
Abstract
Background SARS-CoV-2 is straining healthcare systems globally. The burden on hospitals during the pandemic could be reduced by implementing prediction models that can discriminate between patients requiring hospitalization and those who do not. The COVID-19 vulnerability (C-19) index, a model that predicts which patients will be admitted to hospital for treatment of pneumonia or pneumonia proxies, has been developed and proposed as a valuable tool for decision making during the pandemic. However, the model is at high risk of bias according to the Prediction model Risk Of Bias ASsessment Tool and has not been externally validated.
Methods We followed the OHDSI framework for external validation to assess the reliability of the C-19 model. We evaluated the model on two different target populations: i) 41,381 patients that have SARS-CoV-2 at an outpatient or emergency room visit and ii) 9,429,285 patients that have influenza or related symptoms during an outpatient or emergency room visit, to predict their risk of hospitalization with pneumonia during the following 0 to 30 days. In total we validated the model across a network of 14 databases spanning the US, Europe, Australia and Asia.
Findings The internal validation performance of the C-19 index was a c-statistic of 0.73 and calibration was not reported by the authors. When we externally validated it by transporting it to SARS-CoV-2 data the model obtained c-statistics of 0.36, 0.53 (0.473-0.584) and 0.56 (0.488-0.636) on Spanish, US and South Korean datasets respectively. The calibration was poor with the model under-estimating risk. When validated on 12 datasets containing influenza patients across the OHDSI network the c-statistics ranged between 0.40-0.68.
Interpretation The results show that the discriminative performance of the C-19 model is low for influenza cohorts, and even worse amongst COVID-19 patients in the US, Spain and South Korea. These results suggest that C-19 should not be used to aid decision making during the COVID-19 pandemic. Our findings highlight the importance of performing external validation across a range of settings, especially when a prediction model is being extrapolated to a different population. In the field of prediction, extensive validation is required to create appropriate trust in a model.
Introduction
Background and objectives
The novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) virus, also known as COVID-19, is quickly spreading throughout the world and burdening healthcare systems worldwide [1]. Numerous prediction models have started to be developed and released to the public to aid decision making during the pandemic [2]. Many of these models aim to inform people of their risk of developing severe outcomes due to COVID-19 [3-5]. A recent systematic review found all then-published models suffer from high risks of bias along with one or more limitations, including small datasets used to develop the models and lack of external validation.[2]
The COVID-19 vulnerability (C-19) index [5] is an example of a model developed to identify people susceptible to severe outcomes during COVID-19 infection. The model is potentially valuable because it aims to predict the hospitalization risk in the general population [2]. The model publication is currently available as a preprint and the model is publicly available at the website http://c19survey.closedloop.ai. The C-19 index aims to predict which patients will require hospitalization due to pneumonia (or proxies for pneumonia) within 3 months. The model was developed using retrospectively collected Medicare data (patients aged 65 or older) that do not contain COVID-19 patients. There is, however, no guarantee that a model trained on non-COVID-19 Medicare patients will perform similarly or even adequately in COVID-19 patients. Moreover, no external validation of the model was presented in the model development paper. Research has shown that there is high risk of bias for a model that lacks external validation [6]. In addition, it is recommended that knowledge of model reproducibility and transportability is assessed before a model is used clinically [7]. Models must be reliable as poor predictions can hurt decision making [2].
The Observational Health Data Science and Informatics (OHDSI) collaboration is a group of researchers collaborating to develop best practices for analyzing observational healthcare data [8]. OHDSI has developed a framework that enables timely validation of prediction models across a large number of datasets from around the globe [9]. The OHDSI network currently contains large COVID-19 cohorts from the US, Europe and Asia. In this study we aim to demonstrate the importance of performing external validation before we can trust a model’s predictions. As a case study we chose to investigate the predictive performance of the C-19 index when applied to COVID-19 data from across the world. This study can inform us about the suitability of utilizing the C-19 model to aid decision making during the COVID-19 pandemic.
Methods
Three models were developed in the C-19 index publication [5]. The simplest model was a logistic regression with a limited number of predictors: age, sex, hospital usage, 11 comorbidities and their age interactions. The two other models were less parsimonious gradient boosting machines with more than 500 variables. Only one of these gradient boosting machine models was reported. Withholding a model makes it non-compliant with the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) statement [10] and makes external validation impossible. In this paper we chose to evaluate the simple logistic regression model, recognizing that COVID-19 prediction models are urgently needed worldwide, and parsimonious models are more readily implemented across healthcare settings.
Source of data
Electronic medical records (EMR) and administrative claims databases from primary care and secondary care containing patients from Australia, Japan, Netherlands, Spain, South Korea, and the US were analyzed in a distributed network, and are detailed in the Supplementary Appendix, Table S1. Five datasets contained COVID-19 cases and nine datasets did not. All datasets used in this paper were mapped into the OHDSI Observational Medical Outcomes Partnership Common Data Model (OMOP-CDM) [11]. The OMOP-CDM was developed to enable researchers with diverse datasets to have a standard database structure. This enables analysis code and software to be shared among researchers which facilitates external validation of prediction models. De-identified or pseudonymised data were obtained from routinely collected records from clinical practice. Analyses were performed using the following databases: AU-ePBRN (linked primary and secondary care from Australia); JMDC (Japanese claims); IPCI (primary care EMR from The Netherlands); SIDIAP (primary care EMR from Spain); AUSOM and HIRA (EMR and claims from South Korea); CCAE, ClinFormatics, MDCR, MDCD (US claims), Optum EHR, Veteran Affairs (VA), CUIMC and TRDW (EMRs for the US). All analyses were conducted locally in a distributed network, where analysis code was sent to participating sites and only aggregate summary statistics were returned, with no sharing of patient-level data between organizations.
Consent to publish
Each site obtained institutional review board (IRB) approval for the study or used de-identified data, and therefore the study was determined not to be human subjects research. Informed consent was not necessary at any site.
Participants
The purpose of the C-19 index is to identify which COVID-19 patients are more likely to require hospitalization due to severe complications. Therefore, we investigated the model performance when applied to patients at an outpatient (OP) or emergency room (ER) visit who have either i) COVID-19 positive test or diagnosis (in databases with COVID-19 data) or ii) influenza or influenza-like symptoms (in databases without COVID-19 data, as a proxy for COVID-19) and no recent prior symptoms or pneumonia. We chose this approach as it mimics the situation where patients first seek treatment or medical advice due to developing symptoms or testing positive for COVID-19 (or influenza).
For external validation in COVID-19 data we defined a cohort of patients presenting at an initial healthcare provider interaction during an OP/ER visit with COVID-19 disease. COVID-19 disease was identified by a diagnosis code for SARS-COV-2 or a positive test for the SARS-COV-2 virus that was recorded after January 1st 2020. We required patients to be aged 18 or over, to have at least 365 days of observation time prior to the index date and to have no diagnosis of influenza, influenza-like symptoms, or pneumonia in the preceding 60 days.
For the influenza validation, we identified patients aged 18 or older with an OP/ER visit with influenza or influenza-like symptoms (i.e. fever and either cough, shortness of breath, myalgia, malaise, or fatigue), at least 365 days of prior observation, and no diagnosis of influenza, influenza-like symptoms, or pneumonia in the preceding 60 days.
Outcome
The outcome was hospitalization with pneumonia on the index date (valid OP/ER visit) and within 30 days after index.
Appendix A contains the definitions for pneumonia, influenza, influenza-like symptoms and COVID-19 used in this study. The full details of the target population cohorts and outcomes used for validation can be found in the study package.
Predictors
The predictors of the logistic regression version of the C-19 index are age in years, male sex, number of inpatient visits during the prior 12 months and indicator variables for various Clinical Classifications Software Refined (CCSR) categories. A table with the C-19 predictors and coefficients is presented in Appendix B. The CCSR categories used were pneumonia except that caused by tuberculosis, other and ill-defined heart disease, heart failure, acute rheumatic heart disease, coronary atherosclerosis and other heart disease, pulmonary heart disease, chronic rheumatic heart disease, diabetes mellitus with complication, diabetes mellitus without complication, chronic obstructive pulmonary disease and bronchiectasis, other specified and unspecified lower respiratory disease. Age interactions with each CCSR variable were also included as predictors. Each CCSR category corresponds to an aggregation of ICD-10 codes that belong to the category.
In the development data, if a patient had an ICD-10 code that was part of the CCSR ‘pneumonia except that caused by tuberculosis’ grouping during a specified time period prior to index their value for the predictor ‘pneumonia except that caused by tuberculosis’ was 1 and 0 otherwise. This was repeated for each CCSR predictor. Data in the OMOP-CDM do not use ICD-10 codes, but instead use Systematized Nomenclature of Medicine (SNOMED) codes. Therefore, to replicate the predictors in the OMOP-CDM data we needed to find the sets of SNOMED codes that correspond to each CCSR predictor. We accomplished this by finding the SNOMED equivalent of each ICD-10 code in a CCSR category.
The SNOMED groupings per CCSR category used by the OHDSI implementation of the C-19 are presented in Appendix B.
Sample Size
We identified 41,381 patients with an OP/ER visit for COVID-19 in 2020: 1,985 patients from South Korea, 37,950 patients from Spain and 1,446 patients from the US. We also identified a total of 9,429,285 patients with an OP/ER visit for influenza or influenza-like symptoms in databases from 6 countries. The number of visits for influenza or influenza-like symptoms per database ranged between 2,793 to 3,146,801.
Missing Data
The prediction models used a cohort design that includes any patient that satisfies the inclusion criteria. We did not exclude patients who are lost to follow-up during the 30-day period after the valid OP/ER visit.
Statistical analysis methods
The model performance was evaluated using the standard discriminative metrics: area under the receiver operating characteristic (AUROC) curve (equivalent to the c-statistic) and area under the precision recall curve (AUPRC). The latter is a useful addition to the AUROC when assessing rare outcomes [12]. The calibration was determined by creating deciles based on the predicted risk and plotting the mean predicted risk versus the observed risk in each decile. If a model is well calibrated, then the mean predicted risk will be approximately equal to the observed risk for each decile.
We follow the TRIPOD statement guidelines [10] for reporting the model validation throughout this paper. For transparency an open source package for implementing the model on any OMOP-CDM data is available at https://github.com/ohdsi-studies/Covid19PredictionStudies/tree/master/CovidVulnerabilityIndex.
Development vs. validation
The differences between the C-19 model development settings and the validation settings include a different target population and different datasets. Our validation design settings were chosen to mimic the COVID-19 situation when a clinician needs to decide whether to admit a patient. Importantly, we validated the C-19 model on COVID-19 patients.
The C-19 index was developed using a cohort design that entered adult patients into the cohort on 9/30/2016 and predicted whether they would be hospitalized for pneumonia or proxies (influenza, acute bronchitis, or other specified upper respiratory infections) in the following 3 months. Patients must have been in the data for 6 or more months and patients who left the database within 3 months of index and did not have death recorded were excluded. In our external validation we used a cohort design but entered adult patients into the cohort when they had an initial OP/ER visit for influenza (or COVID-19) rather than a fixed date and predicted hospitalization due to pneumonia in 30 days rather than 3 months. We excluded patients with influenza or pneumonia within the 60 days prior to index to restrict to initial visits. This mimics the situation during the COVID-19 pandemic where clinicians need to decide whether to hospitalize a patient initially presenting with COVID-19. We required 12 months of prior observation and did not exclude patients who left the database within 3 months of index.
The C-19 index was developed using a subset of patients from the Medicare database prior to the pandemic. This is a US claims database containing patients aged 65 or older. In this study we were able to externally evaluate the C-19 model on COVID-19 data, including adult patients under 65 years of age, from South Korea, Spain and the US.
Results
Online results
The complete results are available as an interactive app at:
http://evidence.ohdsi.org/C19validation
The characteristics of the MDCR data (same data source as the development data but different patient subset) and the HIRA, SIDIAP and VA data (COVID-19 patients) are displayed in Table 1. The characteristics for all datasets used in the study are available in Appendix C.
Characteristics of patients at baseline in MDCR (database similar to development data) and the datasets with COVID-19 data. * indicates censoring due to a low cell count.
Model performance
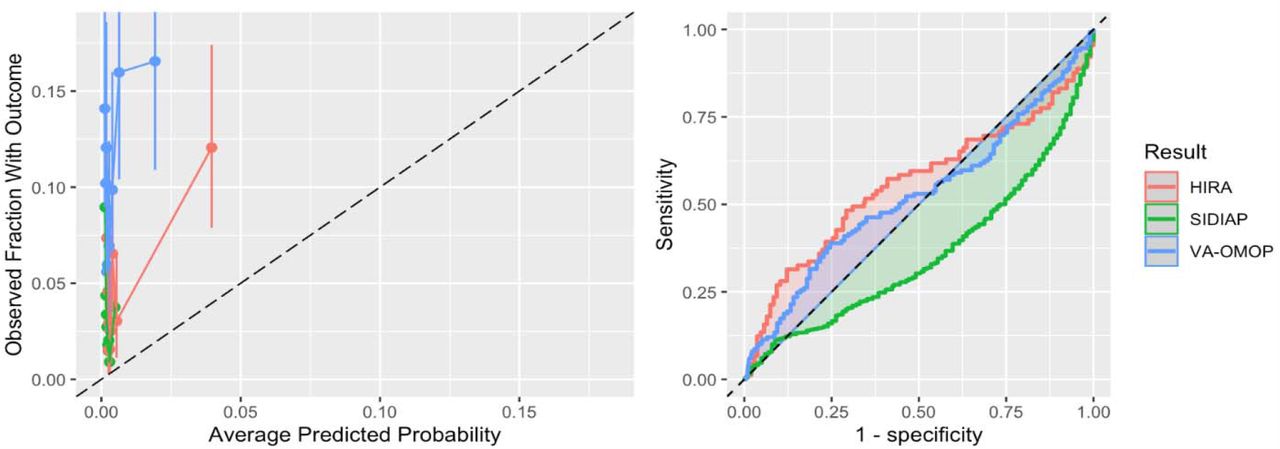
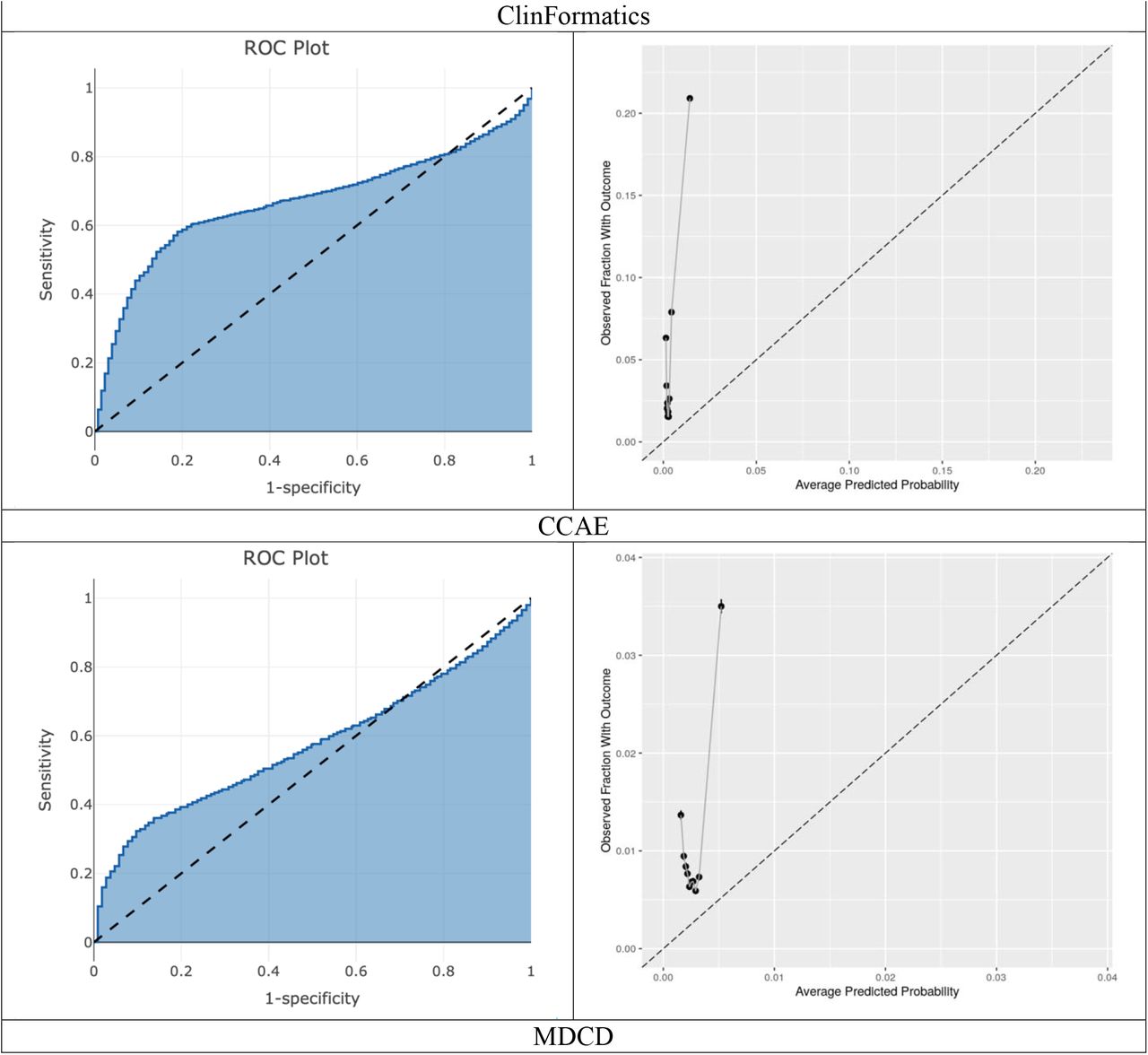
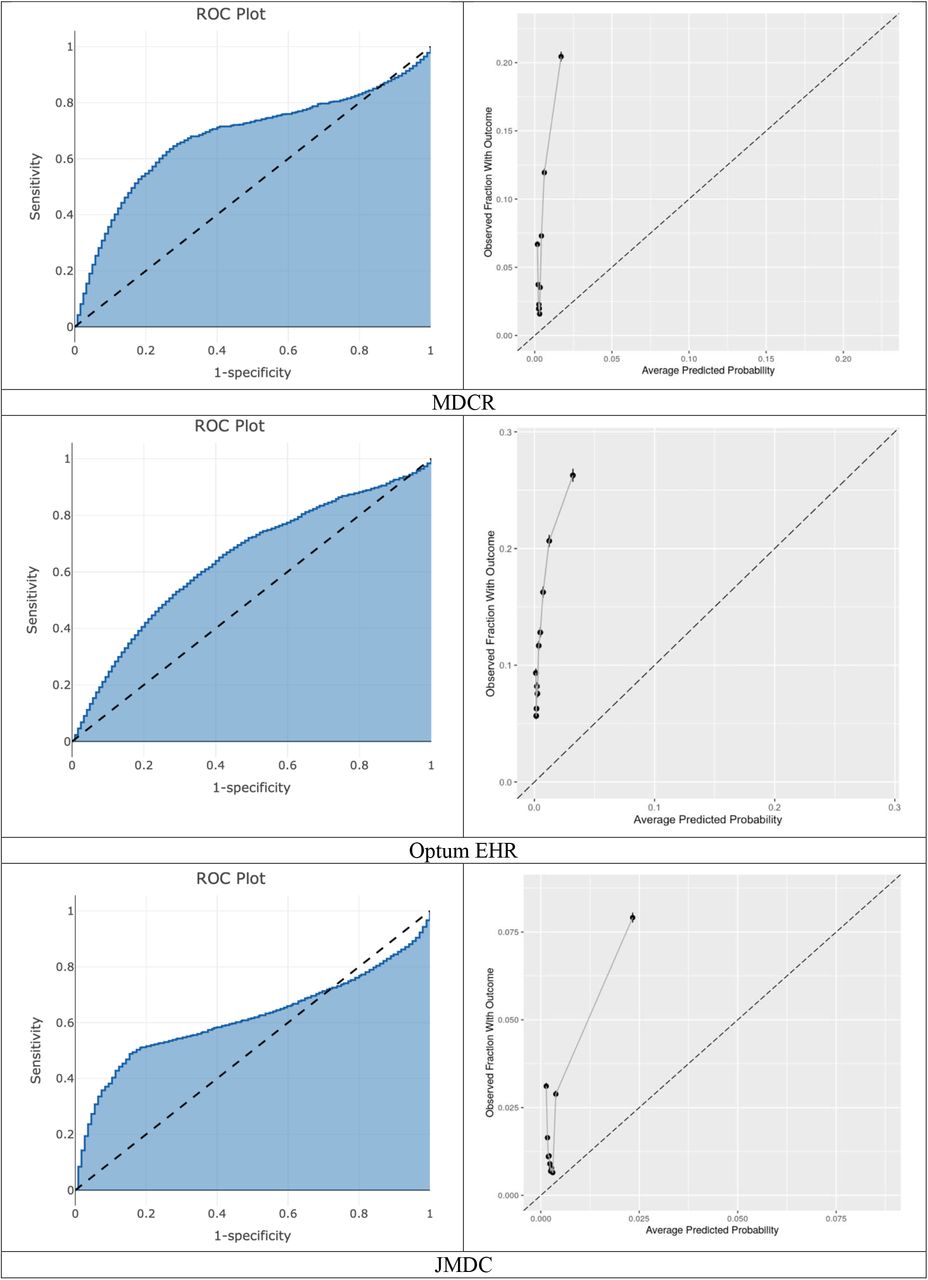
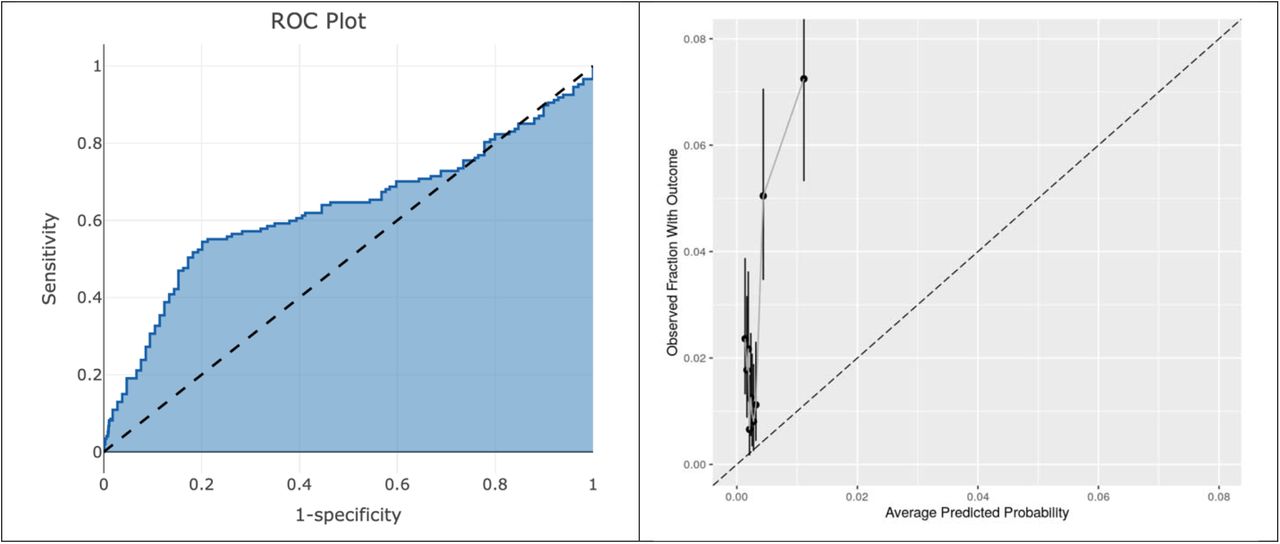
When C-19 was transported to COVID-19 patients it achieved AUROCs between 0.36-0.56, full details are available in Table 2. The AUROC and calibration plots are presented in Figure 1. The internal discriminative performance of the C-19 index was with an AUROC of 0.73. When we validated the model on MDCR patients, but with our target population consisting of symptomatic influenza patients, the performance was 0.65, a significant drop from the 0.73 development performance. The AUROC performance when externally validated to other databases containing influenza patients ranged between 0.40-0.68. Full results are presented in Table 3, and AUROC and calibration plots are presented in Appendix D. As a sensitivity analysis we also validated the C-19 index on a target population consisting of patients with COVID-19 or symptoms during 2020, the results were similar and are presented in Appendix E.
External validation of the C-19 model on COVID-19 data. * The 95% CI is reported when the outcome count is less than 1000.
External validation of the C-19 model on influenza patient data. * The 95% CI is reported when the outcome count is less than 1000.

Discussion
The C-19 index is available online as a tool to predict severity in patients with COVID-19; while lacking validation for this population. Our validation across three datasets with sufficient COVID-19 data showed poor discriminative performance (AUROCs <0.6) and calibration. We observed similarly poor performance when validated across twelve datasets with influenza patients, with best AUROCs <0.70.
Interpretation
The key finding of this study is the performance of the C-19 model when transported to COVID-19 patients. The model performance was poor (AUROCs 0.36-0.56) across the COVID-19 datasets. The performance was worse than random guessing in the SIDIAP data, which is consistent with the poor performance seen when applied to European patients with influenza. The calibration plots show that the C-19 index consistently underestimated risk in the COVID-19 patients.
The datasets used to perform the validation had very different patient populations. MDCR had the oldest patient population and many patients had comorbidities. Compared to MDCR, the CCAE and JMDC datasets presented healthier and younger patients (mean age around 40s) in the target population. While MDCD had younger patients these patients often had comorbidities (i.e. 20% these patients had COPD, 11% had heart failure and 17% has a history of pneumonia). The rate of hospitalization ranged greatly across the sites with values between 0.1% in JMDC and 12.4% in MDCR. The rate of the outcome in the dataset used to develop the C-19 index was 0.23%, much lower than in the MDCR data used to validate the model in this study. This is due to our study restricting to patients at the point they had an OP/ER visit due to influenza or COVID-19. Although five datasets contained COVID-19 patients, only four had sufficient data (VA, HIRA, SIDIAP and CUIMC) for external validation. The result of the C-19 when applied to COVID-19 patients in CUIMC was poor, <0.5 AUROC, however this dataset consisted mostly of hospitalized patients and therefore did not seem suitable for validating a model that predicts hospitalizations.
We chose a target population of symptomatic patients as this resembles the situation in which COVID-19 prediction models may be clinically implemented during the pandemic: clinicians likely would not admit asymptomatic patients. This suggests the internal C-19 AUROC estimate may be optimistic compared to if it were used in a realistic setting, due to the inclusion of many healthy patients. When applied to predict hospitalization in influenza patients across US data the performance ranged between 0.58-0.68. The performance was worse on the CCAE database with younger patients, likely due to age being a key predictor in the model. When the C-19 index was transported across non-US datasets the performance was poor to reasonable in the Australian and Asian data (0.52-0.64) and poor in the European data (0.4-0.49). The European data are extracted from general practice (GP) settings, but the C-19 model was developed using US claims data. Given the differences in clinical settings, it is not surprising that the performances were poor. This highlights that models often may not transport to different healthcare settings. The AUC of 0.36 when the C-19 model was validated in SIDIAP is worse than random guessing and inverting the predicted risk would lead to an AUC of 0.64. This may be a result of the C-19 including age interaction terms that resulted in the age coefficient being negative. Table 1 shows that in SIDIAP the model’s age interacting comorbidities are not as often recorded relative to the other databases. This may have resulted in younger patients being assigned higher risks than older patients in SIDIAP.
Implication
The results provide extensive insight into the performance of the logistic regression C-19 index when used for COVID-19. The external validation uncovered that the logistic regression C-19 model is unreliable when predicting hospitalization risk for COVID-19 patients. Given this result, we do not recommend using the logistic regression C-19 index to aid decision making during the COVID-19 pandemic. The model did not appear to transport to COVID-19 patients, highlighting the importance of externally validating models, especially models whose target population differs from the development population.
There are numerous potential reasons why the logistic regression C-19 model failed to predict hospitalization due to pneumonia in the COVID-19 patients investigated. First reason may be due to the model being developed on patients aged 65 or older but applied to patients aged 18 or older. Age had a negative coefficient in the model, so this may have caused issues when the model was applied to younger patients. A second reason may be due to incorrect phenotyping for the predictors. We matched the SNOMED codes to the CCSR ICD-10 codes provided, but the predictors may require database specific phenotypes due to coding differences across datasets and healthcare settings. This may explain the poor performance in the European datasets that may record things differently than the US. A third reason is the study design:C-19 was developed to predict hospitalization from a set date in 2016 but we validated in a target cohort of symptomatic patients with an OP/ER visit as this more closely matches the clinical use case of the model. This means we are likely to have a sicker population where discrimination may be more difficult. A fourth potential reason is that the C-19 model was developed using data prior to 2017 but was validated on data from 2020: temporal changes and concept drift may negatively impact performance. Although we do not know the reason for the unreliability of the C-19 model on COVID-19 patients, we were able to quantify it by large-scale external validation across a network of datasets. In future work it would be beneficial to develop techniques that can identify reasons for poor external validation performance, as this may inform new best practices for model development.
This study highlights the importance of performing extensive external validation across different settings. During times of uncertainty, such as during pandemics, medical staff who are under pressure to make important decisions could benefit from implementing vetted prediction models. However, it is important to gain an unbiased and reliable evaluation of a model’s performance across numerous patient populations before the model is used. Internal validation can often be biased (e.g., the population used the develop the model does not match the intended target population) and provide optimistic performance estimates (e.g., a poor design or small dataset may result in overestimated discriminative performance). The approach used by the OHDSI collaboration enables efficient external validation of models across multiple datasets and this is a valuable resource when urgency is required.
Limitations
A common issue when using observational healthcare data, especially across a network of databases, is the difficulty in developing phenotypes that are valid on all datasets. In this study we used predictor definitions given by the researchers who developed the model. However, these definitions may not transport across all the datasets and may account for some of the decrease in performance. We were also limited to validate the less complex C-19 model due to the large number of variables and lack of transparency for the more complex models.
Conclusion
We have demonstrated the importance of implementing external validation in multiple datasets to determine the reliability of prediction models. We picked a newly developed model, the C-19 index, that aimed to predict which COVID-19 patients are at risk of severe complications due to the virus. The model reported an internal AUC of 0.73 but was deemed as having a high risk of potential bias [2]. The C-19 index addresses an important issue that could have greatly aided decision making during the COVID-19 pandemic, but its performance in COVID-19 patients was unknown. Our results show that the C-19 index performs poorly when applied to newly diagnosed COVID-19 patients in Asia, Europe and the US. Overall, we suggest that the model currently only be used to predict hospitalization due to pneumonia in older patients in the US. The results of this study demonstrate that internal validation performance should be considered optimistic estimates and a prediction model requires validation across multiple datasets in the target population where it will be used (or a close proxy), before it should be trusted.
Data Availability
Data is not publicly available due to patient privacy concerns.
Funding
This project has received support from the European Health Data and Evidence Network (EHDEN) project. EHDEN received funding from the Innovative Medicines Initiative 2 Joint Undertaking (JU) under grant agreement No 806968. The JU receives support from the European Union’s Horizon 2020 research and innovation programme and EFPIA.
This work was also supported by the Bio Industrial Strategic Technology Development Program (20001234, 20003883) funded by the Ministry of Trade, Industry & Energy (MOTIE, Korea) and a grant from the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea [grant number: HI16C0992].
This project is funded by the Health Department from the Generalitat de Catalunya with a grant for research projects on SARS-CoV-2 and COVID-19 disease organized by the Direcció General de Recerca i Innovació en Salut.
The University of Oxford received a grant related to this work from the Bill & Melinda Gates Foundation (Investment ID INV-016201), and partial support from the UK National Institute for Health Research (NIHR) Oxford Biomedical Research Centre.
DPA is funded through a NIHR Senior Research Fellowship (Grant number SRF-2018-11-ST2-004). The views expressed in this publication are those of the author(s) and not necessarily those of the NHS, the National Institute for Health Research or the Department of Health.
BSKH is funded through Innovation Fund Denmark (5153-00002B) and the Novo Nordisk Foundation (NNF14CC0001).
This project is part funded by the UNSW RIS grant.
Author contributions
All authors made substantial contributions to the conception or design of the work; DPA and PBR led the acquisition of the data; JMR led the analysis; all authors were involved in the interpretation of data for the work; All authors have contributed to the drafting and revising critically the manuscript for important intellectual content; all authors have given final approval and agree to be accountable for all aspects of the work.
Competing interests
Dr. Prieto-Alhambra reports grants and other from AMGEN, grants, non-financial support and other from UCB Biopharma, grants from Les Laboratoires Servier, outside the submitted work; and Janssen, on behalf of IMI-funded EHDEN and EMIF consortiums, and Synapse Management Partners have supported training programmes organised by DPA’s department and open for external participants.
Dr. Rijnbeek reports grants from Innovative Medicines Initiative, grants from Janssen Research and Development, during the conduct of the study.
Dr. Reich and Ms. Kostka report they are employees of IQVIA.
Dr. Reps, Dr. Ryan, Dr. Shoaibi and Dr. Rao are employees with compensation at Janssen Research & Development, JNJ.
Dr. Suchard reports grants from US National Institutes of Health, grants from IQVIA, personal fees from Janssen Research and Development, personal fees from Private Health Management, during the conduct of the study.
Dr. Morales is supported by a Wellcome Trust Clinical Research Development Fellowship (Grant 214588/Z/18/Z) and reports grants from Chief Scientist Office (CSO), grants from Health Data
Research UK (HDR-UK), grants from National Institute of Health Research (NIHR), outside the submitted work.
Dr. Hripcsak reports grants from US NIH National Library of Medicine, during the conduct of the study; grants from Janssen Research, outside the submitted work.
Benjamin Skov Kaas-Hansen reports grants from Innovation Fund Denmark and Novo Nordisk Foundation, outside the submitted work.
Acknowledgements
We would like to acknowledge the patients who suffered from or died of this devastating disease, and their families and caregivers. We would also like to thank the healthcare professionals involved in the management of COVID-19 during these challenging times, from primary care to intensive care units.
The authors appreciate healthcare professionals dedicated to treating COVID-19 patients in Korea, and the Ministry of Health and Welfare and the Health Insurance Review & Assessment Service of Korea for sharing invaluable national health insurance claims data in a prompt manner.
Appendix
Data sources formatted to the OMOP-CDM used in this research
Appendix A: Definitions used in the study
[excel file called exValConcepts]
Appendix B: Predictor SNOMED codes
Appendix C: Characteristics for all databases
Excel sheet: cv19indexCovs.csv
Appendix D: ROC and calibration plots
Full results are available from http://evidence.ohdsi.org/C19validation
Plots using Target population of patients with influenza or influenza-like symptoms





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



