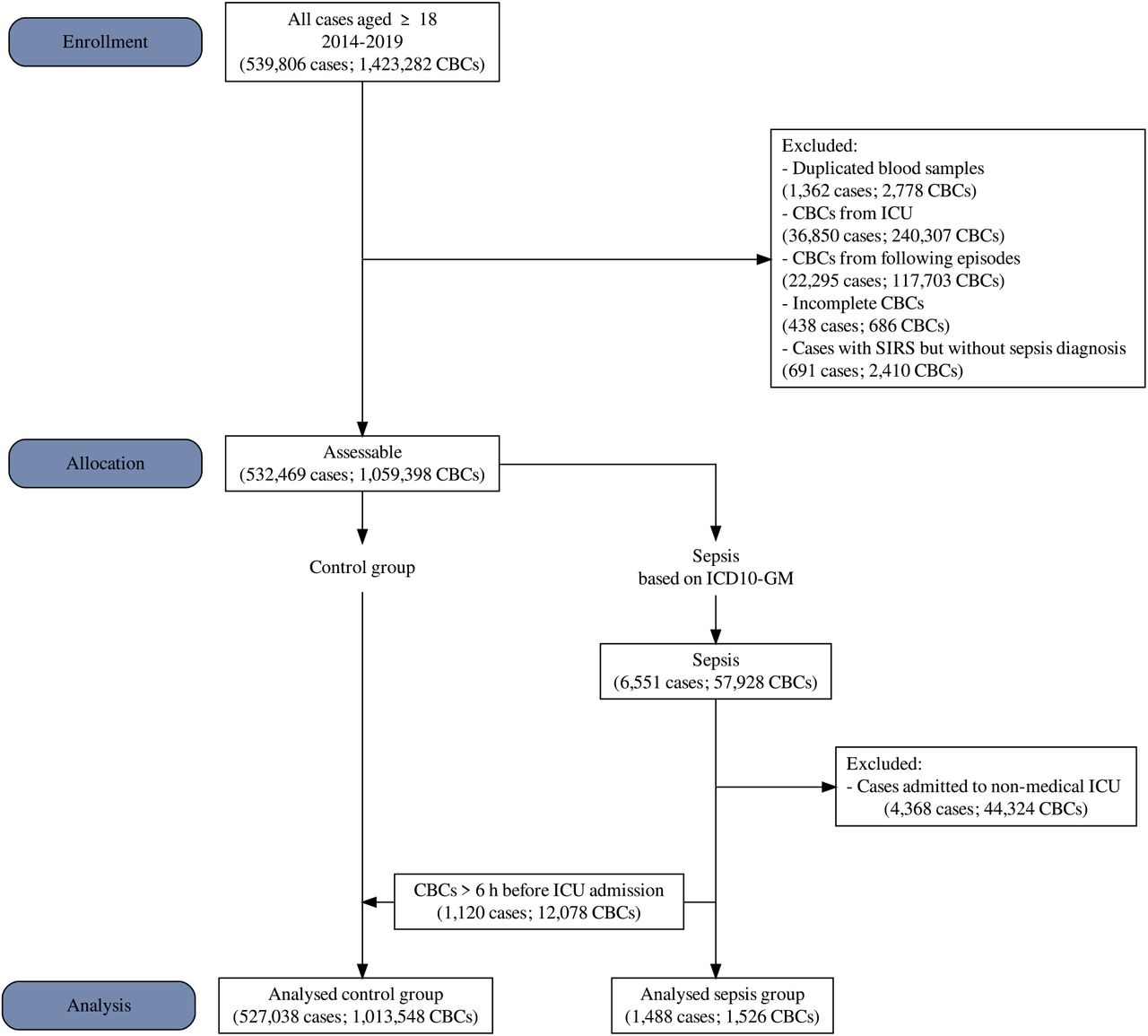
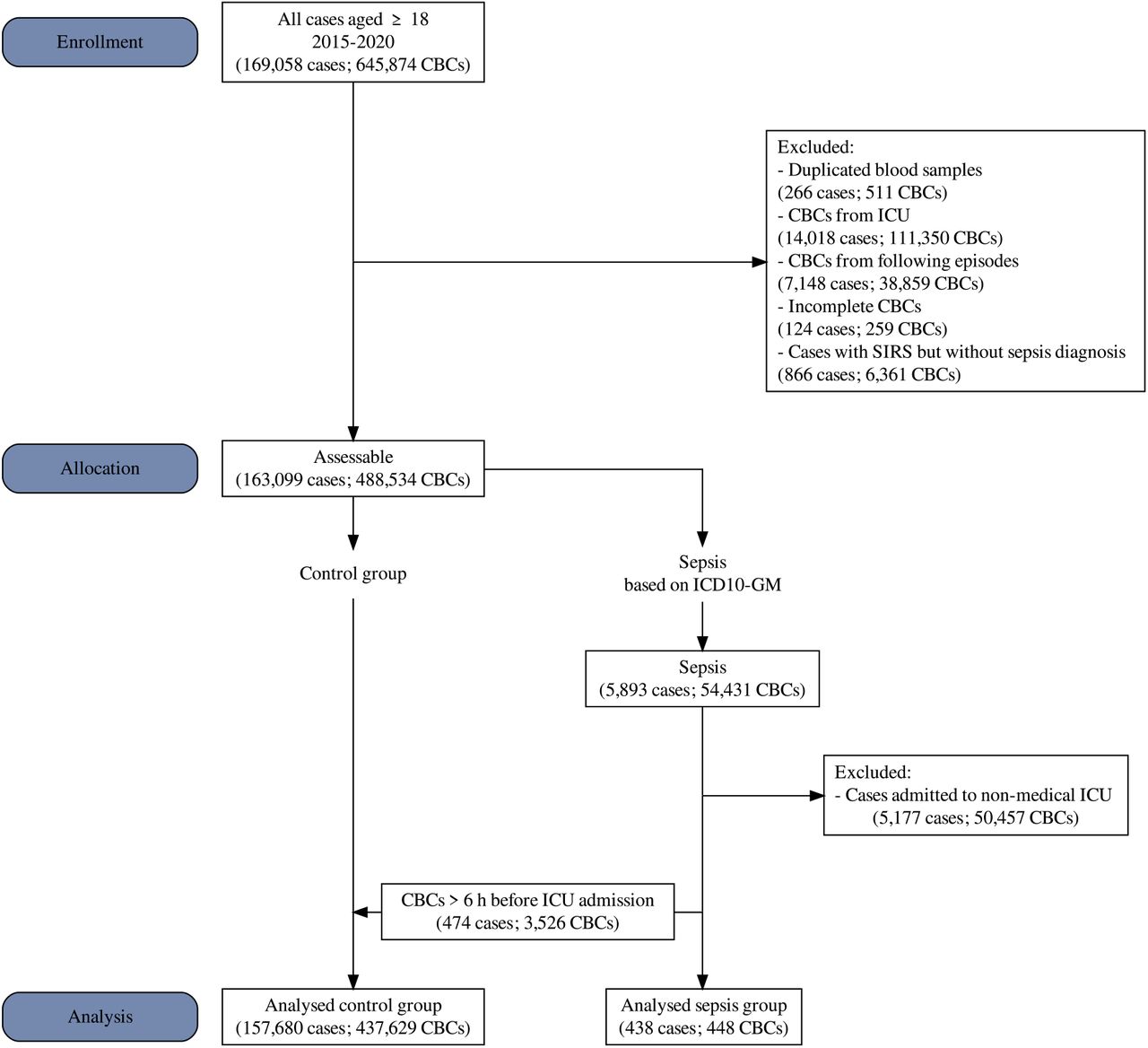
First, we divided the study data into control and sepsis groups according to sepsis-related ICD-10 codes. In the sepsis group, only CBCs from patients with ICU stay and admission were labelled. In sepsis cases with multiple admissions to ICUs, we expected the first ICU episode to be sepsis-related and excluded all subsequent CBCs. To avoid systemic bias of our results due to postoperative sepsis development and SIRS caused by the preceding interventions, we included only admissions to medical ICUs and excluded all cases that were explicitly coded as SIRS. As incomplete CBCs are rare in daily practice, we chose complete-case analysis. The resulting dataset was then split into a training dataset (UMLT 2014-2019) and a hold-out validation set (UMLV 2020-2021). All inclusion criteria are depicted in Figure 1.

The flowchart depicts the inclusion criteria and the size of the main dataset from UMLT.
UMLT: University of Leipzig Medical Center (Training Set); CBC: complete blood count; ICU: intensive care unit; SIRS: systemic inflammatory response syndrome; ICD-10-GM: International Statistical Classification of Diseases and Related Health Problems Version 10 – German Modification
We used the control or sepsis label as the response variable and age, sex, haemoglobin (HGB), mean corpuscular volume (MCV), platelets (PLTs), red blood cells (RBCs), and white blood count (WBC) as feature variables to train a random forest model. This selection of parameters was based on a laboratory medicine rationale, as these parameters represent the main characteristics of the CBC. For training, we used the RUSBoost algorithm,18 which is a hybrid sampling and boosting algorithm for ensemble learning. The random under sampling (RUS) balances the control and sepsis cases for the training of every tree by randomly selecting a sample of control cases equal to the number of sepsis cases. While still selecting one control CBC per sepsis CBC we oversampled the pre-septic CBCs that were taken more than 6 hours before ICU admission in the control group by a factor of 10. For hyperparameter optimisation a 5-fold cross-validation was performed. All CBCs were evaluated independently of previous or subsequent measurements. The prediction performance of our CBC model on all datasets was assessed using the area under the receiver operating characteristic (AUROC). To assess prediction performance as a function of time before ICU admission, separate AUROCs were calculated for different time intervals. In each of these intervals, CBCs of sepsis cases were labelled and used as response variable whereas subsequent CBCs were excluded. Clinically relevant sensitivity cut-offs of 90% and 50% were used for the calculation and illustration of specificities.
Model Validation
To validate the CBC model, we tested it on the hold-out validation set (UMLV 2020-2021) and two external datasets.
First, we acquired an equivalent dataset of all patients aged 18 or older admitted to the University Medicine Greifswald (UMG) between January 2015 and December 2020. We applied the same exclusion and data preprocessing steps as described above for the UML data. The Ethics Committee at UMG approved the study (reference number: BB133/10).
Second, we utilised the recently published and publicly available MIMIC-IV dataset.12 Before applying the same exclusion and data preprocessing steps as described above, we labelled the patients with sepsis based on ICD-9 and -10 codes, since only some of the cases in the MIMIC-IV dataset were coded using ICD-10.
PCT Comparison
To evaluate the performance of a trained prediction model in comparison with the biomarker PCT, we selected from the UML dataset all laboratory orders in which PCT was also measured. On the UMLT subset we trained a new CBC+PCT model analogous to the CBC model with PCT as an additional biomarker. To avoid overfitting the model due to the significantly smaller dataset, we limited the number of splits to 10 per tree. Statistical significance for the comparison was determined using the DeLong test.19 An alpha level of 0.05 was considered statistically significant.
More detailed information on the methods used in this study is presented in the supplement.
Results
Training and Internal Validation
At UML, 1,934,343 CBC measurements were performed in 724,059 cases from January 2014 to December 2021. The final UMLT dataset provided 1,013,548 CBCs (527,038 cases) in the control group, and 1,526 CBCs (1,488 cases) in the sepsis group, which met the inclusion criteria to train the ML model. More detailed information is displayed in Figure 1.
The sepsis sample consisted of 938 (63%) male and 550 (37%) female cases, with a median age of 67 (IQR, 57–76). The sepsis and control group differed significantly in all characteristics (see supplement for tabular comparisons). In 686 (0.05%) CBCs, at least one parameter was missing.
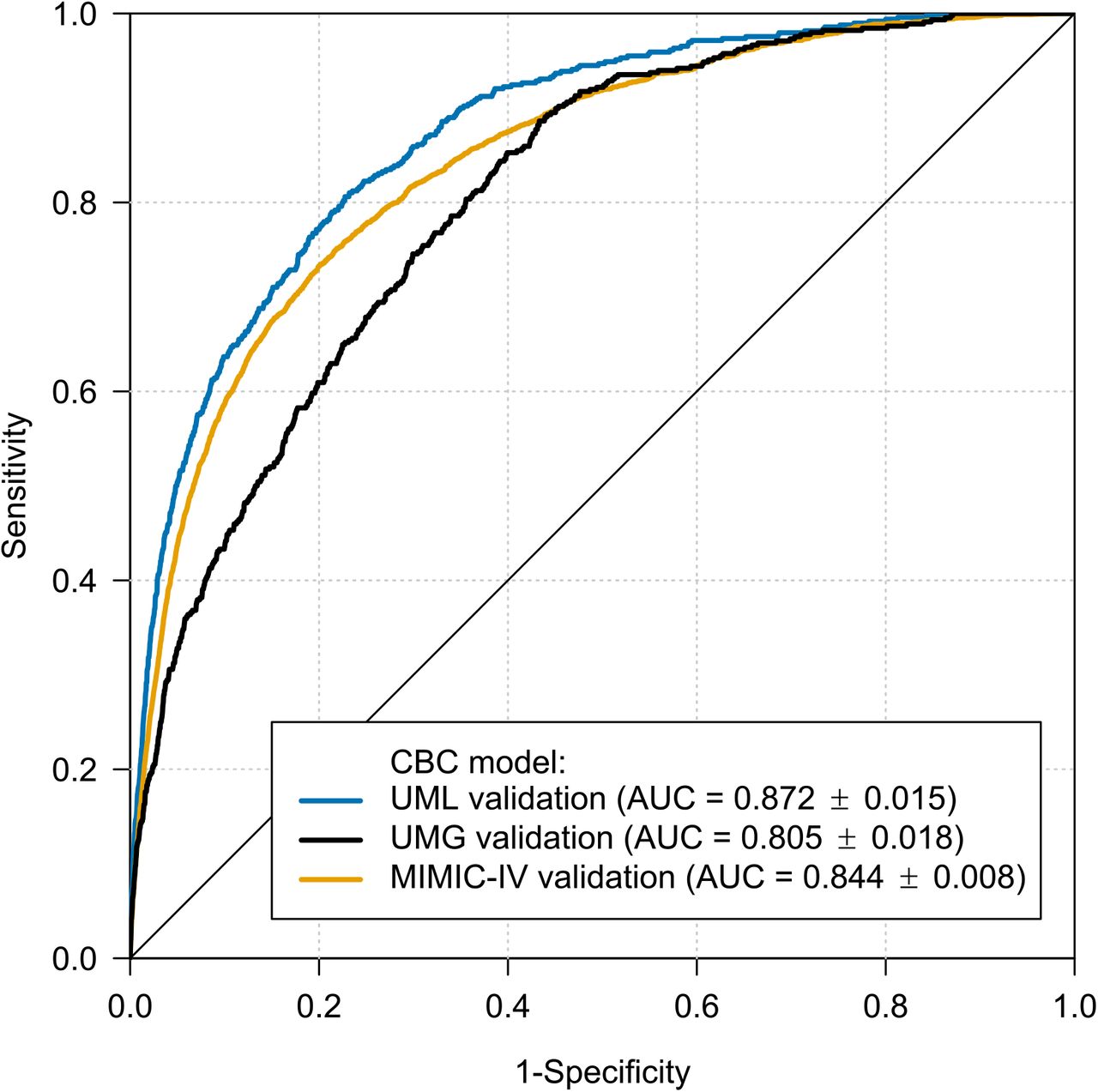
On the UMLV hold-out dataset, the AUROC of the derived CBC model was 0.872 (95% CI, 0.857–0.887, Figure 2). Adjusting the model to a sensitivity of 90% (S90), specificity was 65.1% (95% CI, 64.9–95.2); with a sensitivity of 50% (S50), specificity reached 95.2% (95% CI, 95.1–95.3). Corresponding to the sepsis label prevalence of 0.13% present in the final dataset, the positive predictive value (PPV) for S50 was 1.37% (95% CI, 1.2–1.55), and the negative predictive value (NPV) was 99.93% (95% CI, 99.92–99.94), versus PPV 0.34% (95% CI, 0.31– 0.38) and NPV 99.98% (95% CI, 99.97–99.98) for S90. Cohort analysis revealed the highest prevalence (0.81%) and PPV (5.2%; 95% CI, 4.46–6.03; S50) in the emergency department. Additional results of the cohort analysis and an illustration of the dependence of PPV on the prevalence and sensitivity can be found in the supplement.
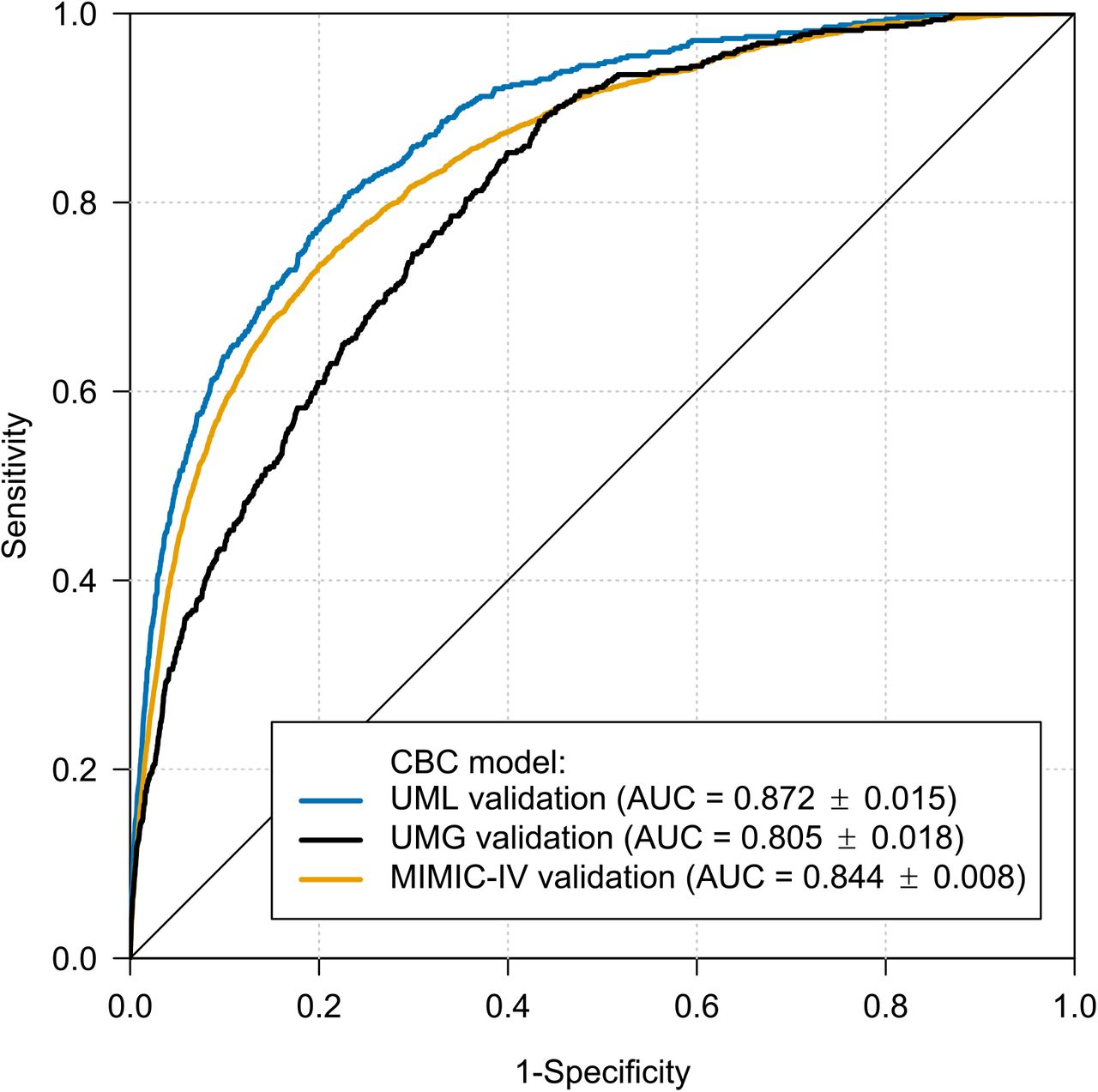
ROC curves of the CBC model for internal and external validation data.
ROC:receiver operating characteristic; AUC: area under the receiver operating characteristic with 95% confidence intervals; CBC: complete blood count; UML: University Medicine Leipzig; UMG: University Medicine Greifswald; MIMIC-IV: Medical Information Mart for Intensive Care IV database.
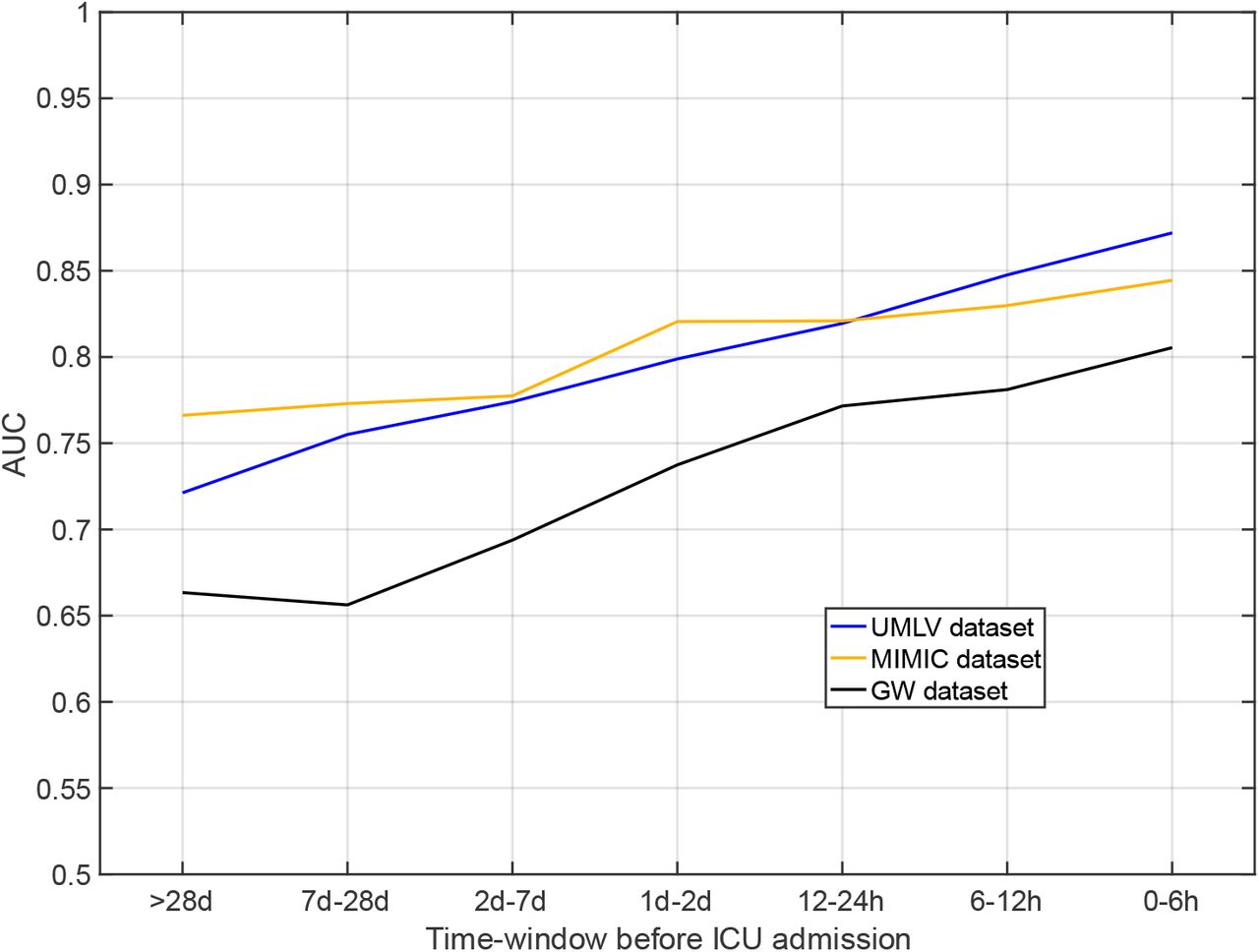
The AUROCs decreased with time interval to ICU admission to 0.848 for CBCs taken 6-12 h before ICU admission, 0.820 for 12-24 h, 0.799 for 24-48 h, 0.774 for 2-7 d and to a baseline AUROC of 0.721 for CBCs ordered 28 days or more before ICU admission (Figure 3). In addition to these temporal dynamics, significantly different score values were calculated between patients with and without sepsis diagnosis admitted to an ICU (Figure S2, supplement). Except for sex, all parameters showed relevant importance in the resulting ML model. WBC was found to have the largest impact on the prediction (Figure S8, supplement).
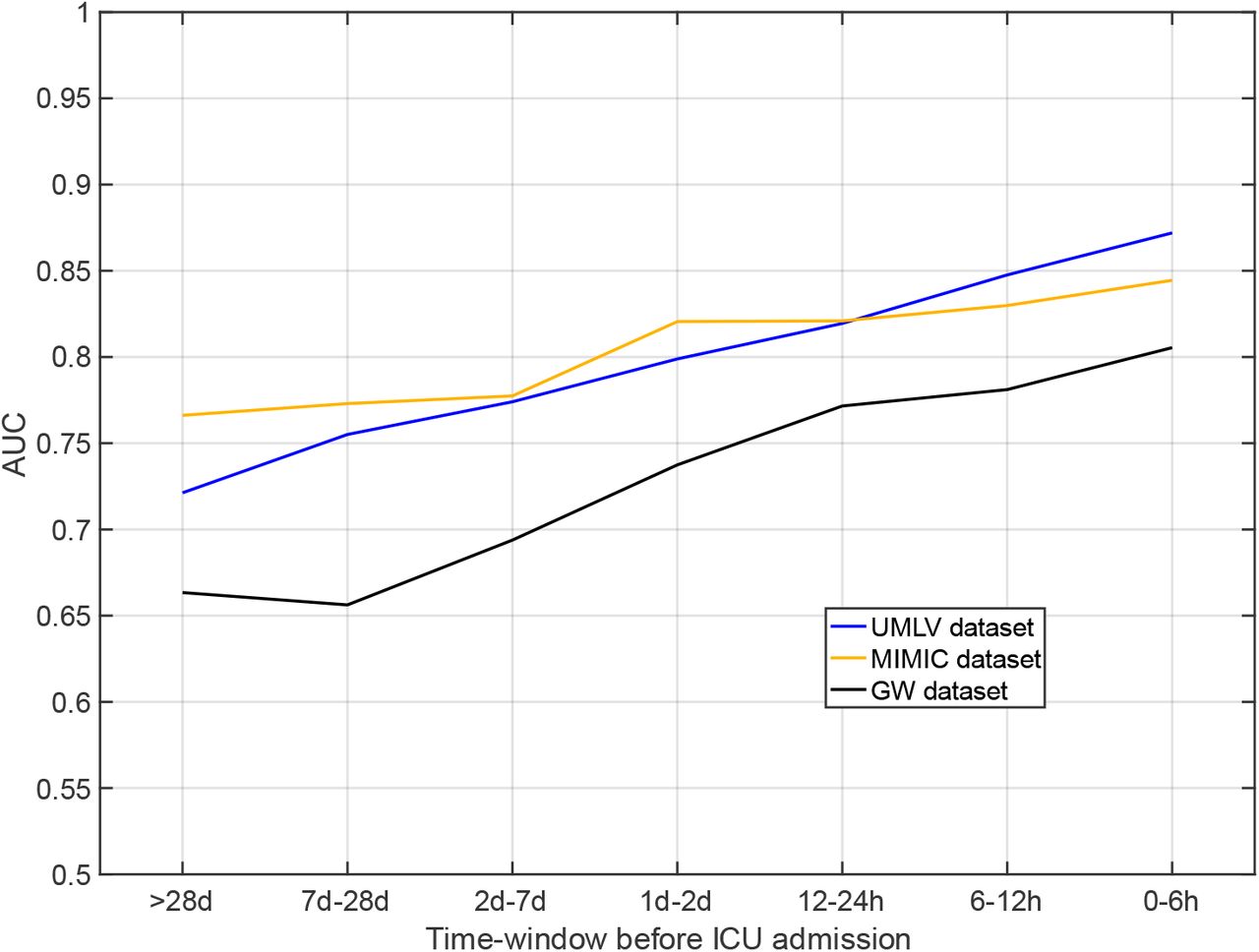
Temporal dynamics of the CBC model.
AUC: area under the receiver operating characteristic; CBC: complete blood count; ICU: intensive care unit, UMLV: University of Leipzig Medical Center (Validation Set); UMG: University Medicine Greifswald; MIMIC-IV: Medical Information Mart for Intensive Care IV database.
External Validations
The CBC model was tested on data from two large external datasets (UMG and MIMIC-IV). The UMG dataset consisted of 645,874 CBC measurements from 169,058 cases, performed between January 2015 and December 2020. With analogous application of the UML exclusion criteria, the final validation dataset included 437,629 CBCs (157,680 cases) in the control group and 448 CBCs (438 cases) in the sepsis cohort. The AUROC of the ML algorithm was 0.805 (95% CI, 0.787–0.824).
MIMIC-IV provides data from over 40,000 patients who stayed in ICUs of the Beth Israel Deaconess Medical Center (Boston, USA) from 2008 to 2019. In total, it contains 3,322,100 CBCs from 586,743 cases. After the exclusion process, 2,511,592 CBCs (559,135 cases), including 2,638 with positive sepsis labelling (2,513 cases), were available for validation. The AUROC of the CBC model (trained only with the UMLT data) remained high at 0.845 (95% CI, 0.837–0.852). Clinical and sociodemographic characteristics of the sepsis cohorts in the three datasets are displayed in Table 1.
Comparison Versus PCT
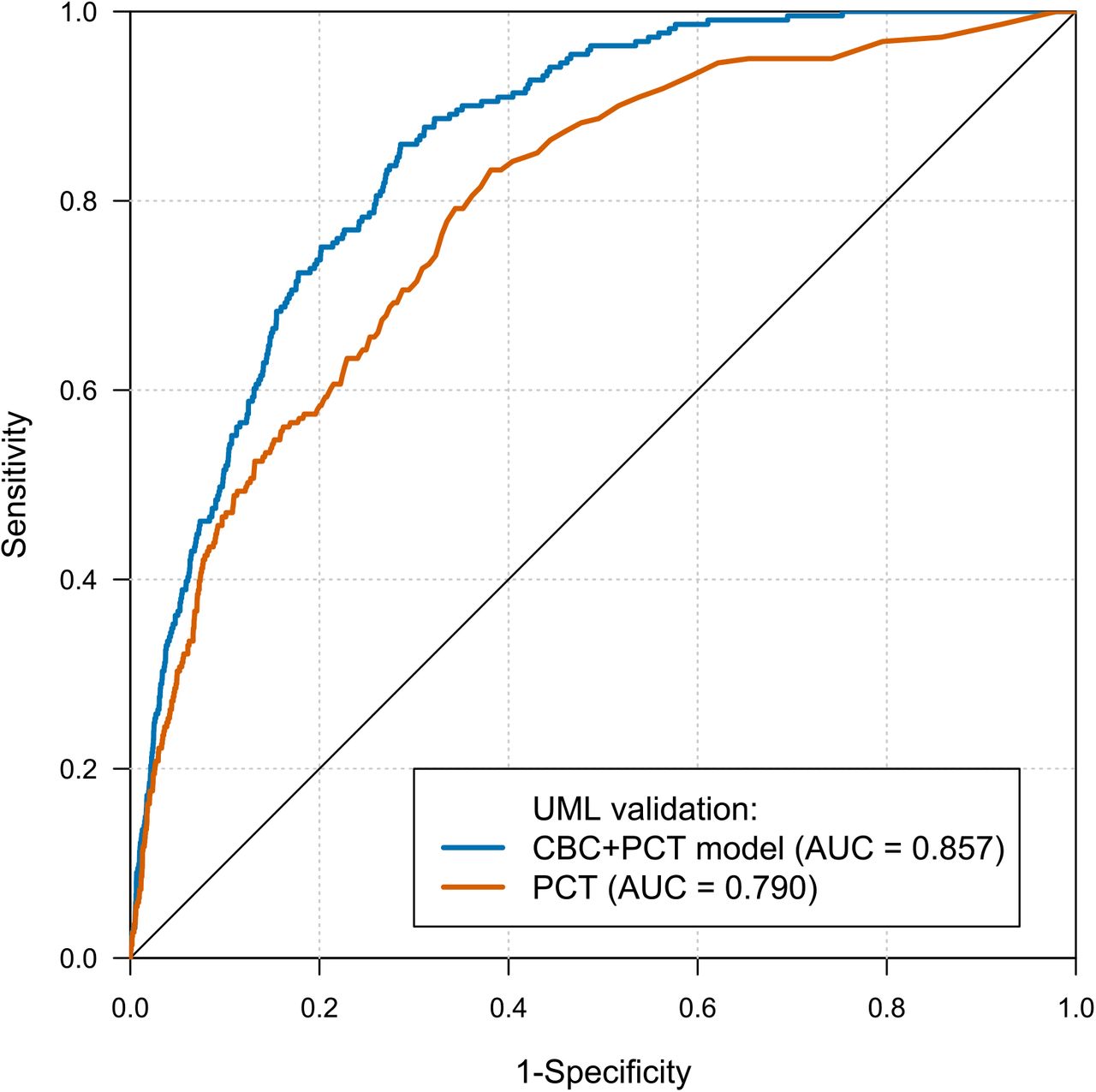
To evaluate the performance of the CBC model in comparison to the sepsis biomarker PCT, data from 17,898 cases with 24,125 simultaneous measurements of CBC and PCT, including 425 sepsis cases with 425 measurements, could be extracted from the UMLT dataset. The AUROC of the CBC+PCT model on the subset from UMLV was 0.857 (95% CI, 0.836–0.877), while the prediction performance of the biomarker PCT alone yielded an AUROC of 0.790 (95% CI, 0.759–0.821, Figure 4). The difference between both predictors was statistically significant (p<0.001).

ROC curves of the comparison of the CBC+PCT model to PCT.
ROC: receiver operating characteristic; AUC: area under the receiver operating characteristic; CBC: complete blood count; PCT: procalcitonin; UML: University Medicine Leipzig; The difference between both predictors is statistically significant (p<0.001, DeLong test).
Discussion
With this study, we demonstrate the first ML-based diagnostic approach for the prediction of sepsis and need for intensive care based solely on simple blood count diagnostics. The use of broadly available CBC data in the development of clinical decision support systems (CDSS) has the potential to improve clinical outcome through earlier diagnosis.
Currently, our unique diagnostic approach can be compared with the existing literature only to a limited extent. Other studies have applied different diagnostic parameters, patient populations, ML techniques, and endpoints.9,20,21 Importantly, the studies have significantly preselected patient collectives (e.g., with already existing sepsis suspicion) and used divergent sepsis definitions.22 To date, there are no published results of comparable approaches using the publicly available MIMIC-IV dataset.
Few ML-based approaches have reported an AUROC of >0.90, but all require a multitude of input features, some of which must be recorded hourly. Among these features are variables that are rarely available from EHRs, such as vital signs, blood cultures, current medication, and cormorbidities.23,24 Furthermore, extensive and costly laboratory measurements are not often requested outside the ICU. Even if data are available in ICUs, the corresponding algorithms are inadequate to support the treatment of non-ICU patients. Crucial for the clinical relevance of a sepsis alert system is the prediction of patients who are not yet under intensive care and have not yet been suspected of having an infection.25 To date, only one study that included non-ICU patients and was based solely on laboratory diagnostics has successfully predicted sepsis. Choi et al.26 identified five laboratory measurements (albumin, mean platelet volume, total protein, blood urea nitrogen, and alkaline phosphatase) as the optimal combination to distinguish septic patients and patients with fever without sepsis, achieving, without external validation, an AUROC of 0.83. However, the study did not differentiate ICU and non-ICU patients, and this extensive laboratory diagnostic is rarely requested simultaneously in standard medical care in Europe. Consequently, for optimal applicability, we limited ourselves to the commonly available CBC without differentiation of leucocytes and were able to show a precise discrimination of patients with sepsis from an unselected non-ICU patient cohort (AUROC 0.872). Additionally, we are not aware of any other ML model, based on either ICU or non-ICU data, which can predict sepsis from routine laboratory diagnostics, and that has been externally validated.
Our external validations proved the robustness of our approach, with AUROCs of 0.845 and 0.805, despite significant differences in the clinical and sociodemographic characteristics of the cohorts. A recently published independent validation of the most widely implemented early warning system for sepsis in U.S. hospitals, the Epic Sepsis Model (based on demographic, vital sign, laboratory, medication, procedural, and comorbidity variables) showed a rather poor performance with an AUROC of 0.63 and thus a high risk of alert fatigue.27 This finding underlines the importance of external validation and reveals a major lack of research in the field of ML models.
Another important aspect of the alert system is the prediction time prior to sepsis onset. Early warnings can be achieved if a model strongly weights the “baseline risk” of developing sepsis. However, to achieve the optimal clinical impact and prevent alarm fatigue, the model must warn close to the sepsis onset. We therefore optimised our model for temporal dynamics and were able to achieve a significant discriminatory power in the period 6-48 h before ICU admission. Only a few studies addressed this temporal dynamic before. Using only CBCs, our model is superior to these, and only outperformed by models that include complex clinical data directly before sepsis onset.9,21 There is no study that has systematically addressed AUROCs from baseline (e.g., weeks) as well as close to sepsis onset. Therefore, the proportion of “baseline risk” in the previously published models cannot be estimated.9,21 In our view this is of crucial importance, as only small differences between AUROCs at sepsis onset and baseline mean a large number of alarms without temporal context to sepsis onset. Future alerts from the same patient may not be seriously considered by the treating physicians and alert fatigue could result.
PCT is considered the best-established sepsis biomarker and is used in practice as laboratory confirmation of suspected sepsis. However, its predictive performance is not sufficient to be recommended for the diagnosis of sepsis by clinical guidelines.4 To achieve an increased diagnostic value the presented CBC model could be combined with PCT. The resulting CBC+PCT model significantly outperforms PCT in our data set. This underlines the great potential for further development by adding more diagnostic biomarkers and will be subject of future research. However, in the interest of broad applicability and given the unexpected high predictive power of the CBC, we decided to keep the prediction model simple without addition of further diagnostic parameters.
Our study has limitations. We carried out a retrospective trial based on ICD-10 coded diagnoses. ICD-10 coding strategies have an impact on the incidence rate of sepsis and may explain differences between our training and validation sites.28 However, for our data extraction, we used only explicit sepsis-related ICD-10 codes and performed validations (see supplement). According to the current literature, the true incidence of sepsis is underestimated by 1.4-to 3-fold.5,28 For this reason, it is plausible to assume that some patients were correctly predicted by our model but not coded. The alteration of the sepsis definition during our observation time may further influence the results.29 The high number of patients with only mild diseases may positively influence the AUROC. Therefore, we performed cohort analyses and could demonstrate a comparable performance (see supplement). Furthermore, we did not comprehensively evaluate the chosen ML algorithm, RUSBoost. A smaller or simpler model might provide similar results and other learning algorithms might achieve a better performance.9 However, a systematic comparison of different machine learning approaches was outside the scope of this study. Finally, due to our selection process, the application in (post-)surgical patients can only be assessed to a limited extent.
In conclusion, we have demonstrated that CBCs contain sufficient information that, when combined with ML, facilitates early and reliable prediction of patients at risk of ICU admission due to sepsis. Our approach showed high robustness in the validations and can be calculated with any CBC diagnostic at no additional cost. CBC diagnostics are widely available, easy to perform, highly standardised, generally well digitised and have a short turn-around time. Included in a CDSS, our CBC model could reduce the time needed to detect patients with sepsis who would benefit from ICU admission. This would allow a definitive therapy to be initiated much earlier and has the potential to significantly improve clinical outcome. We are currently in the process of initiating a prospective evaluation of our CBC model as part of our laboratory based CDSS (www.ampel.care).30
Data Availability
All data and code are published under the Creative Commons Attribution 4.0 International (CC BY 4.0) Public License.
Data Availability
Datasets from the UML and UMG and a conversion function for the MIMIC-IV data are available as an R package at https://github.com/ampel-leipzig/sbcdata. The MATLAB scripts are also available at https://github.com/ampel-leipzig/sbcmodel. All data and code are published under the Creative Commons Attribution 4.0 International (CC BY 4.0) Public License.
Author Contributions
Funding was acquired by TK. The study was conceptualised by SG, DS, MF, MS, PA, TK. The Data was acquired by MF. The data was analysed by SG, DS, PA. Software was written by SG, DS, PA. Original drafts of the manuscript were written by SG, DS, PA, TK. Drafts were edited and reviewed by CL, LH, MF, MG, MN, BI, MS. Visualisations were produced by SG, MS, PA. The model was validated with a randomly selected prospective patient cohort by LH. The project was supervised by SG, TK.
Declaration of Interests
No competing interests
The study was supported by the AMPEL project (www.ampel.care). This project is co-financed through public funds according to the budget decided by the Saxon State Parliament under the RL eHealthSax 2017/18 grant number 100331796. The funder provided support in the form of salaries for authors PA, MS, LH, and SG. The author DS was funded by the POLAR_MI project of the German Federal Ministry of Education and Research under grant number 01ZZ1910[A-Z]. Both funders did not have any additional role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript. All authors have completed the ICMJE uniform disclosure form at http://www.icmje.org/disclosure-of-interest/ and declare: no support from any organisation for the submitted work; no financial relationships with any organisations that might have an interest in the submitted work in the previous three years; no other relationships or activities that could appear to have influenced the submitted work.
Supplementary Material
Validation of sepsis label based on ICD-10 Codes
Since it was not possible for us to separate sepsis from ICU admission, we compared the validation set based on ICD-10 coded administration data with data prospectively collected as part of our quality improvement initiative (10.1097/CCM.0000000000002069) at UMG. The dataset of the initiative contains only patients with severe sepsis or septic shock. We found that patients from the medical ICU (only data for 2015 and 2016) and surgical ICU (2015-2020) that are present in both databases fulfil the sepsis definition at the time of ICU admission (difference of ICU admission and sepsis onset according to the sepsis definition, medical patients: -0.6 h [-1.4,0.6], Median [25%,75% quartile]); surgical patients: 0.8 hours [-0.3,6.9], Median [25%,75% quartile]).
Given the size of our data set, it was not possible for us to check all cases individually. However, we manually examined sample subsets at UML. In 60 random cases identified as “true positives” we detected 9 cases (15%) with sepsis onset >7d after ICU admission. In 89 random cases identified as “true positives” we found 2 cases (2%) that were labeled with sepsis ICD-10 codes without this being plausibly supported by the patient file. A random sample of 75 “false positives” revealed that 4 cases (5%) had a diagnosis of sepsis in the discharge letter but were not coded with ICD. This is significantly higher than would be expected given the sepsis prevalence in the data set (0.13%). Interestingly, symptomatic infection was identified in 40 cases (53%).
Sepsis Related ICD-10 Codes
Cases coded with one of the following International Statistical Classification of Diseases and Related Health Problems - Version 10 (ICD-10) codes were labelled as sepsis:
A02.1
A20.7
A22.7
A24.1
A26.7
A32.7
A39.2, A39.3, A39.4
A40.0, A40.1, A40.2, A40.3, A40.8, A40.9
A41.0, A41.1, A41.2, A41.3, A41.4, A41.51, A41.52, A41.58, A41.8, A41.9
A42.7
B37.7
R57.2
R65.1
For the Medical Information Mart for Intensive Care IV database (MIMIC-IV) dataset sepsis cases were labelled accordingly, including additional ICD-10 and ICD-9 codes:
A41.01, A41.02
A41.53, A41.59, A41.81, A41.89
R65.2, R65.20, R65.21
785.52
995.91, 995.92
Data Processing and Model Development
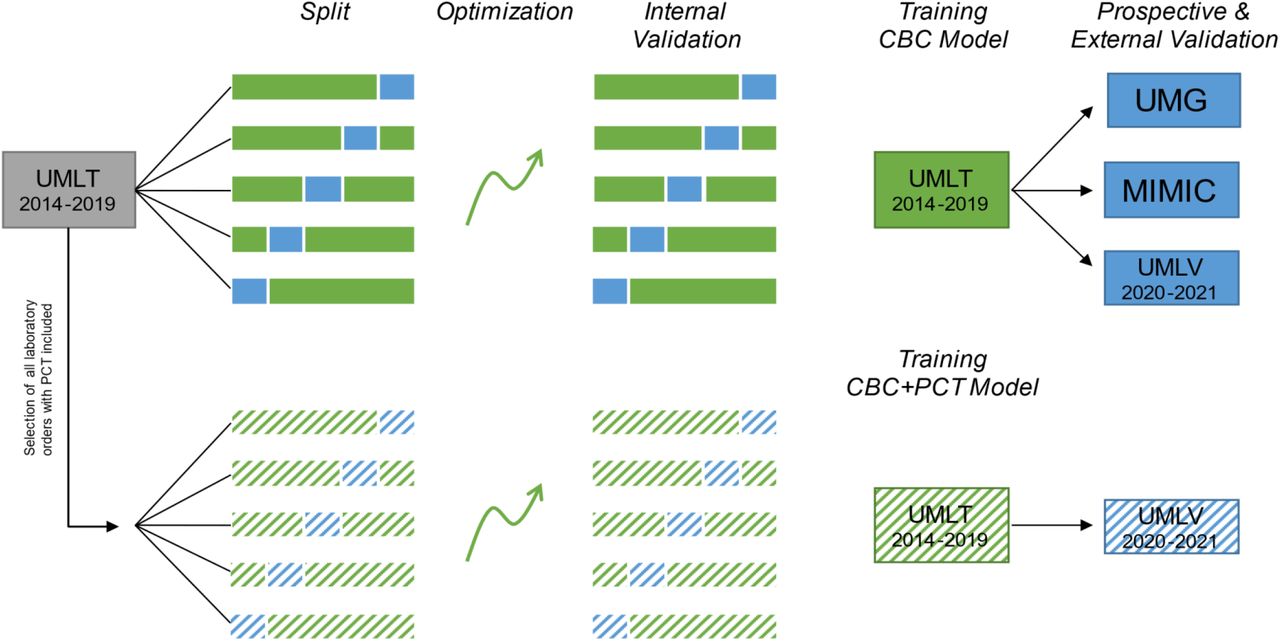
We tuned the hyperparameters, including number of trees, maximum tree depth and learning rate in a 5-fold cross-validation to maximize the area under the receiver operating characteristic (AUROC). For internal validation (data not shown) the optimized hyperparameters were applied in a second 5-fold cross validation and the mean AUROC of the 5 sub models was calculated. The final CBC model was then trained on the whole UMLT training dataset. The same procedure was followed for training the modified CBC+PCT model on preselected data points including PCT measurements. All validations were performed on data sets that were unknown for model training. The high-level diagram of this workflow is displayed in figure S1.
Following final hyperparameters of the CBC model were used:
Number of trees: 700
Maximum split count (tree depth): 40
Learning rate: 1
Laboratory Diagnostics
The blood was collected in EDTA tubes (S-Monovette®, Sarstedt, Nürnbrecht, Germany for University of Leipzig Medical Centre (UML) and BD-Vacutainer®, Becton, Dickinson and Company, Franklin Lakes, USA for University Medicine Greifswald (UMG)). At UML the complete blood counts (CBCs) were analysed within 4 hours at the laboratory on a Sysmex XN-10 in an XN-9000 or XN-9100 configuration. The Institute of Clinical Chemistry and Laboratory Medicine (IKCL) at the UMG used the same Sysmex device to analyse the CBC.

UMLT: University of Leipzig Medical Centre (Training Set); UMLV: University of Leipzig Medical Centre (Validation Set); UMG: University Medicine Greifswald; MIMIC: Medical Information Mart for Intensive Care IV database; CBC: complete blood count; PCT: procalcitonin

CBC: complete blood count; ICU: intensive care unit, UMLV: University of Leipzig Medical Centre (Validation Set); UMG: University Medicine Greifswald; MIMIC-IV: Medical Information Mart for Intensive Care IV database; Displayed are the score values of the CBC model over time comparing sepsis cases and cases with ICU admission but without sepsis diagnosis. In all three validation data sets, the largest difference is detected between 6 and 48 hours before ICU admission.

CBC: complete blood count; correlation of prevalence and positive predictive value by different cut-offs of the CBC model with sensitivity of 50% (S50) and 90% (S90) based on UMLV data.

Correlation of sensitivity and positive predictive for two cohorts with different prevalences based on UMLV data. Graphs were derived from all patients with a sepsis prevalence of 0.13% (blue) and the emergency department cohort with a prevalence of 0.81% (red).
UMLV: University of Leipzig Medical Centre (Validation Set); CBC: complete blood count; ICU: intensive care unit; SIRS: systemic inflammatory response syndrome; ICD-10-GM: International Statistical Classification of Diseases and Related Health Problems Version 10 - German Modification.

UMG: University Medicine Greifswald; CBC: complete blood count; ICU: intensive care unit; SIRS: systemic inflammatory response syndrome; ICD-10-GM: International Statistical Classification of Diseases and Related Health Problems Version 10 - German Modification

MIMIC-IV: Medical Information Mart for Intensive Care IV database; CBC: complete blood count; ICU: intensive care unit; SIRS: systemic inflammatory response syndrome; ICD9/10-CM: International Statistical Classification of Diseases and Related Health Problems Version 9 and 10
Predictor Importance
Predictor importance was calculated using MATLAB’s built-in function “predictorImportance” for classification ensembles created by “fitcensemble”. For every tree the amount of node risk change is determined that is associated with a feature. For this, the node risk is determined for every node, which is the product of node probability and node impurity. Then, the node risk change is the difference between the parent nodes risk and the child nodes risks divided by the number of branch nodes. Finally, the predictor importance is determined by calculating a weighted average over all trees. Accordingly, the predictor importance is the weighted average over the changes in node risk for a particular feature. For a clearer presentation of the values, we have indicated the respective share of the total for every feature.
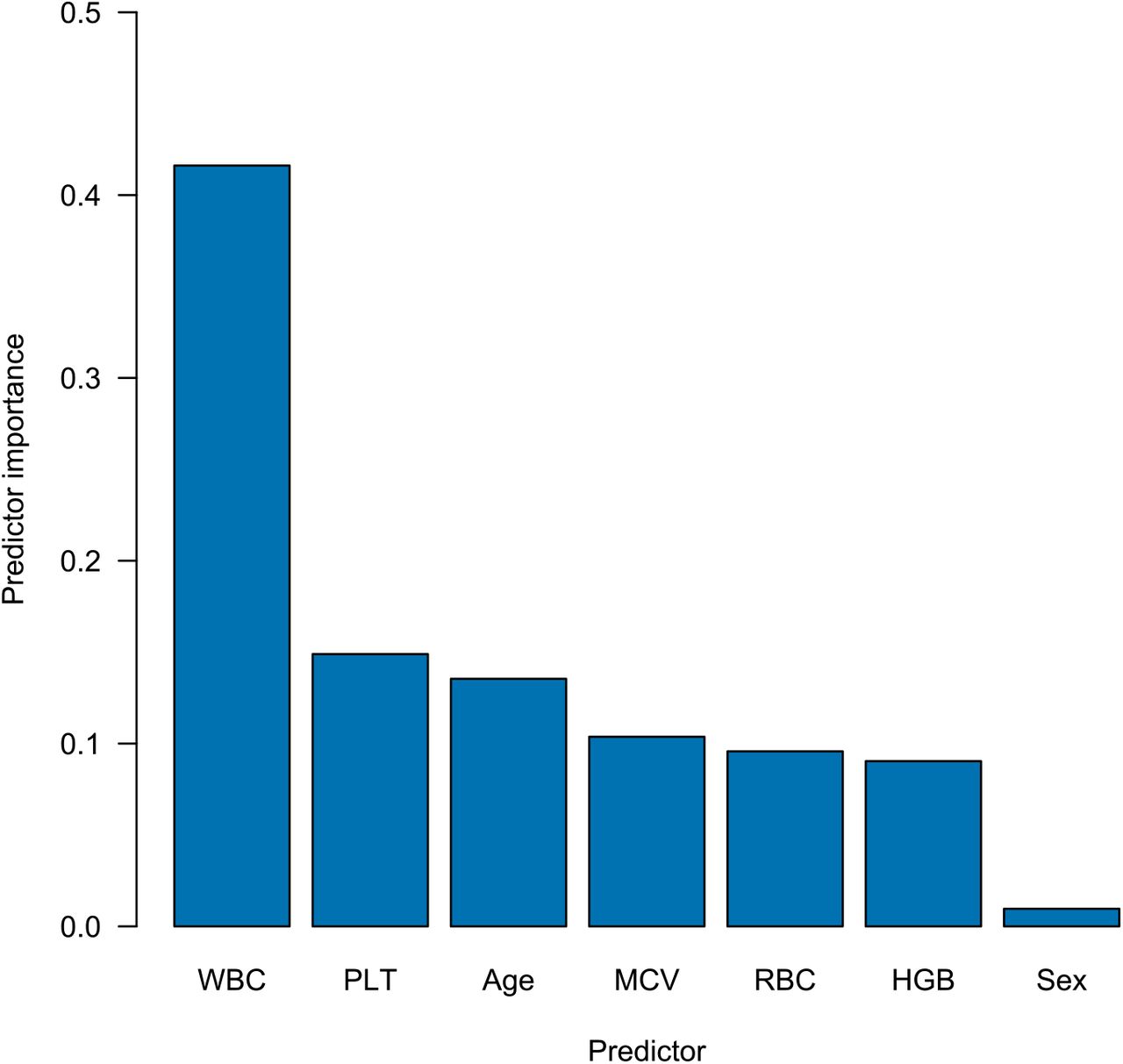
WBC: white blood count; PLT: platelets; MCV: mean corpuscular volume; RBC: red blood cells; HGB: haemoglobin
Seed analysis
To rule out that the choice of random seed had a meaningful impact on our results, we ran the entire MATLAB pipeline for 20 different random seeds. The following seeds were used: 1969207776, 1969381777, 1969549025, 1969715444, 1969880797, 1970045850, 1970211320, 1970376985, 1970541848, 1970708391, 1970871325, 1971035844, 1971201286, 1971364957, 1971529602, 1971694292, 1971859146, 1972024133, 1972188575, 1972352809.
Exploration of model behaviour
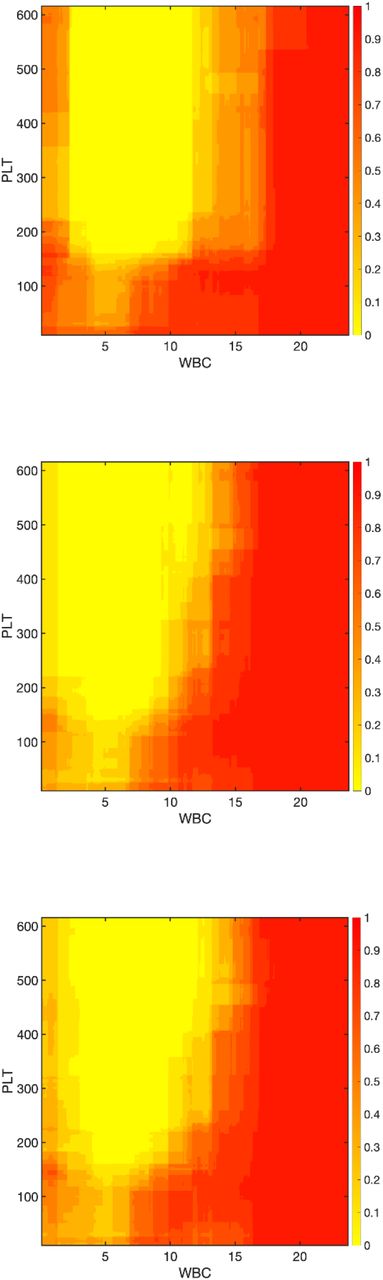
To explore the model’s behaviour for different blood count constellations, we analysed the CBC model’s decisions for different blood count values and illustrate them in the following figures. Six different cohorts were examined:
All patients <60y
All patients 60-80y
All patients >80y
Sepsis patients <60y
Sepsis patients 60-80y
Sepsis patients >80y
From every cohort, the median values were determined for the following features: Age, RBC, MCV, HGB. These values were used to generate an exemplary patient for every group. The sex was chosen to be male for all exemplary patients, since data from male patients was more prevalent in most cohorts. The two remaining features WBC and PLT were sampled in a wide range to display all clinically meaningful values. The model’s output score was plotted as a heatmap. The observed cut-offs were 0.97 (for a sensitivity of 50%) and 0.69 (for a sensitivity of 90%).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Acknowledgments
We thank the whole AMPEL team for their support, including Mark Wernsdorfer for his preparatory work and Stefan Bollmann and Thomas Hildebrandt for retrieving laboratory and administrative data at University Medicine Greifswald and Manuela Gerber for selective individual chart review at University Medicine Greifswald.
References



