
Abstract
Objective To develop a machine learning (ML) risk stratification model for predicting all-cause mortality and cardiovascular mortality while estimating the influence of lifestyle behavioral factors on the model’s efficacy.
Method A prospective cohort study was conducted using a nationally representative sample of adults aged 40 years or older, drawn from the US National Health and Nutrition Examination Survey from 2007 to 2010. The participants underwent a comprehensive in-person interview and medical laboratory examinations, and subsequently, their records were linked with the National Death Index for further analysis.
Result Within a cohort comprising 7921 participants, spanning an average follow-up duration of 9.75 years, a total of 1911 deaths, including 585 cardiovascular-related deaths, were recorded. The model predicted mortality with an area under the receiver operating characteristic curve (AUC) of 0.848 and 0.829. Stratifying participants into distinct risk groups based on ML scores proved effective. All lifestyle behaviors exhibited an inverse association with all-cause and cardiovascular mortality. As age increases, the discernible impacts of dietary scores and sedentary time become increasingly apparent, whereas an opposite trend was observed for physical activity.
Conclusion We develop a ML model based on lifestyle behaviors to predict all-cause and cardiovascular mortality. The developed model offers valuable insights for the assessment of individual lifestyle-related risks. It applies to individuals, healthcare professionals, and policymakers to make informed decisions.
Introduction
Cardiovascular disease (CVD) poses a formidable challenge to global health, contributing significantly to non-communicable diseases (NCDs) and representing a leading cause of mortality worldwide1,2. According to data from the World Health Organization (WHO), cardiovascular disease contributes to deaths of nearly one million people in the United States, accounting for 30% of the total annual mortality3. The escalating prevalence of CVD over the past few decades underscores the urgency of identifying effective preventive measures. Extensive research has elucidated a link between modifiable lifestyles and cardiovascular mortality.4–7 The inherent modifiability of lifestyle renders it of considerable practical significance as a predictive model factor. Through model prediction, the population can be informed of the current level of risk in their lifestyle and effectively promote their transition to a healthier lifestyle. However, traditional statistical methods exhibit limitations in establishing predictive models, struggling to effectively handle the intricate interaction between numerous variables.
Machine learning (ML), with its ability to analyze vast and complex datasets, presents a compelling solution to the limitations of traditional methods in unraveling the multifaceted associations between lifestyle choices and mortality outcomes8. Unlike conventional statistical models that rely on predefined hypotheses and assumptions, ML algorithms can identify intricate patterns and nonlinear relationships within data, offering a more holistic and data-driven perspective9,10. In recent times, an increasing number of studies have applied ML in the field of cardiovascular disease.11,12. This becomes particularly crucial in the realm of cardiovascular health, where the impact of diverse lifestyle factors may manifest in subtle and interconnected manners.
The NHANES dataset holds a distinct advantage due to its comprehensive inclusion of health, lifestyle, and biochemical information, providing a rich data source for analysis13–15. Implementing of high-quality standardized collection and testing procedures effectively mitigates the potential for measurement bias, ensuring the reliability of the data. This robust data quality, coupled with a wealth of information, facilitates in-depth exploration of the intricate relationship between lifestyle and both cardiovascular and all-cause mortality, offering a reliable and comprehensive foundation for unraveling the complexities inherent in this association.
This study endeavors to establish a predictive model for mortality related to lifestyle factors and aims to delve into the intricate role of these lifestyle factors using ML models.
Method
The prospective cohort were derived from the National Health and Nutrition Examination Survey (NHANES), a nationwide survey conducted biennially since 1999. All NHANES protocols received approval from the National Center for Health Statistics ethics review board, and written informed consent was obtained from all participants. The modeling survey was deemed exempt from further review.
Study Population
The sample population was derived from the NHANES cycles of 2007-2008 and 2009-2010. We selected participants aged over 40 who participated in in-person interview, physical examinations and laboratory tests in a mobile examination center. The screening process is shown in Supplementary Figure 1.
Study outcomes
The follow-up data was obtained from the National Health Data Center, which links the NHANES survey population with the death records of the National Death Index (NDI).
Cardiovascular mortality was determined using the International Statistical Classification of Diseases, 10th Revision (ICD-10), and the NCHS classified cardiovascular diseases (054-068, 070). We linked participants with the 2019 mortality data records and excluded individuals whose follow-up years and survival status could not be ascertained.
Model features
The model encompassed a set of features including age, gender, race, BMI, education level, income, hypertension, diabetes, family history of diseases, non HDL-cholesterol, C-reactive protein, diet score, physical activity level, Sedentary minutes, sleep quality, alcohol consumption and smoking status. Age, gender, race, education level, income, and history of close family diseases can be directly obtained from interview data. BMI was derived from physical examination data, while non-HDL cholesterol and C-reactive protein values were obtained from laboratory test data. Sedentary minutes were acquired through the physical activity questionnaire.
NHANES contains a wealth of nutrition information gathered through health interviews, health examinations, and laboratory testing. Participants underwent a 24-hour dietary recall (First Day) interview as part of their health examination at the mobile examination center. Subsequently, they were instructed to complete a second 24-hour dietary recall (Second Day) interview within a period of 3 to 10 days following the initial recall. To rate the dietary patterns of participants, the following steps were taken: linking to the Food Patterns Equivalents Database (FPED) of the US Department of Agriculture based on the USDA code of the food, estimating the daily nutritional intake of participants based on the 24-hour dietary recall on the first day and the 24-hour dietary recall on the second day, and referencing the US Dietary Guidelines 2020-2025 and the scoring rules of the Healthy Eating Index (HEI) to assess and rate the dietary patterns of participants.
Physical activity was obtained from NHANES’s physical activity questionnaire. The questionnaire contains the information on the weekly exercise intensity and corresponding time reported by the participants. Participants were classified into four (4) groups based on the 2nd edition of the Physical Activity Guidelines for Americans. The "Inactive" group comprised individuals not involved in any moderate- or vigorous-intensity physical activity beyond basic daily life movements. Those deemed "Insufficiently active" engaged in some moderate- or vigorous-intensity physical activity but did not reach the threshold of 150 minutes of moderate-intensity activity per week, or 75 minutes of vigorous-intensity activity, or the equivalent combination. The "Active" category encompassed participants achieving the equivalent of 150 to 300 minutes of moderate-intensity physical activity weekly, meeting the key guideline target range for adults. Lastly, the "Highly active" group included individuals undertaking more than 300 minutes of moderate-intensity physical activity weekly, surpassing the key guideline target range for adults.
Due to the J-shaped association between sleep duration and all-cause mortality, participants were divided into three groups based on sleep duration: optimal (6-8 hours/day), intermediate (5-5.9 or 8.1-10 hours/day), and poor (<5 or >10 hours/day)6,16.
Smoking status was categorized into three groups: non-smokers, individuals who smoked previously, and those who reported current smoking based on responses to the cigarette use questionnaire. Data on alcohol consumption was derived from alcohol use questionnaire, wherein participants provided information on the frequency and quantity of drinks consumed. The average daily alcohol consumption was used to measure the level of alcohol consumption among participants.
Variables related to mental health exhibiting missing values exceeding 40% were excluded from the analysis. Subsequently, the random forest (RF) algorithm was employed to impute missing values in the remaining dataset. In order to mitigate the influence of dimensionality and enhance modeling efficiency, continuous variables were rescaled and standardized. The data distribution before imputation is presented in Supplementary Table 1 & 2.
Model development and Risk stratification
A binary classification model was constructed based on follow-up data and participant features to predict mortality. Model development included trials of various ML classifiers, including logistic regression, ridge regression, support vector machines, random forest and Extreme Gradient Boosting (XGBoost). The initial step involved cross validation on the selected models to determine the approximate range of optimal values for each parameter followed by deployment of the grid search method to select the best model through 10-fold cross validation approach. To assess the performance of each model receiver operating curve (ROC) and the corresponding area under the curve (AUC) values were computed. The model output was calibrated using Platt’s scaling and the impact of this calibration was visualized by comparing the Brier score between the uncalibrated and the calibrated outputs.
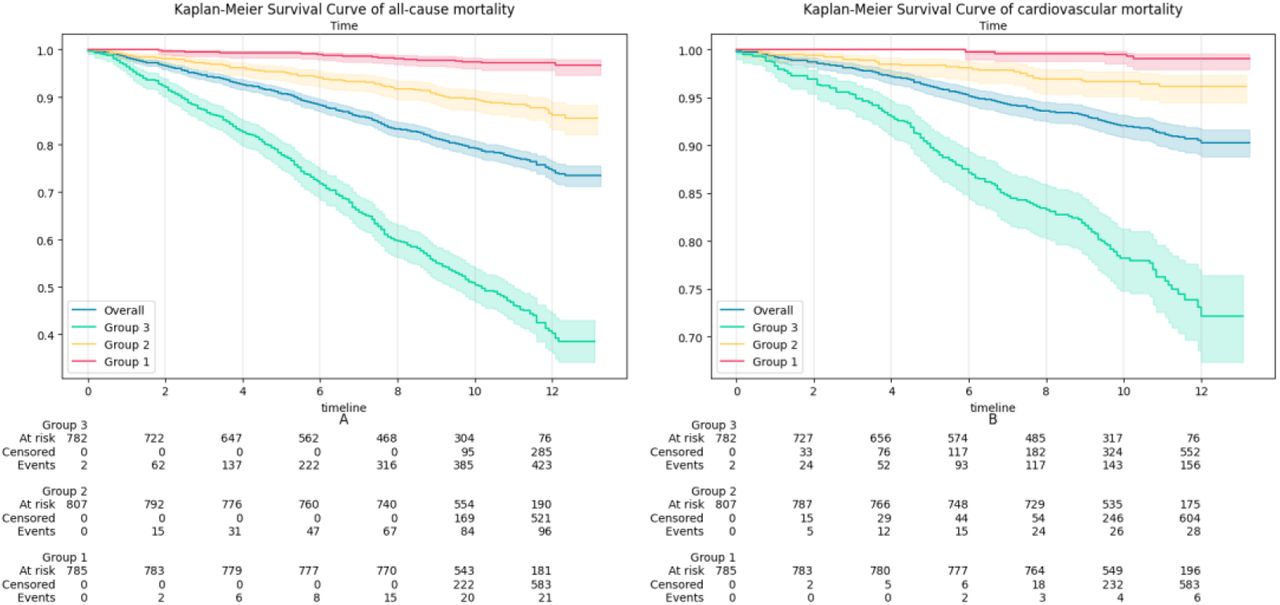
Participants were stratified into three groups based on the tertiles of the ten-year survival probability predicted by the model. The discriminative ability of the model was further validated by employing the log-rank test to compare the survival curves among these groups.
Feature importance based on machine learning models
To estimate feature importance ranking, as well as main effect of features and interaction effect between features, SHAP (Shapley Additive explanations) was employed. The SHAP is a useful and classical method to calculate the marginal contribution of features to the model’s output. This method provides insight from both global and local perspectives, particularly beneficial for interpreting "black box model".
Result
Baseline characteristics
The cohort consisted of 7921 participants, with average age of 60.79±12.18, and 3866(48.81%) males. During an average follow-up period of 9.75 years, there were 1,911 deaths (24.13%), with 585 cases attributed to cardiovascular diseases. The detailed information was shown in the Table 1. In terms of lifestyle, there are differences between the all-cause mortality group and the cardiovascular disease mortality group and the alive group.
Performance of models
Table 2 presents the AUC scores for all models in predicting all-cause mortality and cardiovascular disease mortality. XGBoost demonstrated notable performance, achieving an AUC score of 0.848 for predicting all-cause mortality and 0.829 for predicting cardiovascular disease mortality, establishing it as the top-performing model. The grid search parameters dictionary and the optimal parameter values were displayed in the Supplementary Table 2. Following calibration, there was an improvement in Brier scores, and detailed information was described in the Supplementary Table 3. Figure 1 shows the calibrated and uncalibrated AUC scores of the XGBoost model. The calibrated score was 0.884, indicating that the model fits the data well.

uncalibrated and calibrated ROC of XGBoost model
Machine learning-based risk stratification
Depends on the calibrated output, participants were divided into three groups. Each group survival curve was shown in Figure 2. It can be seen from Supplementary Table 4 that there are significant differences in the survival curves for each group. This demonstrates that the model effectively distinguishes individuals with different risks of mortality.

KM-curves of all groups based on tertiles
Features importance and Features’ Role in the Model
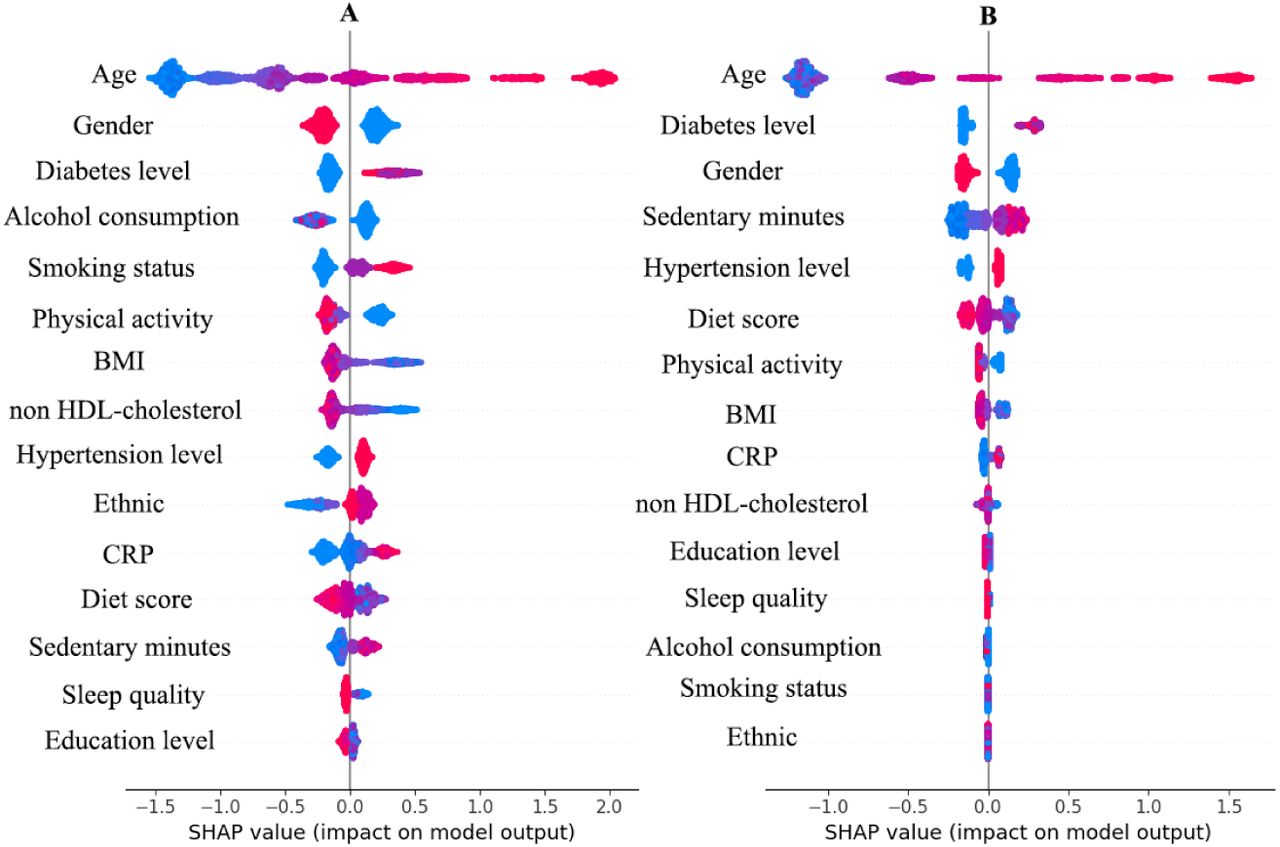
In the prediction of both all-cause mortality and cardiovascular disease mortality, age, gender, and diabetes status have made significant contributions to the predictive outcomes (Figure 3). In terms of lifestyle, smoking, alcohol consumption, and physical activity emerge as significant features exerting a substantial impact on the prediction of all-cause mortality. On the other hand, the model indicates that, reduced sedentary time, higher dietary scores, and increased physical activity in the model will lower individual risk scores.

The importance and role of features in the model
Figure 3 illustrates the importance of features in the model, wherein each scatter represents a sample.
The importance increases from bottom to top, with color representing the numerical value of the feature. The x-axis represents the role of different values of each feature in the model, with positive values indicating that the feature increases the probability of the model making death predictions.
Plot A : SHAP value of features in predicting all-cause mortality. Plot B: SHAP value of features in predicting in cardiovascular mortality.
Features interaction effect
Given the prominent role of age in the model predictions, it is essential to further explore the interaction between age and various lifestyle factors. As shown in Figure 4, the impact of diet score and sedentary time on outcome prediction becomes more pronounced with advancing age, while the impact of physical activity level exhibits an opposite trend.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
dependence plot interaction effect with age
The figure illustrates the interaction between features and age. Each scatter point along a line perpendicular to the x-axis represents the SHAP values of features sharing the same x-value but varying age values. In the visualization, color represents the value of age, transitioning from blue to red as age increases. The y-axis corresponds to the SHAP values of features at different age values.
A,B and C represent SHAP value of diet score, sedentary time and physical activity level in predicting all-cause mortality. D,E and F represent shap value of diet score, sedentary time and physical activity level in predicting cardiovascular mortality.
Discussion
In this prospective cohort spanning an average of 9.75 years, a model was developed and validated to predict both the all-cause mortality and cardiovascular mortality based on the comprehensive dataset encompassing lifestyle data and basic characteristic variables. In addition, the effect of lifestyles on all-cause mortality and cardiovascular mortality and their interaction effect with age were estimated using SHAP. These estimates indicate that lifestyle affects outcome predictions to varying degrees and exhibits diverse patterns in interaction with age.
Simultaneously interpreting multiple risk factors for individual outcomes poses a challenge for the general public, as well as for healthcare professionals and policymakers. By employing ML algorithms, we established a predictive model related to lifestyle and further explored the contributions of diverse factors to survival outcomes. The results indicate that our model performs effectively and can unveil the roles of less influential predictive factors within the model. Additionally, the potential impact of complex and subtle interactions among predictive factors is often overlooked. The inherent advantages of tree models, coupled with their integration with SHAP, allowed for exploring interactions among various predictive factors.
According to the report from the Physical Activity Guidelines for Americans 2nd edition, there is a positive correlation between sedentary time and all-cause mortality17. A prospective survey study from NHANES reveals that, with the prolongation of sedentary time, the risk of all-cause mortality also increases18. Similarly, a longitudinal survey study conducted in China also identified an association between sedentary behavior and all-cause mortality19. In our model, sedentary behavior contributes to the model’s inclination to predict adverse events, consistent with previous research. Furthermore, we found that sedentary behavior has a stronger impact on cardiovascular mortality, ranking higher in feature importance analysis. The relationships between lifestyle factors such as physical activity20, diet21, sleep22, and both all-cause mortality and cardiovascular mortality have been described in detail in previous literature and is consistent with our findings. Overall, machine learning models and traditional models have drawn similar conclusions regarding the relationship between lifestyle factors and mortality.
Beyond lifestyle factors, age and gender, two fundamental demographic characteristics, play a significant role in the model. While a minority of studies may suggest that the role of age in their models is not statistically significant, the prevailing body of research, including our findings, consistently indicates that age plays a non-negligible role in outcome prediction23,24. Studies in various countries and regions consistently indicate that females tend to have lower mortality rates or death risks compared to males25–27. This finding is also reflected in our model, where the male gender feature inclines the model toward predicting a higher likelihood of death. This may be attributed to a higher proportion of females adopting healthier lifestyles compared to males28. Additionally, relatively higher estrogen levels in females may contribute to maintaining healthy vascular function29. Moreover, females might be more inclined to proactively address health issues and seek early treatment30.
Leveraging the advantages of tree-based models in exploring interactions in machine learning31, we conducted additional analysis to scrutinize the interactions between various lifestyle factors and age. We discovered some phenomena worth discussing by exploring interactions in the model through SHAP (Shapley Additive explanations).. For example, as age increases, the impact of diet and sedentary behavior on adverse outcome events gradually strengthens, while the effect of physical activity diminishes. Specifically, the gap between recommended and not recommended diet and sedentary behaviors widens across different age groups, while the gap between recommended and not recommended physical activities gradually narrows. Given the limited literature on the interaction between lifestyle and age, more research is needed to confirm this finding. The occurrence of this finding may be attributed to the insufficient granularity in the categorization of physical activity. We classified physical activity as a categorical variable with four levels. However, as participants age, although their physical activity levels decrease, they still fall within the same category as relatively younger individuals, resulting in attenuation of its impact. This can be observed in Supplementary Table 7; as age increases, the average exercise time in the same physical activity group gradually decreases. However, this does not imply that the role of physical activity can be disregarded in the elderly population. One reason is that low physical activity levels can exacerbate the adverse effects of sedentary behavior32,33.
There are countless factors associated with mortality outcomes, and it’s not practical to include all relevant variables in a predictive model. While lifestyle may not be the most significant factor in outcome prediction among many related variables, it possesses an excellent feature—modifiability. Policymakers or healthcare professionals can raise public awareness and guide individuals toward healthier lifestyles through various means such as education and outreach. Our model enables users to predict mortality based on their current conditions, serving as a warning and reminder. This functionality assists users in moving towards healthier lifestyle changes. That’s why we chose to establish a predictive model for lifestyle-related mortality rates.
Strength and limitations
This research has several advantages and limitations that need to be acknowledged. We utilized sufficient data and implemented measures such as 10-fold cross-validation to ensure and validate the stability of the model. However, it’s important to note that our data is derived from a single cohort, and the effectiveness of the model lacks external validation. This study is a prospective cohort study, and the reliability of causal inference is relatively strong. However, during the follow-up process, a small fraction of participants were lost to follow-up (LTFU) or withdrew from the study for various reasons, leading to the possibility of not capturing the occurrence of outcome events. To the best of our knowledge, this study represents the first attempt to apply ML algorithms to explore the relationship between lifestyle and mortality. Additionally, we leveraged the advantages of tree models to investigate interactions in this context. However, inferences about the role of features based on ML only describe the features’ impact on outcome prediction within the model and may not necessarily reflect their real-world effects. The actual effects require further assessment in conjunction with domain expertise.
Conclusion
By employing modifiable lifestyle factors and readily available indicators, we effectively predicted overall mortality and cardiovascular disease mortality using the XGBoost model. This model can serve as a valuable predictive tool to encourage individuals to modify unhealthy lifestyles and prevent adverse events.
Reference




