
Abstract
We analyze risk factors correlated with the initial transmission growth rate of the recent COVID-19 pandemic in different countries. The number of cases follows in its early stages an almost exponential expansion; we chose as a starting point in each country the first day di with 30 cases and we fitted for 12 days, capturing thus the early exponential growth. We looked then for linear correlations of the exponents α with other variables, for a sample of 126 countries. We find a positive correlation, i.e. faster spread of COVID-19, with high confidence level with the following variables, with respective p-value: low Temperature (4 · 10−7), high ratio of old vs. working-age people (3 · 10−6), life expectancy (8 · 10−6), number of international tourists (1 · 10−5), earlier epidemic starting date di (2 · 10−5), high level of physical contact in greeting habits (6 · 10−5), lung cancer prevalence (6 · 10−5), obesity in males (1 · 10−4), share of population in urban areas (2 · 10−4), cancer prevalence (3 · 10−4), alcohol consumption (0.0019), daily smoking prevalence (0.0036), UV index (0.004, smaller sample, 73 countries), low Vitamin D serum levels (0.002 – 0.006, smaller sample, ~ 50 countries). There is highly significant correlation also with blood type: positive correlation with types RH-(2 · 10−5) and A+ (2 · 10−3), negative correlation with B+ (2 · 10−4). We also find positive correlation with moderate confidence level (p-value of 0.02 ~ 0.03) with: CO2/SO emissions, type-1 diabetes in children, low vaccination coverage for Tuberculosis (BCG). Several of the above variables are correlated with each other and so they are likely to have common interpretations. Other variables are found to have a counterintuitive negative correlation, which may be explained due their strong negative correlation with life expectancy: slower spread of COVID-19 is correlated with high death-rate due to pollution, prevalence of anemia and hepatitis B, high blood pressure in females. We also analyzed the possible existence of a bias: countries with low GDP-per capita, typically located in warm regions, might have less intense testing and we discuss correlation with the above variables.
I. INTRODUCTION
The recent coronavirus (COVID-19) pandemic is now spreading essentially everywhere in our planet. The growth rate of the contagion has however a very high variability among different countries, even in its very early stages, when government intervention is still almost negligible. Any factor contributing to a faster or slower spread needs to be identified and understood with the highest degree of scrutiny. In [1] the early growth rate of the contagion has been found to be correlated at high significance with temperature T. In this work we extend a similar analysis to many other variables. This correlational study could help further investigation in order to find causal factors and it can help policy makers in their decisions.
Some factors are intuitive and have been found in other studies, such as temperature [1, 3–9] (see also [10] for a different conclusion) and air travel [2, 10]; we aim here at being more exhaustive and at finding also factors which are not “obvious” and have a potential biological origin, or correlation with one.
The paper is organized as follows. In section II we explain our methods, in section III we show our main results, in section IV we show the detailed results for each individual variable of our analysis, in section V we discuss correlations among variables and in section VI we draw our conclusions.
II. METHOD
As in [1], we use the empirical observation that the number of COVID-19 positive cases follows a common pattern in the majority of countries: once the number of confirmed cases reaches order 10 there is a very rapid growth, which is typically well approximated for a few weeks by an exponential. Subsequently the exponential growth typically gradually slows down, probably due to other effects, such as: lockdown policies from governments, a higher degree of awareness in the population or the tracking and isolation of the positive cases. The growth is then typically stopped and reaches a peak in countries with a strong lockdown/tracking policy.
Our aim is to find which factors correlate with the speed of contagion, in its first stage of free propagation. For this purpose we analyzed a datasets of 126 countries taken from [12] on April 15th. We have chosen our sample using the following rules:
We start analyzing data from the first day di in which the number of cases in a given country reaches a reference number Ni, which we choose to be Ni = 30 [54];
We include only countries with at least 12 days of data, after this starting point;
We excluded countries with too small total population (less than 300 thousands inhabitants).
We then fit the data for each country with a simple exponential curve  , with 2 parameters, N0 and α; here t is in units of days. In the fit we used Poissonian errors, given by
, with 2 parameters, N0 and α; here t is in units of days. In the fit we used Poissonian errors, given by  , on the daily counting of cases.
, on the daily counting of cases.
Note that the statistical errors on the exponents α, considering Poissonian errors on the daily counting of cases, are typically only a few percent of the spread of the values of a among the various countries. For this reason we disregarded statistical errors on α. The analysis was done using the software Mathematica, from Wolfram Research, Inc..
III. MAIN RESULTS
We first look for correlations with several individual variables. Most variables are taken from [13], while for a few of them have been collected from other sources, as commented below.
1. Non-significant variables
We find no significant correlation of the COVID-19 transmission in our set of countries with many variables, including the following ones:
Number of inhabitants;
Asthma-prevalence;
Participation time in leisure, social and associative life per day;
Population density;
Average precipitation per year;
Vaccinations coverage for: Polio, Diphteria, Tetanus, Pertussis, Hepatitis B;
Share of men with high-blood-pressure;
Diabetes prevalence (type 1 and 2, together);
Air pollution (“Suspended particulate matter (SPM), in micrograms per cubic metre”).
2. Significant variables, strong evidence
We find strong evidence for correlation with:
Temperature (negative correlation, p-value 4.4 · 10−7);
Old-age dependency ratio: ratio of the number of people older than 64 relative to the number of people in the working-age (15-64 years) (positive correlation, p-value 3.3 · 10−6);
Life expectancy (positive correlation p-value 8.1 · 10−6);
International tourism: number of arrivals (positive correlation p-value 9.6 · 10−6);
Starting day di of the epidemic (negative correlation, p-value 1.7 · 10−5);
Amount of contact in greeting habits (positive correlation, p-value 5.0 · 10−5);
Lung cancer death rates (positive correlation, p-value 6.3 · 10−5);
Obesity in males (positive correlation, p-value 1.2 · 10−4);
Share of population in urban areas (positive correlation, p-value 1.7 · 10−4);
Share of population with cancer (positive correlation, p-value 2.8 · 10−4);
Alcohol consumption (positive correlation, p-value 0.0019);
Daily smoking prevalence (positive correlation, p-value 0.0036);
UV index (negative correlation, p-value 0.004; smaller sample, 73 countries);
Vitamin D serum levels (negative correlation, annual values p-value 0.006, seasonal values 0.002; smaller sample, ~ 50 countries).
3. Significant variables, moderate evidence
We find moderate evidence for correlation with:
CO2 (and SO) emissions (positive correlation, p-value 0.015);
Type-1 diabetes in children (positive correlation, p-value 0.023);
Vaccination coverage for Tuberculosis (BCG) (negative correlation, p-value 0.028).
4. Significant variables, counterintuitive
Counterintuitively we also find correlations in a direction opposite to a naive expectation:
Death-rate-from-air-pollution (negative correlation, p-value 3.5 · 10−5);
Prevalence of anemia, adults and children, (negative correlation, p-value 1.4·10−4 and 7. × 10−6, respectively);
Share of women with high-blood-pressure (negative correlation, p-value 1.6 · 10−4);
Incidence of Hepatitis B (negative correlation, p-value 2.4 · 10−4);
PM2.5 air pollution (negative correlation, p-value 0.029).
A. Bias due to GDP: lack of testing?
We also find a correlation with GDP per capita, which we should be an indicator of lack of testing capabilities. Note however that GDP per capita is also quite highly correlated with another important variable, life expectancy, as we will show in section V: high GDP per capita is related to an older population, which is correlated with faster contagion.
Note also that correlation of contagion with GDP disappears when excluding very poor countries, approximately below 5 thousand $ GDP per capita: this is likely due to the fact that only below a given threshold the capability of testing becomes insufficient.

Exponent α for each country vs. GDP per capita. We show the data points and the best-fit for the linear interpolation.
In the left panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with GDP per capita (GDP). In the right panel: R2 for the best-estimate and number of countries N.
We performed 2-variables fits, including GDP and each of the above significant variables, in order to check if they remain still significant. In section IV we will show the results of such fits, and also the result of individual one variable fits excluding countries below the threshold of 5 thousand $ GDP per capita. We list here below the variables that are still significant even when fitting together with GDP.
1. Significant variables, strong evidence
In a 2-variable fit, including GDP per capita, we find strong evidence for correlation with:
Amount of contact in greeting habits (positive correlation, p-value 1.5 · 10−5);
Temperature (negative correlation, p-value 2.3 · 10−5);
International tourism: number of arrivals (positive correlation, p-value 2.6 · 10−4);
Old-age dependency ratio: ratio of the number of people older than 64 relative to the number of people in the working-age (15-64 years) (positive correlation, p-value 5.5 · 10−4);
Vitamin D serum levels (negative correlation, annual values p-value 0.0032, seasonal values 0.0024; smaller sample, ~ 50 countries).
Starting day of the epidemic (negative correlation, p-value 0.0037);
Lung cancer death rates (positive correlation, p-value 0.0039);
Life expectancy (positive correlation, p-value 0.0048);
2. Significant variables, moderate evidence
We find moderate evidence for:
UV index (negative correlation, p-value 0.01; smaller sample, 73 countries);
Type-I diabetes in children, 0-19 years-old (negative correlation, p-value 0.01);
Vaccination coverage for Tuberculosis (BCG) (negative correlation, p-value 0.023);
Obesity in males (positive correlation, p-value 0.02);
CO2 emissions (positive correlation, p-value 0.02);
Alcohol consumption (positive correlation, p-value 0.03);
Daily smoking prevalence (positive correlation, p-value 0.03);
Share of population in urban areas (positive correlation, p-value 0.04);
3. Significant variables, counterintuitive
Counterintuitively we still find correlations with:
Death rate from air pollution (negative correlation, p-value 0.002);
Prevalence of anemia, adults and children, (negative correlation, p-value 0.023 and 0.005);
Incidence of Hepatitis B (negative correlation, p-value 0.01);
Share of women with high-blood-pressure (negative correlation, p-value 0.03).
In the next section we analyze in more detail the significant variables, one by one (except for those which are not significant anymore after taking into account of GDP per capita). In section V we will analyze cross-correlations among such variables and this will also give a plausible interpretation for the existence of the “counterintuitive” variables.
IV. RESULTS FOR EACH VARIABLE
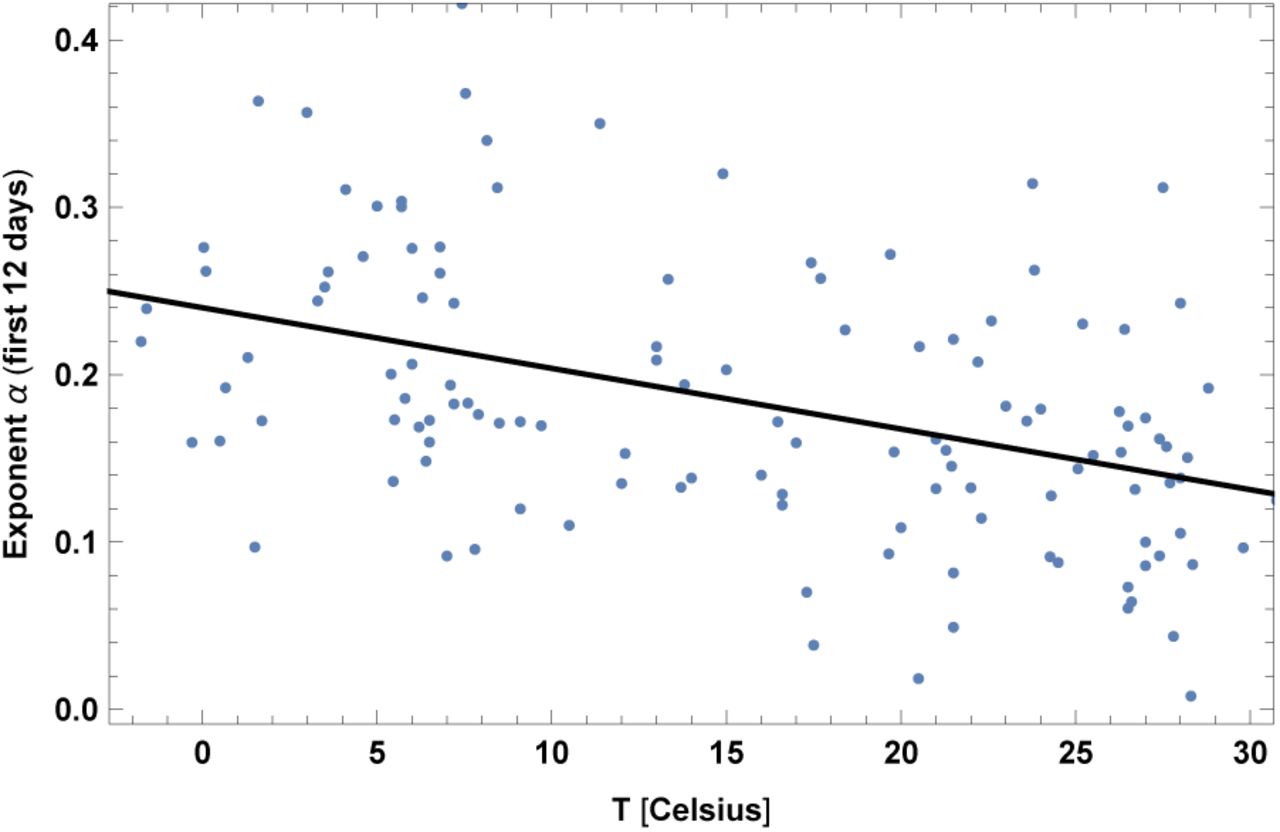
1. Temperature
The average temperature T has been collected for the relevant period of time, ranging from January to mid April, weighted among the main cities of a given country, see [1] for details. Results are shown in fig. 2 and Table II.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with temperature T. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with temperature T and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
We also found that another variable, the absolute value of latitude, has a similar amount of correlation as for the case of T. However the two variables have a very high correlation (about 0.91) and we do not show results for latitude here. Another variable which is also very highly correlated is UV index and it is shown later.

Exponent α for each country vs. average temperature T, for the relevant period of time, as defined in [1]. We show the data points and the best-fit for the linear interpolation.
2. Old-age dependency ratio
This is the ratio of the number of people older than 64 relative to the number of people in the working-age (15-64 years). Data are shown as the proportion of dependents per 100 working-age population, for the year 2017. Results are shown in fig. 3 and Table III. This is an interesting finding, since it suggests that old people are not only subject to higher mortality, but also more likely to be contagious. This could be either because they are more likely to become sick, or because their state of sickness is longer and more contagious, or because many of them live together in nursing homes, or all such reasons together.
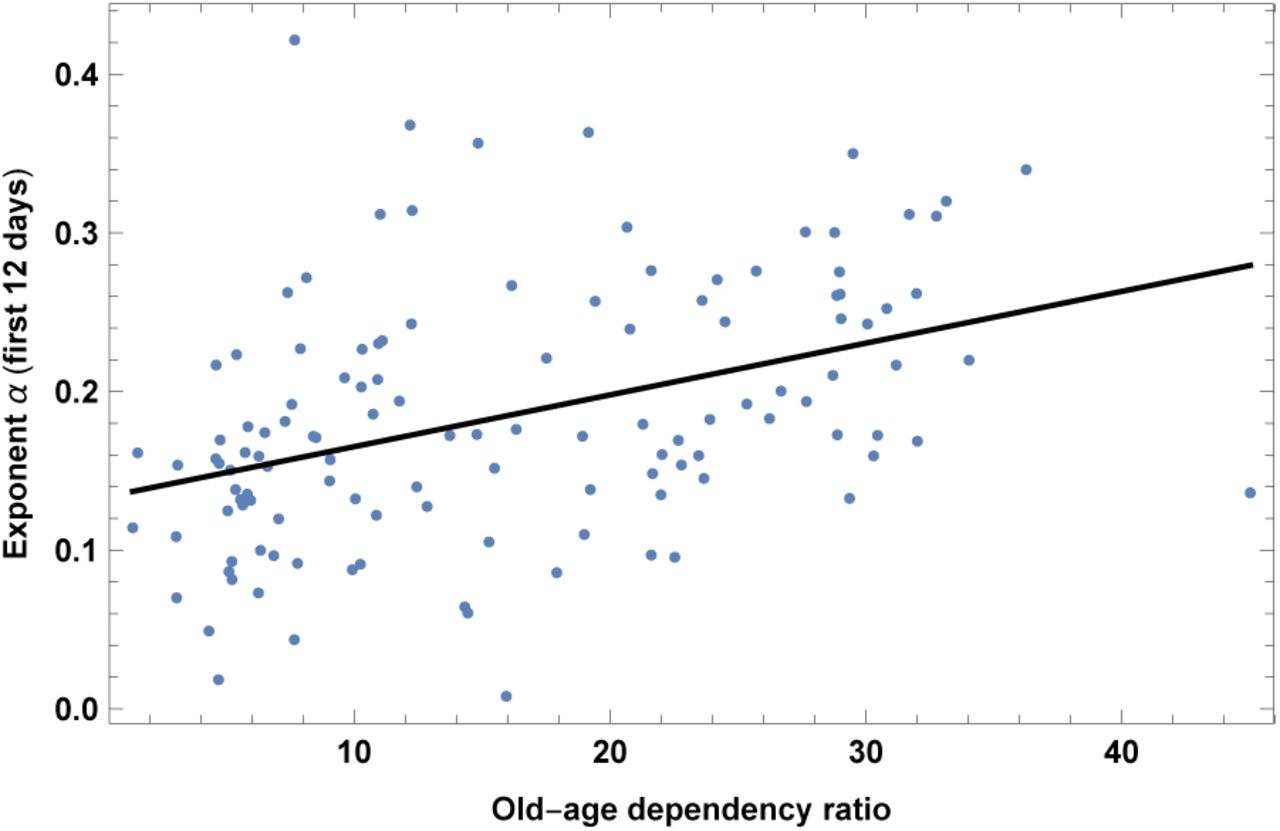
Exponent α for each country vs. old-age dependency ratio, as defined in the text. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with old-age dependency ratio, OLD. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of _ with OLD and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
Note that a similar variable is life expectancy (which we analyze later); other variables are also highly correlated, such as median age and child dependency ratio, which we do not show here. In analogy to the previous interpretation, data indicate that a younger population, including countries with high percentage of children, is more immune to COVID-19, or less contagious.
3. Life expectancy
This dataset is for year 2016. It has high correlation with old-age dependency ratio. It also has high correlations with other datasets in [13] that we do not show here, such as median age and child dependency ratio (the ratio between under-19-year-olds and 20-to-69-year-olds). Results are shown in fig. 4 and Table IV.
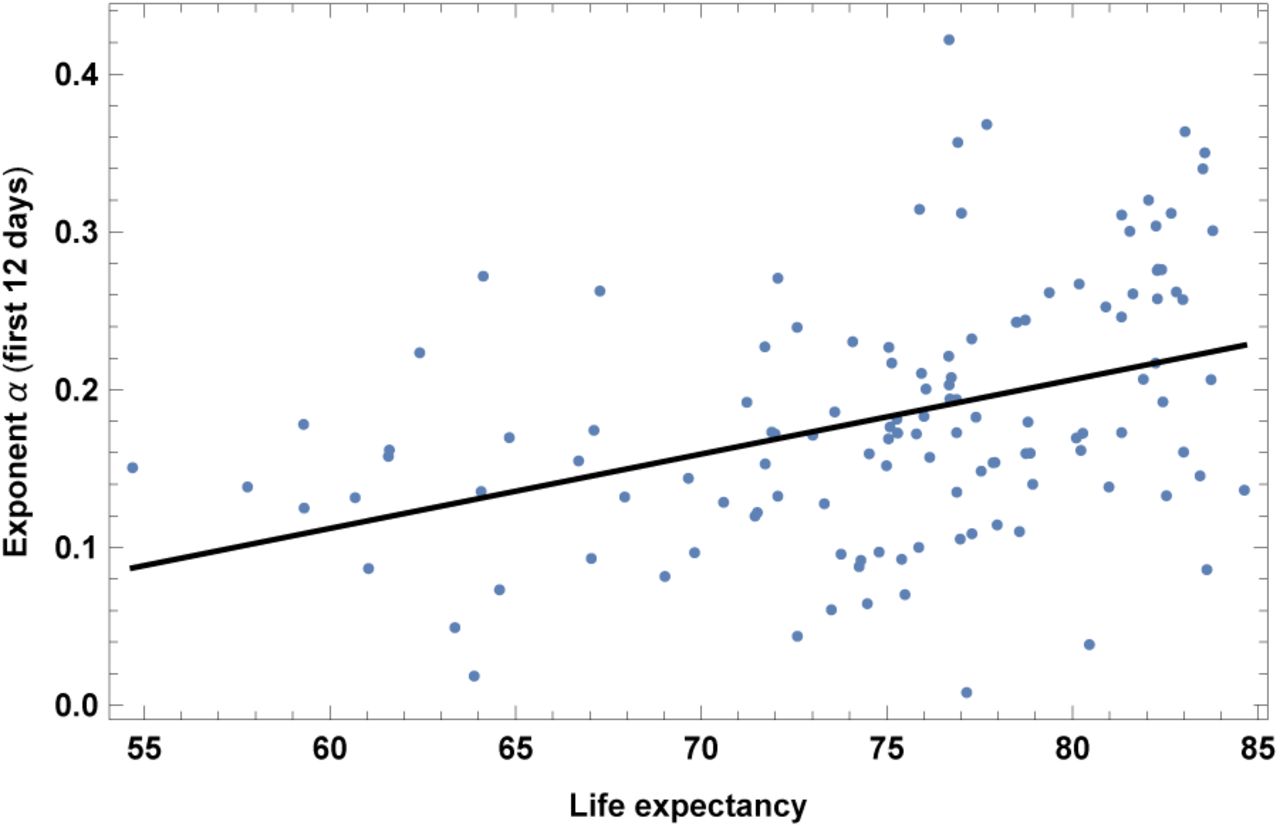
Exponent _ for each country vs. life expectancy. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with life expectancy, LIFE. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with LIFE and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
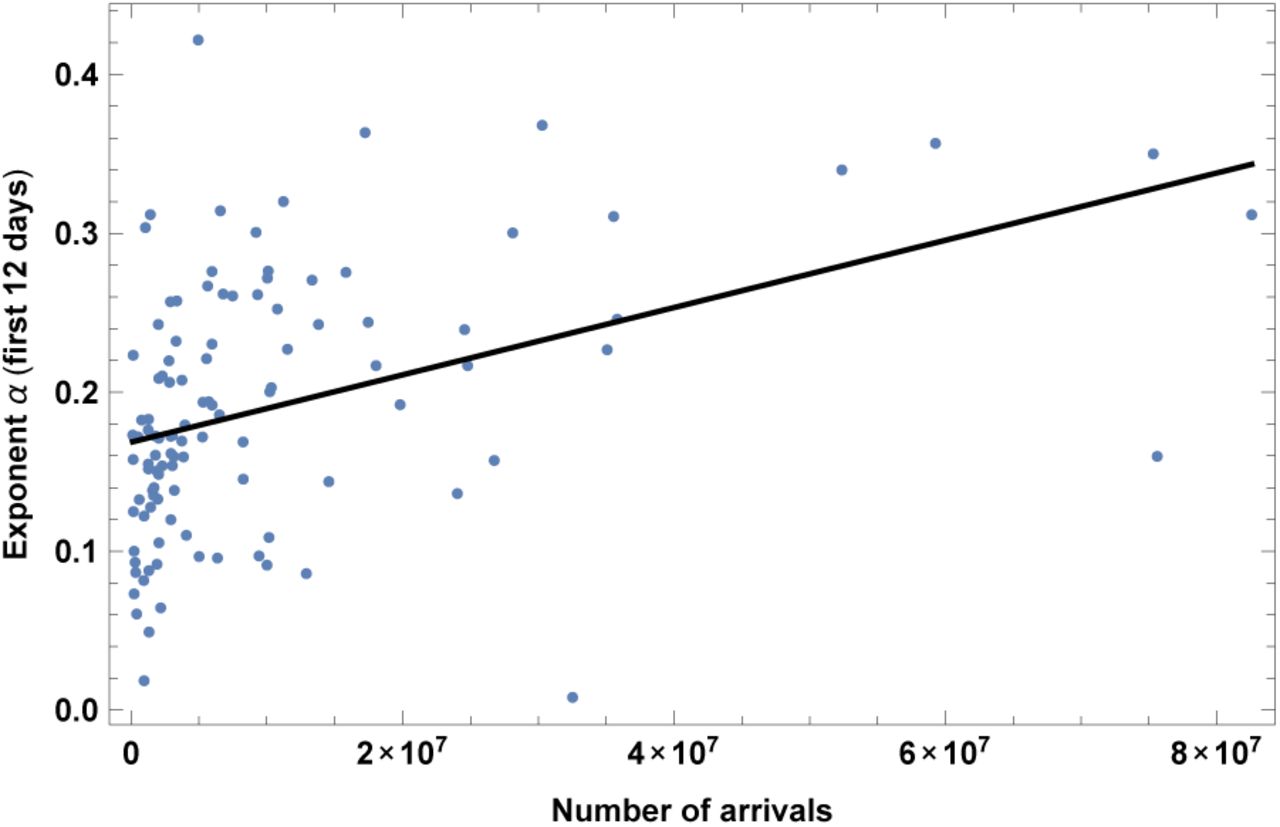
4. International tourism: number of arrivals
The dataset is for year 2016. Results are shown in fig. 5 and Table V. As expected, more tourists correlate with higher speed of contagion. This is in agreement with [2, 10], that found air travel to be an important factor, which will appear here as the number of tourists as well as a correlation with GDP.

Exponent α for each country vs. number of tourist arrivals. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with number of tourist arrivals, ARR. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with ARR and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
5. Starting date of the epidemic
This refers to the day di chosen as a starting point, counted from December 31st 2019. Results are shown in fig. 6 and Table VI, which shows that earlier contagion is correlated with faster contagion. One possible interpretation is that countries which are affected later are already more aware of the pandemic and therefore have a larger amount of social distancing, which makes the growth rate smaller. Another possible interpretation is that there is some other underlying factor that protects against contagion, and therefore epidemics spreads both later and slower.
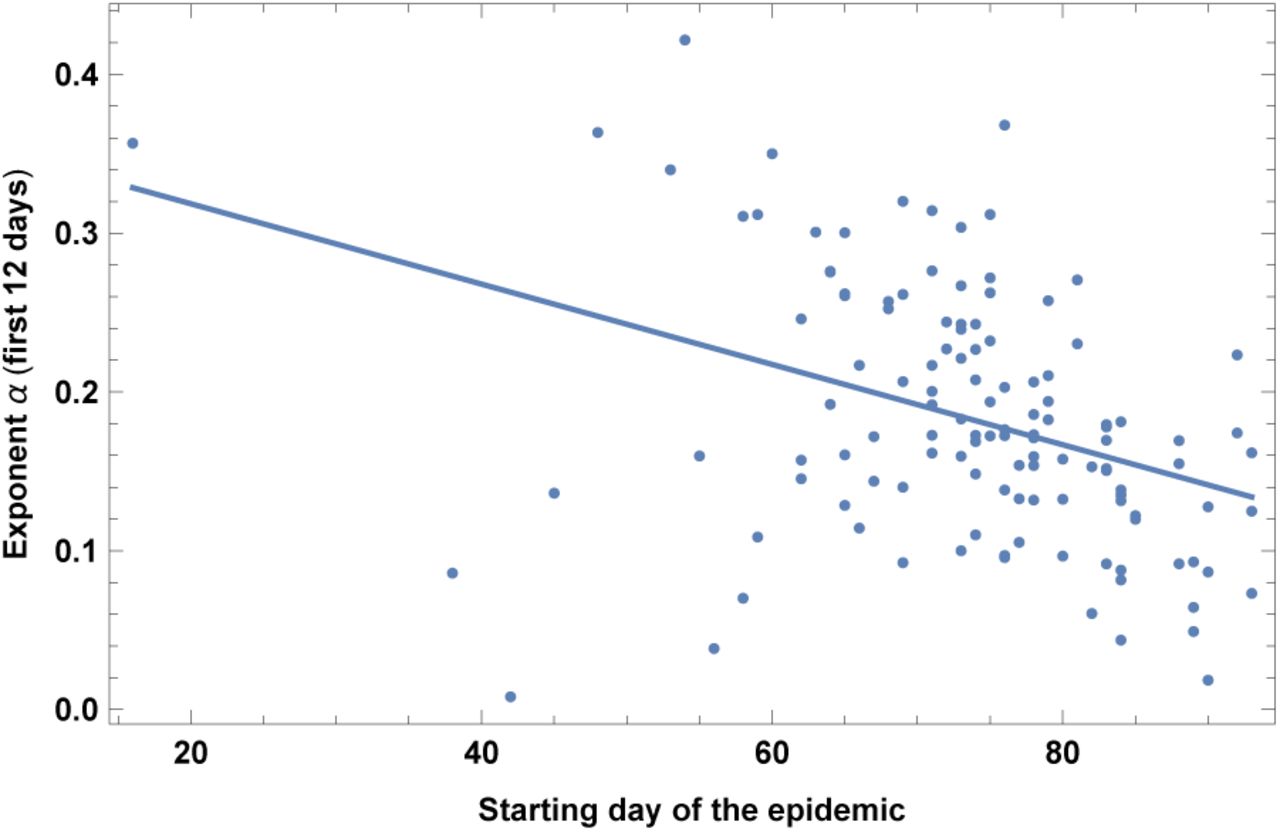
Exponent α for each country vs. starting date of the analysis of the epidemic, DATE, defined as the day when the positive cases reached N = 30. Days are counted from Dec 31st 2019. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with vs. starting date of the analysis of the epidemic, DATE, as defined in the text. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with DATE and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
6. Greeting habits
A relevant variable is the level of contact in greeting habits in each country. We have subdivided the countries in groups according to the physical contact in greeting habits; information has been taken from [28].
No or little physical contact, bowing. In this group we have: Bangladesh, Cambodia, Japan, Korea South, Sri Lanka, Thailand.
Handshaking between man-man and woman-woman. No or little contact man-woman. In this group we have: India, Indonesia, Niger, Senegal, Singapore, Togo, Vietnam, Zambia
Handshaking. In this group we have: Australia, Austria, Bulgaria, Burkina Faso, Canada, China, Estonia, Finland, Germany, Ghana, Madagascar, Malaysia, Mali, Malta, New Zealand, Norway, Philippines, Rwanda, Sweden, Taiwan, Uganda, Kingdom United, States United.
Handshaking, plus kissing among friends and relatives, but only man-man and woman-woman. No or little contact man-woman. In this group we have: Afghanistan, Azerbaijan, Bahrain, Belarus, Brunei, Egypt, Guinea, Jordan, Kuwait, Kyrgyzstan, Oman, Pakistan, Qatar, Arabia Saudi, Arab Emirates United, Uzbekistan.
Handshaking, plus kissing among friends and relatives. In this group we have: Albania, Algeria, Argentina, Armenia, Belgium, Bolivia, and Bosnia Herzegovina, Cameroon, Chile, Colombia, Costa Rica, Côte d’Ivoire, Croatia, Cuba, Cyprus, Czech Republic, Denmark, Dominican Republic, Ecuador, El Salvador, France, Georgia, Greece, Guatemala, Honduras, Hungary, Iran, Iraq, Ireland, Israel, Italy, Jamaica, Kazakhstan, Kenya, Kosovo, Latvia, Lebanon, Lithuania, Luxembourg, Macedonia, Mauritius, Mexico, Moldova, Montenegro, Morocco, Netherlands, Panama, Paraguay, Peru, Poland, Portugal, Puerto Rico, Romania, Russia, Serbia, Slovakia, Slovenia, Africa South, Switzerland, Trinidad and Tobago, Tunisia, Turkey, Ukraine, Uruguay, Venezuela.
Handshaking and kissing. In this group we have: Andorra, Brazil, Spain.
We have arbitrarily assigned a variable, named GRE, from 0 to 1 to each group, namely GRE = 0; 0.25; 0.5; 0.4; 0.8 and 1, respectively. We have chosen a ratio of 2 between group 2 and 3 and between group 4 and 5, based on the fact that the only difference is that about half of the possible interactions (men-women) are without contact. Results are shown in Fig. 7 and Table VII.

Exponent α for each country vs. level of contact in greeting habits, GRE, as defined in the text. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of a with level of contact in greeting habits, GRE, as defined in the text. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with GRE and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
Note also that an outlier is visible in the plot, which corresponds to South Korea. The early outbreak of the disease in this particular case was strongly affected by the Shincheonji Church, which included mass prayer and worship sessions. By excluding South Korea from the dataset one finds an even larger significance, p-value= 6:4 · 10−8 and R2 ≈ 0:23.
7. Lung cancer death rates
This dataset refers to year 2002. Results are shown in Fig. 8 and Table VIII. Such results are interesting and could be interpreted a priori in two ways. A first interpretation is that COVID-19 contagion might correlate to lung cancer, simply due to the fact that lung cancer is more prevalent in countries with more old people. Such a simplistic interpretation is somehow contradicted by the case of generic cancer death rates, discussed in section III, which is indeed less significant than lung cancer. A better interpretation is therefore that lung cancer may be a specific risk factor for COVID-19 contagion. This is supported also by the observation of high rates of lung cancer in COVID-19 patients [14].

Exponent α for each country vs. lung cancer death rates. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of a with lung cancer death rates, LUNG. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with LUNG and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
8. Obesity in males
This refers to the prevalence of obesity in adult males, measured in 2014. Results are shown in fig. 9 and Table IX. Note that this effect is mostly due to the difference between very poor countries and the rest of the world; indeed this becomes non-significant when excluding countries below 5K$ GDP per capita. Note also that obesity in females instead is not correlated with growth rate of COVID-19 contagion in our sample. See also [15] for increased risk of severe COVID-19 symptoms for obese patients.

Exponent α for each country vs. prevalence of obesity in adult males. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with mean annual levels of vitamin D (variable name: D). We also show the p-value, excluding countries below 5 thousand S GDP per capita. In the left bottom panel: same quantities for correlation of α with D and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
9. Urbanization
This is the share of population living in urban areas, collected in year 2017. Results are shown in Fig. 10 and Table X. This is an expected correlation, in agreement with [19, 20].
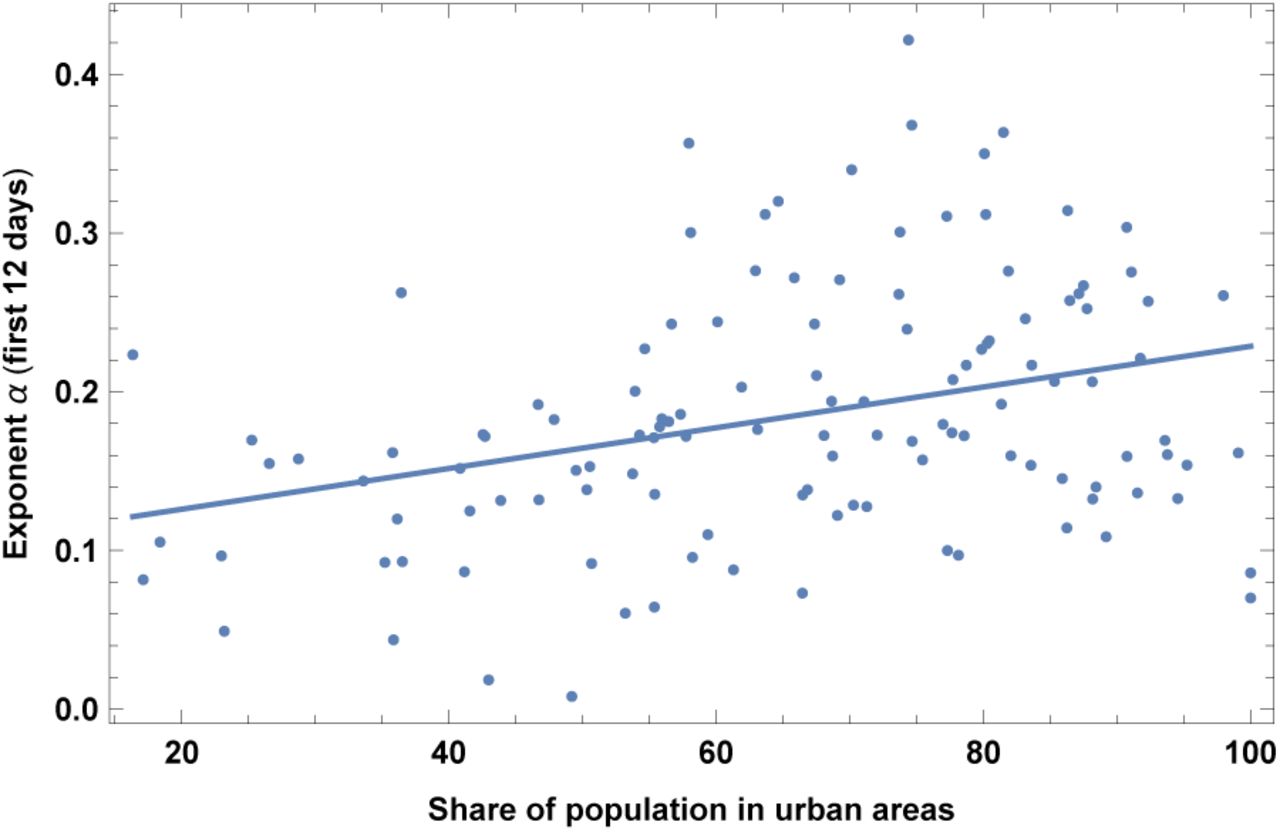
Exponent α for each country vs. share of population in urban areas. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with share of population in urban areas, URB, as defined in the text. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with URB and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
10. Alcohol consumption
This dataset refers to year 2016. Results are shown in Fig. 11 and Table XI. Note that this variable is highly correlated with old-age dependency ratio, as discussed in section V. While the correlation with alcohol consumption may be simply due to correlation with other variables, such as old-age dependency ratio, this finding deserves anyway more research, to assess whether it may be at least partially due to the deleterious effects of alcohol on the immune system.
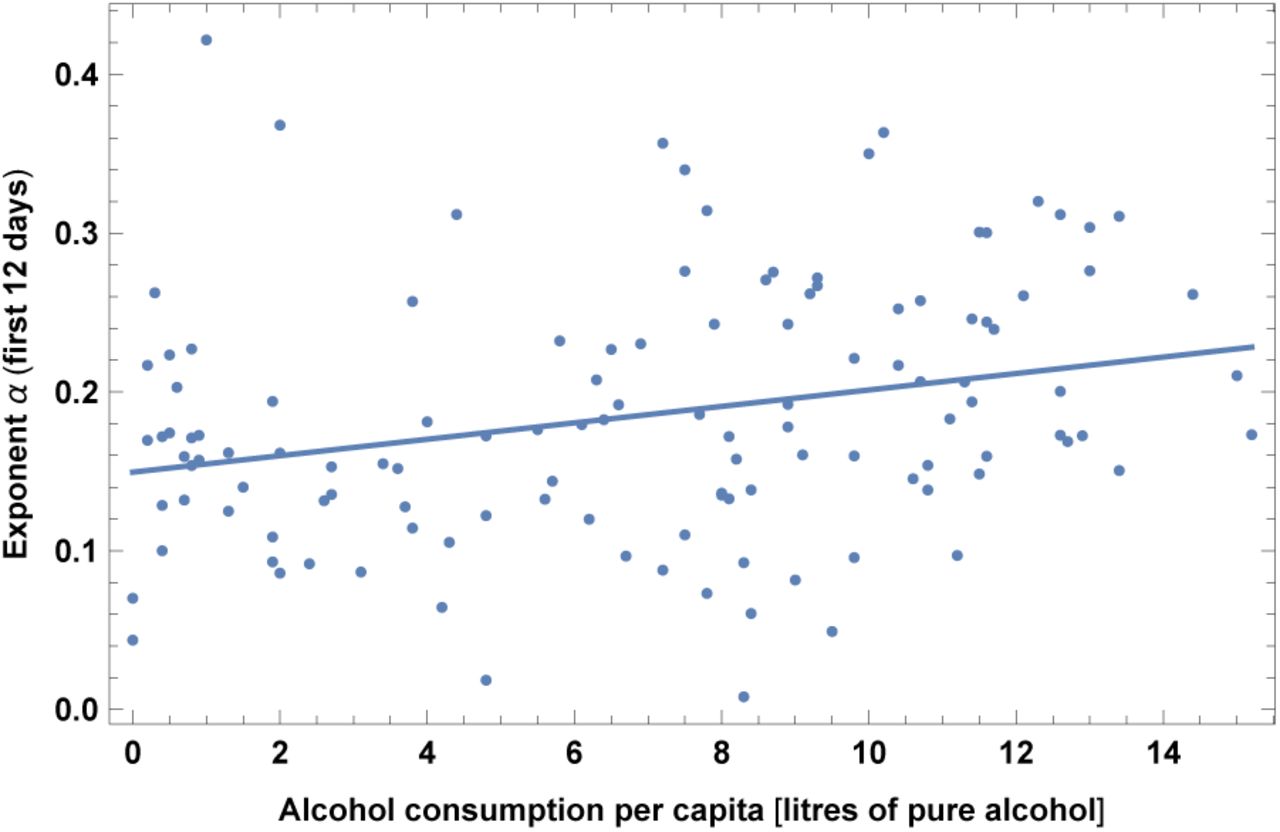
Exponent α for each country vs. alcohol consumption. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with alcohol consumption (ALCO). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with ALCO and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
11. Smoking
This dataset refers to year 2012. Results are shown in Fig. 12 and Table XII. As expected this variable is highly correlated with lung cancer, as discussed in section V. We find that COVID-19 spreads more rapidly in countries with higher daily smoking prevalence. Note however that this becomes non-significant when excluding countries below 5K$ GDP per capita.

Exponent α for each country vs. daily smoking prevalence. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with daily smoking prevalence (SMOK). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with SMOK and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
Correlation of α with smoking thus could be simply due to correlation with other variables or to a bias due to lack of testing in very poor countries. Alternative interpretations are that smoking has negative effects on conditions of lungs that facilitates contagion or that it contributes to increased transmission of virus from hand to mouth [16]. Interestingly, note that our finding is in contrast with claims of a possible protective effect of nicotine and smoking against COVID-19 [17, 18].
12. UV index
This is the UV index for the relevant period of time of the epidemic. In particular the UV index has been collected from [21], as a monthly average, and then with a linear interpolation we have used the average value during the 12 days of the epidemic growth, for each country. Results are shown in Fig. 13 and Table XIII. Not surprisingly in section V we will see that such quantity is very highly correlated with T (correlation coefficient 0.93). Note also that here the sample size is smaller (73) than in the case of other variables, so it is not strange that the significance of a correlation with α here is not as high as in the case of α with Temperature. More research is required to answer more specific questions, for instance whether the virus survives less in an environment with high UV index, or whether a high UV index stimulates vitamin D production that may help the immune system, or both.

Exponent α for each country vs. UV index for the relevant month of the epidemic. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with UV index for the relevant period of time of the epidemic (UV). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with UV and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
13. Vitamin D serum concentration
Another relevant variable is the amount of serum Vitamin D. We have collected data in the literature for the average annual level of serum Vitamin D and for the seasonal level (Ds). The seasonal level is defined as: the amount during the month of March or during winter for northern hemisphere, or during summer for southern hemisphere or the annual level for countries with little seasonal variation. The dataset for the annual D was built with the available literature, which is unfortunately quite inhomogeneous as discussed in Appendix A. For many countries several studies with quite different values were found and in this case we have collected the mean and the standard error and a weighted average has been performed. The countries included in this dataset are 50, as specified in Appendix. The dataset for the seasonal levels is more restricted, since the relative literature is less complete, and we have included 42 countries.
Results are shown in Fig. 14 and Table XXXII for the annual levels and in Fig. 14 and Table XXXII for the seasonal levels.
Interestingly, in section V we will see that D is not highly correlated with T or UV index, as one naively could expect, due to different food consumption in different countries. A slightly higher correlation, as it should be, is present between T and Ds. Note that our results are in agreement with the fact that increased vitamin D levels have been proposed to have a protective effect against COVID-19 [45-47].

Exponent α for each country vs. annual levels of vitamin D, for the relevant period of time, as defined in the text, for the base set of 42 countries. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with mean annual levels of vitamin D (variable name: D). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with D and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.

Exponent α for each country vs. seasonal levels of vitamin D, for the relevant period of time, as defined in the text, for the base set of 42 countries. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with mean annual levels of vitamin D (variable name: Ds). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with Ds and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
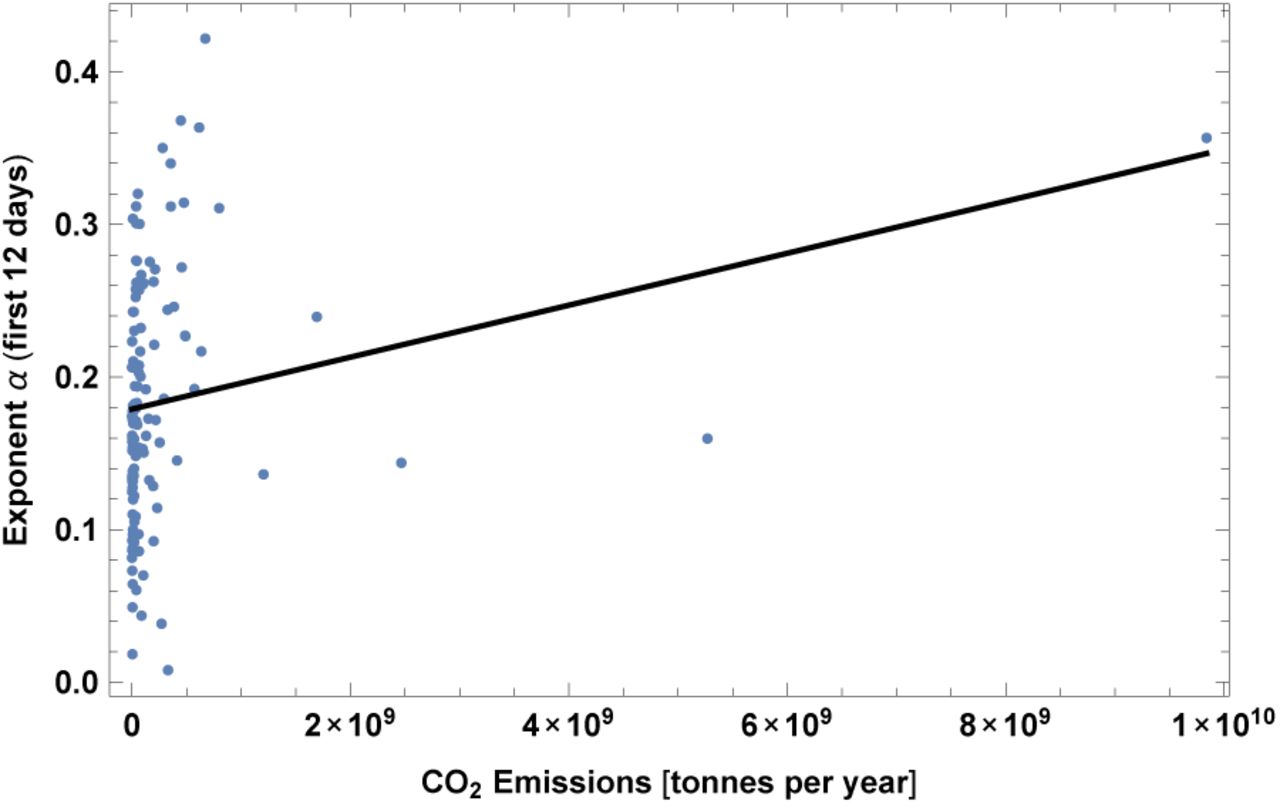
14. CO2 Emissions
This is the data for year 2017. We have also checked that this has very high correlation with SO emissions (about 0.9 correlation coefficient). We show here only the case for CO2, but the reader should keep in mind that a very similar result applies also to SO emissions. Note also that this is expected to have a high correlation with the number of international tourist arrivals, as we will show in section V. Results are shown in Fig. 16 and Table XVI.

Exponent a for each country vs. CO2 emissions. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with CO2 emissions. We also show the p-value, excluding countries below 5 thousand S GDP per capita. In the left bottom panel: same quantities for correlation of α with CO2 and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
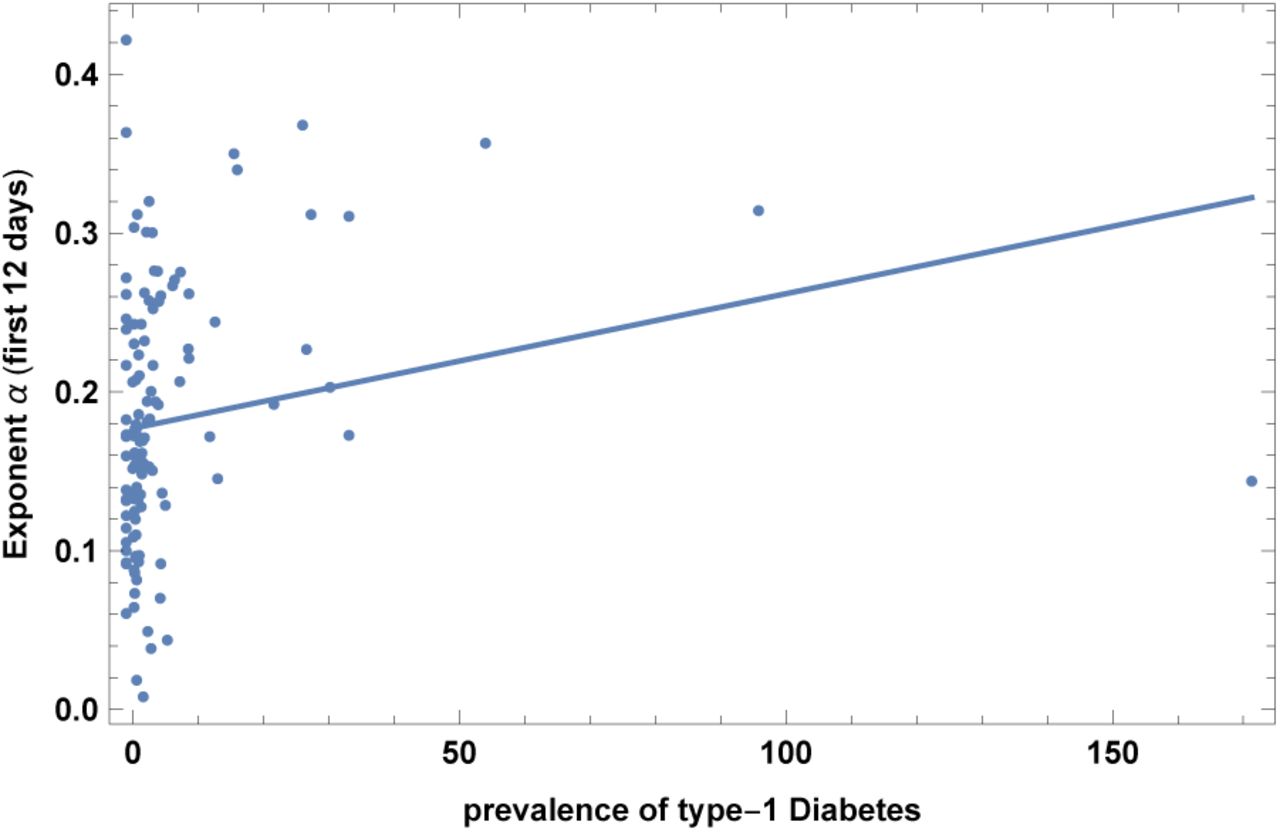
15. Prevalence of type-1 Diabetes
This is the prevalence of type-1 Diabetes in children, 0-19 years-old, taken from [23]. Results are shown in Fig. 17 and Table XXIII. Note however that significance becomes very small when restricting to countries with GDP per capita larger than 5K$. Note also that in the case of diabetes of any kind we do not find a correlation with COVID-19. Such correlation, even if not highly significant, could be non-trivial and could constitute useful information for clinical and genetic research. See also [49].

Exponent α for each country vs. prevalence of type-1 Diabetes. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with prevalence of type-1 Diabetes, DIA. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with DIA and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
16. Tuberculosis (BCG) vaccination coverage
This dataset is the vaccination coverage for tuberculosis for year 2015 [55]. Results are shown in Fig. 18 and Table XVIII. This correlation, even if not highly significant and to be confirmed by more data, is also quite non-trivial and could be useful information for clinical and genetic research (see also [29-31]) and even for vaccine development [32-34].
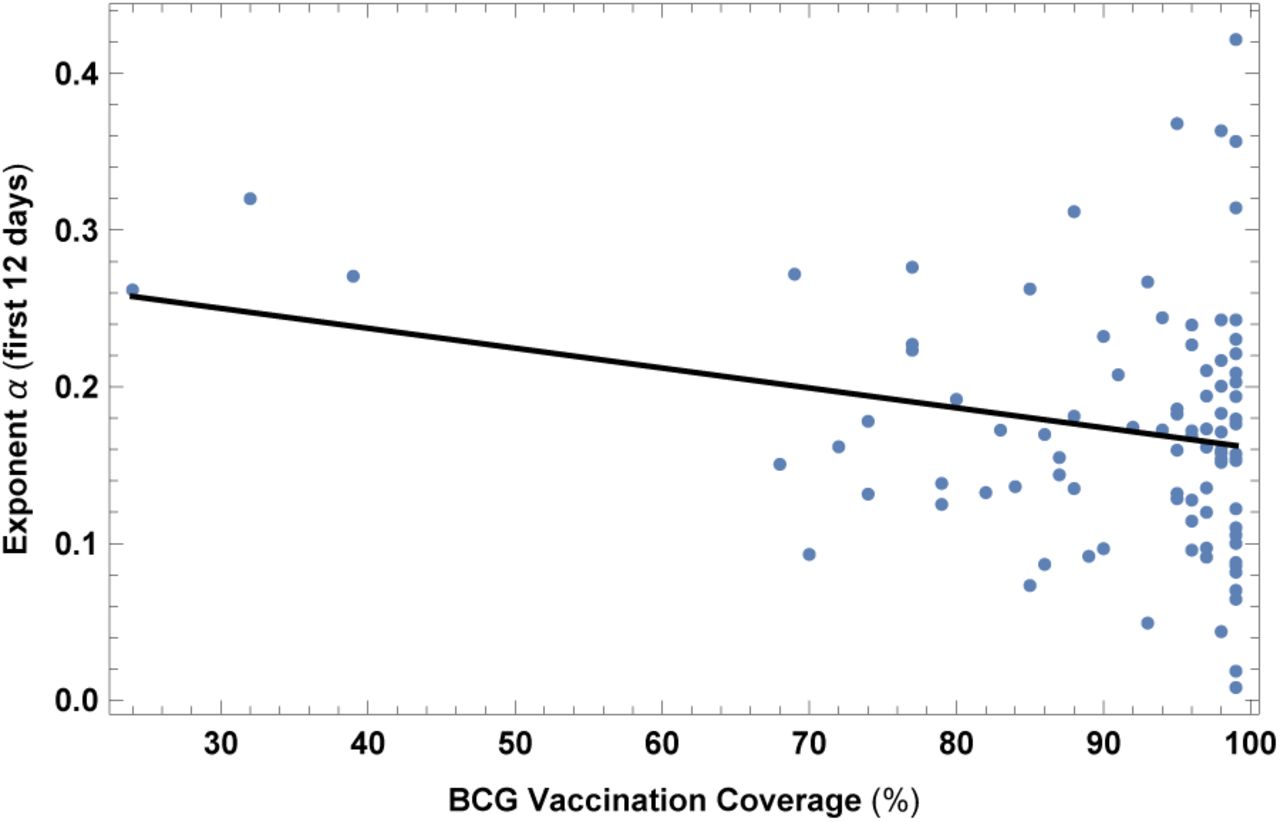
Exponent α for each country vs. BCG vaccination coverage. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with BCG vaccination coverage (BCG). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with BCG and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
A. “Counterintuitive” correlations
We show here other correlations that are somehow counterintuitive, since they go in the opposite direction than from a naive expectation. We will try to interpret these results in section V.
1. Death rate from air pollution
This dataset is for year 2015. Results are shown in Fig. 19 and Table XIX. Contrary to naive expectations and to claims in the opposite direction [48], we find that countries with larger death rate from air pollution actually have slower COVID-19 contagion.
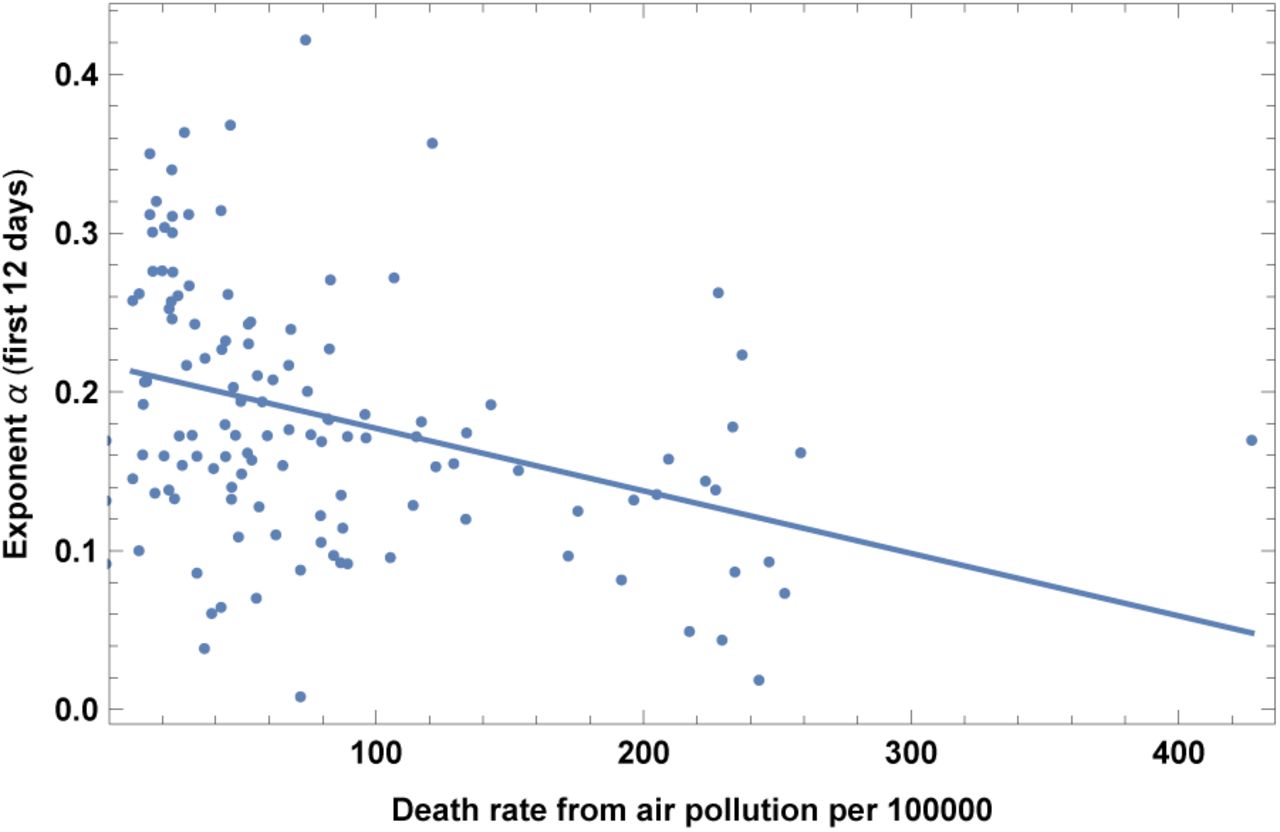
Exponent α for each country vs. death rate from air pollution per 100000. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with death rate from air pollution per 100000 (POLL). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with POLL and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
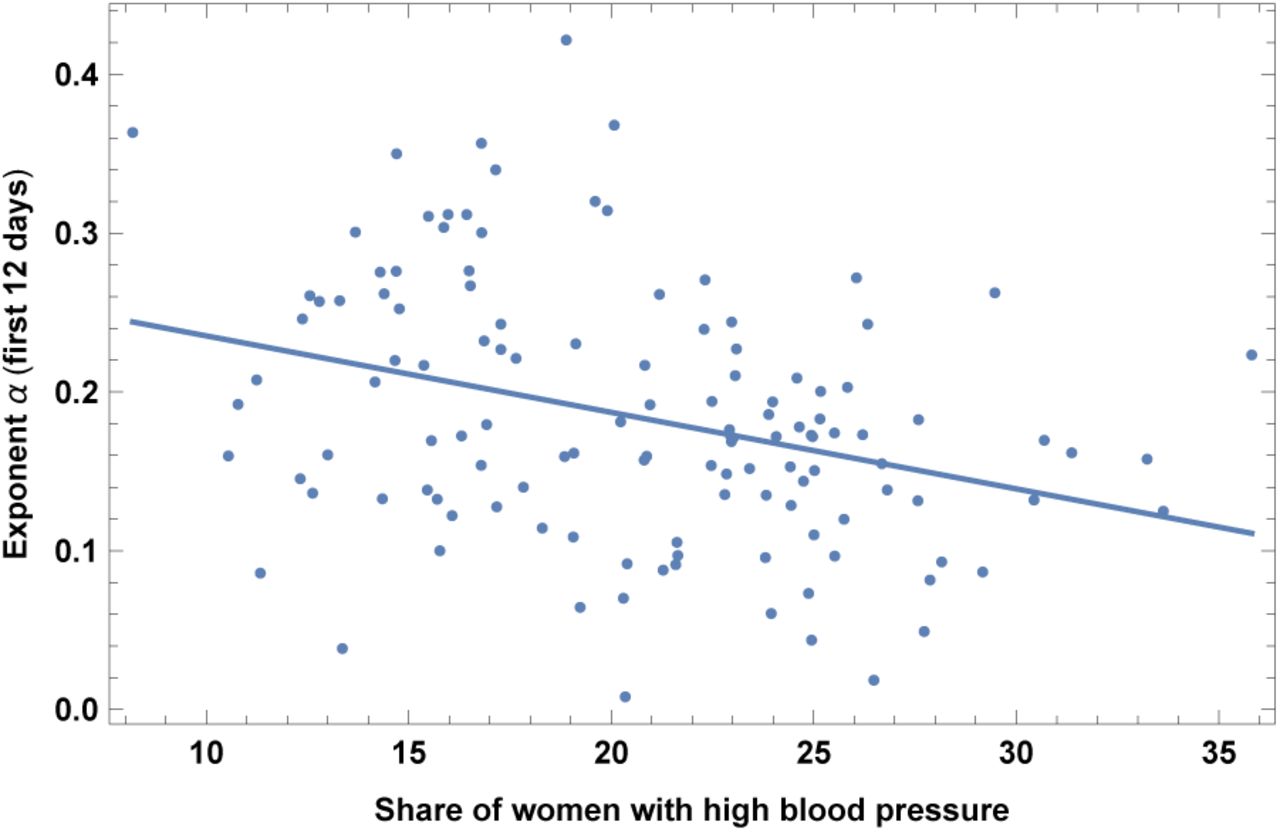
2. High blood pressure in females
This dataset is for year 2015. Results are shown in Fig. 20 and Table XX. Countries with larger share of high blood pressure in females have slower COVID-19 contagion. Note that we do not find a significant correlation instead with high blood pressure in males.
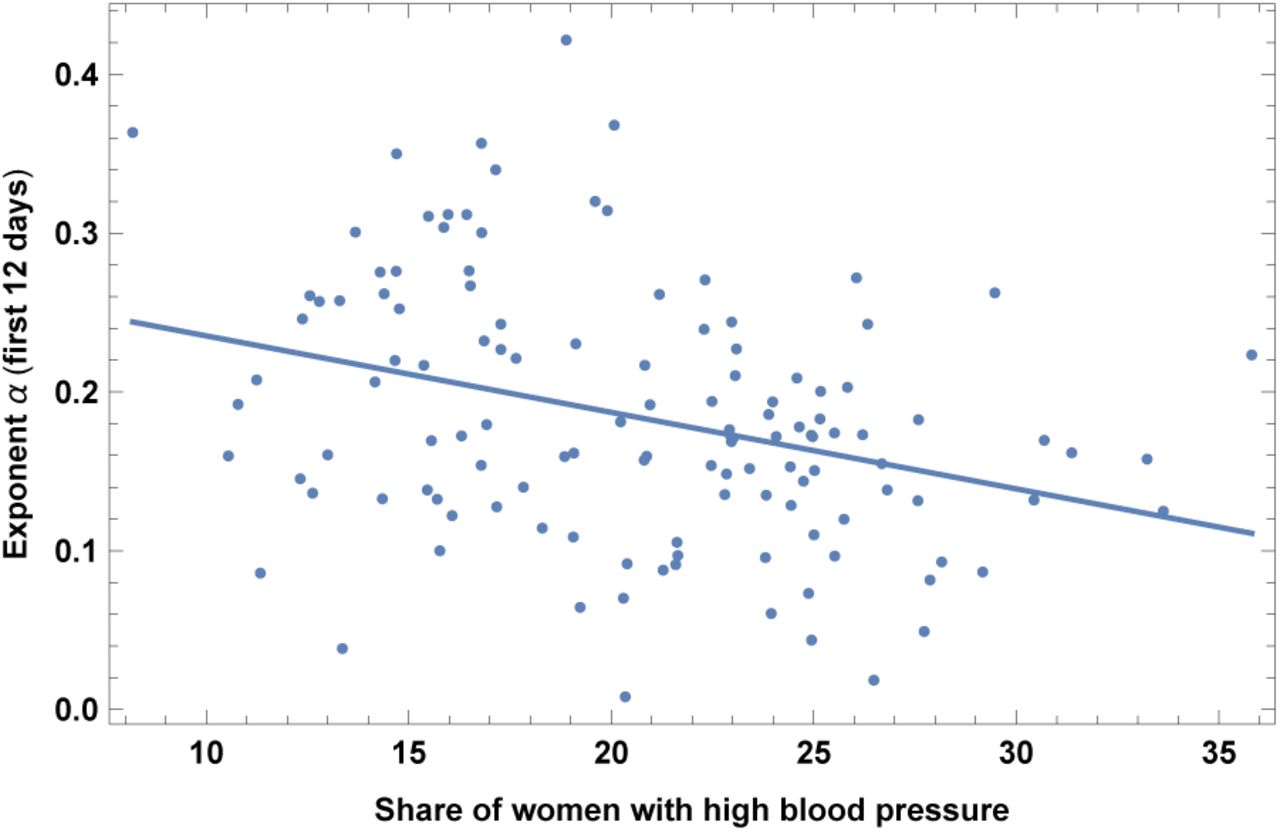
Exponent α for each country vs. share of women with high blood pressure. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with share of women with high blood pressure (PRE). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with PRE and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
3. Hepatitis B incidence rate
This is the incidence of hepatitis B, measured as the number of new cases of hepatitis B per 100,000 individuals in a given population, for the year 2015. Results are shown in Fig. 21 and Table XXI. Countries with higher incidence of hepatitis B have slower contagion of COVID-19.

Exponent α for each country vs. incidence of Hepatitis B, for the relevant period of time, as defined in the text, for the base set of 42 countries. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with incidence of Hepatitis B (HEP). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with HEP and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
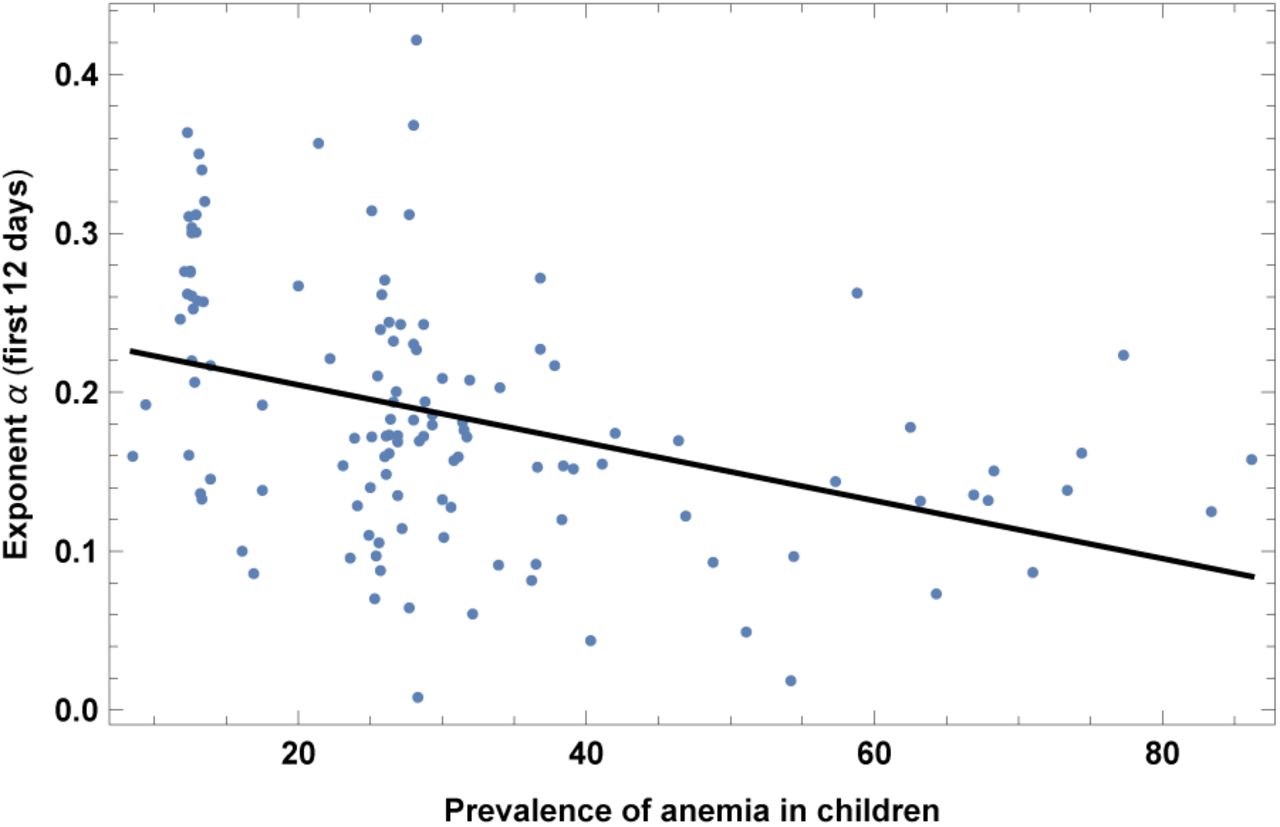
4. Prevalence of Anemia
Prevalence of anemia in children in 2016, measured as the share of children under the age of five with hemoglobin levels less than 110 grams per liter at sea level. A similar but less significant correlation is found also with anemia in adults, which we do not report here. Results are shown in Fig. 22 and Table XXII. The significance is quite high, but could be interpreted as due to a high correlation with life expectancy, as we explain in section V. A different hypothesis is that this might be related to genetic factors, which might affect the immune response to COVID-19.

Exponent α for each country vs. prevalence of anemia in children. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with prevalence of anemia in children (ANE). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with ANE and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
B. Blood types
Blood types are not equally distributed in the world and thus we have correlated them with α. Data were taken from [50]. Very interestingly we find significant correlations, especially for blood types B+ (slower COVID-19 contagion) and A-(faster COVID-19 contagion). In general also all RH-negative blood types correlate with faster COVID-19 contagion. It is interesting to compare with findings in clinical data: (i) our finding that blood type A is associated with a higher risk for acquiring COVID-19 is in good agreement with [26], (ii) we find higher risk for group 0-and no correlation for group 0+ (while [26] finds lower risk higher risk for groups 0), (iii) we have a strong significance for lower risk for RH+ types and in particular lower risk for group B+, which is probably a new finding, to our knowledge. These are also non-trivial findings which should stimulate further medical research on the immune response of different blood-types against COVID-19.

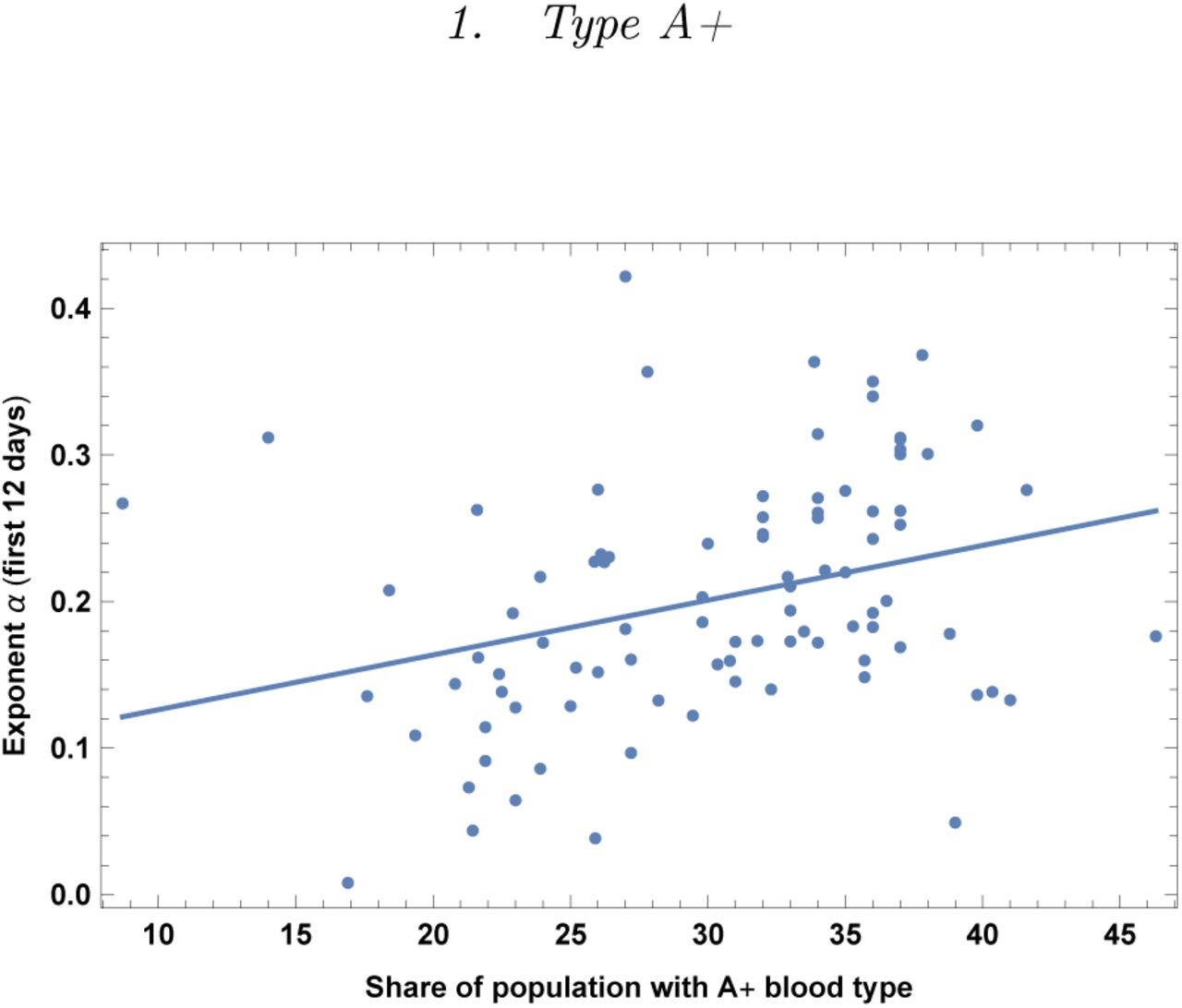
Exponent α for each country vs. percentage of population with blood type A+. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with blood type A+. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with A+ blood and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.

Exponent α for each country vs. percentage of population with blood type B+. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with blood type B+. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with B+ and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
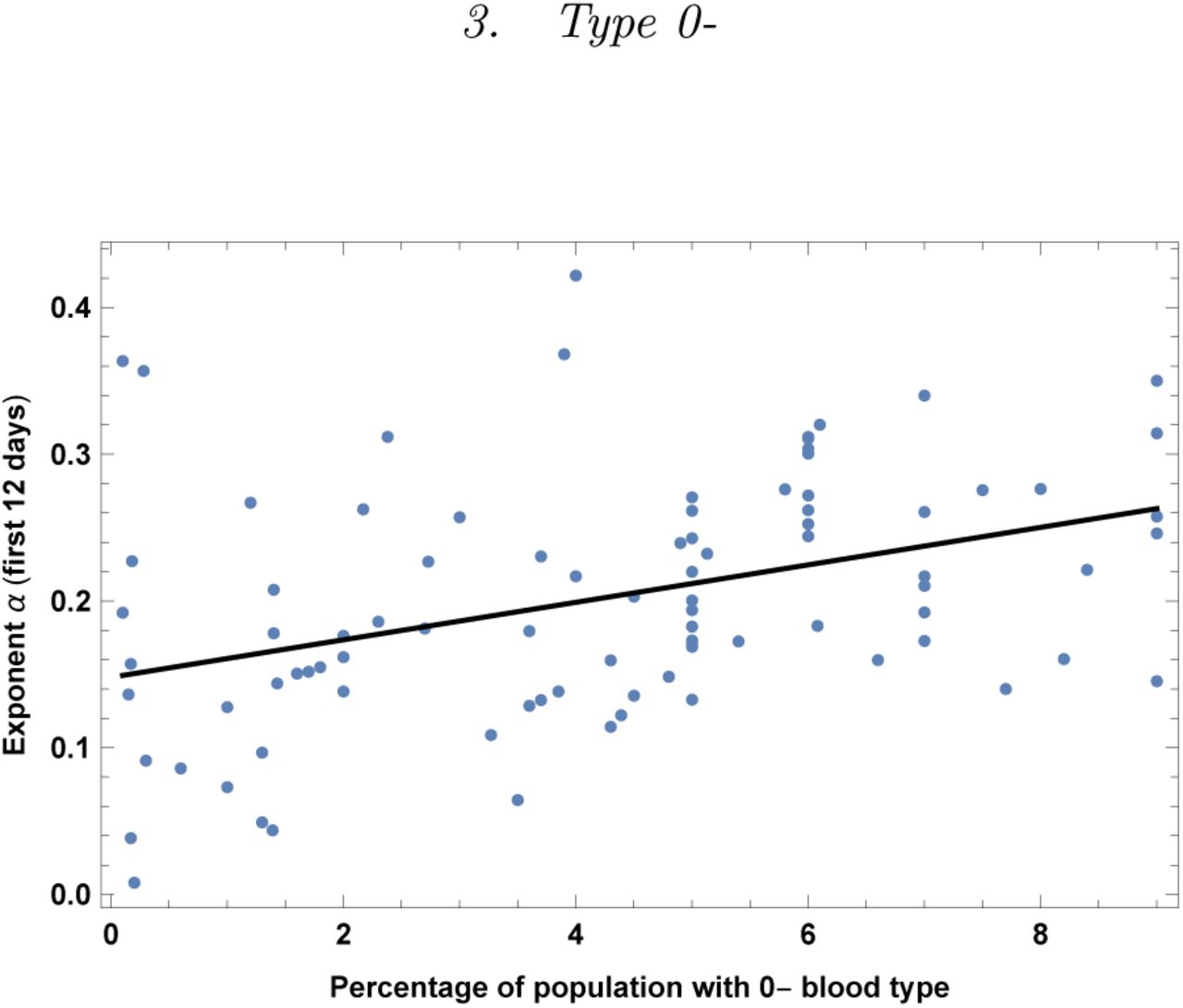
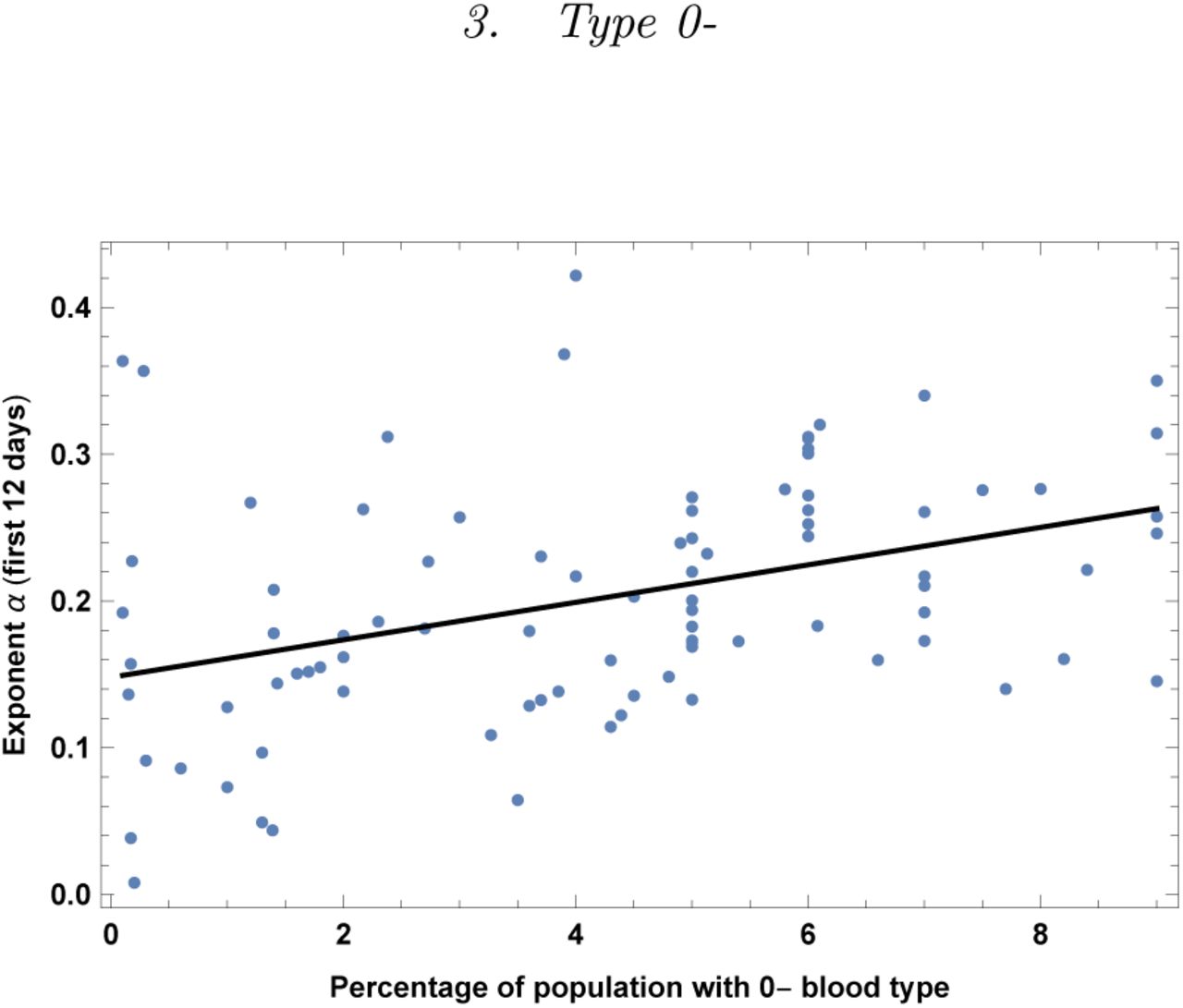
Exponent α for each country vs. percentage of population with blood type 0-. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with blood type 0–. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with 0– and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.

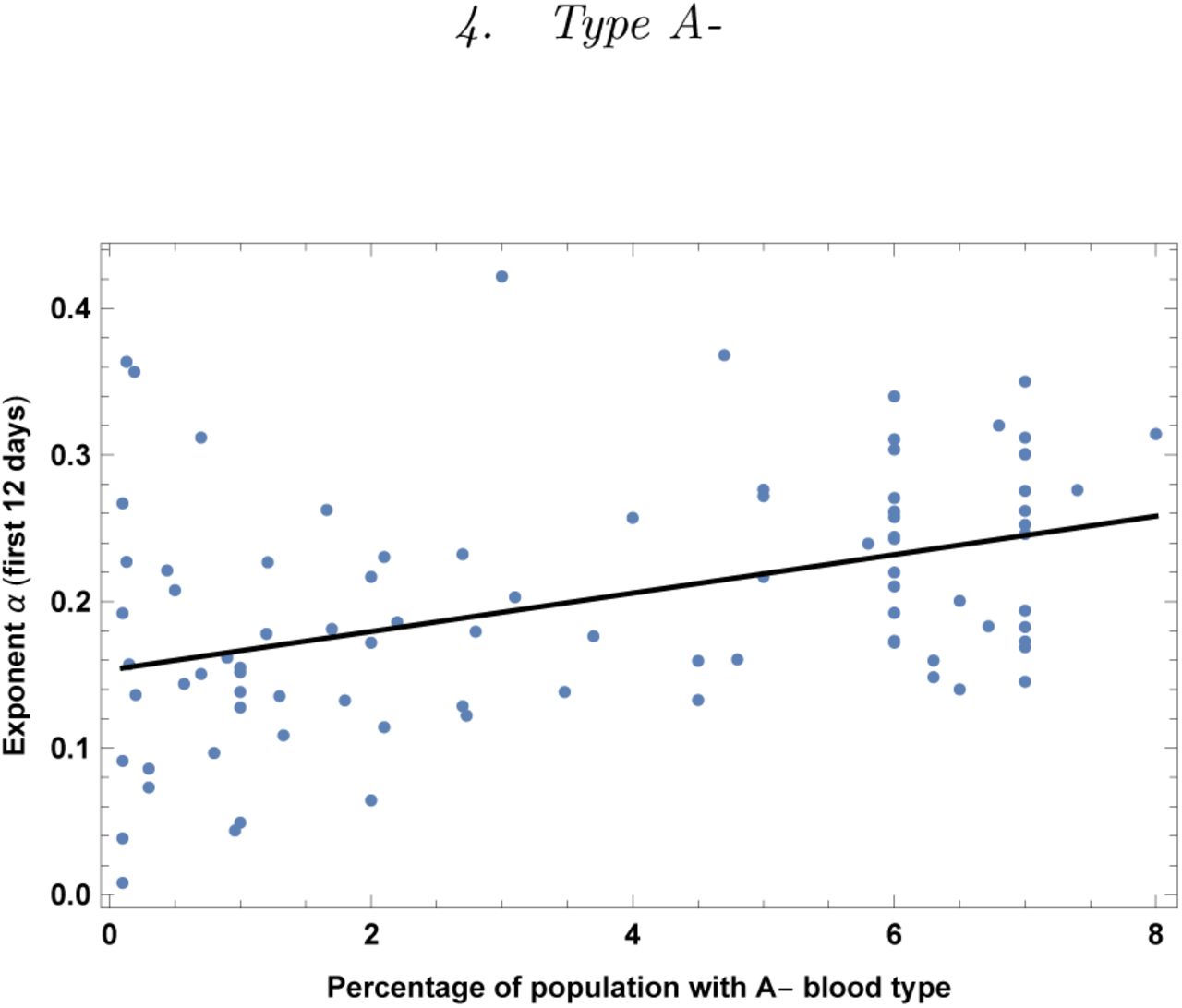
Exponent α for each country vs. percentage of population with blood type A-. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with blood type A-. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with A-and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
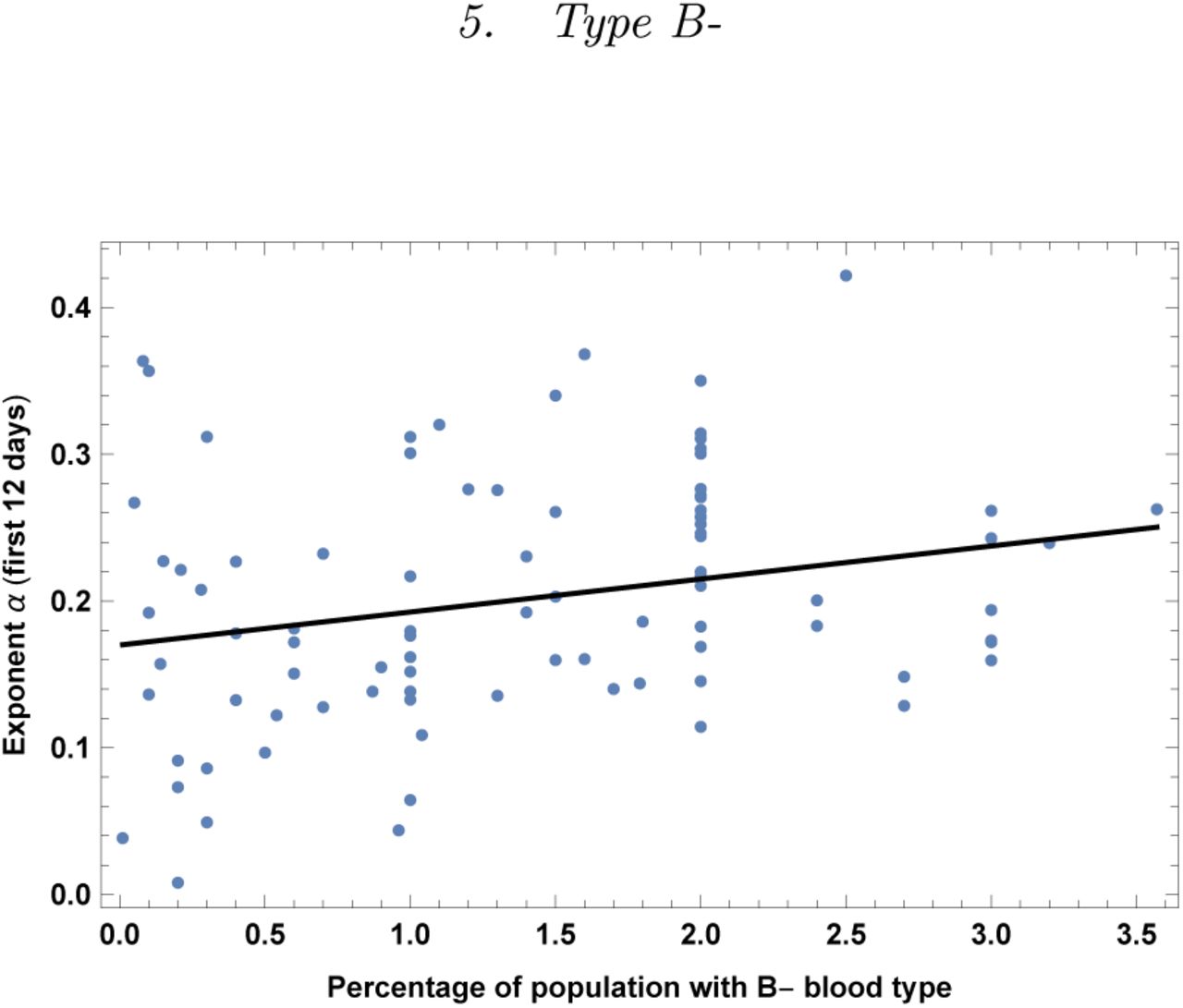
Exponent α for each country vs. percentage of population with blood type B-. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with blood type B-. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with B-and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.

Exponent α for each country vs. percentage of population with blood type AB-. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with blood type AB-. We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with AB-and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.

Exponent α for each country vs. percentage of population with RH-positive blood. We show the data points and the best-fit for the linear interpolation.
In the left top panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation, for correlation of α with percentage of population with RH-positive blood (RH+). We also show the p-value, excluding countries below 5 thousand $ GDP per capita. In the left bottom panel: same quantities for correlation of α with RH+ and GDP per capita. In the right panels: R2 for the best-estimate and number of countries N. We also show the correlation coefficient between the 2 variables in the two-variable fit.
V CROSS-CORRELATIONS
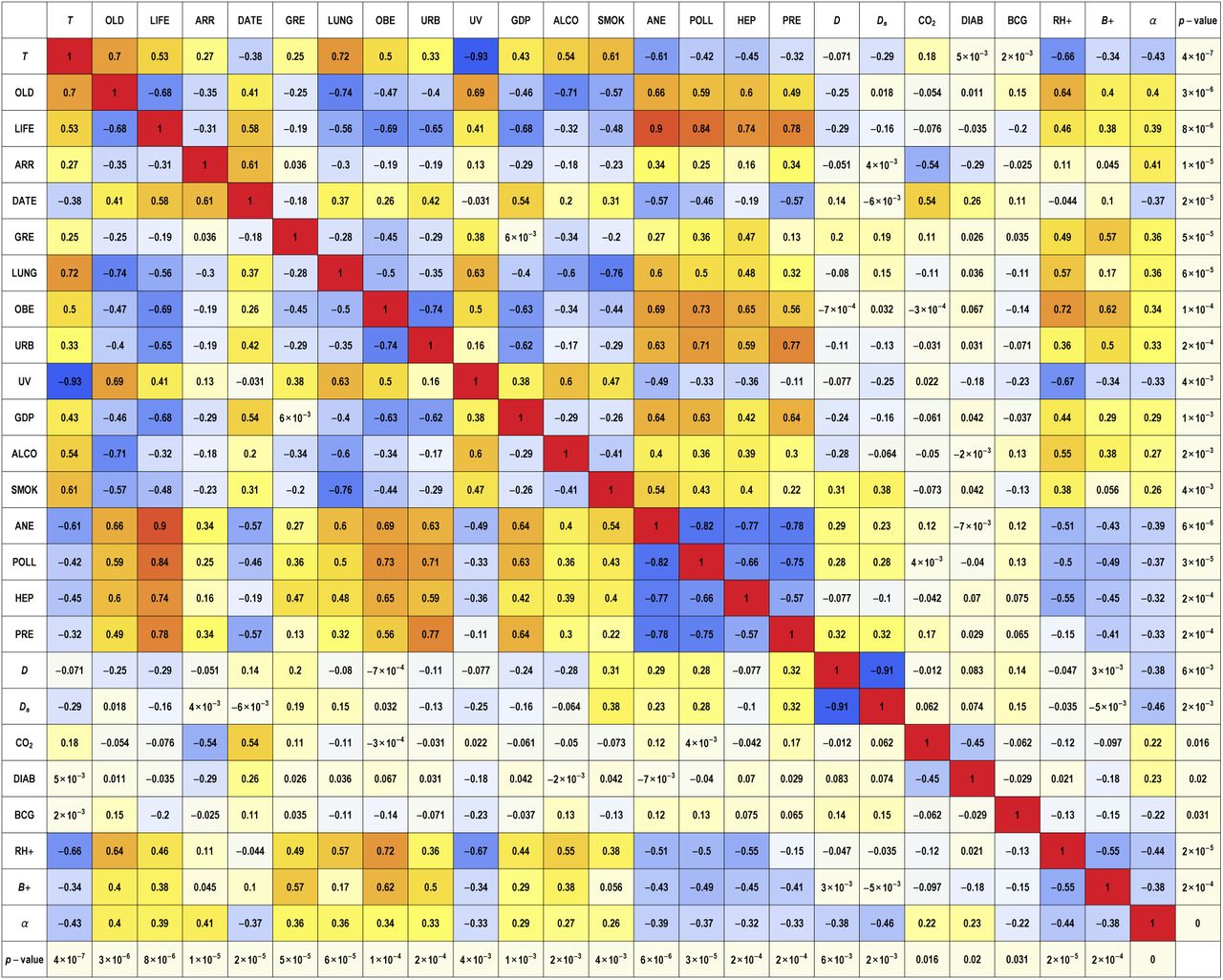
In this section we first perform linear fits of α with each possible pair of variables (excluding the ones which were not significant when combined with GDP per capita and considering only RH+ and B+ for blood types). We show the correlation coefficients between the two variables, for each pair, in Fig. 30. We also show the p-value of the t-statistic of each pair of variables and the total R2 of such fits in Fig. 31.

Correlation coefficients between each pair of variables. Such coefficient corresponds to the off-diagonal entry of the (normalized) covariance matrix, multiplied by −1. In the last column and row we show the p-value of each variable when performing a one-variable linear fit for the growth rate α. Note also that the fits that include vitamin D variables (D and Ds) and UV index are based on smaller samples than for the other fits, as explained in the text. The variables considered here are: Temperature (T), Old age dependency ratio (OLD), Life expectancy (LIFE), Number of tourist arrivals (ARR), Starting date of the epidemic (DATE), Amount of contact in greeting habits (GRE), Lung cancer (LUNG), Obesity in males (OBE), Urbanization (URB), UV Index (UV), GDP per capita (GDP), Alcohol consumption (ALCO), Daily smoking prevalence (SMOK), Prevalence of anemia in children (ANE), Death rate due to pollution (POLL), Prevalence of hepatitis B (HEP), High blood pressure in females (PRE), average vitamin D serum levels (D), seasonal vitamin D serum levels (Ds), CO2 emissions (CO2), type 1 diabetes prevalence (DIAB), BCG vaccination (BCG), percentage with blood of RH+ type (RH+), percentage with blood type B+ (B+).

Significance and R2 for two-variable linear fits of α, with each variable chosen in pairs in each entry. Variables names are the same as in legend of Fig. 30. Each cell in the table gives R2 and the p-value of the each of the two variables, using t-statistic, labeled as pH for horizontal and pV for vertical.
We give here below possible interpretations of the redundancy among our variables and we perform multiple variable fits in the following subsections.α
A. Possible Interpretations
The set of most significant variables, i.e. with smallest p-value, which correlate with faster propagation of COVID-19 are the following: low temperature, high percentage of old vs working people and life expectancy, number of international tourist arrivals, high percentage of RH-blood types, earlier starting date of the epidemic, high physical contact in greeting habits, prevalence of lung cancer. Such variables are however correlated with each other and we analyze them together below. Most other variables are mildly/strongly correlated with the previous set of variables, except for: prevalence of Type-I diabetes, BCG vaccination, Vitamin D levels, which might indeed be considered as almost independent factors.
From the above table one can verify that all the “counterintuitive” variables (death-rate due to pollution, POLL, prevalence of anemia, ANE, prevalence of hepatitis B, HEP, high blood pressure in women, PRE) have a strong negative correlation with life expectancy, LIFE. This offers a neat possible interpretation: since countries with high deaths by pollution or high prevalence of anemia or hepatitis B or high blood pressure in women have a younger population, then the virus spread is slower. Therefore one expects that when performing a fit with any of such variable and LIFE together, one of the variables will turn out to be non-significant, i.e. redundant. Indeed one may verify from Table 31 that this happens for all of the four above variables.
Redundancy is also present when one of the following variables is used together with life expectancy in a 2 variables fit: smoking, urbanization, obesity in males. Also, old age dependency and life expectancy are obviously quite highly correlated.
Other variables instead do not have such an interpretation: BCG vaccination, type-1 diabetes in children and vitamin D levels. In this case other interpretations have to be looked for. Regarding the vaccination a promising interpretation is indeed that BCG-vaccinated people could be more protected against COVID-19 [29-31].
Lung cancer and alcohol consumption remain rather significant, close to a p-value of 0.05, even after taking into account for life expectancy, but they become non-significant when combining with old age dependency. In this case it is also difficult to disentangle them from the fact that old people are more subject to COVID-19 infection.
Blood type RH+ is also quite correlated with T (and with old age dependency ratio), however it remains moderately significant when combined with it.
Finally vitamin D levels, which are measured on a smaller sample, also have little correlations with the main factors and might indeed constitute an independent factor. This factor is also quite interesting, since it may open avenues for research on protective factors. It is quite possible that high levels of Vitamin D have an impact on the immune response to COVID-19 [45-47].
B. Multiple variable fits
It is not too difficult to identify redundant variables, looking at very strongly correlated pairs in Table 30. It is generically harder, instead, to extract useful information when combining more than 2 or 3 variables, since we have many variables with a comparable predictive power (individual R2 are at most around 0.2) and several of them exhibit mild/strong correlations. In the following we perform examples of fits with some of the most predictive variables, trying to keep small correlation between them.
1. Temperature+Arrivals+Greetings
Here we show an example of a fit with 3 parameters.
In the left upper panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation. In the right panels: R2 for the best-estimate and number of countries N. Below we show the correlation matrix for all variables.
2. Temperature+Arrivals+Greetings+Starting date
Here we show an example of a fit with 4 parameters. As we combine more than 3 parameters, typically at least one of them becomes less significant.
In the left upper panel: best-estimate, standard error (σ), t-statistic and p-value for the parameters of the linear interpolation. In the right panels: R2 for the best-estimate and number of countries N. Below we show the correlation matrix for all variables.
3. Many variables fit
One may think of combining all our variables. This is however not a straightforward task, because we do not have data on the same number N of countries for all variables. As a compromise we may restrict to a large number of variables, but still keeping a large number of countries. For instance we may choose the following set: T, OLD, LIFE, ARR, DATE, GRE, LUNG, OBE, URB, GDP, ALCO, SMOK, ANE, POLL, HEP, PRE, CO2. These variables are defined for a sample of N = 102 countries. By combining all of them we get R2 = 0.48, which tells us that only about half of the variance is described by these variables. Moreover clearly many of these variables are redundant. Indeed by diagonalizing the covariance matrix one finds that only about 7 independent linear combinations of the factors are significant.
Rather than reporting such factors, which is not particuarly illuminating, we checked that for instance eliminating the following factors reduces the R2 very little, to about R2 ≈ 0.47: ALCO, SMOK, ANE, POLL, CO2, OBE. Moreover, reducing just to 6 variables, e.g. T, LIFE, ARR, DATE, GRE, LUNG, brings R2 down to about 0.44. Such a choice however is not unique, due to redundancy of our variables.
VI. CONCLUSIONS
We have collected data for countries that had at least 12 days of data after a starting point, which we fixed to be at the threshold of 30 confirmed cases. We considered a dataset of 126 countries, collected on April 15th. We have fit the data for each country with an exponential and extracted the exponents α, for each country. Then we have correlated such exponents with several variables, one by one.
We found a positive correlation with high confidence level with the following variables, with respective p-value: low temperature (negative correlation, p-value 4 · 10−7), high ratio of old people vs. people in the working-age (15-64 years) (p-value 3 · 10−6), life expectancy (p-value 8 · 10−6), international tourism: number of arrivals (p-value 1 · 10−5), earlier start of the epidemic (p-value 2 · 10−5), high amount of contact in greeting habits (positive correlation, p-value 5 · 10−5), lung cancer death rates (p-value 6 · 10−5), obesity in males (p-value 1 · 10−4), share of population in urban areas (p-value 2 · 10−4), share of population with cancer (p-value 2.8 · 10−4), alcohol consumption (p-value 0.0019), daily smoking prevalence (p-value 0.0036), low UV index (p-value 0.004; smaller sample, 73 countries), low vitamin D serum levels (annual values p-value 0.006, seasonal values 0.002; smaller sample, ~ 50 countries).
We find moderate evidence for positive correlation with: CO2 (and SO) emissions (p-value 0.015), type-1 diabetes in children (p-value 0.023), vaccination coverage for Tuberculosis (BCG) (p-value 0.028).
Counterintuitively we also find negative correlations, in a direction opposite to a naive expectation, with: death rate from air pollution (p-value 3 · 10−5), prevalence of anemia, adults and children, (p-value 1 · 10−4 and 7 · 10−6, respectively), share of women with high-blood-pressure (p-value 2 · 10−4), incidence of Hepatitis B (p-value 2 · 10−4), PM2.5 air pollution (p-value 0.029).
As is clear from the figures, the data present a high amount of dispersion, for all fits that we have performed. This is of course unavoidable, given the existence of many systematic effects. One obvious factor is that the data are collected at country level, whereas many of the factors considered are regional. This is obvious from empirical data (see for instance the difference between the epidemic development in Lombardy vs. other regions in Italy, or New York vs. more rural regions), and also sometimes has obvious explanations (climate, health factors vary a lot region by region) as well as not so obvious ones. Because of this, we consider R2 values as at least as important as p-values and correlation coefficients: an increase of the R2 after a parameter is included means that the parameter has a systematic effect in reducing the dispersion (“more data points are explained”).
Several of the above variables are correlated with each other and so they are likely to have a common interpretation and it is not easy to disentangle them. The correlation structure is quite rich and non-trivial, and we encourage interested readers to study the tables in detail, giving both R2, p-values and correlation estimates. Note that some correlations are “obvious”, for example between temperature and UV radiation. Others are accidental, historical and sociological. For instance, social habits like alcohol consumption and smoking are correlated with climatic variables. In a similar vein correlation of smoking and lung cancer is very high, and this is likely to contribute to the correlation of the latter with climate. Historical reasons also correlate climate with GDP per capita.
Other variables are found to have a counterintuitive negative correlation, which can be explained due their strong negative correlation with life expectancy: death-rate due to pollution, prevalence of anemia, Hepatitis B and high blood pressure for women.
We also analyzed the possible existence of a bias: countries with low GDP-per capita, typically located in warm regions, might have less intense testing and we discussed the correlation with the above variables, showing that most of them remain significant, even after taking GDP into account. In this respect, note that in countries where testing is not prevalent, registration of the illness is dependent on the development of severe symptoms. Hence, while this study is about infection rates rather than mortality, in quite a few countries we are actually measuring a proxy of mortality rather than infection rate. Hence, effects affecting mortality will be more relevant. Pre-existing lung conditions, diabetes, smoking and health indicators in general as well as pollution are likely to be important in this respect, perhaps not affecting a per se but the detected amount of α. These are in turn generally correlated with GDP and temperature for historical reasons. Other interpretations, which may be complementary, are that co-morbidities and old age affect immune response and thus may directly increase the growth rate of the contagion. Similarly it is likely that individuals with co-morbidities and old age, developing a more severe form of the disease, are also more contagious than younger or asymptomatic individuals, producing thus an increase in α. In this regard, we wish to point the reader’s attention to the relevant differences in correlations once we apply a threshold on GDP per capita. It has long been known that human wellness (we refer to a psychological happiness study [53], but the point is more general) depends non-linearly on material resources, being strongly correlated when resources are low and reaching a plateau after a critical limit. The biases described above (weather comorbidity, testing facilities, pre-existing conditions and environmental factors) seem to reflect this, changing considerably in the case our sample has a threshold w.r.t. a more general analysis without a threshold.
About pollution our findings are mixed. We find no correlation with generic air pollution (“Suspended particulate matter (SPM), in micrograms per cubic metre”). We find higher contagion to be moderately correlated only with and CO2/SO emissions. Instead we find a negative correlation with death rates due to air pollution and PM2.5 concentration (in contrast with [48]). Note however that correlation with PM2.5 becomes non significant when combined with GDP per capita, while CO2/SO becomes non significant when combined with tourist arrivals. Finally death rates due to air pollution is also redundant when correlating with life expectancy.
Some of the variables that we have studied cannot be arbitrarily changed, but can be taken into account by public health policies, such as temperature, amount of old people and life expectancy, by implementing stronger testing and tracking policies, and possibly lockdowns, both with the arrival of the cold seasons and for the old aged population.
Other variables instead can be controlled by governments: testing and isolating international travelers and reducing number of flights in more affected regions; promoting social distancing habits as long as the virus is spreading, such as campaigns for reducing physical contact in greeting habits; campaigns to increase the intake of vitamin D, decrease smoking and obesity.
We also emphasize that some variables are useful to inspire and support medical research, such as correlation of contagion with: lung cancer, obesity, low vitamin D levels, blood types (higher risk for all RH-types, A types, lower risk for B+ type), type 1 diabetes. This definitely deserves further study, also of correlational type using data from patients.
In conclusion, our findings can thus be very useful both for policy makers and for further experimental research.
Data Availability
All data are publicly available
Acknowledgments
GT acknowledges support from FAPESP proc. 2017/06508-7, partecipation in FAPESP tematico 2017/05685-2 and CNPQ bolsa de produtividade 301432/2017-1. We would like to acknowledge Alberto Belloni, Jordi Miralda and Miguel Quartin for useful discussions and comments.
Appendix A: Vitamin D
We collected most data on vitamin D from [35-39] and from references therein. For a first dataset of 50 countries we have collected annual averages. For many countries several studies with different values were found and in this case we have collected the mean and the standard error (when available) and a weighted average has been performed. The resulting values that we have used are listed in Table XXXII.
Vitamin D serum levels (in nmol/l) obtained with a weighted average from refs. [35-39] and references therein. The “annual” level refers to an average over the year. The “seasonal” level refers to the value present in the literature, which is closer to the months of January-March: either the amount during such months or during winter for northern hemisphere, or during summer for southern hemisphere or the annual level for countries with little seasonal variation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}