
Abstract
Background During the COVID-19 epidemic, governments around the world have implemented unprecedented non-pharmaceutical measures to control its spread. As these measures carry significant economic and humanitarian cost, it is an important topic to investigate the efficacy of different policies and accurately project the future spread under such said policies.
Methods We developed a novel epidemiological model, DELPHI, based on the established SEIR model, that explicitly captures government interventions, underdetection, and many other realistic effects. We estimate key biological parameters using a meta-analysis of over 190 COVID-19 research papers and fit DELPHI to over 167 geographical areas since early April. We extract the inferred government intervention effect from DELPHI.
Findings Our epidemiological model recorded 6% and 11% two-week out-of-sample Median Absolute Percentage Error on cases and deaths, and successfully predicted the severity of epidemics in many areas (including US, UK and Russia) months before it happened. Using the extracted government response, we find mass gathering restrictions and school closings on average reduced infection rates the most, at 29.9 ± 6.9% and 17.3 ± 6.7%, respectively. The most stringent policy, stay-at-home, on average reduced the infection rate by 74.4 ± 3.7% from baseline across countries that implemented it. We also further show that a reversal of stay-at-home policies in some countries, such as Brazil, could have disastrous results by end of July.
Interpretation Our findings highlight that among the widely implemented policies around the world, mass gathering restrictions and school closings appear to be the most effective policies in reducing the infection rate. Given the continued spread of the epidemic in many countries, we recommend these policies to continue to the extent that they can be feasibly implemented. Our results also show that under an assumption of R0 of 2.5-3 for COVID-19, stay-at-home policies appear to be the only effective policy that was widely implemented in reducing the R0 below 1. This implies that stay-at-home policies might be necessary, for at least the vulnerable population, if an uncontrolled second wave reemerges.
Research in Context
Evidence before this study
Evidence before this study Previous research into COVID-19 has focused on reporting estimates of epidemiological parameters of COVID-19. We conducted an extensive literature search on PubMed and MedRXiv including keywords such as “non-pharmaceutical interventions” and “government interventions”. We discovered some studies reporting on the theoretical effect of non-pharmaceutical interventions in a theoretical modeling framework. There have also been a few published studies reporting on the overall effect of government interventions in the very early stages of the epidemics in various regions, such as the United States and Europe. However, there were few studies that tried to quantify the effect of each policy that was implemented, and none that the authors know of that are conducted on the global scale of this paper.
Added value of this study
Added value of this study As governments continue to implement non-pharmaceutical interventions, we aim to understand the effect of different policies that have been implemented in the past. We developed a novel epidemiological model that has been continuously providing high accuracy forecasts since early April. It also provides global estimates for the effects of different policies as they have been implemented across 167 areas. The large number of areas we consider enable us to derive inference for many popular policies that have been implemented, including mass gathering restrictions, school closures, along with travel and work restrictions.
Implications of all the available evidence
Implications of all the available evidence The evidence indicates that mass gathering restrictions were the most effective single policy in reducing the spread of COVID-19, followed by school closings. Stay-at-home policies greatly reduced the effective R0 and most likely enabled the effective control of the epidemics in many regions. Policy simulations suggest that many countries around the world are not yet suitable for a loosening of policy guidance, or there would be potentially severe humanitarian costs.
1. Introduction
Currently, the world is facing the deadliest pandemic in recent history - COVID-19. As of June 7th, there have been over 7.0 million confirmed cases of COVID-19 and the disease has taken over 400,000 lives. To stop the further spread of COVID-19, governments around the world have enacted some of the most wide-ranging non-pharmaceutical interventions in history. These interventions, especially the more severe ones, carry significant economic and humanitarian cost. Thus, it is critical to understand the effectiveness of such interventions in limiting disease spread.
However, there are many challenges in attempting to understand the effect of government interventions in a specific region or country. Different regions have implemented, often concurrently, a variety of different policies, and worse, even the same interventions could produce largely different effects in different societies, due to differences in factors such as demographics, population density, and culture.
Thus, in order to provide a sensible analysis of the effect of policies across different countries, in early April we created a novel epidemiological model, DELPHI, to model the spread of COVID-19. DELPHI (Differential Equations Lead to Predictions of Hospitalizations and Infections) extends a classic SEIR model to include many realistic effects that are critical in this pandemic, including deaths and underdetection. Specifically, we included an explicit nonlinear multiplicative factor on the infection rate to model the spread as it happened in different regions. Such explicit characterization of government intervention allows us to understand the effect of different non-pharmaceutical interventions as they have been implemented in various regions while accounting for regional population characteristics including baseline infection rate and mortality rate. Furthermore, we formulated DELPHI with data scarcity as a key consideration.
The aforementioned innovations have allowed DELPHI to produce relatively accurate projections even during the early stages of the epidemic. A major hospital system in the United States planned its intensive care unit (ICU) capacity based on our forecasts. Our epidemiological predictions are used by a major pharmaceutical company to design a worldwide vaccine distribution strategy that can contain future phases of the pandemic. They have also been inorporated into the US Center for Disease Control’s core ensemble forecast. [1]
DELPHI has been applied to 167 geographic areas (countries/provinces/states) worldwide, covering all 6 populated continents. Its results and insights have also been available since early April on www.covidanalytics.io. In this paper, we document the statistical innovations, quantitative results, and insights extracted from the DELPHI model.
2. Methods
2.1. The DELPHI Model
The DELPHI model is a compartment epidemiological model that extends the classic SEIR model into 11 states under the following 8 groups:
Susceptible (S): People who have not been infected.
Exposed (E): People currently infected, but not contagious and within the incubation period.
Infected (I): People currently infected and contagious.
Undetected (UR) & (UD): People infected and self-quarantined due to the effects of the disease, but not confirmed due to lack of testing. Some of these people recover (UR) and some die (UD).
Detected, Hospitalized (DHR) & (DHD): People who are infected, confirmed, and hospitalized. Some of these people recover (DHR) and some die (DHD).
Detected, Q,!arantine (DQR) & (DQD): People who are infected, confirmed, and home-quarantined rather than hospitalized. Some of these people recover (DQR) and some die (DQD).
Recovered (R): People who have recovered from the disease (and assumed to be immune).
Deceased (D): People who have died from the disease.
In addition to main functional states, we introduce auxiliary states to calculate a few useful quantities: Total Hospitalized (TH), Total Detected deaths (DD) and Total Detected Cases (DT). The full mathematical formulation of the model with all the differential equations can be found in the attached Supplementary Materials.
Figure 1a depicts a flow representation of the model, where each arrow represents how individuals can flow between different states. The underlying differential equations are governed by 11 explicit parameters which are shown on the appropriate arrows in Figure 1a and defined below. To limit the amount of data needed to train this model, only the parameters denoted with a tilde are being fitted against historical data for each area (country/state/province); the others are largely biological parameters that are fixed using available clinical data from a meta-analysis of over 190 papers on COVID-19 available at time of model creation. [2] A small selection of references for each parameter is given below.
 is the baseline infection rate.
is the baseline infection rate.γ (t) measures the effect of government response and is defined as:
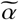

 where the parameters
where the parameters  and
and  capture, respectively, the timing and the strength of theresponse. The effective infection rate in the model is
capture, respectively, the timing and the strength of theresponse. The effective infection rate in the model is 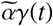 , which is time dependent.
, which is time dependent.
rd is the rate of detection. This equals to
, where Td is the median time to detection (fixed to be 2 days). [3]β is the rate of infection leaving incubation phase. This equals to
, where Tβ is the median time to leave incubation (fixed at 5 days). [4]σ is the rate of recovery of non-hospitalized patients. This equals to
, where Tσ is the median time to recovery of non-hospitalized patients (fixed at 10 day). [5, 6]κ is the rate of recovery under hospitalization. This equals to
, where Tκ is the median time to recovery under hospitalization (fixed at 15 days). [7, 8]- is the rate of death. This captures the speed at which a dying patient dies, and thus inversely proportional to how long a dying patient stays alive.
- is the mortality percentage. This is the percentage of people who die from the disease in a particular region. Note this quantity is independent from the rate of death.
pd is the (constant) percentage of infectious cases detected. This is set to 20%. [3, 9, 10] (
ph is the (constant) percentage of detected cases hospitalized. This is set to 15%. [11, 12]
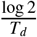
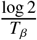
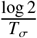
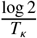
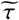
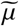
Therefore, we fit on 5 parameters from the list above 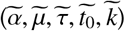 . In addition, we introduce two additional parameters
. In addition, we introduce two additional parameters 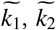 to account for the unknown initial population in the infected and exposed (E) states (see Supplementary Materials for details). We thus fit seven parameters per area.
to account for the unknown initial population in the infected and exposed (E) states (see Supplementary Materials for details). We thus fit seven parameters per area.
The parameters are fitted by minimizing a weighted Mean Squared Error (MSE) metric with respect to the parameters. Define DT (t) and DD(t) as the number of reported total detected cases and detected deaths, respectively, on day t. Then, the loss function for a training period of T days is defined as:
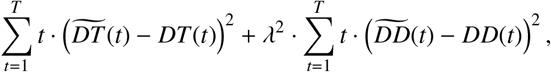 where
where 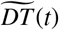 and
and 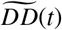 are respectively the total detected cases and deaths predicted by DEL-PHI. The factor t gives more prominence to more recent data, as recent errors are more likely to propagate into future errors. The lambda factor
are respectively the total detected cases and deaths predicted by DEL-PHI. The factor t gives more prominence to more recent data, as recent errors are more likely to propagate into future errors. The lambda factor 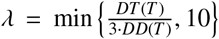 balances the fitting between detected cases and deaths; this re-scaling coefficient was obtained experimentally. We only include historical data starting when the area recorded more than 100 cases; this allows us to exclude sporadic outbreaks that are not epidemics. Non-convex optimization methods, including trust-region methods [13] and the Nelder-Mead method [14], are utilized to carry out the process of minimization.
balances the fitting between detected cases and deaths; this re-scaling coefficient was obtained experimentally. We only include historical data starting when the area recorded more than 100 cases; this allows us to exclude sporadic outbreaks that are not epidemics. Non-convex optimization methods, including trust-region methods [13] and the Nelder-Mead method [14], are utilized to carry out the process of minimization.
In the following subsections, we will detail the three key characteristics of the DELPHI model compared to the standard SEIR formulation.
2.1.1. Accounting for Under-detection
In the COVID-19 crisis, one of the key modeling difficulties is the chronic underdetection of confirmed cases. This is both due to the lack of detection abilities in the early stages of the pandemic and also the similarity between a mild case of COVID-19 and the common flu. Thus, to account for such significant effect, we explicitly included the UR/UD states to model people who actually contracted COVID-19 (and are infectious), but were not detected. In particular, we assume that only pd of the total number of the cases were detected, while 1 − pd of the total cases flow to the UR/UD states. There are two methods to gain information on the detection rate: treating pd as a parameter and fit to the historical data, or recover pd from serological evidence. However, both methods were impractical during the creation of this model. In an early to mid stage pandemic, a wide range of detection percentages are consistent with the data but leads to vastly different predictions (see e.g. [15]), so historical data could not provide strong evidence. Furthermore, at the time of redaction, the serological data were largely limited to specific sub-areas such as cities and counties (see [16, 17, 18, 19] for examples), while region-wide surveys were largely limited to a few European countries (see [20, 21] for examples and discussion) and only very sparsely available around the world.
Thus, we instead fix the detection percentage to be 20% based on various reports trying to understand the extent of underdetection in countries with earlier outbreaks [3, 9, 10]. More recently, an independent study [22] has corroborated our assumption in the United States.
2.1.2. Separation of Recovery and Deaths
A large focus in many governments’ response to the COVID-19 pandemic is to minimize the number of deaths, and thus in DELPHI, we included a death state. In most epidemiological models that extend to include the death state (see e.g. [3, 23] for COVID-19 modeling examples), the death state (D) is shown to flow from the same active infectious state as the recovery state (R), with a schematic shown in Figure 1b. However, this modeling approach would cause the mortality percentage 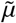 to be dependent on the rates of recovery and death (details are available in the Supplementary Materials). Thus, to resolve such mismatch, we explicitly separated out the
to be dependent on the rates of recovery and death (details are available in the Supplementary Materials). Thus, to resolve such mismatch, we explicitly separated out the 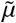 fraction of the population infected that would eventually die (ID) from the
fraction of the population infected that would eventually die (ID) from the 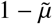 fraction that would recover (IR), as illustrated in Figure 1c.
fraction that would recover (IR), as illustrated in Figure 1c.
This allows the mortality rate 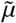 to be independent from the rates of death and recovery. The final DELPHI model further differentiated the IR states into hospitalized (DHR), quarantined (DQR), and undetected (UR) states to account for the different treatments people received, and similarly with the ID states.
to be independent from the rates of death and recovery. The final DELPHI model further differentiated the IR states into hospitalized (DHR), quarantined (DQR), and undetected (UR) states to account for the different treatments people received, and similarly with the ID states.
2.1.3. Modeling Elfect of Increasing Government Response
One of the key assumptions in the standard SEIR model is that the rate of infection α is constant throughout the epidemic. However, in real epidemics such as the COVID-19 crisis, the rate of infection starts decreasing as governments respond to the spread of epidemic, and induce behavior changes in societies. To account for such effect, we model the effect of government measures with a sigmoid-like function γ(t) (specifically the inverse tangent).
The concave-convex nature of an arctan curve models three phases: The early, concave part of the arctan models limited changes in behavior in response to early information, while most people continue business-as-usual activities. The transition from the concave to the convex part of the curve quantifies the sharp decline in infection rate as policies go into full force and the society experiences a shock event. The latter convex part of the curve models a flattening out of the response as the government measures reach saturation, representing the diminishing marginal returns in the decline of infection rate. An illustration of such three phases is included in the Supplementary Materials.
Parameters 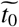 and
and 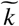 control the timing of such measures and the rapidity of their penetration. This formulation allows us to model, under the same framework, a wide variety of policies that different governments impose, including social distancing, stay-at-home policies, quarantines, etc. This modeling captures the increasing force of intervention in the early-mid stages of the epidemic. In Section 3.3, we would show how this model can be extended to provide insights on the relaxation of measures.
control the timing of such measures and the rapidity of their penetration. This formulation allows us to model, under the same framework, a wide variety of policies that different governments impose, including social distancing, stay-at-home policies, quarantines, etc. This modeling captures the increasing force of intervention in the early-mid stages of the epidemic. In Section 3.3, we would show how this model can be extended to provide insights on the relaxation of measures.
3. Results and Discussion
3.1. Forecasting Results
DELPHI was created in early April and has been continuously updated to reflect new observed data. Figures 2a and 2b show our projections of the number of cases in Russia and the United Kingdom made on three different dates, and compare them against historical observations. They suggest that DELPHI achieves strong predictive performance, as the model has been consistently predicting, with high accuracy, the overall spread of the disease for several weeks. Notably, DELPHI was able to anticipate, as early as April 17th, the dynamics of the pandemic in the United Kingdom (resp. Russia) up to May 12th. At a time when 100-110K (resp. 30-35K) cases were reported, the model was predicting 220-230K (resp. 225-235K) cases by May 12th—a prediction that became accurate a month later.

Furthermore, Table 1 reports the median Mean Absolute Percentage Error (MAPE) on the observed total cases and deaths in each area of the world using parameters obtained on April 28th, and evaluated on the 15 days period up until May 12th. Overall, our model seems to predict the epidemic progression relatively well in most countries with < 10% MAPE on reported cases, and < 15% MAPE on reported deaths. Additionally, the areas with the highest errors are often those that have the fewest deaths. This stems from the fact that DELPHI—like all SEIR-based models—is not designed to perform well on areas with small populations and interactions. The effect is further exacerbated by the choice of the metric, as MAPE inherently heavily penalizes errors on small numbers. Further detailed results for each country/region that we predict, and examples of areas with high MAPE, can be found in the Supplementary Materials.
Median country-level Mean Absolute Percentage Error (MAPE) of the predicted number of cases and deaths in each continent (projections made using data up to 04/27 for the period from 04/28 to 05/12).
3.2. Elfect of Government Interventions
A natural application of the DELPHI model is policy evaluation. For that, we can extract the normalized fitted government response curve γ(t) in each area, and utilize it to understand the impact of specific government policies that have been implemented. In particular, we aim to understand the average effect of each policy on γ(t) during the period of implementation. To this end, for all countries except US, we collect data from the Oxford Coronavirus Government Response Tracker for historical data on government policies [24], during the period between January 1st 2020, and May 19th 2020. For the US, we collect the policy data from the Institute for Health Metrics and Evaluation [25] during the same period.
At each point in time, we categorize the government intervention data based on whether they restrict mass gatherings, schools, travel and work activities. We group travel restrictions and work restrictions together due to their tendency to be implemented simultaneously. From January 1st to May 19th, the 167 areas in total implemented 5 combinations of such interventions. Specifically, these are: (1) No measure; (2) Restrict travel and work only; (3) Restrict mass gatherings, travel and work; (4) Restrict mass gatherings, schools, travel and work; and (5) Stay-at-Home. The detailed correspondence between raw policy data and our categories are contained in the Supplementary Materials. Other potentially feasible combinations were not implemented by the countries. Then for each policy category i = 1, …, 5, we extract the average value of 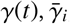 across all time periods and areas for which policy i was implemented. Then we calculate the residual fraction of infection rate under policy i, pi, compared to the baseline policy of no measure:
across all time periods and areas for which policy i was implemented. Then we calculate the residual fraction of infection rate under policy i, pi, compared to the baseline policy of no measure:
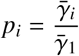 Table 2 shows the number of area-days that each policy was implemented around the world and its effect. We further report the standard deviation of such estimate treating each geographical area as an independent sample. We see that each selected policy was enacted for at least hundreds of Area-Days worldwide, while the stringent stay-at-home policy was cumulatively implemented the most. In particular, we see that mass gathering restrictions generate a large reduction in infection rate, with the incremental reduction between travel and work restrictions compared to mass gathering, travel, and work restrictions is 29.9 ± 6.9%. This is further supported by the large residual infection rate of 88. ± 9 4.5% when travel and work restrictions are implemented, but mass gatherings are allowed. Additionally, we observe that closing schools also generate a large reduction in the infection rate, with an incremental effect of 17.3 ± 6.6% on top of mass gathering and other restrictions. Stay-at-home orders produced the strongest reduction in infection rate across the different countries, with a residual infection rate of just 25.6 ± 3.7% compared to when no measure was implemented.
Table 2 shows the number of area-days that each policy was implemented around the world and its effect. We further report the standard deviation of such estimate treating each geographical area as an independent sample. We see that each selected policy was enacted for at least hundreds of Area-Days worldwide, while the stringent stay-at-home policy was cumulatively implemented the most. In particular, we see that mass gathering restrictions generate a large reduction in infection rate, with the incremental reduction between travel and work restrictions compared to mass gathering, travel, and work restrictions is 29.9 ± 6.9%. This is further supported by the large residual infection rate of 88. ± 9 4.5% when travel and work restrictions are implemented, but mass gatherings are allowed. Additionally, we observe that closing schools also generate a large reduction in the infection rate, with an incremental effect of 17.3 ± 6.6% on top of mass gathering and other restrictions. Stay-at-home orders produced the strongest reduction in infection rate across the different countries, with a residual infection rate of just 25.6 ± 3.7% compared to when no measure was implemented.
Implementation Length and Effect of each policy category as implemented across the world.
If COVID-19 has an average basic reproductive number R0 of 2.5-3 ([26, 27]), then on average, only the strongest measure (Stay-at-Home orders) are sufficient to control a COVID-19 epidemic in reducing R0 to be less than 1.
3.3. Extension: Evaluating Reopening Strategies
The DELPHI model provides insights into the effect of government policies through the residual infection rates pi under each policy.
A natural extension is to utilize the pi in creating what-if scenarios on the effect of lifting restrictions in different countries by reverting the effect of each policy on γ(t) at the time of the hypothetical policy relaxation. Specifically, suppose that we are considering a policy easing from policy i to j at time tc in some area. Then for all times t ≥ tc, we correct the government response as follows:
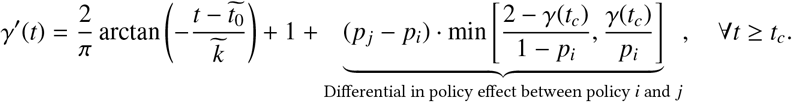 Essentially, we apply a correction term that is proportional to the fractional difference in policy effect between policy i and j (which is pj − pi > 0 as it is an easing). The multiplicative factor min
Essentially, we apply a correction term that is proportional to the fractional difference in policy effect between policy i and j (which is pj − pi > 0 as it is an easing). The multiplicative factor min 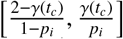 scales the fractional difference so that the resulting γ ′ (t) is constrained within the initial range [0, 2]. Then, we would replace γ (t) with γ ′(t) in the DELPHI model to forecast the epidemic under the updated policy. Using this correction factor, we predict what would happen in different areas under various future policies. Figure 3 shows results for France and Brazil respectively, under policy change implemented on June 16th (four weeks after the last historical value on May 19th). Further results for other countries are contained in the Supplementary Material.
scales the fractional difference so that the resulting γ ′ (t) is constrained within the initial range [0, 2]. Then, we would replace γ (t) with γ ′(t) in the DELPHI model to forecast the epidemic under the updated policy. Using this correction factor, we predict what would happen in different areas under various future policies. Figure 3 shows results for France and Brazil respectively, under policy change implemented on June 16th (four weeks after the last historical value on May 19th). Further results for other countries are contained in the Supplementary Material.

We observe different levels of risk for the same re-opening strategies across different countries. For example, Figure 3c predicts that loosening measures in Brazil on June 16th would result in a second wave of infections with up to 6.8 million additional cases by July 15th, while even a stay-at-home order would lead to almost 1.9 million additional cases. Such alarming numbers can be understood through Figure 3d where we compute a rolling average of the weekly incidence of cases per 100K people. We can see that Brazil is still on a steep ascending curve, and that any kind of loosening could be catastrophic. Such behaviour stands in sharp contrast with France’s situation. Figure 3b demonstrates that the peak has long passed in France and the epidemic has mostly died out. Thus, as we can see in Figure 3a, loosening policies (like France has already started doing) is likely to only minimally affect the number of infections.
To further understand the disparate impact of the policies across countries, we made predictions for the situation around the world assuming a policy that involves mass gathering, travel, and work restrictions was universally implemented on 06/16. Figure 4a shows three clusters of countries for July 15th:

Countries with a small number of cumulative cases (relative to the population), and that are in a late stage of the pandemic with relatively few new cases, such as Greece, Japan, Morocco and Venezuela.
Countries with a large number of cumulative cases, but that are in a late stage of the pandemic, with relatively few new cases, mainly in Western and Northern Europe (e.g. the United Kingdom, Italy, France and Finland).
Countries where the pandemic has had a large impact with a large number of cumulative cases, and where the situation will still be worsening at an alarming rate. These include the United States, India and Brazil. A close-up of these countries is presented in Figure 4b, where we see that DELPHI predicts Brazil would be severely hit by July, with up to 8% of the entire population infected, if the hypothetical policy above is implemented. This suggests that in these countries, such hypothetical policy could be inadequate for controlling the epidemic, and a stronger policy (such as Stay-at-Home orders) is needed.
4. Limitations
One fundamental limitation of this analysis is its observational nature. Thus, despite the flexible parameters in DELPHI accounting for many state-dependent effects, there are many other potential confounders and second-order effects that could affect this analysis. For example, one effect that is not considered in DELPHI is a time-varying mortality rate caused by changing treatment procedures designed to best help COVID-19. Including such effect could sharpen the analysis further, though at the expense of increased fitting difficulty and data requirements.
This analysis also assumes, in analyzing government interventions, that the same nominal policy (e.g. Mass gathering restrictions) could be compared across countries. In reality, different countries have implemented variants (though largely similar) of restrictions under the same name, and this could further impact the validity of the analysis.
In the reopening analysis, we have assumed that the effect of government interventions imposed at the start of the epidemic is indicative of the effect when it is removed. This is potentially affected by a permanent change in social behavior during the epidemic. For example, if a significant portion of the population adapts social distancing measure even after the official restrictions are lifted, this could lead to a smaller resurgence of infections than what is predicted in the analysis.
5. Conclusions
We introduced DELPHI, a novel epidemiological model that extended SEIR to include many realistic effects critical in this pandemic. DELPHI was able to accurately predict the spread of COVID-19 in many countries, and aid planning for many organizations worldwide. Furthermore, the explicit modeling on government intervention allowed us to understand the effect of government interventions, and help inform how societies could reopen.
Data Availability
All data used in this paper is available at the DELPHI repository hosted on github.
https://github.com/CSSEGISandData/COVID-19
https://covid19.healthdata.org/united-states-of-america
https://www.bsg.ox.ac.uk/research/research-projects/coronavirus-government-response-tracker
Funding
None.
Footnotes
M.L.L, H.T.B, O.S.L, T.A.T, N.K.T, D.B designed the study, M.L.L, H.T.B, O.S.L acquired data, carried out analysis and formulated the results. M.L.L, H.T.B, O.S.L, T.A.T, N.K.T, D.B wrote the manuscript.




{kind=link}
{kind=link}
{kind=link}
{kind=link}