
Abstract
Background The rapid spread of coronavirus disease 2019 (COVID-19) revealed significant constraints in critical care capacity. In anticipation of subsequent waves, reliable prediction of disease severity is essential for critical care capacity management and may enable earlier targeted interventions to improve patient outcomes. The purpose of this study is to develop and externally validate a prognostic model/clinical tool for predicting COVID-19 critical disease at presentation to medical care.
Methods This is a retrospective study of a prognostic model for the prediction of COVID-19 critical disease where critical disease was defined as ICU admission, ventilation, and/or death. The derivation cohort was used to develop a multivariable logistic regression model. Covariates included patient comorbidities, presenting vital signs, and laboratory values. Model performance was assessed on the validation cohort by concordance statistics. The model was developed with consecutive patients with COVID-19 who presented to University of California Irvine Medical Center in Orange County, California. External validation was performed with a random sample of patients with COVID-19 at Emory Healthcare in Atlanta, Georgia.
Results Of a total 3208 patients tested in the derivation cohort, 9% (299/3028) were positive for COVID-19. Clinical data including past medical history and presenting laboratory values were available for 29% (87/299) of patients (median age, 48 years [range, 21-88 years]; 64% [36/55] male). The most common comorbidities included obesity (37%, 31/87), hypertension (37%, 32/87), and diabetes (24%, 24/87). Critical disease was present in 24% (21/87). After backward stepwise selection, the following factors were associated with greatest increased risk of critical disease: number of comorbidities, body mass index, respiratory rate, white blood cell count, % lymphocytes, serum creatinine, lactate dehydrogenase, high sensitivity troponin I, ferritin, procalcitonin, and C-reactive protein. Of a total of 40 patients in the validation cohort (median age, 60 years [range, 27-88 years]; 55% [22/40] male), critical disease was present in 65% (26/40). Model discrimination in the validation cohort was high (concordance statistic: 0.94, 95% confidence interval 0.87-1.01). A web-based tool was developed to enable clinicians to input patient data and view likelihood of critical disease.
Conclusions and Relevance We present a model which accurately predicted COVID-19 critical disease risk using comorbidities and presenting vital signs and laboratory values, on derivation and validation cohorts from two different institutions. If further validated on additional cohorts of patients, this model/clinical tool may provide useful prognostication of critical care needs.
Introduction
The exponential spread of coronavirus disease 2019 (COVID-19) has revealed constraints in critical care capacity around the globe.1,2 While there are early indications that social distancing measures have resulted in decreased transmission (i.e., “flattening the curve”), there is concern that subsequent pandemic waves may occur. Accurate and rapid patient prognostication is essential for critical care utilization management. Early identification of patients likely to develop critical disease may facilitate prompt intervention and improve outcomes.
Early reports suggest severe disease and poor outcomes are associated with older age, male sex, and comorbidities including hypertension, diabetes, and coronary artery disease.3–6 Recent case series from the United States and France have additionally reported obesity is associated with hospitalization and worse COVID-19 disease.7–10 Several attempts have been made to develop prognostic models for COVID-19 disease, largely based on early data from patient cohorts in China.11–18 These models have used demographic features, including age, sex, and comorbidities, and a limited set of laboratory values including lymphocyte count, lactate dehydrogenase (LDH), C-reactive protein (CRP), which have been reported to be associated with more severe disease.19,20 These initial models are of variable quality, with a high likelihood of biases and limited numbers of variables, and performance evaluation is limited by suboptimal reporting and limited validation.21
This study describes the development and external validation of a multivariate regression model and associated clinical tool to predict risk of COVID-19 critical disease, presented utilizing TRIPOD (transparent reporting of a multivariable prediction model for individual prognosis or diagnosis) reporting guidelines.22
Methods
Study Design and Population
The prognostic model was developed with data from a single-center retrospective observational cohort study of sequential patients with COVID-19 disease diagnosed by nucleic acid detection from nasopharyngeal or throat swabs at the University of California, Irvine Medical Center (UCI Health) from March 1, 2020 to April 31, 2020 (derivation cohort). UCI Health is a 411-bed academic medical center located in Orange County, California which performed outpatient, emergency department, and inpatient COVID-19 testing throughout the study period.
The model was validated with a separate retrospective observational cohort of patients with COVID-19 disease at Emory Healthcare (validation cohort). Emory Healthcare is a multi-hospital 1500-bed academic system located in Atlanta, Georgia which performed outpatient, emergency department, and inpatient COVID-19 testing throughout the study period. Patients in the validation cohort were randomly selected from a radiology database of patients who underwent imaging with a clinical concern for COVID-19 disease from March 12, 2020 to April 7, 2020 and were diagnosed with COVID-19 by nucleic acid detection from nasopharyngeal swabs.
Data was obtained by manual chart review of the electronic health record. Clinical and laboratory values were obtained from the earliest documented result at the time of presentation. If a specific laboratory value was not initially available, the value occurring in time closest after presentation was used. If no value was obtained for a patient during the admission, it was marked as “missing”. Data collection and validation were performed in accordance with the Institutional Review Board at each institution. Only de-identified data was transmitted between institutions. This study followed the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD) reporting guidelines.22
Outcome
The primary outcome was the likelihood of critical disease, defined as meeting the criteria of ICU admission, ventilation, and/or death. The initial index date for each patient was the date of COVID-19 diagnosis. All patients had follow-up of outcomes for a minimum of 10 days.
Statistical Analysis
Developing the Prediction Model
We searched the literature for predictors of COVID-19 disease severity and identified the following candidate predictors: demographic characteristics (age, sex), presenting vital signs (temperature, heart rate, respiratory rate, systolic blood pressure, diastolic blood pressure, body mass index), past medical history (hypertension, diabetes, cardiovascular disease, coronary artery disease, asthma, chronic kidney disease, metabolic syndrome [as defined by consensus criteria]23, and total number of these comorbidities), and presenting laboratory values (white blood cell count, lymphocyte percentage, serum creatinine, aspartate aminotransferase [AST], lactate dehydrogenase [LDH], C-reactive protein [CRP], procalcitonin, ferritin, troponin I, d-dimer, triglycerides, and high density lipoprotein [HDL]).
Two-sided t-tests were used for continuous variables and Pearson’s chi-squared test (χ2) was used for categorical variables to assess for differences in each candidate predictor based on critical disease status. Based on these results and prevalence of candidate predictor, the top thirteen covariates were chosen and used to create multivariable logistic regression model. For missing data, median imputation was performed based on underlying critical disease status. Each covariate was independently normalized to a scale of [0, 1] based on minimum and maximum values present in the dataset. The model was implemented using L2 regularization and optimized using the limited memory Broyden–Fletcher–Goldfarb–Shanno (BFGS) technique. Finally, a Wald chi-squared test was used to evaluate the contribution from each variable.
Validating the Prediction Model
The predictive accuracy of the model was determined retrospectively in the external validation cohort with discrimination and calibration. For any given patient, missing data was imputed using population-derived median values from the training cohort. Additionally, all model inputs were clipped to the minimum and maximum values present in the training cohort. Model discrimination (i.e., the degree to which the model differentiates between individuals with critical and non-critical outcomes) was calculated with the C statistic. All analyses were conducted using the Python scikit-learn library (0.22.2)24 and IBM SPSS Statistics Subscription, version 1.0.0.1012 (IBM Corp., Armonk, N.Y., USA).
Developing a Clinical Tool
A web-based application was created in Python using a Flask server (1.1.1) to facilitate clinical implementation of the trained model.
Results
For the derivation cohort, a total of 3,208 COVID-19 tests were conducted over the study period, of which 9.3% (299/3208) were positive. Clinical data including past medical history and presenting laboratory values were available for 29.1% (87/299) patients (median age, 48 years [range, 21-88 years]; 64.4% [56/87] male). (Figure 1). Most common comorbidities included obesity (35.6%, 31/87), hypertension (36.8%, 32/87), and diabetes (24%, 24/87). Critical disease was present in 24.1% (21/87).
For the derivation cohort, a total of 3,208 COVID-19 tests were conducted over the study period, of which 9.3% (299/3208) were positive. Of positive patients, laboratory data was available for 29.1% (87/299) patients.
Of a total of 40 patients in the validation cohort (median age, 60 years [range, 27-88 years]; 55% [22/40] male), critical disease was present in 65% (26/40). Most common comorbidities included obesity (53%, 21/40), hypertension (60%, 24/40), and diabetes (40%, 16/40). Characteristics between the derivation and validation cohorts were notable for increased prevalence of comorbidities in the validation cohort.
After feature selection, the following factors associated with greatest increased risk of critical disease were used in model training: age, gender, total number of comorbidities (which included cardiovascular disease, coronary artery disease, chronic kidney disease, asthma/chronic obstructive pulmonary disease, diabetes mellitus, hypertension, and obesity), BMI, respiratory rate, white blood cell count, lymphocyte percentage, creatinine, lactate dehydrogenase (LDH), troponin I, ferritin, procalcitonin, and C-reactive protein (CRP) (Table 1).
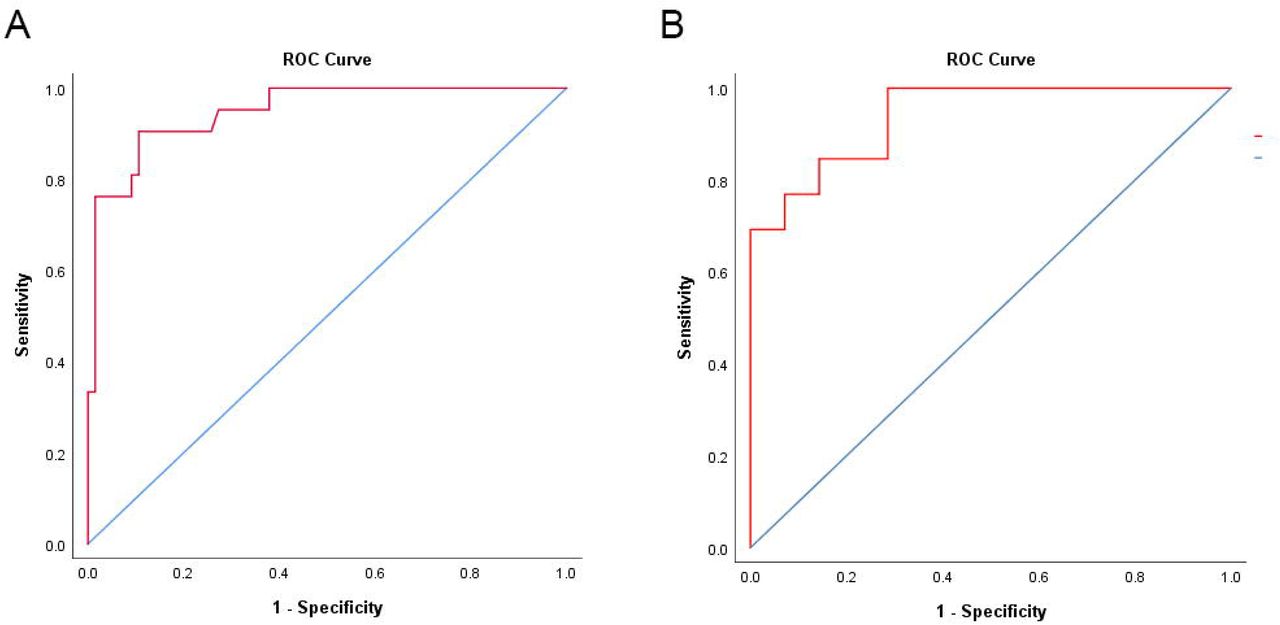
Model discrimination in the derivation cohort was high (concordance statistic: 0.948, 95% confidence interval 0.900-0.997);); with the best logistic regression score cut point at 30%, sensitivity was 90.4%, specificity was 89.4%, positive predictive value was 73.0%, and negative predictive value was 96.7%.
Model discrimination in the validation cohort was also high (concordance statistic: 0.940, 95% confidence interval 0.870-1.009); with the same 30% logistic regression cut point, sensitivity was 100%, specificity was 71.4%, positive predictive value was 86.7%, and negative predictive value was 100% (Figure 2). Procalcitonin was unavailable for all patients. The average number of missing variables was 1.33 (range 1-3) for cases that were correctly predicted as critical or non-critical and 2.11 (range 1-5) for cases that were incorrectly predicted.

Model discrimination for the derivation cohort (A) was (concordance statistic: 0.948, 95% confidence interval 0.900-0.997) and validation cohort (B) was (concordance statistic: 0.940, 95% confidence interval 0.870-1.009).
A web-based tool was developed to enable clinicians to input patient data and view model output (Figure 3). The page accepts user input and outputs a likelihood of critical disease and does not require all variables to be present.

{kind=link}
{kind=link}
{kind=link}
Discussion
In this study, we developed and externally validated a predictive model and clinical tool that can be used to prognosticate the likelihood of COVID-19 critical disease based on data available early in a patient’s presentation.
By using derivation and validation cohorts from separate institutions with different underlying patient characteristics, in particular a higher prevalence of comorbidities in the validation cohort, we achieved high calibration and discrimination. This model has the potential to be utilized by front-line healthcare providers to predict critical care demand and provide early indications of likelihood a patient’s condition may worsen. As therapeutic interventions become validated, this may enable early intervention in at-risk patients to improve outcomes. In particular, antiviral therapies may have increased efficacy if administered earlier in the disease course.
Compared with other earlier models, which were primarily single institution-based, were developed from patient cohorts in China, utilized only a few variables, and did not include subsequently identified risk factors such as number of comorbidities and obesity,7–10 this model may have greater relevance and predictive strength in cohorts of Western patients in which obesity is more common. In particular, the inclusion of nearly 30 candidate variables in model derivation ensures sufficient consideration to numerous previously identified prognostic correlates.
Interestingly, variables which have previously been reported to be associated with worse COVID-19 disease, most notably including older age and hypertension, were less predictive in our sample than body mass index, total number of comorbidities and several laboratory values. The tool performed well in the validation set even though there was a higher rate of missing data for some values such as procalcitonin and ferritin, which were not frequently performed at the validation institution. In settings in which laboratory data is easily and rapidly acquired, this study suggests there may be value to establishing a panel of COVID-19-specific laboratory studies including lactate dehydrogenase, troponin I, ferritin, procalcitonin, and C-reactive protein (in addition to commonly acquired complete blood count and serum chemistries).
Front-line medical providers have been inundated with critically ill COVID-19 patients. A simple web-based tool utilized at patient presentation may facilitate decision making by simplifying integration of numerous clinical variables. Our model has a high negative predictive value, which can increase physician confidence in determining which patients may be discharged safely at presentation. This is of particular utility in settings of high healthcare utilization, especially when physicians are treating higher than expected numbers of patients and/or working outside of their standard practice. Our model has high positive predictive value, highlighting those patients for whom admission and close clinical monitoring may be appropriate.
The chosen cutoff point of 30% based on the derivation cohort performs with 100% sensitivity and 71.4% specificity in the validation cohort that included more critical patients. In most circumstances, identifying all cases of critical disease is preferred even if some less critical patients are identified, but in certain situation such as a surge in which critical care resources are limited, the cutoff point could be adjusted to a desired balance of sensitivity and specificity.
Limitations
This study has limitations. A limited small sample of patient data was reviewed retrospectively from two centers. As data was obtained retrospectively, there was no control over which laboratory data was collected, which varied with institutional practice patterns. However, the model performed well in a validation data set with incomplete laboratory values. Further testing on larger cohorts of patient data is needed. Conclusions may not be globally generalizable to different patient cohorts.
Conclusions
We present a predictive model and clinical tool which can be used to prognosticate the likelihood of COVID-19 critical disease based on data at patient presentation. Further testing is needed on larger patient cohorts to establish generalizability. In subsequent analyses, we intend to evaluate whether this model can be applied to daily trends of clinical data in admitted patients to predict patient disposition.
Data Availability
Data is available pending appropriate IRB requests to the University of California, Irvine.
References



