
Abstract
Objective To compare the inference regarding the effectiveness of the various non-pharmaceutical interventions (NPIs) for COVID-19 obtained from different SIR models.
Study design and setting We explored two models developed by Imperial College that considered only NPIs without accounting for mobility (model 1) or only mobility (model 2), and a model accounting for the combination of mobility and NPIs (model 3). Imperial College applied models 1 and 2 to 11 European countries and to the USA, respectively. We applied these models to 14 European countries (original 11 plus another 3), over two different time horizons.
Results While model 1 found that lockdown was the most effective measure in the original 11 countries, model 2 showed that lockdown had little or no benefit as it was typically introduced at a point when the time-varying reproductive number was already very low. Model 3 found that the simple banning of public events was beneficial, while lockdown had no consistent impact. Based on Bayesian metrics, model 2 was better supported by the data than either model 1 or model 3 for both time horizons.
Conclusions Inferences on effects of NPIs are non-robust and highly sensitive to model specification. Claimed benefits of lockdown appear grossly exaggerated.
1 Introduction
Until effective and safe vaccines can become widely available, the levers of policy makers to manage COVID-19 have included non-pharmaceutical interventions (NPI), such as social distancing mandates, travel restrictions, self-isolation, banning of public events, closure of schools, and ultimately complete lockdown. These measures aim to reduce infections by decreasing contact between individuals. Given that multiple NPIs are often introduced in quick succession, it is difficult to separate their effects.
Here, we compare the inferences regarding the effectiveness of various NPIs obtained from different SIR (susceptible-infected-removed) models. The first model (model 1) was produced by the Imperial College COVID-19 Response Team and led to arguably the most influential publication to-date in support of large benefits from total lockdown1. Its publication in Nature 1, concluded that complete lockdown was responsible for 80% of the reduction in the time-varying reproduction number, Rt, and that 3.1 million deaths were avoided in 11 European countries due to lockdown. The Imperial College team also developed and applied a different model (model 2) to the USA2, which assumes Rt varies as a function of mobility. In model 2, there is no explicit causal link between an NPI and Rt–NPIs enter the model indirectly via their effects on mobility. Inference regarding the (complex) impact of NPIs is possible by observing the Rt trajectory at the time of intervention/s.
We compare the results and performance (fit to the data) of these two models, when applied to the original 11 countries, plus another 3 European countries for which data were available but had not been included in the original publication. We also considered a third model (model 3), a hydrid of the first two, that considers both mobility and various NPIs together. We aim to understand if inferences are robust to model specification and whether some model provides a better fit than others.
2 Methods
Data
We compare the impact of NPIs and mobility on Rt for three models, two time horizons and two sets of European countries. Specifically,
For all models, we examine the evolution of Rt for two time horizons: up to May 5th (the end date chosen by Flaxman et al. 1), and July 12th to allow investigating both the imposition and lifting of various NPIs.
The original publication by Flaxman et al.1 had included 11 European countries (Austria, Belgium, Denmark, France, Germany, Italy, Norway, Spain, Sweden, Switzerland, United Kingdom). However, suitable data were also available for the Netherlands, Portugal, and Greece; therefore we also considered 14 countries.
Seeding of new infections in all models was chosen to be 10 days before the day a given country has cumulatively observed 10 deaths so that mobility data are available for all countries examined and thus allow a fair comparison between models. Flaxman et al. 1 chose the seeding of new infections to be 30 days before a country has cumulatively observed 10 deaths. We have altered the prior for the initial infection count, to reflect this modification. Seeding dates appear in Table A.1.
For mobility data we follow Unwin et al.2, and use Google’s COVID-19 Community Mobility Report3, which provides data measuring the percentage change in mobility compared to a baseline level for visits to: retailers and recreation venues, grocery markets and pharmacies, parks, transit stations, workplaces and residential places. We use the average change in mobility across all locations, excluding residential places and parks. Mobility indicators are proxies for changes in human behavior and of exposure risk. Behavior change could be due to one or more centrally imposed interventions or the product of individuals responding to the epidemic on their own initiative.
Model 1 (all NPIs considered)
In model 1, the evolution of Rt is given by,
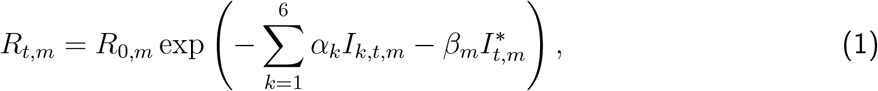 where Rt,m is the effective reproductive rate for country m at time t and Ik,t,m is an indicator variable, where Ik,t,m = 1 if NPI k is in place at time t, for country m and Ik,t,m = 0 otherwise, for k = 1, …, 6. The subscript k refers to the various NPIs (Table A.2). The variable
where Rt,m is the effective reproductive rate for country m at time t and Ik,t,m is an indicator variable, where Ik,t,m = 1 if NPI k is in place at time t, for country m and Ik,t,m = 0 otherwise, for k = 1, …, 6. The subscript k refers to the various NPIs (Table A.2). The variable 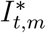 indicates the last intervention. In all countries except Sweden, this was lockdown, see Flaxman et al. 1 for details. We allow the impact of lifting an NPI on Rt to be different in magnitude from the impact of imposing that NPI in the first place. The timing of lifting NPIs in different countries appears in Table A.3.
indicates the last intervention. In all countries except Sweden, this was lockdown, see Flaxman et al. 1 for details. We allow the impact of lifting an NPI on Rt to be different in magnitude from the impact of imposing that NPI in the first place. The timing of lifting NPIs in different countries appears in Table A.3.
In Equation 1, the proportional variation of Rt from the initial R0 is modelled as a step function and only allowed to change, immediately so, in response to an intervention. Therefore, any decrease in Rt (even if this decrease is a result of the increasing proportion of the population who are infected, changes in human behavior, clustered contact structures and/or pre-existing immunity4) must, by construction, be attributed to interventions; the impact of a new intervention is immediate without time lag or gradual change. This assumption was clearly made for simplicity but is unrealistic.
Model 2 (Mobility Only Considered)
In model 2, the proportional variation of Rt from R0 is allowed to vary with mobility. Model 2 does not presume Rt follows a step function and is therefore capable of capturing more gradual changes over time. The impact of mobility on Rt is allowed to vary across countries by use of country-specific random effects terms. Specifically,
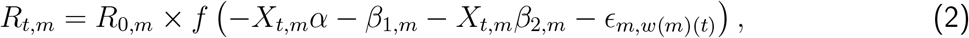 where
where 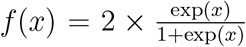 is twice the inverse of the logit function, Xt,m is the average change in mobility, excluding residential places and parks, at time t for country m and Em,w(m)(t) is a weekly AR(2) process centered around zero. In Equation 2, α is a measure of the impact of the average change in mobility on Rt which is common to all countries, while β2,m measures country-specific deviations from this common value. The advantage of model 2 is that it gives a more flexible estimate of Rt, allowing it to change with mobility trends. Although NPIs are not explicitly included in the model, the impact of an NPI can be measured by observing the value of Rt, and its subsequent change, when specific interventions were imposed.
is twice the inverse of the logit function, Xt,m is the average change in mobility, excluding residential places and parks, at time t for country m and Em,w(m)(t) is a weekly AR(2) process centered around zero. In Equation 2, α is a measure of the impact of the average change in mobility on Rt which is common to all countries, while β2,m measures country-specific deviations from this common value. The advantage of model 2 is that it gives a more flexible estimate of Rt, allowing it to change with mobility trends. Although NPIs are not explicitly included in the model, the impact of an NPI can be measured by observing the value of Rt, and its subsequent change, when specific interventions were imposed.
Model 3 (Mobility and NPIs jointly considered)
After communication with the Imperial College team, we also consider a third model (model 3) which jointly includes mobility and NPIs. The motivation behind the formulation of model 3 is to attempt to untangle the impacts of mobility, lockdown and other NPIs. In our communication, the Imperial College team proposed a similar model but only included mobility and a single NPI, lockdown, in their model. Given that our goal is to quantify the relative contributions of several NPIs, we consider all NPIs, plus mobility.
However, we caution against using model 3 as a tool for inference. NPIs may impact mobility in possibly non-linear, non-additive, lagged and interactive fashions, with possibly complex feedback. We have included this model here to compare its performance against models 1 and 2. The functional form of Rt,m, in model 3 is:
 For a discussion of prior specification and Bayesian measures of model fit for all models, see Appendix B.
For a discussion of prior specification and Bayesian measures of model fit for all models, see Appendix B.
3 Results
Mobility
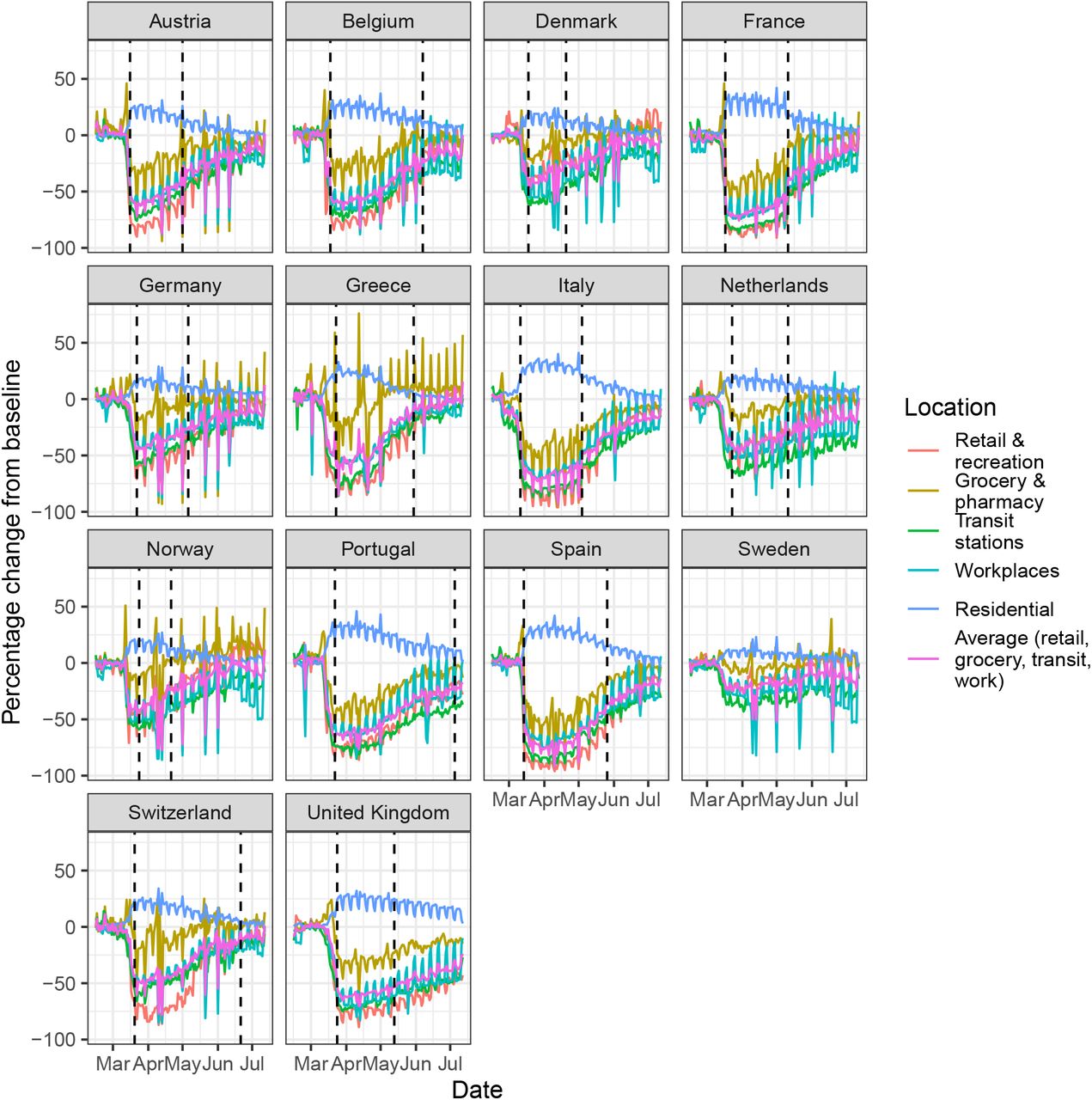
Figure 1 and Figure A.1 show that for most countries the initial reduction in mobility preceded the date of the first lockdown. This suggests that people’s behavior changed in response to earlier, less severe interventions such as banning of public events and social distancing, and/or as a result of individual choices in the face of an unknown, but potentially catastrophic, pandemic.
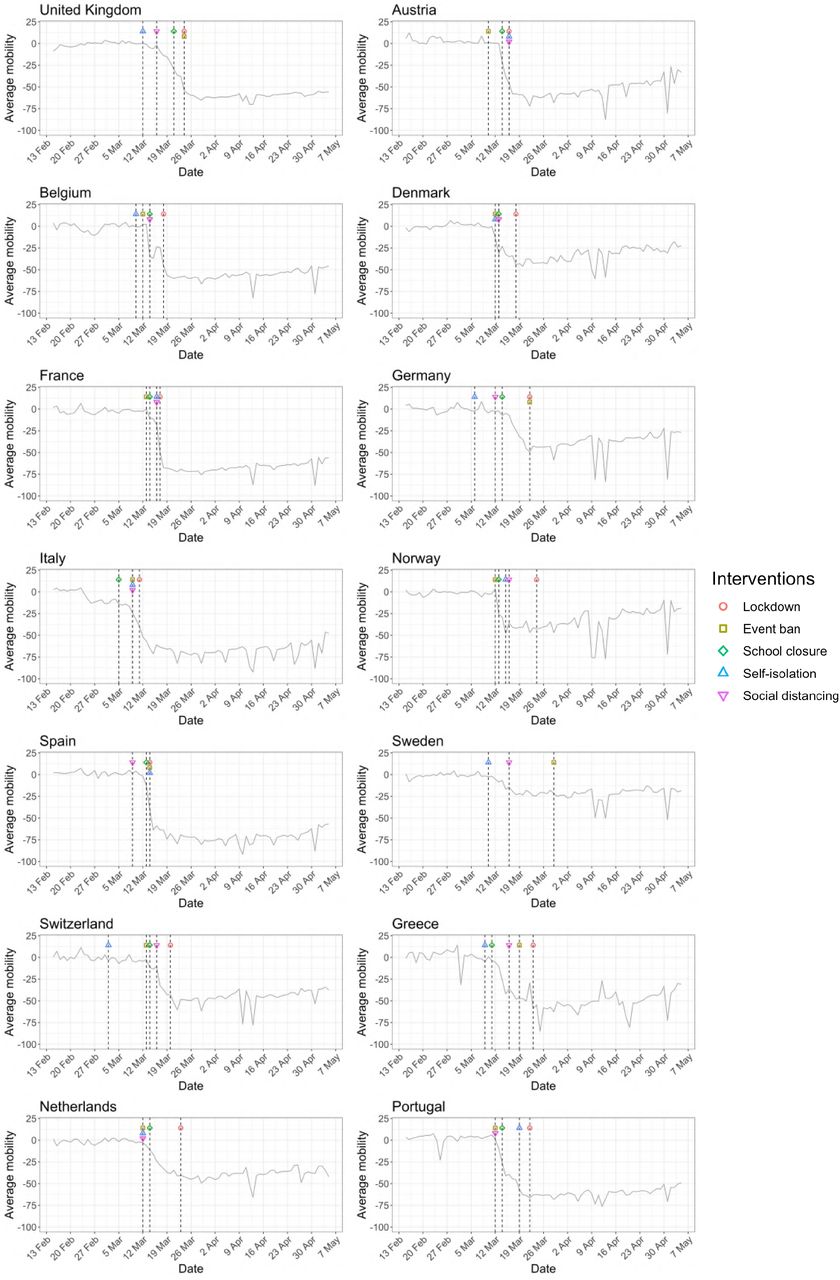
Percentage change in average mobility from baseline level from February 15th to May 5th in each of the European countries examined in Flaxman et al. 1, as well as an additional three countries consisting of Greece, the Netherlands and Portugal.
Convergence diagnostics
Convergence diagnostics (trace plots and 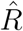 5 based on 10 chains - see also6) for all three models and both time horizons appear in Figure A.2, providing strong evidence that the Markov chains have converged.
5 based on 10 chains - see also6) for all three models and both time horizons appear in Figure A.2, providing strong evidence that the Markov chains have converged.
Comparison of models up to May 5th
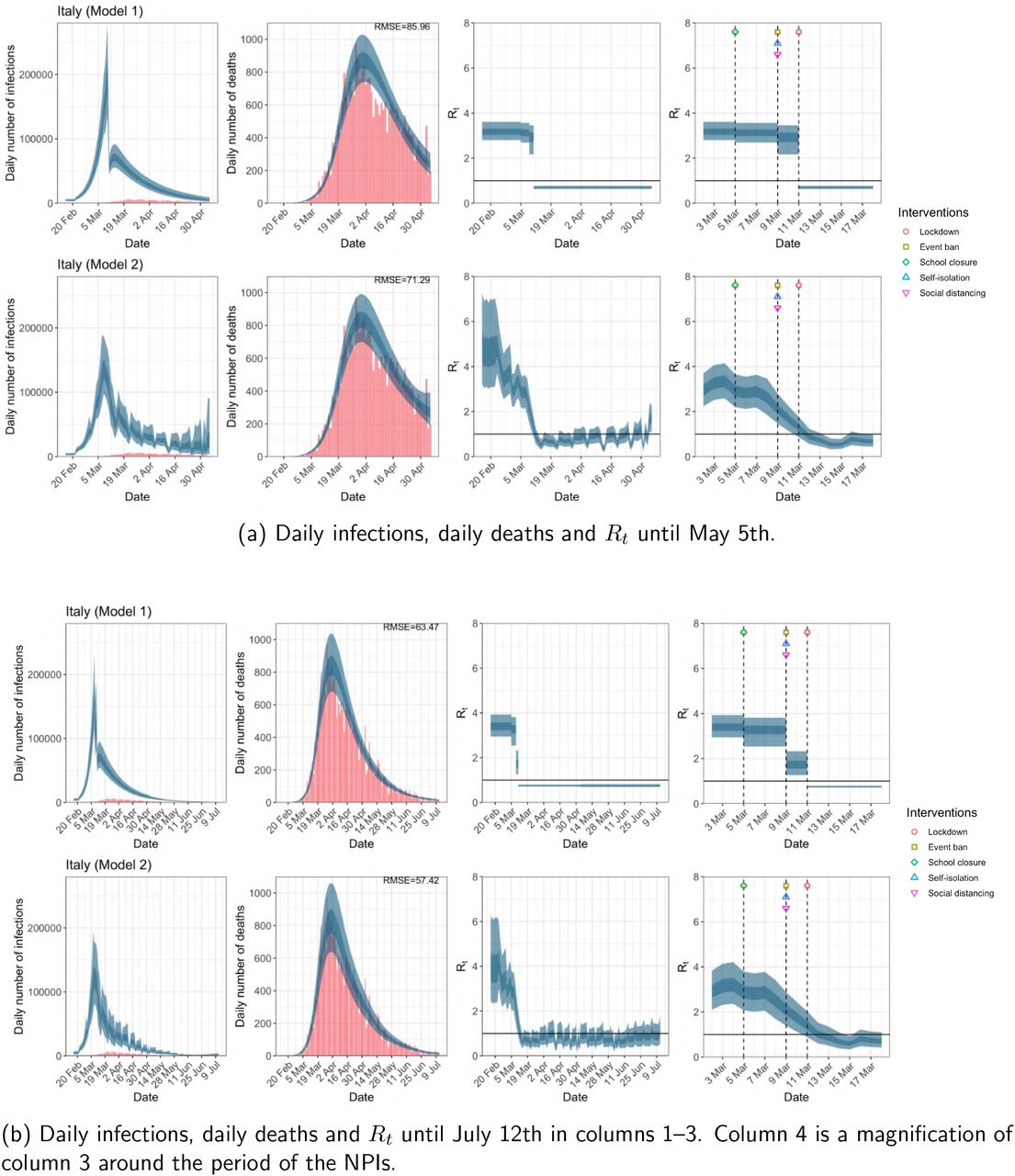
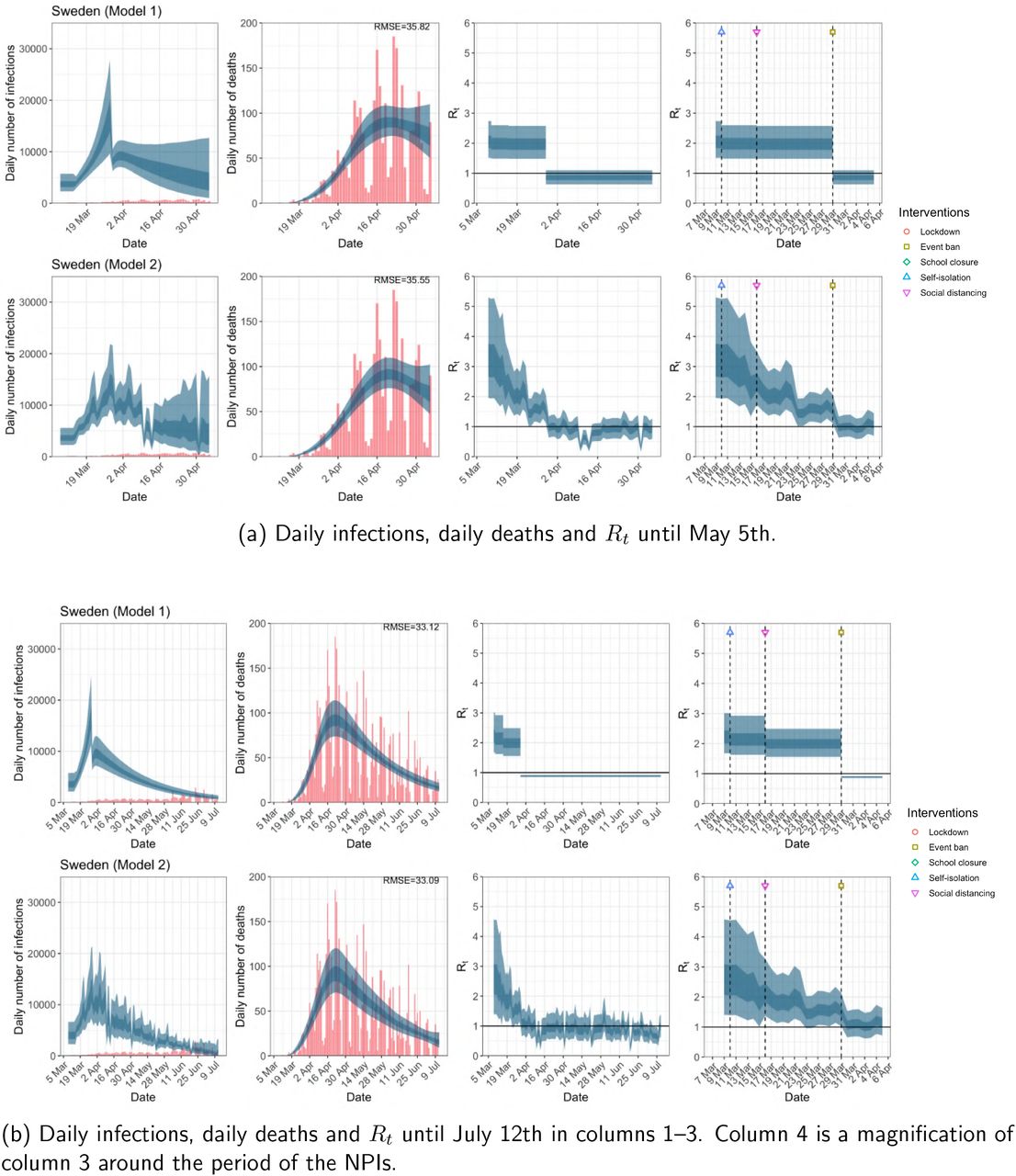
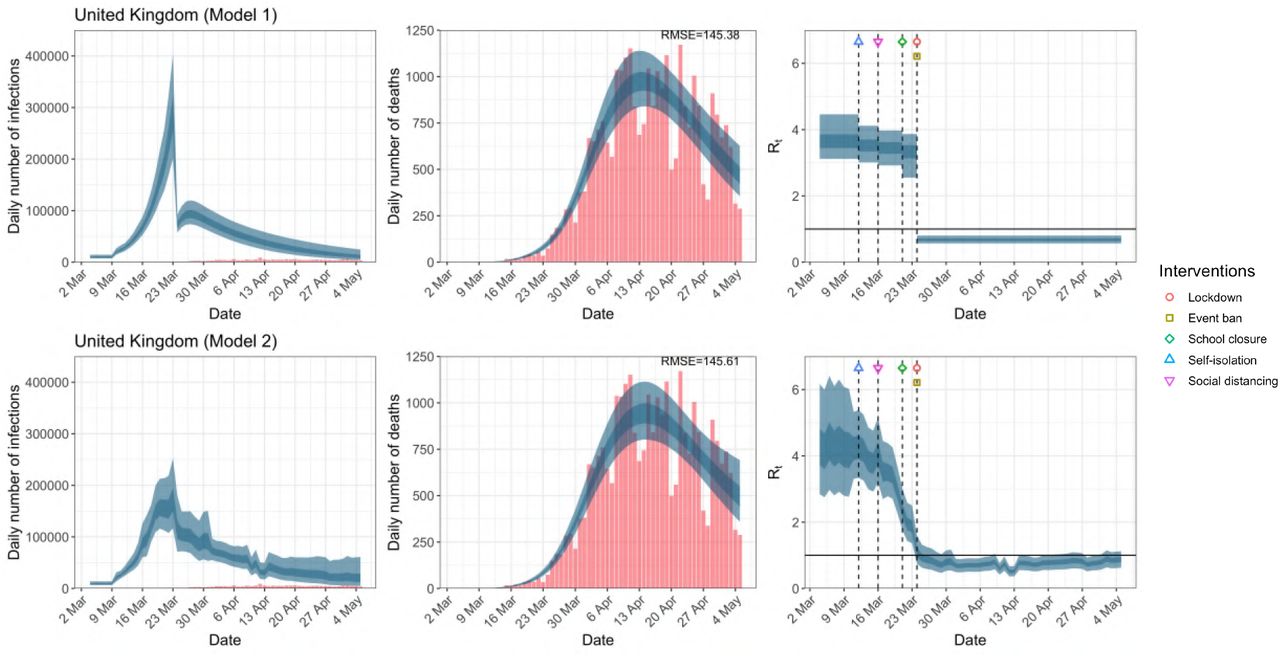
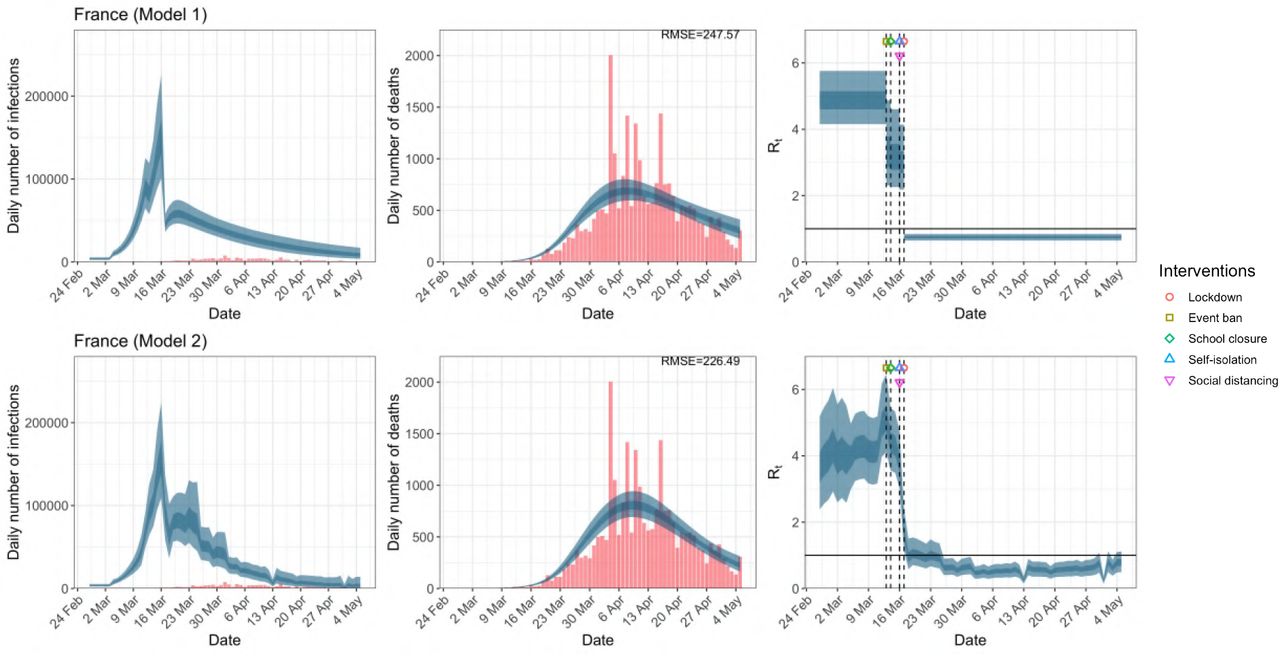
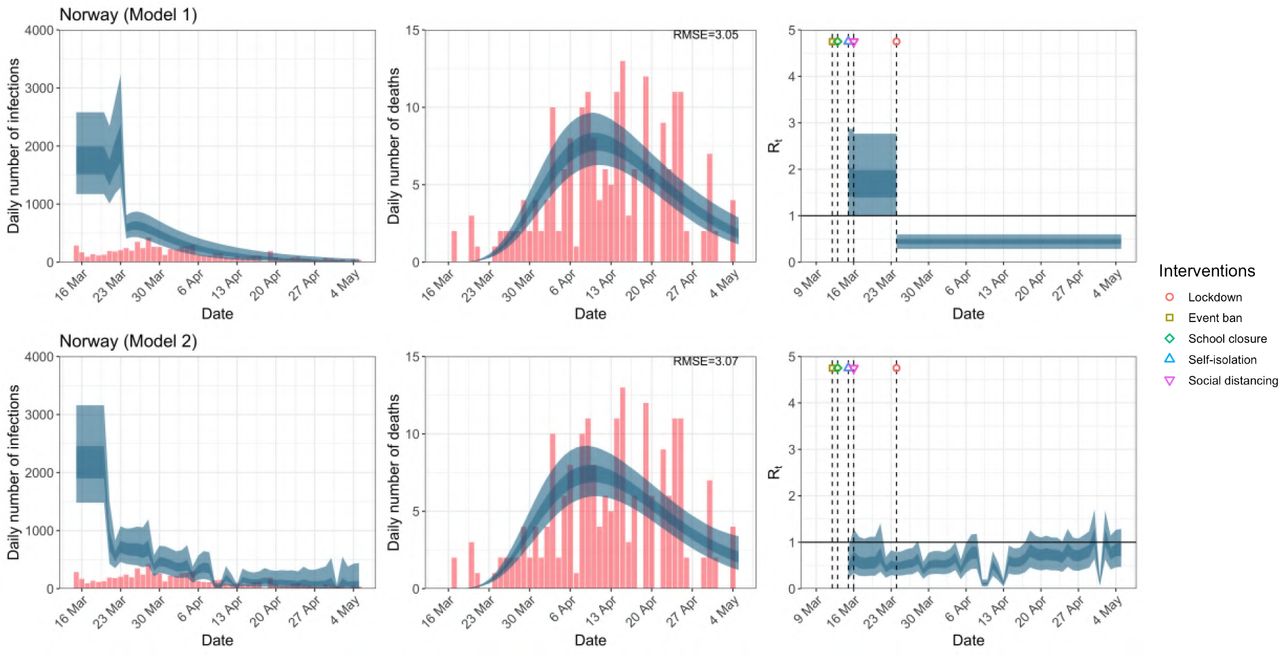
While model 1 and model 2 give very different trajectories of Rt (Figures 2a, A.3a–A.12a, Appendix C), both models produce visually similar fits to the observed daily death counts, i.e. different trajectories of Rt may give rise to the same data and hence different inference surrounding the impact of various NPIs.

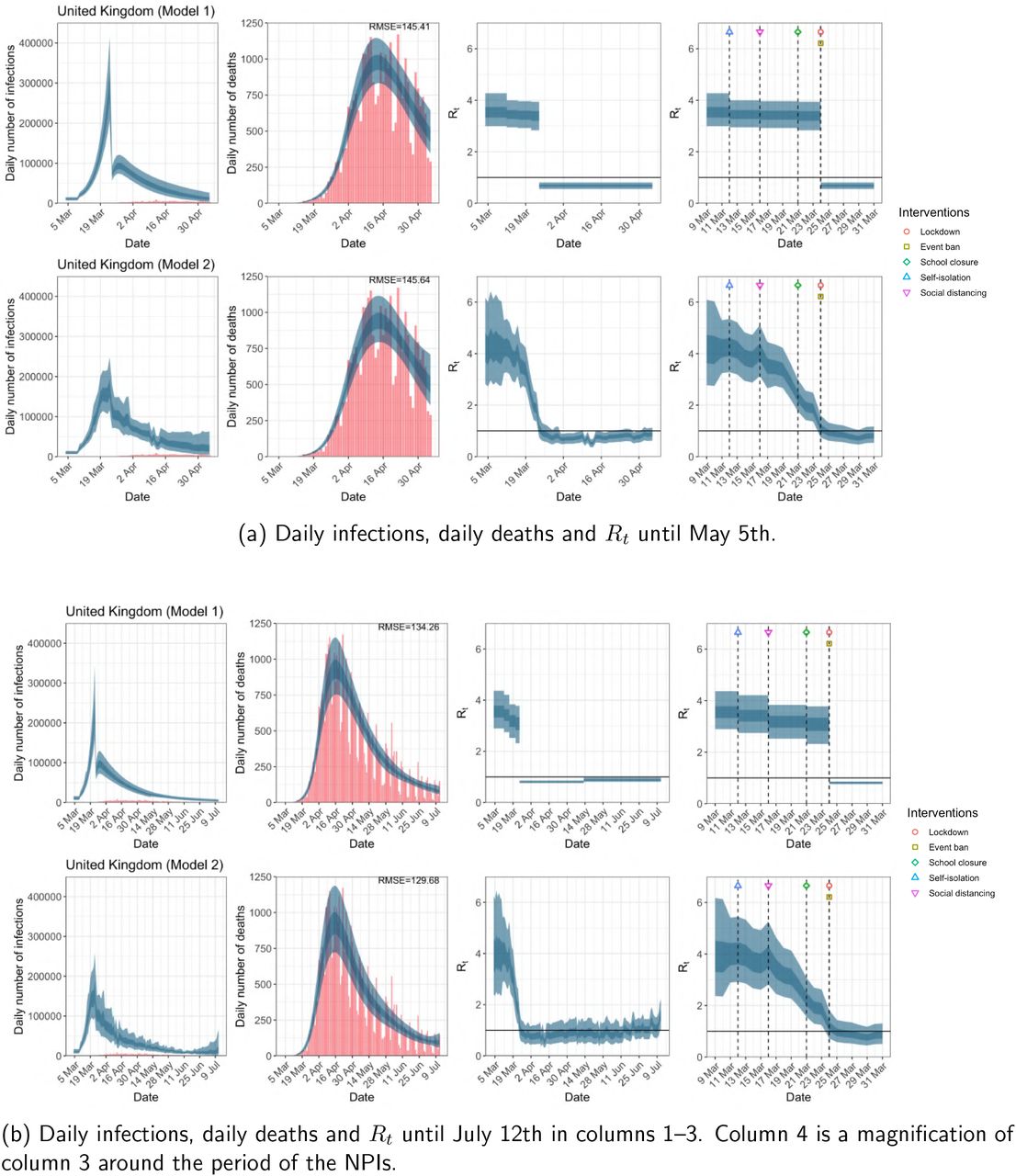
United Kingdom. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
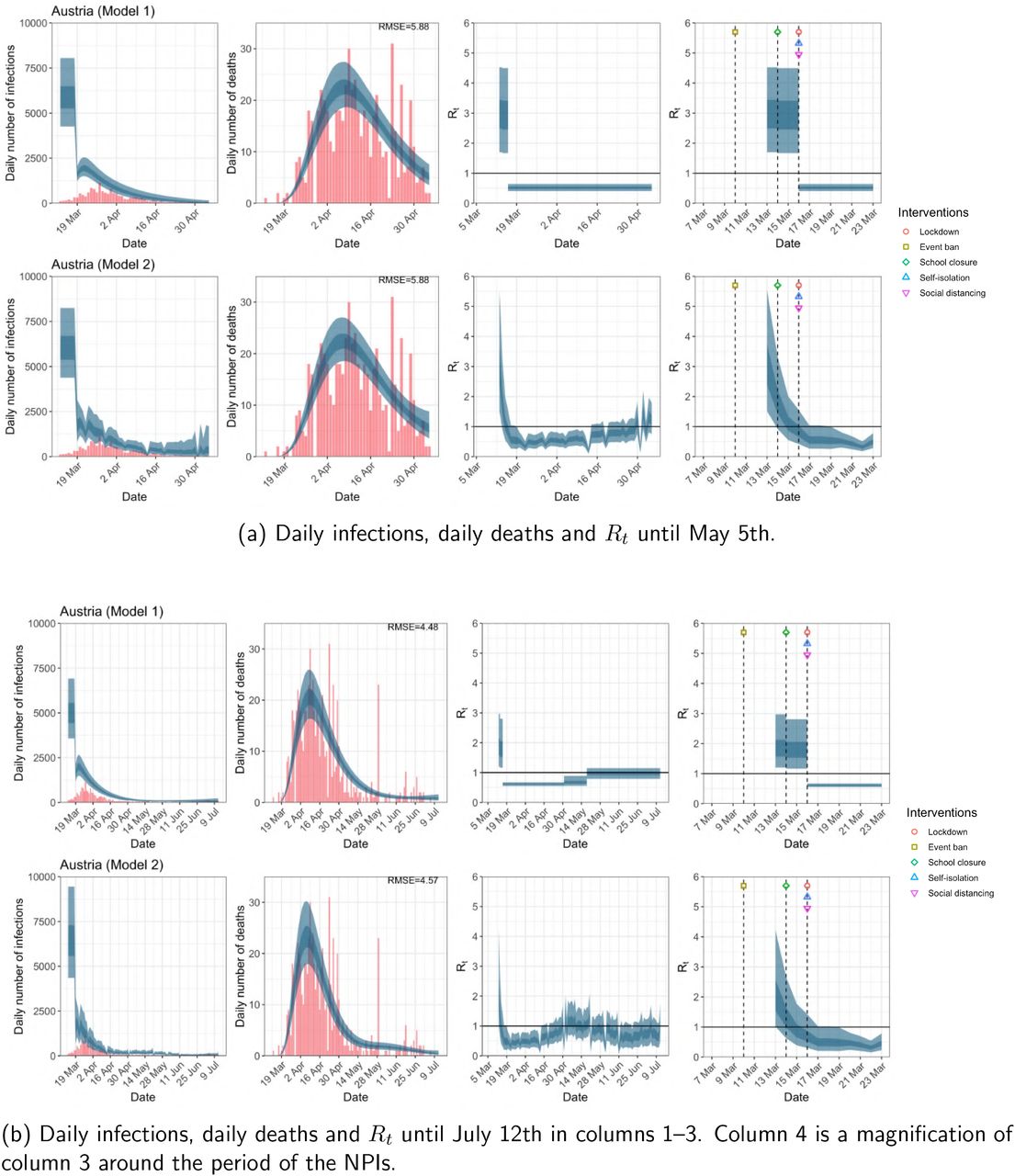
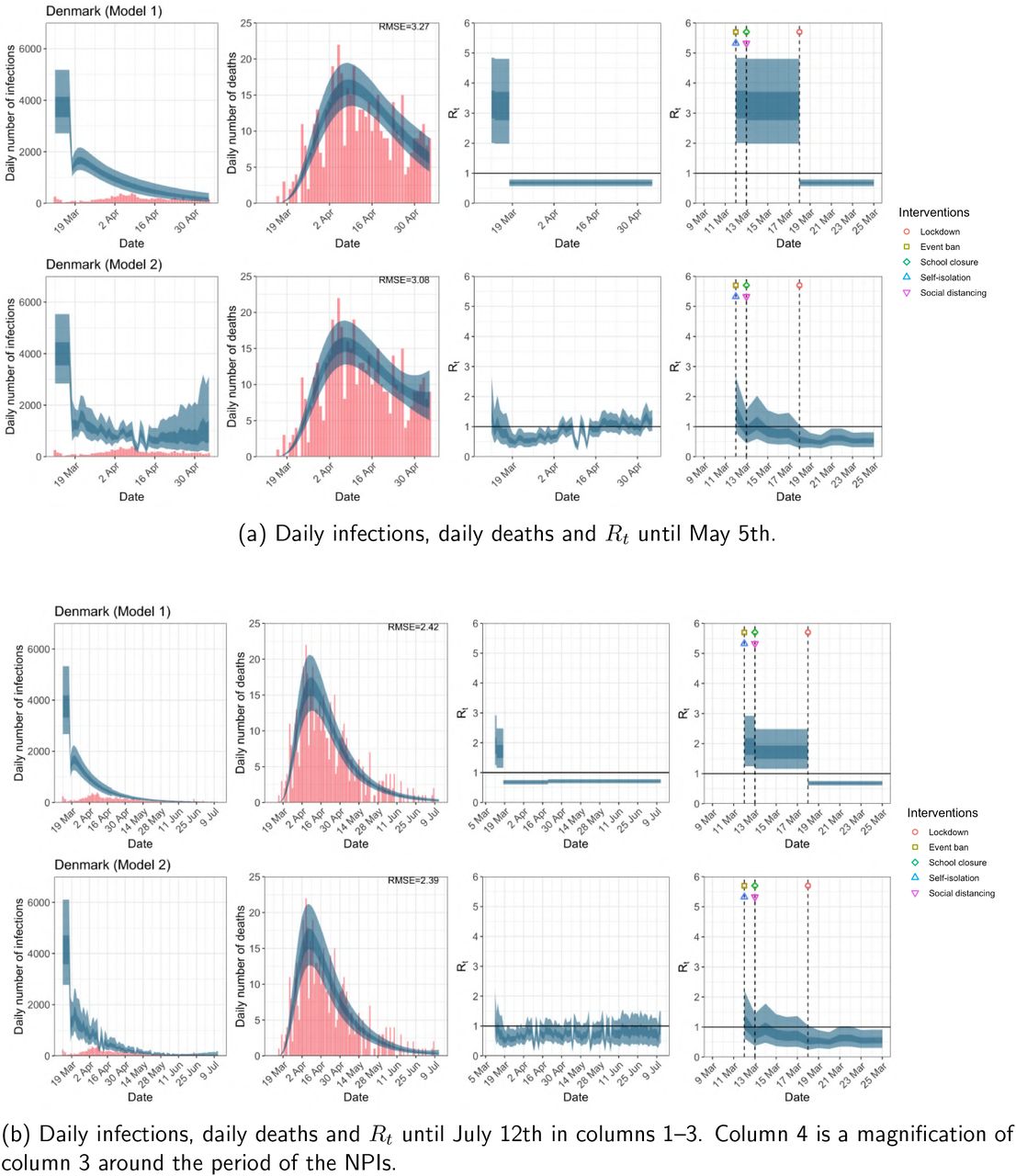
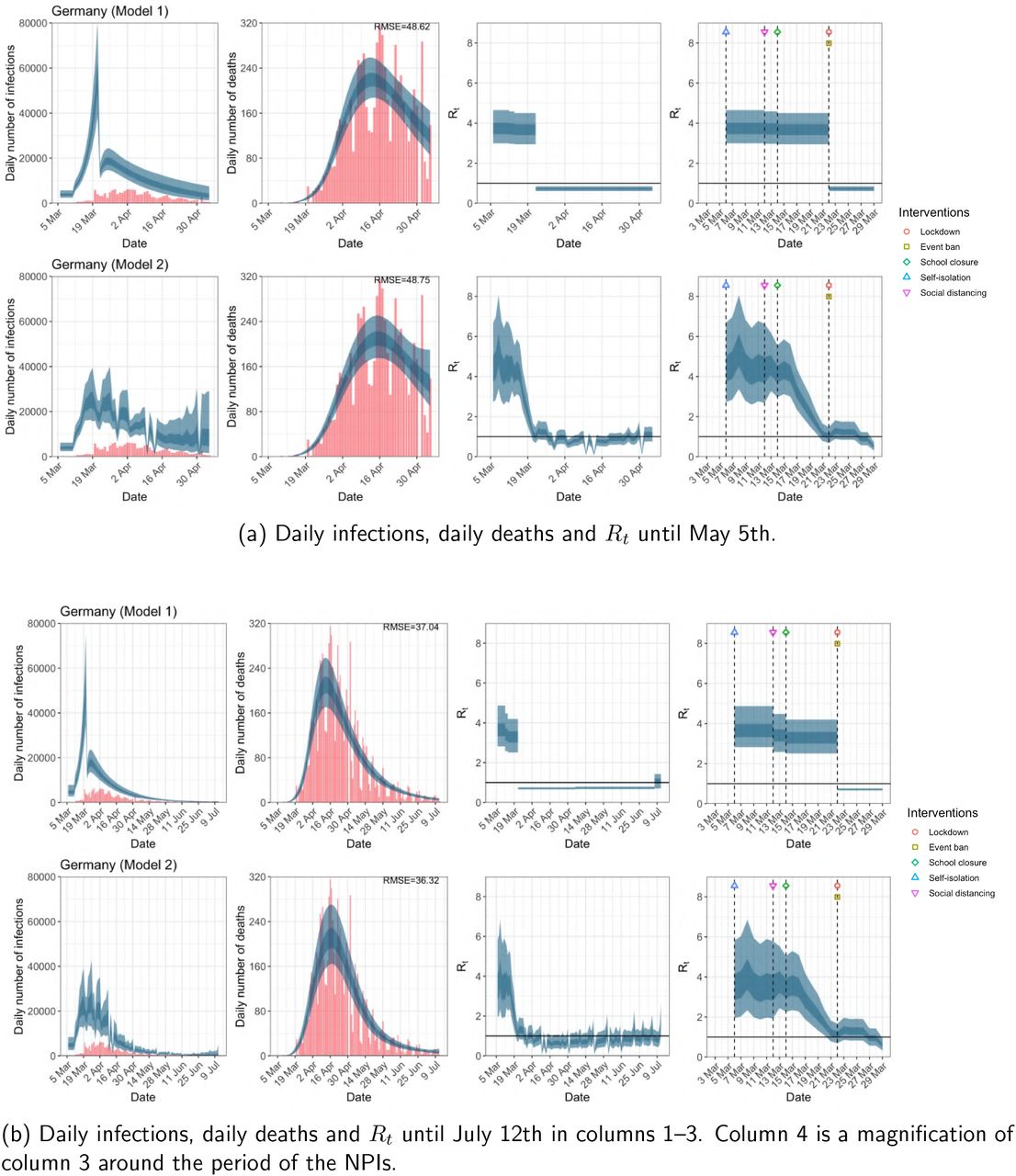
For the 11 countries (Table 1), the inference from model 1 indicates that lockdown had the biggest impact of all the interventions in all countries with an average reduction in Rt of 80%. In contrast, model 2 shows clearly that Rt was falling well before lockdown, excluding Sweden that had no lockdown. In the other 10 countries, Rt < 1.0 at the time of lockdown in 4 countries and only 1.0 − 1.3 in another 3 countries (all three 95% CIs contained 1.0).
Comparison of the value of Rt at lockdown (LD) and its 95% CIs between model 1 and 2 for all eleven countries analysed in Flaxman et al. 1 for the time horizon March 4th to May 5th. Values of basic reproduction number R0 and Rt immediately after the introduction of other NPIs for both models are given in Table A.5 in the Appendix.
When we considered 3 additional countries (Table C.1), the average reduction in Rt from lockdown shrank to 73% in model 1. Model 2 shows Rt < 1.0 in 7 countries and 1.0−1.3 in another 3 countries when lockdown was imposed. In particular, the three added countries already had Rt < 1.0 at the time of lockdown. For Greece and Portugal, Rt was already so low (0.34 and 0.67, respectively) that even the 95% CIs excluded 1.0.
Model 3 provides different inference yet again. Only the mobility and banning of public events have 95% CIs for regression coefficients which do not include zero (Figure A.2). The impact of lockdown is not statistically significant (95% CI is − 0.23, 4.25).
In comparing the models, Table A.4 shows that model 2 provides a lower RMSE for eight of the eleven original countries considered by Flaxman et al. 1, for the period March 4th to May 5th. The three countries for which model 1 had a lower RMSE were the UK, Germany and Norway.
Table 2 demonstrates that model 2 is best supported by the data for all three information criteria, WAIC1, WAIC2 and DIC (see Appendix B.2). Model 3 is the next best supported by the data, while model 1 published in Nature is the least supported.
Estimates and standard errors of various information criteria; the Watanabe-Akaike information criterion, WAIC1 = −2lppd + 2pWAIC1 and WAIC2 = −2lppd + 2pWAIC2 which uses lppd as a measure of fit with pW AIC1 and pWAIC2 as the effective number of parameters to penalize the fit respectively; the Deviance information criterion 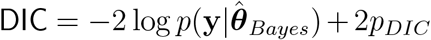 which uses
which uses 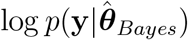 , as the measure of fit, and pDIC as the penalty. Note that a lower value implies a better predictive density, and the preferred model for each criteria and time period is shown in bold. See Appendix B for computational details.
, as the measure of fit, and pDIC as the penalty. Note that a lower value implies a better predictive density, and the preferred model for each criteria and time period is shown in bold. See Appendix B for computational details.
Comparison of models up to July 12th
The analysis of the time horizon March 4th to July 12th, leads to very similar conclusions (Figures 2b, A.3b–A.12b, A.13–A.15). Table 3 indicates that the impact of lockdown on the relative reduction in Rt was 64% for model 1, while in model 2, 7 countries already had Rt ≤ 1.0 and only two countries had 95% CIs for Rt exceeding 1.0 at the time of lockdown. In model 3, in contrast to the period until May 5th, with longer follow-up lockdown is statistically significant (95% CI is 0.23,1.43)
Comparison of the value of Rt at lockdown (LD) and its 95% CIs between model 1 and 2 for all eleven countries analysed in Flaxman et al. 1 and an additional three countries of Greece, Netherlands and Portugal, for the time horizon March 4th to July 12th.
In comparing the models, Table A.4 shows that model 2 provides a lower RMSE than model 1 for all countries for the period March 4th to July 12th, except Austria and Norway. Similarly, Table 2 again demonstrates that model 2 is best supported by the data for all three information criteria, WAIC1, WAIC2 and DIC.
Change of start date
Inferences regarding the impact of the imposition of NPIs is not substantially affected by the start date nor the priors for the initial infection count (Figure A.16).
4 Discussion
We demonstrate that effects of NPIs are non-robust and highly sensitive to model specification, assumptions and data employed to fit models. We obtained very different inferences regarding the effectiveness of lockdown measures in terms of curbing the epidemic wave and reducing fatalities. Lockdown appeared the most effective measure to save lives in the original analysis of 11 European countries performed by the Imperial College team through model 1. This analysis was published in Nature and has probably had a major impact to maintain a mentality among policy makers that lockdown should be used during the advent of second waves in many countries in the Fall of 2020. However, model 2 (which was also originally developed by the same team), suggests that these impacts were highly exaggerated, with little or no benefit from lockdown in most of the same countries.
Importantly, model 2 typically outperformed model 1 in data fit. Consideration of longer follow-up that included also the lifting of many measures still suggested that the originally1 claimed effects of lockdown are grossly overstated. Fitting yet a third model, resulted in yet further variant conclusions, with only mobility and event ban having regression coefficients with 95%CIs that did not contain 0 for the period until May 5th.
The different results and inferences of these models may be partly explained by the highly correlated structure of NPIs and mobility data, as well as the dense time clustering of the different NPIs being applied typically in close sequence. NPIs largely reduce Rt by reducing contact among individuals. An indirect measure of the reduction in individual contact is the mobility data, and so these data will be highly correlated with NPIs, making any inference difficult by default. Moreover, as different NPIs are typically introduced in close sequence, their exact time lag before impact is difficult to model. Interaction effects between different NPIs may also exist. The effectiveness of different NPIs may also vary across locations and across time based on adherence, acceptability, and enforcement. Any collateral harms may also affect acceptability and adherence.
Given that the inference around the effectiveness of various NPIs is highly model dependent and that more aggressive NPIs have more adverse effects on other aspects of health, society, and economy 7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25, it is ill-advised to ignore the substantial model uncertainty. Failing to report this uncertainty may ultimately undermine the public’s trust in the value of policy decisions based on statistical modeling. Flaxman et al. 1 made the statement “We find that, across 11 countries, since the beginning of the epidemic, 3,100,000 [2,800,000 - 3,500,000] deaths have been averted due to intervention”. Both the provided estimate and the accompanying limited uncertainty are highly misleading. When results vary widely based on model specification, strong inferences should be avoided.
We are concerned that Flaxman et al. 1 selectively reported on only model 1, even though the Google mobility data was available from early April and the Imperial College team had obviously been using this data and both models 1 and 2, as evidenced by several of their reports2;26;27, before their Nature publication. The results included in the Nature paper seem to suffer from serious selective reporting, providing the most favorable estimates for lockdown benefits, while model 2 would have led to more nuanced, if not different, conclusions. Also the three European countries excluded from the Nature publication had among the least favorable results for lockdown.
Given that modeling studies are typically not pre-registered, multiple analytical approaches and model specifications may be used on the same data28, and data and results may be filtered by modelers according to whether they fit their prior beliefs. This bias can have devastating implication if it leads to adoption of harmful measures.
We do not claim that lockdown measures definitely had no impact in the first wave of COVID-19. Indeed model 2 showed that Rt was still above 1 in some countries and thus it is possible that in these locations it may have some impact on the course of the epidemic wave. Other investigators using a different analytical approach have suggested also some benefits from lockdown; however, these benefits were of a smaller magnitude (e.g. 13% relative risk reduction29). Small benefits of such modest size would be less likely to match complete lockdown-induced harms in a careful decision analysis. Another modeling approach has found that benefits can be reaped by simple self-imposed interventions such as washing hands, wearing masks, and some social distancing30.
Some limitations of our work should be acknowledged. Besides model fit and parsimony metrics, theoretical and subjective considerations, as well as experience from other countries should be considered in model choice. However, given the observational nature of the data and the dynamic course of epidemic waves, one should avoid strong priors about effectiveness of different NPIs. Similarly, our results should not be interpreted with a nihilistic lens, i.e. that NPIs are totally ineffective. Decreasing exposures makes sense as a way to reduce epidemic wave propagation and eventually fatalities. However, if exposures can be reduced with less aggressive measures and fewer or no harms, this would be optimal. Finally, we did not examine very long-term time horizons. In theory, even effective measures may achieve only temporary mitigation and epidemic waves may surge again, when measures are relieved. We did observe this for the uplifting of measures in the July 12th analyses and empirical data from the emergence of second waves in many European countries and the USA in the fall of 2020 validate this hypothesis31. Availability of effective and safe vaccines may also affect risk-benefit ratios of NPI measures of different aggressiveness and different duration of implementation.
Overall, observational data that feed into complex epidemic models should be dissected very carefully and substantial uncertainty may remain despite the best efforts of modelers28;32. While there has been resistance to testing NPIs with randomized trials, such trials are feasible, and more thought and effort should be devoted on how to complement the available, tenuous observational data33. Regardless, causal interpretations from non-robust models should be avoided. In any decision analysis the accurate quantification of the size, not just the existence, of the impact of lockdown on Rt is also critical. This is difficult task when one considers all the confounds between NPIs and mobility, as well as the several behavioral changes such as hand washing and wearing masks. This is an interesting area for research, and crucial for the management of future pandemics.
Data Availability
All source code for the replication of our results is available from https://github.com/dare-centre/imperial-covid19-model
Author Contributions
All authors contributed equally to this work. VC performed all the computations and produced all the graphics. SC wrote the initial draft. JI and MT wrote subsequent drafts. All authors discussed the results and implications and commented on the manuscript at all stages.
Conflicts of Interest
None.
Code Availability
All source code for the replication of our results is available from https://github.com/dare-centre/imperial-covid19-model.
Funding
None.
Acknowledgements
We congratulate the Imperial College Response Team for sharing openly the code for their models and for the overall transparency of their work that has allowed performing these analyses. We thank Hadi Ashfar for his suggestions to improve the computational efficiency of the HMC scheme. We also thank Jack Wood for his help in the construction of Table A.3. We acknowledge the Sydney Informatics Hub and the University of Sydney’s high performance computing cluster Artemis for providing the high performance computing resources that have contributed to the research results reported within this paper.
A. Appendix: Additional Figures and Tables
Percentage change in mobility from baseline level from February 15th to July 12th, by locations in each of the European countries examined in Flaxman et al. 1, as well as an additional three countries consisting of Greece, the Netherlands and Portugal. Average mobility is computed based on the trends in retailers and recreation venues, grocery markets and pharmacy, transit stations and workplaces. Black dashed lines in each plot indicate the lockdown start and end dates.

Trace plots, posterior mean, 95% CIs and 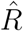 of regression coefficients in Rt for all three models based on ten MCMC chains, for both time horizons. All our analyses use the iterates from chains which had no more than 5% of divergent transitions. Black crosses (×) denote chains with more than 5% of divergent transitions.
of regression coefficients in Rt for all three models based on ten MCMC chains, for both time horizons. All our analyses use the iterates from chains which had no more than 5% of divergent transitions. Black crosses (×) denote chains with more than 5% of divergent transitions.

Austria. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
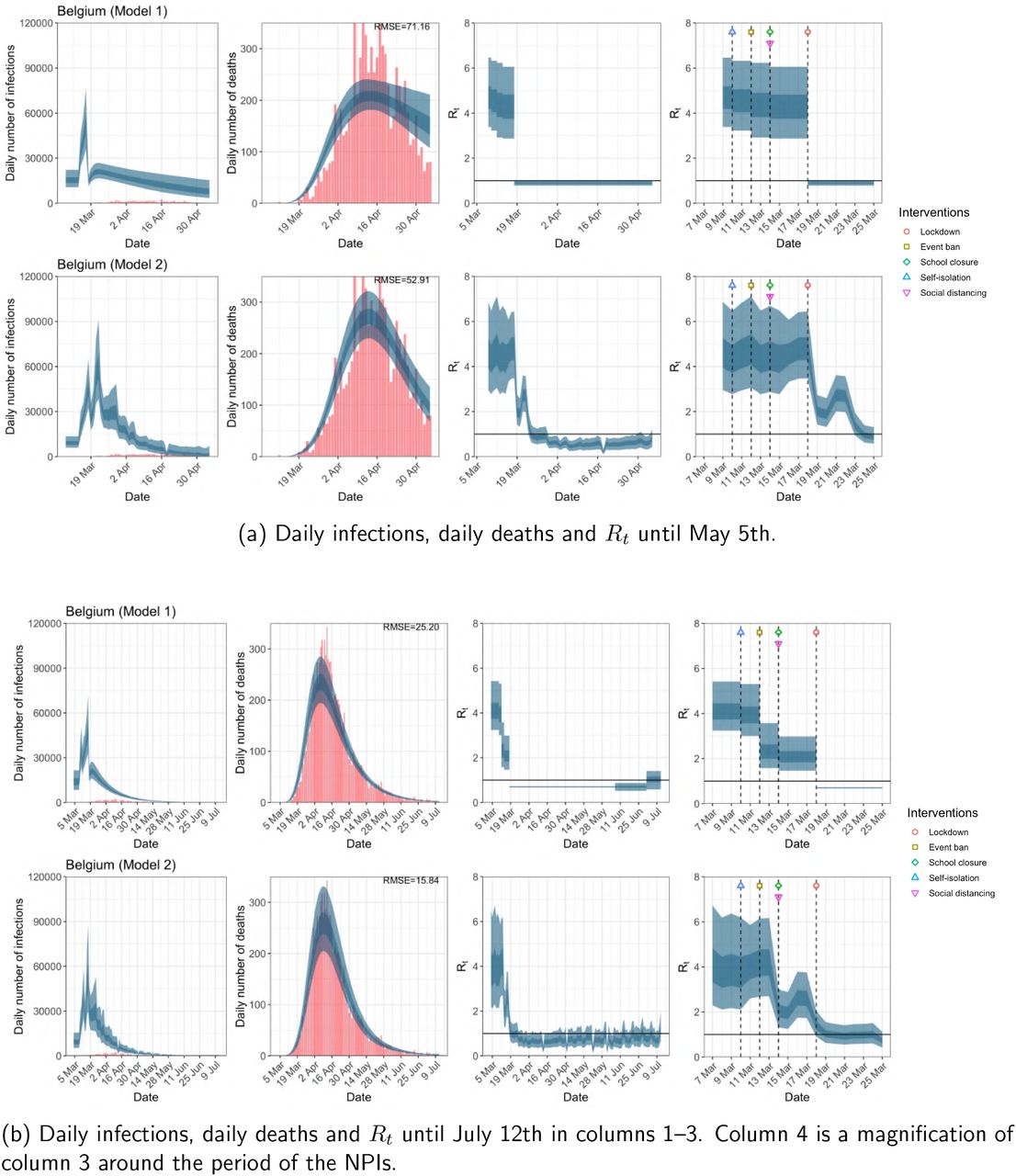
Belgium. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Denmark. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

France. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Germany. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
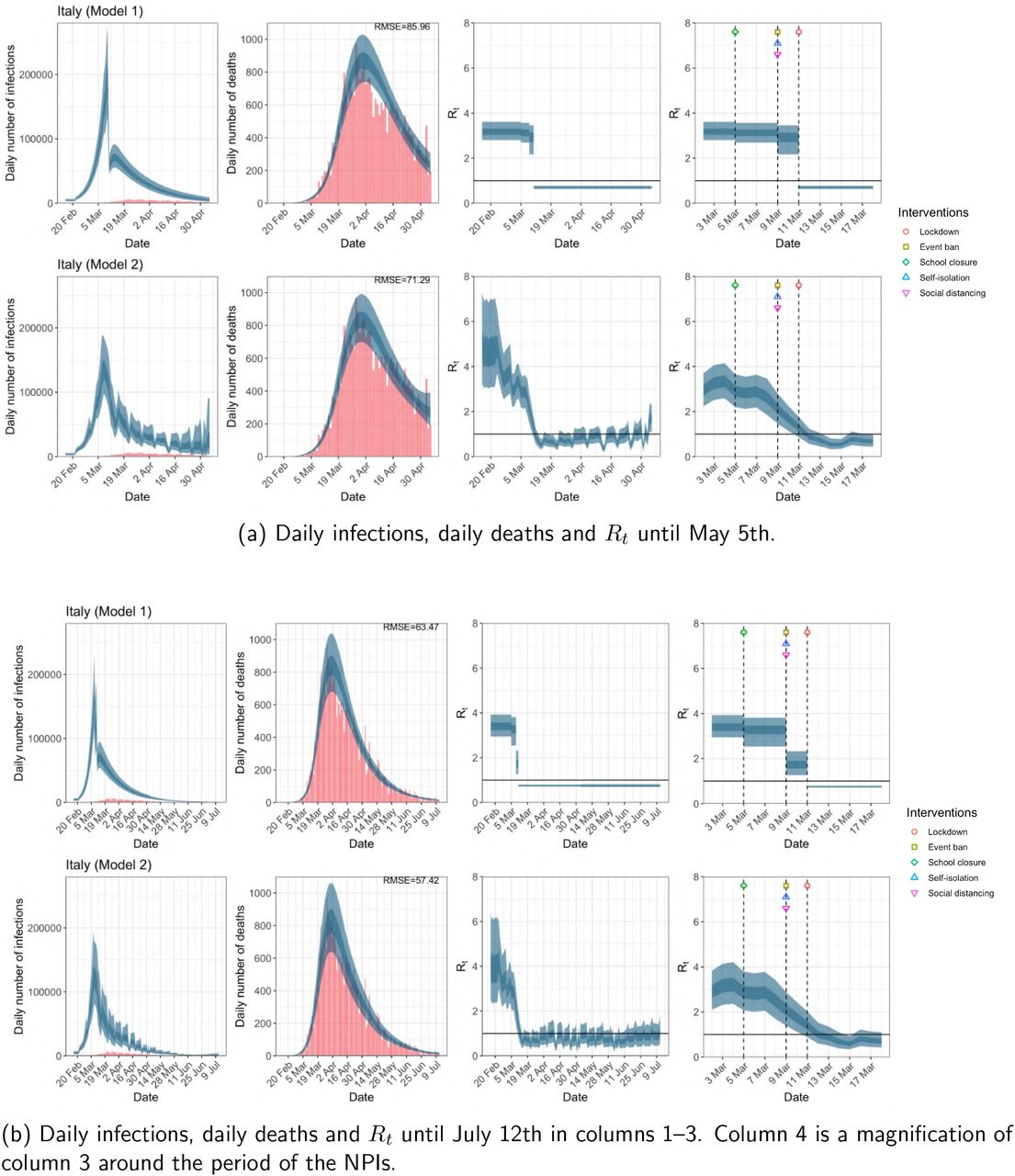
Italy. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
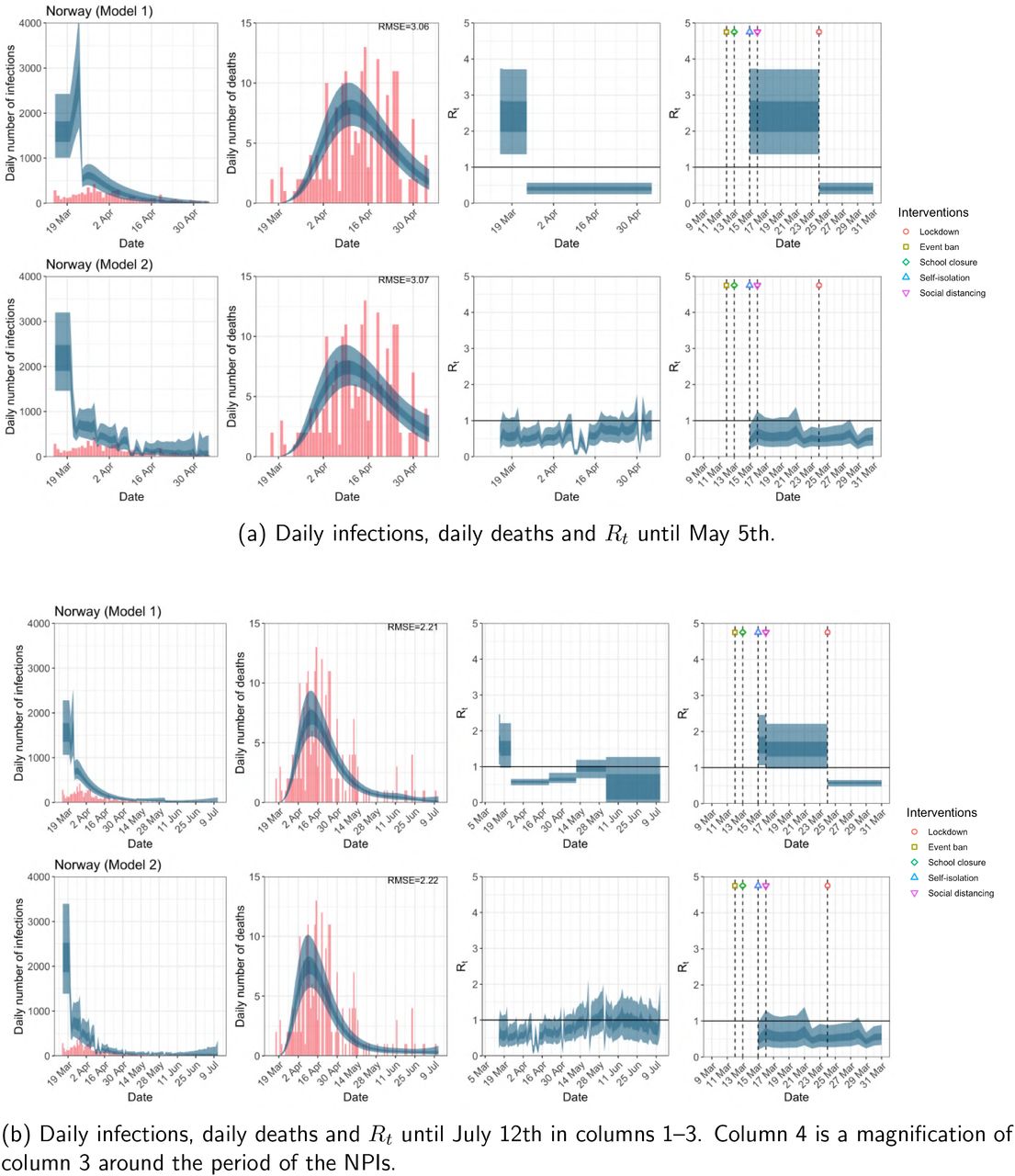
Norway. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Spain. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Sweden. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
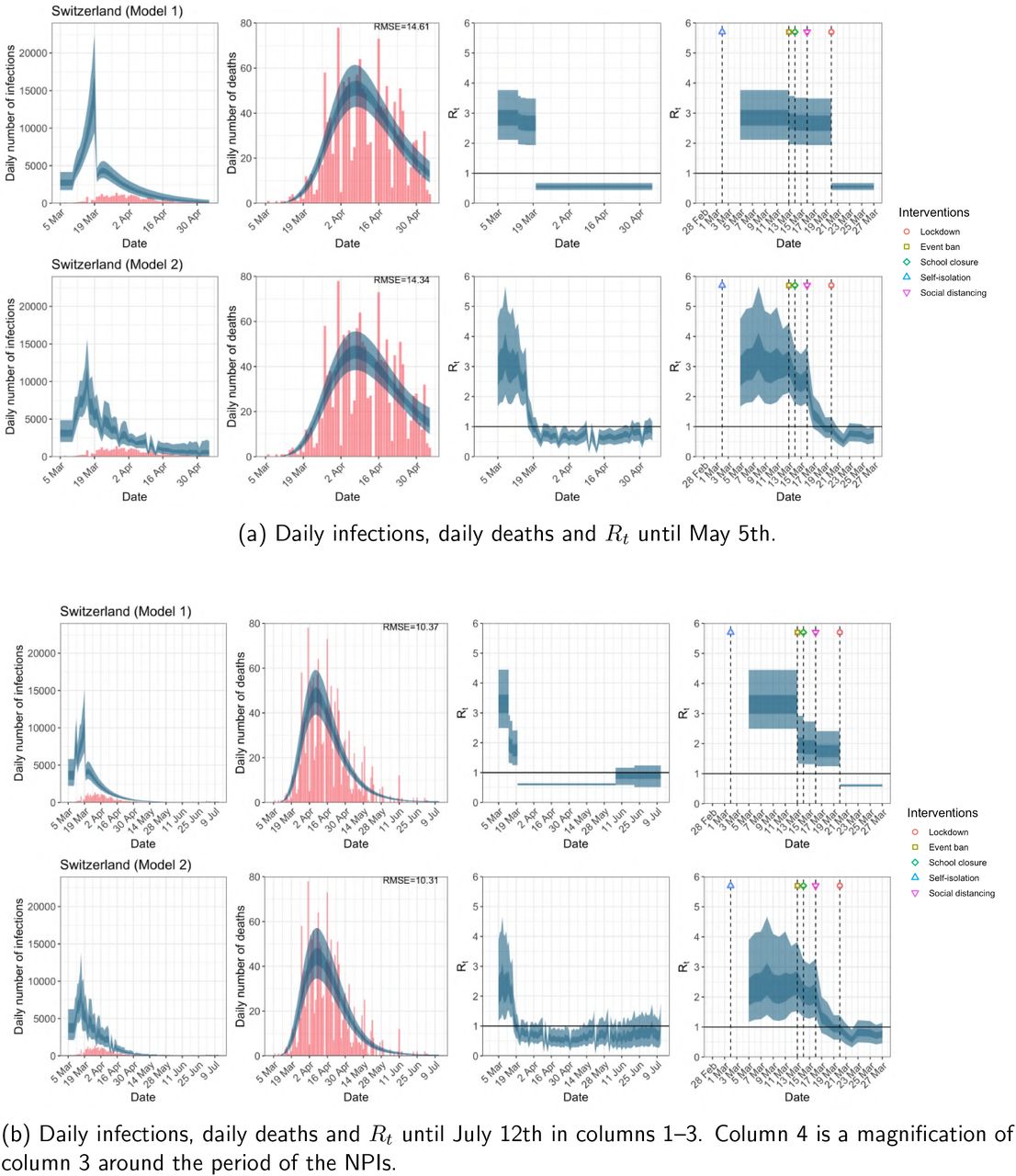
Switzerland. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Greece. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths until July 12th are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively. Column 4 is a magnification of column 3 showing the changes in Rt around the period of the NPIs.
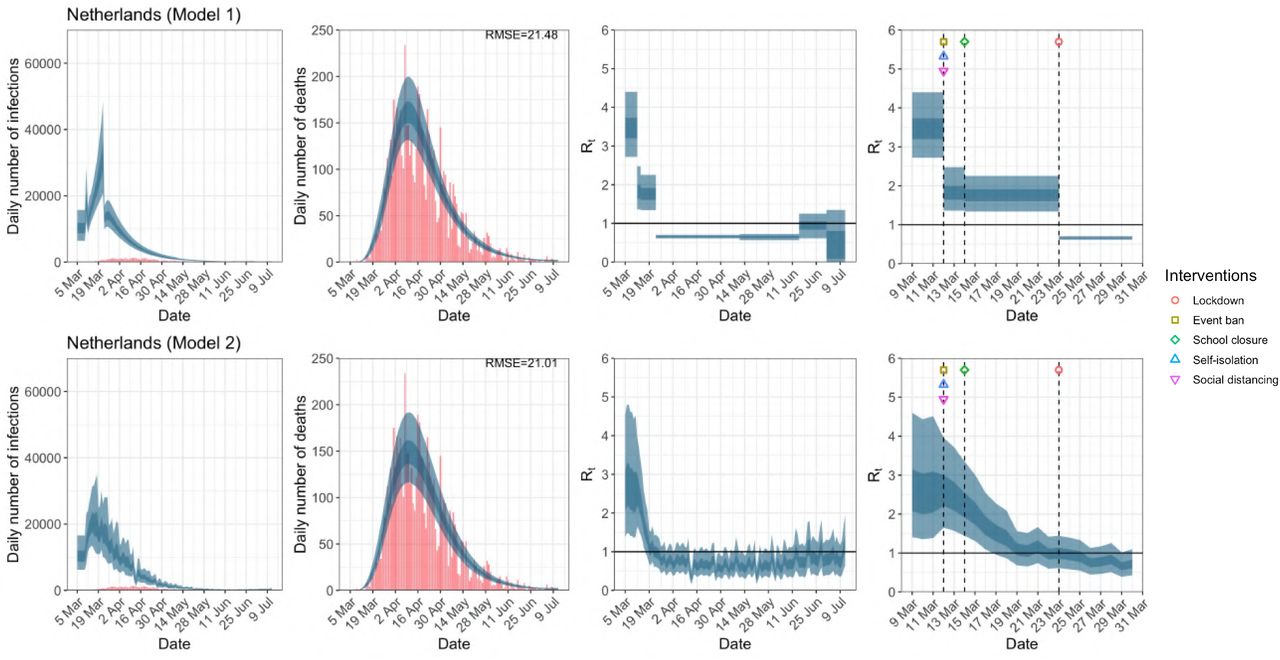
Netherlands. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths until July 12th are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively. Column 4 is a magnification of column 3 showing the changes in Rt around the period of the NPIs.

Portugal. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths until July 12th are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively. Column 4 is a magnification of column 3 showing the changes in Rt around the period of the NPIs.
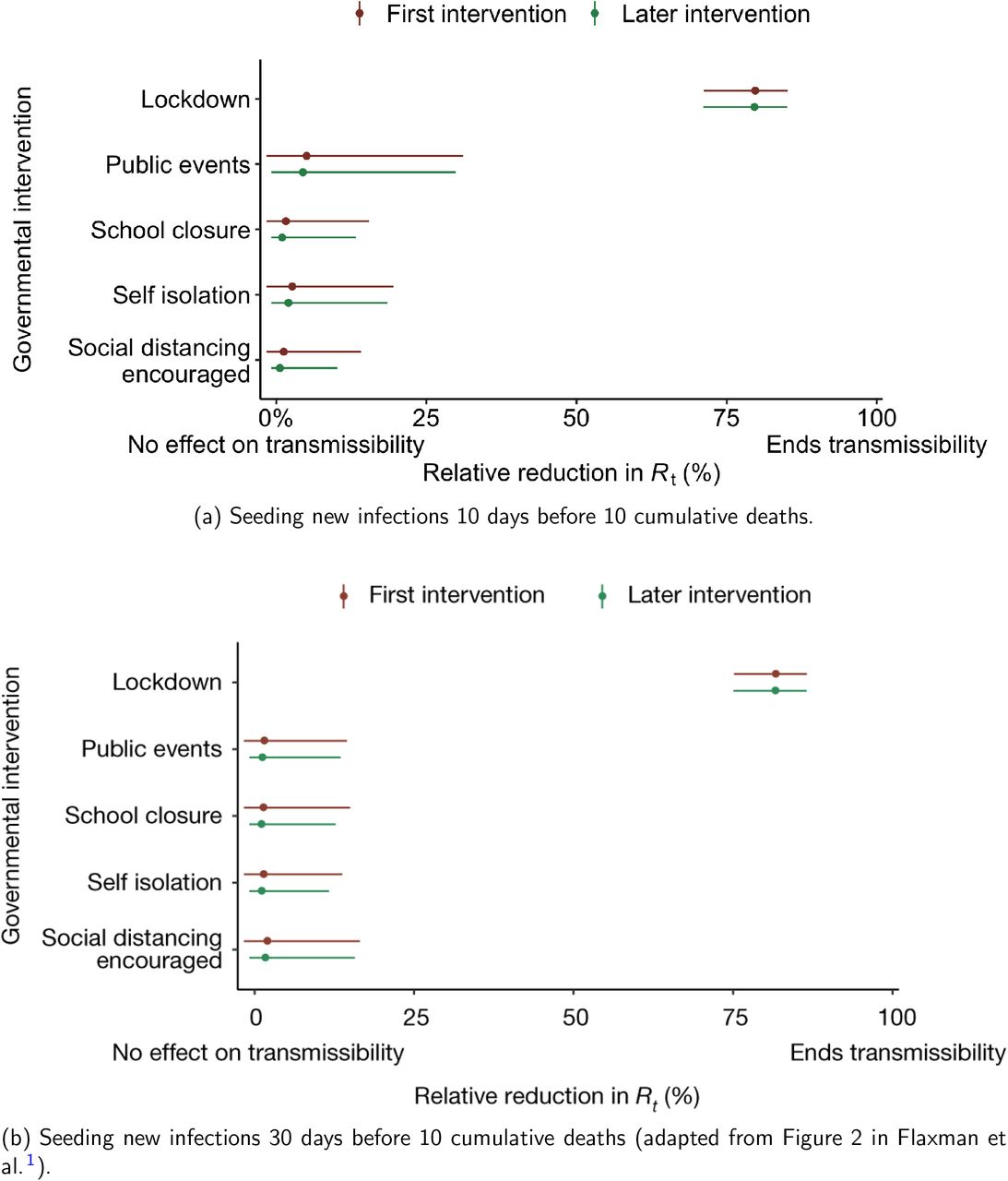
Comparison of the effectiveness of NPIs in terms of the relative percentage reduction in Rt when assuming two different seeding periods of new infections.
Seeding dates of new infections. Two seeding dates were used for Belgium – March 9th and March 4th for the data up to May 5th and July 12th respectively due to a reporting correction in the data.
Correspondence of subscripts for k to each NPI.
RMSE of daily death counts for model 1 and 2 for the data up to May 5th and July 12th.
Basic reproduction number R0 and time-varying reproduction number Rt immediately after the introduction of NPIs given by both models using data up to May 5th for all eleven countries analysed in Flaxman et al.1. These NPIs are self-isolation (SI), social distancing (SD), school closure (SC), event ban (EB) and lockdown (LD). 95% credible intervals are given in parentheses below the corresponding point estimates. Countries where the seeding of new infections occur after the introduction of NPIs are denoted with an asterisk.
B. Appendix: Priors and Measures of Fit
B.1 Priors
For posterior inference in model 1, we use the same priors as in Flaxman et al.1 for the analysis up to May 5th and July 12th. For model 2, we use the same prior distributions as in Unwin et al.2 except for R0, and α in Equation 2.
For R0 we use a weakly informative prior of a normal distribution truncated below at 1 with mean 3.28 and standard deviation 2 is used. This prior is chosen so that approximately 95% of the prior density is between 1 and 738, and that R0 is above the critical value of 1 at the start of the epidemic.
For α, we examine the sensitivity of the posterior to two priors. The first prior that we consider is that used by Unwin et al.2–this prior is very informative, with α ∼N (0, 0.5). That is, a priori they assume α lies in the interval [−1, 1] with probability 0.95. In contrast, the second prior we considered was an uninformative prior, α ∼N (0, 5), and found the posterior mode of α in model 2 up to May 5th to be approximately −4. This means that the prior used by Unwin et al.2 has almost no support over this posterior distribution. This has two consequences, first it makes convergence of the Markov chain very difficult and sensitive to starting values. Second, it shrinks the value of α towards zero, underestimating the impact of mobility on Rt. The second prior, α ∼N (0, 5), makes the convergence of the chain more robust to poor starting values.
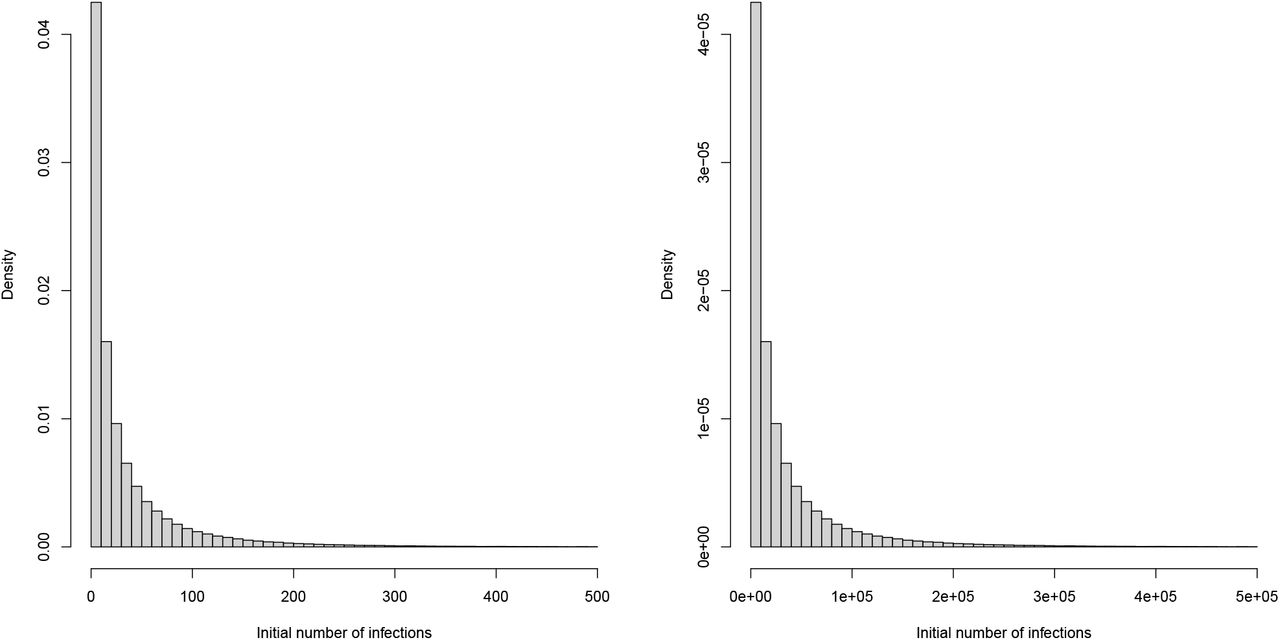
We also change the prior for the number of initial infection at the start of the time period for two reasons. First, due to data constraints, we chose to start the seeding of infections only 10 days before the date of the 10th cumulative death. In contrast, Flaxman et al. 1 chose to start the seeding of infections 30 days prior to the date of the 10th cumulative death. Flaxman et al. 1 chose a prior for initial infection count which was relatively tight, the probability that the initial infection count was greater than 500 is ≈ 0. Using this prior for the number of infections 20 days later again, is not realistic and again leads to convergence problems. We therefore chose a less informative prior for the initial infection count. Plots of these prior distributions can be found in Figure B.1.
Notably, Bayesian data analysts typically examine a variety of priors to gauge the sensitivity of results to the prior specification6. Flaxman et al1 limited analyses to one prior distribution for their entire set of parameters.
B.2 Bayesian measures of model fit
To compare the fit of the three models to the data we consider four metrics; three estimates of various information criteria, as well as the root mean square error (RMSE). The information criteria metrics are two versions of the Watanabe-Akaike information criteria39, denoted by WAIC1 and WAIC2 and the Deviance information criterion DIC40. Both WAIC1 and WAIC2 use the log pointwise predictive density (lppd) as a measure of fit. To penalize the fit, WAIC1 uses
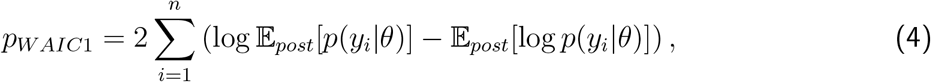 as an estimate of the effective number of parameters, where 𝔼post denotes the expectation over the posterior distribution of model parameters θ given the observed data y = {yi; i = 1, …, n}.
as an estimate of the effective number of parameters, where 𝔼post denotes the expectation over the posterior distribution of model parameters θ given the observed data y = {yi; i = 1, …, n}.

Prior distributions of initial infection count used in Flaxman et al. 1 (left) and our analysis (right).
The criteria WAIC2 uses
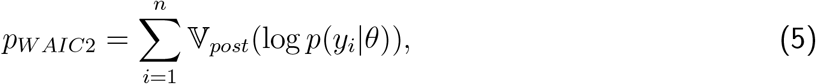 where 𝕍post denotes the variance over the posterior distribution of θ. The DIC metric uses
where 𝕍post denotes the variance over the posterior distribution of θ. The DIC metric uses 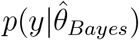 , with
, with 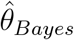 being the posterior mean of θ, as a measure of fit and
being the posterior mean of θ, as a measure of fit and
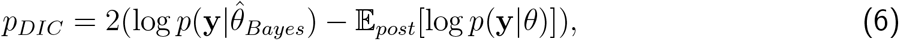 as the penalty.
as the penalty.
C. Appendix: Analysis up to May 5th for all 14 countries
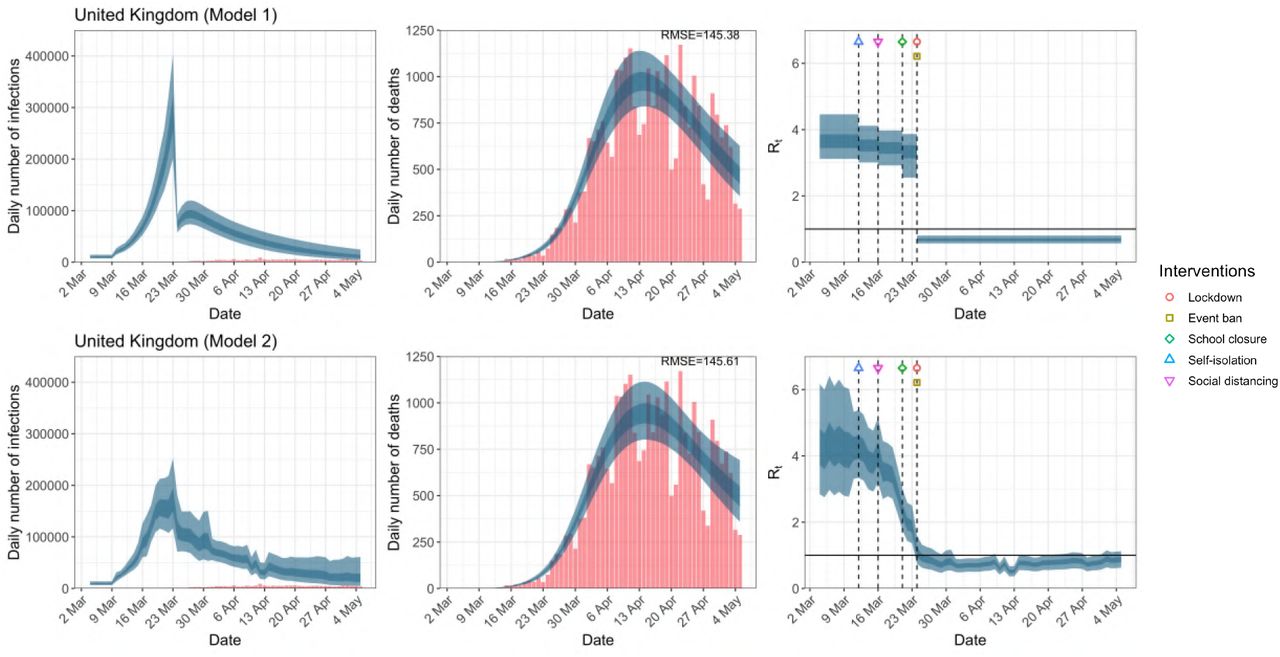
Daily infections, daily deaths and Rt in the United Kingdom until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in Austria until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in Belgium until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
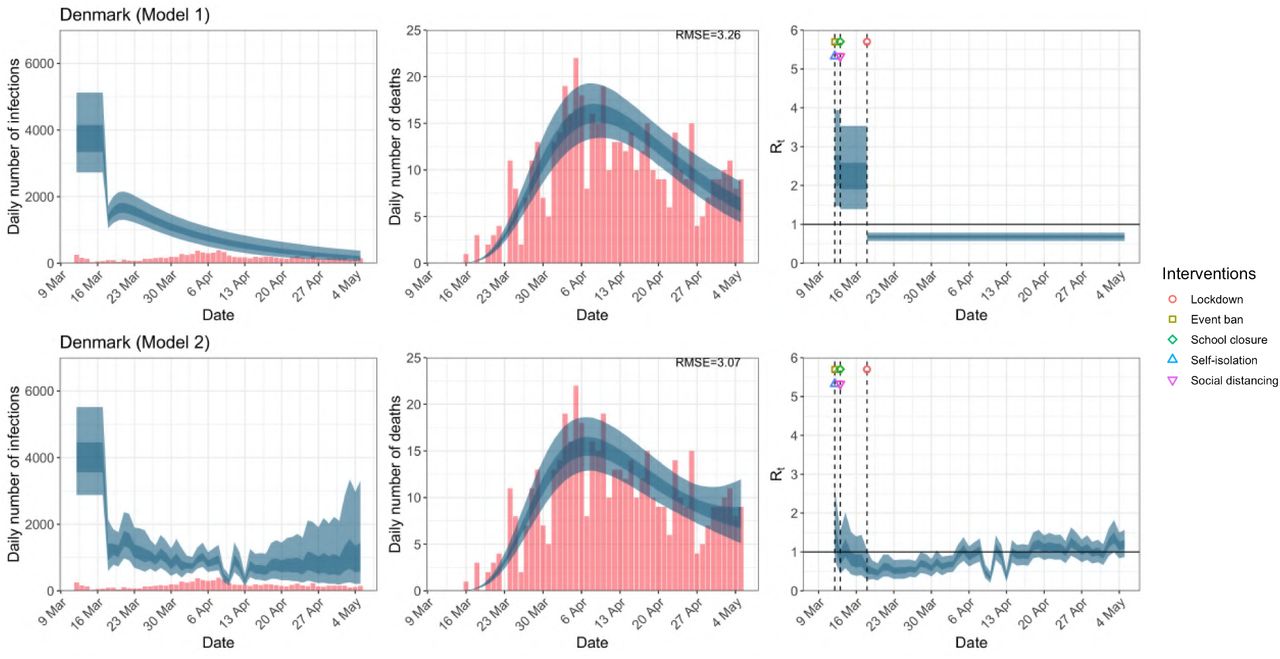
Daily infections, daily deaths and Rt in Denmark until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in France until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in Germany until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
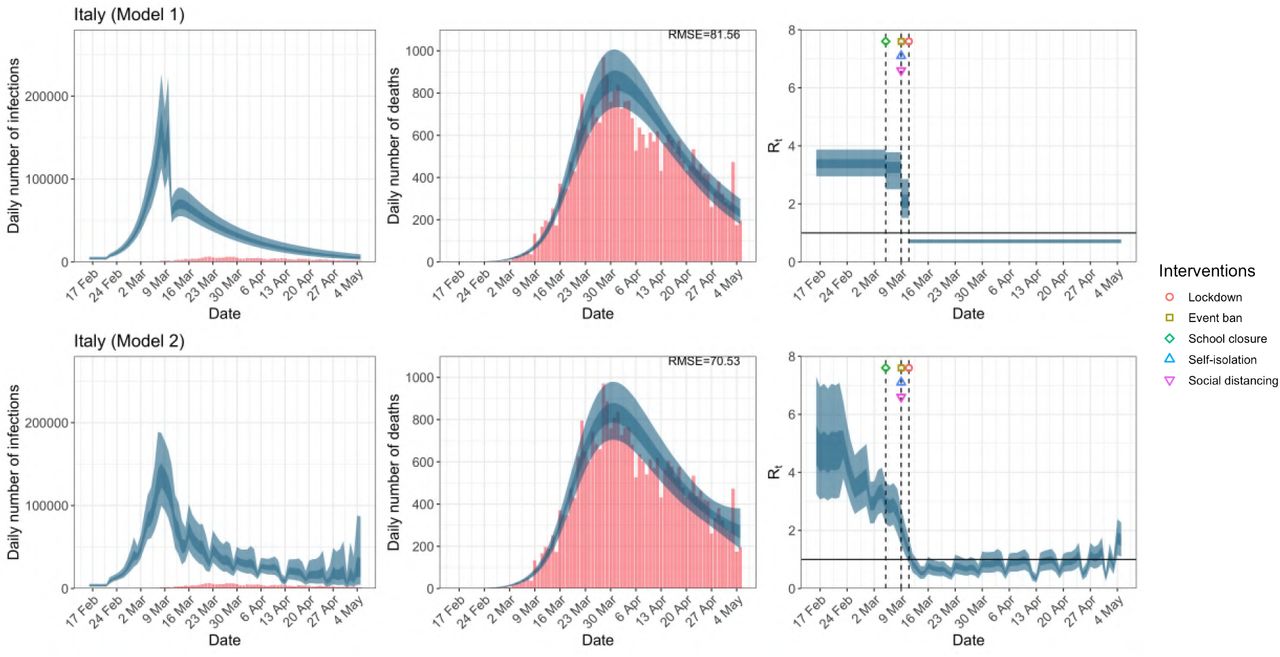
Daily infections, daily deaths and Rt in Italy until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in Norway until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
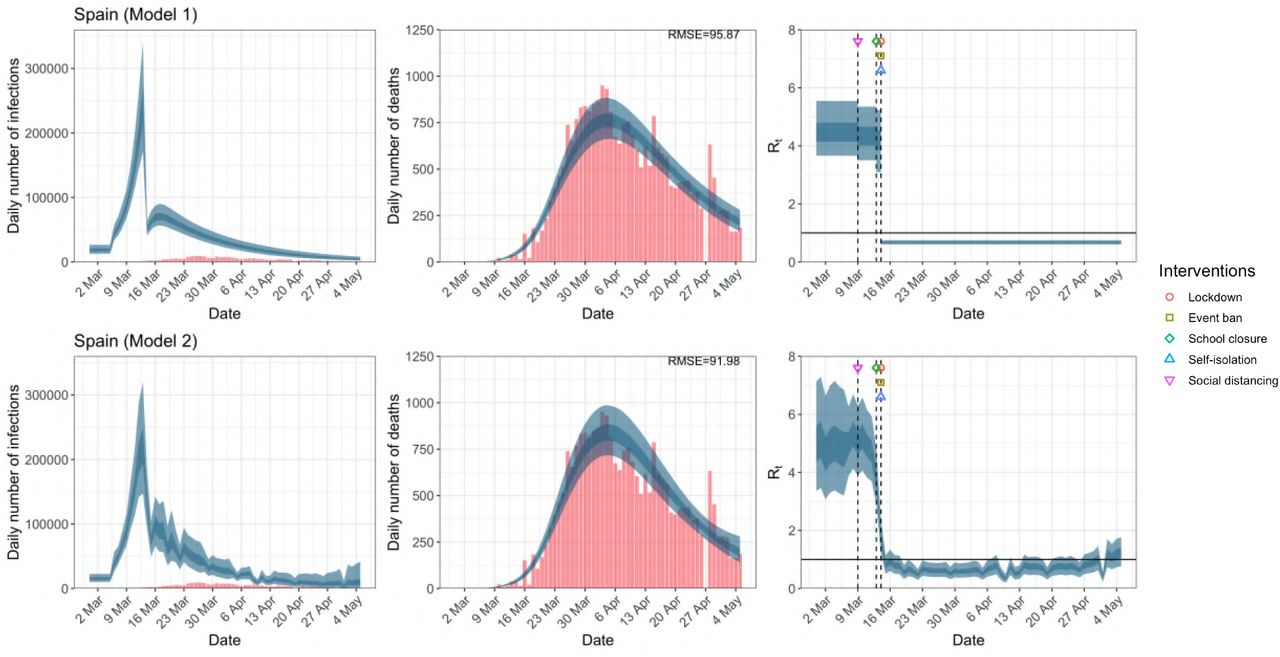
Daily infections, daily deaths and Rt in Spain until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
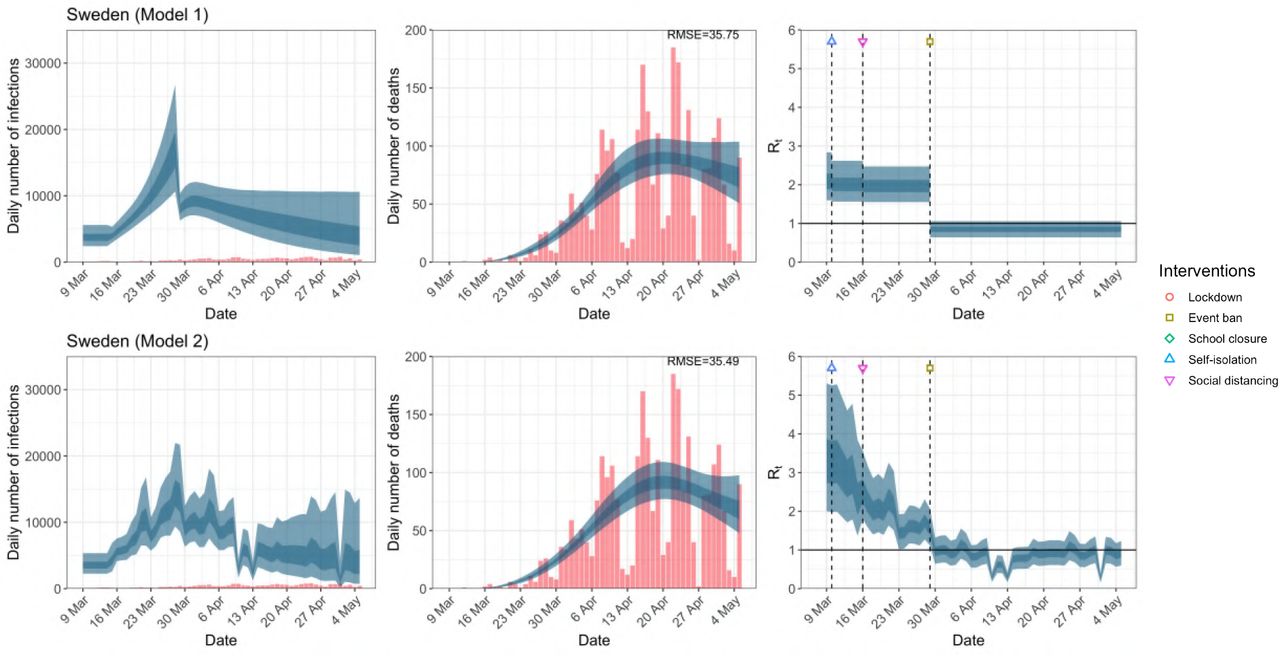
Daily infections, daily deaths and Rt in Sweden until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
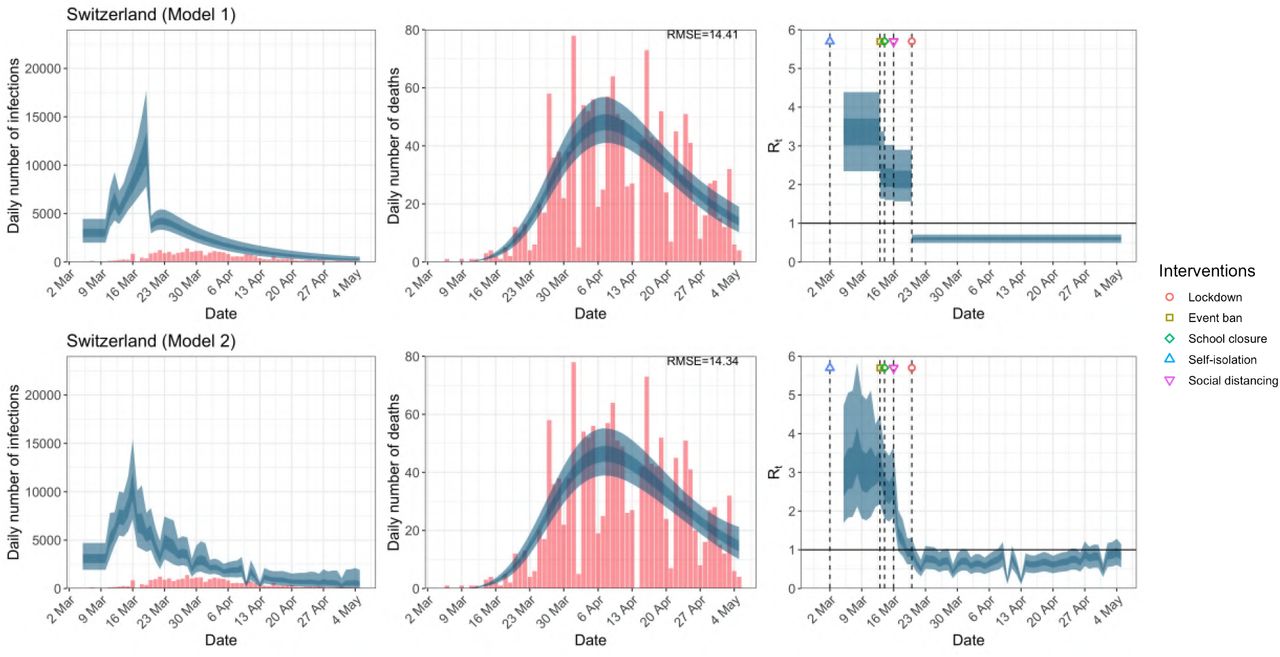
Daily infections, daily deaths and Rt in Switzerland until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in Greece until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

Daily infections, daily deaths and Rt in the Netherlands until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Daily infections, daily deaths and Rt in Portugal until May 5th. The start time for the plots is 10 days before 10 deaths are recorded. Observed counts of daily infections and daily deaths are shown in red, and their corresponding 50% and 95% CIs are shown in dark blue and light blue respectively.
Comparison of the value of Rt at lockdown (LD) and its 95% CIs between model 1 and 2 for all eleven countries analysed in Flaxman et al. 1 and an additional three countries of Greece, Netherlands and Portugal, for the time horizon March 4th to May 5th.
References



