
ABSTRACT
We propose a new method to estimate the time-varying effective (or instantaneous) reproduction number of the novel coronavirus disease (COVID-19). The method is based on a discrete-time stochastic augmented compartmental model that describes the virus transmission. A two-stage estimation method, which combines the Extended Kalman Filter (EKF) to estimate the reported state variables (active and removed cases) and a low pass filter based on a rational transfer function to remove short term fluctuations of the reported cases, is used with case uncertainties that are assumed to follow a Gaussian distribution. Our method does not require information regarding serial intervals, which makes the estimation procedure simpler without reducing the quality of the estimate. We show that the proposed method is comparable to common approaches, e.g., age-structured and new cases based sequential Bayesian models. We also apply it to COVID-19 cases in the Scandinavian countries: Denmark, Sweden, and Norway, where we see a delay of about four days in predicting the epidemic peak.
Introduction
The coronavirus disease 2019 (COVID-19), i.e., a disease outbreak of atypical pneumonia that originated from Wuhan, China1, has caused globally at least 90 million confirmed cases, including an estimated 2 million deaths in approximately 216 countries by the end of 2020. The World Health Organization declared the COVID-19 crisis a pandemic on 11 March 2020.
In modelling the disease’s transmission as well as to inform and evaluate control policies, it is particularly important to estimate its reproduction number. Early estimates for COVID-19 basic reproduction number ℛ0, that denotes the transmission potential of infectious disease when introduced to a completely susceptible population, ranged from 1.4 to 6.492. The effective (or instantaneous) reproduction number ℛt, on the other hand, reflects the extent of transmission in the presence of population immunity or intervention. Thus, the estimation of ℛt is important for evaluating public measure success. However, estimation of ℛt is sensitive to the model structure and parameter assumptions3. As a case in point, due to incorporation of more individual case information and travel data, the estimate for ℛ0 in Wuhan was revised upward from 2.2-2.7 to 5.74. On the other hand, data inavailability or poor quality often hinders the use of certain estimation methods, such as serial interval data that are usually needed to estimate ℛt (e.g., Fraser5, Wallinga and Teunis6, Cauchemez et al.7, White and Pagano8).
In the course of calculating the exact value of ℛt, especially when the data has not yet reached its peak, precise assumptions and data estimates are needed. Nishiura et al.9 discussed a likelihood-based approach to estimate ℛt from early epidemic growth data. Using the compartmental Susceptible-Infectious-Recovered (SIR) model, Bettencourt and Ribeiro10 use the incidence data to estimate ℛ0 and ℛt. In this paper, based on the Susceptible-Infectious-Recovered-Dead (SIRD) model as a reference, we develop a novel approach to estimate ℛt of COVID-19. It uses information on the number of infected or active (I), recovered (R), and death (D) cases, which are readily available for all affected countries, so that they can be accessed rather easily.
The reproduction number is estimated from reported cases under uncertainties using a two-stage estimation method based on the Extended Kalman Filter (EKF) and a low-pass filter. The method not only considers the nominal number of reported cases, but also its daily pattern. To show our method’s practical ability, we apply it to COVID-19 cases in the Scandinavian countries, i.e., Denmark, Sweden, and Norway, and compare the results with two commonly used Bayesian methods due to Bettencourt and Ribeiro10 and Cori et al.5,11. We show that the results are indeed comparable.
A Discrete-Time Stochastic Augmented Compartmental Model
Our estimation method is based on the compartmental SIRD model that can be written as the following first-order nonlinear differential equations:



 where S denotes the number of susceptible individuals, N is the total population, β is the average number of contacts per person per time, γ and κ are the recovery and death rate, respectively. Remark that the value of β is time-varying due to intervention, i.e., β =β (t). To use the model, we require information on the average infectious time Ti and the case fatality rate CFR, so that
where S denotes the number of susceptible individuals, N is the total population, β is the average number of contacts per person per time, γ and κ are the recovery and death rate, respectively. Remark that the value of β is time-varying due to intervention, i.e., β =β (t). To use the model, we require information on the average infectious time Ti and the case fatality rate CFR, so that
 For COVID-19, we take Ti = 9 as the infectious period on average lasts for 9 days (i.e., 7-11 days with 95% CI)12. The time-varying effective reproduction number is then given by:
For COVID-19, we take Ti = 9 as the infectious period on average lasts for 9 days (i.e., 7-11 days with 95% CI)12. The time-varying effective reproduction number is then given by:
 The approximation is under the assumption that government intervention is taken at an early stage so that the susceptible is relatively the same over time as the total population. This is the case especially for emerging diseases. We modify the SIRD model by augmenting the following two equations into the system:
The approximation is under the assumption that government intervention is taken at an early stage so that the susceptible is relatively the same over time as the total population. This is the case especially for emerging diseases. We modify the SIRD model by augmenting the following two equations into the system:
 The former equation takes into account the daily number of reported new cases E, while the latter one says that the effective reproduction number ℛt is assumed to be a piece-wise constant function with jump every one day time interval.
The former equation takes into account the daily number of reported new cases E, while the latter one says that the effective reproduction number ℛt is assumed to be a piece-wise constant function with jump every one day time interval.
Discretizing the model using the forward Euler method, we obtain the following discrete-time augmented SIRD model:

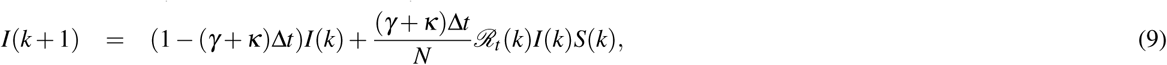



 Our method computes a new estimate of ℛt based on new reported cases. Since their frequency is low (could be once a day), the reported data can be interpolated using, e.g., a modified Akima cubic Hermite interpolation, such that it fits with the time step Δt. In our simulation, the time step Δt is chosen as 0.01, i.e., 100 time discretization within one day interval. The confidence interval of our estimated ℛt is determined by computing the reproduction number for different values of the infectious period Ti within a certain interval.
Our method computes a new estimate of ℛt based on new reported cases. Since their frequency is low (could be once a day), the reported data can be interpolated using, e.g., a modified Akima cubic Hermite interpolation, such that it fits with the time step Δt. In our simulation, the time step Δt is chosen as 0.01, i.e., 100 time discretization within one day interval. The confidence interval of our estimated ℛt is determined by computing the reproduction number for different values of the infectious period Ti within a certain interval.
To simplify the presentation, we define the augmented state vector
 and as such, the discrete-time augmented SIRD model (8)–(13) can be written as follows
and as such, the discrete-time augmented SIRD model (8)–(13) can be written as follows
 where f is the nonlinear term written in the right hand side of (8)–(13) and w is introduced as an uncertainty to model the inaccuracies due to simplification in the modelling. The uncertainty is assumed to be a zero mean Gaussian white noise with known covariance QF. In practice, QF can be considered as a tuning parameter for the EKF. Thus, the transmission model becomes a discrete-time stochastic augmented SIRD model.
where f is the nonlinear term written in the right hand side of (8)–(13) and w is introduced as an uncertainty to model the inaccuracies due to simplification in the modelling. The uncertainty is assumed to be a zero mean Gaussian white noise with known covariance QF. In practice, QF can be considered as a tuning parameter for the EKF. Thus, the transmission model becomes a discrete-time stochastic augmented SIRD model.
Reported cases, such as the number of active cases and the cumulative numbers of recovered and death, can be incorporated into the model using the following output vector
 Here, v denotes uncertainties due to false testing results. We also assume the uncertainty to be a zero mean Gaussian white noise with known covariance RF. As well as QF, RF can also be considered as a tuning parameter. Following the available data that include I, R, D, and E, the data/measurement matrix C is taken to be
Here, v denotes uncertainties due to false testing results. We also assume the uncertainty to be a zero mean Gaussian white noise with known covariance RF. As well as QF, RF can also be considered as a tuning parameter. Following the available data that include I, R, D, and E, the data/measurement matrix C is taken to be

A Two-Stage Filtering Method
A two-stage filtering method is used to estimate the daily reproduction number ℛt. The method consists of the EKF and a low-pass filter. In the first stage of estimation, the EKF is used to estimate the state variables and the value of ℛt under uncertainties in the number of reported cases. Afterwards, the low pass filter is used to remove short term fluctuations of the reported cases that can be caused by delays in the reporting. For example, suddenly in Denmark there were 893 recovered patients reported on 1 April 2020, in contrast to the previous days from 16 February 2020 onwards when there was no recovery reported at all. Such an accumulated delay can cause a falsely decreasing value of ℛt.
The EKF is an extension of Kalman filter for nonlinear systems. The Kalman filter itself is based on a recursive Bayesian estimation and is an optimal linear filter. The idea of EKF is to linearize the non-linearity around its estimate. Due to that linearization, the optimality and stability of the EKF cannot be guaranteed. However, if the non-linearity is not severe, the EKF can give a reasonably good estimate.
Let us denote 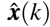 as an estimated vector state from the EKF. Applying first-order Taylor series expansion to f at
as an estimated vector state from the EKF. Applying first-order Taylor series expansion to f at 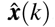 , we obtain
, we obtain
 where
where 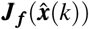 is the Jacobian matrix of f, given by:
is the Jacobian matrix of f, given by:
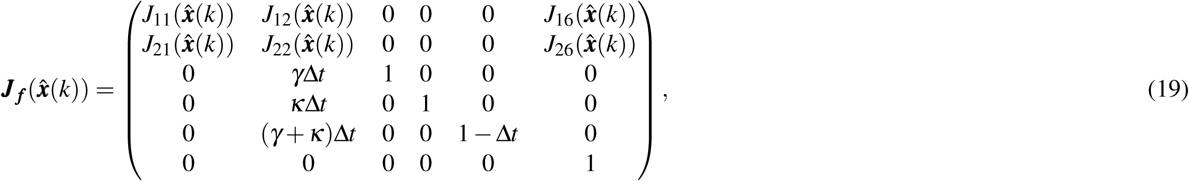 Where
Where





 The EKF consists of two steps: predict and update. The discrete-time stochastic augmented SIRD model is used to predict the next state and covariance and update them after obtaining new data/measurement. The EKF can be considered as one of the simplest dynamic Bayesian networks. While the EKF calculates estimates of the true values of states recursively over time using incoming measurements and a mathematical process model, recursive Bayesian estimation calculates estimates of an unknown probability density function recursively over time using incoming measurements and a mathematical process model13. Let
The EKF consists of two steps: predict and update. The discrete-time stochastic augmented SIRD model is used to predict the next state and covariance and update them after obtaining new data/measurement. The EKF can be considered as one of the simplest dynamic Bayesian networks. While the EKF calculates estimates of the true values of states recursively over time using incoming measurements and a mathematical process model, recursive Bayesian estimation calculates estimates of an unknown probability density function recursively over time using incoming measurements and a mathematical process model13. Let 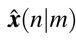 denotes the estimate of x at time n given observations up to and including at time m ≤ n. The Kalman filter algorithm is given as follows14
denotes the estimate of x at time n given observations up to and including at time m ≤ n. The Kalman filter algorithm is given as follows14
Predict

 Update
Update

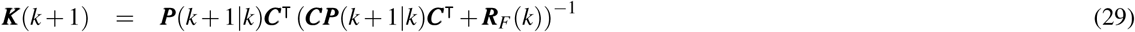

 Here P(k|k) denotes a posteriori estimate covariance matrix. In the second stage, a low pass filter based on a rational transfer function is used to remove short term fluctuation at time step k, and is given by
Here P(k|k) denotes a posteriori estimate covariance matrix. In the second stage, a low pass filter based on a rational transfer function is used to remove short term fluctuation at time step k, and is given by
 where yn is a window length along the data. In our case, we choose
where yn is a window length along the data. In our case, we choose 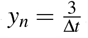 .
.
To evaluate the quality of the estimate, we calculate a Relative Root Mean Square Error (RRMSE) between the estimated and reported cases. The RRMSE is defined as
 where Nd is the number of observed days and X ∈ {I, D, R, E}.
where Nd is the number of observed days and X ∈ {I, D, R, E}.
Case study: Scandinavian countries
In this section, we apply our method to study viral transmission of COVID-19 in Denmark, Sweden, and Norway. All datasets and MATLAB code are available on GitHub (https://github.com/agusisma/covid19). As the country of residence of the corresponding author, Denmark has a high estimated percentage of reported symptomatic COVID-19 cases, i.e., 61% (42%-87% of 95% CI). Norway is at 73% with 43%-98% of 95% CI. On the contrary, Sweden only has 15% (11%-19% of 95% CI). The countries also have a different approach in their public measures in responding to COVID-19, i.e., Sweden did not implement a strict lockdown, unlike its Nordic neighbouring countries.
We plot the observed incidence of COVID-19 in Denmark, Sweden, and Norway in Fig. 1. We also plot in the same figure estimated numbers computed using our method, where good agreement is obtained. For all estimation, the process and observation covariance matrices are considered as tuning parameters and are chosen as QF = diag(10 10 10 10 5 0.2) and RF = diag(100 10 10 5 1), respectively. These parameters are chosen such that the RRMSE between the estimated and reported data are sufficiently small. In our case study, the RRMSE are shown in Table 1.
RRMSE of the two-stage filtering method for Scandinavian countries.


Active (I), Recovered (R), Death (D), and daily new cases (E) in (a) Denmark; (b) Sweden, and (c) Norway. Plotted are reported data and model fit estimated using our method.
In applying our method, we also compare it with two commonly used methods to estimate transmission parameters, namely the sequential Bayesian method of Bettencourt and Ribeiro10 that provides an approximation of the basic reproduction number, and the instantaneous method by Fraser5 that is implemented with a Bayesian analysis11,15. The former method exploits the new reported incidence, while the latter one uses the distribution of the serial interval.
First, we compare our method with that of Bettencourt and Ribeiro10, that allows sequential estimation of the basic reproduction number at the initial stage, i.e., when the growth is still exponential. While the two methods are based on the SIR model, Bettencourt and Ribeiro10 rather use new incidence data, which in here need to be smoothed out using a five-day moving average filter. In Fig. 2, we plot the comparison and summarise the basic reproduction numbers that are taken to be the maximum of the curves in Table 2. It is interesting to note how the methods give rather similar estimations. This indicates that our method gives comparable results to those of10.
Estimates of the basic reproduction number ℛ0 of the countries by our method and Bettencourt and Ribeiro10.


The estimated reproduction number at the early stage of the pandemic in (a) Denmark, (b) Sweden, and (c) Norway using our proposed method and10.
Finally, we plot the time-varying effective reproduction number in Fig. 3. Here, we compare our results with those using Cori et al.11. The method of11 utilises the disease serial interval, which we approximate using a shifted Gamma distribution11 with mean 4.7 and standard deviation 2.916. The prior belief for the value of ℛt is taken to be Gamma function with mean and standard deviation 5. We do not average out the data of daily new cases, but instead take the likelihood estimation of a new case at one day to depend also on the estimation of the previous three days.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Estimated time-varying effective reproduction number of (a) Denmark, (b) Sweden, and (c) Norway by our method and11.
In Fig. 3 we obtain that the two methods give the plot of ℛt with the same trend, indicating that our method is also comparable with11. There is a delay of about four days in the trend, especially with the time when the reproduction number curve crossed the horizontal axis. The delay is caused by the peaks of new daily cases and active ones that also differ by about the same days.
A different trend especially at later times between the methods appears in Fig. 3(c) for Norway. The curve from our method is quite smooth, while it is rather fluctuating in that using Cori et al.11. The discrepancy is caused by the active and recovered cases that apparently were not updated regularly, in contrast to the new positive cases needed by the method of11. The unreported recovery cases were all released at once on May 22, 2020, see Fig. 1(c).
Conclusion and Future Work
Many mathematical models have been developed to estimate several types of reproduction numbers during epidemic outbreaks. We here provide a novel method exploiting reported active, recovered and death cases using the SIR model as an underlying approach. This new method offers several advantages, from the modeling point of view, the resulting ℛt value can follow the dynamics of the model suggested, so it is possible to develop it further if the model chosen has a higher complexity, besides that the estimation approach used can still be expanded in terms of statistical view. In the case that the data provided in time series do not change much or instead have drastic changes, such as accumulating at a certain time, the resulting ℛt value will show the same spikes and serrations. As a result, the latest information from data dynamics can be more elaborated.
By applying the method to COVID-19 cases in the Scandinavian countries and comparing the results to commonly used methods due to10 and11, we showed that our model is comparable, which expectedly will allow for fast assessment of the reproduction number in new outbreaks. Using the method to forecast and critically assess incidence data in countries with high under-reporting, such as Indonesia, is addressed for future work.
Data and Code Availability
Data and codes can be found here: https://github.com/agusisma/covid19
Author contributions statement
A.H. proposed the method and written the codes, H.S., V.T., R.K., E.P., P.H., and N.N. analysed the data, compared the method, and discussed the results. All authors reviewed the manuscript.
Competing interests
The authors declare no competing interests.
Acknowledgements
This work was supported by National Research and Innovation Agency (BRIN), project number 133/FI/P-KCOVID-19 2B3/IX/2020, 835/IT1 B07/KS.00.00/2020. RK gratefully acknowledgement financial support from Riset Peningkatan Kapasitas ITB 2020.
References



