
ABSTRACT
COVID-19 is one of the largest public health emergencies in modern history. Here we present a detailed analysis from a large population center in Southern California (Orange County, population of 3.2 million) to understand heterogeneity in risks of infection, test positivity, and death. We used a combination of datasets, including a population-representative seroprevalence survey, to assess the true burden of disease as well as COVID-19 testing intensity, test positivity, and mortality. In the first month of the local epidemic, case incidence clustered in high income areas. This pattern quickly shifted, with cases next clustering in much higher rates in the north-central area which has a lower socio-economic status. Since April, a concentration of reported cases, test positivity, testing intensity, and seropositivity in a north-central area persisted. At the individual level, several factors (e.g., age, race/ethnicity, zip codes with low educational attainment) strongly affected risk of seropositivity and death.
INTRODUCTION
In late 2019 an epidemic of respiratory disease (coronavirus disease 19 or COVID-19), caused by a novel coronavirus (SARS-CoV-2) emerged in Wuhan, China, and rapidly spread worldwide. COVID-19 has manifested in different ways across social, economic, and demographic groups, with regard to apparent risk of infection, disease severity, and mortality (1– 3). The elderly and those with co-morbidities are at the highest risk of severe disease (4). Many hospitalized patients require supplemental oxygen or ventilators (5), and there is a high mortality rate among those who are hospitalized (6). In many places healthcare facilities have been overwhelmed by a surge in cases and have fallen short of needed ventilators and ICU beds, resulting in massive morbidity and mortality(7,8). Availability of tests and operational barriers were limiting factors for diagnosis in parts of the U.S. during the early months of the pandemic (9).
California is the most populous state in the U.S., with an estimated 39.5 million inhabitants. Orange County (OC) is a coastal county in California, and the sixth most populous county in the country, with an estimated 3.2 million inhabitants). The first confirmed case in California (3rd in the U.S.) was reported from OC. On January 31 the WHO declared a Global Health Emergency, and on February 3rd the U.S. declared a public health emergency. Subsequent cases were reported in California in February, mostly among travelers. On February 26th, local (‘community’) transmission was first confirmed in the United States in northern California. OC had only 2 reported cases in February. By March 11 another 6 cases had been reported in OC. On March 12 there were 8 reported cases; followed by 23 on March 13; 11 each day on March 14 and 15; and 32 on March 16. This surge in cases in mid-March in OC and other counties in California triggered emergency orders by the Governor and the County Health Officer at the Orange County Health Care Agency, prohibiting public or private gatherings and also leading to school and business closures (10). Though many businesses were closed at this time, the mandated social distancing measures had exceptions in place for individuals working in “essential jobs,” which was broadly defined and included medical professionals, food providers, delivery agencies, public officials, contractors, and building laborers (11). The social and economic characteristics of individuals working essential jobs likely differs from the overall population.
Almost half of OC residents over the age of five speak a language other than English at home. Additionally, many within the Hispanic/Latino and Asian communities of OC live below the poverty level (17.9% and 16%, respectively) and face challenges in education, household income, access to healthcare, health disparities, and life expectancy (12,13). The relatively small land area, high population density, and diverse population of OC provides a unique opportunity to explore potentially important social, economic, and demographic correlates of COVID-19 epidemiology.
Here we present results from a detailed spatiotemporal epidemiological analysis of COVID-19 in OC, California. First, we draw from reported tests and mortality from the county health agency. Given that passively detected cases are prone toward bias, in July we also conducted a seroprevalence survey to assess the true burden of disease in the county. In our analyses we leverage both datasets to compare predictors of test positivity, mortality, and seropositivity over the first 6 months of the epidemic.
METHODS
Data
Case and Mortality data
Case data were provided through a memorandum of understanding with the Orange County Health Care Agency (OCHCA) and consisted of individual level records of all negative and positive PCR tests conducted throughout the county from March 1 through August 16, 2020 (this date aligns with our cross-sectional seroprevalence survey which completed on August 16). OCHCA receives testing data from the California Reportable Disease Information Exchange (CalREDIE), an infectious disease surveillance system implemented by the California Department of Public Health (CDPH) [14]. The data include information on test date, age, gender, race, ethnicity, and zip code of the individual taking the test. For individuals who had repeat PCR testing after testing positive, only the first positive diagnosis was included in our analyses. Mortality data were also provided by OCHCA and consisted of individual-level records of deaths attributed to COVID-19.
Seroprevalence data
Participants for the serological survey were recruited using a proprietary database maintained by SoapBoxSample, an LRW Group Company. The database is intended to be representative of the age, income, and racial/ethnic diversity of OC. Participants were contacted by email or phone. We recruited one participant per household to participate in a survey on their thoughts and opinions regarding COVID-19. The survey included questions on socio-demographics, occupation, social activities, any illness or symptoms in the last few months, and whether the individual had been diagnosed with COVID-19. After completing this portion of the survey, each eligible participant was asked if they would be willing to participate in a drive-thru blood test for SARS-CoV-2 antibodies. Eligibility for antibody testing was restricted to a quota sample designed to be demographically representative of the county as a whole. Recruitment to the antibody test was delayed to the end of the questionnaire in order to avoid biasing the serological survey toward individuals who believe that they were infected with SARS-CoV-2. There were a total of 10 field sites for drive-through blood tests, dispersed throughout OC in order to minimize driving distances for participants. The seroprevalence study design and overall findings for OC are described in more detail elsewhere (14).
Serological test
We used a coronavirus antigen microarray to classify participants from the serological survey as seropositive or seronegative. The array tests for both IgG and IgM and contains 12 antigens from SARS-CoV-2 (described in detail at (15)).
Zip-code level socio-demographic data
At the zip-code level we included median household income, the percentage of adults above age 25 who have at least a bachelor’ s degree, and the percentage of adults who have had insurance in the previous 5 years. These data come from the 2018 American Community Survey of 2018 (extracted from (12)).
Analysis
Descriptive Spatiotemporal Data Analysis
Reported cases and number of tests were aggregated at the zip code level and by week. A total of 85 zip codes were included in the analysis. For plotting cases on OC maps, the data were further aggregated by months (March through August). Case incidence was calculated and mapped as positive cases per 100,000 population per week. Testing intensity was calculated and mapped as total number of tests per 100,000 people per week. Test positivity was calculated and mapped as the percentage of positive tests for each month.
Formal testing of spatial autocorrelation was done using the global Moran’ s I statistic and spatial correlograms. Both identify the presence and extent of clustering or dispersion. Local clustering statistics (Local Indicators of Spatial Autocorrelation or LISA (16)) were then used to visualize the location of clusters. All tests were run for case incidence, test positivity, and test intensity. Seropositivity was also mapped and assessed using LISA statistics (since this was a cross sectional survey there is no time component).
Relational Analysis of COVID-19 Test Positivity, Mortality, and Seropositivity
We used logistic regressions to explore geographic, demographic, economic, and epidemiological predictors of the odds of testing positive for COVID-19, of dying from COVID-19, and of being seropositive for SARS-CoV-2 antibodies. Predictors in our models are listed in Supplementary Table 1 and included: age group, gender, and race/ethnicity at the individual level. Zip code level predictors included: median household income, the percentage of adults over age 25 with at least a bachelor’ s degree, the percentage of adults who have had insurance in the previous 5 years, and population density (individuals per square kilometer).
Several specifications were tested for model fit, interpretability, and parsimony. Through preliminary exploratory analyses we noted that the first cases were reported from coastal zip-codes but that this pattern had shifted inland over time. Given the changing dynamics over time, we explored different specifications for ‘time’ in the model for test positivity. The best fitting model included a smoothed interaction term for time (coded by day, Supplemental Table 1) and median household income at the zip code level.
The same predictors were included in the model for mortality, save for the interaction between time and median household income (which did not improve model performance). Given reports of increased mortality related to hospital bed shortages, we also included as a predictor the number of ICU beds occupied by suspected or confirmed COVID-19 patients on the day that an individual tested positive for SARS-CoV-2.
We compared three seropositivity models, with various combinations of individual and zip-code level predictors (see details in Supplementary Appendix A). All model results are presented as model adjusted odds ratios (AORs) with 95% confidence intervals (CIs). Model summary statistics, including model Bayesian Information Criterion are presented in Supplementary Appendix A.
Software
Maps were created using QGIS version 3.4.9. Tests for spatial autocorrelation were done using GeoDa version 1.14.0. All other analyses were conducted using R statistical software version 3.5.2.
RESULTS
A total of 597,922 tests were reported to OCHCA up to August 16, 2020. After dropping repeated tests and those with incomplete data, 318,492 individuals were included. Of these individuals, 36,816 tested positive for COVID-19 and 1,248 died from the disease. In the separate population-based serological survey, 2,979 individuals participated and 350 tested seropositive.
Spatial patterns in reported COVID-19 cases, testing intensity, and seropositivity
The global Moran’ s I statistics and spatial correlograms indicated significant clustering in reported cases and testing intensity in the first month (March) of the local epidemic (Table 1; Supplementary Figures 3 and 4). Conversely, there was no detectable clustering of test positivity in March (Table 1, Supplementary Figure 5). The highest reported case incidence in March was along the central coast and southern portion of the county (Figure 1 A). The LISA statistics indicated statistically significant clustering of high incidence zip codes in the central coast area (Figure 1 B). This clustering of case incidence overlaps with clustering of test intensity in March (Figure 2 A and B).
Global Moran’ s / statistics for reported case incidence, test positivity, and testing intensity for each month of the study period (March – August). The / statistic indicates the degree of spatial clustering whereas the simulated p-value gives an indication of statistical significance. Moran’ s / values roughly range from -1 to 1, with 1 indicating complete spatial clustering (i.e. all areas with high values are neighboring other areas with high values) and -1 indicating complete spatial dispersion (with high value areas always neighboring low value areas).

A.) Reported case incidence of COVID-19 in Orange County, California by month. B.) Results from tests of statistical clustering (LISA statistics). Case incidence is calculated as the number of cases per 100,000 people per week.

A.) Test intensity in Orange County by month. B.) Results from tests of statistical clustering (LISA statistics). Test intensity is calculated as the number of tests per 100,000 people per week at the zip code level.
Clustering of both reported cases and test positivity increased in magnitude in May (Table 1 and Supplementary Figures 3 and 5). While clustering in test intensity (Table 1; Supplemental Figure 4) was high in March, it decreased in May as access to testing spread throughout much of the county. Clustering in testing intensity increased again in June and July (centered on the hotspots in the north-central part of the county, evident in Figures 1 and 3). By April, case incidence, testing intensity, and test positivity had all shifted to a growing cluster in the north-central part of the county. Zip code level seropositivity also revealed a cluster in the north-central part of OC (Figure 4), especially in the city of Santa Ana (Supplementary Figure 1).

A.) Test positivity (% of tests positive for SARS-CoV-2) at the zip code level in Orange County by month. B.) Results from tests of statistical clustering (LISA statistics).

A.) Seropositivity to SARS-CoV-2 at the zip code level, B.) Results of LISA statistics for seropositivity data.
Results from GAM Logistic Regressions
Factors associated with testing positive for SARS-CoV-2 infection
Age was a strong predictor of testing positive. Individuals in the 10-14 and 15-19 age groups had the highest odds of testing positive (both with approximately 2.2 times the odds of testing positive in comparison to the 0 – 4 age group (Table 2 and Figure 5)). Males had 1.2 times the odds of testing positive (95% CI: 1.18 – 1.23). Individuals who identified as Hispanic or Latino had 1.7 times the odds of testing positive (CI: 1.63 – 1.79) when compared to whites, while Asian (AOR: 0.52; CI: 0.49 – 0.55), Black (AOR: 0.58; CI: 0.52 – 0.66), and Pacific Islander (AOR: 0.35; CI: 0.29 – 0.42) individuals had lower odds of testing positive. A large proportion of individuals did not have attributable race or ethnicity data in the records (63 % of all records through August 16).
Generalized additive logistic regression results for odds of testing positive for SARS-CoV-2 in Orange County. This table excludes the coefficients for median income and time due to the interaction between median income and time. A random intercept was included for zip code.
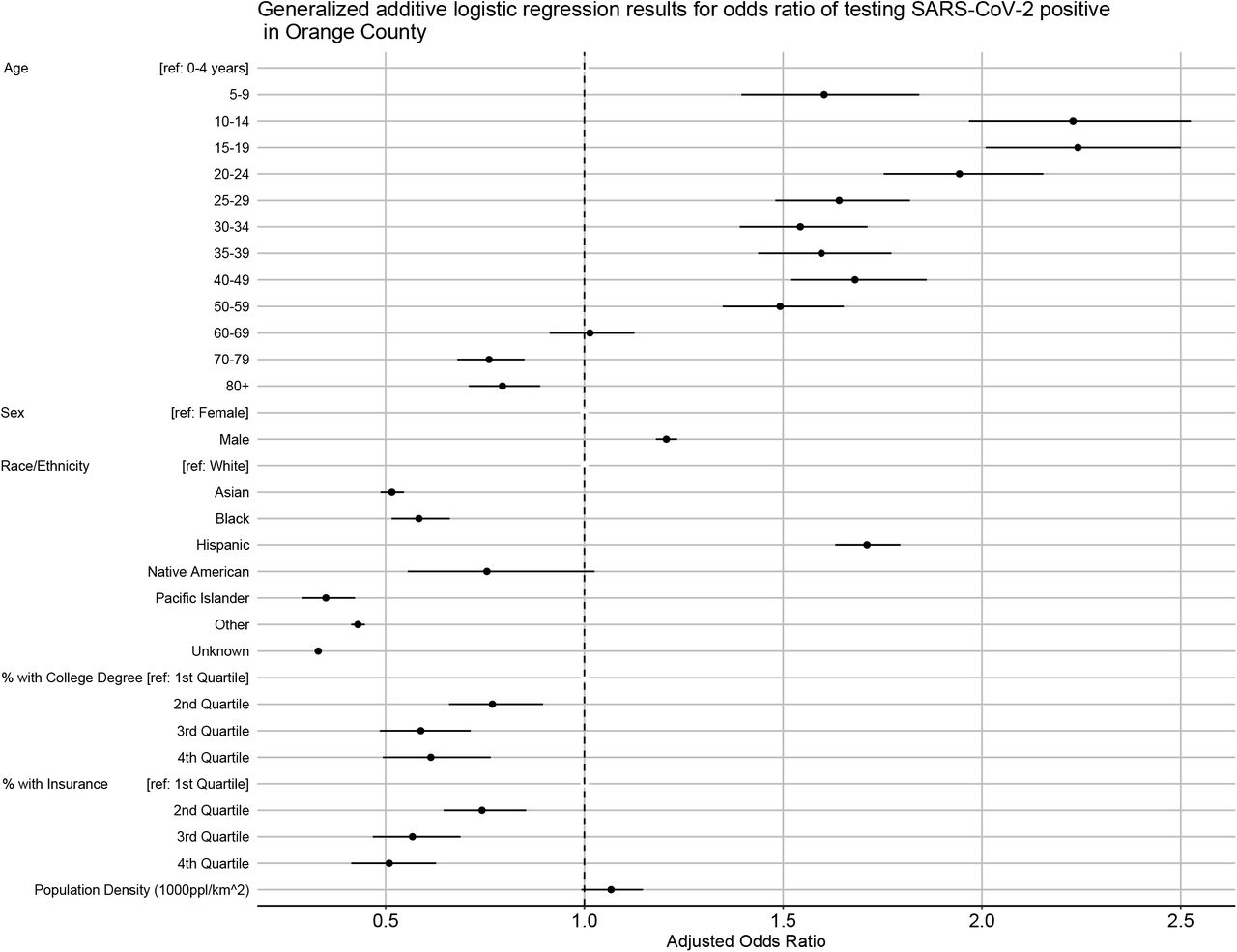
Model adjusted odds ratios and confidence intervals from the logistic regression for odds of testing positive (Table 1)
Zip code level population density was not a significant predictor of testing positive (Table 2, Figure 5). However, education (percentage of adults with at least a bachelor’ s degree), insurance coverage (percentage of adults who had insurance in the previous 5 years), and median household income were all statistically significant predictors of testing positive. For example, individuals who lived in zip codes with the highest education levels had 39% decreased odds of testing positive (AOR for the fourth quartile: 0.61; CI: 0.49 – 0.76). In addition, the interaction between zip code level median household income (Supplementary Figure 2) indicates that individuals from wealthier zip codes had increased risk of testing positive at the beginning of the OC epidemic. However, this pattern quickly shifted, with individuals from lower income areas showing the highest odds of testing positive in subsequent months.
Factors associated with COVID-19 associated mortality
For each increase in 10 years of age there was an associated 2.5 fold increase in the odds of mortality (AOR: 2.56, CI: 2.46 – 2.67; Table 3, Figure 6). Infected males were almost twice as likely to die from COVID-19 when compared to females (AOR: 1.97; CI: 1.71 – 2.26). While Asian individuals were less likely to test positive for SARS-CoV-2 infection (Table 2), those who did test positive had higher odds of mortality. Compared to whites, Asians had 31% increased odds of dying from COVID-19 (AOR: 1.31; CI: 1.08 – 1.59).
Logistic regression results for odds of dying among those who tested positive for SARS-CoV-2 in Orange County. A random intercept was included for zip code.
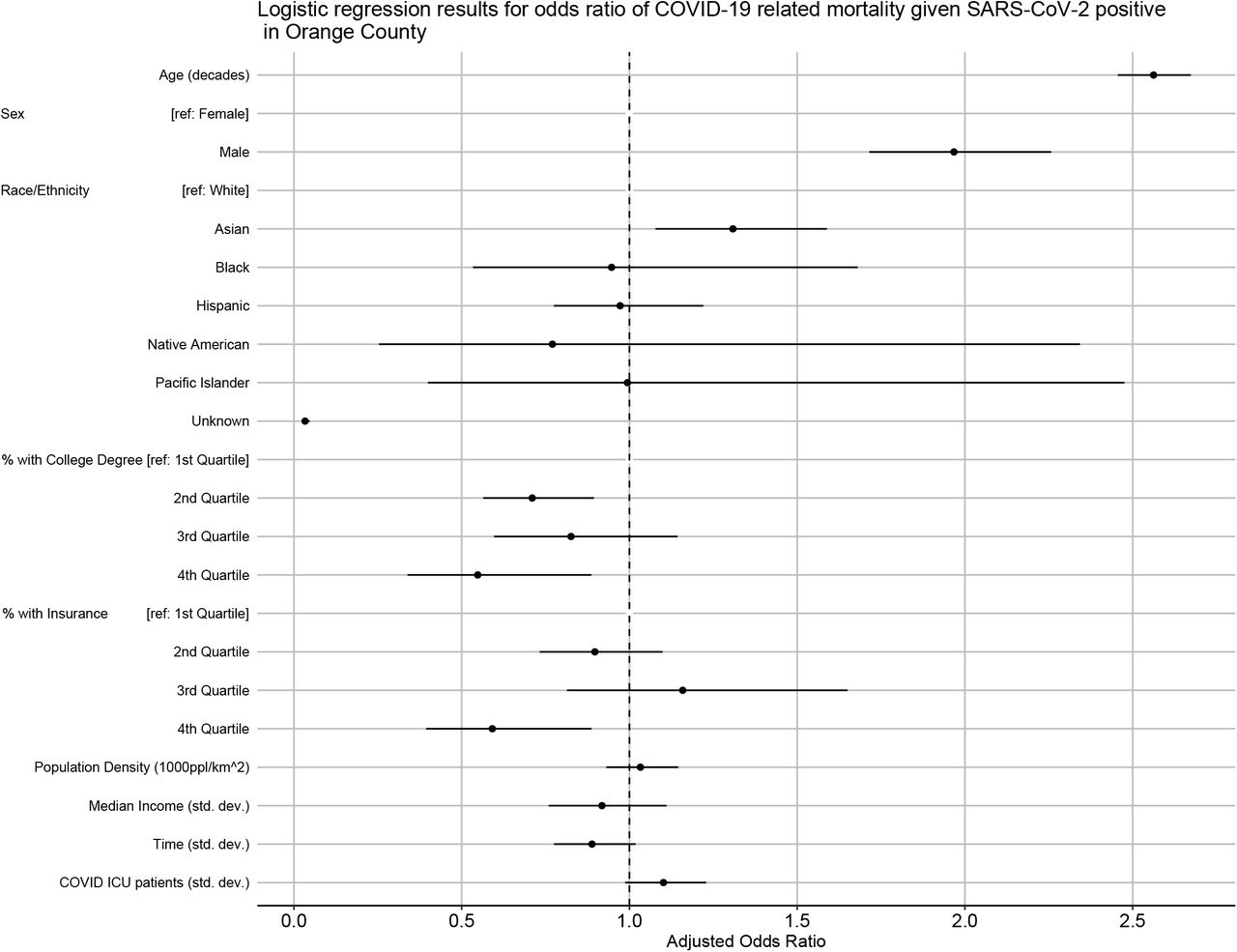
Model adjusted odds ratios and confidence intervals from the logistic regression for the odds of dying from COVID-19
Living in zip codes with high education levels and insurance coverage was also predictive of mortality outcomes (Table 3, Figure 6). Individuals who tested positive for COVID-19 and lived in zip codes with the highest levels of educational attainment had 45% lower odds of dying (AOR for the fourth quartile: 0.55; CI: 0.34 – 0.89). Those who lived in zip codes with the highest levels of insurance coverage had 41% lower odds of dying. Zip code level population density and median household income were not significant predictors of mortality after accounting for the other risk factors.
There was no significant change in risk of COVID-19 mortality over this time period. The number of COVID-19 patients in ICU was also not predictive of mortality.
Factors associated with SARS-CoV-2 seropositivity
Zip code level cumulative incidence was a significant predictor of individual-level seropositivity in the absence of other zip code level predictors (Supplementary Table 2). Every increase in 10% of the zip code cumulative incidence resulted in approximately a 50% increase in the odds that an individual would be seropositive.
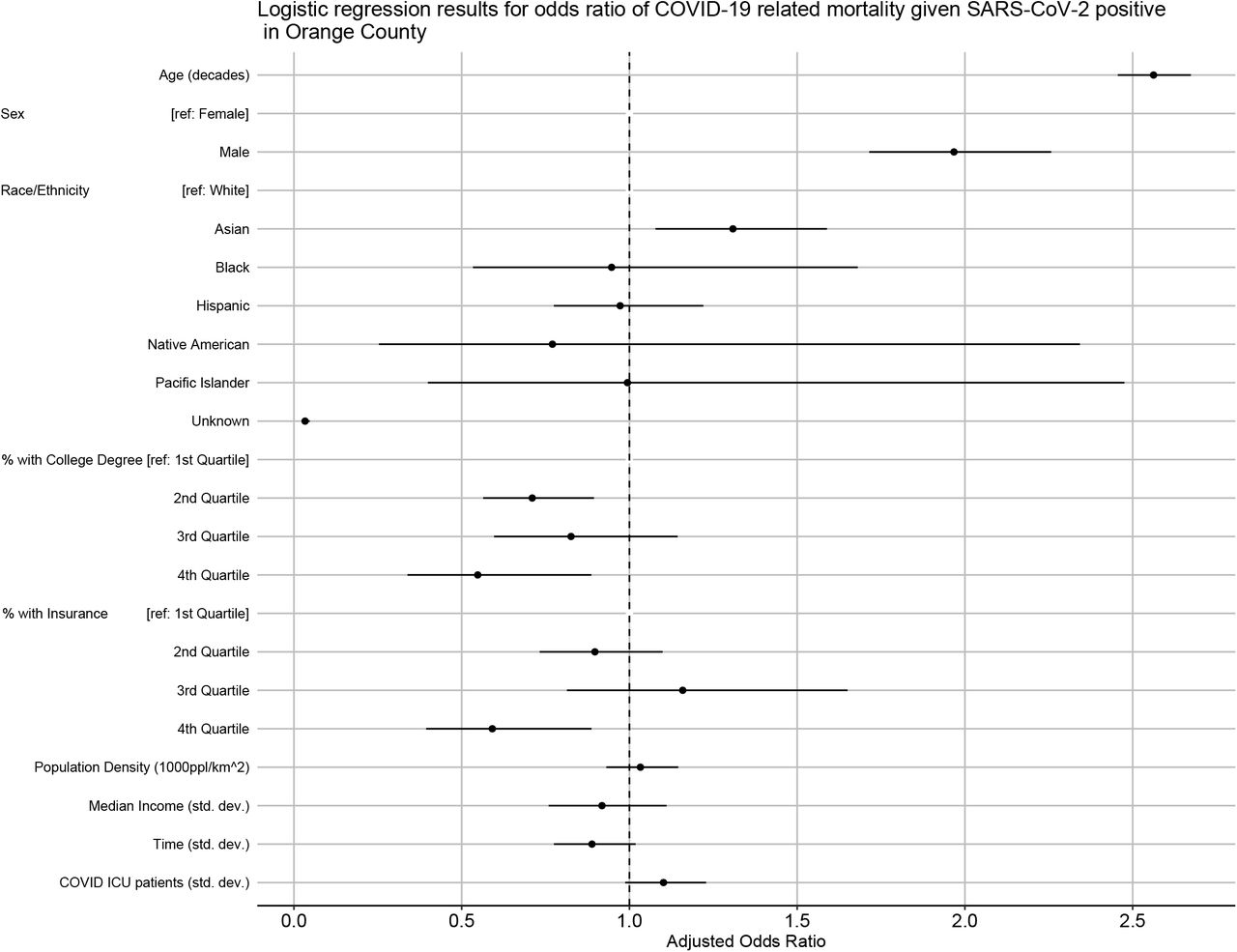
Zip code level cumulative incidence was no longer a statistically significant predictor of seropositivity when other zip code level predictors were added to the model (Table 4, Figure 7).
Logistic regression results for odds ratio of testing sero-positive for SARS-CoV-2 in Orange County.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Model adjusted odds ratios and confidence intervals from the logistic regression for the odds of being seropositive for SARS-CoV-2
In the full model (including all zip code level covariates) median household income had a protective effect, with individuals coming from zip codes with higher median household income having lower odds of being seropositive for SARS-CoV-2 antibodies (AOR for every one standard deviation increase: 0.75; CI: 0.57 – 0.98).
We found no difference in age groups with regard to seropositivity. While males were more likely to test positive or to die from SARS-CoV-2 infection, they were less likely than females to be seropositive (AOR: 0.75; CI: 0.59 – 0.94). Hispanic and Latino individuals had 55% increased odds of being seropositive (AOR: 1.55, CI: 1.17 – 2.03). Pacific Islanders may also have had higher odds of being seropositive, but with small total numbers and broad confidence intervals (AOR: 3.94, CI: 1.07 – 14.57; a total of 3 out of 12 individuals tested were seropositive).
DISCUSSION
Infectious disease data from passive case detection can be biased in a variety of ways, including the well-documented challenge of uneven access to testing and diagnosis (17). In our analysis of COVID-19 in OC, we used a rich set of complementary data that include those passively collected (reported cases, mortality records) and those from active screening (population-based serological testing). Results indicate that, in the early days of the epidemic in OC, both testing intensity and test positivity concentrated in wealthy and affluent areas along the central coast. After March, however, a large cluster of reported cases formed in lower-income North-Central OC (especially the cities of Santa Ana and Anaheim, Supplementary Figure 1), growing in size in May and persisting over time. Testing intensity has spread throughout the county during this same time period.
Consistent with emerging reports, we also found that age and male gender strongly predict testing positive and COVID-19 associated mortality (18). Intriguingly, whereas older age groups and males were more likely to have symptomatic disease, our population-based serological survey found that females were more likely than males to be seropositive. Hispanic and Latino individuals had higher risk of infection and testing positive, even after controlling for several zip code level socio-economic factors. Given the consistency of this racial/ethnic finding between the models for test positivity and seropositivity, the risk of being infected with SARS-CoV-2 rises above and beyond the risks of living in a zip code with high transmission or a zip code with low-income and low levels of educational attainment. Other studies also note an increased risk of testing positive for Hispanics and Latinos (19–21). Our seroprevalence survey indicates that in OC, this finding is not an artifact of passive case detection but instead represents a true greater risk of infection for Hispanics and Latinos.
While Asians were less likely to test positive for COVID-19, they were more likely to die when infected. This disparity is consistent with national data, though its cause is uncertain (22). This pattern may reflect discrepancies in outreach communication to these communities or other socio-economic and cultural factors (23,24) and warrants further detailed investigation.
Social determinants of health, defined as “conditions in which people are born, grow, work, live, age, and the wider set of forces and systems,” play a critical role in the creation of disparities related to morbidity, mortality, and quality of life (25). These social determinants include (among other factors) poverty, wealth, educational quality, neighborhood conditions, childhood experience, and social support. Several speculative explanations have been proposed for these sociodemographic patterns related to COVID-19, including living in dense quarters. In addition, as the state and local shelter in place and social distancing policies were mandated, individuals who are independently wealthy or who work in occupations where working from home is a viable option, were more capable of practicing social (more accurately “physical”) distancing. People from low socioeconomic status (SES) areas, by contrast, may have less ability to practice social distancing. Our analyses show that individuals from zip codes with lower overall educational attainment and insurance coverage were more likely to test positive for and die from COVID-19. The association with median household income was more complex and changed over time with regard to test positivity. However, we also find that individuals from zip codes with lower median household income were also more likely to be seropositive for SARS-CoV-2. These findings underscore the importance of understanding contextual factors surrounding infectious disease outbreaks.
Study limitations include that County-reported testing and mortality data did not include individual-level information on income, education, and insurance. These variables were only available at the zip code level. Zip codes are unlikely to adequately represent important spatial units (e.g., neighborhoods, communities). Our measure of population density may also not accurately capture the importance of housing or household density. Missing data on race/ethnicity (63% of all official test records) and small counts of some race/ethnicity groups may have impacted our findings for groups with low counts in this analysis. Even when race/ethnicity data were available, they were broad categories (i.e. Asian rather than specific Asian ethnicities). We also note, however, that the population-based seroprevalence data on SARS-CoV-2 included detailed individual-level information on socio-demographic covariates, which we exploited for our detailed analyses.
Study strengths include the diversity of OC in terms of socioeconomic and demographic predictors, which provide sufficient power to investigate these factors in our analyses. California was also one of the first states to issue an executive order for residents to stay home, providing data for several months when only essential workers were permitted to work outside the home. Our analyses were able to identify temporal shifts in the demographics of COVID-19 test positivity that likely reflect disparities related to occupation type that are further amplified by household characteristics. Finally, we are able to assess differences in risk of infection and test positivity by comparing our population-level serological survey to routinely collected (passive) data from County statistics.
The reasons for the spatial, socio-demographic, and economic patterns we discovered are likely complex and broadly related to issues of accessing health care and general social determinants of health. The clear disparities in how this disease has manifested in OC point toward the need for approaches that are socio-culturally appropriate and those that have a focus on health equity as a fundamental building block. Measures that focus on the hardest-hit communities may serve as efficient points of intervention for COVID-19.
Data Availability
Data on reported cases and deaths came from the Orange County Health Care Agency (OCHCA). These data can be requested directly through OCHCA: Alissa Dratch: adratch{at}ochca.com The serological data can be requested directly from the PI or MPI of that project: Dr Tim Bruckner: tim.bruckner{at}uci.edu Dr Bernadette Boden-Albala: bbodenal{at}uci.edu
First author biography
Dr. Parker is an infectious disease epidemiologist with expertise in spatial epidemiology, demography, and biomedical anthropology. He is an assistant professor in public health at the University of California, Irvine and the director of the Global Health Research, Education, and Translation (GHREAT) initiative.
ACKNOWLEDGEMENTS
We acknowledge the actOC research manager (Emily Drum) and logistical expertise of Dr Bruce Albala for setting up and helping run the seroprevalence study. Many UCI students and alumni were involved in collecting blood samples for the serological survey and we gratefully acknowledge their contributions. We are grateful to the Felgner lab members who made the serological survey possible under sometimes trying conditions (especially Rie Nakajima, Aarti Jain, and Rafael Ramiro de Assis). Guiyun Yan and Xiaoming Wang provided space for cold storage. The serological survey was funded through a contract with OCHCA (MA-042-20011978). We also acknowledge conversations with colleagues and community leaders with regard to social determinants of health and health equity, including but not limited to: Sora Tanjasiri, Mary Anne Foo, Brittany Morey, Ahn Ellen, Tricia Nguyen, America Bracho, and many others.
Footnotes
↵φ TB was PI and and BBA was MPIs for the serological survey. BBA oversaw the data exchange between UCI and the OCHCA as well.
Daniel M. Parker: dparker1{at}hs.uci.edu
Tim Bruckner: tim.bruckner{at}uci.edu
Verónica M. Vieira: vvieira{at}uci.edu
Catalina Medina: catalmm1{at}uci.edu
Vladimir N. Minin: vminin{at}uci.edu
Philip L. Felgner: pfelgner{at}hs.uci.edu
Alissa Dratch: ADratch{at}ochca.com
Matthew Zahn: MZahn{at}ochca.com
Scott M. Bartell: sbartell{at}uci.edu
Bernadette Boden-Albala: bbodenal{at}hs.uci.edu
Added ORCID number for V. Vieira. The original submission was missing a figure and the figure numbers are therefore out of order. I've updated with the correct figures in this version.



